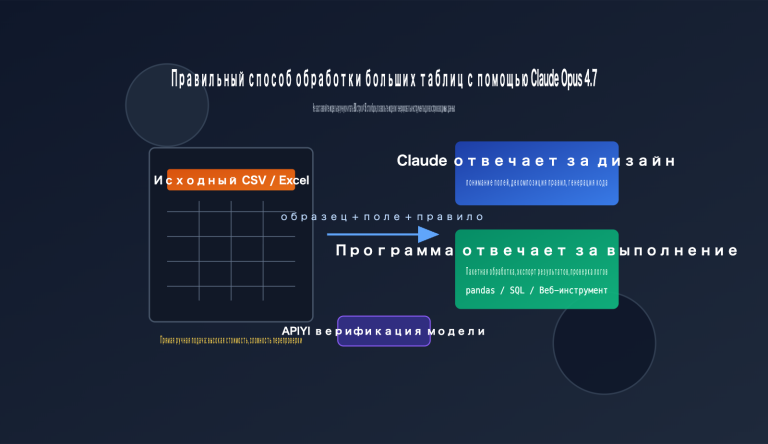
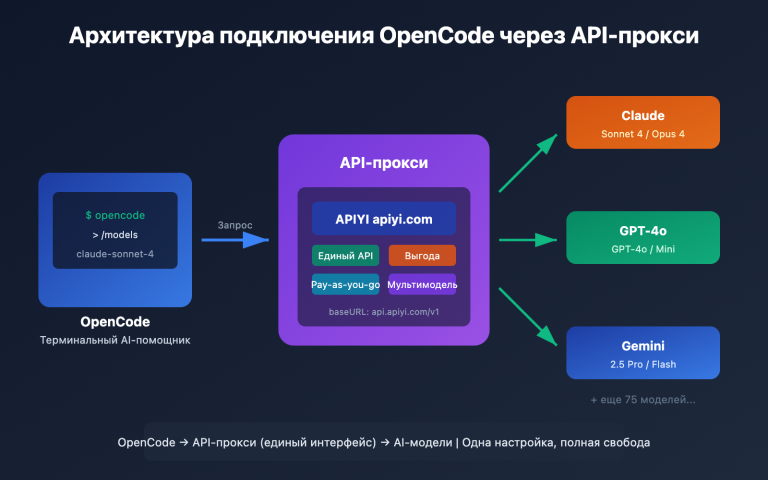
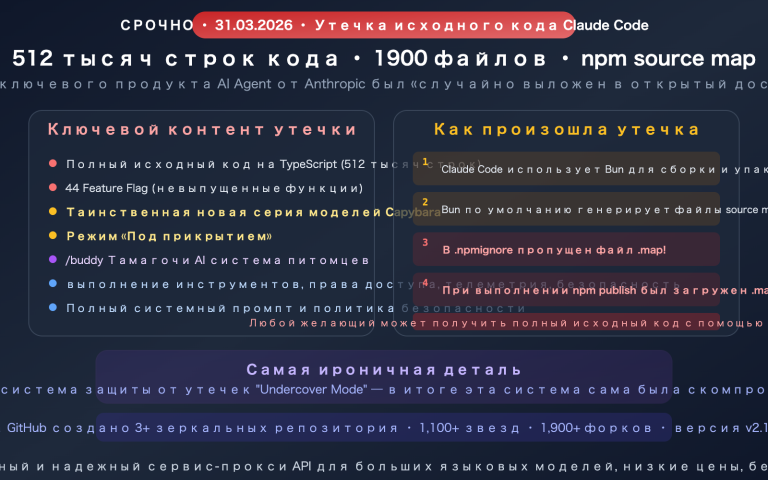
К 2026 году 41% всех коммитов уже создается с помощью ИИ, однако доля ошибок в таком коде на 1,7 раза выше, чем в коде, написанном человеком. Генерация кода ускоряется, но возможности для его проверки катастрофически отстают — ожидается, что к 2026 году разрыв в качестве достигнет 40%.
Вопрос уже не в том, стоит ли внедрять ИИ-ревью кода, а в том, как сделать это максимально эффективно. В этой статье мы разберем 7 проверенных практик и проанализируем, почему модели Claude Opus 4.6 и Sonnet 4.6 на данный момент являются лучшим выбором для автоматизации проверки кода.
Основная ценность: Прочитав статью, вы освоите полноценный рабочий процесс ИИ-ревью и поймете, как выбрать подходящую модель для повышения качества кода в вашей команде.
Текущее состояние AI-ревью кода: почему это стало критически важным
Вызовы при проверке кода в 2026 году
| Вызов | Данные | Влияние |
|---|---|---|
| Рост доли AI-кода | 41% коммитов созданы с помощью AI | Резкий рост нагрузки на ревью |
| Уровень дефектов AI | В 1,7 раза выше, чем у кода от людей | Требуется более строгая проверка |
| Разрыв в качестве | Ожидается 40% к 2026 году | Скорость генерации опережает возможности проверки |
| Риски безопасности | 45% AI-кода содержат уязвимости OWASP Top 10 | Безопасность — приоритет №1 |
| Принятие предложений | AI: 16,6%, люди: 56,5% | Качество AI-рекомендаций требует улучшения |
AI-ревью против человеческого ревью
AI не заменяет ревьюера-человека, а усиливает его возможности. Команды, внедрившие AI-ревью, отмечают:
- Сокращение времени на ревью на 40-60%
- Повышение выявляемости дефектов — особенно в части безопасности и граничных условий
- Значительное улучшение единообразия стиля кода
Однако у AI-ревью есть четкие границы:
- ❌ Не понимает бизнес-дедлайны и контекст проекта
- ❌ Не чувствует «исторических компромиссов» в легаси-системах
- ❌ Не несет финальной ответственности за результат
- ❌ Не может выступать в роли ментора или передавать командные знания
🎯 Лучшая стратегия: AI делает первый проход (стиль, баги, безопасность), человек принимает окончательное решение (архитектура, намерения, риски). Используя сервис-прокси API APIYI (apiyi.com) для вызова API Claude Opus 4.6 или Sonnet 4.6, можно быстро интегрировать AI-ревью в текущие CI/CD процессы.
7 лучших практик AI-ревью кода
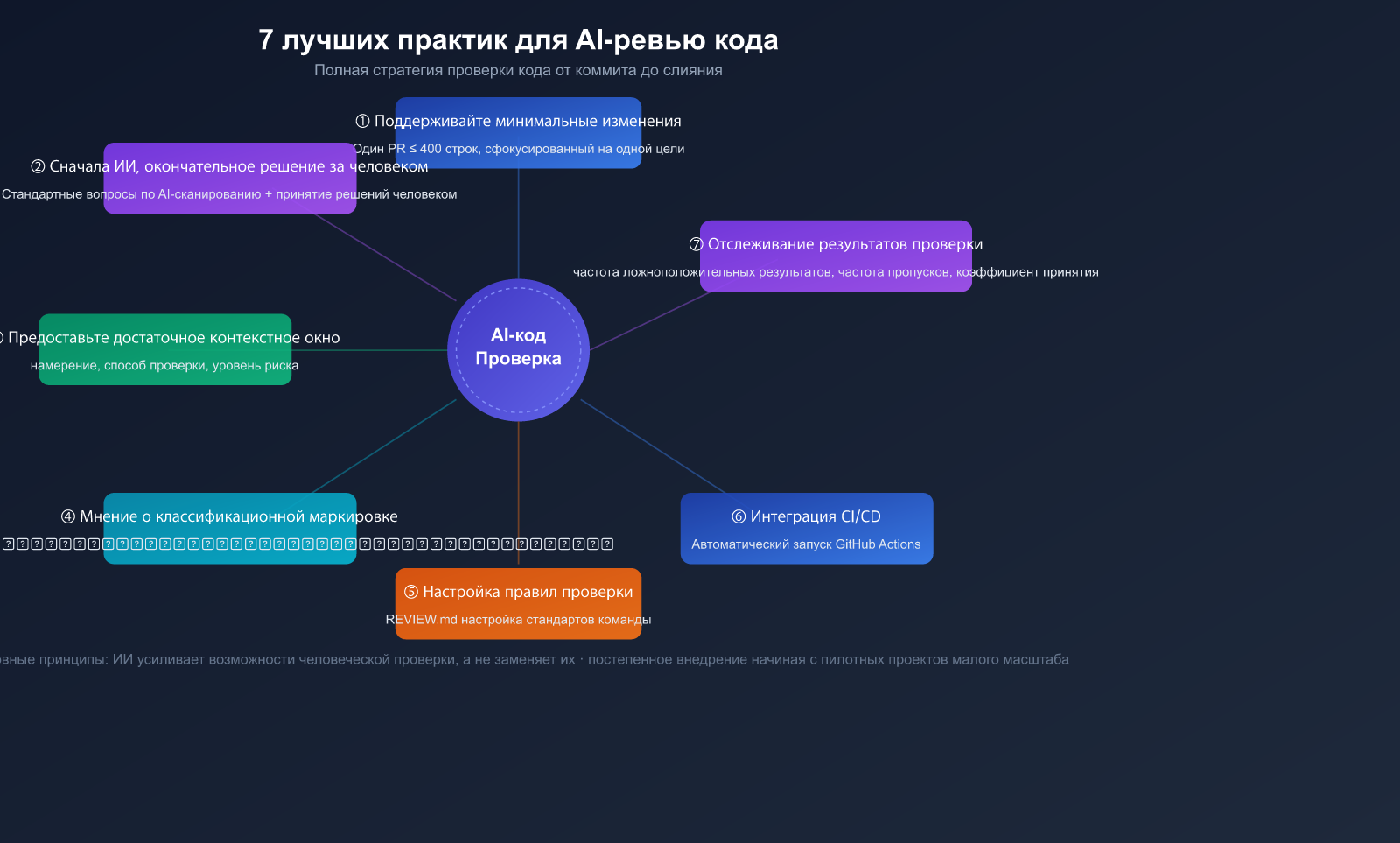
Практика 1: Сохраняйте изменения небольшими и сфокусированными
AI-ревьюер заметно теряет связность, если объем изменений (diff) превышает 1000 строк. Даже несмотря на то, что Claude Opus 4.6 обладает контекстным окном в 1 миллион токенов, качество проверки крупных изменений все равно уступает небольшим правкам.
Что делать:
- Ограничивайте размер одного PR до 200–400 строк
- Разбивайте крупные рефакторинги на несколько логически независимых PR
- Один PR — одна задача
Практика 2: AI сначала, человек — финальное решение
Самый эффективный рабочий процесс — это модель «двухуровневого ревью»:
Коммит кода → Автоматическое AI-ревью (первый проход)
↓
Пометка проблем + классификация по уровню критичности
↓
Ревьюер-человек фокусируется на зонах высокого риска (финальное решение)
↓
Мердж или отклонение
AI берет на себя рутину (стиль, именование, «мертвый» код, простые баги), а человек фокусируется на:
- Разумности архитектуры
- Корректности бизнес-логики
- Критически важных решениях по безопасности
- Оценке влияния на производительность
Практика 3: Предоставляйте достаточно контекста
Чем больше информации получает AI-ревьюер, тем выше качество проверки. Рекомендуем включать в описание PR:
## Цель изменений
Кратко опишите в 1-2 предложениях, зачем потребовались эти изменения.
## Способ проверки
- [ ] Модульные тесты пройдены успешно
- [ ] Проведено ручное тестирование сценария XX
- [ ] Регрессии производительности не выявлено
## Уровень риска
Низкий/Средний/Высокий + пояснение
## Заявление об использовании ИИ
В данных изменениях часть XX была сгенерирована с помощью ИИ, пожалуйста, уделите особое внимание её проверке.
## Зоны особого внимания
Пожалуйста, сфокусируйтесь на изменениях логики прав доступа в каталоге `src/auth/`.
### Практика 4: Уровневая маркировка замечаний при ревью
Частая проблема при использовании ИИ для ревью — «слишком много шума»: когда стилистические советы смешиваются с критическими багами, из-за чего разработчики пропускают важные замечания.
**Рекомендуемая система уровней критичности:**
| Маркер | Значение | Действие |
|------|------|----------|
| 🔴 **Bug** | Критический дефект, требующий исправления до слияния | Блокирует слияние |
| 🟡 **Nit** | Мелкая недоработка, которую стоит исправить, но не критично | Исправление по желанию |
| 🟣 **Pre-existing** | Старая проблема, не связанная с текущими изменениями | Зафиксировать, но не блокировать |
| 💡 **Suggestion** | Предложение по улучшению | Обсудить и принять решение |
Встроенная функция анализа кода в Claude Code уже поддерживает эту систему уровней (Red/Yellow/Purple).
### Практика 5: Настройка правил ревью
Универсальные правила ИИ-ревью могут не соответствовать стандартам вашей команды. Настройте поведение проверки через конфигурационный файл:
```markdown
# REVIEW.md (разместите в корне проекта)
## Обязательные проверки
- Все SQL-запросы должны использовать параметризацию
- API-эндпоинты должны содержать middleware для аутентификации
- Все пользовательские данные должны проходить валидацию
Можно пропустить
- Стиль именования CSS-классов (автоматически отформатирован через prettier)
- Сортировка импортов (автоматически обработана через ruff)
- Язык комментариев (допустимы как китайский, так и английский)
Командные соглашения
- Отдавайте предпочтение композиции, а не наследованию
- Используйте паттерн Result для обработки ошибок
- Уровни логирования: INFO для бизнес-событий, DEBUG для отладки
Практика 6: Интеграция в CI/CD конвейер
AI-ревью кода должно быть автоматизированным, а не запускаться вручную.
Рекомендуемый способ интеграции:
# Пример GitHub Actions
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
Также можно выполнять кастомную проверку через API, напрямую вызывая модель Claude:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Ты — эксперт по ревью кода.
Проанализируй следующие изменения в коде и классифицируй их по уровню серьезности:
- 🔴 Bug: требует обязательного исправления
- 🟡 Nit: рекомендуется исправить
- 💡 Suggestion: предложение по улучшению
Для каждой проблемы укажи номер строки и вариант исправления."""},
{"role": "user", "content": f"Проведи ревью следующих изменений:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Практика 7: Отслеживание эффективности ревью
AI-ревью кода — это не «настроил и забыл». Необходимо постоянно отслеживать ключевые метрики:
- Частота ложных срабатываний (False Positive Rate): сколько из отмеченных AI проблем оказались реальными.
- Частота пропусков (False Negative Rate): сколько багов, обнаруженных после деплоя, пропустил AI.
- Коэффициент принятия: доля советов AI, которые реально были внедрены разработчиками.
- Изменение времени ревью: сократилось ли среднее время проверки кода человеком.
💡 Совет по внедрению: Если ваша команда только начинает пробовать AI-ревью кода, рекомендую начать с PR, не относящихся к критическим путям. Используйте Claude Sonnet 4.6 через сервис-прокси APIYI (apiyi.com) для пилотного проекта: стоимость в 5 раз ниже, чем у Opus, а качество проверки близко к уровню Opus, что делает этот вариант самым выгодным для старта.
Почему мы рекомендуем Claude Opus 4.6 и Sonnet 4.6 для код-ревью
Среди множества ИИ-моделей серия Claude 4.6 обладает уникальными преимуществами для задач анализа и проверки кода.
Сравнение ключевых параметров моделей Claude 4.6
| Параметр | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| ID модели | claude-opus-4-6 |
claude-sonnet-4-6 |
| Дата релиза | 5 февраля 2026 г. | 17 февраля 2026 г. |
| Контекстное окно | 1 млн токенов (бета) | 1 млн токенов (бета) |
| Макс. вывод | 128 тыс. токенов | 64 тыс. токенов |
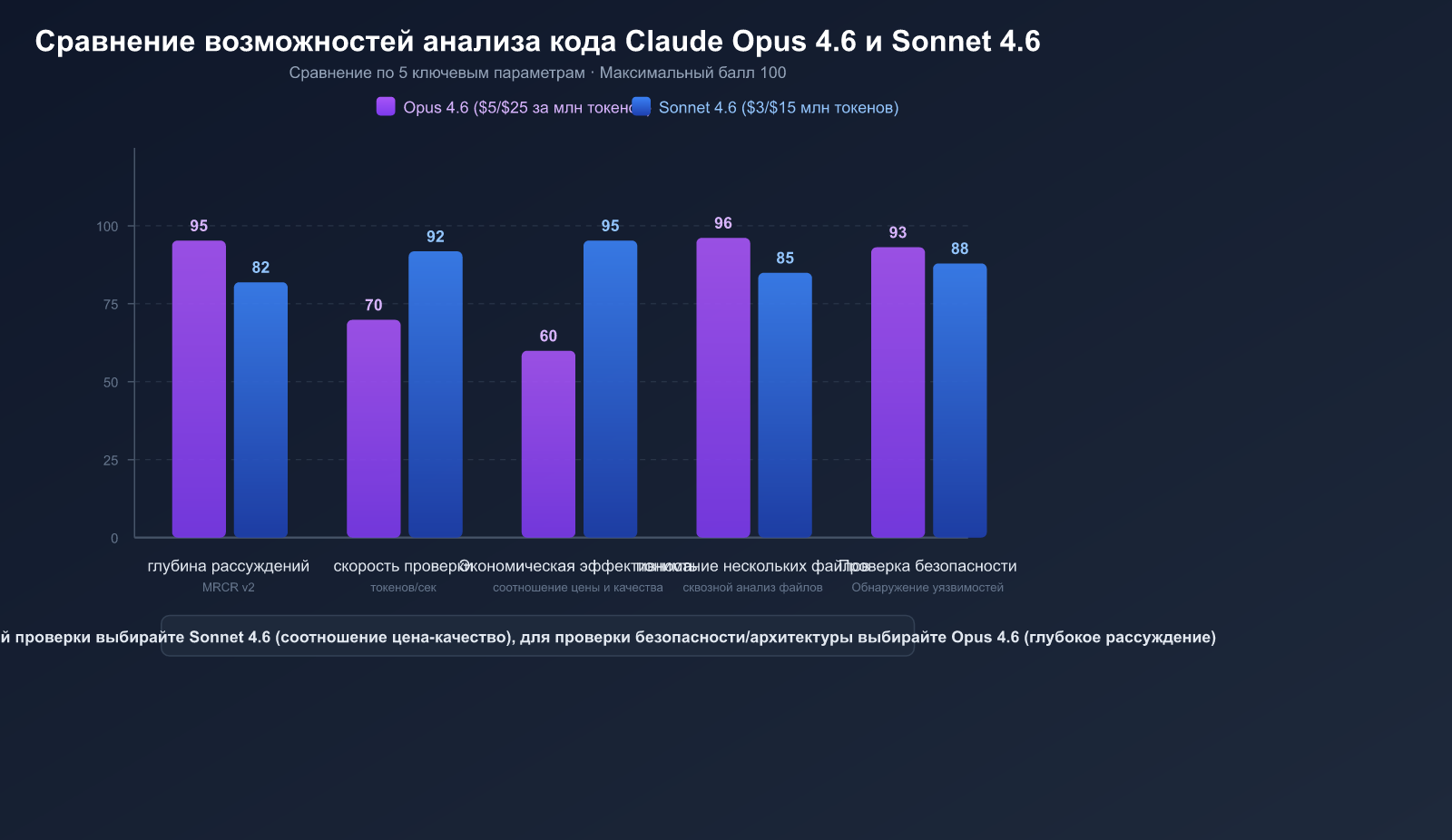
| SWE-bench Verified | 81.42% | 79.6% |
| Цена (вход/выход) | $5/$25 за 1 млн токенов | $3/$15 за 1 млн токенов |
| Сценарии использования | Анализ сложной архитектуры, аудит безопасности | Ежедневное ревью PR, проверка стиля |
| Цена APIYI | Выгоднее | Выгоднее |
Преимущество №1: Контекстное окно в 1 млн токенов
Это ключевое техническое преимущество для код-ревью.
Один PR в крупном проекте может затрагивать десятки файлов. Ограничения контекстного окна в старых моделях заставляли вас «обрезать» код, из-за чего ИИ терял контекст.
Контекст в 1 млн токенов у Claude 4.6 позволяет разом загрузить:
- Полный diff PR (обычно от сотен до тысяч строк)
- Весь код связанных файлов (цепочки импортов, вызываемые функции)
- Графы зависимостей и определения типов
- Тестовые и конфигурационные файлы
- README и архитектурную документацию проекта
Это значит, что ИИ может проводить ревью, понимая всю картину целиком, как опытный разработчик.
Преимущество №2: Топовые способности к кросс-файловым рассуждениям
Самое ценное в код-ревью — это не поиск опечаток, а обнаружение логических ошибок между файлами.
Claude Opus 4.6 набрал 76% в тесте MRCR v2 (многофайловый поиск и рассуждение), тогда как Sonnet 4.5 — всего 18.5%. Это делает Opus 4.6 незаменимым в таких задачах:
- Обнаружение ситуаций, когда в файле А изменен интерфейс, но вызовы в файле Б не обновлены
- Поиск отсутствующей валидации данных на всем пути от входа до базы данных
- Выявление условий гонки (race conditions) в многопоточных сценариях
Реальный кейс: В ходе тестирования Claude Opus 4.6 обнаружил условие гонки в PR по миграции базы данных на 2400 строк — баг в логике отката, который срабатывал только при прерывании миграции. Это сценарий, который практически невозможно покрыть обычными автотестами.
Преимущество №3: Адаптивная глубина мышления
Claude 4.6 внедряет режим adaptive thinking — ИИ автоматически решает, насколько глубоко нужно «задуматься» над проблемой.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый API-интерфейс APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Проверь эти изменения в коде на наличие уязвимостей."},
{"role": "user", "content": diff_content}
],
# Адаптивное мышление Claude 4.6: быстрый ответ на простые вопросы, глубокий анализ сложных
extra_body={"thinking": {"type": "adaptive"}}
)
- Встретил простой вопрос по стилю → быстро ответил, сэкономил токены
- Встретил сложную проблему с конкурентностью или безопасностью → провел глубокий анализ
Преимущество №4: Обнаружение уязвимостей лучше, чем у традиционных инструментов
Исследования показывают, что LLM уровня Claude значительно превосходят классические инструменты статического анализа (SAST) в поиске уязвимостей:
| Критерий сравнения | Claude (LLM) | CodeQL (традиционный SAST) |
|---|---|---|
| Кол-во найденных уязвимостей | 55 | 27 |
| Поиск неизвестных уязвимостей | 4 уязвимости нулевого дня | 0 |
| Типы проверок | Инъекции, аутентификация, утечки данных, логические ошибки и др. (10+) | На основе сопоставления шаблонов |
| Поддержка языков | Любой язык программирования | Ограниченный список |
| Фильтрация ложных срабатываний | ИИ фильтрует автоматически | Требуется ручная проверка |
Типы уязвимостей, которые находит Claude:
- SQL/командные/LDAP/XPath/NoSQL инъекции
- Дефекты аутентификации и авторизации
- Хардкод ключей, логирование чувствительных данных
- Слабые алгоритмы шифрования, ошибки управления ключами
- Условия гонки (TOCTOU)
- Небезопасные конфигурации по умолчанию, CORS
- RCE через десериализацию, инъекции в pickle/eval
- XSS (отраженные, хранимые, DOM-based)
Преимущество №5: Гибкость затрат
Цена Sonnet 4.6 составляет всего 1/5 от стоимости Opus 4.6, при этом в бенчмарках SWE-bench она отстает лишь на 1-2 процентных пункта.
Рекомендуемая стратегия выбора:
| Сценарий | Рекомендуемая модель | Почему? |
|---|---|---|
| Ежедневное ревью PR | Sonnet 4.6 | Лучшее соотношение цены и качества |
| Критически важный код | Opus 4.6 | Максимальная глубина анализа, минимум пропусков |
| Крупный рефакторинг | Opus 4.6 | Лучшая работа с множеством файлов |
| Проверка стиля | Sonnet 4.6 | Простые задачи не требуют Opus |
| CI/CD авто-ревью | Sonnet 4.6 | Контроль затрат при каждом коммите |
🚀 Совет по выбору: Официальная рекомендация Anthropic — «по умолчанию используйте Sonnet 4.6, переходите на Opus 4.6 только для задач, требующих глубоких рассуждений». Внутренние тесты Claude Code показывают, что разработчики выбирают Sonnet 4.6 на 70% чаще, чем предыдущую версию Sonnet 4.5, и даже на 59% чаще, чем флагман Opus 4.5. Используя сервис-прокси API APIYI (apiyi.com), вы можете работать с обеими моделями по более выгодным ценам.
Полноценный рабочий процесс AI-ревью кода
Обзор рабочего процесса
Разработчик создает PR
↓
Автоматический запуск AI-ревью (Sonnet 4.6)
↓
┌─── Низкий риск ──→ AI помечает как Nit, авто-одобрение
│
├─── Средний риск ──→ AI помечает проблемы, быстрое подтверждение человеком
│
└─── Высокий риск ──→ Передача на глубокий анализ в Opus 4.6
↓
Финальная проверка экспертом по безопасности
↓
Merge или отклонение
Пример кода: создание собственной системы AI-ревью
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный API-интерфейс APIYI
)
def get_pr_diff(pr_number):
"""Получение diff содержимого PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Выбор модели для ревью в зависимости от уровня риска"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Проведи ревью следующих изменений:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Пример использования
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Посмотреть полный шаблон промпта для ревью
REVIEW_PROMPT = """Ты — опытный старший инженер-программист, выполняющий ревью кода.
## Основные аспекты проверки
1. **Логическая корректность**: реализует ли код ожидаемый функционал? Учтены ли граничные условия?
2. **Безопасность**: есть ли риски инъекций, XSS, CSRF, жестко закодированные ключи и т.д.?
3. **Производительность**: есть ли N+1 запросы, избыточное выделение памяти, блокирующие операции?
4. **Поддерживаемость**: понятны ли имена? Контролируема ли сложность? Есть ли дублирование кода?
5. **Обработка ошибок**: правильно ли перехватываются и обрабатываются исключения?
6. **Потокобезопасность**: есть ли риски состояний гонки или взаимных блокировок?
Формат вывода
Выводите результаты, классифицируя их по уровню критичности:
🔴 Необходимо исправить (Bug/Security)
- [Имя файла:номер строки] Описание проблемы
- Влияние: …
- Рекомендация по исправлению: …
🟡 Рекомендуется исправить (Nit)
- [Имя файла:номер строки] Описание проблемы
- Рекомендация: …
💡 Предложения по улучшению (Suggestion)
- [Имя файла:номер строки] Точка улучшения
- Пояснение: …
Если качество кода хорошее и проблем не обнаружено, прямо укажите: "Проверка пройдена, проблем не обнаружено".
Не выдумывайте несуществующие проблемы ради самого факта вывода.
💰 Оптимизация затрат: Используйте APIYI (apiyi.com) для вызова модели Claude 4.6 при проведении код-ревью — это выгоднее, чем через официальные каналы. Платформа поддерживает гибкое переключение между Opus 4.6 и Sonnet 4.6, что позволяет автоматически выбирать наиболее экономически эффективную модель в зависимости от уровня риска PR.
Ограничения и важные нюансы AI-ревью кода
5 ограничений, о которых нужно знать
- Полнота поиска (Recall) около 50%: Уязвимости, найденные LLM, обычно реальны (точность ~80%), но примерно половину существующих проблем нейросеть может пропустить.
- Риск промпт-инъекций: Инструменты AI-ревью подвержены риску инъекций при обработке PR из недоверенных источников.
- Слепые зоны контекста: AI не понимает бизнес-контекст проекта, квалификацию членов команды и историю принятых решений.
- Накопление затрат: Если запускать проверку на каждый коммит, расходы для высокоактивных репозиториев могут стать ощутимыми.
- Риск чрезмерного доверия: Члены команды могут постепенно снизить бдительность при проведении ручного ревью.
Стратегии минимизации рисков
| Ограничение | Стратегия обхода |
|---|---|
| Высокий процент пропусков | Двойная защита: AI-ревью + ручная проверка |
| Промпт-инъекции | Проверяйте только PR из доверенных источников |
| Недостаток контекста | Предоставляйте контекст проекта в файле REVIEW.md |
| Высокие затраты | Используйте Sonnet 4.6 для повседневных задач, Opus 4.6 — для критических путей |
| Чрезмерное доверие | Внедрите регламент: "AI дает рекомендации, человек принимает решение" |
Часто задаваемые вопросы
Q1: Может ли AI-ревью кода полностью заменить человека?
Нет. AI-ревью кода — это «усиление», а не «замена». ИИ отлично справляется с поиском шаблонных проблем (стиль, типичные баги, известные уязвимости), но не понимает бизнес-логику, архитектурные компромиссы и негласные знания внутри команды. Лучшая практика — это когда ИИ делает первичный скан, а человек выносит окончательный вердикт. Используя сервис-прокси API APIYI (apiyi.com) для вызова модели Claude 4.6, можно быстро настроить процесс AI-ревью, позволяя разработчикам сосредоточиться на более важных задачах.
Q2: Что выбрать для ревью кода: Opus 4.6 или Sonnet 4.6?
В большинстве случаев — Sonnet 4.6. В бенчмарке SWE-bench он отстает от Opus всего на 1-2 процентных пункта, но стоит в 5 раз дешевле. Переходить на Opus 4.6 стоит только при проверке критически важного кода, масштабном рефакторинге архитектуры или когда требуется глубокий анализ связей между файлами. Через APIYI (apiyi.com) можно гибко переключаться между этими моделями по мере необходимости.
Q3: Какова примерная стоимость AI-ревью кода?
Нативная функция ревью в Claude Code обходится в среднем в $15-25 за сессию, в зависимости от размера PR и сложности кодовой базы. Если вы строите собственную систему ревью через API, стоимость зависит от расхода токенов. Например, при использовании Sonnet 4.6 проверка PR на 500 строк (около 2000 токенов на входе + 1000 на выходе) обойдется примерно в $0.02. С APIYI (apiyi.com) вы также получаете доступ к более выгодным тарифам.
Q4: Как оценить эффективность AI-ревью кода?
Рекомендую отслеживать 4 ключевых показателя: (1) Уровень ложных срабатываний — доля реальных проблем среди всех отмеченных ИИ; (2) Уровень пропусков — доля багов, найденных после деплоя, которые ИИ не заметил; (3) Уровень принятия — как часто разработчики реально применяют советы ИИ; (4) Изменение времени ревью — сократилось ли среднее время проверки у людей. В первые два месяца советую проводить ревью результатов еженедельно.
Q5: Как быстро начать пробовать AI-ревью кода?
Самый простой путь состоит из трех шагов: (1) Зарегистрироваться на APIYI (apiyi.com) и получить API-ключ; (2) Протестировать ревью на недавнем PR с помощью Sonnet 4.6; (3) На основе результатов решить, стоит ли интегрировать это в CI/CD. Начните с некритичных участков кода и постепенно масштабируйте решение на весь проект.
Итог: AI-ревью кода — множитель эффективности команды
AI-ревью кода — это не опция, а обязательный навык для команд разработки в 2026 году. Благодаря контекстному окну в 1 миллион токенов, результатам 81%+ в SWE-bench, адаптивному мышлению и мощным функциям безопасности, Claude Opus 4.6 и Sonnet 4.6 являются лучшим выбором для проверки кода на сегодняшний день.
Рекомендации по выбору:
- Повседневное ревью: по умолчанию Sonnet 4.6 — лидер по соотношению цена/качество.
- Безопасность/Архитектура: переходите на Opus 4.6, если нужна бескомпромиссная глубина анализа.
Рекомендуем быстро подключиться к полной линейке моделей Claude 4.6 через APIYI (apiyi.com), чтобы внедрить возможности AI-ревью в команду с оптимальными затратами.
Справочные материалы
-
Официальный сайт Anthropic: Анонс выпуска Claude Opus 4.6 и Sonnet 4.6
- Ссылка:
anthropic.com/news
- Ссылка:
-
Документация по проверке кода Claude Code: Руководство по использованию встроенных функций проверки
- Ссылка:
code.claude.com/docs/en/code-review
- Ссылка:
-
Claude Code Security Review: GitHub Action для проверки безопасности с открытым исходным кодом
- Ссылка:
github.com/anthropics/claude-code-security-review
- Ссылка:
-
Лучшие практики AI-проверки кода 2026: Комплексный отраслевой анализ
- Ссылка:
verdent.ai/guides
- Ссылка:
-
Научная статья IRIS: Обнаружение уязвимостей с помощью статического анализа на базе LLM
- Ссылка:
arxiv.org
- Ссылка:
Автор: Команда APIYI | Исследуем лучшие практики внедрения ИИ в разработку ПО. Приглашаем посетить APIYI (apiyi.com) для получения доступа к API всей линейки моделей Claude 4.6 и профессиональной технической поддержки.