Примечание автора: Глубокое сравнение 3 самых мощных AI-моделей для решения математических задач в 2026 году, включая данные авторитетных тестов AIME, MATH и других, чтобы помочь вам найти наиболее подходящую модель для математических рассуждений.
Выбор лучшей AI-модели для решения математических задач всегда был одним из самых важных вопросов для разработчиков и студентов. В этой статье сравниваются три новейшие модели математических рассуждений, выпущенные в 2026 году: Gemini 3.1 Pro Preview, Claude Sonnet 4.6 и GPT-5.4, с предоставлением четких рекомендаций по таким параметрам, как результаты тестов, способности к рассуждению, стоимость API и сценарии применения.
Ключевая ценность: Прочитав эту статью, вы точно поймете, какую AI-модель выбрать для различных сценариев решения математических задач и как оптимально использовать их с точки зрения затрат.
Быстрый обзор ключевых математических AI-моделей для решения задач
Прежде чем перейти к детальному анализу, взгляните на таблицу ключевых данных, чтобы быстро понять основные различия между тремя AI-моделями для решения математических задач.
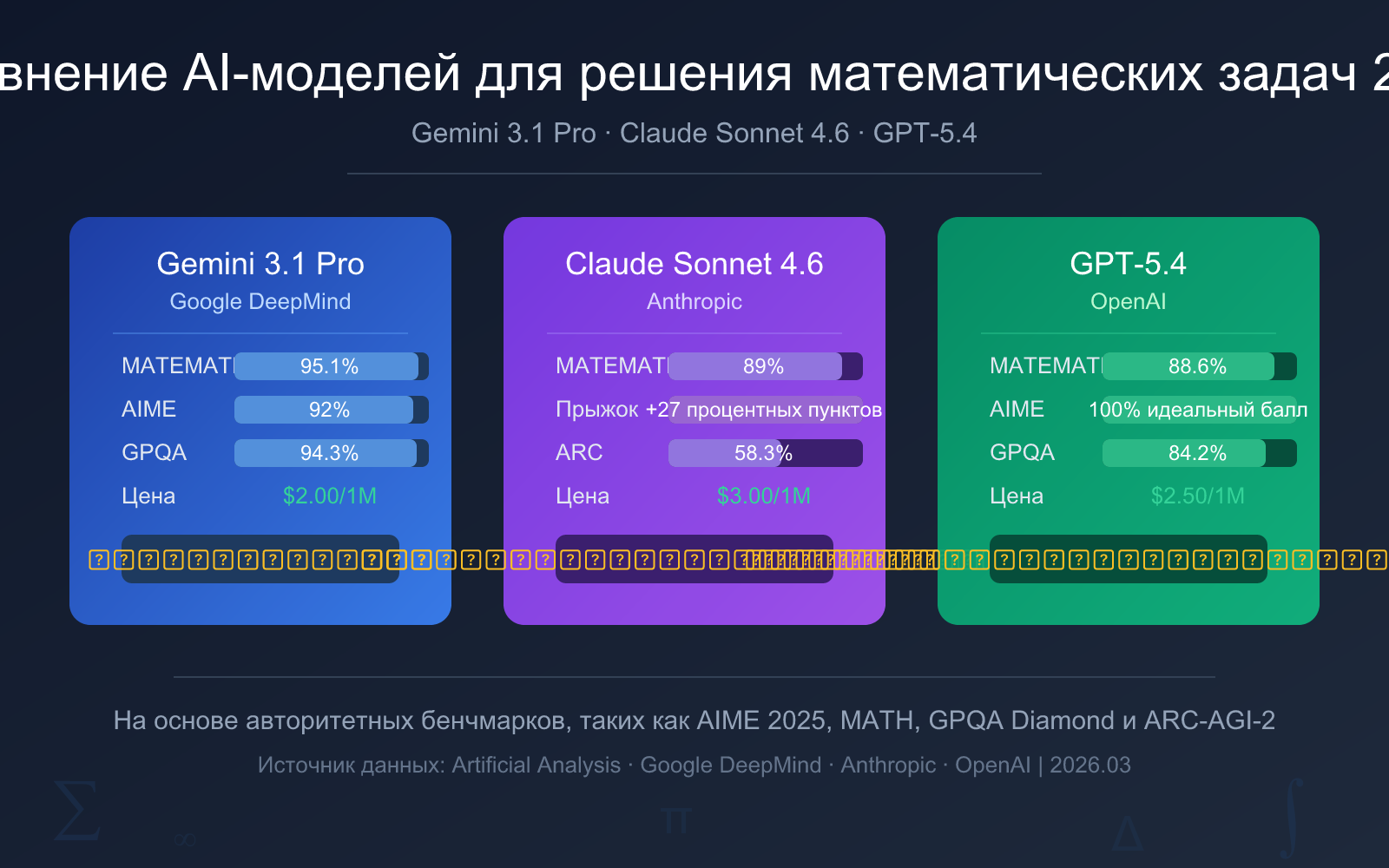
| Критерий сравнения | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Дата выпуска | 19 февраля 2026 г. | начало 2026 г. | 6 марта 2026 г. |
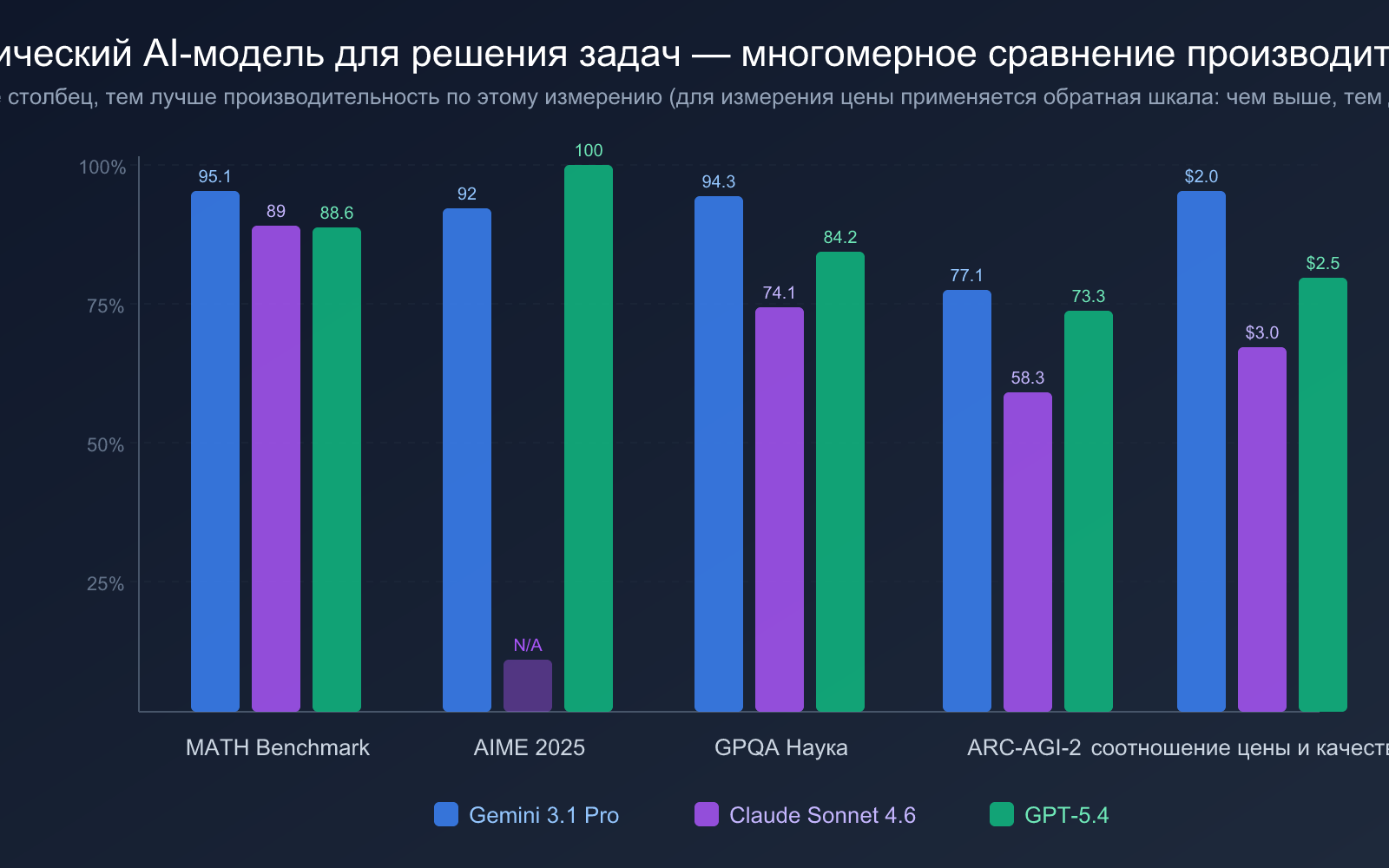
| AIME 2025 | 92% (без инструментов) | — | 100% (идеальный результат) |
| Бенчмарк MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Цена ввода | $2.00 / 1 млн токенов | $3.00 / 1 млн токенов | $2.50 / 1 млн токенов |
| Цена вывода | $12.00 / 1 млн токенов | $15.00 / 1 млн токенов | $15.00 / 1 млн токенов |
| Общая рекомендация | ⭐ Первый выбор | ⭐ Лучший для обучения | ⭐ Лучший для соревнований |
Рекомендуемая последовательность математических AI-моделей
С точки зрения общей стоимости и эффективности мы предлагаем следующий порядок:
- Первый выбор: Gemini 3.1 Pro Preview: лидер по бенчмарку MATH (95.1%), самая низкая цена, самая сильная общая математическая способность.
- Второй выбор: Claude Sonnet 4.6: скачок математических способностей на 27 процентных пунктов, понятный и ясный процесс решения, подходит для учебных сценариев.
- Соревновательный уровень: GPT-5.4: идеальный результат 100% на AIME 2025, подходит для сложных математических олимпиад и профессиональных исследований.
🎯 Техническая рекомендация: Все три модели можно вызывать через единую платформу APIYI apiyi.com. Рекомендуется протестировать каждую на реальных математических задачах, чтобы выбрать модель, наиболее соответствующую вашим потребностям.
Подробный анализ математических способностей Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview — это новейшая флагманская модель от Google DeepMind, выпущенная 19 февраля 2026 года. Это первый случай, когда Google использует инкрементную версию «.1» (ранее промежуточные обновления всегда использовали «.5»), что указывает на целенаправленное обновление, сфокусированное на способностях к логическому выводу.
Результаты математических бенчмарков Gemini 3.1 Pro
| Бенчмарк | Результат | Описание |
|---|---|---|
| MATH | 95.1% | Комплексный математический тест, охватывающий алгебру, геометрию, матанализ и другие области |
| AIME 2025 (без инструментов) | 92% | Американское математическое соревнование, уровень сложности школьных олимпиад |
| AIME 2025 (с выполнением кода) | 100% | Предыдущая модель Gemini 3 Pro достигала идеального результата при включении выполнения кода |
| GPQA Diamond | 94.3% | Вопросы и ответы на уровне аспирантуры, опережает все модели того же уровня |
| ARC-AGI-2 | 77.1% | Способность к абстрактному мышлению, в два раза выше, чем у предыдущей модели 3 Pro |
| MathArena Apex | Значительно лидирует | Улучшение более чем в 20 раз по сравнению с предыдущим поколением |
Среди 18 основных бенчмарков, опубликованных Google, Gemini 3.1 Pro заняла первое место в 12 из них. Особенно впечатляющим является результат 95.1% на бенчмарке MATH, что означает, что модель обладает исключительно сильными способностями к решению задач в различных математических областях: алгебре, геометрии, теории вероятностей, матанализе и других.
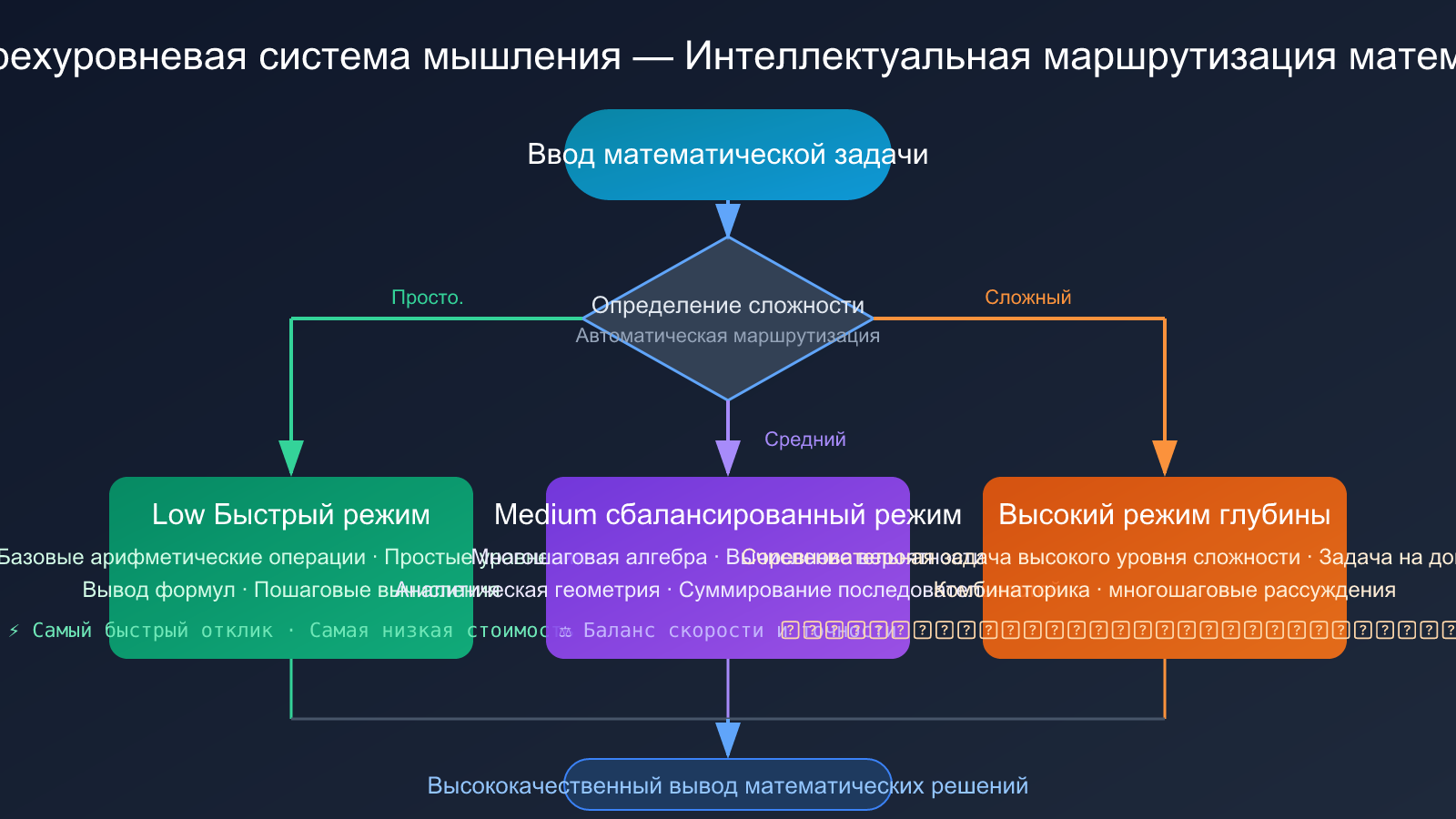
Трехуровневая система мышления Gemini 3.1 Pro
Gemini 3.1 Pro представляет ключевое архитектурное нововведение — трехуровневую систему мышления:
- Low (быстрый режим): Обрабатывает простые математические вычисления и вывод формул, самая высокая скорость отклика.
- Medium (сбалансированный режим): Новый промежуточный уровень, обрабатывает задачи средней сложности, балансирует скорость и точность.
- High (глубокий режим): Обрабатывает сложные многошаговые задачи на логическое рассуждение, такие как задачи уровня математических олимпиад.
Эта трехуровневая система позволяет разработчикам гибко направлять задачи в зависимости от их сложности, не делая выбор между «быстро, но грубо» и «медленно, но точно». Это архитектурное преимущество особенно заметно в сценариях пакетной обработки задач разной сложности (например, в адаптивных системах генерации задач для образовательных платформ).
Практический опыт решения математических задач с Gemini 3.1 Pro
В реальном решении математических задач производительность Gemini 3.1 Pro Preview можно охарактеризовать как «всестороннюю и стабильную»:
- Алгебра: Операции с полиномами, решение систем уравнений, доказательство неравенств — практически без ошибок, благодаря высокому охвату MATH 95.1%.
- Геометрия: Полные цепочки рассуждений для аналитической и стереометрической геометрии, особенно впечатляющие результаты в задачах на вычисления, связанных с системами координат.
- Теория вероятностей и статистика: Четкая логика рассуждений для задач на условную вероятность, комбинаторику, способность корректно обрабатывать сложные пошаговые вычисления.
- Математический анализ: Точное решение определенных и неопределенных интегралов, способность распознавать и правильно применять стандартные методы интегрирования.
Тот факт, что Gemini 3.1 Pro заняла первое место в 12 из 18 основных бенчмарков, не случаен. Её индекс Artificial Analysis Intelligence составляет 57 баллов, что ставит её на первое место вместе с GPT-5.4 (xhigh) и значительно превышает медианное значение в 28 баллов, демонстрируя всестороннее превосходство в логических рассуждениях.
Claude Sonnet 4.6: Подробный обзор способностей к решению математических задач
Claude Sonnet 4.6 — это последняя модель среднего уровня от Anthropic, совершившая качественный скачок в области математических рассуждений: с 62% у предыдущего поколения Sonnet 4.5 до 89%, то есть рост на целых 27 процентных пунктов.
Результаты Sonnet 4.6 в математических бенчмарках
| Бенчмарк | Sonnet 4.6 | Sonnet 4.5 (предыдущее поколение) | Прирост |
|---|---|---|---|
| Математика (общий) | 89% | 62% | +27 п.п. |
| ARC-AGI-2 | 58.3% | 13.6% | Улучшение в 4.3 раза |
| GPQA Diamond | 74.1% | — | Научные рассуждения уровня аспирантуры |
| Способности к программированию | 79.6% | — | Близко к 80.8% у Opus 4.6 |
| Финансовый анализ | 63.3% | — | Лучший в своём классе |
Скачок математических способностей с 62% до 89% — одно из самых впечатляющих изменений в Sonnet 4.6. Это означает, что модель превратилась из «иногда ошибающейся в математических задачах» в «надёжно справляющуюся со сложными вычислениями».
Механизм адаптивного мышления Claude Sonnet 4.6
Ещё одна яркая особенность Claude Sonnet 4.6 — механизм адаптивной глубины мышления (Adaptive Thinking):
- Простые задачи: Быстрый ответ без траты ресурсов на рассуждения. Например, базовые арифметические действия, решение простых уравнений.
- Задачи средней сложности: Умеренное расширение цепочки рассуждений. Например, многошаговые алгебраические операции, вычисление вероятностей.
- Сложные задачи: Автоматический запуск глубокой цепочки рассуждений. Например, комбинаторика, задачи на доказательство, задачи олимпиадного уровня.
Преимущество такого адаптивного механизма на практике: вам не нужно вручную настраивать глубину рассуждений. Модель сама оценивает сложность математической задачи и выделяет соответствующие вычислительные ресурсы, находя оптимальный баланс между задержкой и стоимостью.
Уникальное преимущество Claude Sonnet 4.6: Процесс решения
В сценариях решения математических задач у Claude Sonnet 4.6 есть одно широко признанное уникальное преимущество — ясность процесса решения. Многочисленные оценки указывают, что модели Claude лучше всего объясняют математические концепции. Кроме того, представленный Anthropic режим обучения (Learning Mode) специально разработан для того, чтобы направлять процесс рассуждений ученика, а не просто давать ответ.
Это делает Claude Sonnet 4.6 особенно подходящим для:
- Сценариев математического образования и репетиторства.
- Учащихся, которым нужно понимать шаги решения.
- Исследователей, желающих проверить ход своих мыслей.
💡 Совет по обучению: Если ваша основная потребность — «понять процесс решения математической задачи», а не просто получить ответ, то Claude Sonnet 4.6 — лучший выбор. Вы можете получить бесплатные тестовые кредиты через APIYI apiyi.com, чтобы оценить детальность его процесса решения.
GPT-5.4: Подробный обзор способностей к решению математических задач
GPT-5.4 — это новейшая флагманская модель от OpenAI, выпущенная 6 марта 2026 года. Это первая модель OpenAI для рассуждений, которая в рамках одной модели по умолчанию объединила передовые профессиональные способности, навыки программирования (от GPT-5.3-Codex), нативное управление компьютером и контекстное окно размером 1.05 млн токенов.
Результаты GPT-5.4 в математических бенчмарках
| Бенчмарк | Результат | Описание |
|---|---|---|
| AIME 2025 | 100% (идеальный результат) | Уровень школьных математических олимпиад, идеальное выполнение |
| GSM8K | 99% | Задачи на применение математики для начальной школы, почти идеально |
| MATH | 88.6% | Комплексный бенчмарк математических рассуждений |
| GPQA Diamond | 84.2% (стандарт) / 92.8% (высокие рассуждения) | Научные рассуждения уровня аспирантуры |
| ARC-AGI-2 | 73.3% (стандарт) / 83.3% (Pro) | Способности к абстрактным рассуждениям |
| FrontierMath (предыдущая 5.2) | 40.3% | Новый рекорд для экспертной передовой математики |
GPT-5.4 показал ошеломляющий результат в 100% на AIME 2025, что означает её способность идеально решать все высокосложные задачи Американского математического соревнования. Для пользователей, которым нужно решать задачи олимпиадного уровня, эта производительность очень убедительна.
Стоит отметить, что результат GPT-5.4 на бенчмарке MATH составляет 88.6%, что несколько ниже, чем 95.1% у Gemini 3.1 Pro. Это говорит о том, что хотя GPT-5.4 и демонстрирует идеальные результаты на олимпиадных задачах, она не является сильнейшей в комплексных тестах, охватывающих широкий спектр математических областей.
Варианты конфигурации рассуждений GPT-5.4
GPT-5.4 предлагает несколько конфигураций рассуждений для адаптации к разным типам математических задач:
- GPT-5.4 Стандарт: Подходит для повседневных вычислений и задач средней сложности.
- GPT-5.4 Thinking: Включает расширенные рассуждения, подходит для сложных многошаговых выводов и доказательств.
- GPT-5.4 Pro: Конфигурация с максимальной производительностью, ARC-AGI-2 достигает 83.3%, подходит для самых сложных сценариев.
Однако важно учитывать, что цена GPT-5.4 Pro составляет $30.00/1M входных токенов + $180.00/1M выходных токенов, что значительно дороже стандартной версии. Для большинства сценариев решения математических задач стандартной версии достаточно.
Практический опыт решения математических задач с GPT-5.4
Производительность GPT-5.4 на олимпиадных математических задачах особенно впечатляет:
- Олимпиадная математика: Комплексные задачи по теории чисел, комбинаторике, геометрии уровня AMC/AIME решаются почти идеально, результат в 100% на AIME заслужен.
- Задачи на доказательство: Способна строить полные цепочки математических доказательств, логически строго, переходы между шагами естественны.
- Прикладная математика: Результат в 99% на GSM8K показывает её надёжность и в практических задачах (например, инженерные расчёты, экономическое моделирование).
- Многошаговые рассуждения: Благодаря сверхдлинному контекстному окну в 1.05 млн токенов, способна обрабатывать чрезвычайно сложные многошаговые математические задачи, сохраняя полную цепочку рассуждений.
Уникальное преимущество GPT-5.4 заключается в том, что её предшественница GPT-5.2 установила новый рекорд в 40.3% на FrontierMath (экспертная передовая математика). Это означает, что серия GPT также обладает определёнными исследовательскими способностями в решении действительно передовых, нерешённых математических проблем, чего другим моделям пока трудно достичь.
Интерпретация бенчмарков для AI-моделей математических решений
Прежде чем сравнивать AI-модели для решения математических задач, важно понимать значение и фокус каждого бенчмарка, чтобы точнее оценить возможности моделей:
| Бенчмарк | Полное название | Содержание теста | Уровень сложности |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Задачи из американского математического пригласительного экзамена, охватывают теорию чисел, комбинаторику, геометрию и др. | Уровень школьных олимпиад (топ 5% учащихся) |
| MATH | Mathematics Aptitude Test of Heuristics | Комплексный тест, охватывающий 7 основных областей: алгебру, геометрию, матанализ и др. | Уровень старшей школы и бакалавриата |
| GSM8K | Grade School Math 8K | 8000 текстовых задач по математике для начальной и средней школы | Базовый уровень |
| GPQA Diamond | Graduate-Level Google-Proof QA | Вопросы на научное мышление уровня аспирантуры, составленные экспертами в области | Уровень аспирантуры/докторантуры |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Распознавание новых логических паттернов, тестирует способность к абстрактному мышлению | Уровень общего интеллекта |
| FrontierMath | Frontier Mathematics | Экспертные задачи на переднем крае математики, затрагивающие нерешённые или новые области | Уровень эксперта/исследователя |
Ключевое понимание: AIME больше фокусируется на олимпиадных математических приёмах и креативном мышлении, а MATH — на способности охватить широкий спектр областей. Если модель набирает полный балл на AIME, но не самый высокий на MATH (как GPT-5.4), это говорит о её исключительной силе в решении хитрых олимпиадных задач, но, возможно, о чуть меньшем охвате некоторых базовых областей по сравнению с моделью, набравшей больше баллов на MATH.
Именно поэтому мы рекомендуем Gemini 3.1 Pro Preview в качестве универсального фаворита — результат 95.1% на MATH означает более сбалансированную производительность во всех математических подразделах.
Важно отметить, что бенчмарк AIME 2025 в настоящее время достиг насыщения — многие топовые модели (в сочетании с выполнением кода) могут показывать результат выше 95% или даже полный балл. Поэтому реальную математическую силу моделей лучше различают более сложные бенчмарки, такие как MathArena Apex и FrontierMath. На MathArena Apex Gemini 3.1 Pro показал улучшение более чем в 20 раз по сравнению с предыдущим поколением, демонстрируя исключительно прочную основу для математических рассуждений.
Ещё одно важное измерение — ARC-AGI-2 (способность к абстрактному мышлению). Этот тест оценивает способность модели распознавать совершенно новые логические паттерны — те, которых она не видела во время обучения. Gemini 3.1 Pro Preview лидирует с результатом 77.1%, что говорит о том, что она не только решает знакомые типы задач, но и обладает более сильной способностью к обобщению и рассуждению, лучше справляясь с принципиально новыми математическими задачами.
Практика вызова AI-моделей для решения математических задач через API
Вот минимальный пример кода для вызова AI-модели решения математических задач через API — он запускается всего в 10 строк:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Можно переключить на claude-sonnet-4.6 или gpt-5.4
messages=[{"role": "user", "content": "Решите: Известно, что первый член арифметической прогрессии {an} a1=2, разность d=3, найдите сумму первых 20 членов S20"}]
)
print(response.choices[0].message.content)
Посмотреть полный код вызова для решения математических задач (сравнение нескольких моделей)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Вызов AI-модели для решения математической задачи
Args:
problem: Описание математической задачи
model: Название модели, поддерживаются gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: Системный промпт, можно указать стиль решения
Returns:
Ответ модели с решением
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Единый интерфейс APIYI
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Вы — эксперт по решению математических задач. Решайте математические задачи с чёткими шагами, объясняя логику каждого шага."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Ошибка: {str(e)}"
# Пример использования: сравнение решения одной задачи тремя моделями
problem = "В треугольнике ABC известны стороны a=5, b=7 и угол C=60°. Найдите площадь треугольника и длину третьей стороны c."
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Модель: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Рекомендация: Получите бесплатные тестовые кредиты через APIYI apiyi.com. Один API-ключ даёт доступ ко всем трём упомянутым моделям для решения математических задач, что позволит быстро сравнить их производительность на ваших реальных задачах.
Сравнение цен и стоимости математических AI-моделей
При выборе AI-модели для решения математических задач цена — важный фактор. Вот детальное сравнение цен трёх моделей:
| Параметр цены | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Цена ввода | $2.00/1M токенов | $3.00/1M токенов | $2.50/1M токенов |
| Цена вывода | $12.00/1M токенов | $15.00/1M токенов | $15.00/1M токенов |
| Смешанная цена (3:1) | $4.50/1M токенов | $6.00/1M токенов | $5.63/1M токенов |
| Наценка за длинный контекст | Удваивается при >200K | Нет | Удваивается при >272K |
| Контекстное окно | 1M токенов | Стандартное окно | 1.05M токенов |
| Макс. вывод | 65,536 токенов | Стандартный вывод | 128,000 токенов |
С точки зрения соотношения цены и качества:
- Gemini 3.1 Pro Preview предлагает лучшее соотношение: цена ввода всего $2.00/1M токенов, а результат в бенчмарке MATH — 95.1%, что является лидером. Согласно анализу Artificial Analysis, его эксплуатационные расходы примерно в 7.5 раз ниже, чем у Claude Opus 4.6, при этом он соответствует или превосходит его в математических и программистских бенчмарках.
- Claude Sonnet 4.6 имеет умеренную цену: тариф $3.00/$15.00 соответствует предыдущему поколению Sonnet 4.5, но математические способности улучшились на 27 процентных пунктов, что значительно повысило ценность.
- Цена на GPT-5.4 Standard разумна: тариф $2.50/$15.00 находится в разумных пределах, но если использовать GPT-5.4 Pro ($30/$180), стоимость значительно возрастёт.
💰 Рекомендация по стоимости: Для повседневных задач по решению математических задач рекомендуется использовать Gemini 3.1 Pro Preview для оптимального соотношения цены и качества. Для дальнейшей оптимизации затрат можно рассмотреть использование агрегатора API для получения более гибких вариантов пополнения.
Практическая оценка затрат на решение математических задач
Чтобы помочь вам лучше понять разницу в стоимости, вот оценка затрат для типичного сценария решения математических задач:
Предположения сценария: ежедневное решение 100 задач средней сложности, в среднем 500 входных токенов + 1500 выходных токенов на задачу.
| Модель | Дневная стоимость ввода | Дневная стоимость вывода | Общая дневная стоимость | Месячная стоимость (30 дней) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
Из оценки затрат чётко видно:
- Месячная стоимость Gemini 3.1 Pro Preview составляет около $57, что делает её самой экономичной среди трёх основных моделей.
- Стоимость Claude Sonnet 4.6 и GPT-5.4 Standard примерно одинакова — около $71-72 в месяц.
- Стоимость GPT-5.4 Pro достигает $855 в месяц и подходит только для сценариев с большим бюджетом и требованием к максимальной точности.
- DeepSeek R2 предлагает чрезвычайно конкурентоспособное решение по сверхнизкой цене в $10.80 в месяц.
Сравнительный анализ индекса комплексного интеллекта математических AI-моделей
Помимо отдельных бенчмарков, индекс комплексного интеллекта позволяет более полно оценить потенциал модели в математических рассуждениях. Artificial Analysis Intelligence Index в настоящее время является одной из наиболее авторитетных систем комплексной оценки, которая рассчитывает общий балл модели на основе четырёх измерений: рассуждение, знания, математика и программирование.
| Модель | Индекс комплексного интеллекта | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Комплексная оценка |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Король олимпиадных задач, делит первое место по индексу |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Делит первое место по индексу, самое полное математическое покрытие |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Лидер в научных рассуждениях и объяснениях |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Отличное соотношение цены и качества, самый понятный процесс решения |
С точки зрения индекса комплексного интеллекта, GPT-5.4 (xhigh) и Gemini 3.1 Pro Preview делят первое место с 57 баллами, но у них разные акценты:
- GPT-5.4: Показывает идеальные результаты (100%) на олимпиадных задачах типа AIME, но немного отстаёт по общему бенчмарку MATH (88.6%).
- Gemini 3.1 Pro: Более сбалансирован в общем бенчмарке MATH (95.1%) и научных рассуждениях GPQA Diamond (94.3%).
Это означает, что если ваши математические задачи больше связаны с олимпиадами и экстремально сложными проблемами, GPT-5.4 будет лучшим выбором. Если же вам нужна стабильная производительность в широком спектре математических областей, Gemini 3.1 Pro Preview — более безопасный вариант.
Рекомендации по выбору AI-модели для решения математических задач в зависимости от сценария
Разные сценарии применения математики предъявляют разные требования к моделям. Ниже приведены рекомендации, основанные на реальных сценариях использования.
Математические сценарии для выбора Gemini 3.1 Pro Preview
- Комплексные платформы для обучения математике: Охватывает все области — алгебру, геометрию, матанализ и т.д. Общая способность MATH 95.1% — самая высокая.
- Обработка больших объёмов математических задач: Самая низкая цена. Трёхуровневая система мышления автоматически адаптируется к сложности задачи, снижая стоимость обработки.
- Сценарии, сочетающие научные вычисления: Способность к научным рассуждениям GPQA Diamond 94.3% подходит для задач на стыке физики, химии и математики.
- Визуальные математические задачи: Мультимодальные возможности Gemini дают преимущество при работе с задачами, содержащими диаграммы и геометрические фигуры.
Математические сценарии для выбора Claude Sonnet 4.6
- Математическое образование и репетиторство: Самый понятный процесс решения. Режим Learning Mode специально направлен на обучение студентов рассуждениям, не давая готовый ответ, а направляя мышление.
- Изучение шагов решения: Для сценариев, где нужно понять «почему это делается именно так». Способность Claude к объяснениям признана лучшей. 70% пользователей предпочитают Sonnet 4.6 предыдущей версии 4.5, что говорит о качественном скачке в пользовательском опыте.
- Помощь в математических исследованиях: Подходит исследователям, которым нужен подробный вывод для проверки идей. Адаптивная глубина мышления автоматически подстраивается под сложность проблемы.
- Офисные и финансовые расчёты: Финансовый анализ 63.3% — лучший в своём классе. Продуктивность в офисе GDPval-AA 1633 Elo даже превосходит более дорогой Opus 4.6.
- Комбинация программирования и математики: Способность к программированию 79.6% близка к Opus 4.6, подходит разработчикам, которым нужно писать программы для математических вычислений.
Математические сценарии для выбора GPT-5.4
- Сложные математические олимпиады: 100% на AIME — модель первого выбора для задач олимпиадного уровня.
- Математические рассуждения в длинных документах: Контекстное окно 1.05M подходит для обработки сложных проблем, требующих большого объёма математического контекста.
- Профессиональные математические исследования: Предыдущая версия GPT-5.2 установила новый рекорд 40.3% на FrontierMath, что говорит о высокой экспертной способности в передовой математике.
- Инвестиционный банкинг и количественные финансы: Высокий балл 87.3% в задачах финансового моделирования подходит для сценариев продвинутой финансовой математики.
Стратегия смешанного использования: оптимальная комбинация моделей для решения задач
В реальной производственной среде многие команды используют стратегию смешанного применения для достижения наилучших результатов.
Стратегия 1: Маршрутизация по сложности
- Базовые задачи (арифметика, простые уравнения) → Gemini 3.1 Pro Low режим, самая низкая стоимость.
- Задачи средней сложности (многошаговые рассуждения, текстовые задачи) → Claude Sonnet 4.6 адаптивный режим, понятный процесс решения.
- Сложные задачи (олимпиадные, доказательства) → GPT-5.4 Thinking режим, самая высокая точность.
Стратегия 2: Перекрёстная проверка
- Сначала быстро решить задачу с помощью Gemini 3.1 Pro (низкая стоимость, высокая скорость).
- Ключевые результаты проверить с помощью GPT-5.4 (высокая точность).
- Если нужно объяснить пользователю, переформулировать с помощью Claude Sonnet 4.6 (ясное изложение).
🚀 Рекомендация по внедрению: Вышеуказанную стратегию смешанного использования легко реализовать через платформу APIYI apiyi.com. Один API-ключ позволяет вызывать все модели, достаточно просто переключать параметр
modelв коде.
Рекомендации по выбору AI-моделей для решения математических задач
На основе проведённого анализа, вот рекомендации по выбору модели для разных категорий пользователей:
| Тип пользователя | Рекомендуемая модель | Обоснование |
|---|---|---|
| Студенты / Самостоятельные учащиеся | Claude Sonnet 4.6 | Чёткий процесс решения, режим Learning Mode помогает понять ход мысли |
| Разработчики образовательных платформ | Gemini 3.1 Pro Preview | Наиболее сбалансированные возможности, самая низкая цена, трёхуровневое мышление адаптируется к сложности |
| Участники соревнований / Тренеры | GPT-5.4 | Максимальный балл на AIME, наилучшие возможности для решения задач олимпиадного уровня |
| Научные сотрудники | Gemini 3.1 Pro Preview | 94.3% на GPQA Diamond, лидирующие возможности в междисциплинарных (наука + математика) задачах |
| Корпоративные пользователи (пакетная обработка) | Gemini 3.1 Pro Preview | Наилучшее соотношение цены и качества, цена ввода $2.00 за 1M токенов |
| Команды количественного анализа (финансы) | GPT-5.4 | 87.3% на задачах инвестиционного банкинга, сильнейшая модель для задач финансовой математики |
💡 Совет по выбору: Выбор AI-модели для решения математических задач в первую очередь зависит от вашего конкретного сценария использования. Если вы не уверены, какая модель подходит лучше всего, мы рекомендуем протестировать три модели на платформе APIYI apiyi.com, используя одну и ту же математическую задачу, и сделать окончательный выбор на основе качества решения и скорости ответа. Платформа поддерживает единый интерфейс вызова, что упрощает быстрое сравнение и переключение между моделями.
Другие заслуживающие внимания модели для решения математических задач
Помимо трёх основных моделей, описанных выше, есть ещё несколько AI-моделей, которые заслуживают внимания в определённых сценариях:
| Название модели | AIME 2025 | Ключевое преимущество | Цена API (ввод/вывод) | Подходящий сценарий |
|---|---|---|---|---|
| DeepSeek R2 | Превзошёл Gemini 3.1 Pro | Максимальное соотношение цены и качества | $0.55 / $2.19 за 1M | Пакетная обработка математических задач при ограниченном бюджете |
| Claude Opus 4.6 | — | 91.3% на GPQA, самые глубокие объяснения | $15 / $75 за 1M | Высококлассные научные исследования и глубокая логика |
| Qwen3-235B | 89.2% | Сильнейшая открытая модель | Стоимость самостоятельного развёртывания | Сценарии, требующие приватного развёртывания |
| DeepSeek R1 | ~87.5% | Эталонная открытая модель, 671B MoE | Стоимость самостоятельного развёртывания | Исследования в open-source сообществе и доработка |
| MiMo-V2-Flash | 94.1% | Стоимость логического вывода всего 2.5% от стоимости Claude | Очень низкая | Сверхмасштабная обработка с низкими затратами |
Особого внимания заслуживает DeepSeek R2. Эта модель превзошла Gemini 3.1 Pro Preview на AIME, при этом её цена примерно в 4 раза ниже. Если ваш сценарий решения математических задач крайне чувствителен к бюджету, DeepSeek R2 — очень конкурентоспособный выбор.
Модель MiMo-V2-Flash показала результат 94.1% на AIME 2025, а стоимость её логического вывода составляет всего 2.5% от стоимости Claude. Это делает её отличным выбором для образовательных технологических платформ, которым требуется массовая пакетная обработка математических задач.
Советы по оптимизации промптов для AI-моделей, решающих математические задачи
Независимо от выбранной модели, качественный промпт может значительно улучшить результат решения. Вот проверенные техники составления промптов для математических задач:
- Указывайте тип задачи: В промпте отмечайте «Это задача комбинаторики» или «Это задача аналитической геометрии», чтобы помочь модели выбрать правильную стратегию решения.
- Требуйте пошагового решения: Добавляйте «Пожалуйста, выводите решение по шагам, отмечая на каждом шаге используемую теорему или формулу» — это повысит читаемость процесса.
- Задавайте формат вывода: Например, «Пожалуйста, выводите математические формулы в формате LaTeX» или «Заключительный ответ выделите рамкой».
- Предоставляйте контекстные ограничения: Например, «Предположим, что x — натуральное число» или «Решите в области действительных чисел», чтобы избежать ненужных вариантов обсуждения от модели.
- Кросс-валидация разными моделями: Для ключевых результатов проверяйте согласованность ответов с помощью разных моделей, чтобы повысить уверенность в результате.
Часто задаваемые вопросы
Вопрос 1: Можно ли доверять результатам бенчмарков AI-моделей для решения математических задач?
Бенчмарки предоставляют стандартизированную основу для горизонтального сравнения, но фактическая эффективность также зависит от типа задач, качества промптов и других факторов. AIME и MATH в настоящее время являются наиболее авторитетными бенчмарками для математических рассуждений, широко признанными академическим сообществом и индустрией. Рекомендуем, помимо использования данных бенчмарков, самостоятельно протестировать модели на ваших реальных задачах для проверки.
Вопрос 2: Я студент. Какую AI-модель для решения математических задач мне выбрать?
Рекомендуем в первую очередь выбрать Claude Sonnet 4.6. Его процесс решения задач наиболее понятен, каждый шаг сопровождается чёткими пояснениями, что идеально подходит для обучения и понимания логики решения. Функция Learning Mode от Anthropic также может направлять ваши собственные размышления, а не просто давать ответ. Если вы столкнётесь с особенно сложной олимпиадной задачей, можно переключиться на GPT-5.4 за помощью.
Вопрос 3: Как быстро начать тестирование этих AI-моделей для решения математических задач?
Рекомендуем использовать агрегатор API с единым интерфейсом для нескольких моделей:
- Зарегистрируйте аккаунт на APIYI apiyi.com
- Получите API-ключ и бесплатный тестовый лимит
- Используйте пример кода на Python из этой статьи, изменяя параметр
modelдля переключения между разными моделями - Протестируйте три модели на одной и той же математической задаче, сравнив качество решения и скорость ответа
Вопрос 4: Поддерживают ли эти AI-модели для решения математических задач вывод формул в формате LaTeX?
Все три модели поддерживают вывод математических формул в формате LaTeX. Достаточно добавить в промпт фразу «Пожалуйста, выводите все математические формулы в формате LaTeX». Gemini 3.1 Pro и GPT-5.4 лучше форматируют LaTeX, а Claude Sonnet 4.6 даёт более подробные текстовые пояснения между формулами. Для сценариев, где формулы нужно напрямую копировать в научные работы, рекомендуем использовать Gemini или GPT.
Вопрос 5: Могут ли AI-модели для решения математических задач обрабатывать задачи, представленные на изображениях?
Gemini 3.1 Pro Preview и GPT-5.4 поддерживают мультимодальный ввод и могут напрямую загружать и решать изображения с математическими задачами. Gemini особенно хорошо справляется с изображениями, содержащими геометрические фигуры и рукописные формулы. Claude Sonnet 4.6 также поддерживает ввод изображений, но немного уступает Gemini в распознавании сложных геометрических фигур. Если ваши математические задачи часто представлены в виде изображений (например, при поиске по фото), Gemini 3.1 Pro Preview — лучший выбор.
Итоги
Ключевые моменты при выборе AI-модели для решения математических задач:
- Лучший выбор по совокупности возможностей — Gemini 3.1 Pro Preview: лидирует в MATH с 95.1%, самая выгодная цена $2.00/1M токенов, гибкая трёхуровневая система мышления адаптируется к разной сложности.
- Лучший выбор для обучения и понимания — Claude Sonnet 4.6: математические способности выросли на 27 процентных пунктов до 89%, шаги решения чёткие, адаптивная глубина мышления балансирует стоимость и качество.
- Лучший выбор для олимпиадных задач — GPT-5.4: 100% результат в AIME 2025, сверхдлинное контекстное окно в 1.05M токенов, непревзойдённые способности к сложным рассуждениям.
Нет ни одной модели, которая была бы оптимальной во всех математических сценариях. Конкурентный ландшафт AI-моделей для решения математических задач в 2026 году можно подытожить так:
- Всестороннее покрытие: Gemini 3.1 Pro Preview с результатом 95.1% в MATH и самой низкой ценой занимает первое место по совокупности факторов.
- Обучение и образование: Claude Sonnet 4.6 благодаря росту математических способностей на 27 пунктов и непревзойдённой способности объяснять решения стал лучшим выбором для образовательных сценариев.
- Сложнейшие олимпиады: GPT-5.4 с абсолютным результатом в AIME доминирует в области высокосложных математических соревнований.
- Приоритет бюджета: DeepSeek R2 предлагает сопоставимые математические способности по цене менее 1/4 от стоимости Gemini.
Самая разумная стратегия — выбрать подходящую модель в соответствии с вашими реальными потребностями или даже использовать несколько моделей для задач разной сложности, чтобы в полной мере использовать уникальные преимущества каждой.
Рекомендуем быстро протестировать и сравнить эти модели через APIYI apiyi.com. Платформа предоставляет бесплатный лимит и единый API-интерфейс, позволяя подключиться один раз и гибко вызывать все основные модели для математических рассуждений, легко реализуя стратегию смешанного использования нескольких моделей.
📚 Справочные материалы
-
Google DeepMind Gemini 3.1 Pro Model Card: официальные бенчмарки и технические детали
- Ссылка:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Описание: содержит полные результаты бенчмарков и описание архитектуры
- Ссылка:
-
Anthropic Claude Sonnet 4.6 Release Notes: подробности об улучшении математических рассуждений
- Ссылка:
docs.anthropic.com - Описание: содержит сравнительные данные Sonnet 4.6 с предыдущим поколением и описание механизма адаптивного мышления
- Ссылка:
-
OpenAI GPT-5.4 Release Announcement: новейшие возможности модели и бенчмарки
- Ссылка:
openai.com/index/introducing-gpt-5-4/ - Описание: содержит полные результаты бенчмарков GPT-5.4 и описание конфигурации рассуждений
- Ссылка:
-
Artificial Analysis Model Evaluations: независимая платформа для сравнения бенчмарков
- Ссылка:
artificialanalysis.ai/evaluations/aime-2025 - Описание: предоставляет независимые рейтинги и анализ для бенчмарков, таких как AIME 2025
- Ссылка:
-
AIME 2025 Benchmark Leaderboard: авторитетное сравнение математических рассуждений
- Ссылка:
vals.ai/benchmarks/aime - Описание: постоянно обновляемые данные рейтинга бенчмарков AI для математических рассуждений
- Ссылка:
Автор: Техническая команда APIYI
Техническое обсуждение: Делитесь своим опытом использования AI для решения математических задач в комментариях. Больше руководств по вызову моделей можно найти в документации APIYI docs.apiyi.com