Nota do autor: preparei um guia prático para você configurar o gpt-image-2 no Chatbox via endpoint personalizado e uma análise profunda sobre por que o Chatbox não consegue realizar conversas contínuas para edição de imagens como a versão web do ChatGPT — tudo se resume às diferenças de arquitetura entre os três endpoints: images/generations, chat/completions e a API de Respostas (Responses API).
Muitos usuários configuram a chave API da OpenAI no cliente Chatbox e, ao tentar usar o gpt-image-2 para gerar imagens, recebem erros ou saídas ilegíveis. Este artigo traz duas respostas: primeiro, a forma correta de conectar o gpt-image-2 ao Chatbox (configurando o endpoint personalizado como https://api.apiyi.com/v1/images/generations); segundo, e mais importante, por que o Chatbox não consegue "gerar uma imagem e depois editá-la via conversa" como na interface web do ChatGPT.
Isso não é um bug do Chatbox, mas sim o fato de que a OpenAI separa a geração de imagens, a conclusão de chat e a edição multimodal em três endpoints de API completamente distintos. O caminho padrão que o Chatbox utiliza não suporta a edição contínua de imagens.
Valor central: ao terminar este artigo, você entenderá perfeitamente os limites e as diferenças de capacidade dos três endpoints principais da OpenAI, saberá em quais cenários o Chatbox é suficiente, quando você precisará migrar para a Responses API e como usar o serviço proxy de API da APIYI para realizar invocações estáveis de qualquer endpoint no Brasil.
Qual é a forma correta de conectar o gpt-image-2 ao Chatbox
Vamos direto ao ponto — se você quer que o Chatbox funcione com o gpt-image-2 imediatamente, siga os passos abaixo e resolva em 5 minutos.
Configuração principal para conectar o gpt-image-2 ao Chatbox
O Chatbox chama a API por padrão no formato de "conclusão de chat" (ou seja, o endpoint /v1/chat/completions), mas o gpt-image-2 não é um modelo de chat, ele é um modelo puro de geração de imagens, e o endpoint de chamada é o /v1/images/generations. Portanto, você deve usar a função de "Endpoint Personalizado" do Chatbox para sobrescrever o endereço padrão.
Passos completos de configuração:
| Passo | Ação | Parâmetro Chave |
|---|---|---|
| 1 | Abrir Configurações do Chatbox → Provedor de Modelo → Adicionar provedor personalizado | Escolha o modo compatível com OpenAI API |
| 2 | API Host | https://api.apiyi.com |
| 3 | Caminho da API (sobrescrita chave) | /v1/images/generations |
| 4 | Chave API | Token Bearer obtido no painel da APIYI |
| 5 | Campo Modelo | gpt-image-2 |
| 6 | Tempo limite (Timeout) | Defina ≥ 360 segundos |
Exemplo mínimo de chamada do gpt-image-2 no Chatbox
Abaixo está o exemplo de chamada curl recomendado oficialmente. Você pode usá-lo primeiro para verificar se sua chave API está funcionando:
curl --request POST \
--url https://api.apiyi.com/v1/images/generations \
--header 'Authorization: Bearer sk-your-apiyi-key' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-image-2",
"prompt": "Formato de cinema 16:9, farol antigo na praia ao entardecer"
}'
Após validar este curl, vá ao Chatbox e altere o endpoint para /v1/images/generations e ele funcionará.
🎯 Dica de configuração: Ao configurar o endpoint personalizado do Chatbox pela primeira vez, recomendo validar a chave API e o caminho do endpoint com o curl. Sugerimos usar a plataforma APIYI (apiyi.com) para obter créditos de teste; o valor gratuito é suficiente para concluir toda a verificação da configuração.
Erros comuns de configuração ao conectar o gpt-image-2 ao Chatbox
Reuni as 5 armadilhas em que os usuários mais caem:
| Fenômeno de erro | Causa raiz | Solução |
|---|---|---|
Retorna model not found |
Endpoint usado foi /v1/chat/completions |
Altere para /v1/images/generations |
Retorna invalid prompt format |
Usou o formato de mensagens do chat | Use o campo prompt (string) |
| Timeout de requisição após 60s | Timeout padrão muito curto | Ajuste para ≥ 360s (necessário para alta qualidade) |
| Imagem não aparece | Chatbox não analisa b64_json | Faça a resposta retornar no formato url |
| Erro no prompt em chinês | Problema de codificação | Confirme Content-Type: application/json; charset=utf-8 |
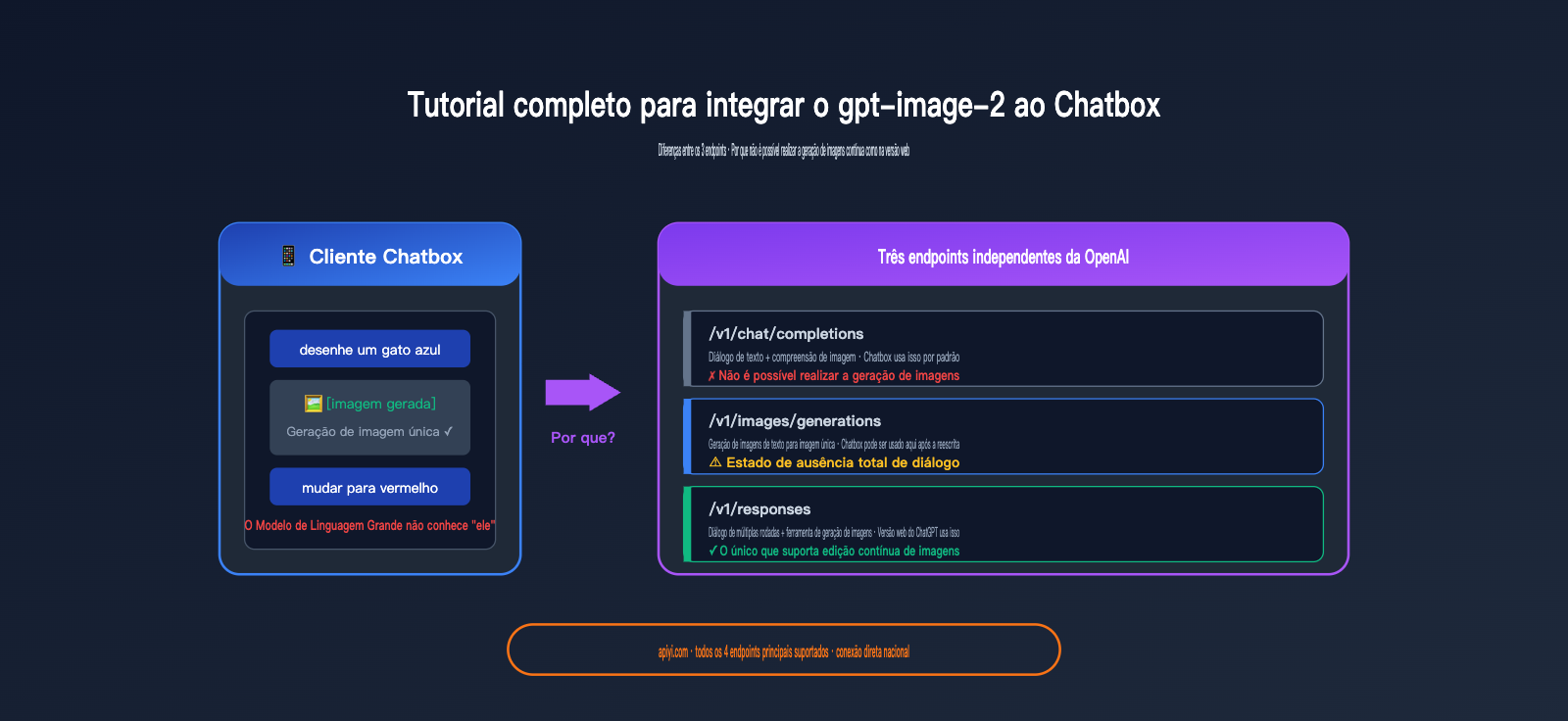
Por que não consigo modificar imagens continuamente ao conectar o gpt-image-2 ao Chatbox?
Este é o ponto técnico central deste artigo. Muitos usuários, após configurarem tudo, perguntam: "Por que gero uma imagem no Chatbox e, quando digo 'mude o céu para azul', o modelo não entende nada? Enquanto na versão web do ChatGPT posso fazer modificações contínuas infinitas?"
A resposta não é um bug do Chatbox, mas sim que o endpoint em si não oferece suporte para isso.
Limitações da arquitetura de endpoint do Chatbox com gpt-image-2
Para explicar isso claramente, precisamos entender os três endpoints completamente independentes fornecidos oficialmente pela OpenAI:
| Endpoint | Caminho | Objetivo do Design | Suporta geração de imagem? | Possui estado de conversa? |
|---|---|---|---|---|
| Chat Completions | /v1/chat/completions |
Completar diálogos de texto | ❌ Apenas entrada de imagem | ❌ Gerenciado pelo cliente |
| Image Generations | /v1/images/generations |
Geração única (texto para imagem) | ✅ Apenas geração | ❌ Totalmente sem estado |
| Image Edits | /v1/images/edits |
Edição única (imagem para imagem) | ✅ Edição | ❌ Totalmente sem estado |
| Responses API | /v1/responses |
Diálogo multirrodada + chamada de ferramentas | ✅ Chamada de ferramentas | ✅ Gerenciado pelo servidor |
A verdade crucial:
- O Chatbox usa o
/v1/chat/completionspor padrão — este endpoint não suporta a geração de imagens. - Ao alterar para
/v1/images/generations, você consegue gerar imagens, mas este endpoint é totalmente sem estado — cada solicitação é isolada. - A versão web do ChatGPT utiliza o
/v1/responses— ele possui a ferramentaimage_generationintegrada + estado de conversa no servidor.

Por que a versão web do ChatGPT consegue modificar imagens continuamente?
O fluxo de trabalho por trás da versão web do ChatGPT é o seguinte:
- Você digita "desenhe um gato azul".
- O ChatGPT chama o endpoint
/v1/responses, e o modelo decide invocar a ferramentaimage_generation. - A ferramenta retorna o ID da imagem (por exemplo,
ig_abc123) e o registra no estado do servidor da sessão atual. - Você diz em seguida: "troque-o por vermelho".
- O ChatGPT chama o
/v1/responsesnovamente, passando oprevious_response_id. - O modelo, com base no contexto, identifica que "o" (ou "ele") se refere à imagem anterior e invoca a ação
editda ferramentaimage_generation. - A ferramenta edita a imagem com base na anterior e retorna uma nova imagem.
O segredo de todo o processo é o previous_response_id + estado de conversa no servidor + ferramenta image_generation integrada — capacidades que o endpoint /v1/images/generations não possui.
As limitações da arquitetura atual do Chatbox
O Chatbox é um cliente no estilo Chat Completions — seu modelo de dados central é o "array de mensagens" (mensagens multirrodada do tipo system / user / assistant). Seu mecanismo de trabalho é:
- Adicionar cada mensagem do usuário ao array de mensagens.
- Chamar um endpoint de estilo chat (por padrão
/v1/chat/completions). - Adicionar a resposta ao array de mensagens.
- Repetir.
Quando você altera o endpoint para /v1/images/generations, o Chatbox, na verdade, apenas troca o caminho da solicitação — mas o array de mensagens continua sendo enviado no formato de chat, e o endpoint aceita apenas um comando único, tornando impossível a transferência do estado da conversa.
💡 Interpretação técnica: O design central do Chatbox pressupõe que "o endpoint é do estilo chat", enquanto a OpenAI projetou a geração e edição de imagens como endpoints de recursos RESTful independentes; essa é uma incompatibilidade ao nível de arquitetura. Recomendamos testar a geração única via
/v1/images/generationsna plataforma APIYI (apiyi.com) e, após validar o resultado, planejar se é necessário migrar para a Responses API.
Limites de capacidade e alternativas para o Chatbox com gpt-image-2
Agora que conhecemos as limitações, podemos listar claramente o que é possível e o que não é possível fazer.
O que o Chatbox + gpt-image-2 pode fazer
| Cenário | Suportado | Observação |
|---|---|---|
| Gerar uma única imagem com um comando | ✅ | Uso padrão |
| Comando em chinês ou inglês | ✅ | Suporte nativo do gpt-image-2 |
| Definir tamanho/proporção | ✅ | Via parâmetro size |
| Definir qualidade (standard/high) | ✅ | Via parâmetro quality |
| Saída em URL ou base64 | ✅ | Via parâmetro response_format |
O que o Chatbox + gpt-image-2 não pode fazer
| Cenário | Suportado | Alternativa |
|---|---|---|
| Pedir para "mudar a cor para vermelho" após gerar | ❌ | Mudar para Responses API |
| Ajustar detalhes da imagem em múltiplas iterações | ❌ | Mudar para Responses API |
| Enviar imagem + comando para edição local | ❌ Chatbox não suporta | Mudar para /v1/images/edits ou Responses API |
| Fundir várias imagens de referência | ❌ Chatbox não suporta | Mudar para Responses API |
| Histórico de conversas gravado no servidor | ❌ | Mudar para Responses API |
Código mínimo para implementar geração contínua de imagens com a Responses API
Se você precisa de "edição de imagem conversacional", deve abandonar o cliente Chatbox e escrever seu próprio código para chamar o endpoint /v1/responses:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
# Primeira rodada: gerar imagem inicial
resp1 = client.responses.create(
model="gpt-5", # A Responses API requer a série gpt-5
input="Desenhe um gato azul caminhando sob o luar, estilo realista",
tools=[{"type": "image_generation"}]
)
response_id_1 = resp1.id
print("Primeira imagem:", resp1.output[-1])
# Segunda rodada: modificar com base na rodada anterior (o segredo é o previous_response_id)
resp2 = client.responses.create(
model="gpt-5",
previous_response_id=response_id_1, # Conecta o estado da conversa
input="Mude a cor dele para laranja e troque o fundo por um nascer do sol",
tools=[{"type": "image_generation"}]
)
print("Após a modificação:", resp2.output[-1])
Observe alguns pontos cruciais:
- Você deve usar o
gpt-5ou um modelo mais recente (o gpt-image-2 não pode ser chamado diretamente como um modelo de conversa). - Você deve passar
tools=[{"type": "image_generation"}]para habilitar as ferramentas. - Você deve usar
previous_response_idpara conectar o histórico da conversa, caso contrário, o modelo não saberá a que "ele" se refere.
🚀 Dica de integração: Ao usar a Responses API para geração contínua de imagens, defina a
base_urlcomohttps://api.apiyi.com/v1. Ela é totalmente compatível com os campos oficiais da OpenAI, bastando alterar uma linha debase_urlno seu código SDK da OpenAI para alternar. Recomendamos a integração via APIYI (apiyi.com) para uma conexão estável no Brasil.
Guia prático de configuração: integrando o gpt-image-2 ao Chatbox
Depois de toda a base teórica, aqui está um guia completo "do zero" para você colocar a mão na massa.
Passo 1: Obter a chave API na plataforma APIYI
- Acesse o painel da APIYI em
api.apiyi.com. - Após criar sua conta, vá para a página "Tokens de API".
- Crie um novo Token (recomendamos usar um token exclusivo para cada projeto).
- Copie o Bearer Token completo (que começa com
sk-).
Passo 2: Configurar o provedor personalizado no Chatbox
No Chatbox, siga estes passos:
- Abra "Configurações" → "Provedor de modelo".
- Clique em "Adicionar" → selecione "Provedor compatível com OpenAI personalizado".
- Preencha os campos abaixo:
Nome: APIYI - Geração de Imagens
API Host: https://api.apiyi.com
API Path: /v1/images/generations # Crucial! Deve ser alterado
API Key: sk-sua-chave-apiyi
Modelo padrão: gpt-image-2
- Configurações avançadas:
- Tempo limite da solicitação: 600 segundos
- Tentativas de repetição: 2
- Codificação de caracteres: UTF-8
Passo 3: Enviar um comando de teste
No campo de conversa do Chatbox, digite:
Formato de filme 16:9, farol antigo à beira-mar ao pôr do sol,
tons quentes suaves, névoa sobre o mar, resolução 2K
Se a configuração estiver correta, você deverá receber a imagem gerada em 1 a 3 minutos.
Passo 4: Solução de problemas rápidos
| Problema | O que verificar |
|---|---|
| Não retorna nada | Verifique se a chave API está completa e se possui permissão de geração de imagens |
| Erro 401 | Chave API incorreta ou expirada, obtenha uma nova |
| Erro 404 | Erro de digitação no API Path, confirme se é /v1/images/generations |
| Erro 429 | Limite de taxa atingido, aguarde alguns minutos e tente novamente |
| Timeout | Tempo limite muito curto, aumente para 600 segundos |
💡 Dica avançada: Se você precisar integrar o gpt-image-2 em sua própria aplicação em vez de um cliente desktop, recomendamos usar o SDK oficial da OpenAI para chamar o endpoint
/v1/images/generations— é muito mais flexível que o Chatbox. Sugerimos conectar via APIYI (apiyi.com), bastando substituir obase_urlporhttps://api.apiyi.com/v1.
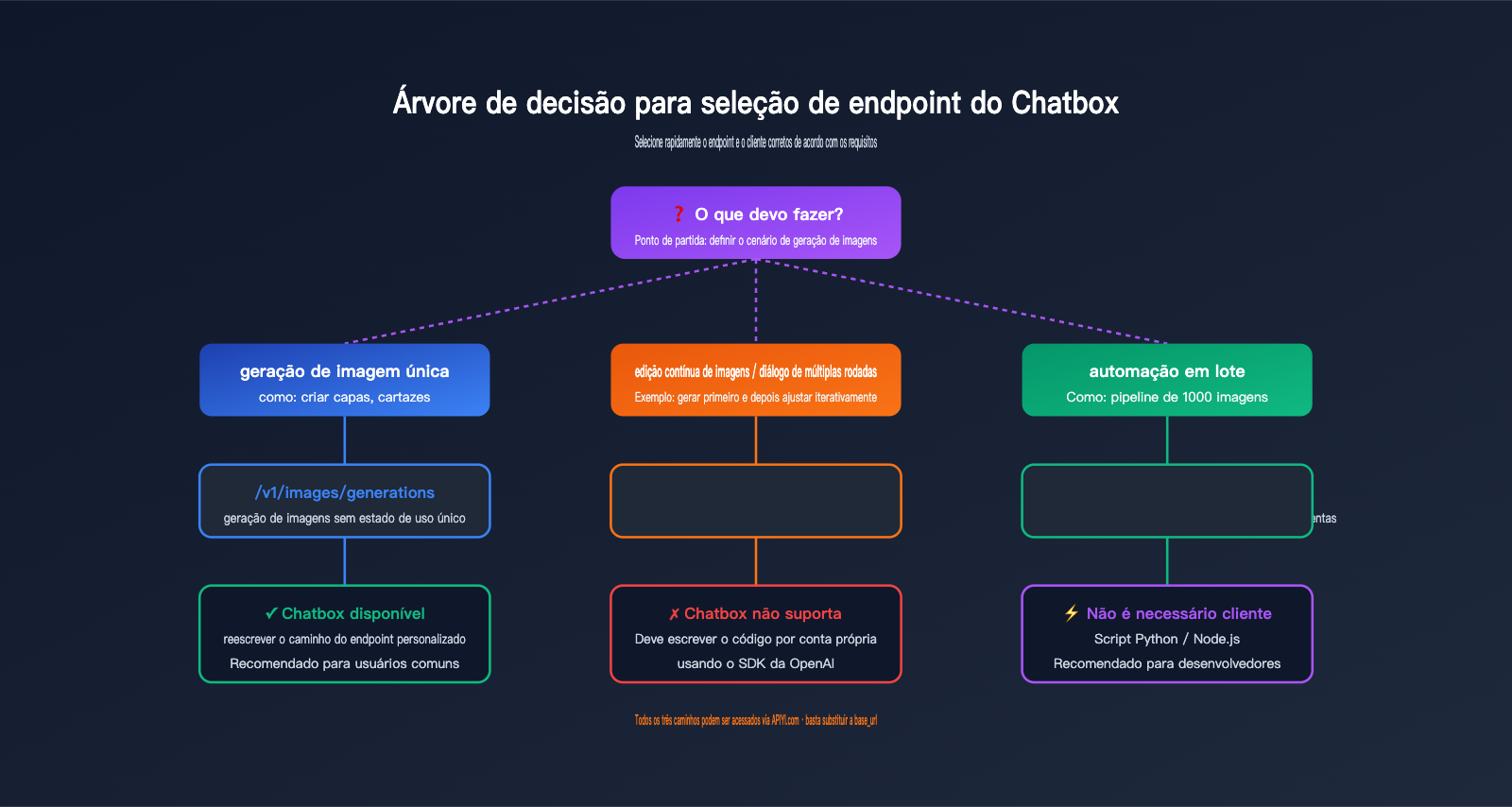
Guia de decisão para seleção de endpoints
Esta tabela de decisão ajudará você a identificar rapidamente qual endpoint usar em cada cenário:
| Sua necessidade | Endpoint recomendado | Cliente aplicável |
|---|---|---|
| Geração única de texto para imagem | /v1/images/generations |
Chatbox / curl / SDK |
| Edição única de imagem (com máscara) | /v1/images/edits |
curl / SDK (Chatbox não é ideal) |
| Modificação de imagem em conversa contínua | /v1/responses |
Código próprio (Chatbox não suporta) |
| Apenas conversa de texto | /v1/chat/completions |
Chatbox / qualquer cliente de chat |
| Conversa de texto + análise de imagem | /v1/chat/completions |
Suportado pelo Chatbox |

FAQ sobre a integração do Chatbox com o gpt-image-2
Pergunta 1: Por que o Chatbox não oferece suporte nativo para a geração contínua de imagens do gpt-image-2?
Isso não é uma falha de design do Chatbox, mas sim uma limitação inerente a clientes desse tipo. O modelo de dados do Chatbox é baseado em um array de messages (estilo chat), enquanto o modelo de dados da Responses API baseia-se em previous_response_id + estado de diálogo no servidor — são dois paradigmas fundamentalmente incompatíveis. Para o Chatbox suportar essa funcionalidade, seria necessário reescrever todo o motor de conversação.
Pergunta 2: Após configurar um endpoint personalizado no Chatbox, posso enviar uma imagem para o gpt-image-2 editar?
Teoricamente sim, mas na prática é bem complicado. O endpoint /v1/images/edits exige o upload de arquivos de imagem no formato multipart/form-data, enquanto a caixa de diálogo do Chatbox suporta apenas entrada de texto. Tentar forçar essa configuração resultará em um erro 415. Alternativa recomendada: utilize curl, Postman ou escreva seu próprio script para chamar o /v1/images/edits.
Pergunta 3: O serviço proxy de API da APIYI suporta a Responses API?
Totalmente. A APIYI é um canal de proxy oficial, com campos de solicitação/resposta 100% sincronizados com a OpenAI, incluindo os 4 endpoints principais: /v1/responses, /v1/images/generations, /v1/images/edits e /v1/chat/completions. Recomendamos utilizar a APIYI (apiyi.com) para chamar a Responses API e realizar a geração contínua de imagens, garantindo uma conexão estável no Brasil sem a necessidade de proxies.
Pergunta 4: Ao usar o Chatbox para chamar o gpt-image-2, qual é o tamanho máximo do campo de comando?
A OpenAI limita o campo de comando a 32.000 caracteres. No uso prático, recomendamos manter abaixo de 1.000 caracteres — comandos excessivamente longos podem dispersar a atenção do modelo, resultando em uma queda na qualidade da geração.
Pergunta 5: É possível configurar modelos de chat e modelos de geração de imagens simultaneamente no Chatbox?
Sim, o Chatbox permite configurar múltiplos "provedores personalizados". Sugerimos criar dois:
APIYI - Conversa→ endpoint/v1/chat/completions→ modelogpt-5/claude-sonnet-4-6, etc.APIYI - Geração de Imagem→ endpoint/v1/images/generations→ modelogpt-image-2
Basta alternar entre os provedores para mudar de modo.
Pergunta 6: Quando a chamada do gpt-image-2 pelo Chatbox falha, como saber se o problema é no Chatbox ou na API?
A maneira mais rápida é testar a API diretamente via curl — se o curl funcionar, o problema está na configuração do Chatbox; se o curl também falhar, o problema está na sua chave API ou na rede. Você pode copiar e usar o exemplo de curl fornecido no início deste artigo.
Pergunta 7: Qual a diferença entre usar a APIYI e a OpenAI oficial?
Os campos são exatamente os mesmos, já que a APIYI é um canal de proxy oficial. As principais diferenças são: conexão direta sem necessidade de proxy, suporte técnico especializado em português e faturamento transparente. Recomendamos que desenvolvedores brasileiros utilizem a APIYI (apiyi.com) para acessar o gpt-image-2 e evitar problemas de estabilidade de rede.
Pergunta 8: Quando devo abandonar o Chatbox e escrever meu próprio código usando a Responses API?
Existem três sinais claros:
- Você precisa de "edição de imagem conversacional" — gerar uma vez e ajustar várias vezes.
- Você precisa de uma saída mista de imagem + texto (explicar algo, gerar uma imagem, depois explicar mais e gerar outra).
- Você está desenvolvendo um produto, não apenas usando para fins pessoais, e precisa gerenciar o estado da conversa no servidor.
Se atender a qualquer um desses critérios, é hora de migrar para a Responses API.
Principais pontos sobre a integração do Chatbox com o gpt-image-2
- O Chatbox utiliza por padrão o
/v1/chat/completions— este endpoint não suporta geração de imagens; é necessário alterar para/v1/images/generations. /v1/images/generationsé um endpoint sem estado — cada solicitação é independente, impossibilitando "edições contínuas".- A capacidade de geração contínua do ChatGPT Web vem da Responses API — utiliza a ferramenta
image_generationintegrada + o estado de diálogoprevious_response_id. - A incapacidade do Chatbox de realizar geração contínua não é um bug — é uma diferença fundamental entre clientes de estilo chat e o paradigma da Responses API.
- Solução alternativa: quando precisar de geração contínua, escreva seu próprio código usando o SDK da OpenAI para chamar o
/v1/responses, utilizando modelos da série gpt-5. - Recomendação de uso: acesse via APIYI (apiyi.com), que suporta todos os 4 endpoints principais; basta substituir a
base_url. - Diagnóstico rápido: em caso de falha na configuração, valide primeiro com curl. Se o curl funcionar, o problema está no cliente, não na API.
Resumo
O problema de "configuração" do Chatbox ao acessar o gpt-image-2 é apenas superficial. O que realmente vale a pena os desenvolvedores entenderem é a arquitetura de três endpoints independentes da OpenAI — cada um projetado para cenários de uso distintos, com limites de capacidade completamente diferentes:
- Chat Completions: É o endpoint para "diálogo de texto + compreensão de imagem", não gera imagens.
- Images Generations / Edits: É o endpoint "sem estado" para "geração/edição única de imagem", simples e direto, mas não suporta iterações de várias rodadas.
- Responses API: É o endpoint para "diálogo de várias rodadas + chamada de ferramentas", o único caminho para implementar a "edição de imagem via chat".
Como o Chatbox é um cliente no estilo chat, ele só consegue se adaptar perfeitamente a um dos dois primeiros modos — suportando a geração única de imagens através da reescrita de endpoints personalizados. No entanto, para alcançar aquela "edição infinita de diálogo" que vemos na versão web do ChatGPT, é preciso abandonar as ferramentas de cliente e escrever seu próprio código para chamar a Responses API.
Depois de entender isso, a escolha do seu fluxo de trabalho ficará clara:
- Pequena escala, geração única, uso pessoal → Chatbox +
/v1/images/generations - Necessidade de edição contínua, integração em nível de produto → Responses API + código próprio
- Geração em lote, pipelines automatizados → SDK direto chamando
/v1/images/generations
✨ Dica final: Para desenvolvedores no Brasil ou que buscam estabilidade, independentemente do caminho escolhido, recomendamos o uso da plataforma APIYI (apiyi.com) — todos os 4 endpoints principais são suportados, com campos 100% consistentes com a API oficial da OpenAI, conexão estável e cobrança transparente por token. Novos usuários recebem créditos de teste gratuitos, suficientes para validar tanto a configuração do Chatbox quanto a Responses API.
Autor: Equipe APIYI
Última atualização: 02/05/2026