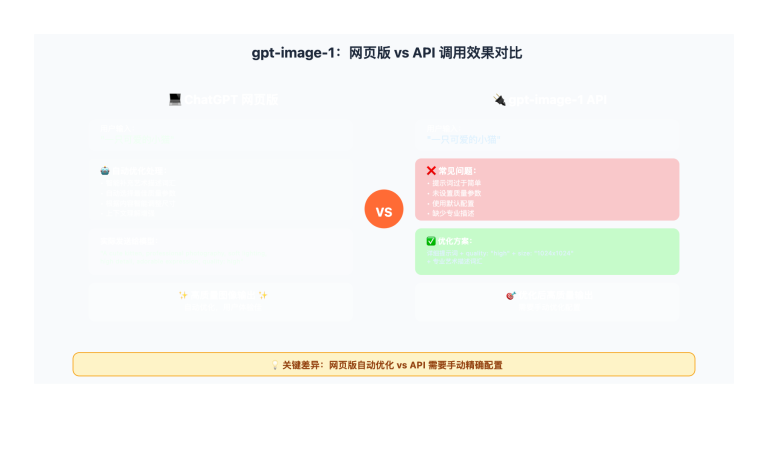
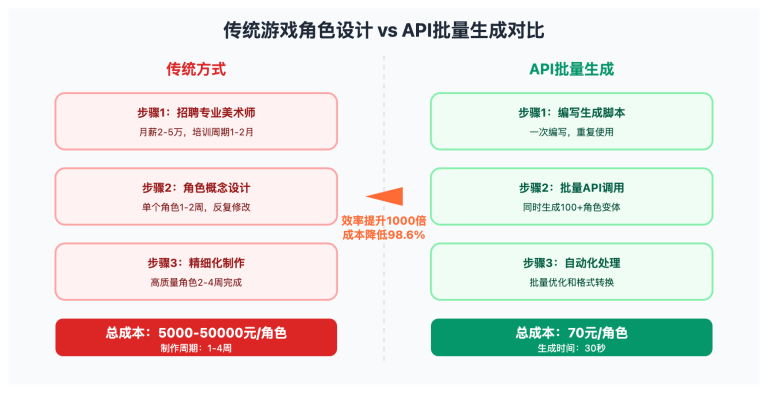
作者注:完整讲解 Z-Image API 的调用方法,包括 Python Diffusers 基础使用、REST API 封装、批量处理和性能优化,帮助开发者快速构建生产级图像生成服务。
对于想要将 Z-Image 集成到自己项目中的开发者来说,掌握其 API 调用方法是关键一步。Z-Image API 基于 Hugging Face Diffusers 库实现,提供了简洁而强大的 Python 接口。无论您是想快速验证原型,还是构建可扩展的生产服务,本文都将为您提供完整的 Z-Image API 使用教程,涵盖从基础调用到高级优化的全流程实践。
核心价值: 通过本教程,您将学会使用 Python Diffusers 调用 Z-Image API,掌握 REST API 封装技巧,了解批量处理和性能优化方法,最终能够构建一个稳定的图像生成服务。
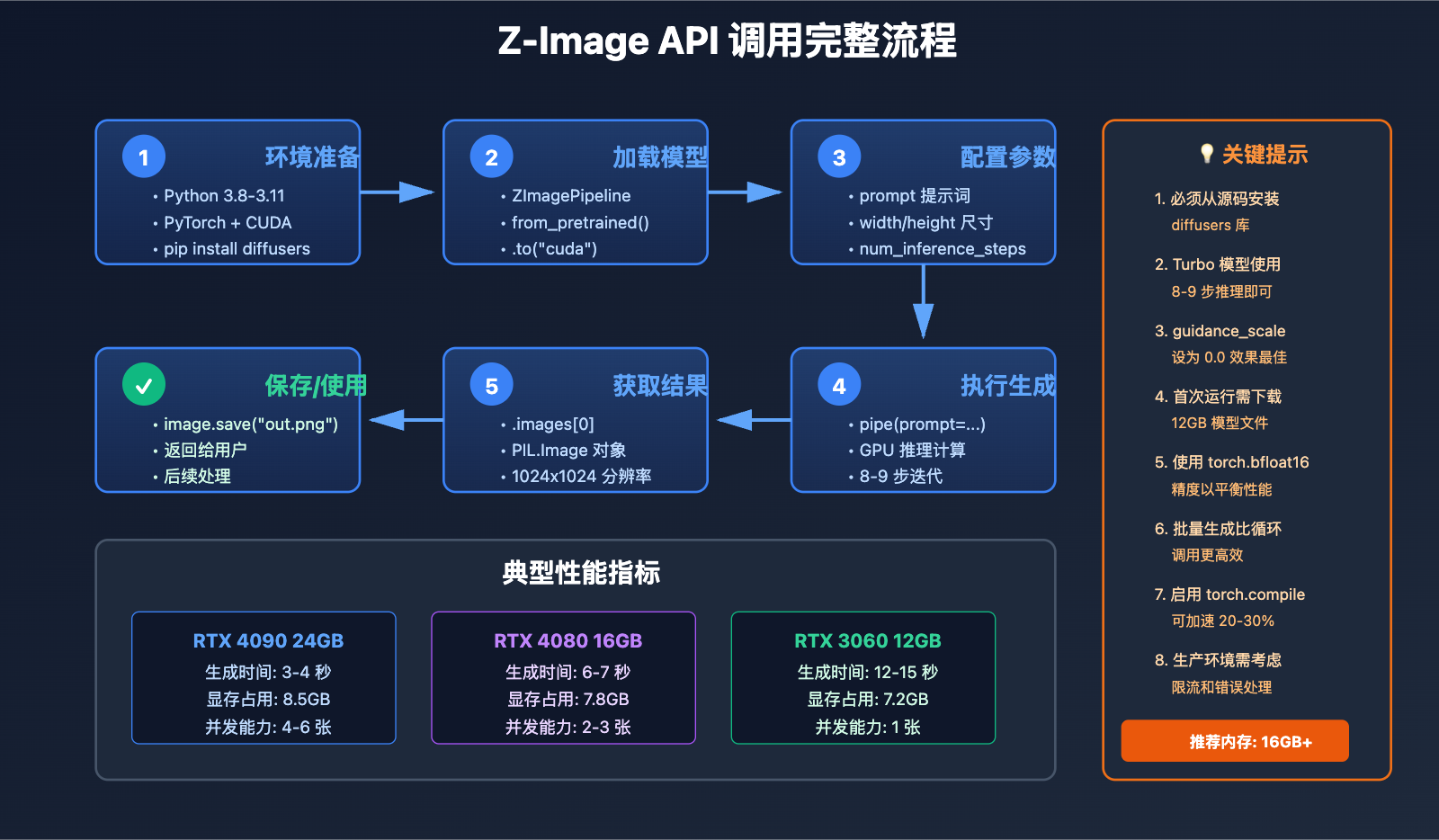
Z-Image API 环境准备
系统要求
在开始使用 Z-Image API 之前,请确保您的开发环境满足以下要求:
硬件要求:
- GPU: NVIDIA GPU,最低 8GB VRAM(推荐 16GB 以上)
- 系统内存: 16GB RAM(推荐 32GB)
- 存储空间: 至少 20GB 可用空间(用于模型文件)
软件要求:
- 操作系统: Linux / Windows 10+ / macOS
- Python 版本: 3.8 – 3.11(推荐 3.10)
- CUDA 版本: 11.8 或 12.1(匹配 PyTorch 版本)
安装依赖库
Z-Image API 依赖 Hugging Face Diffusers 库的最新版本。需要注意的是,必须从源码安装 diffusers,因为 Z-Image 的支持刚刚合并到主分支(PR #12703 和 #12715)。
# 创建虚拟环境(推荐)
conda create -n zimage python=3.10
conda activate zimage
# 安装 PyTorch(CUDA 12.1 版本)
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
# 从源码安装最新版 diffusers(必须)
pip install git+https://github.com/huggingface/diffusers
# 安装其他依赖
pip install transformers accelerate safetensors pillow
关键提示: 如果使用 pip install diffusers 安装稳定版,将无法导入 ZImagePipeline,必须使用源码安装。
🎯 部署建议: 如果您希望快速体验 Z-Image API 而不处理复杂的环境配置,可以考虑使用 API易 apiyi.com 平台提供的统一图像生成 API 接口,该平台已经预配置好所有依赖和优化,开箱即用。
下载模型文件
Z-Image 提供了三个模型变体,根据您的需求选择:
from diffusers import ZImagePipeline
import torch
# 方式1: 自动从 Hugging Face 下载(推荐)
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo", # 或 Z-Image-Base, Z-Image-Edit
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
# 方式2: 从本地路径加载(适合离线环境)
pipe = ZImagePipeline.from_pretrained(
"/path/to/local/model",
torch_dtype=torch.bfloat16,
local_files_only=True,
)
模型选择指南:
| 模型变体 | 推理步数 | 生成速度 | 适用场景 |
|---|---|---|---|
| Z-Image-Turbo | 8-9 步 | 最快 | 快速原型、批量生成 |
| Z-Image-Base | 16-20 步 | 中等 | 高质量单张生成 |
| Z-Image-Edit | 16-20 步 | 中等 | 图像编辑、修复 |
首次运行会自动下载约 12GB 的模型文件到 ~/.cache/huggingface/ 目录。

Z-Image API 基础调用
最简单的图像生成
以下是 Z-Image API 的最基础调用方式:
import torch
from diffusers import ZImagePipeline
# 1. 初始化 Pipeline
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
# 2. 设置提示词
prompt = "一只橙色短毛猫,坐在木质窗台上,阳光透过窗户洒落,背景是模糊的绿色植物,温馨的家居氛围"
# 3. 生成图像
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9,
guidance_scale=0.0,
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
# 4. 保存结果
image.save("output.png")
print("图像已生成: output.png")
执行结果: 在 RTX 4090 上,这段代码通常在 3-4 秒内完成一张 1024×1024 的高质量图像生成。
核心参数详解
Z-Image API 提供了多个参数来控制生成效果:
1. prompt (必需)
- 类型:
str - 说明: 图像描述文本,支持中英文
- 建议: 使用详细的描述,包含主体、环境、光线、风格等要素
- 示例:
prompt = "一座现代建筑,玻璃幕墙,夜晚灯光璀璨,城市天际线背景,超广角摄影,高质量建筑摄影"
2. negative_prompt (可选)
- 类型:
str - 说明: 负面提示词,描述不希望出现的内容
- 示例:
negative_prompt = "模糊,低质量,变形,噪点,水印,文字"
3. height / width
- 类型:
int - 默认值: 1024
- 建议值: 512, 768, 1024, 1280(必须是 64 的倍数)
- 注意: 分辨率越高,显存占用和生成时间越长
4. num_inference_steps
- 类型:
int - 推荐值:
- Turbo 模型: 8-9 步
- Base 模型: 16-20 步
- 规律: 步数越多,质量越高,但速度越慢
5. guidance_scale
- 类型:
float - 推荐值:
- Turbo 模型: 0.0(禁用 CFG)
- Base 模型: 5.0-7.5
- 说明: 控制提示词的引导强度
6. generator
- 类型:
torch.Generator - 作用: 控制随机种子,确保结果可复现
- 示例:
generator = torch.Generator("cuda").manual_seed(42) # 固定种子 generator = torch.Generator("cuda").manual_seed(-1) # 随机种子
批量生成图像
Z-Image API 支持单次调用生成多张图像:
# 批量生成 4 张不同的图像
images = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9,
guidance_scale=0.0,
num_images_per_prompt=4, # 生成 4 张
).images
# 保存所有图像
for idx, img in enumerate(images):
img.save(f"output_{idx}.png")
性能提示: 批量生成比循环调用更高效,可以充分利用 GPU 并行计算能力。但需要注意显存限制,RTX 4090 24GB 显存通常最多支持 4-6 张 1024×1024 图像的并行生成。
🚀 性能优化建议: 对于需要大规模批量生成的场景(如电商产品图批量制作),我们建议使用 API易 apiyi.com 提供的云端 Z-Image API 服务,该服务支持异步任务队列和自动负载均衡,可以同时处理数百个生成请求,无需担心本地硬件瓶颈。
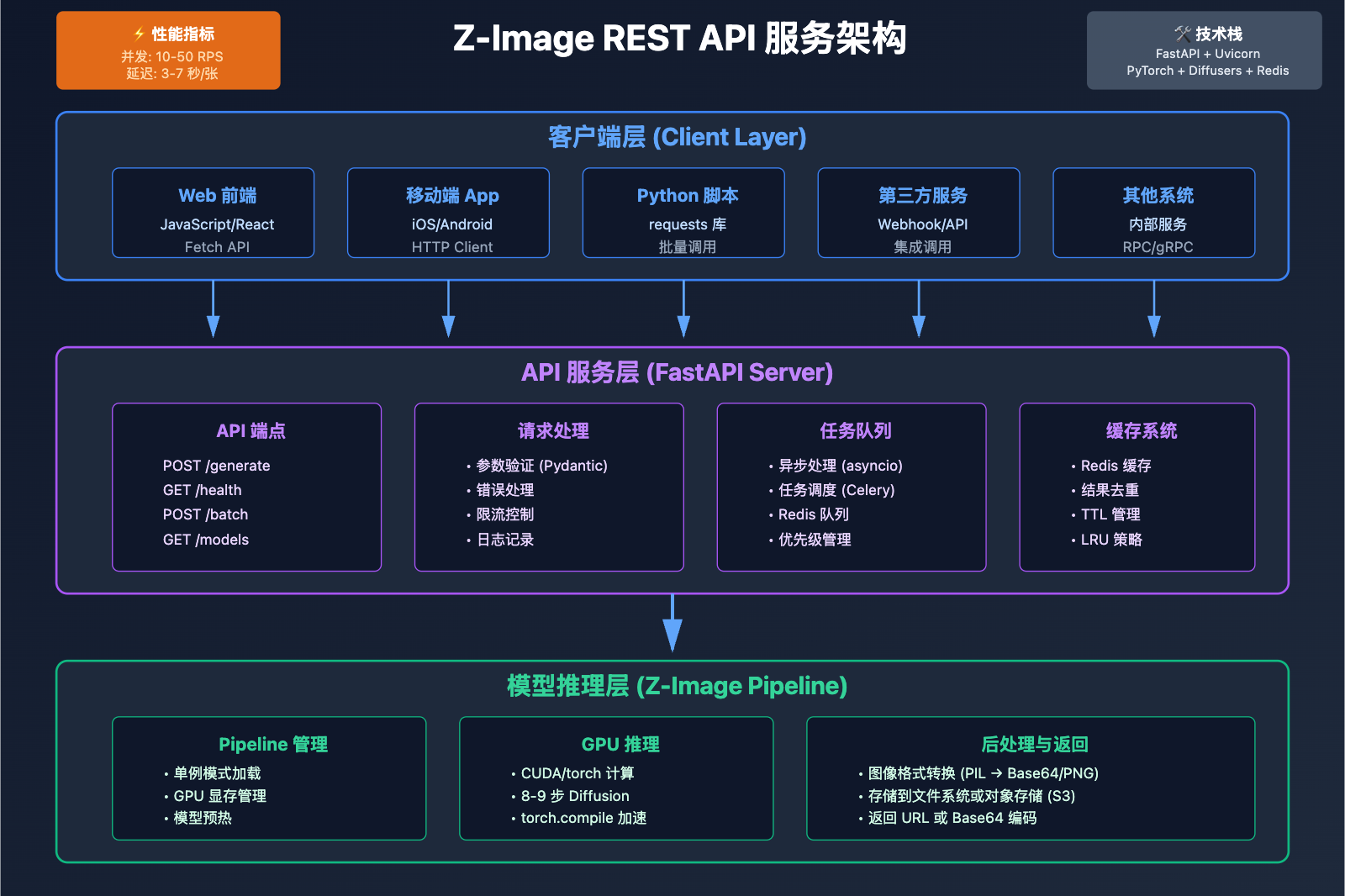
封装 Z-Image REST API 服务
对于生产环境,通常需要将 Z-Image 封装成 REST API 服务,以便其他应用调用。以下是使用 FastAPI 框架的完整实现。
FastAPI 服务器实现
创建 server.py 文件:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from diffusers import ZImagePipeline
import torch
import base64
from io import BytesIO
from PIL import Image
import uvicorn
# 初始化 FastAPI 应用
app = FastAPI(title="Z-Image API Service")
# 全局 Pipeline(启动时加载一次)
pipe = None
@app.on_event("startup")
async def load_model():
"""服务启动时加载模型"""
global pipe
print("正在加载 Z-Image 模型...")
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
print("模型加载完成!")
# 请求数据模型
class GenerateRequest(BaseModel):
prompt: str
negative_prompt: str = ""
width: int = 1024
height: int = 1024
num_inference_steps: int = 9
guidance_scale: float = 0.0
seed: int = -1
num_images: int = 1
# 响应数据模型
class GenerateResponse(BaseModel):
images: list[str] # Base64 编码的图像
seed: int
@app.post("/generate", response_model=GenerateResponse)
async def generate_image(request: GenerateRequest):
"""生成图像的 API 端点"""
try:
# 设置随机种子
if request.seed == -1:
generator = torch.Generator("cuda")
seed = generator.seed()
else:
generator = torch.Generator("cuda").manual_seed(request.seed)
seed = request.seed
# 生成图像
result = pipe(
prompt=request.prompt,
negative_prompt=request.negative_prompt,
height=request.height,
width=request.width,
num_inference_steps=request.num_inference_steps,
guidance_scale=request.guidance_scale,
generator=generator,
num_images_per_prompt=request.num_images,
)
# 将图像转换为 Base64
images_base64 = []
for img in result.images:
buffered = BytesIO()
img.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
images_base64.append(img_str)
return GenerateResponse(images=images_base64, seed=seed)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {"status": "healthy", "model": "Z-Image-Turbo"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
启动服务
# 安装 FastAPI 和 uvicorn
pip install fastapi uvicorn
# 启动服务
python server.py
服务启动后,访问 http://localhost:8000/docs 可以看到自动生成的 API 文档。
客户端调用示例
import requests
import base64
from PIL import Image
from io import BytesIO
# API 请求
url = "http://localhost:8000/generate"
payload = {
"prompt": "一座现代建筑,玻璃幕墙,夜晚灯光璀璨",
"width": 1024,
"height": 1024,
"num_inference_steps": 9,
"seed": 42,
"num_images": 1
}
response = requests.post(url, json=payload)
data = response.json()
# 解码并保存图像
for idx, img_base64 in enumerate(data["images"]):
img_data = base64.b64decode(img_base64)
img = Image.open(BytesIO(img_data))
img.save(f"result_{idx}.png")
print(f"生成完成! 使用种子: {data['seed']}")
Docker 容器化部署
创建 Dockerfile:
FROM nvidia/cuda:12.1.0-runtime-ubuntu22.04
# 安装 Python
RUN apt-get update && apt-get install -y python3.10 python3-pip git
# 设置工作目录
WORKDIR /app
# 复制依赖文件
COPY requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt
# 复制服务代码
COPY server.py .
# 预下载模型(可选,加快启动速度)
RUN python3 -c "from diffusers import ZImagePipeline; ZImagePipeline.from_pretrained('Tongyi-MAI/Z-Image-Turbo')"
# 暴露端口
EXPOSE 8000
# 启动命令
CMD ["python3", "server.py"]
构建并运行容器:
# 构建镜像
docker build -t zimage-api .
# 运行容器(需要 NVIDIA Container Toolkit)
docker run --gpus all -p 8000:8000 zimage-api
🎯 云端部署建议: 对于不熟悉服务器运维的开发者,我们推荐直接使用 AI 图片大师 imagen.apiyi.com 提供的在线 API 服务。该服务基于高性能 GPU 集群部署,提供 99.9% 的 SLA 保证,支持按需付费和包月套餐,无需自己维护服务器和处理扩容问题。
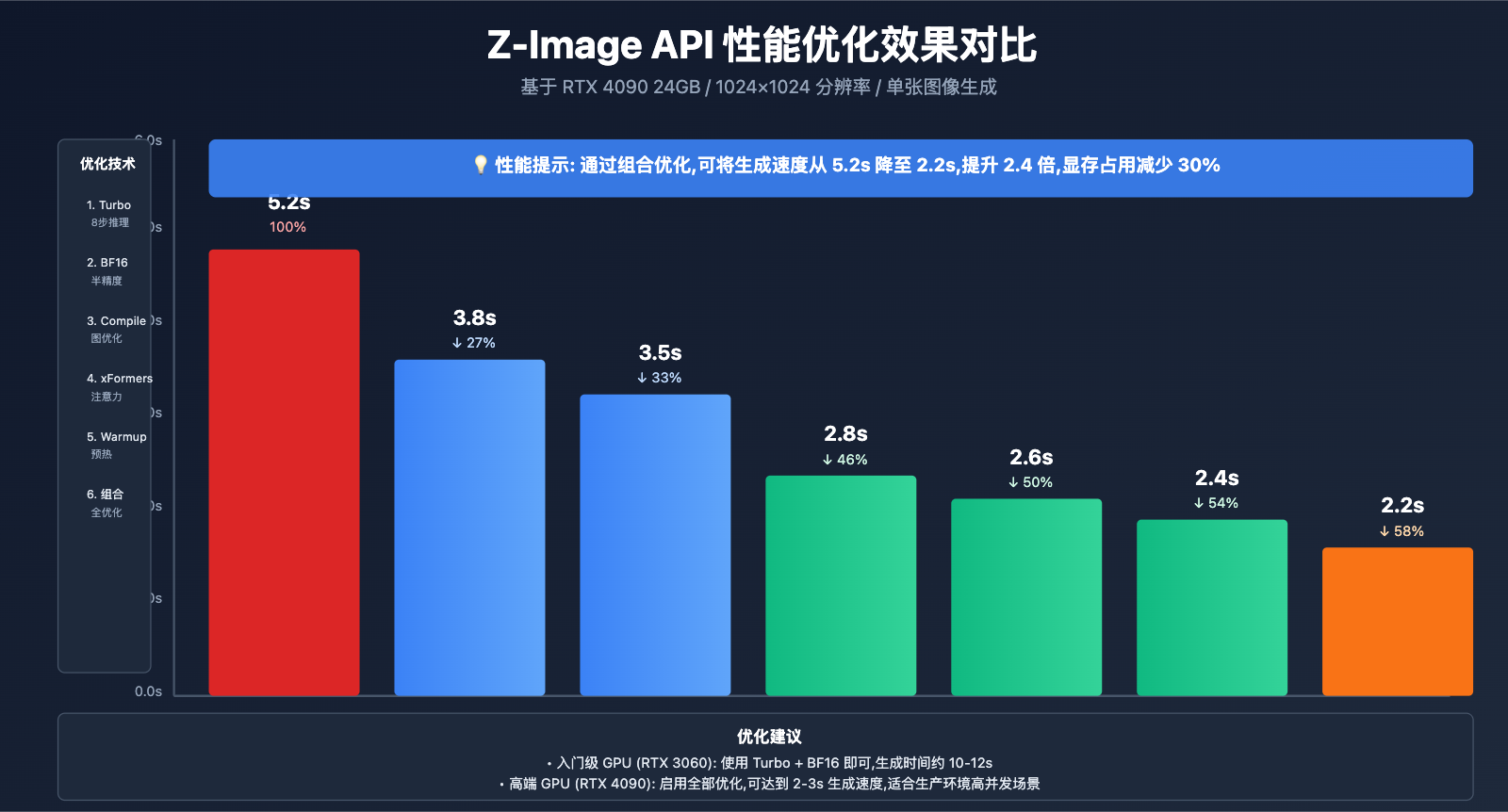
Z-Image API 高级技巧
性能优化策略
1. 启用 Torch Compile(PyTorch 2.0+)
import torch
# 编译模型以加速推理(首次运行会较慢)
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
# 后续调用会显著加速(约 20-30% 提升)
image = pipe(prompt=prompt, ...).images[0]
效果: 在 RTX 4090 上,编译后生成时间从 3.5s 降至 2.8s。
2. 使用 FP16 精度
# 使用半精度浮点数(适合显存紧张的情况)
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.float16, # 改用 FP16
variant="fp16",
)
权衡: FP16 可减少约 30% 显存占用,但在某些情况下可能轻微影响质量。
3. 启用注意力优化
# 启用 xFormers(需要先安装 xformers 库)
pipe.enable_xformers_memory_efficient_attention()
# 或使用 PyTorch 2.0 的 SDPA
pipe.enable_attention_slicing()
4. 批量推理优化
# 对于固定尺寸的批量生成,预热模型
_ = pipe(
prompt="warmup",
height=1024,
width=1024,
num_inference_steps=1,
).images[0]
# 后续相同尺寸的生成会更快
for prompt in prompt_list:
image = pipe(prompt=prompt, height=1024, width=1024).images[0]
错误处理与重试机制
import time
from functools import wraps
def retry_on_cuda_oom(max_retries=3):
"""CUDA OOM 自动重试装饰器"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except RuntimeError as e:
if "out of memory" in str(e):
print(f"CUDA OOM,尝试清理显存... ({attempt+1}/{max_retries})")
torch.cuda.empty_cache()
time.sleep(2)
if attempt == max_retries - 1:
raise
else:
raise
return wrapper
return decorator
@retry_on_cuda_oom(max_retries=3)
def generate_with_retry(pipe, prompt, **kwargs):
return pipe(prompt=prompt, **kwargs).images[0]
多 GPU 并行生成
import torch.multiprocessing as mp
def worker(gpu_id, prompt_queue, result_queue):
"""单个 GPU 工作进程"""
# 设置当前 GPU
torch.cuda.set_device(gpu_id)
# 加载模型到指定 GPU
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
).to(f"cuda:{gpu_id}")
# 处理队列中的任务
while True:
prompt = prompt_queue.get()
if prompt is None: # 结束信号
break
image = pipe(prompt=prompt, height=1024, width=1024).images[0]
result_queue.put((prompt, image))
# 使用多 GPU 生成
if __name__ == "__main__":
num_gpus = torch.cuda.device_count()
prompt_queue = mp.Queue()
result_queue = mp.Queue()
# 启动工作进程
processes = []
for gpu_id in range(num_gpus):
p = mp.Process(target=worker, args=(gpu_id, prompt_queue, result_queue))
p.start()
processes.append(p)
# 分发任务
prompts = ["提示词1", "提示词2", "提示词3", ...]
for prompt in prompts:
prompt_queue.put(prompt)
# 发送结束信号
for _ in range(num_gpus):
prompt_queue.put(None)
# 收集结果
results = []
for _ in range(len(prompts)):
results.append(result_queue.get())
# 等待所有进程结束
for p in processes:
p.join()
常见问题与解决方案
Q1: 导入 ZImagePipeline 失败
错误信息: ImportError: cannot import name 'ZImagePipeline' from 'diffusers'
解决方案:
# 必须从源码安装最新版 diffusers
pip uninstall diffusers
pip install git+https://github.com/huggingface/diffusers
Q2: CUDA 内存不足
错误信息: RuntimeError: CUDA out of memory
解决方案:
- 降低分辨率: 1024 → 768 或 512
- 使用 FP16 精度代替 BF16
- 减少
num_images_per_prompt数量 - 启用注意力切片:
pipe.enable_attention_slicing()
Q3: 批量生成时出现断言错误
错误信息: AssertionError (Issue #12738)
解决方案: 这是已知的 Bug,当前版本批量大小建议设为 1,循环调用而非使用 num_images_per_prompt > 1。
Q4: 生成速度慢
优化建议:
- 使用 Turbo 模型代替 Base 模型
- 启用
torch.compile()编译优化 - 预热模型(首次推理较慢)
- 检查是否启用了不必要的 safety checker
Q5: 如何实现异步任务队列?
推荐方案: 使用 Celery + Redis
from celery import Celery
app = Celery('zimage_tasks', broker='redis://localhost:6379/0')
@app.task
def generate_image_task(prompt, **kwargs):
# 加载模型并生成(在 Worker 进程中)
pipe = get_or_create_pipeline() # 单例模式
image = pipe(prompt=prompt, **kwargs).images[0]
# 保存到存储并返回 URL
return save_and_return_url(image)
🚀 企业级解决方案: 如果您的业务需要高并发、异步处理、任务队列管理等企业级功能,建议使用 API易 apiyi.com 平台提供的托管 Z-Image API 服务。该平台内置了完善的任务调度系统、自动重试机制、结果缓存和 CDN 加速,可以大幅降低开发和运维成本。
生产环境最佳实践
1. 模型加载策略
import threading
class ZImageService:
"""单例模式的 Z-Image 服务"""
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance.pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
).to("cuda")
return cls._instance
def generate(self, prompt, **kwargs):
return self.pipe(prompt=prompt, **kwargs).images[0]
# 全局唯一实例
service = ZImageService()
2. 请求限流与排队
from fastapi import FastAPI, BackgroundTasks
from asyncio import Queue, create_task
import asyncio
app = FastAPI()
request_queue = Queue(maxsize=100) # 最多排队 100 个请求
async def queue_worker():
"""后台队列处理器"""
while True:
task = await request_queue.get()
# 处理任务
await task()
request_queue.task_done()
@app.on_event("startup")
async def start_worker():
create_task(queue_worker())
@app.post("/generate")
async def generate(request: GenerateRequest):
if request_queue.full():
raise HTTPException(status_code=503, detail="服务繁忙,请稍后重试")
# 添加到队列
future = asyncio.Future()
await request_queue.put(lambda: process_request(request, future))
return await future
3. 监控与日志
import logging
import time
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ZImageMetrics:
"""性能指标收集"""
def __init__(self):
self.total_requests = 0
self.total_time = 0.0
self.errors = 0
def record(self, duration, success=True):
self.total_requests += 1
self.total_time += duration
if not success:
self.errors += 1
def get_stats(self):
avg_time = self.total_time / self.total_requests if self.total_requests > 0 else 0
return {
"total_requests": self.total_requests,
"avg_time": avg_time,
"error_rate": self.errors / self.total_requests if self.total_requests > 0 else 0,
}
metrics = ZImageMetrics()
def generate_with_metrics(prompt, **kwargs):
start = time.time()
try:
result = pipe(prompt=prompt, **kwargs).images[0]
metrics.record(time.time() - start, success=True)
logger.info(f"生成成功: {prompt[:50]}... 耗时 {time.time()-start:.2f}s")
return result
except Exception as e:
metrics.record(time.time() - start, success=False)
logger.error(f"生成失败: {str(e)}")
raise
4. 结果缓存
import hashlib
import json
from functools import lru_cache
def get_cache_key(prompt, **kwargs):
"""生成缓存键"""
params = {"prompt": prompt, **kwargs}
params_str = json.dumps(params, sort_keys=True)
return hashlib.md5(params_str.encode()).hexdigest()
# 内存缓存(适合小规模)
@lru_cache(maxsize=1000)
def generate_cached(prompt, seed, width, height, steps):
return pipe(
prompt=prompt,
generator=torch.Generator("cuda").manual_seed(seed),
width=width,
height=height,
num_inference_steps=steps,
).images[0]
# Redis 缓存(适合分布式)
import redis
import pickle
redis_client = redis.Redis(host='localhost', port=6379, db=0)
def generate_with_redis_cache(prompt, **kwargs):
cache_key = get_cache_key(prompt, **kwargs)
# 检查缓存
cached = redis_client.get(cache_key)
if cached:
return pickle.loads(cached)
# 生成并缓存
image = pipe(prompt=prompt, **kwargs).images[0]
redis_client.setex(cache_key, 3600, pickle.dumps(image)) # 缓存 1 小时
return image
总结与下一步
通过本教程,您已经掌握了 Z-Image API 的完整使用方法,从基础的 Python 调用到生产级的 REST API 服务搭建。以下是关键要点回顾:
核心知识点:
- ✅ 必须从源码安装 diffusers 才能使用 ZImagePipeline
- ✅ Turbo 模型使用 8-9 步推理,guidance_scale 设为 0.0
- ✅ 使用 FastAPI 可以快速封装 REST API 服务
- ✅ 批量生成比循环调用更高效
- ✅ torch.compile() 可以显著提升推理速度
- ✅ 生产环境需要考虑限流、缓存、监控等机制
推荐资源:
- Z-Image 官方仓库: github.com/Tongyi-MAI/Z-Image
- Diffusers 文档: huggingface.co/docs/diffusers
- API易图像生成 API: apiyi.com(支持 Z-Image 和其他主流模型)
- AI 图片大师在线工具: imagen.apiyi.com(免费体验 Z-Image)
下一步学习:
- 探索 Z-Image 的图像编辑功能(Z-Image-Edit 模型)
- 研究提示词工程技巧,提升生成质量
- 学习 Z-Image 与其他模型的对比和选型
- 了解商业化部署的成本和定价策略
💡 技术支持: 如果您在使用 Z-Image API 过程中遇到技术问题,或者希望获得企业级的技术支持和 SLA 保障,欢迎访问 API易 apiyi.com 平台,我们的技术团队会为您提供专业的咨询服务和定制化解决方案。
延伸阅读:
- 《Z-Image 新手完全指南:从入门到精通》
- 《Z-Image vs Nano Banana Pro:开源图像模型对比分析》
- 《Z-Image 提示词工程:10 个高质量模板分享》
- 《Z-Image 商业应用案例:电商产品图自动化生成》
本文由 API易技术团队编写,持续更新中。如有疑问或建议,欢迎通过 help.apiyi.com 联系我们。