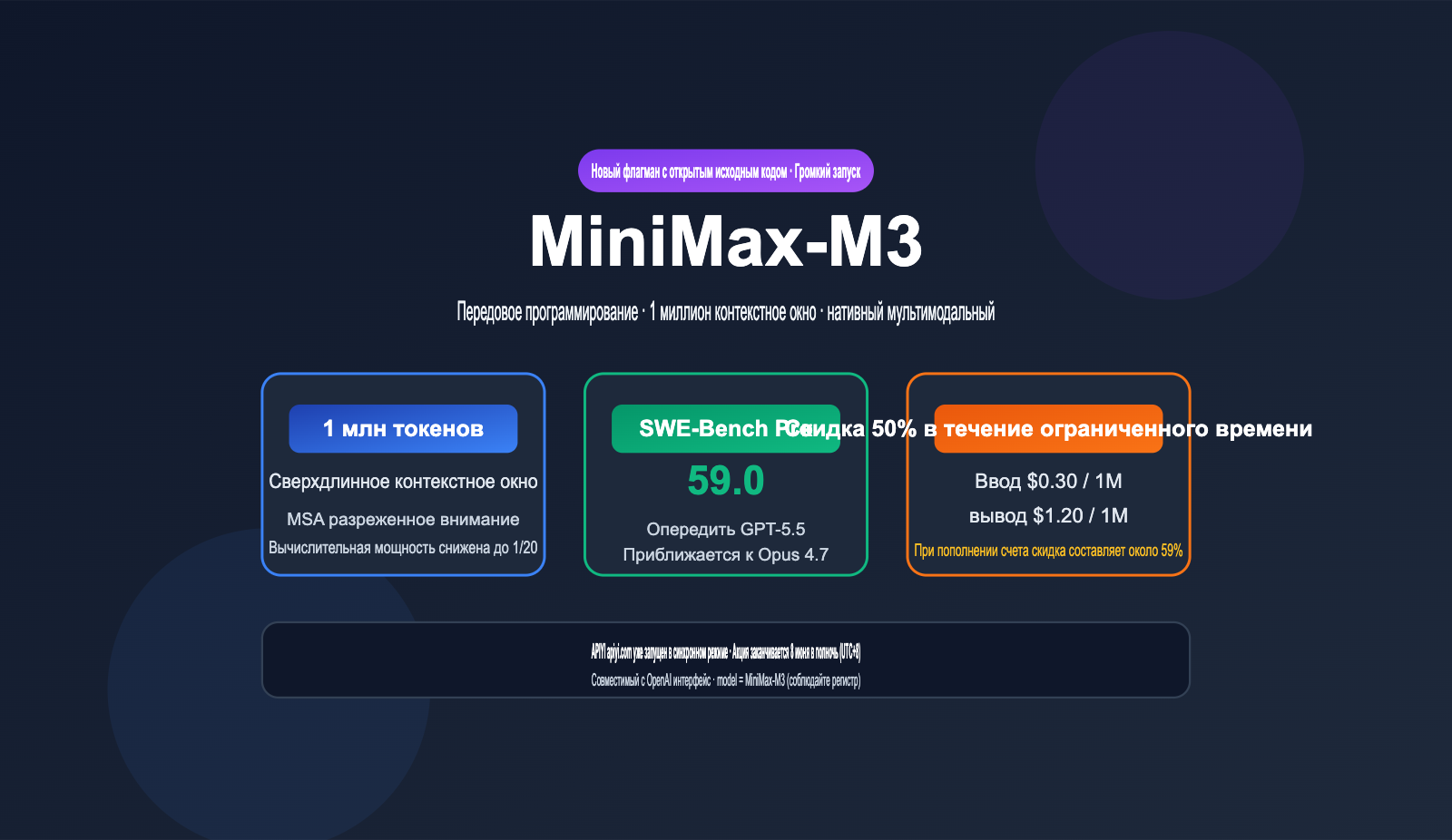
1 июня 2026 года компания MiniMax официально представила свой новый флагман с открытыми весами — MiniMax-M3. Это первая в индустрии модель, которая объединяет в себе три ключевые возможности: передовой уровень программирования, контекстное окно на 1 миллион токенов и нативную мультимодальность. В бенчмарке SWE-Bench Pro модель набрала 59,0 баллов, обойдя GPT-5.5 и Gemini 3.1 Pro и вплотную приблизившись к результатам Claude Opus 4.7.
Еще более впечатляет ценовая политика. Стандартная стоимость составляет $0,60 за 1 млн входных токенов и $2,40 за 1 млн выходных, что само по себе в 10-20 раз дешевле аналогичных закрытых моделей. В период запуска действует скидка 50%, снижающая цену до $0,30 и $1,20 соответственно. На данный момент MiniMax-M3 уже доступна на платформе APIYI (apiyi.com) с учетом этой скидки, а с учетом бонусов при пополнении баланса реальная стоимость может быть ниже на 59%. Акция продлится до полуночи 8 июня (UTC+8).
В этой статье мы разберем архитектурные особенности MiniMax-M3, результаты тестов, тарифную сетку и код для интеграции, чтобы помочь вам решить, стоит ли переходить на эту модель в период действия акции.
Что такое MiniMax-M3: флагман "три-в-одном" в мире open-source
MiniMax-M3 — это новое поколение флагманских моделей от MiniMax, пришедшее на смену серии M2. Модель ориентирована на задачи программирования и работу с агентами. Она использует архитектуру MoE (смесь экспертов) с тонкой грануляцией: около 229,9 млрд параметров всего, при этом на каждый токен активируется лишь около 9,8 млрд, распределенных по 256 экспертам. Это означает, что по стоимости вывода модель сопоставима с компактными решениями уровня 10B, а по возможностям — с топовыми флагманами.
Объем обучающих данных составляет около 100 триллионов токенов, причем мультимодальные данные были интегрированы еще на этапе предварительного обучения. Благодаря этому мультимодальность MiniMax-M3 является "нативной": понимание изображений и видео встроено непосредственно в семантическое пространство, а не добавлено через внешний визуальный энкодер. Помимо обработки изображений и видео, модель поддерживает управление компьютером (Computer Use), что открывает широкие возможности для агентских сценариев.
Разработчики обещают открыть веса модели и технический отчет в течение 10 дней после релиза. Их можно будет найти на HuggingFace и GitHub для частного развертывания и дообучения. Учитывая лицензию модифицированного MIT, использовавшуюся в серии M2, порог для коммерческого использования будет низким (подробности будут в официальной лицензии).
Основные характеристики MiniMax-M3
| Параметр | Значение |
|---|---|
| Дата релиза | 1 июня 2026 г. |
| Архитектура | MoE, 229,9 млрд параметров / 9,8 млрд активных, 256 экспертов |
| Механизм внимания | MSA (MiniMax Sparse Attention) — разреженное внимание |
| Контекстное окно | 1 000 000 токенов (в 5 раз больше, чем у серии M2) |
| Поддержка модальностей | Текст, изображения, видео (вход), текст (выход), управление ПК |
| Обучающие данные | ~100T токенов, мультимодальные корпуса |
| Режим мышления | Переключаемый режим Thinking, цена не меняется |
| Планы по открытию | Открытие весов и отчета в течение 10 дней |
🎯 Совет для быстрого старта: Если хотите протестировать MiniMax-M3 прямо сейчас, не дожидаясь открытия весов и настройки собственного кластера, рекомендуем воспользоваться API-интерфейсом, совместимым с OpenAI, на платформе APIYI (apiyi.com). Просто укажите имя модели
MiniMax-M3— вы сможете провести сравнительные тесты за считанные минуты, а с учетом акции стоимость будет вдвое ниже.
Что означают результаты MiniMax-M3 в бенчмарке SWE-Bench Pro: 59.0 баллов
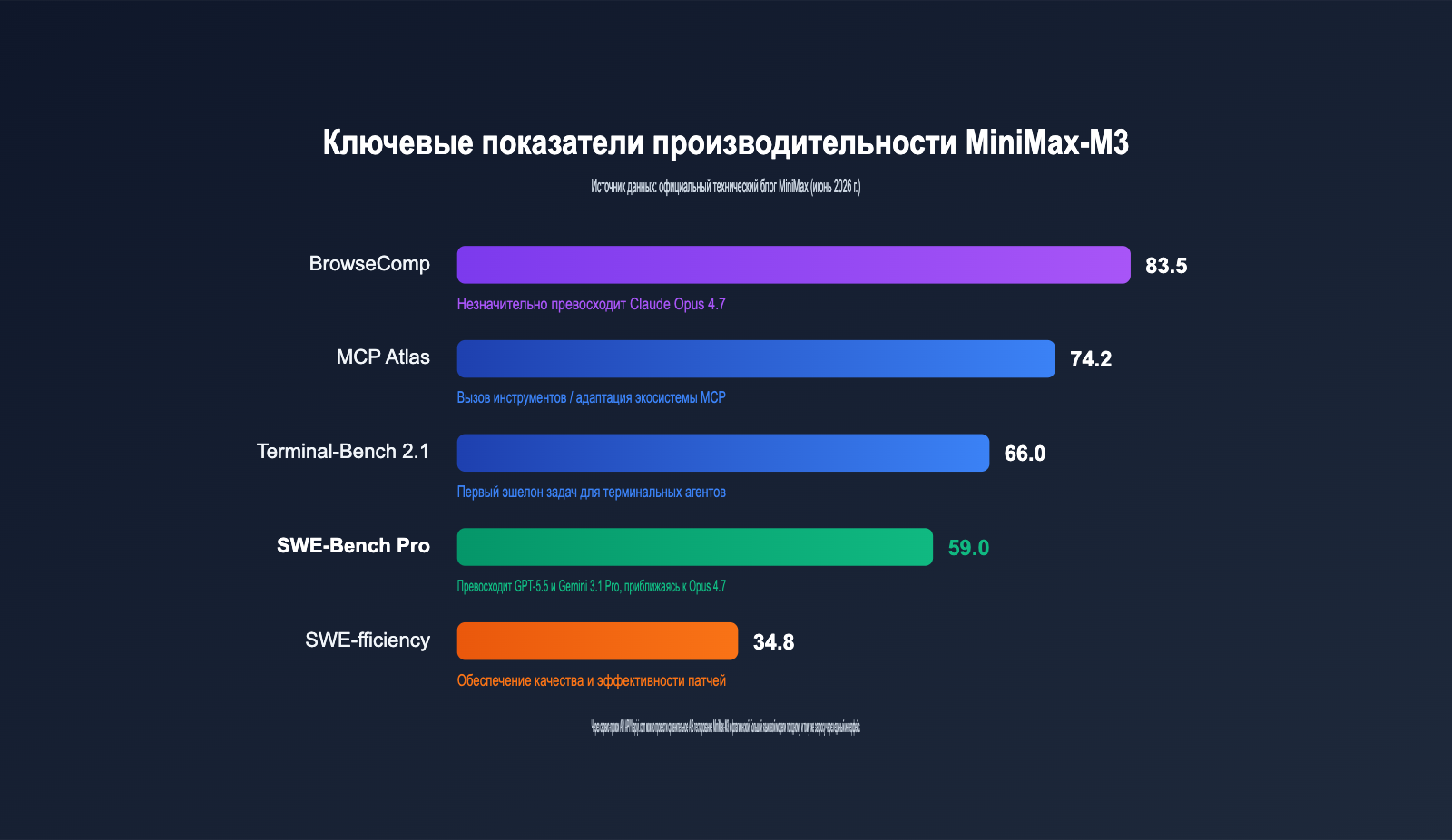
SWE-Bench Pro сегодня считается одним из самых сложных бенчмарков для оценки навыков разработки ПО. Он проверяет способность модели исправлять баги и создавать патчи в реальных репозиториях в режиме «от начала до конца». Результат MiniMax-M3 в 59.0 баллов, согласно официальным данным, превосходит GPT-5.5 и Gemini 3.1 Pro, вплотную приближаясь к Claude Opus 4.7. Для модели, которая скоро выйдет в open-source и имеет менее 10 млрд активных параметров, это первый случай, когда открытая модель обходит закрытых флагманов в данном тесте.
Помимо программирования, впечатляют и показатели для агентов. В Terminal-Bench 2.1 модель набрала 66.0 баллов, в MCP Atlas — 74.2, а в задаче автономного браузинга BrowseComp — 83.5 (здесь она даже немного обошла Claude Opus 4.7). В мультимодальных задачах MiniMax-M3 превзошла Opus 4.7 в SVG-Bench, а в бенчмарке понимания документов OmniDocBench оказалась выше Gemini 3.1 Pro.
Конечно, это не тотальное доминирование. В PostTrainBench, который оценивает способности модели к дообучению, MiniMax-M3 набрала 0.37, что ниже 0.42 у Claude Opus 4.7 и сопоставимо с 0.39 у GPT-5.5. Напоминаем: эти цифры взяты из официального технического блога, независимые тесты еще продолжаются. Для критически важных задач рекомендуем проводить собственные замеры.
Сравнение MiniMax-M3 с основными флагманскими моделями
| Бенчмарк | MiniMax-M3 | Вывод |
|---|---|---|
| SWE-Bench Pro | 59.0 | Выше GPT-5.5 и Gemini 3.1 Pro, почти на уровне Opus 4.7 |
| Terminal-Bench 2.1 | 66.0 | Первый эшелон для терминальных агентов |
| BrowseComp | 83.5 | Небольшое преимущество над Claude Opus 4.7 |
| MCP Atlas | 74.2 | Высокая способность к вызову инструментов и адаптации к экосистеме MCP |
| SWE-fficiency | 34.8 | Баланс между качеством патчей и скоростью работы |
| PostTrainBench | 0.37 | Ниже Opus 4.7 (0.42), на уровне GPT-5.5 (0.39) |
Если хотите проверить эти цифры самостоятельно, вы можете использовать платформу APIYI: она позволяет отправлять один и тот же промпт одновременно в MiniMax-M3, GPT-5.5 и Claude Opus 4.7. Интерфейс унифицирован, так что для переключения модели достаточно изменить один параметр, что идеально подходит для A/B тестирования.
Архитектура MiniMax-M3: как разреженное внимание MSA обеспечивает контекст 1M
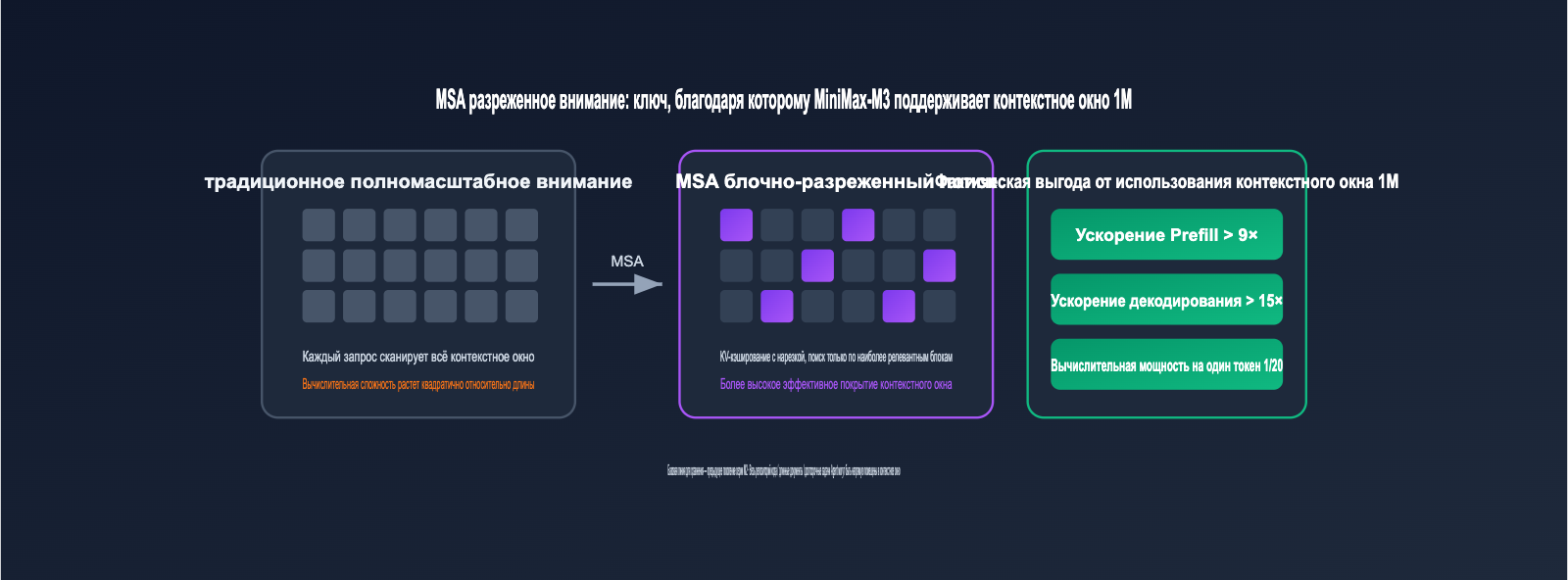
Контекстное окно в 1 млн токенов — это уже не новость, но сделать его экономически выгодным — вот настоящий вызов. Решение MiniMax-M3 — это собственная разработка MSA (MiniMax Sparse Attention). В традиционном механизме внимания вычислительная сложность растет квадратично от длины контекста, тогда как MSA разбивает KV-кэш на блоки и позволяет каждому запросу (query) обращаться только к наиболее релевантным блокам, обеспечивая более эффективное использование контекста.
Официальные данные впечатляют: при контексте 1 млн токенов вычислительные затраты на один токен у MiniMax-M3 в 20 раз ниже, чем у предыдущего поколения M2. Скорость префиллинга (prefill) выросла более чем в 9 раз, а декодирования (decode) — более чем в 15 раз. На уровне операторов это в 4 раза быстрее, чем открытая Flash-Sparse-Attention. Проще говоря, теперь можно загрузить в контекст целый репозиторий кода, сотни страниц PDF или часовое видео с конференции, не беспокоясь о задержках и стоимости.
Для разработчиков это означает, что многие задачи, которые раньше требовали RAG, векторного поиска или многократного суммаризации, теперь можно решать «в лоб», просто подав всё в промпт. Агентам для длинных задач больше не нужно постоянно сжимать историю, что значительно повышает связность выполнения задач.
💡 Совет по работе с длинным контекстом: тарификация для 1M токенов разделена на два уровня: при вводе более 512K токенов цена удваивается. Рекомендуем сначала протестировать качество на реальных документах объемом 200K–400K в панели управления APIYI (apiyi.com), и только после подтверждения результатов переходить к более длинным входным данным. Статистика использования на платформе поможет вам точно рассчитать стоимость токенов для каждого вызова.
Стоимость API MiniMax-M3: скидка 50% и итоговая выгода до 59% при пополнении баланса
Ценообразование MiniMax-M3 построено на ступенчатой модели в зависимости от длины входных данных. Запросы до 512K токенов тарифицируются по стандартному тарифу, а всё, что свыше 512K — по тарифу для длинного контекста. В период запуска действует скидка 50% на все уровни. Платформа APIYI (apiyi.com) уже синхронизировала свои цены с официальными. Акция продлится до 00:00 8 июня 2026 года (UTC+8), дальнейшая политика скидок будет определена позже.
Таблица тарифов API MiniMax-M3 (за 1 млн токенов)
| Уровень тарификации | Вход (цена со скидкой 50%) | Выход (цена со скидкой 50%) | Стандартная цена (Вход/Выход) |
|---|---|---|---|
| 0-512K токенов | $0.30 | $1.20 | $0.60 / $2.40 |
| Свыше 512K токенов | $0.60 | $2.40 | $1.20 / $4.80 |
Чтобы лучше прочувствовать выгоду: выполнение задачи по анализу кода объемом в миллион токенов на флагманских закрытых моделях может стоить более десяти долларов, тогда как с MiniMax-M3 по акционной цене это обойдется в несколько десятков центов. Разница в стоимости достигает 10–20 раз. Для высоконагруженных агентских пайплайнов, пакетной миграции кода или обработки длинных документов эта экономия позволит «отбить» стоимость рабочей станции всего за месяц.
На платформе APIYI можно сэкономить еще больше. Бонусы при пополнении баланса суммируются со скидкой 50%, что дает итоговую выгоду до 59% от стандартной цены. Если вашей команде нужны стабильные объемы вызовов моделей, пополнение баланса до 8 июня — самый выгодный вариант.

Быстрый старт с API MiniMax-M3: подключение за 5 минут
MiniMax-M3 на платформе APIYI использует стандартный протокол, совместимый с OpenAI. Это значит, что любой SDK, фреймворк или клиент, поддерживающий настройку base_url, будет работать без проблем. Единственный нюанс: название модели MiniMax-M3 чувствительно к регистру — буква M должна быть заглавной. Если написать minimax-m3, вы получите ошибку о том, что модель не найдена.
Подключение состоит из трех шагов: зарегистрируйтесь на APIYI (apiyi.com) и создайте API-ключ; установите base_url на https://api.apiyi.com/v1; в параметре model укажите MiniMax-M3. Ниже приведен простейший пример на Python:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="MiniMax-M3", # Важно: M должна быть заглавной
messages=[
{"role": "user", "content": "Реализуй на Python функцию Фибоначчи с LRU-кэшем"}
]
)
print(response.choices[0].message.content)
Если нужно передать изображение или видео, используйте стандартный мультимодальный формат OpenAI: замените content на массив, содержащий image_url. MiniMax-M3 выполнит визуальный анализ и генерацию кода в рамках одной сессии. В таких инструментах, как Cline, Cursor или OpenClaw, достаточно просто обновить base_url и название модели в настройках, чтобы переключить «мозги» вашего помощника на MiniMax-M3.
Краткий гид по сценариям использования MiniMax-M3
| Сценарий | Пригодность | Примечание |
|---|---|---|
| Агентское программирование / исправление багов | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, не теряет контекст в длинных задачах |
| Анализ и миграция целых репозиториев | ⭐⭐⭐⭐⭐ | Контекстное окно 1M позволяет вместить средний проект целиком |
| Анализ длинных документов / мультимодальность | ⭐⭐⭐⭐⭐ | OmniDocBench превосходит Gemini 3.1 Pro |
| Автономный браузинг и вызов инструментов | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Научные исследования / сложные рассуждения | ⭐⭐⭐ | PostTrainBench чуть слабее Opus 4.7, рекомендуется гибридная схема |
Гибридная схема — наиболее рациональный подход: повседневные задачи по кодингу и работе с документами (80% нагрузки) делегируйте MiniMax-M3, а самые сложные задачи на логический вывод оставьте для Claude Opus 4.7 или GPT-5.5. Используя единый интерфейс APIYI для маршрутизации моделей, вы сможете реализовать такую стратегию «ценового расслоения» в рамках одного кода, не заботясь о поддержке ключей и SDK от разных провайдеров.
FAQ по MiniMax-M3
В1: Когда заканчивается акция со скидкой 50% на MiniMax-M3?
Акция действует до 00:00 8 июня 2026 года (UTC+8), сроки синхронизированы на платформе APIYI и официальном сайте MiniMax. О дальнейшей ценовой политике пока не сообщалось, но, скорее всего, цены вернутся к стандартным. Если у вас планируются большие объемы вызовов, рекомендуем пополнить баланс до окончания акции — с учетом бонусов за пополнение реальная стоимость может составить около 41% от базовой цены.
В2: MiniMax-M3 действительно с открытым исходным кодом? Можно ли уже скачать веса?
Разработчики пообещали открыть веса модели и опубликовать технический отчет в течение 10 дней после релиза. Ожидается, что они появятся на странице MiniMaxAI на HuggingFace. На момент написания статьи загрузка весов еще не завершена. Команды, которые не могут ждать и хотят развернуть модель локально, могут сначала протестировать её возможности через API, а затем оценить затраты на оборудование для приватного хостинга — модель MoE с 230 млрд параметров требует серьезных мощностей видеопамяти.
В3: Контекстное окно в 1 млн токенов — это маркетинговый ход или оно реально работает?
Архитектура MSA делает работу с 1 млн токенов инженерно оправданной: скорость prefill выросла более чем в 9 раз, decode — в 15 раз, а вычислительная нагрузка на один токен снизилась в 20 раз по сравнению с предыдущим поколением. Однако следите за тарификацией: при вводе более 512 тыс. токенов цена удваивается. Советуем контролировать длину контекста в зависимости от задач, а не заполнять его «на всякий случай».
В4: Что выбрать: MiniMax-M3, GPT-5.5 или Claude Opus 4.7?
Зависит от типа задач и бюджета. Для программирования агентов, работы с длинным контекстом и мультимодальными документами MiniMax-M3 сейчас вне конкуренции по соотношению цены и качества. В задачах, требующих сложнейших рассуждений и научных исследований, Opus 4.7 всё еще сохраняет преимущество. Мы рекомендуем провести небольшое сравнительное тестирование с вашими реальными промптами на платформе APIYI — данные будут убедительнее любых рейтингов.
Итог: MiniMax-M3 делает флагманские возможности доступными каждому
Релиз MiniMax-M3 стал настоящей «бомбой» на рынке моделей 2026 года: открытые веса + результат 59.0 в SWE-Bench Pro (обход GPT-5.5) + 1 млн токенов контекста + нативная мультимодальность при цене в 5–10% от стоимости закрытых флагманов. Даже если независимые тесты покажут чуть другие цифры, лидерство этой модели по «цене-качеству» будет сложно оспорить.
Сейчас лучшее время воспользоваться ценовым окном: скидка 50% (ввод $0.30 / вывод $1.20 за 1 млн токенов) действует до 8 июня. На APIYI apiyi.com можно дополнительно суммировать это с бонусами за пополнение, получив итоговую скидку около 59%. Самая разумная стратегия сейчас — запустить тесты с минимальными затратами, а затем решать, стоит ли переводить на эту модель основной продакшн-трафик.
Подробности акции и актуальные новости о модели можно найти в официальном блоге APIYI: docs.apiyi.com/news/minimax-m3-launch
Автор: Команда APIYI
Специализируемся на агрегации API больших языковых моделей и лучших практиках их внедрения. Больше обзоров моделей и руководств по интеграции вы найдете на APIYI apiyi.com.