Примечание автора: Глубокий разбор 5 ключевых прорывов модели Qwen-Image-2.0, объединяющей генерацию и редактирование изображений. Технические особенности: облегченная архитектура 7B, нативное разрешение 2K, поддержка длинных промптов до 1000 токенов, а также руководство по подключению через API и практическому использованию.
10 февраля 2026 года команда Alibaba Tongyi представила Qwen-Image-2.0 — масштабное обновление, которое объединяет генерацию и редактирование изображений в рамках одной модели. Что особенно впечатляет: разработчикам удалось сократить количество параметров с 20B в предыдущем поколении до 7B, при этом добившись комплексного роста производительности. APIYI, будучи авторизованным партнером Alibaba Cloud, уже работает над интеграцией модели, так что скоро она станет доступна пользователям по выгодным ценам.
Ключевая ценность: Из этого разбора вы узнаете о 5 главных технологических прорывах Qwen-Image-2.0, ее реальных отличиях от конкурентов и способах быстрого подключения через API.
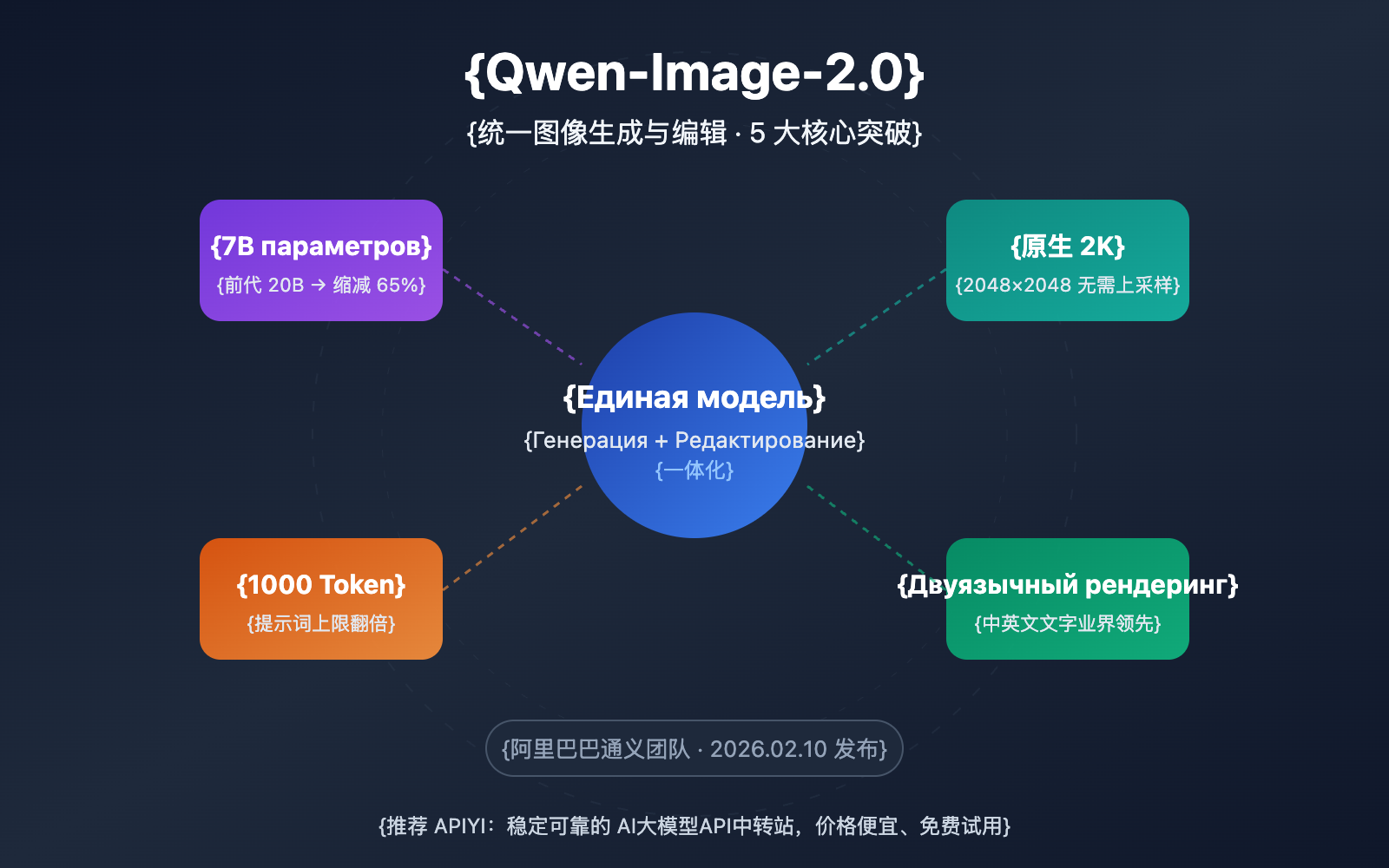
Краткий обзор ключевых особенностей Qwen-Image-2.0
| Особенность | Описание | Ценность |
|---|---|---|
| Единая генерация и правка | Создание по тексту и редактирование объединены в одной модели 7B | Не нужно загружать две разные модели, затраты на развертывание ниже |
| Сокращение параметров на 65% | С 20B в прошлом поколении до 7B (диффузионный декодер) | Ускорение вывода и значительное снижение требований к видеопамяти |
| Нативное разрешение 2K | Поддержка вывода в разрешении до 2048×2048 | Высокая четкость деталей без необходимости апскейлинга |
| Промпты до 1000 токенов | Лимит промптов увеличен вдвое (ранее было около 500) | Поддержка сложных описаний сцен и точного контроля |
| Двуязычный рендеринг текста | Лидирующее качество генерации текста на китайском и английском | Отличные результаты для постеров, инфографики и других текстовых сцен |
Технический разбор Qwen-Image-2.0
Qwen-Image-2.0 использует совершенно новую двухкомпонентную архитектуру: визуально-языковая модель Qwen3-VL (8B) выступает в роли энкодера условий, а MMDiT (мультимодальный диффузионный трансформер, 7B) — в роли диффузионного декодера. Такая конструкция позволяет модели глубоко понимать семантику как текста, так и изображений, а затем генерировать качественный контент через процесс диффузии.
Главное отличие от предыдущей версии Qwen-Image-2512 заключается в единой стратегии обучения: генерация по тексту (T2I) и редактирование изображений (I2I/TI2I) теперь объединены в одном процессе прямого прохода. Это означает, что одна модель справляется с задачами, для которых раньше требовались две независимые модели (Qwen-Image для генерации и Qwen-Image-Edit для правки), что существенно упрощает архитектуру и снижает расходы на инфраструктуру.
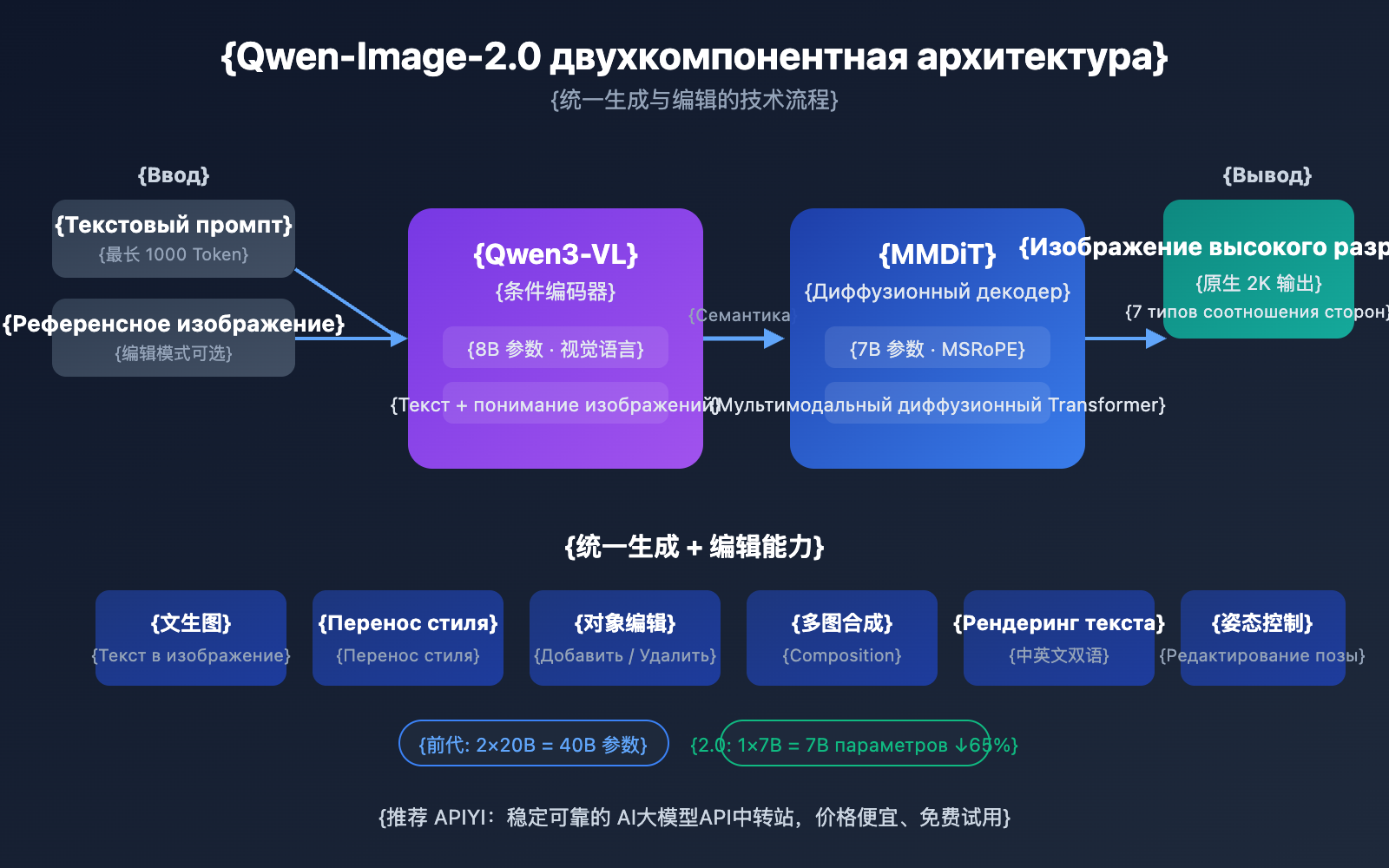
5 ключевых прорывов Qwen-Image-2.0
Прорыв 1: Унифицированная архитектура генерации и редактирования
Это самое знаковое нововведение в Qwen-Image-2.0. В предыдущем поколении приходилось отдельно поддерживать модель для генерации (text-to-image) и модель для редактирования. Версия 2.0 объединяет их в одну:
| Возможность | Предыдущее решение | Qwen-Image-2.0 |
|---|---|---|
| Текст в изображение | Qwen-Image-2512 (20B) | Унифицированная модель (7B) |
| Редактирование изображений | Qwen-Image-Edit-2511 (20B) | Унифицированная модель (7B) |
| Перенос стиля | Отдельная обработка в модели редактирования | Прямая поддержка в унифицированной модели |
| Композиция из нескольких фото | Отдельная обработка в модели редактирования | Прямая поддержка в унифицированной модели |
| Общий объем видеопамяти | Требуется загрузка двух моделей по 20B | Нужна всего одна модель 7B |
На практике это означает, что вы можете сначала создать изображение с помощью текста, а затем сразу же применить к нему перенос стиля, добавить или удалить объекты или изменить позу — и все это без переключения между моделями.
Прорыв 2: Превосходство производительности при 7 млрд параметров
Размер модели уменьшился с 20B до 7B (диффузионный декодер) — это сокращение параметров на 65%, но качество изображений не только не упало, а даже выросло. Секрет кроется в глубоком семантическом понимании энкодера Qwen3-VL. Эта визуально-языковая модель с 8B параметров берет на себя основную работу на этапе «понимания запроса», позволяя диффузионному декодеру максимально эффективно сосредоточиться на «генерации изображения».
Для разработчиков это означает:
- Ускорение инференса: вызов API занимает около 5–8 секунд на одно изображение.
- Снижение требований к VRAM: ожидается, что модель сможет работать на 24 ГБ видеопамяти (предыдущему поколению требовалось более 48 ГБ).
- Экономия на развертывании: возможность запуска на одной видеокарте потребительского класса.
Прорыв 3: Нативное разрешение 2K
Qwen-Image-2.0 нативно поддерживает вывод в разрешении 2048×2048 без необходимости использования дополнительных шагов апскейлинга (super-resolution). Поддерживается 7 стандартных соотношений сторон:
| Соотношение сторон | Разрешение | Рекомендуемые сценарии |
|---|---|---|
| 16:9 | 1664×928 | Обложки для видео, иллюстрации в блогах (по умолчанию) |
| 1:1 | 1328×1328 | Аватары в соцсетях, главные фото товаров |
| 9:16 | 928×1664 | Обои для смартфонов, обложки для коротких видео |
| 4:3 | 1472×1104 | Традиционные горизонтальные презентации |
| 3:4 | 1104×1472 | Традиционные вертикальные форматы |
| 3:2 | 1584×1056 | Горизонтальные фото в художественном стиле |
| 2:3 | 1056×1584 | Вертикальные фото в художественном стиле |
Прорыв 4: Длинные промпты до 1000 токенов
Лимит на промпт увеличился вдвое — с 500 до 1000 токенов. Это дает пространство для описания по-настоящему сложных сцен. В ходе тестов это оказалось особенно полезным для:
- Профессиональной инфографики: точный контроль расположения элементов, текстового контента и цветовой палитры.
- Сцен с множеством объектов: одновременное описание пространственных отношений и деталей взаимодействия нескольких персонажей.
- Смешения стилей: детальное описание желаемого художественного стиля и требований к текстуре.
Прорыв 5: Лидерство в рендеринге двуязычного текста
Способность Qwen-Image-2.0 генерировать текст внутри изображений является одной из лучших в индустрии, особенно это касается китайских иероглифов — поддерживаются различные стили, такие как Кайшу (уставное письмо), Шоуцзинь (стиль «стройного золота»), Сяочжуань (малая печать) и другие. Это дает явное преимущество в таких задачах, как:
- Дизайн маркетинговых постеров и рекламных баннеров.
- Технические диаграммы с текстовыми пояснениями.
- Графический контент для социальных сетей.
- Создание визуальных материалов для брендинга.
🎯 Практический совет: На данный момент Qwen-Image-2.0 находится в стадии закрытого тестирования API. Сервис APIYI (apiyi.com) активно работает над интеграцией. Скоро модель будет доступна там по цене на 20% ниже официальной, с поддержкой унифицированного вызова в формате, совместимом с OpenAI. Следите за обновлениями.
Быстрый старт с Qwen-Image-2.0
Простейший пример
Ниже приведен базовый способ генерации изображения через API Qwen-Image-2.0 (на основе формата DashScope API):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "Сиба-ину в солнцезащитных очках серфит на пляже, солнечный день, стиль HD-фотографии"
}]
)
print(response.choices[0].message.content)
Посмотреть пример вызова через нативный API DashScope
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "Современный минималистичный рабочий стол, на столе ноутбук и комнатное растение, мягкий естественный свет"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"URL изображения: {image_url}")
# Примечание: URL действителен 24 часа, пожалуйста, скачайте и сохраните его вовремя
Совет: APIYI (apiyi.com) внедряет поддержку Qwen-Image-2.0. После запуска вы сможете использовать формат, совместимый с OpenAI, и с помощью одного API-ключа сравнивать результаты работы GPT Image 1.5, Gemini 3 Pro Image, FLUX.2 и других моделей генерации изображений.
Сравнение Qwen-Image-2.0 с конкурентами

| Параметр | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| Разработчик | Alibaba | OpenAI | Black Forest Labs | |
| Генерация + Редактирование | ✅ | ✅ | ✅ | ❌ |
| Макс. разрешение | 2K | 2K+ | 2K | 2K |
| Рендеринг кит. текста | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| Скорость инференса | 5-8 сек | 10-15 сек | 5-10 сек | 10-20 сек |
| Open-source экосистема | Пред. поколение открыто | Закрытый код | Закрытый код | Частично открыт |
| Справочная цена API | Скидка более 20% (APIYI) | $0.04-0.08 / изобр. | Оплата за токены | $0.04 / изобр. |
Уникальные преимущества Qwen-Image-2.0:
- Лучший для работы с китайским языком: Возможности двуязычного рендеринга текста являются лидирующими в индустрии. Китайские постеры и инфографика выглядят значительно лучше, чем у конкурентов.
- Самая легкая архитектура: Параметры 7B обеспечивают качество на уровне GPT Image 1.5 при более низких затратах на инференс.
- Потенциал открытого исходного кода: Вся предыдущая серия была выпущена под лицензией Apache-2.0, поэтому ожидается открытие исходного кода и для версии 2.0.
- Богатая экосистема: Более 2380 лайков на HuggingFace, более 484 адаптеров LoRA — сообщество очень активно.
Примечание к сравнению: Вышеуказанные данные основаны на открытой технической документации и рейтингах AI Arena. Рекомендуем протестировать модели в ваших реальных сценариях через платформу APIYI (apiyi.com), чтобы сравнить их производительность.
Рекомендуемые сценарии использования Qwen-Image-2.0
Модель отлично подходит для следующих задач:
- Карточки товаров для e-commerce: Единая модель берет на себя и генерацию самого товара, и замену фона, что серьезно упрощает воркфлоу. Идеально для дизайнеров и операторов маркетплейсов.
- Маркетинговые материалы: Постеры, иллюстрации для соцсетей, рекламные креативы. Мощный рендеринг текста — это ключевое конкурентное преимущество. Подходит для отделов маркетинга.
- Креативный дизайн: Поддержка множества стилей — от реализма и аниме до акварели и графики. Длинные промпты до 1000 токенов позволяют ювелирно контролировать творческое направление. Находка для дизайнеров и создателей контента.
- Технические диаграммы и графика: Слайды для презентаций, инфографика, блок-схемы и другой профессиональный контент с попиксельно точной версткой. Подходит для команд технической документации.
🎯 Совет по выбору: Если ваш бизнес завязан на генерации изображений с текстовыми элементами (особенно на китайском языке), Qwen-Image-2.0 — это сейчас самый перспективный вариант. Мы рекомендуем провести сравнительные тесты на платформе APIYI (apiyi.com), чтобы найти решение, которое лучше всего ляжет в ваши бизнес-процессы.
Эволюция версий и стоимость Qwen-Image-2.0
Хронология развития
Серия Qwen-Image с момента выхода первой версии в августе 2025 года обновляется очень бодро:
| Версия | Дата | Ключевые изменения |
|---|---|---|
| Qwen-Image v1 | 2025.08 | Дебют 20B MMDiT, открытый код (Apache-2.0) |
| Qwen-Image-Edit | 2025.08 | Добавлена специальная модель для редактирования |
| Qwen-Image-2512 | 2025.12 | Улучшены реалистичные текстуры и рендеринг текста |
| Qwen-Image-2.0 | 2026.02 | Единая архитектура, легковесная 7B, нативное разрешение 2K |
Справочные цены
| Канал | Модель | Ориентировочная цена |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | ¥0.50 / фото |
| Alibaba Cloud DashScope | qwen-image-plus | ¥0.20 / фото |
| Replicate | Qwen Image | $0.030 / фото |
| Fal.ai | Qwen Image Edit | $0.021 / фото |
| APIYI (скоро) | Qwen-Image-2.0 | Скидка более 20% от официальной цены |
💡 Официальные цены на релизную версию Qwen-Image-2.0 еще уточняются. Платформа APIYI (apiyi.com) уже активно работает над интеграцией и предложит доступ со скидкой более 20% от тарифов правообладателя. Регистрируйтесь, чтобы получить бесплатные тестовые токены. Следите за обновлениями!
Часто задаваемые вопросы
Q1: В чем разница между Qwen-Image-2.0 и Qwen-Image-2512?
Самое большое отличие в том, что версия 2.0 объединяет генерацию и редактирование в одной модели на 7B параметров. Предыдущая версия 2512 была чисто генеративной моделью на 20B, и для редактирования изображений требовалось отдельно загружать Qwen-Image-Edit. Версия 2.0 также поддерживает нативное разрешение 2K и длинные промпты до 1000 токенов, а качество изображений и рендеринг текста стали заметно лучше.
Q2: Можно ли сейчас использовать Qwen-Image-2.0 через API?
На данный момент API находится на стадии закрытого тестирования по приглашениям, но модель можно бесплатно попробовать онлайн на chat.qwen.ai. Сервис APIYI (apiyi.com) уже работает над интеграцией — после запуска там предложат цены на 20% ниже официальных, поддержку формата OpenAI и возможность сравнивать несколько моделей генерации через один ключ.
Q3: Подходит ли Qwen-Image-2.0 для локального развертывания?
Веса Qwen-Image-2.0 пока не выложены в открытый доступ. Однако, учитывая, что вся предыдущая серия была выпущена под лицензией Apache-2.0, сообщество ожидает, что и версия 2.0 станет open-source. Объем в 7B параметров означает, что модель, скорее всего, можно будет запустить на пользовательских GPU (с 24 ГБ видеопамяти). Пока ждем открытия кода, рекомендуем протестировать возможности через API на apiyi.com.
Итоги
Ключевые особенности Qwen-Image-2.0:
- Единая архитектура — главная фишка: Одна модель на 7B справляется и с генерацией, и с редактированием, тогда как раньше требовалось две модели по 20B.
- Легкость без потери качества: Количество параметров сократилось на 65%, но качество картинки и набор функций заметно выросли.
- Незаменима для работы с китайским языком: Двуязычный рендеринг текста и поддержка различных шрифтов делают её лучшим выбором для создания контента с иероглифами.
- Доступ по API скоро откроется: Сейчас идет этап тестирования, полноценный релиз уже не за горами.
Qwen-Image-2.0 — это важный прорыв среди китайских моделей генерации изображений. Для команд, которым нужен качественный визуальный контент с поддержкой китайского языка, это сейчас одна из самых перспективных моделей.
Рекомендуем следить за обновлениями на APIYI (apiyi.com), чтобы получить доступ по выгодной цене (на 20% дешевле официальной). Платформа предоставляет бесплатные лимиты и единый интерфейс для разных моделей, что очень удобно для быстрого сравнения результатов.
📚 Справочные материалы
-
Официальный блог Qwen: Анонс релиза Qwen-Image-2.0
- Ссылка:
qwen.ai/blog?id=qwen-image-2.0 - Описание: Официальный технический разбор и обзор функциональных возможностей.
- Ссылка:
-
Репозиторий GitHub: Главная страница проекта Qwen-Image
- Ссылка:
github.com/QwenLM/Qwen-Image - Описание: Исходный код, техническая документация и руководства по использованию.
- Ссылка:
-
Рейтинг AI Arena: Топ моделей для генерации и редактирования изображений
- Ссылка:
arena.ai/leaderboard/text-to-image - Описание: Независимый сторонний рейтинг, данные в котором обновляются в реальном времени.
- Ссылка:
-
Документация API Alibaba Cloud: DashScope Image Generation API
- Ссылка:
help.aliyun.com/zh/model-studio/qwen-image-api - Описание: Официальное руководство по подключению к API и описание параметров.
- Ссылка:
Автор: Техническая команда
Обсуждение: Будем рады вашим вопросам и мнениям в комментариях. Еще больше полезных материалов вы найдете в техническом сообществе APIYI на сайте apiyi.com.