作者注:AI漫劇(まんげき)の量産に向けた完全なワークフローを詳しく解説し、Sora 2のCharacter CameoとVeo 3.1の4K出力による効率的な制作方法を詳しく紹介します。
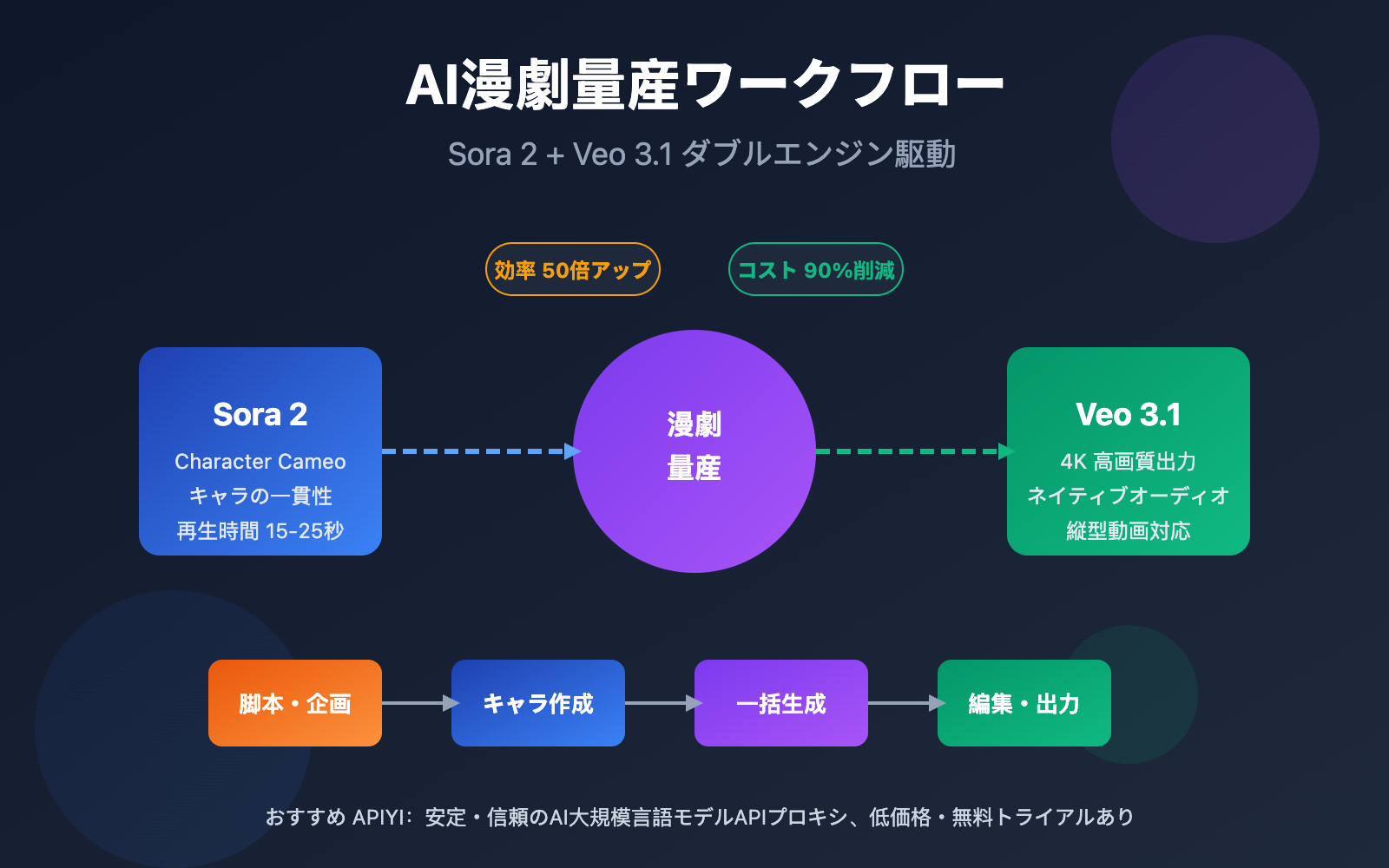
AI漫劇は、コンテンツ制作における新たなトレンドとなりつつあります。Sora 2とVeo 3.1を活用して、いかに効率的な量産ワークフローを構築するかが、現在すべてのクリエイターが模索している核心的な課題です。
核心価値:この記事を読み終える頃には、漫劇制作の完全なワークフローをマスターし、Sora 2のCharacter Cameoによるキャラクターの一貫性保持や、Veo 3.1を用いた4K縦型動画出力の実践的なテクニックを習得できるでしょう。
AI漫劇量産の核心価値と市場機会
AI漫劇の量産は、コンテンツ制作の効率の限界を再定義しています。従来の漫劇制作には膨大な手描き作業とアニメーション制作が必要でしたが、Sora 2とVeo 3.1の登場により、個人のチームでも工業レベルの制作が可能になりました。
| 比較項目 | 従来の漫劇制作 | AI漫劇量産 | 効率アップ |
|---|---|---|---|
| 1話あたりの制作期間 | 7-14日 | 2-4時間 | 50-80倍 |
| キャラクターの一貫性 | 絵師の技術に依存 | APIで自動保持 | 100%一致 |
| シーン生成 | コマごとの描画 | 一括生成 | 20-50倍 |
| コスト | 数十万円〜/話 | 数千円〜/話 | 90%削減 |
| 生産能力の上限 | 月2-4話 | 月50-100話 | 25倍 |
漫劇量産における3つの核心的メリット
第一に、キャラクターの一貫性における技術革新です。Sora 2のCharacter Cameo機能により、再利用可能なキャラクターIDを作成できるようになりました。これにより、異なるシーンでも同一キャラクターが完全に一致した外見を保つことが可能です。これは、従来のAI動画生成における「顔が変わってしまう」という最大の悩みを解決しました。
第二に、量産プロセスの標準化です。API連携を通じて、クリエイターは脚本の解析、プロンプト生成、動画生成、事後編集を一連の自動化パイプラインに統合できます。20〜50のシーン生成にかかる時間を、数時間から1時間以内にまで短縮できます。
第三に、マルチプラットフォーム対応の柔軟性です。Veo 3.1はネイティブで縦型動画の生成をサポートしており、TikTok、YouTube Shorts、Instagram Reelsなどの短尺動画プラットフォームに最適な9:16比率のコンテンツを、二次的なクロップなしで直接出力できます。
🎯 プラットフォームのアドバイス:漫劇の量産には安定したAPI利用環境が不可欠です。Sora 2やその他の主要な動画モデルの統合インターフェースを提供し、一括タスク送信とコスト最適化をサポートしている APIYI (apiyi.com) の利用をお勧めします。
漫劇制作ワークフロー 全工程の徹底解説
完結した漫劇(マンゲキ)制作ワークフローは、5つの核心フェーズに分けることができます。各フェーズには明確なインプット・アウトプットと技術的なポイントがあります。
漫劇制作ワークフロー 第1フェーズ:脚本企画と絵コンテ設計
漫劇制作ワークフローの出発点は、構造化された脚本です。従来の脚本とは異なり、AI漫劇の脚本では、カットごとに詳細な視覚的描写を提供する必要があります。
| 脚本要素 | 従来の書き方 | AI漫劇ワークフローの書き方 | 役割の説明 |
|---|---|---|---|
| シーン描写 | カフェの中 | モダンでミニマルなカフェ、掃き出し窓、午後の陽光、暖色系 | ビデオ生成の視覚的根拠を提供 |
| キャラクターの動作 | 小明がコーヒーを飲む | 黒髪の男性、白シャツ、右手にコーヒーカップを持ち、微笑みながら窓の外を見る | 動作の生成を確実にする |
| 映像言語 | 近景 | クローズアップ、45度の横顔、背景の被写界深度をぼかす | 構図の生成をガイドする |
| 再生時間の指定 | なし | 8秒 | APIパラメータの設定 |
絵コンテ脚本のサンプル形式:
episode: 1
title: "初次相遇"
total_scenes: 12
characters:
- id: "char_001"
name: "小雨"
description: "20岁女性,黑色长发,白色连衣裙"
- id: "char_002"
name: "阿明"
description: "22岁男性,短发,休闲西装"
scenes:
- scene_id: 1
duration: 6
setting: "城市街道,傍晚,霓虹灯初亮"
characters: ["char_001"]
action: "小雨独自走在街道上,低头看手机"
camera: "跟随镜头,中景"
漫劇制作ワークフロー 第2フェーズ:キャラクター資産の作成
キャラクターの一貫性は、漫劇の量産における最大の課題です。Sora 2とVeo 3.1は、それぞれ異なるソリューションを提供しています。
Sora 2でのキャラクター作成方法:
- キャラクターの参考画像(正面、側面、全身写真)を準備する
- Character APIを通じて参考素材をアップロードする
- 再利用可能なキャラクターID(Character ID)を取得する
- その後のシーン生成でそのIDを引用する
Veo 3.1でのキャラクター保持方法:
- 複数のキャラクター参考画像をアップロードする
- style reference(スタイルリファレンス)機能を使用してスタイルを固定する
- プロンプトでキャラクターの特徴を詳細に記述する
- 連続生成を通じて一貫性を維持する
テクニカルアドバイス:主要キャラクターについては、異なる角度から3〜5枚の参考画像を作成することをお勧めします。これにより、AIモデルによるキャラクター特徴の理解精度が大幅に向上します。
漫劇制作ワークフロー 第3フェーズ:ビデオの一括生成
これは漫劇制作ワークフローの中で最も核心となる技術工程です。APIを通じて生成タスクを一括送信することで、生産性を大幅に向上させることができます。
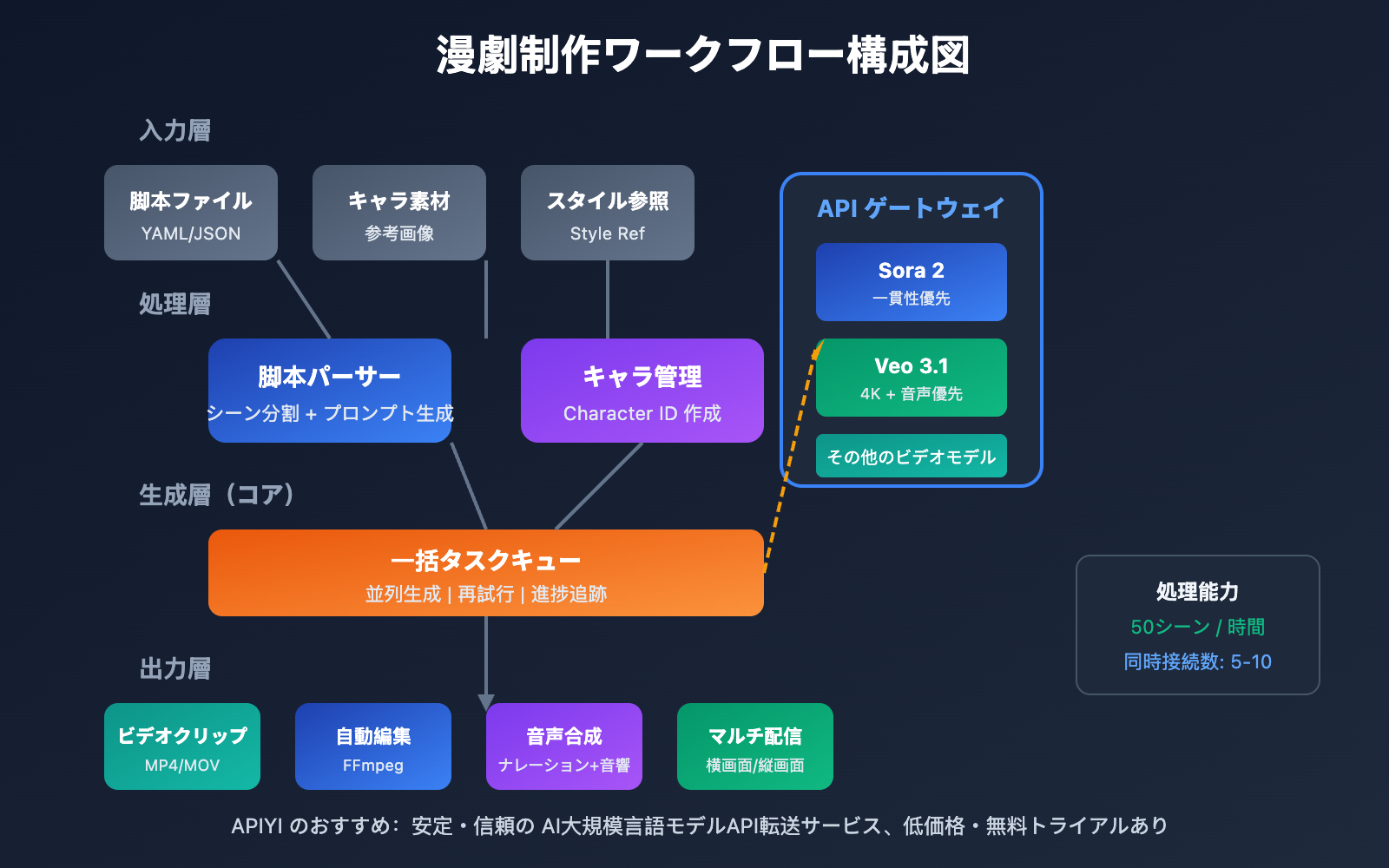
一括生成の戦略:
- 並列生成:複数のシーンの生成リクエストを同時に送信します。
- 優先度管理:重要なシーンを優先的に生成し、タイムリーな調整を可能にします。
- 失敗時の再試行:生成に失敗したタスクを自動的に検出し、再送信します。
- 結果の検証:品質基準を満たすアウトプットを自動的にフィルタリングします。
漫劇制作ワークフロー 第4フェーズ:ポストプロダクション(編集とオーディオ)
生成されたビデオクリップは、編集による統合とオーディオの追加が必要です。
| 編集工程 | 推奨ツール | 所要時間の割合 | 自動化レベル |
|---|---|---|---|
| ビデオ結合 | FFmpeg / Premiere | 15% | 完全自動化可能 |
| トランジション効果 | After Effects | 10% | 半自動化 |
| ナレーション・BGM | Eleven Labs / Suno | 25% | 完全自動化可能 |
| 字幕追加 | Whisper + Aegisub | 15% | 完全自動化可能 |
| カラーグレーディング | DaVinci Resolve | 20% | 半自動化 |
| 品質チェック・修正 | 目視確認 | 15% | 手動作業が必要 |
漫劇制作ワークフロー 第5フェーズ:マルチプラットフォーム配信
各プラットフォームの要件に合わせて、対応する仕様のビデオファイルを出力します。
- TikTok / Reels:9:16 縦型、1080×1920、60秒以内
- Bilibili / YouTube:16:9 横型、1920×1080、再生時間制限なし
- 小紅書 (Red):3:4 または 9:16、カバー画像の引きの強さを重視
- WeChat ビデオアカウント:各種アスペクト比に対応、9:16 を推奨
🎯 効率アップのアドバイス:APIYI (apiyi.com) の統合インターフェースを使用すると、複数のビデオモデルを同時に呼び出すことができます。シーンに合わせて最適なモデルを選択することで、コストと品質のバランスを実現できます。
Sora 2 のマンガ動画制作における核心的な活用法
Sora 2 は OpenAI が発表した動画生成モデルであり、その Character Cameo 機能はマンガ動画の大量制作における重要な技術的支柱となっています。
Sora 2 Character Cameo キャラクターの一貫性技術
Character Cameo は、再利用可能なキャラクターアイデンティティを作成することを可能にし、同一キャラクターが異なるシーンでも一貫した外見を保つことを保証します。
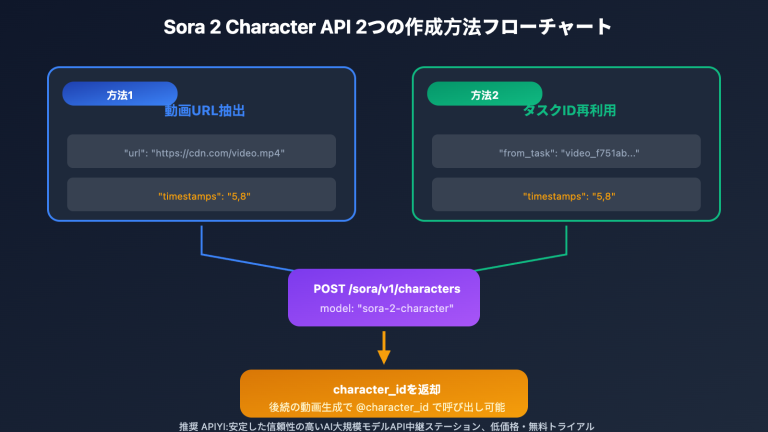
キャラクター ID を作成する 2 つの方法:
方法 1:既存の動画から抽出する
import requests
# 从视频 URL 提取角色特征
response = requests.post(
"https://vip.apiyi.com/v1/sora/characters/extract",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"video_url": "https://example.com/character_reference.mp4",
"character_name": "protagonist_male"
}
)
character_id = response.json()["character_id"]
方法 2:参考画像から作成する
# 从多角度参考图创建角色
response = requests.post(
"https://vip.apiyi.com/v1/sora/characters/create",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"images": [
"base64_front_view...",
"base64_side_view...",
"base64_full_body..."
],
"character_name": "protagonist_female",
"description": "20岁亚洲女性,黑色长发,温柔气质"
}
)
Sora 2 の「画像から動画生成(Image-to-Video)」機能のマンガ動画制作への応用
Sora 2 の画像から動画生成(Image-to-Video)機能は、静止画のマンガのコマを動的な動画に変換することができ、マンガ動画制作のワークフローにおいて重要な役割を果たします。
| 動画生成シナリオ | 入力要件 | 出力効果 | 適用シーン |
|---|---|---|---|
| 単一画像の動態化 | 高画質静止画 | 6〜15 秒の動的動画 | 表紙、場面転換シーン |
| 表情や動き | 人物のアップ | 瞬きや微笑みなどの微細な表情を追加 | 会話シーン |
| シーンの拡張 | 部分的な画面 | カメラのズーム(トラック・イン/アウト)、環境の拡張 | エスタブリッシング・ショット(状況説明カット) |
| スタイル変換 | 任意の画像 | アニメ風や実写スタイルへの変換 | スタイルの統一 |
Sora 2 マンガ動画生成のベストプラクティス
構造化プロンプトテンプレート:
[主体の説明] + [動作・行動] + [シーン・環境] + [カメラワーク] + [スタイルの指定]
例:
"一位黑发女孩(character_id: char_001)坐在咖啡厅窗边,
轻轻搅动咖啡杯,阳光从落地窗洒入,暖色调,
中近景,浅景深,日系动漫风格,柔和色彩"
生成パラメータの推奨事項:
- 長さ:後工程の編集を考慮し、1カットあたり 6〜10 秒を推奨。
- 解像度:品質とコストのバランスから、1080p を優先。
- スタイルプリセット:より安定したマンガスタイルを得るために Comic プリセットを使用。
🎯 API 呼び出しのアドバイス:Sora 2 API の一括呼び出しは、タスクキュー管理と自動リトライをサポートし、大量生成の成功率を高めることができる APIYI (apiyi.com) 経由での利用が推奨されます。
Veo 3.1 のマンガ動画制作における核心的な活用法
Veo 3.1 は Google DeepMind が発表した最新の動画生成モデルであり、マンガ動画の大量制作の分野において独自の優位性を持っています。
Veo 3.1 の 4K 出力と画質の優位性
Veo 3.1 は前世代と比較して画質と安定性が大幅に向上しており、特に高精細な出力が求められるマンガ動画プロジェクトに適しています。
| Veo バージョン | 最高解像度 | オーディオサポート | キャラクターの一貫性 | 生成速度 |
|---|---|---|---|---|
| Veo 2 | 1080p | なし | 普通 | 比較的速い |
| Veo 3 | 4K | ネイティブオーディオ | 良好 | 中程度 |
| Veo 3.1 | 4K | 強化されたオーディオ | 優秀 | 30〜60秒 |
Veo 3.1 の主な強み:
- ネイティブオーディオ生成:効果音、環境音、さらにはキャラクターのセリフを同時に生成可能。
- キャラクター一貫性の強化:複数の参考画像をアップロードする機能により、一貫性が大幅に向上。
- 縦型動画のネイティブサポート:9:16 比率の動画を直接生成でき、ショート動画プラットフォームに最適。
- 精密なスタイル制御:スタイル参照(Style Reference)画像を通じて、出力スタイルを正確にコントロール。
Veo 3.1 の縦型動画生成のマンガ動画制作への応用
ショート動画プラットフォーム向けのマンガ動画コンテンツには縦型フォーマットが必要ですが、Veo 3.1 のネイティブ縦型サポートにより、再トリミングによる画質の損失を避けることができます。
縦型動画の生成方法:
# 通过上传竖屏参考图触发竖屏生成
response = requests.post(
"https://vip.apiyi.com/v1/veo/generate",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"prompt": "动漫风格,黑发少女在樱花树下,微风吹动头发,唯美氛围",
"reference_image": "vertical_reference_9_16.jpg",
"duration": 8,
"with_audio": True,
"audio_prompt": "轻柔的钢琴背景音乐,树叶沙沙声"
}
)
Veo 3.1 の複数参考画像によるキャラクター制御技術
Veo 3.1 は、複数の参考画像をアップロードしてキャラクター、オブジェクト、シーンの生成をガイドすることをサポートしています。これは、マンガ動画の大量制作における一貫性を保つために極めて重要です。
複数参考画像の活用戦略:
- キャラクター画像:異なる角度からのキャラクターの定型ショットを 3〜5 枚。
- シーン画像:背景シーンのスタイル参考を 2〜3 枚。
- スタイル画像:全体の画風の参考を 1〜2 枚。
🎯 モデル選択のアドバイス:高画質とネイティブオーディオが必要な場合は Veo 3.1 を、キャラクターの一貫性を重視する場合は Sora 2 を選択してください。APIYI (apiyi.com) は両方のモデルの統合呼び出しをサポートしており、柔軟な切り替えが可能です。
マンガ動画量産化の技術スキーム:API による自動化の実践
マンガ動画の制作ワークフローを自動化することは、生産能力を向上させるための鍵となります。以下に、完全な技術実装スキームを紹介します。
マンガ動画量産化自動化スクリプトのアーキテクチャ
import asyncio
from typing import List, Dict
class MangaDramaProducer:
"""漫剧批量制作自动化框架"""
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://vip.apiyi.com/v1"
async def batch_generate(
self,
scenes: List[Dict],
model: str = "sora-2"
) -> List[str]:
"""批量生成场景视频"""
tasks = []
for scene in scenes:
task = self.generate_scene(scene, model)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
async def generate_scene(
self,
scene: Dict,
model: str
) -> str:
"""单场景生成"""
# 构建提示词
prompt = self.build_prompt(scene)
# 调用 API
video_url = await self.call_api(prompt, model)
return video_url
自動化スクリプトの完全なコードを表示する
import asyncio
import aiohttp
from typing import List, Dict, Optional
from dataclasses import dataclass
import json
@dataclass
class Scene:
"""场景数据结构"""
scene_id: int
duration: int
setting: str
characters: List[str]
action: str
camera: str
dialogue: Optional[str] = None
@dataclass
class Character:
"""角色数据结构"""
char_id: str
name: str
description: str
reference_images: List[str]
class MangaDramaProducer:
"""漫剧批量制作完整框架"""
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://vip.apiyi.com/v1"
self.characters: Dict[str, str] = {} # name -> character_id
async def create_character(
self,
character: Character
) -> str:
"""创建角色 ID"""
async with aiohttp.ClientSession() as session:
async with session.post(
f"{self.base_url}/sora/characters/create",
headers={"Authorization": f"Bearer {self.api_key}"},
json={
"images": character.reference_images,
"character_name": character.char_id,
"description": character.description
}
) as resp:
result = await resp.json()
char_id = result["character_id"]
self.characters[character.name] = char_id
return char_id
def build_prompt(self, scene: Scene) -> str:
"""构建场景提示词"""
char_refs = []
for char_name in scene.characters:
if char_name in self.characters:
char_refs.append(
f"(character_id: {self.characters[char_name]})"
)
prompt_parts = [
scene.action,
f"场景:{scene.setting}",
f"镜头:{scene.camera}",
"动漫风格,高质量,细节丰富"
]
if char_refs:
prompt_parts.insert(0, " ".join(char_refs))
return ",".join(prompt_parts)
async def generate_scene(
self,
scene: Scene,
model: str = "sora-2",
with_audio: bool = False
) -> Dict:
"""生成单个场景"""
prompt = self.build_prompt(scene)
async with aiohttp.ClientSession() as session:
endpoint = "sora" if "sora" in model else "veo"
async with session.post(
f"{self.base_url}/{endpoint}/generate",
headers={"Authorization": f"Bearer {self.api_key}"},
json={
"prompt": prompt,
"duration": scene.duration,
"with_audio": with_audio
}
) as resp:
result = await resp.json()
return {
"scene_id": scene.scene_id,
"video_url": result.get("video_url"),
"status": result.get("status")
}
async def batch_generate(
self,
scenes: List[Scene],
model: str = "sora-2",
max_concurrent: int = 5
) -> List[Dict]:
"""批量生成场景"""
semaphore = asyncio.Semaphore(max_concurrent)
async def limited_generate(scene):
async with semaphore:
return await self.generate_scene(scene, model)
tasks = [limited_generate(s) for s in scenes]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理失败的任务
successful = []
failed = []
for i, result in enumerate(results):
if isinstance(result, Exception):
failed.append(scenes[i])
else:
successful.append(result)
# 重试失败的任务
if failed:
retry_results = await self.batch_generate(
failed, model, max_concurrent
)
successful.extend(retry_results)
return successful
# 使用示例
async def main():
producer = MangaDramaProducer("your_api_key")
# 创建角色
protagonist = Character(
char_id="char_001",
name="小雨",
description="20岁女性,黑色长发,温柔气质",
reference_images=["base64_img1", "base64_img2"]
)
await producer.create_character(protagonist)
# 定义场景
scenes = [
Scene(1, 8, "城市街道黄昏", ["小雨"], "独自走路看手机", "跟随中景"),
Scene(2, 6, "咖啡厅内部", ["小雨"], "坐在窗边喝咖啡", "固定中近景"),
Scene(3, 10, "公园长椅", ["小雨"], "望着夕阳发呆", "慢推特写")
]
# 批量生成
results = await producer.batch_generate(scenes, model="sora-2")
print(json.dumps(results, indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(main())
マンガ動画量産化のコスト最適化戦略
| 最適化の方向性 | 具体的施策 | 予想削減額 | 実施難易度 |
|---|---|---|---|
| モデルの選択 | 単純なシーンには低コストモデルを使用 | 30-50% | 低 |
| 解像度の制御 | 必要に応じて 720p/1080p/4K を選択 | 20-40% | 低 |
| ボリュームディスカウント | APIアグリゲータープラットフォームの利用 | 10-20% | 低 |
| キャッシュの再利用 | 類似シーンで生成結果を再利用 | 15-25% | 中 |
| 長さの最適化 | カットごとの長さを正確に制御 | 10-15% | 中 |
🎯 コスト管理のアドバイス:APIYI (apiyi.com) は、さまざまな動画モデルの統一インターフェースを提供しており、ニーズに合わせて異なるグレードのモデルを選択できます。バッチタスクの割引と組み合わせることで、マンガ動画量産化の全体的なコストを効果的に削減できます。
Sora 2 vs Veo 3.1:マンガ動画制作の比較分析
適切な動画生成モデルを選択することが、マンガ動画量産化を成功させる鍵です。以下に、2つの主要モデルの詳細な比較を示します。
Sora 2 と Veo 3.1 のコア機能比較
| 比較項目 | Sora 2 | Veo 3.1 | マンガ動画制作のアドバイス |
|---|---|---|---|
| 最大秒数 | 15-25 秒 | 8-15 秒 | Sora 2 は長回しカット向き |
| キャラクターの一貫性 | Character Cameo ネイティブ対応 | 複数参考画像スキーム | Sora 2 の方が安定 |
| 音声生成 | 別途アフレコが必要 | ネイティブオーディオ対応 | Veo 3.1 の方が効率的 |
| 出力解像度 | 1080p | 4K | Veo 3.1 の画質がより優れている |
| 縦向き対応 | 後編集でクロップが必要 | ネイティブ対応 | Veo 3.1 の方がショート動画向き |
| スタイルプリセット | Comic/Anime プリセット | Style Reference | それぞれに強みあり |
| 生成速度 | 中程度 | 30-60秒/本 | Veo 3.1 の方がやや速い |
| API の安定性 | 高い | 高い | どちらも商用利用可能 |
マンガ動画制作のシーン選択ガイド
Sora 2 を選択すべきシーン:
- 厳密なキャラクターの一貫性が求められる連続したストーリー
- 長回しの叙事詩的シーン(10 秒以上)
- 複雑なキャラクター同士の掛け合いシーン
- すでに成熟したアフレコ・ワークフローがある場合
Veo 3.1 を選択すべきシーン:
- 4K 高画質出力を追求する場合
- ショート動画プラットフォーム向けコンテンツ(TikTok、YouTube ショートなど)
- ネイティブオーディオによる迅速な制作が必要な場合
- 縦向きコンテンツがメインのプロジェクト
ハイブリッド活用戦略:
大規模なマンガ動画プロジェクトでは、シーンの特性に合わせて2つのモデルを使い分けることをお勧めします:
- 主要キャラクターのシーン → Sora 2(一貫性の確保)
- 環境・風景カット → Veo 3.1(高画質+音響効果)
- 会話シーン → Veo 3.1(ネイティブオーディオ)
- アクションシーン → Sora 2(長時間のサポート)
🎯 モデル切り替えのアドバイス:APIYI (apiyi.com) の統一インターフェースを使用すれば、同一プロジェクト内で Sora 2 と Veo 3.1 を柔軟に切り替えることができます。コード構造を変更する必要はなく、モデルのパラメータを変更するだけで対応可能です。
よくある質問
Q1: Sora 2 と Veo 3.1、マンガ動画の量産にはどちらが適していますか?
両者にはそれぞれの強みがあります。Sora 2 の「Character Cameo」機能はキャラクターの一貫性を保つ点で非常に優れており、特定のキャラクターが登場し続ける連続したストーリー展開に適しています。一方、Veo 3.1 はネイティブでのオーディオ生成と 4K 出力に対応しており、画質と制作スピードを重視するショート動画プロジェクトに向いています。具体的なニーズに合わせて、これらを組み合わせて使用することをお勧めします。
Q2: マンガ動画を量産する場合、コストはどのくらいかかりますか?
AI を活用したマンガ動画の量産では、1話(3〜5分)あたりのコストを 50〜200 元(約 1,000〜4,000 円)程度に抑えることが可能です。これは主にシーン数、解像度の設定、使用するモデルのランクによって変動します。従来の制作手法と比較して 90% 以上のコスト削減が期待できます。また、APIYI(apiyi.com)などのアグリゲータープラットフォームを利用することで、さらなるボリュームディスカウントを受けることも可能です。
Q3: マンガ動画の量産をすぐに始めるにはどうすればよいですか?
以下のステップで素早く開始することをお勧めします:
- APIYI(apiyi.com)にアクセスしてアカウントを登録し、API キーを取得する
- 主要なキャラクターの参考画像を 2〜3 枚用意する
- 構造化された絵コンテ(まずは 5〜10 シーン程度)を作成する
- 本記事で提供しているコード例を使用して、テスト生成を行う
- 生成結果に基づいてプロンプトやパラメータを調整する
Q4: マンガ動画の制作ワークフローでキャラクターの一貫性を保つには?
核心となる方法は以下の通りです:Sora 2 の「Character Cameo」を使用してキャラクター ID を作成する、各キャラクターの多角的な参考画像を用意する、プロンプト内でキャラクターの説明を一貫させる、固定のスタイルプリセットを使用する。本格的な制作に入る前に、3〜5 つのテストシーンを生成して一貫性を検証することをお勧めします。
まとめ
マンガ動画量産の核心となるポイント:
- ワークフローの標準化:脚本から配信までの完全なマンガ動画制作ワークフローを構築し、各工程のインプットとアウトプットを明確にする。
- モデル選定戦略:キャラクターの一貫性を重視する場合は Sora 2、画質やオーディオを重視する場合は Veo 3.1 を選ぶなど、シーンに応じて柔軟に切り替える。
- バッチ自動化:API を通じてタスクを一括送信することで、50 シーンの生成時間を 1 時間以内に短縮する。
- コストの最適化:必要に応じて解像度やモデルのランクを選択し、アグリゲータープラットフォームを活用してボリュームディスカウントを得る。
AI によるマンガ動画の量産技術は急速に成熟しています。Sora 2 や Veo 3.1 の核心的な能力をマスターし、効率的な制作ワークフローを構築することが、このコンテンツブームの波を捉える鍵となります。
統一されたビデオモデル API インターフェースを提供する APIYI(apiyi.com)の利用をお勧めします。このプラットフォームは Sora 2 や Veo 3.1 などの主要モデルをサポートしており、無料のテスト用クレジットやテクニカルサポートも提供されています。
参考文献
⚠️ リンク形式の説明: すべての外部リンクは、コピーしやすく、かつSEOウェイトの流出を防ぐためにクリック不可の
資料名: domain.com形式を使用しています。
-
OpenAI Sora 公式ドキュメント: Sora 2 機能紹介およびAPI利用ガイド
- リンク:
help.openai.com/en/articles/12593142-sora-release-notes - 説明: 公式 Character Cameo 機能の詳細解説
- リンク:
-
Google Veo 公式ページ: Veo 3.1 モデル紹介
- リンク:
deepmind.google/models/veo - 説明: 4K出力と音声生成機能の説明
- リンク:
-
AI Comic Factory: オープンソース漫画生成プロジェクト
- リンク:
github.com/jbilcke-hf/ai-comic-factory - 説明: LLM + SDXLによる漫画生成の実装リファレンス
- リンク:
-
Hugging Face AI Comic: 漫画生成技術ブログ
- リンク:
huggingface.co/blog/ai-comic-factory - 説明: バッチ生成とAPI統合の技術的な詳細
- リンク:
著者: 技術チーム
技術交流: コメント欄でのマンガ動画の大量制作に関する実践経験の議論を歓迎します。AI動画生成に関するさらなる資料は、APIYI apiyi.com 技術コミュニティをご覧ください。