「동시 요청을 몇 개나 보내는 게 좋을까요?」——Nano Banana 2 API로 이미지를 대량 생성할 때 개발자분들이 가장 많이 묻는 질문입니다. 정답은 플랫폼의 제한이 아니라, 여러분의 대역폭과 메모리가 얼마나 많은 Base64 이미지 데이터를 감당할 수 있는지에 달려 있습니다.
핵심 요약: 이 글을 읽고 나면 Nano Banana 2 API 동시 호출의 병목 지점을 파악하고, 서버 사양에 맞춰 최적의 동시 요청 수를 계산하는 방법과 검증된 5가지 성능 최적화 팁을 얻어가실 수 있습니다.
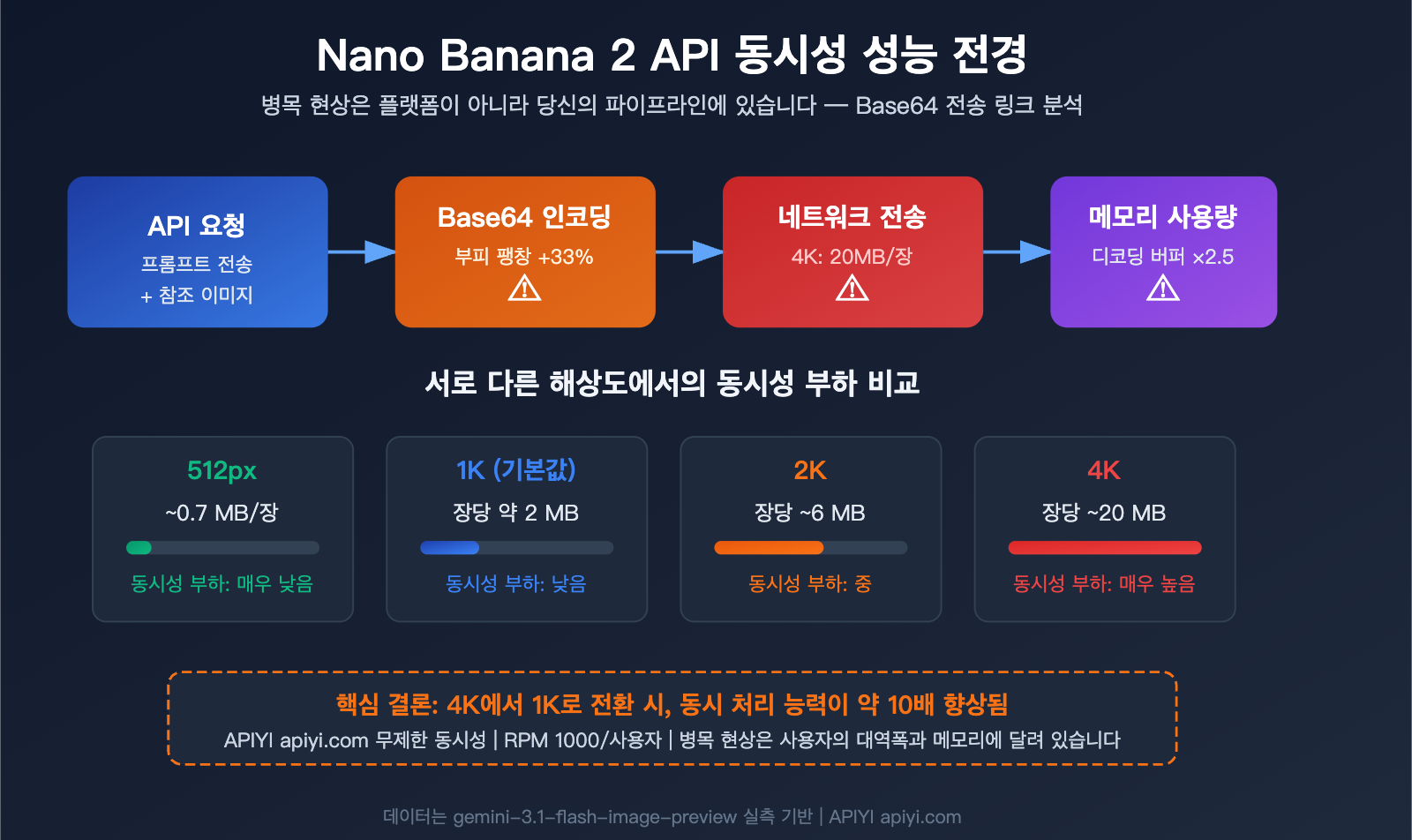
Nano Banana 2 API 동시성 핵심 문제: 병목 현상은 플랫폼이 아닌 당신의 파이프라인에 있습니다
많은 개발자가 가장 먼저 "플랫폼이 동시성을 얼마나 지원하나요?"라고 묻곤 합니다. 하지만 사실 APIYI 플랫폼은 동시성에 제한을 두지 않습니다. RPM(분당 요청 수)은 사용자당 1,000회까지 문제없이 지원하며, 필요에 따라 할당량을 추가로 늘릴 수도 있습니다.
진짜 병목 현상은 여기에 있습니다: Gemini 이미지 생성 API는 이미지를 전송할 때 Base64 인코딩 방식을 사용합니다. 즉, 이미지의 업로드와 다운로드 과정에서 효율적인 바이너리 스트림이 아닌, 거대한 JSON 텍스트를 주고받게 됩니다. 이는 당신의 대역폭과 메모리에 엄청난 부담을 줍니다.
왜 Base64가 동시성의 핵심 병목인가요?
Gemini 공식 API(Nano Banana 2의 gemini-3.1-flash-image-preview 포함)는 이미지 전송 시 Base64 인코딩만 지원합니다. Base64 인코딩은 바이너리 데이터를 약 33% 정도 팽창시키는데, 이는 다음과 같은 결과를 초래합니다.
| 해상도 | 원본 이미지 크기 | Base64 인코딩 후 | API 응답 데이터 크기 |
|---|---|---|---|
| 512px (0.5K) | ~400 KB | ~530 KB | ~600 KB – 1 MB |
| 1K (기본) | ~1.5 MB | ~2 MB | ~2 MB |
| 2K | ~4 MB | ~5.3 MB | ~5-8 MB |
| 4K | ~15 MB | ~20 MB | ~20 MB |
4K 이미지의 API 응답 데이터는 무려 20 MB에 달합니다. 만약 10개의 4K 동시 요청을 보낸다면, 네트워크와 메모리상에서 200 MB의 데이터가 한꺼번에 흐르게 되는 셈입니다.
Nano Banana 2 API 모델 파라미터 요약
| 파라미터 | 값 |
|---|---|
| 모델 ID | gemini-3.1-flash-image-preview |
| 입력 컨텍스트 | 131,072 토큰 |
| 출력 제한 | 32,768 토큰 |
| 지원 해상도 | 512px / 1K / 2K / 4K |
| 지원 화면 비율 | 1:1, 3:2, 4:3, 16:9, 9:16, 21:9 등 14종 |
| 최대 참조 이미지 | 14장 (물체 10장 + 캐릭터 4장) |
| 생성 속도 | 장당 3-5초 |
| APIYI RPM | 사용자당 1000회 (할당량 증설 가능) |
| APIYI 동시성 제한 | 제한 없음 |
🎯 기술 제언: APIYI apiyi.com 플랫폼은 Nano Banana 2에 대해 동시성 제한을 두지 않으며, 사용자당 RPM 1,000회를 지원합니다. 병목 현상은 당신의 로컬 환경, 즉 대역폭과 메모리에 의해 결정되므로 이 부분을 최적화하는 것이 중요합니다.
Nano Banana 2 API 동시성 계산: 환경에 맞는 최적의 솔루션 선택하기
동시성을 얼마나 설정할지는 막연하게 결정하는 것이 아니라, 실제 환경에 맞춰 계산해야 합니다. 핵심 지표는 대역폭, 메모리, 목표 해상도 세 가지입니다.
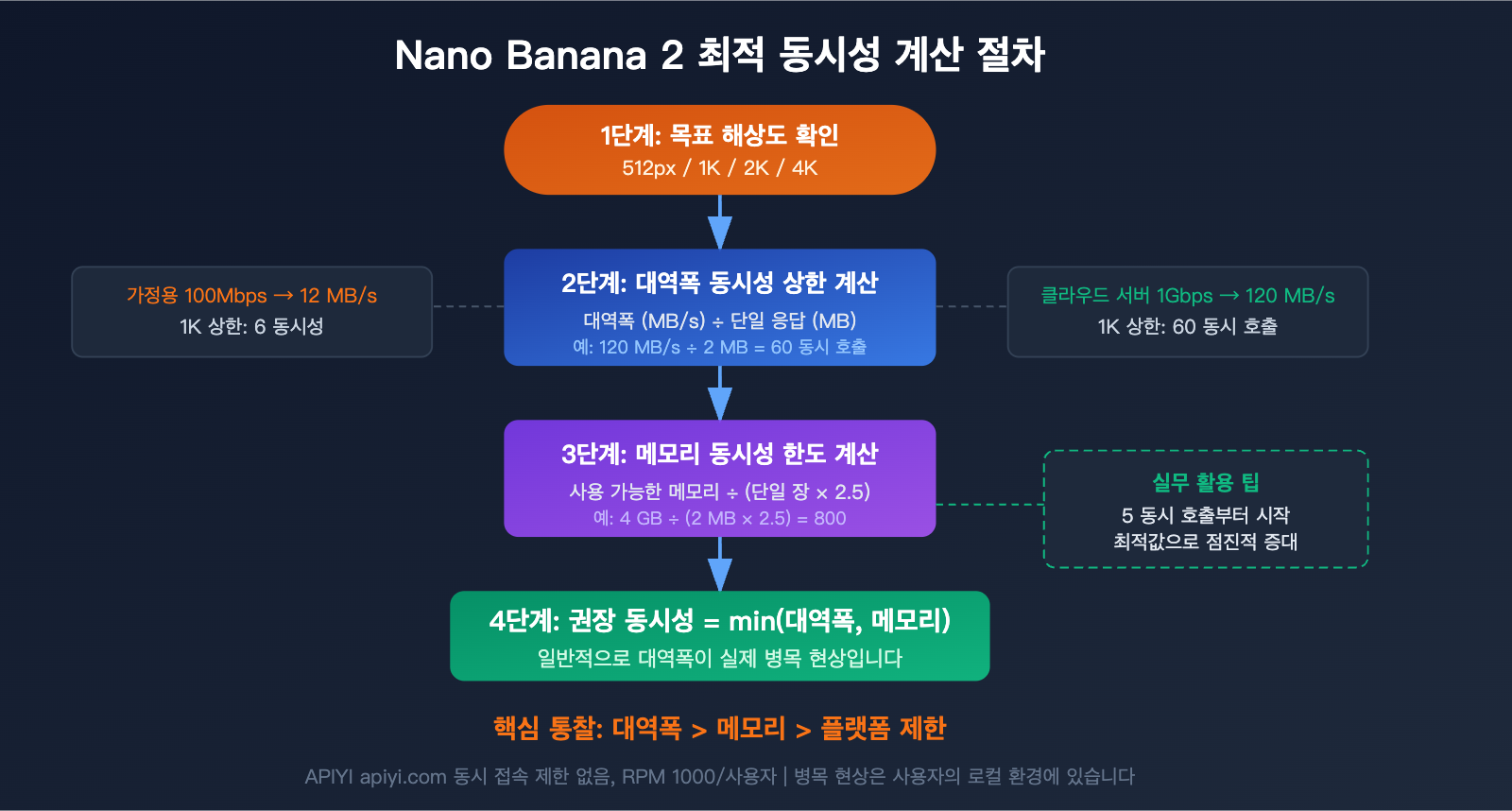
1단계: 대역폭 확인하기
대역폭은 동시에 전송할 수 있는 데이터의 양을 결정합니다. 계산 공식은 다음과 같습니다.
최대 동시성 (대역폭 기준) = 가용 대역폭 (MB/s) ÷ 단일 응답 크기 (MB)
| 네트워크 환경 | 가용 대역폭 | 1K 동시성 상한 | 2K 동시성 상한 | 4K 동시성 상한 |
|---|---|---|---|---|
| 가정용 광랜 (100Mbps) | ~12 MB/s | 6 | 2 | 0-1 |
| 기업용 네트워크 (500Mbps) | ~60 MB/s | 30 | 10 | 3 |
| 클라우드 서버 (1Gbps) | ~120 MB/s | 60 | 20 | 6 |
| 고성능 서버 (10Gbps) | ~1200 MB/s | 600 | 200 | 60 |
2단계: 가용 메모리 확인하기
각 동시 요청은 Base64 응답 데이터를 디코딩하고 디스크에 쓰기 완료할 때까지 메모리에 온전히 유지해야 합니다. 메모리 계산 공식은 다음과 같습니다.
필요 메모리 = 동시성 × 단일 응답 크기 × 2.5 (디코딩 버퍼 계수)
2.5를 곱하는 이유는 Base64 디코딩 과정에서 원본 문자열과 디코딩된 바이너리 데이터가 메모리에 동시에 존재하며, JSON 파싱 오버헤드까지 고려해야 하기 때문입니다.
| 가용 메모리 | 1K 동시성 상한 | 2K 동시성 상한 | 4K 동시성 상한 |
|---|---|---|---|
| 2 GB | 400 | 100 | 40 |
| 4 GB | 800 | 200 | 80 |
| 8 GB | 1600 | 400 | 160 |
3단계: 두 값 중 작은 값 선택하기
최종 권장 동시성 = min(대역폭 상한, 메모리 상한)
실제 환경에서는 메모리보다 대역폭이 진정한 병목 현상의 원인인 경우가 대부분입니다.
실제 시나리오별 권장 동시성
| 시나리오 | 권장 해상도 | 권장 동시성 | 예상 처리량 |
|---|---|---|---|
| 개인 개발/테스트 | 1K | 3-5 | ~1장/초 |
| 소규모 팀 배치 작업 | 1K | 10-20 | ~4장/초 |
| 기업용 운영 환경 | 1K-2K | 20-50 | ~10장/초 |
| 고처리량 이미지 서비스 | 1K | 50-100 | ~20장/초 |
| 4K 고화질 이미지 필요 | 4K | 3-5 | ~1장/초 |
💡 실전 팁: 적절한 동시성을 확신할 수 없다면 5개부터 시작하여 10, 20으로 점진적으로 늘려가며 응답 시간과 에러율을 관찰하세요. 응답 시간이 눈에 띄게 길어지거나 타임아웃이 발생한다면 병목 지점에 도달했다는 신호입니다. APIYI apiyi.com 플랫폼에서 테스트할 때는 플랫폼 측 제한을 걱정하지 말고, 오직 로컬 환경의 성능 지표에만 집중하세요.
Nano Banana 2 API 빠른 시작: 3단계 통합 가이드
1단계: 의존성 설치
pip install openai Pillow
2단계: 초간단 호출 예제
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "해변에서 선글라스를 쓴 귀여운 고양이 생성"
}
]
)
# Base64 이미지 데이터 추출 및 저장
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("이미지 저장 완료: output.png")
동시 배치 생성 전체 코드 보기
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
# 설정 파라미터
MAX_CONCURRENCY = 10 # 최대 동시 요청 수, 대역폭에 따라 조절하세요
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""이미지 한 장을 생성하고 즉시 저장하여 메모리 확보"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Base64 문자열이 메모리를 점유하지 않도록 즉시 디코딩 및 저장
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""스레드 풀을 사용한 이미지 동시 생성"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# 통계
success = [r for r in results if r["success"]]
print(f"\n완료: {len(success)}/{total} 성공")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"평균 소요 시간: {avg_time:.1f}s | 총 용량: {total_size:.1f} MB")
# 사용 예시
prompts = [
"노을 지는 미래 도시",
"아늑한 카페 내부",
"수중 산호초 풍경",
"오로라가 있는 산맥 풍경",
"기타를 치는 귀여운 로봇",
]
batch_generate(prompts)
3단계: 참조 이미지 업로드 (이미지-이미지 변환)
이미지-이미지 변환 시 참조 이미지를 업로드해야 하며, 이 역시 Base64로 인코딩합니다:
import base64
# 로컬 이미지를 읽어 Base64로 변환
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "이 사진을 수채화 스타일로 변환해줘"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
주의: 참조 이미지 업로드 시 전체 요청 본문 크기는 20MB를 초과할 수 없습니다. 이미지가 너무 크다면 1K 해상도 이하로 먼저 압축하는 것을 권장합니다.
Nano Banana 2 API 동시성 최적화 5가지 실전 팁
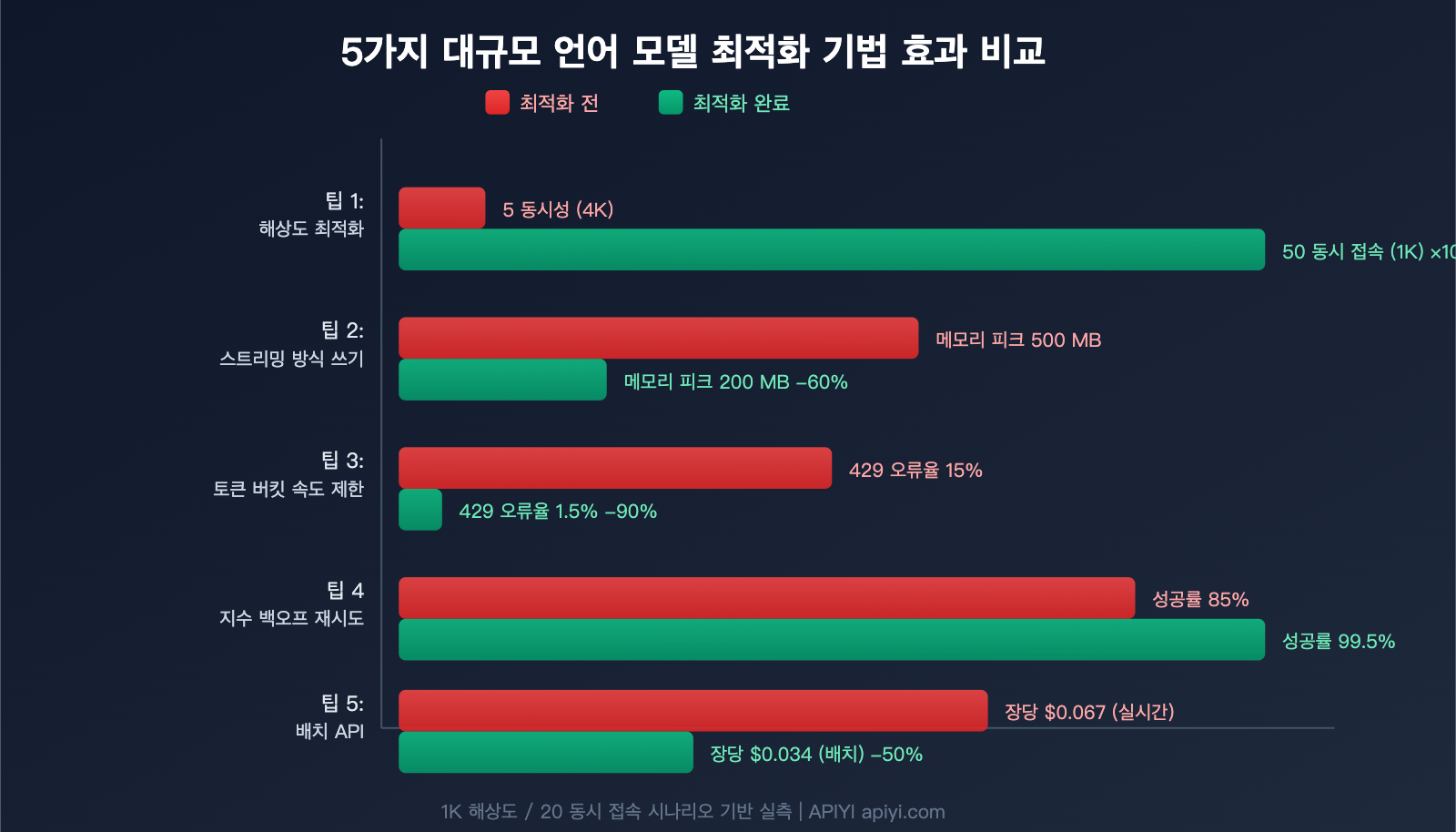
팁 1: 필요에 맞는 해상도 선택 (기본 4K 피하기)
가장 간단하면서 효과적인 최적화 방법입니다. 많은 개발자가 기본값으로 4K를 요청하지만, 실제 서비스 환경에서는 1K만으로도 충분합니다.
| 사용 사례 | 권장 해상도 | 단일 용량 | 동시성 효율 |
|---|---|---|---|
| 소셜 미디어용 | 1K | ~2 MB | 높음 |
| 이커머스 상품 | 2K | ~6 MB | 보통 |
| 인쇄/포스터 | 4K | ~20 MB | 낮음 |
| 미리보기/썸네일 | 512px | ~0.7 MB | 매우 높음 |
4K에서 1K로 전환하면 동일 조건에서 동시 처리 능력이 약 10배 향상됩니다.
팁 2: 스트리밍 수신 + 즉시 디스크 저장
전체 JSON 응답이 수신될 때까지 기다리지 마세요. 스트리밍으로 데이터를 받으면서 즉시 디코딩하고 디스크에 기록하세요.
import gc
def generate_and_save(prompt, filepath):
"""이미지 생성 및 즉시 저장, 메모리 능동 해제"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# 즉시 디코딩
img_bytes = base64.b64decode(part.image.data)
# Base64 문자열 참조 즉시 삭제
del part.image.data
# 즉시 디스크 저장
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # 가비지 컬렉션 강제 실행
팁 3: 토큰 버킷(Token Bucket)으로 동시성 제어
모든 요청을 한꺼번에 보내지 말고, 토큰 버킷 알고리즘을 사용하여 요청을 균일하게 분산하세요.
import threading
import time
class TokenBucket:
"""토큰 버킷 속도 제한기"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # 초당 토큰 보충량
self.capacity = capacity # 버킷 용량
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# 사용: 초당 최대 10개 요청, 최대 버스트 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # 토큰 대기
return generate_single_image(prompt, index)
팁 4: 지수 백오프(Exponential Backoff)로 429 에러 처리
속도 제한(HTTP 429)이 발생하면 지수 백오프 전략을 사용하세요.
import random
def generate_with_retry(prompt, index, max_retries=5):
"""지수 백오프를 적용한 재시도 메커니즘"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"속도 제한 발생, {delay:.1f}초 후 재시도...")
time.sleep(delay)
return {"index": index, "success": False, "error": "최대 재시도 횟수 초과"}
팁 5: 배치 작업은 Batch API로 50% 비용 절감
실시간 결과가 필요 없는 대량 작업의 경우, Nano Banana 2의 Batch API를 사용하면 비용을 절반으로 줄일 수 있습니다.
| 모드 | 1K 이미지 단가 | 4K 이미지 단가 | 지연 시간 | 추천 사례 |
|---|---|---|---|---|
| 실시간 API | $0.067 | $0.151 | 3-5초 | 인터랙티브 앱 |
| Batch API | $0.034 | $0.076 | 수분-수시간 | 대량 사전 생성 |
💰 비용 최적화: 대기 시간이 허용되는 작업이라면 APIYI(apiyi.com)를 통해 Batch API를 호출하여 비용을 50% 절감하세요. 이커머스 상품 이미지 대량 생성이나 마케팅 소스 사전 제작 등에 특히 유용합니다.
Nano Banana 2 API 해상도별 비용 및 토큰 소모 상세 분석
토큰 소모량을 이해하면 비용을 훨씬 효율적으로 관리할 수 있습니다.
| 해상도 | 출력 토큰 소모량 | 표준 가격 | Batch 가격 (50% 할인) | 100장당 비용 |
|---|---|---|---|---|
| 512px | 747 토큰 | $0.045 | $0.022 | $4.50 / $2.20 |
| 1K | 1,120 토큰 | $0.067 | $0.034 | $6.70 / $3.40 |
| 2K | 1,680 토큰 | $0.101 | $0.050 | $10.10 / $5.00 |
| 4K | 2,520 토큰 | $0.151 | $0.076 | $15.10 / $7.60 |
🚀 빠른 시작: APIYI(apiyi.com) 플랫폼을 통해 Nano Banana 2를 호출해 보세요. 공식 가격과 동일하며, 동시 접속 제한이 없고 사용자당 1000 RPM을 지원합니다. 가입만 해도 테스트 크레딧을 드립니다.
Nano Banana 2와 이전 모델 비교
| 비교 항목 | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| 모델 ID | gemini-2.5-flash (이미지) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| 최대 해상도 | 1024×1024 | 4K | 4K |
| 1K 단가 | $0.039 | $0.134 | $0.067 |
| 4K 단가 | 지원 안 함 | $0.240 | $0.151 |
| 생성 속도 | 2-4초 | 5-8초 | 3-5초 |
| Batch API | 지원 안 함 | 지원 안 함 | 지원 (50% 할인) |
| 참조 이미지 제한 | 5장 | 10장 | 14장 |
| APIYI 지원 | ✅ | ✅ | ✅ |
Nano Banana 2는 Pro 버전 대비 4K 가격이 37% 저렴하고, 속도는 40% 향상되었으며, Batch API 지원이 추가되었습니다.
Nano Banana 2 API 동시성 성능 모니터링
실제 동시성 작업을 실행할 때는 다음 지표들을 모니터링하는 것이 좋습니다.
import psutil
import time
class PerformanceMonitor:
"""동시성 성능 모니터링 도구"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- 성능 보고서 ---")
print(f"실행 시간: {elapsed:.1f}s")
print(f"완료된 요청: {self.request_count}")
print(f"성공률: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"처리량: {self.request_count/elapsed:.2f} req/s")
print(f"데이터 크기: {self.total_bytes/(1024**2):.1f} MB")
print(f"대역폭 사용량: {self.total_bytes/(1024**2)/elapsed:.1f} MB/s")
print(f"메모리 점유율: {mem:.0f} MB")
자주 묻는 질문 (FAQ)
Q1: APIYI 플랫폼에서 Nano Banana 2의 동시성 제한이 있나요?
APIYI 플랫폼은 Nano Banana 2의 동시 요청 수를 제한하지 않습니다. RPM(분당 요청 수)은 사용자당 기본 1,000회까지 지원하며, 더 높은 사양이 필요하시면 고객 센터를 통해 별도로 할당량을 늘릴 수 있습니다. 실제 동시성 병목 현상은 사용자의 로컬 대역폭과 메모리에서 발생합니다. APIYI apiyi.com 플랫폼을 통해 직접 테스트해 보시고, 본인의 환경에 최적화된 동시성 수치를 찾아보시는 것을 추천합니다.
Q2: 왜 Gemini 이미지 API는 Base64 전송만 지원하나요?
이는 Google Gemini API의 현재 설계 방식 때문입니다. Base64 인코딩을 사용하면 이미지 데이터를 JSON 응답에 직접 포함할 수 있어 별도의 파일 저장소나 CDN 배포가 필요하지 않습니다. 단점은 데이터 크기가 약 33% 증가하여 대역폭과 메모리 효율이 떨어진다는 점입니다. 개발자 커뮤니티에서 JPEG 형식 출력 및 임시 URL 다운로드 옵션 추가를 Google에 지속적으로 요청하고 있으나, 아직 구현되지는 않았습니다.
Q3: 1K와 4K 해상도의 차이가 큰가요?
사용 목적에 따라 다릅니다. 소셜 미디어용 이미지, 웹 전시, 앱 인터페이스 등에서는 1K 해상도로도 충분하며 육안으로는 거의 차이를 느끼기 어렵습니다. 4K는 인쇄물, 포스터, 고화질 배경화면 등 세부 사항을 확대해서 봐야 하는 경우에 적합합니다. 먼저 1K로 테스트하여 결과물을 확인한 후, 더 높은 선명도가 필요할 때 4K로 전환하는 것을 권장합니다. APIYI apiyi.com을 통해 해상도를 자유롭게 전환하며 조정할 수 있습니다.
Q4: 429 오류가 자주 발생하면 어떻게 하나요?
429 오류는 속도 제한(Rate Limit)에 도달했음을 의미합니다. 해결 방법은 다음과 같습니다: (1) 동시 요청 수를 줄입니다. (2) 토큰 버킷(Token Bucket) 알고리즘을 사용하여 요청을 균등하게 분산합니다. (3) 지수 백오프(Exponential Backoff) 재시도 로직을 구현합니다. (4) 대량 작업 시 Batch API를 사용합니다. APIYI 플랫폼에서 제한 문제가 발생하면 고객 센터에 문의하여 RPM 할당량을 늘릴 수 있습니다.
Q5: 대량 생성 시 총비용은 어떻게 계산하나요?
공식은 총비용 = 이미지 수량 × 단가입니다. 예를 들어 1K 이미지 1,000장을 생성할 경우: 표준 모드는 1,000 × $0.067 = $67, Batch 모드는 1,000 × $0.034 = $34가 됩니다. APIYI apiyi.com의 가격은 공식 가격과 동일하며, 유연한 충전 방식을 지원하여 필요한 만큼만 사용하기에 적합합니다.
요약: Nano Banana 2 API를 위한 최적의 동시성 전략 찾기
Nano Banana 2 API의 동시성 최적화 핵심은 "플랫폼이 얼마나 허용하는가"가 아니라, "내 파이프라인이 얼마나 처리할 수 있는가"에 달려 있습니다. 다음 3가지 핵심 포인트를 꼭 기억하세요:
- 해상도가 모든 것을 결정합니다: 4K에서 1K로 줄이면 동시성 처리 능력은 10배 향상되고, 비용은 56% 절감됩니다.
- 대역폭이 진짜 병목입니다: Base64 인코딩을 사용하면 이미지 크기가 실제보다 33% 커지므로, CPU보다 대역폭에 가해지는 부하가 훨씬 큽니다.
- 작은 규모에서 시작해 점진적으로 조정하세요: 동시성 5부터 시작하여 응답 시간과 오류율을 모니터링하며 최적의 수치까지 단계적으로 올리세요.
APIYI(apiyi.com) 플랫폼을 통해 Nano Banana 2 API를 호출하는 것을 추천합니다. 동시성 제한이 없고 사용자당 RPM 1000을 지원하며, 가격도 공식과 동일합니다. 플랫폼 측의 제약 사항을 걱정할 필요 없이, 여러분의 파이프라인 성능 최적화에만 집중하세요.

참고 자료
-
Gemini 3.1 Flash Image Preview: 모델 사양 및 API 문서
- 링크:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- 링크:
-
Gemini Image Generation API: 이미지 생성 API 사용 가이드
- 링크:
ai.google.dev/gemini-api/docs/image-generation
- 링크:
-
Gemini API Rate Limits: 공식 속도 제한 문서
- 링크:
ai.google.dev/gemini-api/docs/rate-limits
- 링크:
-
APIYI Nano Banana 2 연동 문서: 통합 API 인터페이스 설명
- 링크:
api.apiyi.com
- 링크:
📝 작성자: APIYI Team | APIYI 기술 팀은 AI 이미지 생성 API 분야를 깊이 있게 연구하며, apiyi.com을 통해 개발자들에게 동시 접속 제한 없는 유연한 요금제의 Nano Banana 2 API 연동 서비스를 제공합니다.