최근 AI 애플리케이션을 개발하면서 가장 고통스러운 순간이 언제인가요? 아마도 이런 상황일 겁니다. 프롬프트를 17번이나 수정하고 테스트 케이스 몇 개를 돌려보며 "이제 좀 괜찮네" 싶어 배포했는데, 사용자가 전혀 예상치 못한 엣지 케이스(Edge Case)로 서비스를 단번에 무너뜨리는 상황 말이죠. 이는 OpenAI가 2025년 10월에 공개한 쿡북(Cookbook) 게시물인 *"Building resilient prompts using an evaluation flywheel(평가 플라이휠을 활용한 회복 탄력성 있는 프롬프트 구축)"*에서 해결하고자 하는 핵심 문제입니다.
OpenAI 엔지니어 Neel Kapse와 커뮤니티의 저명한 ML 교육자 Hamel Husain은 이 글에서 **평가 플라이휠(Evaluation Flywheel)**이라는 핵심 개념을 제시합니다. 사회학의 정성적 연구 방법론을 도입하여, AI 애플리케이션 개발을 단순히 "프롬프트를 수정하고 기도하는(prompt-and-pray)" 방식에서 벗어나 체계적인 "엔지니어링 규율"의 영역으로 끌어올렸습니다. 본 글에서는 이 OpenAI 평가 플라이휠 프레임워크를 가장 쉬운 관점에서 해석하고, 여러분의 AI 프로젝트에 어떻게 적용할 수 있을지 가이드해 드립니다.
🎯 빠른 가이드: 쿡북에서는 실제 '아파트 임대 어시스턴트 AI'를 사례로 들어, 실패 분석부터 자동 그레이더(Grader), CI 통합까지의 전체 워크플로우를 완벽하게 보여줍니다. 글에서 언급된 Evals API와 프롬프트 최적화 도구는 OpenAI 플랫폼의 고급 기능으로, APIYI(apiyi.com)와 같은 OpenAI 공식 중계 서비스를 통해 바로 호출할 수 있습니다. 국내 개발자들도 쿡북의 프로세스를 그대로 따라 하면 충분히 구현 가능합니다.
아파트 임대 어시스턴트 사례: 엣지 케이스에 무너진 실제 AI 애플리케이션
쿡북에서 선택한 사례는 우리 일상과 매우 밀접합니다. 아파트 크기, 방문 예약, 시설 안내 등 자주 묻는 질문에 답해주는 AI 어시스턴트죠. 처음엔 평범한 챗봇 같지만, 실제 운영 환경에 배포하면 생각지도 못한 방식으로 문제가 발생합니다.
글에서 나열한 실패 사례들은 매우 대표적이며, 누구나 한 번쯤 겪어봤을 법한 내용입니다.
| 실패 유형 | 구체적 현상 | 결과 |
|---|---|---|
| 스케줄 오류 | 존재하지 않는 방문 시간대 추천 | 고객의 헛걸음, 불만 폭주 |
| 상태 혼란 | 예약 변경 시 기존 예약 미취소 | 동일 시간대 중복 예약, 영업 리드 관리 실패 |
| 레이아웃 붕괴 | 시설 목록이 텍스트 덩어리로 출력 | 사용자 경험 저하, 정보 전달 불가 |
| 링크 오류 | 매물 도면 링크 404 | 경쟁사로 고객 이탈 |
| 데이터 드리프트 | 실제 데이터와 다른 운영 시간 안내 | 사용자 오도, 법적 리스크 |
AI 애플리케이션을 만들어본 사람이라면 알겠지만, 이런 문제들은 프롬프트를 작성할 때 일부러 무시한 것이 아니라 발생할 것이라고 전혀 예상하지 못한 것들입니다. Fractional 팀은 관련 '영수증 검사(Receipt Inspection)' 사례에서 이러한 현상을 잘 정리했습니다. 몇 가지 '해피 패스(Happy Path)'만 테스트해서는 운영 환경의 '롱테일 버그'를 절대 잡아낼 수 없으며, 반드시 "실패 수집 → 패턴 귀납 → 자동 측정"의 폐쇄형 루프를 구축해야 합니다.
이 루프가 바로 평가 플라이휠이 해결하려는 핵심 과제입니다.
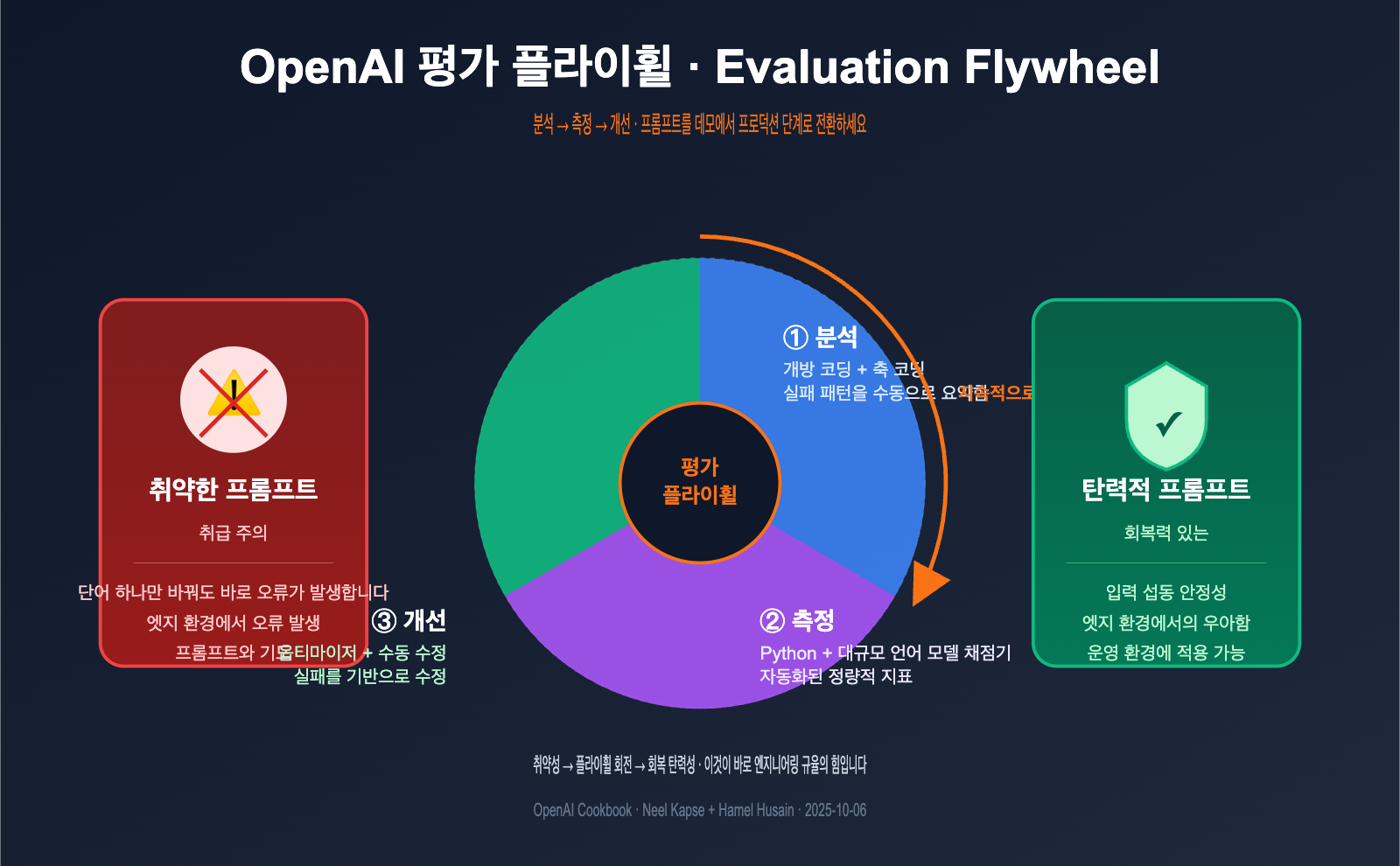
OpenAI 평가 플라이휠의 핵심 정의: '프롬프트 기도문'을 대체하는 엔지니어링 규율
Cookbook은 평가 플라이휠을 매우 간결하게 정의합니다. 지레짐작을 구조화된 엔지니어링 규율로 대체하는 지속적인 반복 과정이죠. 이 과정은 세 단계로 구성되며, 실제 바퀴가 구르듯 계속 회전하면서 한 바퀴 돌 때마다 시스템의 회복 탄력성을 높여줍니다.
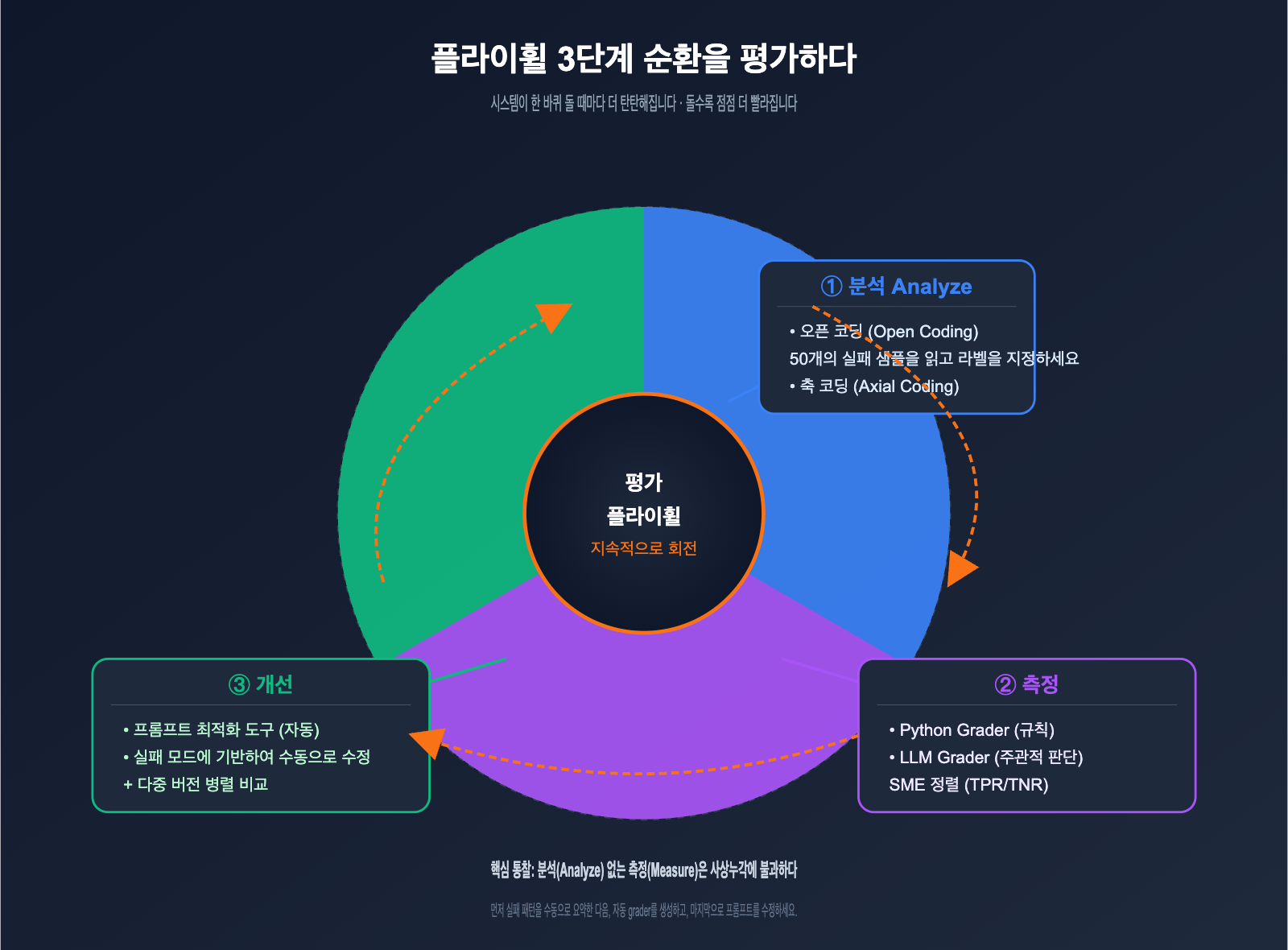
각 단계의 역할은 매우 명확하며, 특정 문제를 해결하는 데 집중합니다.
| 단계 | 핵심 질문 | 주요 활동 | 산출물 |
|---|---|---|---|
| Analyze (분석) | "왜 실패했는가?" | 실패 샘플 분석, 실패 패턴 도출 | 실패 분류 목록 + 비중 |
| Measure (측정) | "실패가 얼마나 심각한가?" | 평가기(Grader) 생성, 데이터셋 실행 | 정량적 지표 + 기준선(Baseline) |
| Improve (개선) | "어떻게 수정할 것인가?" | 프롬프트 수정, 평가 재실행 | 새 버전 + 지표 비교 |
많은 팀이 '분석(Analyze)' 단계를 건너뛰고 바로 자동 평가를 시도하는데, 이는 평가 플라이휠이 실패하는 가장 흔한 이유입니다. 정성적 분석 없는 자동 측정은 사상누각과 같습니다. 무엇을 측정하는지조차 모르기 때문이죠. 이것이 바로 이 Cookbook이 제시하는 핵심 통찰이자, 일반적인 평가 튜토리얼과 차별화되는 지점입니다.
💡 비유: 평가 플라이휠은 제품 관리자에게 익숙한 PDCA 사이클과 비슷하지만, 프롬프트 엔지니어링에 최적화된 구체적인 방법론을 갖추고 있습니다. 분석은 '문제 찾기', 측정은 '문제 정량화', 개선은 '문제 해결'을 의미하며 세 단계 모두 필수적입니다. APIYI(apiyi.com)에서 OpenAI Evals API를 호출해 평가를 시작하기 전, 분석 단계를 확실히 다져두는 것을 권장합니다.
OpenAI 평가 플라이휠 1단계: Analyze(분석)의 2단계 라벨링 기법
분석 단계는 평가 플라이휠에서 가장 간과되기 쉽지만 가장 중요한 부분입니다. Cookbook에서는 사회학의 정성적 연구에서 수십 년간 검증된 **오픈 코딩(Open Coding) → 액시얼 코딩(Axial Coding)**이라는 매우 전문적인 방법론을 제시합니다.
**1단계 오픈 코딩(Open Coding)**은 아주 직관적입니다. 실패 샘플 50개를 읽으면서, 미리 정해진 분류 없이 각 실패 사례에 설명형 태그를 붙이는 것입니다. 예를 들면 다음과 같습니다.
- "존재하지 않는 방문 예약 시간 추천"
- "시설 목록이 텍스트 덩어리로 출력됨"
- "일정 변경 시 기존 예약이 취소되지 않음"
- "해당 아파트가 아닌 다른 곳의 면적을 답변함"
- "평면도 링크가 작동하지 않음"
이 단계에서는 분류의 깔끔함을 추구하지 마세요. 그저 눈에 보이는 것을 솔직하게 기술하면 됩니다. 오픈 코딩은 독서 노트를 쓰는 것과 같습니다. 너무 일찍 분류하려 하면 오히려 예외적인 패턴을 놓칠 수 있으니 자유롭게 적어보세요.
**2단계 액시얼 코딩(Axial Coding)**부터는 구조화가 시작됩니다. 1단계에서 얻은 파편화된 태그들을 의미 있는 상위 범주로 묶는 과정입니다. Cookbook에서 제시하는 예시 분류는 다음과 같습니다.
- 방문 예약 관련 문제 (통합: 잘못된 시간, 미취소, 중복 예약) → 전체 실패의 35%
- 형식 오류 (통합: 레이아웃 깨짐, 링크 오류) → 전체 실패의 10%
- 데이터 정확성 문제 (통합: 영업시간 오류, 면적 오류) → 전체 실패의 나머지 %
액시얼 코딩은 목차를 정리하는 것과 같습니다. 실패의 '지형도'를 한눈에 파악할 수 있게 해주죠. 35%라는 수치는 어디를 먼저 수정해야 ROI가 가장 높을지 즉각적으로 알려줍니다.
| 라벨링 방법 | 목표 | 마음가짐 | 산출물 |
|---|---|---|---|
| 오픈 코딩 | 발견 (Discovery) | 자유롭게, 사전 분류 금지 | 50개 이상의 설명형 태그 |
| 액시얼 코딩 | 구조화 (Structure) | 귀납적 추론, 범주 구축 | 5~8개의 상위 실패 범주 |
🔧 실무 팁: 국내 개발자라면 생산 로그를 APIYI(apiyi.com)와 같은 OpenAI 중계 서비스를 통해 Evals API 플랫폼의 데이터셋 라벨링 인터페이스로 바로 연결해 보세요. 별도의 백엔드 구축 없이도 가능합니다. 오픈 코딩은 피드백 라벨링 열에, 액시얼 코딩은 분류 라벨링 열에 입력하면 Cookbook의 프로세스를 그대로 구현할 수 있습니다.
OpenAI 평가 플라이휠 2단계: Measure(측정)를 위한 두 가지 Grader 선택 가이드
Analyze 단계에서 "실패가 어떤 모습인지" 파악했다면, Measure 단계에서는 이러한 실패 사례를 자동 검출 코드로 변환해야 합니다. Cookbook에서는 엔지니어들이 가장 혼동하기 쉬운 두 가지 Grader 선택 가이드를 제시합니다.
| Grader 유형 | 적용 시나리오 | 장점 | 단점 |
|---|---|---|---|
| Python Grader | 결정론적 규칙 (문자열, 정규식, API 검증) | 결과가 안정적, 환각 없음, 추가 비용 없음 | 주관적 차원 평가 불가 |
| LLM Grader | 주관적 판단 (형식 미학, 의미 일치, 추론 품질) | 유연함, 코딩하기 어려운 차원 평가 가능 | SME 정렬 검증 필요, 토큰 비용 발생 |
아파트 어시스턴트 사례를 예로 들면, 두 Grader는 각자의 영역에서 활용됩니다.
- "추천 시간이 실제 이용 가능한 시간대인가?" → Python Grader (데이터베이스 또는 API 조회)
- "시설 목록이 보기 좋게 정렬되었는가?" → LLM Grader (0-10점 척도)
- "평면도 링크에 접근 가능한가?" → Python Grader (HEAD 요청)
- "답변 어조가 브랜드 정체성에 부합하는가?" → LLM Grader (루브릭 기반 점수 산정)
Cookbook은 매우 중요한 엔지니어링 실무를 강조합니다. LLM Grader는 반드시 SME(분야 전문가, Subject Matter Expert) 정렬 검증을 거쳐야 하며, GPT-4o의 점수를 맹신해서는 안 됩니다. 구체적인 방법은 데이터를 train/validation/test로 나누고, 다음 두 가지 지표를 동시에 확인하는 것입니다.
- High TPR (True Positive Rate, 참양성률): 실제 실패를 정확히 잡아내는가
- High TNR (True Negative Rate, 참음성률): 정상적인 샘플을 잘못 판단하지 않는가
단순히 정확도만 보면 높은 베이스라인에 속기 쉽습니다. 반드시 두 지표를 함께 확인해야 합니다. 이것이 바로 LLM-as-Judge를 "작동하는 것처럼 보이는 수준"에서 "실제로 작동하는 수준"으로 끌어올리는 분기점입니다.
📊 검증 프로세스: SME가 100개의 샘플을 Ground Truth로 라벨링 → LLM Grader가 동일 샘플 평가 → TPR/TNR 계산 → 두 지표가 기준을 충족할 때까지 Grader 프롬프트 조정. 이 과정은 APIYI의 Evals 플랫폼에서 기본적으로 지원하며, Evals API는 OpenAI 공식 프로토콜과 완벽하게 호환됩니다.
OpenAI 평가 플라이휠 3단계: Improve(개선)를 위한 이중 트랙 실험
3단계에서는 드디어 프롬프트를 수정할 수 있습니다. Cookbook은 두 가지 병렬 개선 경로를 제시하며, 이들은 택일이 아닌 상호 보완적으로 사용해야 합니다.
경로 1: 프롬프트 최적화 도구(Prompt Optimizer) 자동화
OpenAI 플랫폼에 내장된 Prompt Optimizer 도구를 활용하세요. 실패 샘플 세트와 원본 프롬프트를 입력하면, 도구가 다양한 수정 전략(Few-shot 추가, Chain-of-Thought 적용, 지시문 순서 조정 등)을 시도하고 Grader를 통해 개선 효과를 평가합니다. 이 경로는 효율적이어서 초기 탐색 단계에 적합합니다.
경로 2: 실패 패턴 기반의 수동 프롬프트 수정
Analyze 단계에서 요약된 구체적인 실패 패턴을 바탕으로 엔지니어가 직접 프롬프트를 수정합니다. 예를 들면 다음과 같습니다.
- 방문 일정 오류 → 프롬프트에 "이용 가능한 시간표 확인"이라는 강제 단계 추가
- 레이아웃 붕괴 → XML 태그를 사용하여 출력 형식을 명확히 지정
- 예약 변경 미취소 → "취소 후 재예약"이라는 상태 머신 로직 추가
수동 경로의 장점은 정밀함입니다. 각 수정 사항이 어떤 실패 패턴을 겨냥하는지 명확히 알 수 있어 디버깅이 용이합니다.
두 경로를 모두 완료하면 여러 개의 프롬프트 후보 버전이 생깁니다. 이때 Improve 단계의 핵심 단계가 남았습니다. 동일한 Grader 세트를 사용하여 동일한 데이터셋에서 모든 버전을 실행하고, 지표가 가장 우수한 버전을 선택하는 것입니다. 이 단계를 건너뛰면 안 됩니다. 인간은 자신이 수정한 프롬프트에 대해 "자기 만족적 편향"을 갖기 쉬우며, 이를 바로잡을 수 있는 유일한 방법은 오직 데이터 수치뿐이기 때문입니다.
모든 버전을 테스트하고 나면 플라이휠이 한 바퀴 회전합니다. 그러면 시스템이 개선됨에 따라 더 깊은 엣지 케이스가 드러나고, 다시 Analyze 단계로 돌아가 다음 사이클을 시작하게 됩니다. 이것이 바로 "플라이휠"의 정수입니다. 멈추지 않고, 더 빠르게 회전하며, 더 견고해지는 과정이죠.
韧性提示词 (Resilient Prompt) 与脆弱提示词的本质区别
文章标题里的 resilient prompt (韧性提示词) 是一个非常重要的概念,Cookbook 给出的定义是:在所有可能的输入上都能给出高质量响应的 prompt。听起来简单,实际是一个非常高的工程标准。

韧性和脆弱的差异主要体现在五个维度上:
| 对比维度 | 脆弱 Prompt | 韧性 Prompt |
|---|---|---|
| 输入鲁棒性 | 단어 하나만 바꿔도 붕괴 | 동의어 교체에도 안정적 |
| 엣지 케이스 | 이상한 출력 및 환각 | 우아한 성능 저하 또는 사람에게 전달 |
| 관측 가능성 | 블랙박스, 오류 시 추측만 가능 | 완전한 Grader로 위치 파악 가능 |
| 생산 환경 | 데모 성능 ≠ 실제 성능 | 완전한 평가 루프 통과 |
| 진화 가능성 | A 수정 시 B 고장 | 자동 회귀 테스트로 보호 |
엔지니어의 직관으로는 "대충 이 정도면 되겠지" 싶지만, 실제 운영 환경에서는 0.1% 확률의 문제가 발생합니다. 0.1%는 작아 보이지만, 백만 번 호출 시 1,000번의 사고로 이어집니다. 韧性提示词(韧性 프롬프트)의 엔지니어링 가치는 80%를 90%로 만드는 것이 아니라, 99%를 99.9%로 끌어올리는 데 있습니다.
🚀 연동 팁: 프롬프트를 99.9% 수준의 韧性으로 끌어올리려면 평가 루프를 자동화해야 합니다. 이를 위해 안정적인 OpenAI Evals API와 Prompt Optimizer 도구가 필요합니다. APIYI(apiyi.com)와 같은 OpenAI 공식 API 중계 서비스를 사용하면 공식 인터페이스와 완벽하게 동기화되며, 국내 IDC 노드를 통해 장시간 평가 작업 중에도 연결 끊김 없이 안정적인 운영이 가능합니다.
OpenAI 평가 플라이휠의 CI/CD 통합 및 생산 모니터링
Cookbook에서 강조하는 마지막 단계는 평가 플라이휠을 일상적인 엔지니어링 규율로 만드는 것입니다. 구체적인 실행 방안은 두 가지입니다.
첫 번째: CI/CD 통합
Grader 제품군을 CI 파이프라인에 연결하여 프롬프트가 변경될 때마다 자동으로 평가를 수행합니다. 지표가 임계값 이상으로 저하되면 PR 병합이 자동으로 차단됩니다. 이 단계는 '평가'를 연구 활동에서 일상적인 개발 업무로 전환하며, 프롬프트가 진정한 엔지니어링 단계로 진입했음을 의미합니다.
| CI 임계값 유형 | 권장 설정 | 설명 |
|---|---|---|
| 전체 정확도 | 저하 ≤ 1% | 전체적인 회귀 방지 |
| 핵심 Grader | 저하 ≤ 0.5% | 우선순위가 높은 실패 패턴 엄격 관리 |
| 새로운 패턴 감지 | 차단 대신 경고 | 새로운 문제 발견 장려 |
| 지연 시간 P95 | 증가 ≤ 10% | 비용 및 사용자 경험 제어 |
두 번째: 생산 모니터링
CI 외에도 생산 환경에서 지속적으로 샘플링을 수행하여 CI 세트에 포함되지 않은 '야생의 실패 패턴'을 찾아내야 합니다. 이러한 새로운 패턴은 평가 세트에 다시 추가되어 플라이휠을 다음 단계로 회전시킵니다.
구체적인 방법은 생산 로그를 일정 비율(예: 1%)로 샘플링하여 동일한 Grader 세트를 실행하고, 지표에 이상이 발견되면 수동으로 분석하는 것입니다. 새로 발견된 실패 패턴은 Open Coding → Axial Coding 과정을 거쳐 테스트 세트에 추가되고, 플라이휠은 다시 돌아갑니다.
이 순환 구조를 통해 프롬프트 시스템은 배포 후 멈춰 있는 것이 아니라 지속적으로 더 높은 韧性을 갖추게 됩니다. 이것이 바로 Cookbook이 모든 AI 엔지니어에게 남기는 핵심 엔지니어링 규율입니다.
OpenAI 평가 플라이휠이 국내 개발자에게 주는 5가지 실무적 시사점
Cookbook을 정독한 후, 국내 개발자들에게 직접적인 지침이 될 만한 5가지 시사점을 정리해 보았습니다.
시사점 1: Measure(측정)가 아닌 Analyze(분석)부터 시작하세요
많은 팀이 무작정 Grader를 설정하고 지표부터 올리려 하지만, 정작 중요한 '수동 분석' 단계를 건너뜁니다. 이렇게 하면 Grader가 측정하는 것이 실제 실패 패턴이 아니게 되어, 지표는 좋아 보여도 사용자 불만은 여전한 상황이 발생합니다. 50개 이상의 수동 Open Coding(개방형 코딩) 없이는 자동 평가를 시작하지 마세요.
시사점 2: Open Coding 단계에 GPT를 개입시키지 마세요
Open Coding은 반드시 사람이 해야 합니다. GPT는 귀납적 추론 과정에서 기존 학습 데이터의 편향을 반영해 라벨을 오염시킬 수 있기 때문입니다. LLM이 개입할 가장 이른 시점은 Axial Coding(축 코딩) 이후 Grader를 구현할 때이며, Analyze 단계의 '발견'은 인간만의 영역으로 남겨두어야 합니다.
시사점 3: LLM Grader보다 Python Grader를 우선하세요
확정적인 규칙으로 커버할 수 있다면 굳이 LLM Grader를 쓸 필요가 없습니다. 이유는 세 가지입니다. 안정적이고, 저렴하며, SME(분야 전문가)와의 정렬(Alignment)이 필요 없기 때문이죠. LLM Grader는 규칙으로 해결할 수 없는 주관적인 차원을 평가할 때만 사용하세요.
시사점 4: 지표를 비즈니스 영향과 연결하세요
'스케줄링 문제 35%, 형식 오류 10%'와 같은 수치는 '사용자 이탈률'이나 '불만 접수율'로 환산해야 비로소 의사결정에 가치가 생깁니다. 지표 그 자체는 의미가 없으며, 그 지표가 초래하는 비즈니스 결과가 중요합니다.
시사점 5: 플라이휠을 일회성 프로젝트가 아닌 자동화 시스템으로 만드세요
플라이휠을 한 번 돌리는 것의 ROI는 크지 않을 수 있지만, 장기적인 복리 효과는 엄청납니다. Grader를 CI 작업으로 만들고, 프로덕션 샘플링을 정기 작업으로 설정하며, 새로운 실패 패턴을 자동 알림으로 연결해 플라이휠이 24시간 스스로 돌아가게 하세요.
OpenAI 평가 플라이휠을 국내에서 재현하기 위한 Python 코드 골격
Cookbook은 주로 OpenAI 플랫폼의 UI 워크플로우를 보여주지만, Evals API를 통한 프로그래밍 방식의 호출도 충분히 지원합니다. 다음은 코드 기반 워크플로우를 선호하는 국내 개발자를 위한 Python 코드 골격입니다.
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # OpenAI 공식 API 중계 서비스로 전환
api_key="당신의 APIYI 키"
)
# 1. 평가 작업 생성 (Grader 집합 정의)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Python Grader 예시
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # LLM Grader 예시
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "출력 형식의 명확성을 0-10점으로 평가하세요"
}
]
)
# 2. 평가 실행 (Run)
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. 평가 결과 가져오기
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"통과율: {result.report_url}")
이 코드에는 세 가지 핵심 포인트가 있습니다. 첫째, base_url 전환입니다. 이 한 줄이 국내에서 장시간 평가 작업을 안정적으로 수행할 수 있게 해줍니다. 둘째, testing_criteria 배열입니다. 모든 Grader를 배열로 구성하여 한 번에 실행할 수 있습니다. 셋째, Evals API는 비동기 방식이므로 대규모 데이터셋 평가 시 수 분에서 수십 분이 소요될 수 있습니다. 프로그램 내에서 대기(Wait) 및 재시도(Retry) 로직을 반드시 고려하세요.
OpenAI 평가 플라이휠 FAQ
Q1: 평가 플라이휠은 LangSmith / Weights&Biases와 같은 평가 플랫폼과 어떤 차이가 있나요?
포지셔닝이 다릅니다. LangSmith는 주로 '평가의 도구화'를 해결하고, 평가 플라이휠은 '평가의 방법론'을 해결합니다. 전자는 어떻게 구현할지를 알려주고, 후자는 어떻게 사고할지를 알려주죠. 두 가지를 함께 사용하여 도구로 방법론을 뒷받침하는 것이 좋습니다.
Q2: 실패 샘플 50개면 충분한가요? 너무 적지 않나요?
Open Coding 단계에서는 50개면 충분합니다. 통계적 완벽함보다는 패턴을 발견하는 것이 목표이기 때문입니다. Measure 단계에서 필요한 샘플 수는 실패율에 따라 달라집니다. 실패율이 5%라면 안정적인 지표 신뢰 구간을 얻기 위해 1,000개의 샘플이 필요하지만, 실패율이 30%라면 200개로도 충분합니다.
Q3: 프롬프트 최적화 도구(Prompt Optimizer)가 수동 수정을 완전히 대체할 수 있나요?
아니요. 자동 도구는 알려진 평가 기준(grader) 내에서 부분 최적화하는 데는 능숙하지만, 비즈니스 제약 조건(예: "고객이 모든 응답을 80자 이내로 제한함"과 같은 암묵적 규칙)을 이해하는 데는 한계가 있습니다. 수동 수정과 자동 최적화를 결합하는 것이 가장 좋은 방법입니다.
Q4: 국내에서 Evals API를 호출하는 것은 안정적인가요?
OpenAI에 직접 연결하여 장시간 작업(평가는 보통 몇 분에서 몇 시간 소요)을 수행하면 연결이 끊기는 경우가 잦습니다. APIYI(apiyi.com)와 같은 OpenAI API 중계 서비스를 통해 호출하는 것을 권장합니다. 국내 IDC 노드는 장기 연결에 최적화되어 있어 평가 작업의 중단율을 획기적으로 낮출 수 있습니다.
Q5: 평가 플라이휠은 어느 규모의 팀에 적합한가요?
1인 프로젝트부터 100인 팀까지 모두 적합합니다. 차이점은 플라이휠이 돌아가는 빈도뿐입니다. 1인 프로젝트는 2주에 한 번 돌릴 수 있고, 대규모 팀은 일 단위나 시간 단위로 반복할 수 있죠. 중요한 것은 규모가 아니라 '규율'을 세우는 것입니다.
Q6: Hamel Husain은 누구이며, 왜 이 쿡북이 이렇게 주목받나요?
Hamel은 머신러닝 커뮤니티에서 매우 영향력 있는 교육자로, 오랫동안 대규모 언어 모델 애플리케이션의 엔지니어링 베스트 프랙티스를 추진해 왔습니다. 이 쿡북은 OpenAI가 공식적으로 정성적 연구 방법론(Open Coding 등)을 프롬프트 엔지니어링에 체계적으로 도입한 첫 사례라 업계에서 큰 화제가 되었습니다.
요약
OpenAI 평가 플라이휠 방법론의 진정한 가치는 한국 AI 엔지니어 커뮤니티에 "프롬프트 엔지니어링을 어떻게 해야 전문적인가"에 대한 표준 답안을 제시했다는 점입니다. 이는 단순한 도구가 아니라 엔지니어링 규율이며, 프롬프트 개발을 '감에 의존하는 수작업'에서 '체계적인 엔지니어링'으로 변화시킵니다.
Analyze → Measure → Improve의 3단계를 개발 프로세스에 녹여내면, 당신의 AI 애플리케이션은 "데모용으로 그럴듯한 수준"에서 "운영 환경에 배포하고 SLA를 보장할 수 있는 수준"으로 업그레이드됩니다. 이 업그레이드의 핵심은 실패를 체계적으로 수집하고, 패턴을 구조화하며, 개선 사항을 자동 측정으로 검증하는 완전한 순환 고리에 있습니다.
프롬프트 기반의 AI 애플리케이션을 개발 중이라면 이 플라이휠을 구축하는 것을 강력히 추천합니다. APIYI(apiyi.com)와 같은 API 중계 플랫폼을 통해 Evals API와 프롬프트 최적화 도구를 호출해 보세요. base_url 한 줄만 변경하면 국내 네트워크 안정성 문제 없이 전체 쿡북 프로세스를 바로 실행할 수 있습니다.
'플라이휠'을 근육 기억으로 만드세요. 당신의 프롬프트는 오늘부터 더 탄탄해질 것입니다.
📌 작성자: APIYI Team — OpenAI / Anthropic / Google 멀티모달 API의 엔지니어링 사례를 꾸준히 추적합니다. 더 많은 쿡북 실전 가이드와 Evals API 연동 방법은 apiyi.com 문서 센터에서 확인하세요.