«Какое количество параллельных запросов будет оптимальным?» — это самый частый вопрос от разработчиков, которые используют API Nano Banana 2 для массовой генерации изображений. Ответ кроется не в ограничениях платформы, а в том, какой объем данных Base64 способны выдержать ваши пропускная способность сети и оперативная память.
Ключевая ценность: прочитав эту статью, вы поймете, где именно возникают «бутылочные горлышки» при параллельных вызовах API Nano Banana 2, научитесь рассчитывать оптимальное количество потоков исходя из возможностей вашего сервера и получите 5 проверенных советов по оптимизации производительности.

Основная проблема параллелизма API Nano Banana 2: узкое место не в платформе, а в вашем канале
Многие разработчики первым делом спрашивают: «Какую нагрузку выдержит платформа?». На самом деле, платформа APIYI не ограничивает параллелизм: RPM (количество запросов в минуту) может достигать 1000 на пользователя без каких-либо проблем, а при необходимости мы можем выделить дополнительные квоты.
Настоящее узкое место: API генерации изображений Gemini использует Base64-кодирование для передачи данных. Это означает, что загрузка и выгрузка каждого изображения — это огромный JSON-текст, а не эффективный бинарный поток. Это создает колоссальную нагрузку на вашу пропускную способность сети и оперативную память.
Почему Base64 — главное препятствие для параллелизма
Официальный API Gemini (включая gemini-3.1-flash-image-preview, используемый в Nano Banana 2) поддерживает передачу изображений только через Base64. Кодирование Base64 увеличивает объем бинарных данных примерно на 33%, что приводит к следующим результатам:
| Разрешение | Исходный размер | После Base64 | Объем ответа API |
|---|---|---|---|
| 512px (0.5K) | ~400 КБ | ~530 КБ | ~600 КБ — 1 МБ |
| 1K (по умолчанию) | ~1.5 МБ | ~2 МБ | ~2 МБ |
| 2K | ~4 МБ | ~5.3 МБ | ~5-8 МБ |
| 4K | ~15 МБ | ~20 МБ | ~20 МБ |
Ответ API для одного изображения 4K весит 20 МБ. Если вы запустите 10 параллельных запросов 4K, через вашу сеть и память будет проходить 200 МБ данных.
Краткий справочник параметров модели Nano Banana 2 API
| Параметр | Значение |
|---|---|
| ID модели | gemini-3.1-flash-image-preview |
| Входной контекст | 131 072 токена |
| Лимит вывода | 32 768 токенов |
| Поддерживаемые разрешения | 512px / 1K / 2K / 4K |
| Соотношение сторон | 14 вариантов (1:1, 3:2, 4:3, 16:9, 9:16, 21:9 и др.) |
| Макс. эталонных изображений | 14 (10 объектов + 4 персонажа) |
| Скорость генерации | 3-5 секунд/изображение |
| RPM в APIYI | 1000/пользователь (можно увеличить) |
| Лимит параллелизма APIYI | Без ограничений |
🎯 Технический совет: Платформа APIYI (apiyi.com) не ограничивает параллелизм для Nano Banana 2, а RPM составляет 1000 запросов на пользователя. Узкое место находится в вашей локальной среде — именно пропускная способность сети и объем оперативной памяти определяют, сколько параллельных запросов вы сможете реально обработать.
Расчет параллелизма API Nano Banana 2: выбираем оптимальный вариант под ваше окружение
Количество параллельных запросов нельзя брать «с потолка», его нужно рассчитывать исходя из ваших реальных условий. Есть три ключевых показателя: пропускная способность сети, оперативная память и целевое разрешение.
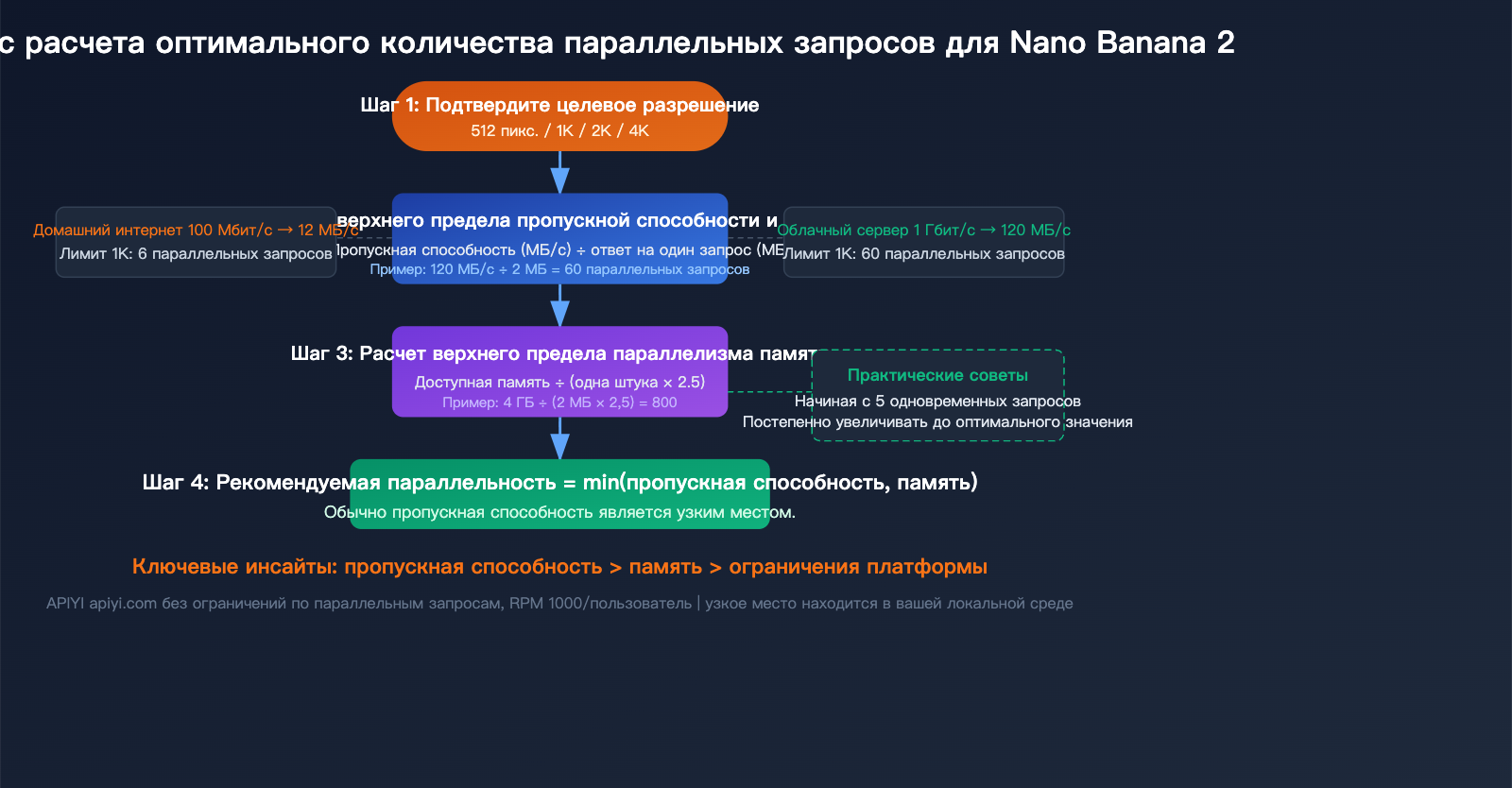
Шаг 1: Определите пропускную способность вашей сети
Она определяет, сколько данных можно передавать одновременно. Формула:
Макс. параллелизм (сеть) = Доступная полоса пропускания (МБ/с) ÷ Размер одного ответа (МБ)
| Сетевое окружение | Доступная полоса | Лимит 1K | Лимит 2K | Лимит 4K |
|---|---|---|---|---|
| Домашний интернет (100 Мбит/с) | ~12 МБ/с | 6 | 2 | 0-1 |
| Корпоративная сеть (500 Мбит/с) | ~60 МБ/с | 30 | 10 | 3 |
| Облачный сервер (1 Гбит/с) | ~120 МБ/с | 60 | 20 | 6 |
| Высокопроизводительный сервер (10 Гбит/с) | ~1200 МБ/с | 600 | 200 | 60 |
Шаг 2: Определите доступную оперативную память
Каждый параллельный запрос должен полностью удерживать Base64-ответ в памяти до завершения декодирования и записи на диск. Формула памяти:
Необходимая память = Параллелизм × Размер одного ответа × 2.5 (коэффициент буфера декодирования)
Множитель 2.5 используется потому, что в процессе декодирования Base64 исходная строка и декодированные бинарные данные одновременно находятся в памяти, плюс добавляются накладные расходы на парсинг JSON.
| Доступная память | Лимит 1K | Лимит 2K | Лимит 4K |
|---|---|---|---|
| 2 ГБ | 400 | 100 | 40 |
| 4 ГБ | 800 | 200 | 80 |
| 8 ГБ | 1600 | 400 | 160 |
Шаг 3: Выберите меньшее из двух значений
Итоговый рекомендуемый параллелизм = min(лимит сети, лимит памяти)
На практике в большинстве случаев именно сеть является узким местом, а не память.
Рекомендуемые значения параллелизма для разных сценариев
| Сценарий | Рекомендуемое разрешение | Рекомендуемый параллелизм | Ожидаемая пропускная способность |
|---|---|---|---|
| Личная разработка/тесты | 1K | 3-5 | ~1 изобр./сек |
| Пакетная генерация (малая команда) | 1K | 10-20 | ~4 изобр./сек |
| Корпоративная среда | 1K-2K | 20-50 | ~10 изобр./сек |
| Высокопроизводительный сервис | 1K | 50-100 | ~20 изобр./сек |
| Нужны HD-изображения 4K | 4K | 3-5 | ~1 изобр./сек |
💡 Практический совет: Если не уверены, с какого количества параллельных запросов начать, стартуйте с 5, постепенно увеличивая до 10, 20, и наблюдайте за временем отклика и частотой ошибок. Если время отклика заметно растет или появляются тайм-ауты, значит, вы близки к пределу. При тестировании на платформе APIYI (apiyi.com) не беспокойтесь об ограничениях со стороны платформы — сосредоточьтесь на производительности вашей локальной системы.
Быстрый старт с API Nano Banana 2: интеграция в 3 шага
Шаг 1: Установка зависимостей
pip install openai Pillow
Шаг 2: Минималистичный пример вызова
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Generate a cute cat wearing sunglasses on a beach"
}
]
)
# Извлекаем данные изображения в формате Base64 и сохраняем
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("Изображение сохранено: output.png")
Посмотреть полный код для параллельной генерации
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI
)
# Параметры конфигурации
MAX_CONCURRENCY = 10 # Максимальное количество параллельных потоков, настройте под свой канал
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""Генерация одного изображения с немедленным сохранением для освобождения памяти"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Декодируем и сохраняем сразу, чтобы Base64-строка не висела в памяти
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""Параллельная генерация изображений с использованием пула потоков"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}с")
results.append(result)
# Статистика
success = [r for r in results if r["success"]]
print(f"\nГотово: {len(success)}/{total} успешно")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"Среднее время: {avg_time:.1f}с | Общий объем: {total_size:.1f} МБ")
# Пример использования
prompts = [
"A futuristic city at sunset",
"A cozy coffee shop interior",
"An underwater coral reef scene",
"A mountain landscape with aurora",
"A cute robot playing guitar",
]
batch_generate(prompts)
Шаг 3: Загрузка эталонного изображения (изображение-в-изображение)
Для сценариев изображение-в-изображение нужно загрузить эталонное изображение, также закодированное в Base64:
import base64
# Читаем локальный файл и конвертируем в Base64
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Преобразуй это фото в стиль акварельной живописи"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
Внимание: при загрузке эталонного изображения размер всего тела запроса не должен превышать 20 МБ. Если файл большой, рекомендуем предварительно сжать его до разрешения ниже 1K.
5 практических советов по оптимизации параллельных запросов к API Nano Banana 2
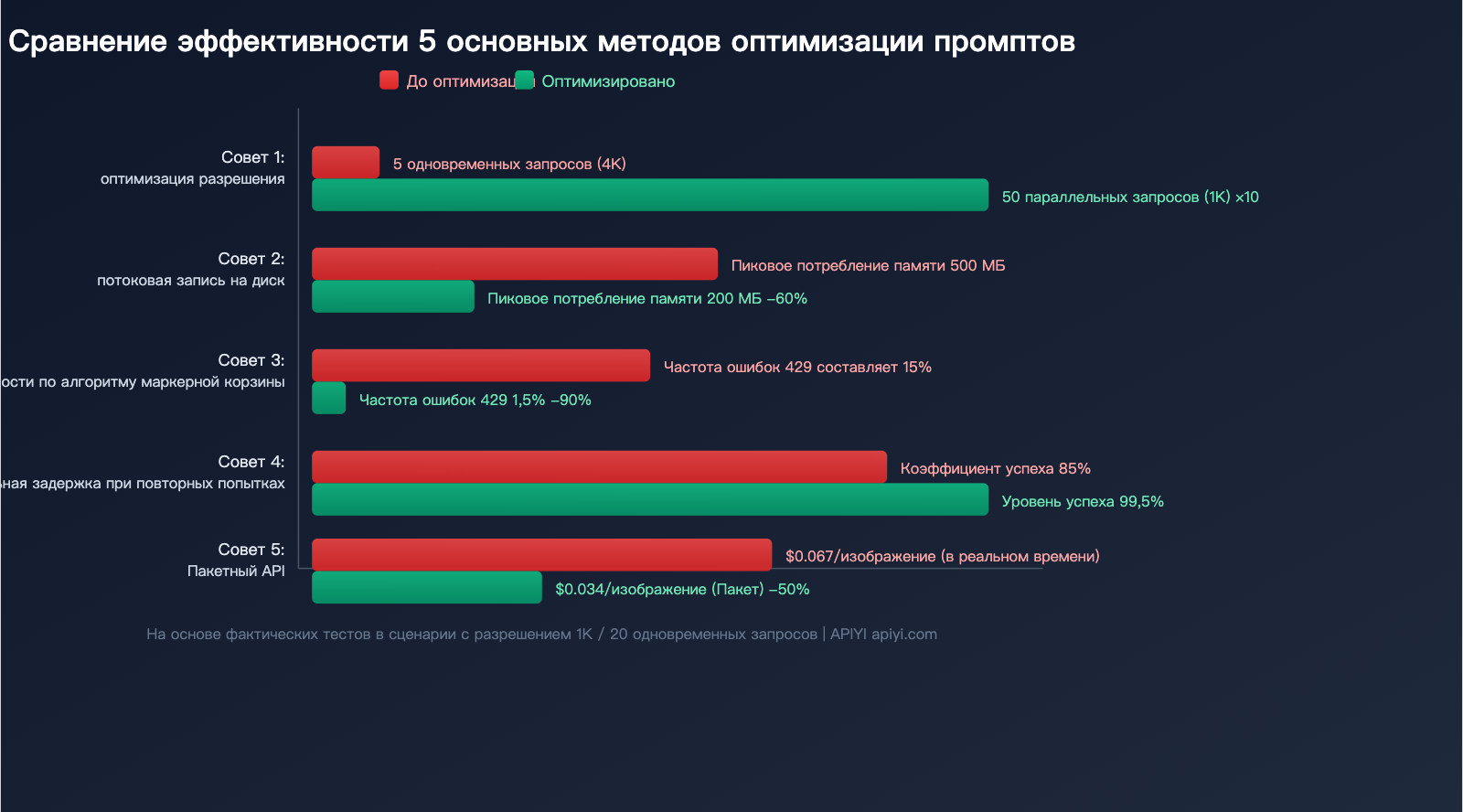
Совет 1: Выбирайте разрешение по необходимости, избегайте 4K по умолчанию
Это самый простой и эффективный способ оптимизации. Многие разработчики запрашивают 4K по умолчанию, хотя в большинстве случаев достаточно 1K:
| Сценарий использования | Рекомендуемое разрешение | Размер файла | Эффективность параллелизма |
|---|---|---|---|
| Контент для соцсетей | 1K | ~2 МБ | Высокая |
| Фото товаров для E-com | 2K | ~6 МБ | Средняя |
| Печать / Плакаты | 4K | ~20 МБ | Низкая |
| Превью / Миниатюры | 512px | ~0.7 МБ | Очень высокая |
Переход с 4K на 1K увеличивает пропускную способность примерно в 10 раз.
Совет 2: Потоковый прием + моментальная запись на диск
Не ждите, пока весь JSON-ответ будет полностью получен. Используйте потоковую передачу: декодируйте и записывайте на диск «на лету».
import gc
def generate_and_save(prompt, filepath):
"""Генерация изображения с немедленной записью и очисткой памяти"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Декодируем сразу
img_bytes = base64.b64decode(part.image.data)
# Удаляем ссылку на Base64-строку
del part.image.data
# Пишем на диск
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # Принудительный запуск сборщика мусора
Совет 3: Ограничитель скорости (Token Bucket) для контроля ритма
Не отправляйте все запросы одновременно, используйте алгоритм «маркерной корзины» (Token Bucket) для равномерного распределения нагрузки:
import threading
import time
class TokenBucket:
"""Ограничитель скорости на основе маркерной корзины"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # Скорость пополнения в секунду
self.capacity = capacity # Емкость корзины
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# Использование: максимум 10 запросов в секунду, пик 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # Ждем токен
return generate_single_image(prompt, index)
Совет 4: Экспоненциальная задержка при ошибках 429
При получении ошибки ограничения скорости (HTTP 429) используйте стратегию экспоненциальной задержки:
import random
def generate_with_retry(prompt, index, max_retries=5):
"""Механизм повторных попыток с экспоненциальной задержкой"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"Лимит превышен, ждем {delay:.1f}с перед повтором...")
time.sleep(delay)
return {"index": index, "success": False, "error": "max retries"}
Совет 5: Используйте Batch API для экономии 50% бюджета
Для массовых задач, где не требуется мгновенный результат, Nano Banana 2 поддерживает Batch API, что позволяет сократить расходы вдвое:
| Режим | Цена за 1K фото | Цена за 4K фото | Задержка | Сценарий |
|---|---|---|---|---|
| Real-time API | $0.067 | $0.151 | 3-5 сек | Интерактивные приложения |
| Batch API | $0.034 | $0.076 | Мин-часы | Массовая генерация |
💰 Оптимизация затрат: если ваш сценарий допускает ожидание, вызов Batch API через APIYI (apiyi.com) сэкономит вам 50% бюджета. Идеально подходит для генерации карточек товаров для маркетплейсов, создания маркетинговых материалов и т.д.
Подробный разбор стоимости и расхода токенов для API Nano Banana 2
Понимание того, как расходуются токены, поможет вам лучше контролировать бюджет:
| Разрешение | Расход токенов (вывод) | Стандартная цена | Цена Batch (скидка 50%) | Стоимость за 100 шт. |
|---|---|---|---|---|
| 512px | 747 токенов | $0.045 | $0.022 | $4.50 / $2.20 |
| 1K | 1 120 токенов | $0.067 | $0.034 | $6.70 / $3.40 |
| 2K | 1 680 токенов | $0.101 | $0.050 | $10.10 / $5.00 |
| 4K | 2 520 токенов | $0.151 | $0.076 | $15.10 / $7.60 |
🚀 Быстрый старт: Используйте Nano Banana 2 через платформу APIYI (apiyi.com). Цены такие же, как у официального провайдера, при этом нет ограничений по параллельным запросам, а лимит RPM составляет 1000 запросов на пользователя. Зарегистрируйтесь и получите тестовый баланс.
Сравнение Nano Banana 2 с предыдущими моделями
| Параметр | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| ID модели | gemini-2.5-flash (изображения) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| Макс. разрешение | 1024×1024 | 4K | 4K |
| Цена за 1K | $0.039 | $0.134 | $0.067 |
| Цена за 4K | Не поддерживается | $0.240 | $0.151 |
| Скорость генерации | 2-4 сек. | 5-8 сек. | 3-5 сек. |
| Batch API | Нет | Нет | Да (скидка 50%) |
| Лимит эталонных изображений | 5 шт. | 10 шт. | 14 шт. |
| Доступно в APIYI | ✅ | ✅ | ✅ |
По сравнению с версией Pro, Nano Banana 2 предлагает снижение цены на 4K-генерацию на 37%, прирост скорости на 40%, а также поддержку Batch API.
Мониторинг производительности параллельных вычислений Nano Banana 2 API
При выполнении параллельных задач в реальных условиях рекомендуется отслеживать следующие показатели:
import psutil
import time
class PerformanceMonitor:
"""Монитор производительности параллельных задач"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- Отчет о производительности ---")
print(f"Время работы: {elapsed:.1f}с")
print(f"Выполнено запросов: {self.request_count}")
print(f"Успешность: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"Пропускная способность: {self.request_count/elapsed:.2f} зап/с")
print(f"Объем данных: {self.total_bytes/(1024**2):.1f} МБ")
print(f"Использование канала: {self.total_bytes/(1024**2)/elapsed:.1f} МБ/с")
print(f"Потребление памяти: {mem:.0f} МБ")
Часто задаваемые вопросы
Q1: Есть ли ограничения на параллельные вызовы Nano Banana 2 на платформе APIYI?
Платформа APIYI не ограничивает количество параллельных запросов для Nano Banana 2. По умолчанию поддерживается 1000 запросов в минуту (RPM) на пользователя. Если вам нужно больше, свяжитесь со службой поддержки для увеличения квоты. Реальным «узким местом» при параллельной работе обычно становятся пропускная способность вашей сети и объем оперативной памяти. Рекомендуем провести тесты на платформе APIYI (apiyi.com), чтобы подобрать оптимальное количество потоков для вашей среды.
Q2: Почему API изображений Gemini поддерживает только передачу в формате Base64?
Это текущее архитектурное решение Google Gemini API. Кодирование Base64 позволяет встраивать данные изображения непосредственно в JSON-ответ, что избавляет от необходимости использовать внешние хранилища файлов или CDN. Минус в том, что размер данных увеличивается примерно на 33%, что создает дополнительную нагрузку на сеть и память. Сообщество разработчиков уже направило запрос в Google с просьбой добавить поддержку вывода в формате JPEG и временных URL для скачивания, но пока это не реализовано.
Q3: Большая ли разница в качестве между разрешением 1K и 4K?
Все зависит от сценария использования. Для картинок в соцсетях, веб-интерфейсов или мобильных приложений 1K вполне достаточно — разница для человеческого глаза практически незаметна. 4K пригодится для печати, постеров или обоев высокого разрешения, где важно рассматривать детали при увеличении. Советуем сначала протестировать 1K, и если четкости будет не хватать, переключиться на 4K. На платформе APIYI (apiyi.com) можно легко менять разрешение в любой момент.
Q4: Что делать, если часто возникают ошибки 429?
Ошибка 429 означает, что вы превысили лимит скорости (Rate Limit). Решения: (1) уменьшите количество параллельных запросов; (2) используйте ограничитель скорости (token bucket), чтобы равномерно распределить нагрузку; (3) внедрите повторные попытки с экспоненциальной задержкой; (4) для пакетных задач перейдите на Batch API. Если вы столкнулись с лимитами на платформе APIYI, обратитесь в поддержку для увеличения квоты RPM.
Q5: Как рассчитать общую стоимость пакетной генерации?
Используйте формулу: Общая стоимость = Количество изображений × Цена за единицу. Например, генерация 1000 изображений в 1K: стандартный режим — 1000 × $0.067 = $67, режим Batch — 1000 × $0.034 = $34. Цены на APIYI (apiyi.com) соответствуют официальным, а гибкая система пополнения баланса отлично подходит для работы по мере необходимости.
Итог: находим оптимальную схему параллелизма для Nano Banana 2 API
Успех оптимизации параллелизма Nano Banana 2 API зависит не от того, «сколько разрешает платформа», а от того, «сколько может вытянуть ваш конвейер». Запомните эти 3 ключевых момента:
- Разрешение решает всё: переход с 4K на 1K увеличивает пропускную способность в 10 раз и снижает затраты на 56%.
- Пропускная способность — узкое место: кодирование Base64 делает каждое изображение на 33% тяжелее оригинала, поэтому нагрузка на сеть здесь гораздо выше, чем на CPU.
- Масштабируйте постепенно: начните с 5 параллельных запросов, отслеживайте время отклика и частоту ошибок, а затем плавно повышайте до оптимальных значений.
Рекомендуем использовать APIYI (apiyi.com) для вызова Nano Banana 2 API: здесь нет ограничений по параллелизму, лимит RPM составляет 1000 на пользователя, а цены соответствуют официальным. Это позволит вам сосредоточиться на оптимизации производительности собственного конвейера, не беспокоясь об ограничениях со стороны платформы.

Справочные материалы
-
Gemini 3.1 Flash Image Preview: спецификации модели и документация API
- Ссылка:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- Ссылка:
-
Gemini Image Generation API: руководство по использованию API для генерации изображений
- Ссылка:
ai.google.dev/gemini-api/docs/image-generation
- Ссылка:
-
Gemini API Rate Limits: официальная документация по лимитам скорости
- Ссылка:
ai.google.dev/gemini-api/docs/rate-limits
- Ссылка:
-
Документация по подключению APIYI Nano Banana 2: описание единого API-интерфейса
- Ссылка:
api.apiyi.com
- Ссылка:
📝 Автор: Команда APIYI | Техническая команда APIYI специализируется на сфере API для генерации изображений с помощью ИИ. Через сервис apiyi.com мы предоставляем разработчикам доступ к API Nano Banana 2 с неограниченным параллелизмом и гибкой тарификацией.