Nota do autor: Uma comparação neutra entre as capacidades de programação, qualidade de código, janela de contexto, preço e experiência do desenvolvedor do Claude Code e do GPT-5.4, para ajudar você a decidir se vale a pena mudar.
No dia do lançamento do GPT-5.4, surgiu um coro nas redes sociais: "Cancelem a assinatura do Claude Code!" O motivo parece convincente — 1M de contexto, liderança em várias frentes e o fim daquele jeito "robótico" de falar que finalmente foi mitigado.
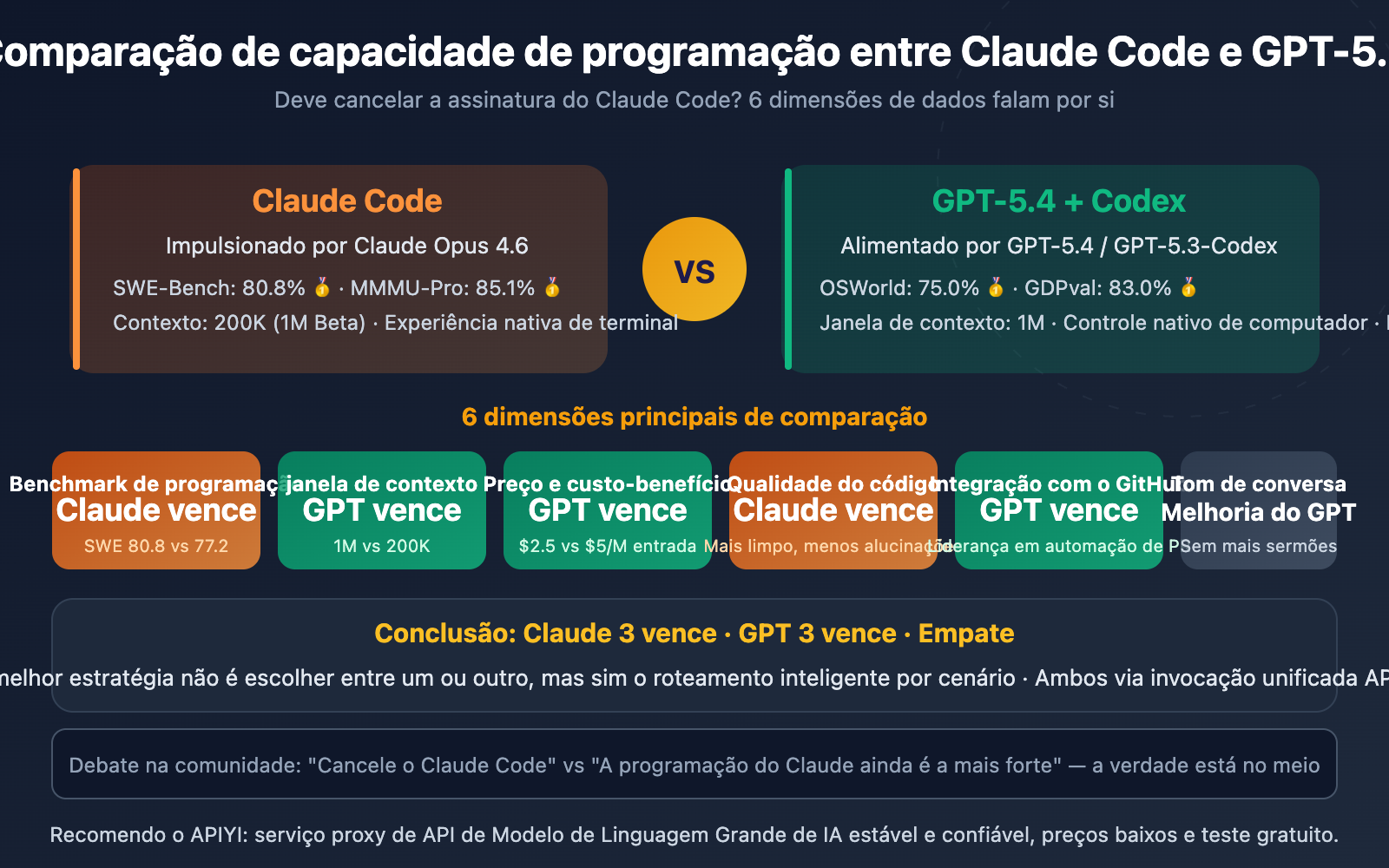
Mas a realidade não é tão simples. Dados de benchmark mostram que o Claude Opus 4.6 ainda lidera no benchmark de programação SWE-Bench com 80,8%, contra 77,2% do GPT-5.4. O feedback real da comunidade de desenvolvedores é, no mínimo, dividido.
Valor central: Este artigo compara objetivamente o Claude Code e o GPT-5.4 em 6 dimensões para ajudar você a decidir se deve mudar — ou se a escolha mais inteligente seria usar os dois.
Comparação de Dados Principais: Claude Code vs GPT-5.4
| Dimensão de Comparação | Claude Code (Opus 4.6) | GPT-5.4 / Codex | Vencedor |
|---|---|---|---|
| Programação SWE-Bench | 80,8% | 77,2% | Claude |
| Raciocínio Visual MMMU-Pro | 85,1% | 81,2% | Claude |
| Trabalho de Conhecimento GDPval | 78,0% | 83,0% | GPT |
| Controle de Computador OSWorld | 72,7% | 75,0% | GPT |
| Matemática FrontierMath | 27,2% | 47,6% | GPT |
| Terminal Terminal-Bench | 65,4% | 75,1% | GPT |
| Janela de Contexto | 200K (1M Beta) | 1.000K | GPT |
| Preço de Entrada da API | $5,00/M | $2,50/M | GPT |
| Preço de Saída da API | $25,00/M | $15,00/M | GPT |
| Limpeza do Código | Mais limpo e padronizado | Padrão | Claude |
| Refatoração e Depuração | Líder | Padrão | Claude |
| Automação de PR no GitHub | Regular | Integração profunda | GPT |
Placar: Claude 4 vitórias, GPT 8 vitórias — mas não tire conclusões precipitadas ainda. No cenário de programação, o peso do SWE-Bench, da qualidade do código e da capacidade de refatoração é muito maior do que o de trabalho de conhecimento ou controle de computador. Vamos analisar ponto a ponto.
Análise profunda da capacidade de programação: Claude Code vs GPT-5.4
Dimensão 1: Benchmarks de Programação — Claude Code na Liderança
No benchmark de programação mais acompanhado, o SWE-Bench Verified (que mede a capacidade de correção de Issues reais do GitHub):
| Modelo | SWE-Bench Verified | SWE-Bench Pro |
|---|---|---|
| Claude Opus 4.6 | 80.8% 🥇 | — |
| Gemini 3.1 Pro | 80.6% | — |
| GPT-5.4 | 77.2% | 57.7% |
O Claude Opus 4.6 lidera o GPT-5.4 por 3,6 pontos percentuais. Em cenários de correção de código em nível de produção — como compreensão de arquiteturas de múltiplos arquivos e rastreamento de cadeias de dependências complexas — o Claude demonstra uma compreensão superior da estrutura do código.
Por outro lado, o GPT-5.4 lidera significativamente no Terminal-Bench 2.0 (tarefas intensivas em operações de terminal) com 75,1% contra 65,4% do Claude. Se o seu fluxo de trabalho depende pesadamente de comandos no terminal, o GPT leva vantagem.
Dimensão 2: Qualidade do Código e Experiência do Desenvolvedor — Claude Code é mais Limpo
Vários feedbacks da comunidade de desenvolvedores apontam consistentemente para a mesma conclusão: o código gerado pelo Claude é mais limpo, segue melhores padrões e apresenta menos alucinações.
Pontos de destaque:
- Tarefas de refatoração: O Claude se sai melhor em refatorações complexas e depuração (debugging).
- Compreensão de arquitetura: Ao analisar grandes repositórios e arquiteturas em camadas, a cadeia de raciocínio do Claude é mais estável, com menos deriva de contexto.
- Velocidade de geração: A velocidade inicial de geração do Claude Code é superior (cerca de 1200 linhas em 5 minutos vs. cerca de 200 linhas em 10 minutos no Codex).
A força do GPT-5.4 reside na geração de documentação e escrita de códigos boilerplate — tarefas que não exigem uma compreensão profunda da arquitetura do projeto.
Dimensão 3: Janela de Contexto — GPT-5.4 Atropela
Este é o maior trunfo estrutural do GPT-5.4:
| Capacidade | Claude Code | GPT-5.4 |
|---|---|---|
| Contexto Padrão | 200K | 1,000K |
| Contexto Beta | 1M | — |
| Saída Máxima | 32K | 128K |
Uma janela de 1M de tokens significa que você pode carregar uma base de código inteira de nível de produção de uma só vez. No entanto, vale notar: solicitações que excedem 272K tokens são cobradas com o dobro do preço de entrada e 1,5 vez o preço de saída. Na prática, a maioria das tarefas de programação não ultrapassa os 200K de contexto.
🎯 Sugestão prática: A janela de contexto é a vantagem matadora do GPT-5.4, mas ela só brilha ao lidar com repositórios gigantescos. Em projetos de pequeno e médio porte, os 200K de contexto do Claude, combinados com sua melhor compreensão de arquitetura, costumam ser a melhor escolha. Ambos podem ser acessados de forma unificada via APIYI apiyi.com.
Claude Code vs GPT-5.4: Comparação de Preço e Ecossistema

Dimensão 4: Preço — GPT-5.4 tem Melhor Custo-Benefício
O GPT-5.4 apresenta preços de API consistentemente menores que o Claude Opus 4.6:
- Entrada: $2.50 vs $5.00/M (50% mais barato)
- Saída: $15.00 vs $25.00/M (40% mais barato)
- Entrada em Cache: $0.25 vs $0.50/M (50% mais barato)
No nível de assinatura, a comunidade de desenvolvedores relata que as restrições de uso do Claude são mais severas. O plano Codex de $20/mês oferece limites de uso mais generosos que o plano Claude Pro de $17/mês. Muitos usuários relatam que o Codex Pro quase nunca atinge o teto, enquanto usuários do Claude enfrentam limitação de taxa (rate limiting) frequente, mesmo em planos de valor mais alto.
Dimensão 5: Integração com GitHub — GPT Codex Lidera Claramente
Este é um diferencial frequentemente negligenciado, mas que impacta muito o dia a dia do desenvolvedor.
Segundo relatos: as revisões de PR do GitHub no Claude Code costumam "fornecer comentários prolixos, mas deixar passar bugs óbvios", enquanto o Codex consegue identificar "bugs realmente difíceis de encontrar", oferecendo comentários inline e fluxos de trabalho de correção acionáveis. O GitHub App do Codex também mantém a consistência de comportamento entre a CLI e a interface web.
Dimensão 6: Tom de Conversa — O problema do GPT-5.x "soar robótico" foi mitigado
Este é um ponto recorrente nas redes sociais. A série GPT-5 passou por uma evolução notável para deixar de soar artificial:
- GPT-5.0: Criticado por ser um "robô frio".
- GPT-5.1: Ganhou mais "calor" e naturalidade na conversação.
- GPT-5.3 Instant: Focado em ser "menos cringe", com redução de 26,8% nas alucinações.
- GPT-5.4: Herdou as melhorias de tom do 5.3, reforçando ao mesmo tempo suas capacidades técnicas.
Contudo, objetivamente, o Claude ainda é considerado superior na naturalidade do diálogo e na legibilidade das explicações de código. O GPT-5.4 diminuiu a distância, mas a lacuna ainda existe.
🎯 Otimização de custos: Independentemente do modelo escolhido, o acesso unificado via APIYI apiyi.com permite desfrutar de métodos de faturamento mais flexíveis. Os preços do GPT-5.4 são sincronizados com o site oficial ($2.50/$15.00), e recargas a partir de 100 dólares ganham 10% de bônus.
Claude Code vs GPT-5.4: Sugestões de Seleção de Cenários

Exemplo de Invocação de API Claude Code vs GPT-5.4
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Refatoração complexa → use Claude Opus 4.6 (maior qualidade de código)
refactor_result = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Refatore a arquitetura de injeção de dependência deste módulo"}]
)
# Análise de grandes repositórios → use GPT-5.4 (1M de contexto)
analysis_result = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analise as vulnerabilidades de segurança de todo o projeto"}]
)
Sugestão: Ao registrar uma conta no APIYI (apiyi.com), você pode invocar o Claude e o GPT-5.4 simultaneamente. Os preços do GPT-5.4 são sincronizados com o site oficial, e recargas a partir de 100 dólares ganham 10% de bônus. Alternar entre modelos por cenário exige apenas a mudança de um parâmetro.
Perguntas Frequentes
Q1: Devo cancelar a assinatura do Claude Code?
Depende do seu cenário principal de trabalho. Se sua necessidade central for refatoração de código complexo e correção de bugs em nível de produção, o Claude continua sendo a escolha mais forte (liderando com 80,8% no SWE-Bench). Se você precisa de janela de contexto ultra-longa, integração com GitHub e menor custo, o GPT-5.4 / Codex tem mais vantagens. A melhor estratégia não é escolher um ou outro, mas sim invocar ambos via API conforme o cenário.
Q2: A capacidade de programação do GPT-5.4 é realmente superior em tudo?
Não. O GPT-5.4 lidera em dimensões como GDPval (trabalho de conhecimento), OSWorld (controle de computador) e FrontierMath (matemática), mas no benchmark de programação mais importante, o SWE-Bench, o Claude Opus 4.6 mantém a liderança com 80,8% vs 77,2%. Em termos de qualidade de código, capacidade de refatoração e compreensão de arquitetura, a comunidade de desenvolvedores ainda prefere o Claude. Ambos podem ser comparados através da invocação unificada no APIYI (apiyi.com).
Q3: Como usar o Claude e o GPT-5.4 simultaneamente?
Através do APIYI (apiyi.com), registre uma conta para:
- Obter uma chave API unificada
- Configurar o
base_urlparahttps://vip.apiyi.com/v1 - Usar
model="claude-opus-4-6"para tarefas de refatoração - Usar
model="gpt-5.4"para análise de grandes projetos - Usar
model="gpt-5.3-chat-latest"para tarefas diárias (mais econômico)
Recargas a partir de 100 dólares ganham 10% de bônus, e uma única conta cobre todos os principais modelos.
Resumo
Conclusões principais sobre Claude Code vs GPT-5.4:
- Claude ainda lidera em benchmarks de programação: Com 80,8% no SWE-Bench contra 77,2% do concorrente, ele entrega uma qualidade de código mais limpa, além de refatoração e depuração superiores — por isso, dizer para "cancelar a assinatura do Claude Code" é uma afirmação precipitada.
- GPT-5.4 domina em contexto e custo-benefício: Janela de contexto de 1M de tokens (5x maior que a do Claude), preços de API 40-50% mais baratos e integração mais profunda com o GitHub — ideal para grandes projetos e cenários sensíveis a custos.
- A melhor estratégia é usar ambos: Use o Claude para refatoração e correção de bugs; use o GPT-5.4 para análise de grandes bases de código e operações de terminal; e use o GPT-5.3 Instant para tarefas rotineiras para economizar.
Não se deixe levar por títulos clickbait como "Cancele o Claude Code". Desenvolvedores realmente inteligentes escolhem a ferramenta mais adequada para cada cenário — em vez de serem fiéis a apenas uma marca.
Recomendamos o acesso unificado ao Claude e ao GPT-5.4 através do APIYI (apiyi.com). Com uma única chave API, você invoca todos os modelos e ainda ganha 10% de bônus em recargas a partir de 100 dólares.
📚 Referências
-
Comparação detalhada Claude Code vs Codex: Perspectiva detalhada do desenvolvedor da equipe Builder.io
- Link:
builder.io/blog/codex-vs-claude-code - Descrição: Inclui comparação prática de preços, qualidade de código, integração com GitHub, etc.
- Link:
-
Análise competitiva: GPT-5.4 mira no Claude: Como o GPT-5.4 se posiciona na competição
- Link:
trendingtopics.eu/gpt-5-4-targets-anthropics-claude-with-premium-pricing-and-coding-muscle/ - Descrição: Análise profunda do posicionamento premium do GPT-5.4 Pro e suas ambições em programação.
- Link:
-
Comparação multidimensional GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro: Dados de 12 benchmarks
- Link:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Descrição: A comparação mais abrangente entre os três gigantes, incluindo análise de competitividade e sugestões de seleção.
- Link:
-
Benchmark para desenvolvedores: Claude Sonnet 4.6 vs GPT-5: Testes do SitePoint em cenários reais de desenvolvimento
- Link:
sitepoint.com/claude-sonnet-4-6-vs-gpt-5-the-2026-developer-benchmark/ - Descrição: Dados comparativos em tarefas específicas como refatoração, depuração e geração de documentação.
- Link:
Autor: Equipe Técnica APIYI
Troca de ideias: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, acesse a Central de Documentação em docs.apiyi.com