В последнее время многие разработчики сталкиваются со следующим сообщением об ошибке при вызове Gemini API:
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
Проще говоря: эта модель сейчас очень популярна, серверы не справляются, попробуйте повторить запрос позже.
Эта проблема особенно актуальна для новых моделей Gemini 3.1 Pro Preview и Gemini 3.1 Flash Image Preview (Nano Banana 2). В этой статье мы подробно разберем суть этой ошибки, ее отличия от других распространенных ошибок, а также 5 проверенных и эффективных решений.
Основная ценность: Прочитав эту статью, вы точно поймете первопричину ошибки 503 high demand, освоите 5 практических решений и больше не будете задерживать разработку из-за этой проблемы.
Что на самом деле означает ошибка Gemini API 503 High Demand
Давайте сначала разберем эту проблему на простом примере:
Представьте, что серверы Google Gemini — это популярный ресторан. Обычно дела идут хорошо, мест хватает. Но вдруг в один прекрасный день ресторан попадает в тренды (выпускается новая модель), и весь город устремляется туда, чтобы встать в очередь. Вместимость ресторана ограничена, и когда все места заняты, они заняты. В этот момент вы подходите к входу, и официант говорит вам: "Извините, сейчас слишком много людей, час пик обычно временный, пожалуйста, зайдите позже."
В этом и заключается суть сообщения This model is currently experiencing high demand — проблема не в вашем коде, не в вашем API-ключе, а в том, что у Google не хватает вычислительной мощности серверов.
3 ключевых факта об ошибке Gemini 503
| Факт | Описание | Влияние |
|---|---|---|
| Проблема на стороне сервера | 503 означает недостаточную емкость серверов Google, это не связано с вашим кодом или конфигурацией | Обновление платного тарифного плана тоже не поможет |
| Затрагивает всех пользователей | С ней сталкиваются как бесплатные, так и платные пользователи, а также корпоративные клиенты | Это не та проблема, которую можно "решить деньгами" |
| Обычно временная | Около 70% ошибок 503 в часы пик устраняются сами в течение 60 минут | Требуется механизм повторных попыток, а не исправление кода |
Почему Gemini 3.1 Pro и Nano Banana 2 особенно подвержены ошибке 503
Всплеск ошибок 503 в феврале 2026 года имеет четкую хронологию:
- 19 февраля: Google выпускает предварительную версию Gemini 3.1 Pro Preview, и множество разработчиков устремляются для тестирования.
- 26 февраля: Выпускается Nano Banana 2 (
gemini-3.1-flash-image-preview), что приводит к резкому росту спроса на генерацию изображений. - 17-21 февраля: StatusGator непрерывно фиксирует предупреждения о снижении производительности сервиса Gemini в течение всей недели.
- Частота отказов в часы пик около 45%: Данные сообщества показывают, что частота отказов запросов в пиковые часы приближается к половине.
Основная причина: Новые модели только что запущены, и Google еще не масштабировал выделенную вычислительную мощность (кластеры GPU по требованию). Ресурсы серверов для моделей в статусе Preview изначально ограничены, и когда разработчики со всего мира одновременно начинают тестирование, возникает ситуация, когда спрос превышает предложение.

Фундаментальные различия между Gemini 503 High Demand и 429 Rate Limit
Многие разработчики путают ошибки 503 и 429, но причины этих ошибок совершенно разные, и решения для них тоже совершенно разные. Если ошибиться с направлением, то все усилия будут напрасны.
| Критерий сравнения | 503 High Demand | 429 Rate Limit |
|---|---|---|
| Сообщение об ошибке | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| Основная причина | Недостаточная вычислительная мощность серверов Google | Превышена ваша личная частота запросов |
| Область влияния | Затрагивает всех пользователей | Затрагивает только вас |
| Решает ли обновление | ❌ Обновление платного тарифа не поможет | ✅ Обновление до Tier 1 может помочь |
| Эффективен ли повтор | ✅ Обычно восстанавливается через некоторое время | ❌ Без снижения частоты ошибки будут продолжаться |
| Характеристики пикового периода | Часто возникает в рабочее время Северной Америки (9:00-17:00 PT) | Не зависит от времени суток, ошибка возникает при превышении лимита |
| Фундаментальное решение | Повторный запрос + резервная модель + смещение пиковой нагрузки | Снижение частоты запросов или обновление тарифа |
Как определить в двух словах
- Видите 503 → Проблема у Google, подождите или смените модель
- Видите 429 → Вы сами запрашиваете слишком быстро, замедлитесь или обновите тариф
🎯 Технический совет: Обработка ошибок 503 и 429 в производственной среде — это базовый навык интеграции API. При вызове моделей серии Gemini через платформу APIYI apiyi.com, платформа использует встроенные механизмы интеллектуального повтора и балансировки нагрузки, что значительно снижает частоту ошибок 503, воспринимаемых конечными пользователями.
Решение первое: Экспоненциальная задержка при повторных попытках (самое базовое)
Раз 503 означает "попробуйте снова через некоторое время", то самый прямой способ справиться с этим — это автоматический повтор. Но нельзя просто так бездумно повторять запросы — нужно использовать стратегию "экспоненциальной задержки", удваивая интервал между каждой попыткой, чтобы не усугублять нагрузку на сервер.
Код для экспоненциальной задержки при повторных попытках с Gemini 503
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""Вызов API Gemini с экспоненциальной задержкой"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# Экспоненциальная задержка: 2с, 4с, 8с, 16с, 32с + случайное дрожание
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - Попытка {attempt+1}, ожидание {wait_time:.1f}с...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 Rate Limit: ждать дольше
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - Ожидание {wait_time:.1f}с...")
time.sleep(wait_time)
else:
raise # Прочие ошибки выбрасывать напрямую
raise Exception(f"Не удалось после {max_retries} попыток")
# Пример использования
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
Ключевые параметры экспоненциальной задержки при повторных попытках
| Параметр | Рекомендуемое значение | Описание |
|---|---|---|
| Максимальное количество повторов | 5 раз | Более 5 попыток обычно означает, что проблема не временная |
| Начальное ожидание | 2 секунды | Слишком короткое ожидание усугубит нагрузку на сервер |
| Коэффициент задержки | 2x | Удваивается каждый раз: 2с → 4с → 8с → 16с → 32с |
| Случайное дрожание | 0-1 секунда | Помогает избежать одновременного повтора запросов от множества клиентов |
| Максимальное ожидание | 32 секунды | Если превышено 32 секунды, следует переключиться на резервный вариант |
💡 Полезный совет: Случайное дрожание (jitter) очень важно. Если все клиенты будут повторять попытки ровно через 2 секунды, это вызовет "эффект стаи" — все запросы одновременно снова хлынут на сервер, что приведет к очередной волне ошибок 503. Добавление случайного дрожания позволяет распределить повторные запросы.
Решение 2: Понижение версии модели / Автоматическое переключение на резервную модель
Когда Gemini 3.1 Pro Preview постоянно возвращает 503 ошибку, самое практичное решение — это автоматическое переключение на более стабильную резервную модель.
Стратегия понижения версии модели Gemini при 503 ошибке
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Цепочка понижения версии модели: сначала используем самую мощную, если не работает — понижаем версию
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # Предпочтительная: новейшая и самая мощная
"gemini-3.0-pro", # Резервная 1: Pro предыдущего поколения, более стабильная
"gemini-2.5-flash-image-preview", # Резервная 2: Flash-версия, быстрая
"gemini-2.5-flash", # Запасной вариант: самый стабильный Flash
]
def call_with_fallback(messages):
"""Вызов API с понижением версии модели"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ Выполнено понижение до резервной модели: {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} возвращает {e.status_code}, пробуем следующую модель...")
continue
raise
raise Exception("Все модели недоступны")
response = call_with_fallback(
messages=[{"role": "user", "content": "Проанализируй узкие места производительности этого кода"}]
)
Рейтинг стабильности моделей Gemini
| Модель | Стабильность | Частота 503 ошибок | Подходящие сценарии |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | Крайне низкая | Запасной вариант для высокодоступных производственных сред |
gemini-3.0-pro |
⭐⭐⭐⭐ | Низкая | Стабильные сценарии, требующие возможностей Pro |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | Средняя | Резервный вариант для генерации изображений |
gemini-3.1-pro-preview |
⭐⭐ | Высокая | Требует новейших возможностей, но допускает случайные сбои |
gemini-3.1-flash-image-preview |
⭐⭐ | Высокая | Генерация изображений Nano Banana 2 |
🚀 Быстрый старт: Через платформу APIYI (apiyi.com) вы можете вызывать все модели из таблицы выше с помощью одного API-ключа. Для переключения модели достаточно изменить параметр
model, без необходимости перенастраивать аутентификацию. Реализовать цепочку понижения версии модели в коде очень удобно.
Решение 3: Вызовы вне пиковых часов (бесплатное решение)
Высокий спрос, приводящий к 503 ошибкам, имеет четкую временную закономерность. Данные сообщества показывают:
- Пиковые часы (9:00–17:00 PT): уровень отказов около 45%
- Часы низкой нагрузки (2:00–7:00 PT): уровень отказов менее 5%
В пересчете на пекинское время:
| Период (по пекинскому времени) | Соответствующее тихоокеанское время | Частота 503 ошибок Gemini | Рекомендации |
|---|---|---|---|
| 1:00 – 10:00 утра | 9:00–18:00 PT (предыдущего дня) | 🔴 Пик | Избегать или использовать резервную модель |
| 10:00 – 15:00 дня | 18:00–23:00 PT (предыдущего дня) | 🟡 Средняя | Вызывать с механизмом повторных попыток |
| 15:00 – 23:00 вечера | 23:00–7:00 PT | 🟢 Низкая | Оптимальное окно для вызовов |
| 23:00 – 1:00 ночи | 7:00–9:00 PT | 🟡 Средняя | Начинает расти |
Сценарии, подходящие для вызовов вне пиковых часов
- Пакетная обработка данных: задачи, не требующие ответа в реальном времени, планировать на часы низкой нагрузки.
- Плановые задачи: настроить cron job для выполнения в часы низкой нагрузки.
- Генерация контента: статьи, изображения и т.д., которые можно сгенерировать заранее и опубликовать позже.
Решение четыре: Комбинированная стратегия (рекомендуется для продакшн-среды)
В реальных продакшн-средах одного решения часто бывает недостаточно. Рекомендуется комбинировать первые 3 решения:
Схемы вызова API Gemini продакшн-уровня
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
Вызов API Gemini продакшн-уровня
Стратегия: экспоненциальная задержка при повторных попытках + понижение версии модели + классификация ошибок
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - Повторная попытка {attempt+1}/{max_retries}, ждём {wait:.1f}с")
time.sleep(wait)
else:
print(f"⚠️ {model} продолжает выдавать 503, переключаемся на следующую модель")
break # Выходим из цикла повторных попыток, переключаемся на другую модель
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 Превышен лимит запросов - ждём {wait}с")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} Таймаут запроса, пробуем следующую модель")
break
raise Exception("Все модели и повторные попытки завершились неудачей, проверьте сеть или попробуйте позже")
# Использование
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "你好"}]
)
print(f"✅ Используемая модель: {used_model}")
print(response.choices[0].message.content)
Посмотреть полную продакшн-обёртку (с логированием, мониторингом, кешированием)
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Простое кеширование запросов
_cache = {}
def get_cache_key(messages, model):
"""Генерирует ключ кеша для запроса"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
Обёртка для вызова API Gemini продакшн-уровня
Особенности:
- Экспоненциальная задержка при повторных попытках (обработка 503)
- Автоматическое понижение версии модели
- Кеширование ответов (уменьшает количество повторяющихся запросов)
- Структурированное логирование
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# Проверка кеша
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("Попадание в кеш, пропуск вызова API")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"Успешно | model={model} | время={elapsed:.2f}с")
# Запись в кеш
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | попытка={attempt+1} | ждём={wait:.1f}с")
time.sleep(wait)
else:
logger.warning(f"503 продолжается | model={model} | понижение до следующей модели")
break
elif e.status_code == 429:
logger.warning(f"429 Превышен лимит запросов | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"Ошибка | model={model} | ошибка={e}")
break
raise Exception(f"Все попытки провалились: {errors}")
Решение пять: Использование интеллектуальной маршрутизации платформы-прокси API
Если вы не хотите самостоятельно реализовывать вышеупомянутую сложную логику повторных попыток и снижения версии, есть более простое решение — использовать платформу-прокси API со встроенной интеллектуальной маршрутизацией.
Как платформа-прокси API решает проблему Gemini 503
Профессиональные платформы-прокси API обычно обладают следующими возможностями:
- Ротация нескольких API-ключей: Платформа использует несколько Google API-ключей, автоматически переключаясь на другой при ограничении скорости одного ключа.
- Интеллектуальные повторные попытки: На уровне платформы реализованы повторные попытки с экспоненциальной задержкой, что прозрачно для разработчика.
- Балансировка нагрузки: Распределение запросов между несколькими аккаунтами Google и регионами.
- Обнаружение сбоев: При обнаружении увеличения частоты ошибок 503 для определенной модели, платформа автоматически снижает долю запросов, направляемых к этой модели.
🎯 Технический совет: Платформа APIYI (apiyi.com) предоставляет вышеупомянутые возможности интеллектуальной маршрутизации для моделей серии Gemini. При вызове через OpenAI-совместимый интерфейс платформа автоматически обрабатывает повторные попытки при ошибке 503 и балансировку нагрузки между несколькими ключами на бэкенде, избавляя разработчика от необходимости самостоятельно реализовывать сложную логику отказоустойчивости.
Минимальный пример кода для решения с платформой-прокси API
import openai
# Используем сервис-прокси APIYI, обработка 503 ошибок выполняется платформой
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Вот так просто, не нужно самостоятельно обрабатывать 503 ошибки
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Полный процесс устранения ошибок Gemini API
При возникновении ошибок Gemini API следуйте этому процессу для быстрого определения проблемы:
Шаг первый: Проверьте код ошибки
| Код ошибки | Сообщение об ошибке | Тип | Немедленные действия |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | Недостаточная вычислительная мощность сервера | Подождать повторной попытки или сменить модель |
| 429 | "resource exhausted" | Индивидуальное ограничение скорости | Снизить частоту запросов или обновить тариф |
| 400 | "invalid request" | Ошибка параметров запроса | Проверить формат и параметры запроса |
| 401 | "unauthorized" | Ошибка аутентификации | Проверить API-ключ |
| 500 | "internal error" | Внутренняя ошибка сервера | Подождать повторной попытки |
Шаг второй: Различите 503 и 429
- Несколько API-ключей выдают ошибку → 503, это проблема сервера Google.
- Только ваш ключ выдает ошибку → 429, это проблема вашего личного лимита.
Шаг третий: Выберите соответствующее решение
- 503: Экспоненциальная задержка при повторных попытках → снижение версии модели → вызов модели в непиковое время.
- 429: Снизить частоту запросов → включить оплату и обновиться до Tier 1 (бесплатный уровень 5-15 RPM, Tier 1 — 150-300 RPM).
Часто задаваемые вопросы
В1: Почему я сталкиваюсь с ошибкой 503 High Demand, хотя я оплатил услугу?
Ошибка 503 никак не связана с тем, оплатили вы услугу или нет. 503 — это проблема нехватки вычислительных мощностей на серверах Google, и с ней сталкиваются как бесплатные, так и корпоративные пользователи. Это отличается от ошибки 429 (ограничение скорости запросов) — 429 действительно можно решить, обновив тарифный план, но 503 так не исправить. При возникновении 503 рекомендуется использовать экспоненциальную задержку при повторных попытках или переключиться на более стабильную версию модели. Вызов через платформу APIYI (apiyi.com) позволяет использовать балансировку нагрузки с несколькими API-ключами, что снижает частоту возникновения 503 ошибок.
В2: Когда исчезнут ошибки 503 в Gemini 3.1 Pro Preview?
Согласно историческому опыту, пик ошибок 503 после выпуска новой модели обычно длится 1-3 недели, и ситуация заметно улучшается по мере постепенного расширения мощностей Google. Gemini 3.0 Pro также переживал аналогичную волну 503 ошибок сразу после запуска, но сейчас он очень стабилен. В период ожидания рекомендуется реализовать стратегию понижения версии модели: при возникновении 503 автоматически откатываться к gemini-3.0-pro или gemini-2.5-flash.
В3: «high demand» и «model is overloaded» — это одна и та же ошибка?
По сути, это разные формулировки одной и той же проблемы. "This model is currently experiencing high demand" и "The model is overloaded" — это оба статуса 503, которые указывают на нехватку вычислительных мощностей на серверах Google. Первая формулировка чаще встречается в более новых версиях API, вторая — в ранних. Способ обработки абсолютно одинаков.
В4: Есть ли способ заранее узнать, будет ли Gemini API выдавать 503 ошибку?
Официальных предварительных предупреждений нет. Но вы можете следить за несколькими сигналами: (1) 1-2 недели после выпуска Google новой модели — это период повышенного риска; (2) в рабочее время Северной Америки (с ночи до утра по пекинскому времени) частота 503 ошибок выше; (3) на форуме сообщества discuss.ai.google.dev обычно есть оперативная обратная связь. Рекомендуется всегда иметь в коде логику повторных попыток и понижения версии, а не добавлять её в последний момент, когда проблема уже возникла. Платформа APIYI (apiyi.com) предоставляет мониторинг состояния доступности моделей, что может помочь вам заранее предвидеть проблемы.
В5: Должен ли я обрабатывать 503 и 429 ошибки одновременно в своём коде?
Обязательно. В производственной среде вы столкнётесь как с 503, так и с 429 ошибками, и хотя стратегии их обработки различаются, обе они одинаково важны. Для 503 используйте экспоненциальную задержку при повторных попытках + понижение версии модели, для 429 — снижение частоты запросов + управление очередью запросов. Код из «Решения четыре: Комбинированная стратегия» в этой статье обрабатывает обе эти ошибки и может быть напрямую использован в производственной среде.
Итоги
Суть ошибки 503 This model is currently experiencing high demand очень проста — вычислительных мощностей серверов Google временно не хватает. Особенно это касается новых моделей, таких как Gemini 3.1 Pro Preview, Nano Banana 2, которые почти неизбежно сталкиваются с этим на начальном этапе запуска.
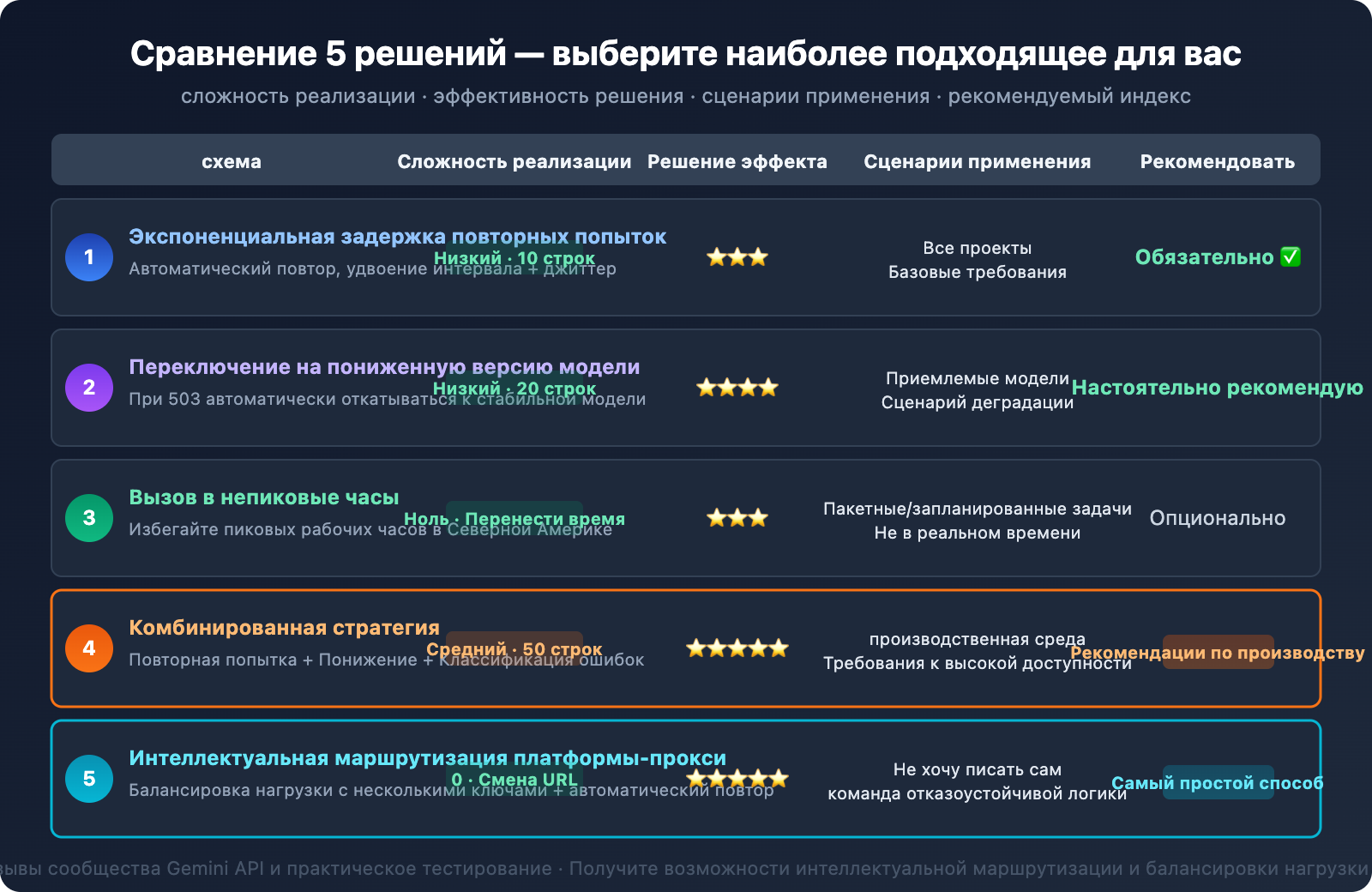
5 решений по приоритету:
- Экспоненциальная задержка при повторных попытках — самое базовое решение, которое должно быть в каждом проекте.
- Цепочка понижения версии модели — автоматическое переключение на более стабильную модель при 503 ошибке.
- Вызовы вне пиковых часов — некритичные по времени задачи планировать на периоды низкой нагрузки.
- Комбинированная стратегия — рекомендуется для производственной среды: повторные попытки + понижение версии + классификация ошибок.
- Интеллектуальная маршрутизация через платформу-прокси API — самый простой способ, платформа сама обрабатывает логику отказоустойчивости.
Независимо от выбранного решения, основной принцип таков: ошибка 503 — не ваша вина, но вы должны изящно её обрабатывать. Рекомендуем быстро интегрировать модели серии Gemini через APIYI (apiyi.com), чтобы воспользоваться встроенными возможностями интеллектуальной маршрутизации и повторных попыток.
Справочные материалы
-
Google AI Developers Forum — 503 Error Discussions
- Ссылка:
discuss.ai.google.dev - Описание: Обсуждения сообщества и официальные ответы по ошибке 503 Gemini API
- Ссылка:
-
Google Gemini API — Rate Limits Documentation
- Ссылка:
ai.google.dev/gemini-api/docs/rate-limits - Описание: Официальные правила ограничения скорости и описание квот для каждого уровня (Tier)
- Ссылка:
-
Google Gemini API — Troubleshooting Guide
- Ссылка:
ai.google.dev/gemini-api/docs/troubleshooting - Описание: Официальное руководство по устранению неполадок
- Ссылка:
📝 Автор: Команда APIYI | Для технической поддержки и подключения к API посетите apiyi.com