В начале апреля 2026 года таинственная AI-модель для генерации видео под названием HappyHorse тихо появилась в слепом рейтинге Artificial Analysis Video Arena. Версии V1 и V2 практически одновременно взлетели на вершины Elo-рейтингов в категориях «текст-в-видео» и «изображение-в-видео», оставив позади таких гигантов, как Seedance 2.0, Kling 3.0 и PixVerse V6. Однако всего через несколько дней HappyHorse 1.0 внезапно исчезла из списков, оставив после себя лишь несколько скриншотов и скудную официальную страницу.
Вокруг модели HappyHorse в англоязычном AI-сообществе моментально разгорелись споры: не маскируется ли под этим именем Wan 2.7? Не является ли это экспериментальной разработкой следующего поколения от команды ByteDance Seedance? Или же это внезапный прорыв какой-то неизвестной азиатской лаборатории? В этой статье мы на основе общедоступных проверенных данных разберем архитектуру, производительность, статус открытого кода и вероятное происхождение HappyHorse 1.0, чтобы помочь вам решить, стоит ли добавлять эту «темную лошадку» в ваш стек инструментов для генерации видео.
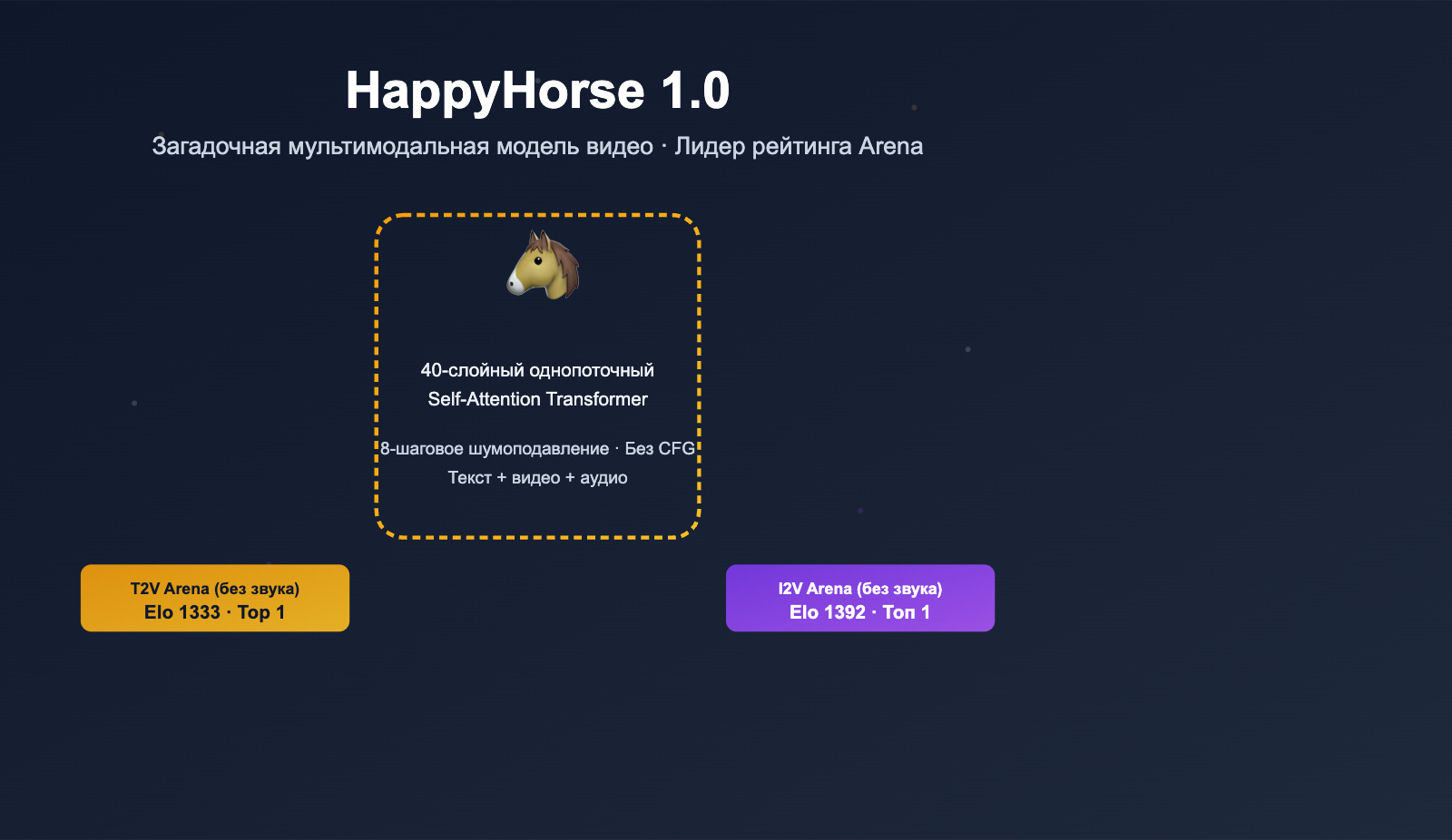
Краткий обзор ключевой информации о модели HappyHorse
Прежде чем переходить к техническим деталям, давайте сведем всю известную информацию в одну таблицу для быстрого ознакомления.
| Параметр | Известные данные о HappyHorse 1.0 |
|---|---|
| Тип модели | Модель генерации видео по тексту и изображению (синхронная генерация видео и аудио) |
| Архитектура | 40-слойный однопотоковый Self-Attention Transformer, без Cross-Attention |
| Шаги вывода | Всего 8 шагов шумоподавления, без использования CFG (Classifier-Free Guidance) |
| Поддержка языков | Китайский, английский, японский, корейский, немецкий, французский |
| Релиз | Базовая модель / дистиллированная модель / модель апскейлинга / код вывода (официально заявлено как полностью открытое ПО) |
| Где была замечена | Artificial Analysis Video Arena (в некоторых источниках упоминается видео-трек LMArena) |
| Текущий статус | V1/V2 исчезли из публичных рейтингов, официальный сайт работает, но на GitHub/Model Hub статус «Coming Soon» |
| Вероятное происхождение | Азиатская команда, сообщество предполагает связь с экосистемой Wan 2.7 / Seedance, но официально не подтверждено |
🎯 Совет по тестированию: Поскольку официальные веса модели HappyHorse еще не открыты на популярных платформах для инференса, если вы хотите оперативно сравнить видеомодели того же уровня (например, Seedance 2.0, Kling 3.0, Veo 3.1), мы рекомендуем использовать сервис-прокси API, такой как APIYI (apiyi.com). Это позволит параллельно вызывать разные модели и бесшовно переключиться на HappyHorse сразу после ее официального релиза, избегая лишней работы по перенастройке инфраструктуры.
Хронология появления модели HappyHorse
Чтобы понять, почему эта «счастливая лошадка» произвела такой фурор в зарубежном AI-сообществе, давайте разберемся в хронологии событий.
Год Лошади и совпадение в названии
2026 год по китайскому календарю — это год Лошади. Начиная с празднования Китайского Нового года в феврале, зарубежные СМИ и колонки вроде UX Tigers постоянно упоминали, что китайские AI-разработчики готовят серию релизов, связанных с «лошадьми». Название «HappyHorse» не только отсылает к знаку зодиака, но и вызывает ассоциации с другой моделью, которую в сообществе сокращенно называют «The Horse». Это стало одной из главных улик, по которой пользователи сразу определили азиатское происхождение проекта.
Взлет и исчезновение в Arena
Согласно скриншотам и отчетам, опубликованным в начале апреля экспертами по AI-видео (например, Брентом Линчем в X, бывшем Twitter), история HappyHorse 1.0 развивалась примерно так:
- Первое появление: Версия V1 появилась в Artificial Analysis Video Arena как анонимная запись и всего за несколько часов ворвалась в тройку лидеров в слепом тестировании «текст-в-видео».
- Запуск V2: Практически одновременно появилась вариация V2, и обе версии некоторое время занимали первое и второе места в рейтинге «изображение-в-видео».
- Вершина рейтинга: В категории без аудио HappyHorse 1.0 обошла такие топовые модели, как Seedance 2.0 720p, Kling 3.0 и PixVerse V6.
- Исчезновение: В течение нескольких дней обе версии (V1 и V2) были удалены из публичного рейтинга. Остались только скриншоты и записи сторонних наблюдателей, а на официальной странице появилось уведомление: «Базовая модель скоро будет с открытым исходным кодом».
Такой сценарий — «внезапный взлет, доминирование и тихое исчезновение» — обычно означает одно из двух: либо лаборатория проводит анонимное A/B-тестирование, либо разработчики еще не готовы к официальному релизу и решили убрать модель из публичного доступа после того, как она привлекла слишком много внимания. Оба варианта только добавили загадочности модели HappyHorse.

Разбор архитектуры HappyHorse: как 40-слойный однопоточный Transformer захватил лидерство
Хотя официальная научная статья еще не опубликована, на основе описаний с сайтов happyhorse-ai.com и зеркала happy-horse.net можно выделить ключевые архитектурные решения HappyHorse 1.0.
Однопоточный Self-Attention вместо сложных многопоточных структур
Традиционные модели генерации видео (особенно мультимодальные, работающие с аудио, текстом и изображением одновременно) обычно используют многопоточную (multi-stream) архитектуру. У текста, видео и аудио есть свои энкодеры, которые взаимодействуют через Cross-Attention. Такая структура гибкая, но крайне неэффективна в плане параметров: при выводе приходится постоянно перебрасывать тензоры между ветками.
HappyHorse 1.0 упрощает всё до единого конвейера: 40-слойный Self-Attention Transformer одновременно обрабатывает токены текста, видео и аудио. Здесь нет никакого Cross-Attention или специализированных подсетей для отдельных модальностей. Все данные кодируются в единую последовательность токенов и моделируются в одном пространстве внимания. У такого подхода есть несколько преимуществ:
- Высокая эффективность использования параметров: не нужны избыточные параметры для изоляции модальностей.
- Короткий путь вывода: нет лишних пересылок между модальностями, ядро (Kernel) работает более непрерывно.
- Единая цель обучения: текст, видео и аудио разделяют общую функцию потерь, что упрощает сквозную (end-to-end) оптимизацию.
- Естественная синхронизация: звук и видео являются токенами одной последовательности, что обеспечивает синхронность «из коробки».
8 шагов денойзинга + вывод без CFG
Для разработчиков, привыкших к Stable Video Diffusion, Sora или Kling, «десятки шагов денойзинга + Classifier-Free Guidance» — это уже мышечная память. Однако описание HappyHorse 1.0 выглядит радикально: всего 8 шагов денойзинга без использования CFG позволяют получить качество, занимающее первое место в Arena.
Скорее всего, при обучении модели применялись методы типа Consistency Distillation, Rectified Flow или Progressive Distillation, которые сжимают многошаговую выборку до нескольких прямых предсказаний. В сочетании с «дистиллированной моделью» и «моделью апскейлинга», которые также были представлены, стек вывода выглядит очень перспективно как для локального запуска, так и для высокой пропускной способности на серверах.
Возможный масштаб параметров и требования к видеопамяти
Поскольку веса модели еще не открыты, точно оценить количество параметров модели HappyHorse невозможно. Но, учитывая 40 слоев, однопоточную архитектуру, поддержку 6 языков и результаты в Arena, можно предположить, что она находится в одном классе с Wan 2.x, Seedance 1.x и Hunyuan Video — скорее всего, в диапазоне 10B–30B параметров. Это значит, что для полноценного локального запуска потребуется как минимум одна профессиональная видеокарта с большим объемом памяти, а владельцам обычных потребительских GPU придется ждать появления INT8/FP8-квантованных версий.
🎯 Совет по выбору архитектуры: Если вы оцениваете «инфраструктуру генерации видео следующего поколения» для своей команды, рекомендуем обратить пристальное внимание на парадигму «однопоточный Transformer + минимальное количество шагов вывода», которую демонстрирует HappyHorse 1.0. Пока модель не стала полностью open-source, вы можете использовать APIYI (apiyi.com) для работы с моделями Seedance, Kling или Veo, чтобы отточить промпты, сценарии и пайплайны пост-обработки. Как только веса HappyHorse станут доступны, вы сможете легко переключиться на них.
Результаты тестирования модели HappyHorse: как удалось возглавить рейтинги Arena
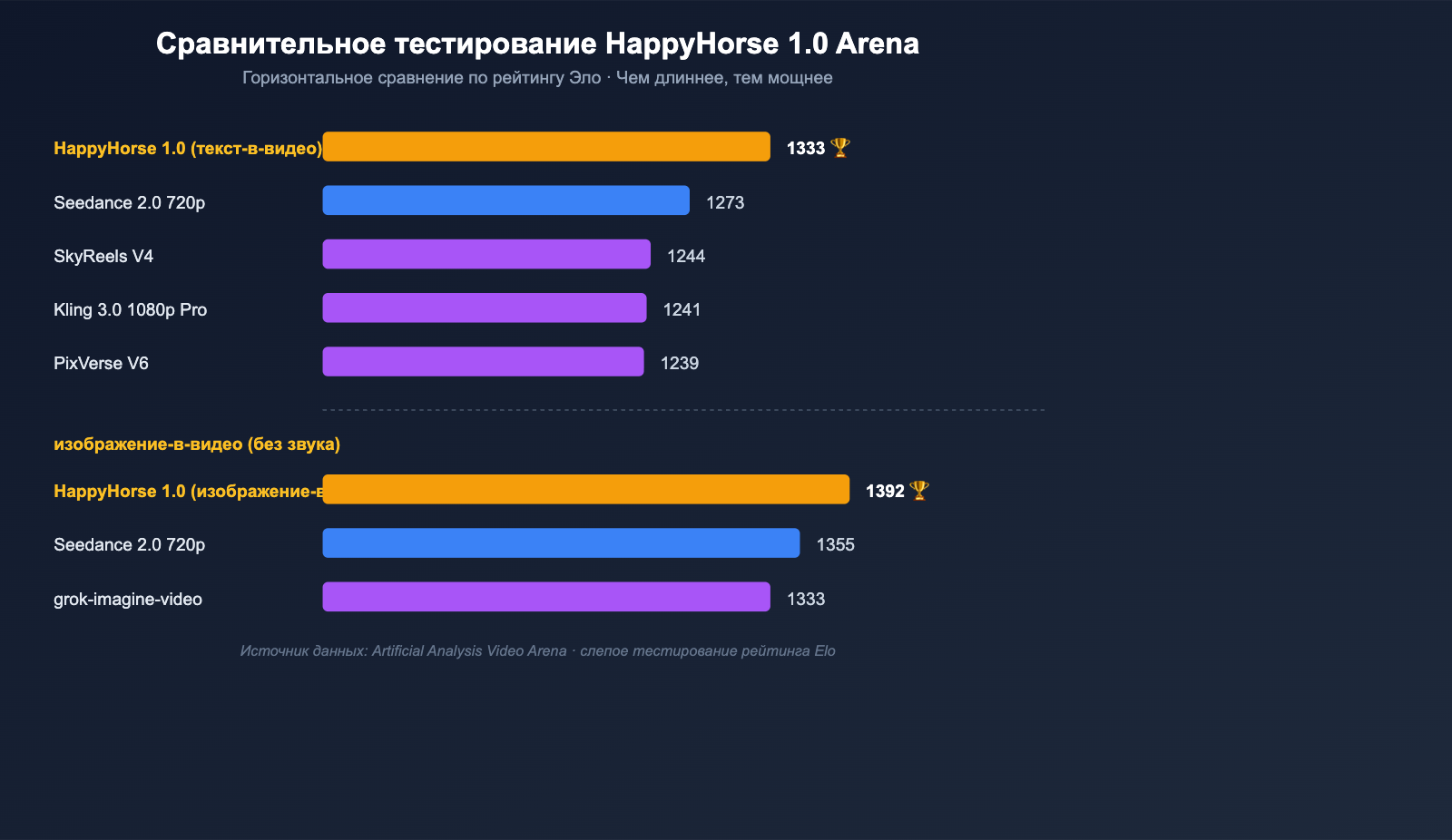
Закончив с разбором архитектуры, перейдем к цифрам — именно они лучше всего убеждают профильные команды. В таблице ниже собраны данные из открытых источников по слепому тестированию Elo-рейтинга HappyHorse 1.0 на платформе Artificial Analysis Video Arena, а также позиции основных конкурентов.
Сравнение Elo: текст-в-видео / изображение-в-видео
| Категория | Место | Модель | Elo-рейтинг |
|---|---|---|---|
| Текст-в-видео (без звука) | 1 | HappyHorse-1.0 | 1333 |
| Текст-в-видео (без звука) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Текст-в-видео (без звука) | 3 | SkyReels V4 | 1244 |
| Текст-в-видео (без звука) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Текст-в-видео (без звука) | 5 | PixVerse V6 | 1239 |
| Текст-в-видео (со звуком) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Текст-в-видео (со звуком) | 2 | HappyHorse-1.0 | 1205 |
| Изображение-в-видео (без звука) | 1 | HappyHorse-1.0 | 1392 |
| Изображение-в-видео (без звука) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Изображение-в-видео (без звука) | 3 | PixVerse V6 | 1338 |
| Изображение-в-видео (без звука) | 4 | grok-imagine-video | 1333 |
| Изображение-в-видео (без звука) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Ключевые выводы:
- Максимальный отрыв в категории «изображение-в-видео»: 1392 против 1355 баллов. Разница в 40 пунктов в системе слепого тестирования — это уровень, на котором пользователи стабильно замечают качественное превосходство.
- Первое место в «текст-в-видео»: 1333 против 1273 баллов. Отрыв в 60 пунктов означает, что даже без использования эталонного изображения модель HappyHorse превосходит Seedance 2.0 в базовых навыках: композиции кадра и проработке движений персонажей.
- Второе место по звуку: Seedance 2.0 пока лидирует в синхронизации звука и видео, что связано с глубокой инженерной проработкой модели под задачи «AI-режиссера» и длинные нарративы.
- Версия V2: В некоторых скриншотах мелькала версия V2, которая кратковременно вырывалась вперед, но официальных данных о ней пока нет. Возможно, это был тестовый билд, который позже «исчез».
Поддержка языков и фокус на человеке
Разработчики официально заявили, что HappyHorse 1.0 нативно поддерживает 6 языков: китайский, английский, японский, корейский, немецкий и французский. Особый акцент сделан на «человекоцентричных» (human-centric) сценариях, включая:
- Детализированную мимику (facial performance);
- Естественную координацию речи (speech coordination);
- Реалистичную пластику тела (body motion);
- Точную синхронизацию губ (lip sync).
Такое позиционирование четко определяет нишу модели HappyHorse: виртуальные люди, цифровой контент и короткометражные сериалы, а не просто генерация красивых пейзажей. Это объясняет, почему модель так сильна в «изображении-в-видео» (оживление фото персонажа) — это ключевой запрос для создания цифровых аватаров.
Откуда взялась модель HappyHorse: Wan 2.7? Seedance? Или новая «темная лошадка»?
Когда скриншоты HappyHorse 1.0 начали распространяться в англоязычном AI-сообществе, главным вопросом стал: «Чьих это рук дело?». Опираясь на данные сообщества, мы составили таблицу основных версий.
Сравнение трех основных гипотез
| Версия | Основные аргументы | Контраргументы |
|---|---|---|
| Ребрендинг Alibaba Wan 2.7 | Релиз совпадает по времени; Alibaba Tongyi Lab агрессивна в видео-сегменте; название «Horse» отсылает к году Лошади | Официальное описание Wan 2.7 больше ориентировано на изображения/мышление, что не стыкуется с 40-слойной архитектурой HappyHorse |
| Экспериментальная версия команды ByteDance Seedance | Seedance 2.0 — лидер Arena; у ByteDance есть ресурсы для анонимного тестирования | Seedance 2.0 все еще лидирует в аудио-сегменте, нет смысла выпускать «более сильную» версию под другим именем |
| Неизвестная лаборатория / Академический консорциум | Стиль релиза («все в open source + дистилляция + апскейлинг») характерен для исследований; странное название и минималистичный сайт | Качество модели достигло коммерческого уровня, академической команде сложно обучить такую модель в одиночку |
Мы склоняемся к третьей гипотезе: HappyHorse 1.0, скорее всего, создана новой командой, которая хочет громко заявить о себе через open source. Анонимное участие в Arena нужно было для подтверждения качества «слепыми» данными перед официальным запуском. Такая стратегия — «сначала рейтинг, потом open source, затем продукт» — уже не раз доказывала свою эффективность за последние 18 месяцев.
Впрочем, это лишь догадки. Пока нет официального репозитория на GitHub или Model Hub, любые утверждения — лишь слухи. Для разработчиков сейчас важнее следить за кривой возможностей модели, а не за тем, кто стоит за ее созданием.
🎯 Совет: Пока веса модели HappyHorse не открыты, а происхождение не подтверждено, не рекомендуем завязывать на нее критически важные бизнес-процессы. Лучше использовать проверенные коммерческие модели, такие как Seedance 2.0, Kling 3.0 или Veo 3.1, через надежные платформы, например APIYI (apiyi.com), параллельно отслеживая прогресс HappyHorse.
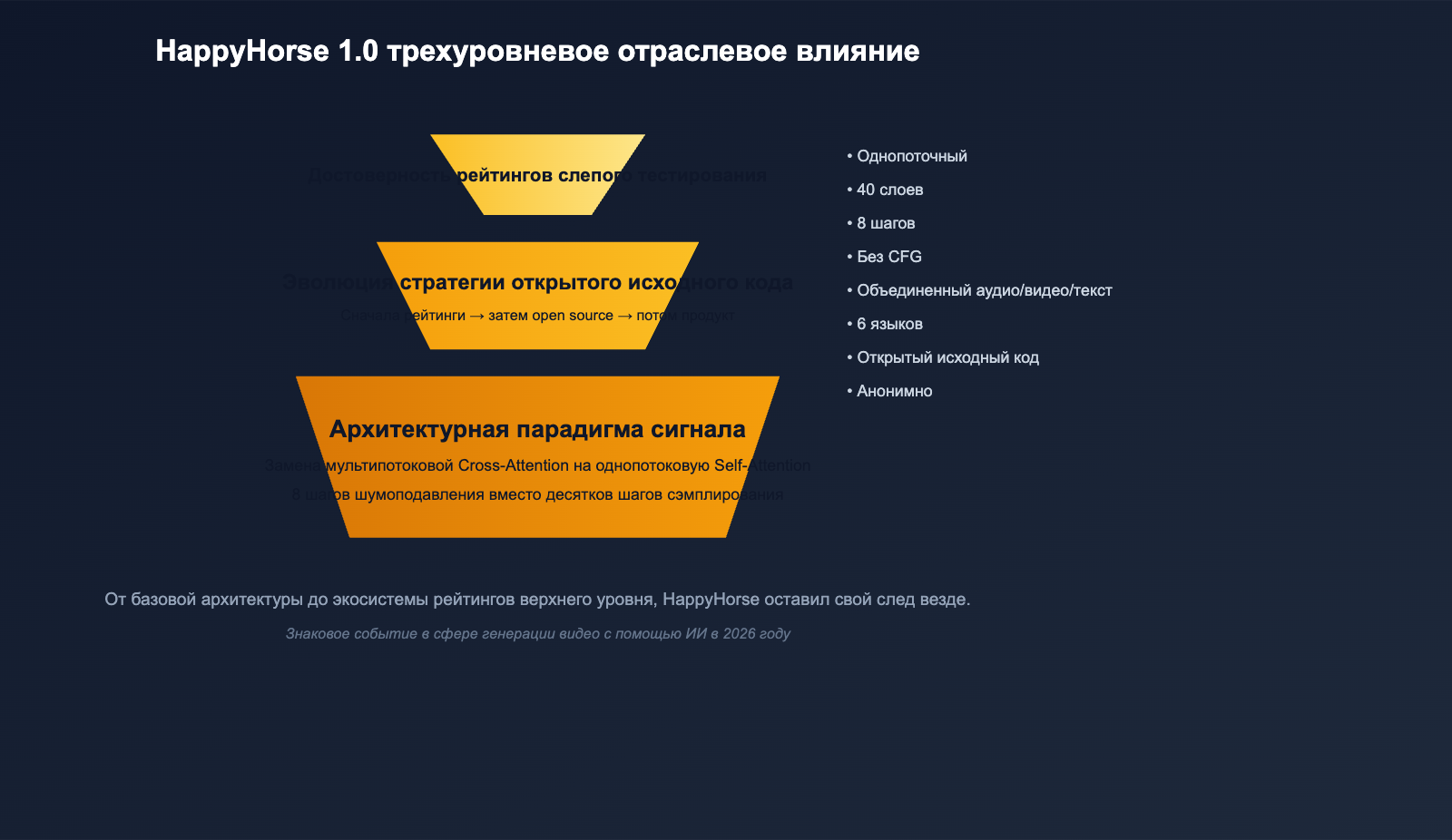
Три уровня влияния модели HappyHorse на индустрию
Даже если HappyHorse 1.0 в конечном итоге окажется лишь тщательно спланированной рекламной кампанией, она уже оставила три заметных следа в сфере генерации видео с помощью ИИ.
Уровень 1: Сигнал об изменении архитектурной парадигмы
Последние два года основные видеомодели продолжали совершенствоваться по пути многопотоковой диффузии (Diffusion) с механизмом Cross-Attention. Модель HappyHorse, заняв первое место в Arena, наглядно доказала, что путь «однопотокового Self-Attention + минимальное количество шагов вывода» также может привести к состоянию SOTA (State-of-the-Art), при этом будучи гораздо более «чистым» с инженерной точки зрения. Это заставит многие команды переосмыслить подход: не пора ли сэкономить на «налоге на сложность» в виде слоя Cross-Attention?
Уровень 2: Эволюция стратегии open-source
HappyHorse выбрала тактику «анонимное появление в рейтинге → публичное обещание открыть исходный код → публикация весов», вместо традиционного «сначала статья, потом веса». Это больше похоже на запуск потребительского продукта, где «пользовательские данные» ставятся выше академических публикаций. Если модель действительно будет открыта, как обещано, HappyHorse 1.0 может стать еще одной фундаментальной видеомоделью для массовой доработки, вслед за Wan, Hunyuan Video и Open-Sora.
Уровень 3: Доверие к слепым рейтингам
С другой стороны, «внезапный взлет и исчезновение» HappyHorse стали тревожным звонком для таких платформ слепого тестирования, как Artificial Analysis и LMArena. Анонимных записей становится все больше, и вопрос о том, как отличить «реально новую модель» от «определенного чекпоинта уже существующей модели», станет серьезным вызовом для администраторов рейтингов. Для разработчиков это означает, что при изучении рейтинга Elo теперь нужно больше полагаться на «карточку модели + примеры вывода + реальные бизнес-данные», а не просто смотреть на цифры.
Как разработчикам реагировать на «внезапные» релизы вроде HappyHorse
Для инженерных команд и создателей контента вместо того, чтобы гадать «кто это и когда они откроют код», лучше выстроить стандартный алгоритм действий на случай подобных сюрпризов.
Рекомендуемый процесс из четырех шагов
| Шаг | Действие | Цель |
|---|---|---|
| 1 | Настроить текущие процессы генерации видео через единый интерфейс | Обеспечить бесшовное переключение при появлении любой новой модели |
| 2 | Собрать типичные промпты и эталонные изображения | Создать внутренний «бенчмарк-набор», независимый от публичной Arena |
| 3 | Провести внутреннее тестирование сразу после появления модели | Проверить, подтверждаются ли баллы Arena на ваших собственных данных |
| 4 | Оценить общую стоимость (цена API / задержка вывода / комплаенс) | Принять решение о замене основной модели |
Суть этого процесса в следующем: не позволяйте графику выпуска какой-либо одной модели диктовать вам условия, а сделайте «быстрое подключение новых моделей» своей базовой компетенцией. HappyHorse 1.0 — это только начало, и можно ожидать, что во второй половине 2026 года в различных видео-Arena появится еще больше подобных анонимных моделей.
🎯 Инженерный совет: для команд, которые хотят долгосрочно отслеживать модель HappyHorse и ее конкурентов, таких как Seedance, Kling и Veo, мы рекомендуем использовать для генерации видео сервис-прокси API, такой как APIYI (apiyi.com), поддерживающий параллельный вызов нескольких моделей. Так, независимо от того, кто окажется в топе рейтинга, вам нужно будет лишь изменить параметр
modelв коде, чтобы провести сравнение и запустить модель в продакшн.
FAQ по модели HappyHorse
Q1: Можно ли уже скачать и использовать HappyHorse 1.0?
На текущий момент (начало апреля 2026 года) на официальной странице HappyHorse 1.0 ссылки на репозиторий GitHub и Model Hub по-прежнему помечены как «Coming Soon». Это означает, что веса и код для инференса еще не находятся в открытом доступе. К любым источникам, утверждающим, что модель «уже можно скачать и развернуть», стоит относиться с большой осторожностью. Рекомендуем следить за официальным сайтом, а до момента официального релиза весов использовать такие коммерческие модели, как Seedance 2.0 или Kling 3.0, через платформы вроде APIYI (apiyi.com).
Q2: Почему модель HappyHorse исчезла из рейтинга Arena?
В открытых источниках нет точного объяснения причин. Исходя из обсуждений в сообществе, есть две основные версии: во-первых, авторы модели могли отозвать её для доработки результатов перед официальным релизом; во-вторых, платформа могла временно скрыть её из-за того, что статус анонимного участника не был подтвержден. В любом случае, это не стоит расценивать как признак того, что «модель плохая» — её Elo-рейтинг до исчезновения был основан на реальных данных слепого тестирования.
Q3: HappyHorse 1.0 и Wan 2.7 — это одна и та же модель?
Официальной информации, подтверждающей это, нет. Wan 2.7 — это модель для генерации изображений и видео, официально выпущенная лабораторией Alibaba Tongyi в апреле 2026 года, с упором на «режим мышления» и рендеринг длинных текстов. В то же время модель HappyHorse делает акцент на 40-слойном однопоточном трансформере и 8-шаговом инференсе с шумоподавлением — их технические описания различаются. В сообществе есть догадки об их общем происхождении, но пока это больше похоже на «два продукта одного периода и одной ниши», а не на одну модель под разными названиями.
Q4: Умеет ли модель HappyHorse генерировать видео со звуком?
Да. Официально подтверждено, что HappyHorse 1.0 обрабатывает токены текста, видео и аудио в рамках одного 40-слойного трансформера, поэтому она нативно поддерживает сценарий «ввод текста → вывод короткометражки со звуком». В рейтинге Arena в категории с аудио она сейчас занимает второе место, уступая Seedance 2.0, но всё еще оставаясь в первом эшелоне.
Q5: Как мне, как разработчику, подготовиться к этому?
Самый разумный подход — сохранять нейтральность инструментария: подключите свои задачи по генерации видео к единой платформе, поддерживающей параллельный вызов нескольких моделей (например, APIYI apiyi.com). Заранее отладьте промпты, сценарии для съемки и процессы модерации. Как только модель HappyHorse станет доступна через API или с открытым кодом, вы сможете переключить параметр model и внедрить эту «темную лошадку» без необходимости переписывать код.
Q6: Для каких бизнес-задач подходит HappyHorse 1.0?
Судя по акценту разработчиков на «человеческих сценариях, мимике, синхронизации губ и мультиязычности», модель HappyHorse лучше всего подходит для: виртуальных стримеров / коротких видео с цифровыми людьми, AI-сериалов, рекламных роликов на разных языках и фрагментов с персонажами в рекламе. Если ваш бизнес в основном сфокусирован на пейзажах или съемке товаров, то Seedance 2.0, Veo 3.1 или Kling 3.0 остаются более надежными и готовыми к работе решениями.
Итог: что нам дала модель HappyHorse
Если собрать все факты воедино, HappyHorse 1.0 заслуживает подробного разбора не только из-за высокого Elo-рейтинга в Artificial Analysis Video Arena. Она олицетворяет собой сдвиг в парадигме выпуска моделей для генерации видео в 2026 году: переход от сложных многопоточных структур к однопоточным трансформерам, от десятков шагов шумоподавления к минимальному количеству шагов инференса, от публикации научных статей к анонимному участию в рейтингах и от закрытых API к обещаниям open-source. Каждое из этих изменений по отдельности не является революционным, но в совокупности они означают, что мы входим в новый ритм итераций видеомоделей.
Совет командам на передовой прост: не гадайте, «кто это», а используйте ситуацию как стресс-тест для инженерии. Сможет ли ваш конвейер генерации видео интегрировать и оценить новую модель в день её появления? Если ответ «да», то независимо от того, станет ли модель HappyHorse по-настоящему открытой, окажется ли она чьим-то «клоном» или навсегда исчезнет из виду, вы в любом случае останетесь в выигрыше.
🎯 Финальный совет: если вы хотите первыми пробовать все актуальные AI-видеомодели (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6 и другие), сохранив при этом возможность в один клик переключиться на HappyHorse, рекомендуем использовать единый сервис-прокси APIYI (apiyi.com). Это избавит вас от необходимости интегрировать SDK каждого поставщика по отдельности и сведет затраты на миграцию к минимуму при выходе новых моделей.
Автор: Команда APIYI | Следим за внедрением больших языковых моделей и инженерными практиками. Больше обзоров видео- и мультимодальных моделей вы найдете на APIYI (apiyi.com).