Выбор быстрой и недорогой модели — главная головная боль любого разработчика, работающего с высоконагруженными проектами. 3 марта 2026 года Google официально представила Gemini 3.1 Flash Lite Preview. Это самая быстрая и экономичная модель в линейке Gemini 3, специально созданная для задач с высокой пропускной способностью: перевода, суммаризации и классификации данных.
Основная ценность: из этой статьи вы узнаете всё о технических параметрах, преимуществах и сценариях использования Gemini 3.1 Flash Lite, а также сможете быстро внедрить её в свой проект с помощью готовых примеров кода.

Краткий обзор ключевых параметров Gemini 3.1 Flash Lite
Прежде чем углубляться в детали, давайте взглянем на основные технические характеристики модели:
| Параметр | Характеристики Gemini 3.1 Flash Lite | Примечание |
|---|---|---|
| ID модели | gemini-3.1-flash-lite-preview |
Предварительная версия |
| Контекстное окно | 1 000 000 токенов | Длинный контекст |
| Макс. вывод | 64 000 токенов | Поддержка длинных текстов |
| Цена (вход) | $0.25 / 1 млн токенов | Очень низкая стоимость |
| Цена (выход) | $1.50 / 1 млн токенов | Высокая эффективность |
| Скорость вывода | ~382 токена/сек | Мгновенный отклик |
| Входные модальности | Текст, изображения, аудио, видео | Мультимодальность |
| Выходные модальности | Текст | Генерация текста |
| Дата релиза | 3 марта 2026 г. | Новейшая модель |
🚀 Быстрый старт: Gemini 3.1 Flash Lite Preview уже доступна на платформе APIYI (apiyi.com). Мы поддерживаем API, совместимый с OpenAI, поэтому вы можете подключиться мгновенно без лишних настроек.
5 главных преимуществ Gemini 3.1 Flash Lite
Преимущество 1: Скорость выше в 2,5 раза
Gemini 3.1 Flash Lite совершила качественный скачок в плане производительности. Согласно данным бенчмарков Artificial Analysis:
- Время до первого токена (TTFT): в 2,5 раза быстрее, чем у Gemini 2.5 Flash.
- Скорость вывода: достигает 382 токенов/сек, что на 64% выше показателя Gemini 2.5 Flash (232 токена/сек).
- Общая пропускная способность: выросла примерно на 45%.
Это означает, что в задачах, чувствительных к задержкам — таких как перевод в реальном времени, чат-боты или суммаризация контента — пользователи получают практически мгновенный отклик.
Преимущество 2: Максимальная экономичность
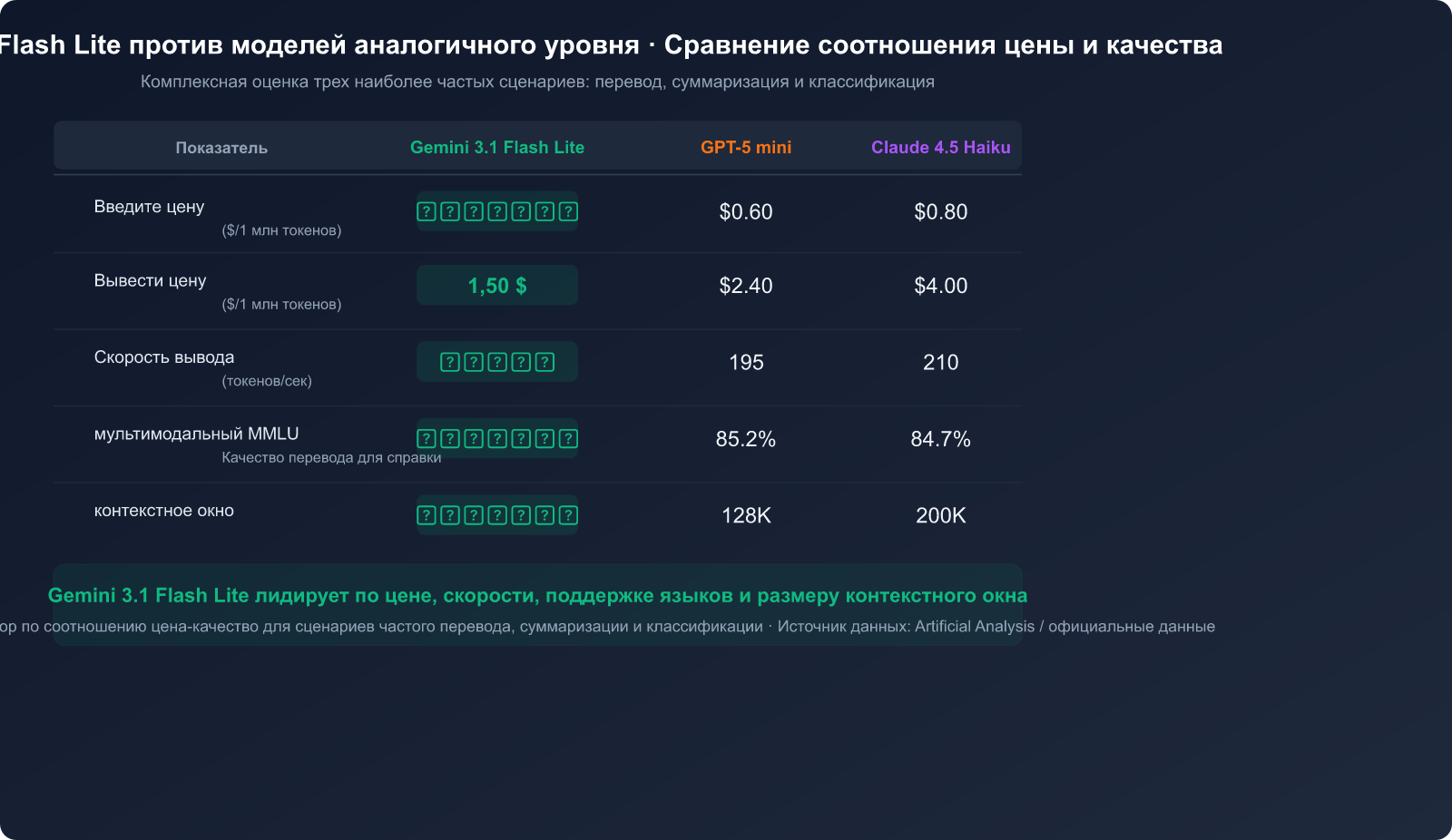
Ценовая стратегия Gemini 3.1 Flash Lite выглядит крайне привлекательно:
| Сравнение цен | Цена на вход ($/1M токенов) | Цена на выход ($/1M токенов) | Общая стоимость |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0.25 | $1.50 | ⭐ Самая низкая |
| Gemini 3 Flash | $1.00 | $4.00 | Средняя |
| Gemini 3 Pro | $2.50 | $15.00 | Высокая |
| Claude 4.5 Haiku | $0.80 | $4.00 | Средняя |
| GPT-5 mini | $0.60 | $2.40 | Средняя |
При обработке 1 млн токенов в день ежемесячные затраты на Gemini 3.1 Flash Lite составят всего около $52.50, что более чем на 80% дешевле по сравнению с Gemini 3 Pro.
Преимущество 3: Контекстное окно в 1 млн токенов
Gemini 3.1 Flash Lite поддерживает контекстное окно объемом 1 млн токенов, что большая редкость для моделей в этой ценовой категории. Это позволяет вам:
- Переводить или делать краткий пересказ целых книг за один раз.
- Анализировать многочасовые расшифровки записей встреч.
- Разбираться в огромных кодовых базах и генерировать к ним документацию.
- Выполнять многоязычный параллельный перевод длинных документов.
Преимущество 4: Нативная мультимодальность
Несмотря на то, что модель позиционируется как легковесная, Gemini 3.1 Flash Lite сохранила полноценные возможности мультимодального ввода:
- Текст: стандартное понимание и генерация текста.
- Изображения: распознавание и анализ графики.
- Аудио: обработка голосового контента.
- Видео: понимание видеоряда.
Это делает модель пригодной не только для чисто текстовых задач, но и для мультимодальных сценариев, таких как перевод с картинками или генерация субтитров к видео.
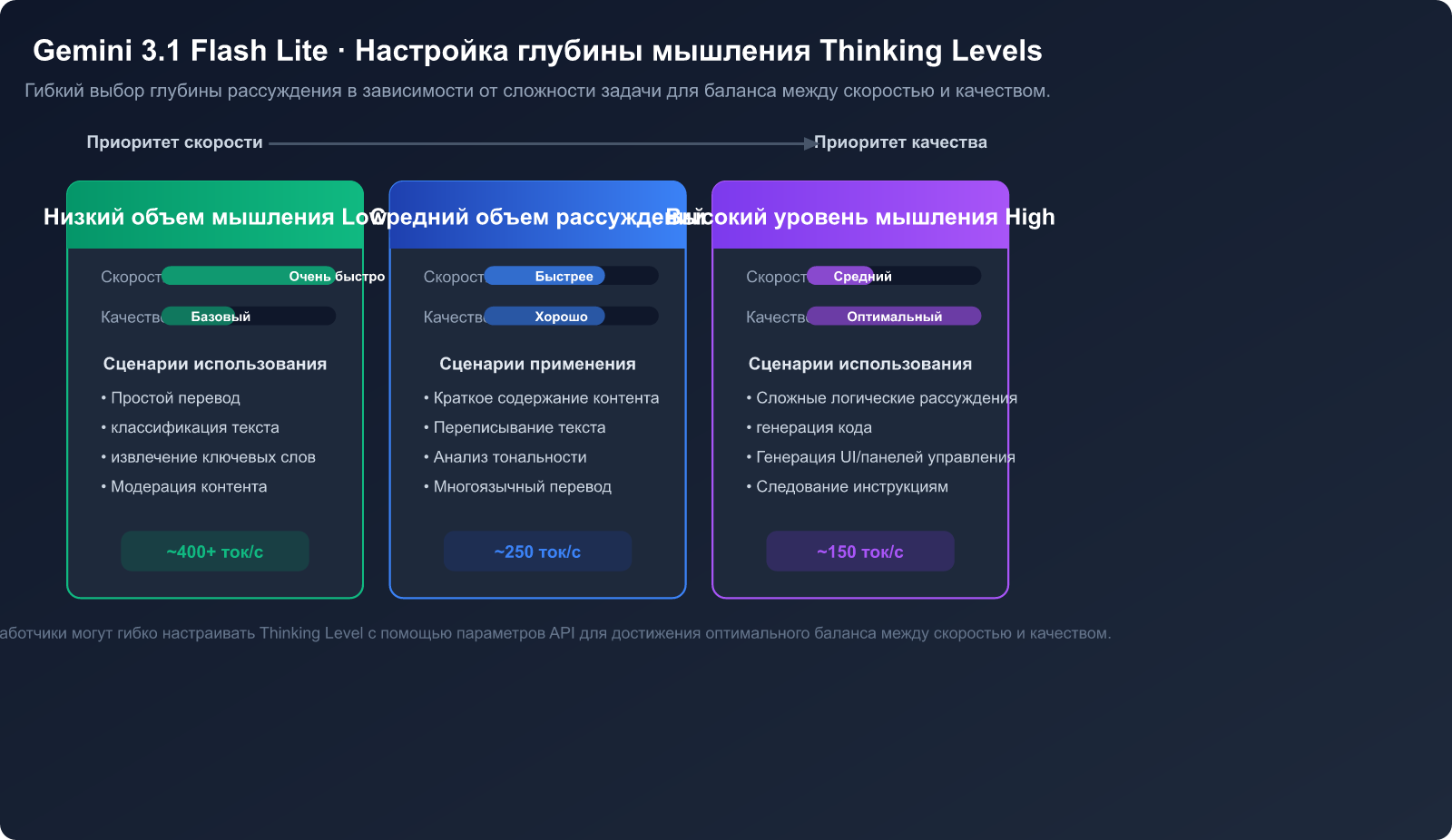
Преимущество 5: Регулируемая глубина мышления
Gemini 3.1 Flash Lite поддерживает функцию Thinking Levels, позволяя разработчикам гибко настраивать глубину рассуждений модели в зависимости от сложности задачи:
- Низкий уровень мышления: для простых переводов, классификации и других задач, где важна максимальная скорость.
- Средний уровень мышления: для суммаризации, перефразирования и задач, требующих умеренного понимания контекста.
- Высокий уровень мышления: для сложных логических рассуждений, генерации кода и задач, требующих глубокого анализа.
Бенчмарки производительности Gemini 3.1 Flash Lite
Модель Gemini 3.1 Flash Lite получила 1432 балла по шкале Elo в рейтинге Arena.ai, что делает её одной из самых сильных в своём классе.
| Бенчмарк | Gemini 3.1 Flash Lite | Описание |
|---|---|---|
| GPQA Diamond | 86.9% | Научные рассуждения |
| MMMU-Pro | 76.8% | Мультимодальные рассуждения |
| MMMLU | 88.9% | Многоязычные вопросы и ответы |
| LiveCodeBench | 72.0% | Генерация кода |
| Video-MMMU | 84.8% | Понимание видео |
| SimpleQA | 43.3% | Параметрические знания |
| MRCR v2 (128k) | 60.1% | Понимание длинного контекста |
Примечательно, что по результатам 6 бенчмарков, включая GPQA Diamond и MMMLU, Gemini 3.1 Flash Lite превзошла GPT-5 mini и Claude 4.5 Haiku, доказав, что даже легковесные модели могут демонстрировать интеллект передового уровня.
🎯 Технический совет: Данные бенчмарков показывают, что Gemini 3.1 Flash Lite особенно хороша в многоязычной обработке (MMMLU 88.9%), что делает её отличным выбором для задач перевода. Вы можете быстро протестировать модель в многоязычных задачах через APIYI (apiyi.com).
Быстрый старт с Gemini 3.1 Flash Lite
Простой пример кода
Используя интерфейс, совместимый с OpenAI, вы можете вызвать Gemini 3.1 Flash Lite всего несколькими строками кода:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI
)
# Пример сценария перевода
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Вы профессиональный переводчик. Переведите введенный пользователем китайский текст на русский, сохраняя смысл и тон."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
Посмотреть полный код: пакетный перевод + суммаризация
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="Russian"):
"""Перевод текста на целевой язык"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Переведите следующий текст на {target_lang}. Сохраните исходный смысл и тон."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Генерация краткого содержания (суммаризация)"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Кратко изложите основные мысли текста, используя не более {max_words} слов."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Классификация текста"""
cats = ", ".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Классифицируйте следующий текст по одной из категорий: {cats}. Верните только название категории."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Пример использования
texts = [
"Квантовые вычисления радикально изменят область криптографии в ближайшее десятилетие",
"Запас хода новых электромобилей превысил 1000 километров",
"Центральный банк объявил о снижении ключевой ставки на 25 базисных пунктов"
]
categories = ["Технологии", "Авто", "Финансы", "Спорт", "Развлечения"]
for text in texts:
# Перевод
translated = translate_text(text)
# Классификация
category = classify_text(text, categories)
# Суммаризация
summary = summarize_text(text, max_words=30)
print(f"Оригинал: {text}")
print(f"Перевод: {translated}")
print(f"Категория: {category}")
print(f"Итог: {summary}")
print("---")
💰 Оптимизация затрат: Для высокочастотных задач, таких как перевод, суммаризация и классификация, сверхнизкая цена Gemini 3.1 Flash Lite (входящий трафик всего $0.25 за миллион токенов) позволяет значительно сократить операционные расходы. Используя платформу APIYI (apiyi.com), вы также получаете дополнительные ценовые преимущества и бесплатные тестовые лимиты.
Лучшие сценарии использования Gemini 3.1 Flash Lite
Сценарий 1: Высокочастотный пакетный перевод
Gemini 3.1 Flash Lite достигает впечатляющего результата в 88,9% в многоязычном бенчмарке MMMLU. Благодаря крайне низкой стоимости вызова и высокой скорости отклика, эта модель становится идеальным выбором для задач пакетного перевода:
- Перевод описаний товаров для e-commerce: перевод десятков тысяч товарных позиций ежедневно.
- Перевод пользовательских отзывов: оперативный перевод обратной связи от зарубежных клиентов.
- Интернационализация технической документации: генерация многоязычных версий масштабных руководств.
- Перевод субтитров: быстрая конвертация субтитров для видео на разные языки.
Сценарий 2: Создание резюме в реальном времени
Скорость генерации 382 токена/сек делает модель отличным решением для задач суммаризации «на лету»:
- Дайджесты новостей: автоматическое создание кратких сводок из огромных потоков новостей.
- Протоколы совещаний: быстрая подготовка итогов длительных аудиозаписей встреч.
- Обзоры литературы: пакетная генерация аннотаций к научным статьям.
- Сводки писем: автоматическая классификация и краткое изложение корпоративной переписки.
Сценарий 3: Масштабная модерация и классификация контента
Низкая задержка и доступная цена делают модель идеальным инструментом для конвейеров модерации:
- Модерация пользовательского контента: фильтрация безопасности на социальных платформах.
- Автоматическая классификация тикетов: интеллектуальная маршрутизация в системах поддержки клиентов.
- Анализ тональности: мониторинг репутации бренда в реальном времени.
- Автоматическая генерация тегов: автоматизация разметки в системах управления контентом.
Руководство по выбору сценария
| Сценарий использования | Почему стоит выбрать | Ключевое преимущество | Оценка затрат (мес.) |
|---|---|---|---|
| Пакетный перевод | MMMLU 88.9%, мощный перевод | Низкая цена + качество | ~$50 (1 млн токенов/день) |
| Суммаризация | 382 токена/сек, высокая скорость | Низкая задержка | ~$30 (500 тыс. токенов/день) |
| Модерация | Высокая точность, быстрый отклик | Экономичность + объем | ~$20 (300 тыс. токенов/день) |
| Чат-боты | TTFT в 2.5 раза быстрее | Мгновенный отклик | ~$80 (2 млн токенов/день) |
| Длинные документы | Контекстное окно 1M токенов | Обработка целых книг | Оплата по факту |
💡 Совет: Если ваша задача связана с высокочастотной, пакетной и чувствительной к бюджету обработкой текста, Gemini 3.1 Flash Lite — это лучшее соотношение цены и качества на текущий момент. Мы рекомендуем протестировать модель на реальных задачах через платформу APIYI (apiyi.com), которая поддерживает переключение между моделями для сравнения результатов.
Нюансы использования Gemini 3.1 Flash Lite
Текущие ограничения
Поскольку модель находится в стадии предварительного просмотра (Preview), стоит учитывать следующие моменты:
- Стадия превью: Модель все еще находится в статусе Preview, поэтому API-интерфейсы и поведение могут меняться.
- Ограничения вывода: Максимальный объем вывода составляет 64 тыс. токенов, поэтому задачи с генерацией очень длинных текстов нужно разбивать на части.
- Производительность при сверхдлинном контексте: При работе с контекстом в 1 млн токенов результаты средние (тест MRCR v2 1M показывает всего 12,3%), поэтому для достижения наилучшего качества рекомендуется ограничиваться 128 тыс. токенов.
- Границы безопасности: Система оценки безопасности для задач «изображение-в-текст» еще требует доработки, поэтому при работе с чувствительным контентом стоит добавить дополнительный уровень проверки.
Рекомендации по использованию
- Параметр температуры: Для задач перевода рекомендуем использовать
temperature=0.3, а для суммаризации —temperature=0.5. - Системный промпт: Четкое определение роли модели и требований к формату вывода значительно повышает качество ответов.
- Пакетная обработка: Используйте асинхронные вызовы для увеличения пропускной способности, чтобы максимально эффективно задействовать высокую скорость модели.
- Контроль контекста: Несмотря на поддержку 1 млн токенов, для обычных задач лучше придерживаться лимита в 128 тыс. токенов — это обеспечит оптимальное соотношение цены и качества.
Часто задаваемые вопросы
Q1: В чем разница между Gemini 3.1 Flash Lite и Gemini 3 Flash?
Gemini 3.1 Flash Lite — это облегченная версия в линейке Gemini 3, оптимизированная для высокочастотных задач с низкими затратами. По сравнению с Gemini 3 Flash, она дешевле на 75% по входным данным ($0.25 против $1.00) и работает примерно на 64% быстрее, однако чуть слабее в задачах сложного логического вывода. Проще говоря: если нужна максимальная экономичность — выбирайте Flash Lite, если нужна более мощная логика — Flash. Через платформу APIYI apiyi.com можно протестировать обе модели и быстро подобрать ту, что лучше подходит для ваших задач.
Q2: Подходит ли Gemini 3.1 Flash Lite для перевода?
Отлично подходит. Gemini 3.1 Flash Lite набрала 88,9% в многоязычном бенчмарке MMMLU, что является одним из лучших показателей в своем классе. Учитывая сверхнизкую стоимость входных данных ($0,25 за миллион токенов) и скорость вывода 382 токена/сек, это одна из самых выгодных моделей для массового перевода. Рекомендуем получить бесплатные тестовые лимиты на APIYI apiyi.com, чтобы проверить качество перевода на практике.
Q3: Как вызывать Gemini 3.1 Flash Lite через совместимый с OpenAI интерфейс?
Просто установите base_url на адрес APIYI, а в параметре model укажите gemini-3.1-flash-lite-preview. Менять структуру кода вашего существующего OpenAI SDK не нужно — переход будет бесшовным. Подробности и примеры кода смотрите в разделе «Быстрый старт» этой статьи.
Q4: Насколько эффективно работает контекстное окно 1M у Gemini 3.1 Flash Lite?
В пределах 128 тыс. токенов модель показывает отличные результаты (оценка MRCR v2 128K — 60,1%), но при экстремальных нагрузках в 1 млн токенов производительность заметно падает (оценка MRCR v2 1M — 12,3%). Для повседневных задач советуем придерживаться лимита в 128 тыс. токенов, а при работе с очень длинными документами использовать стратегию сегментации.
Резюме
Gemini 3.1 Flash Lite Preview — это настоящий чемпион по соотношению цены и качества в 2026 году для таких задач, как перевод, суммаризация и классификация. Модель предлагает сверхнизкую стоимость в $0,25 за миллион входных токенов, невероятную скорость вывода 382 токена/сек, огромное контекстное окно в 1 млн токенов, а также отличные показатели в бенчмарках: 88,9% в MMMLU (мультиязычность) и 86,9% в GPQA Diamond (научные рассуждения).
Если вам нужно обрабатывать миллионы токенов ежедневно для пакетного перевода или создавать сервисы суммаризации в реальном времени с минимальной задержкой, Gemini 3.1 Flash Lite — это ваш выбор номер один.
Рекомендуем подключаться к Gemini 3.1 Flash Lite Preview через сервис-прокси API APIYI (apiyi.com). Платформа предоставляет интерфейс, совместимый с OpenAI, и поддерживает переключение между популярными моделями в один клик, что позволяет быстро тестировать решения и сравнивать их эффективность.
Справочные материалы
-
Google DeepMind — Карточка модели Gemini 3.1 Flash-Lite: Официальные технические характеристики и результаты бенчмарков
- Ссылка:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Ссылка:
-
Google AI for Developers — Gemini 3.1 Flash-Lite Preview: Официальная документация API и руководство для разработчиков
- Ссылка:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Ссылка:
-
Artificial Analysis — Оценка производительности: Независимые сторонние тесты скорости и качества работы
- Ссылка:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Ссылка:
📝 Автор: Техническая команда APIYI | Больше руководств по использованию AI-моделей и технических инструкций можно найти в справочном центре APIYI help.apiyi.com





