2026年6月1日,MiniMax正式发布了全新的开源旗舰模型——MiniMax-M3。这是业界首个在单一模型中同时实现三大突破的开放权重模型:前沿级的编程能力、100万token的上下文窗口,以及原生的多模态输入。在SWE-Bench Pro测试中,它取得了59.0分,直接超越了GPT-5.5和Gemini 3.1 Pro,并逼近Claude Opus 4.7的水平。
更具冲击力的是其定价。官方标准价为输入$0.60 / 输出$2.40(每1M tokens),仅为同级闭源模型的5%-10%;发布期间更有限时5折优惠,降至输入$0.30 / 输出$1.20。目前,MiniMax-M3已同步上线APIYI(apiyi.com)平台,不仅对齐官网的5折优惠,叠加充值赠送后,实际成本最低可达约4.1折。活动截止时间为6月8日零点(UTC+8)。
本文将详细解析MiniMax-M3的架构亮点、基准测试成绩、价格阶梯及接入代码,帮助您在活动期间判断是否值得切换至该模型。

MiniMax-M3 是什么:开源阵营的“三合一”旗舰
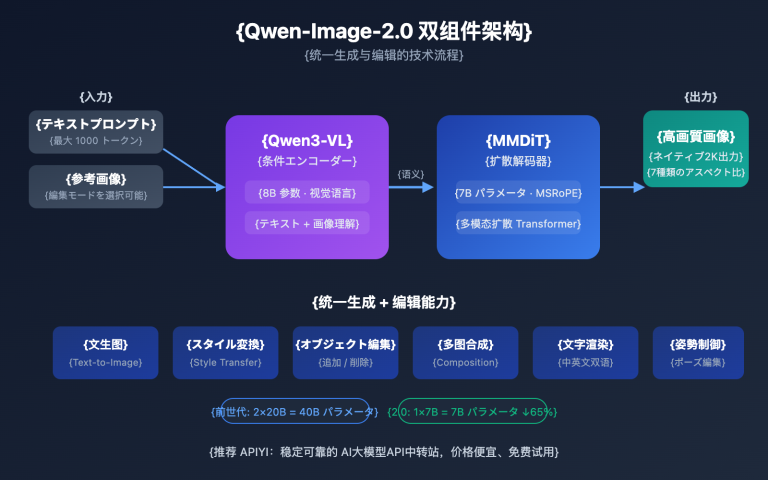
MiniMax-M3 是 MiniMax 继 M2 系列之后的新一代旗舰,定位是面向编程和 Agent 场景的通用模型。它采用细粒度 MoE(混合专家)架构,总参数约 229.9B,每个 token 仅激活约 9.8B 参数,分布在 256 个专家上。这意味着它在推理成本上更接近一个 10B 级别的小模型,能力上却对标第一梯队旗舰。
训练数据规模约 100 万亿 tokens,并且从预训练阶段就混入了图文交错数据。因此,MiniMax-M3 的多模态是“原生”的——图像、视频理解能力直接长在语义空间里,而不是后期外挂视觉编码器拼接出来的。除了图片和视频输入,它还支持桌面计算机操作(Computer Use),为 Agent 场景留足了接口。
官方承诺模型权重和技术报告将在发布后 10 天内完全开源,届时可以在 HuggingFace 与 GitHub 获取,支持私有化部署和微调。参考此前 M2 系列采用的修改版 MIT 许可,商用门槛预计很低,具体以正式发布的许可证为准。
MiniMax-M3 核心规格一览
| 维度 | MiniMax-M3 规格 |
|---|---|
| 发布时间 | 2026 年 6 月 1 日 |
| 架构 | 细粒度 MoE,总参数 229.9B / 激活 9.8B,256 专家 |
| 注意力机制 | MSA(MiniMax Sparse Attention)稀疏注意力 |
| 上下文窗口 | 1,000,000 tokens(约为 M2 系列的 5 倍) |
| 模态支持 | 文本 + 图像 + 视频输入,文本输出,支持桌面操作 |
| 训练数据 | 约 100T tokens,图文交错多模态语料 |
| 思考模式 | 可开关的 Thinking 模式,价格一致 |
| 开源计划 | 发布后 10 天内开放权重与技术报告 |
🎯 快速体验建议:想第一时间验证 MiniMax-M3 的真实水平,不必等权重放出再自建集群。我们建议直接通过 APIYI(apiyi.com)的 OpenAI 兼容接口调用,模型名填
MiniMax-M3即可,几分钟就能跑通对比测试,活动期间成本还能再砍一半。
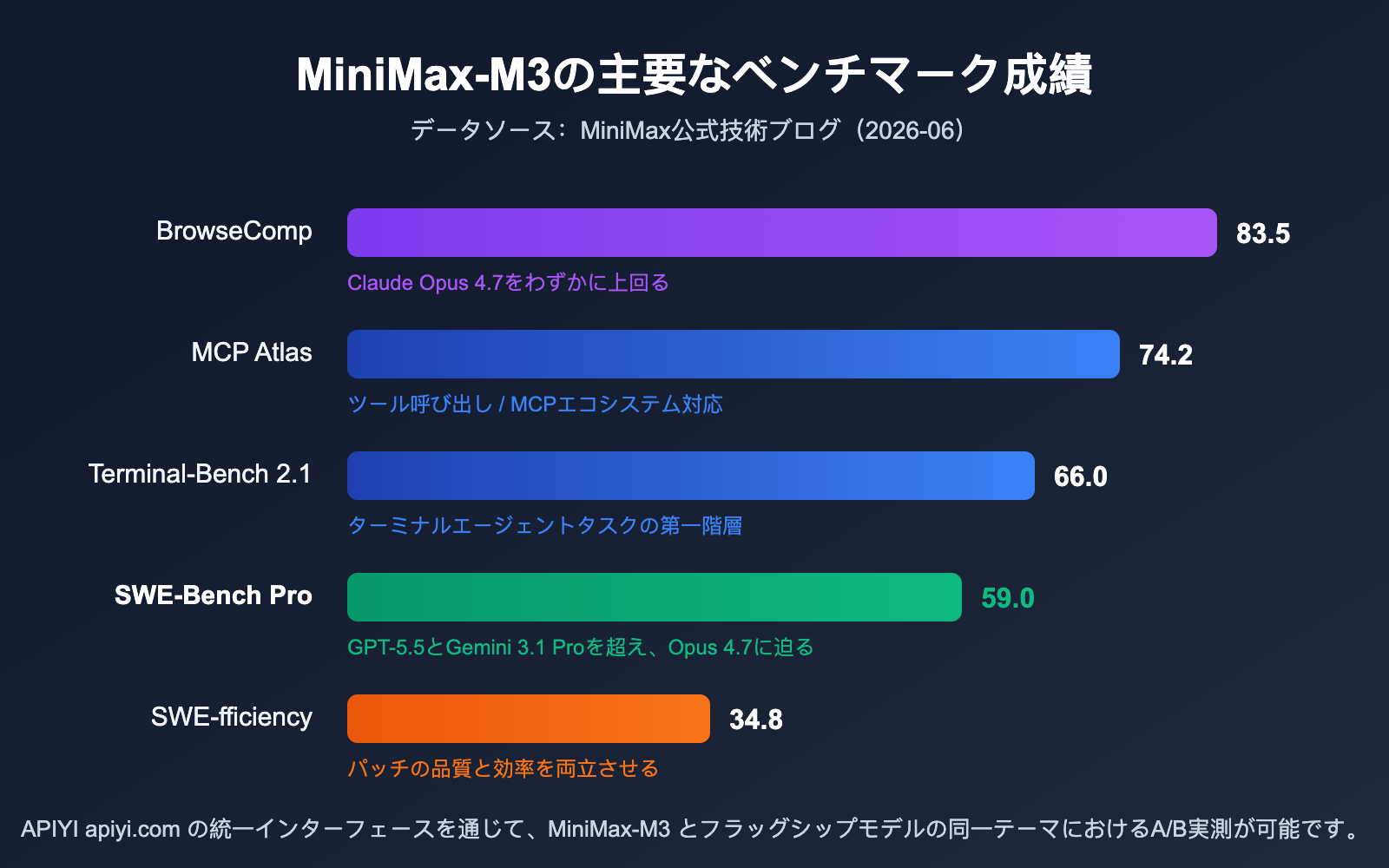
MiniMax-M3 ベンチマークスコア:SWE-Bench Pro 59.0 が意味するもの
SWE-Bench Pro は、現在最も難易度が高いとされる実戦的なソフトウェアエンジニアリングのベンチマークの一つであり、モデルが実際のコードリポジトリでバグを修正し、パッチを適用するエンドツーエンドの能力を測定します。MiniMax-M3 が記録した 59.0 点というスコアは、公式の比較データによると GPT-5.5 や Gemini 3.1 Pro を上回り、Claude Opus 4.7 に肉薄する数値です。まもなくオープンソース化される、アクティブパラメータ数 10B 未満のモデルとしては、オープンソース陣営がこのベンチマークでクローズドソースのフラッグシップモデルを上回った初めてのケースとなります。
プログラミング以外でも、エージェント関連の指標は非常に優秀です。Terminal-Bench 2.1 で 66.0 点、MCP Atlas で 74.2 点、自律ブラウジングタスクの BrowseComp では 83.5 点を記録しました。特に最後の項目については、Claude Opus 4.7 をわずかに上回っています。マルチモーダル面では、SVG-Bench で Opus 4.7 を超え、ドキュメント理解のベンチマークである OmniDocBench でも Gemini 3.1 Pro を上回る結果となりました。
もちろん、すべてにおいて圧倒しているわけではありません。科学研究の事後学習能力を測定する PostTrainBench では、MiniMax-M3 は 0.37 点となり、Claude Opus 4.7 の 0.42 点には及ばず、GPT-5.5 の 0.39 点とほぼ同水準でした。一点注意が必要なのは、これらの数値は現時点では公式の技術ブログによるものであり、第三者による独立した再検証が進行中であるという点です。重要な業務での利用を検討される場合は、ご自身で評価を実行し確認することをお勧めします。
MiniMax-M3 と主要フラッグシップモデルの比較
| ベンチマーク | MiniMax-M3 | 比較結果 |
|---|---|---|
| SWE-Bench Pro | 59.0 | GPT-5.5、Gemini 3.1 Pro を上回り、Opus 4.7 に肉薄 |
| Terminal-Bench 2.1 | 66.0 | ターミナルエージェントタスクで第一線級 |
| BrowseComp | 83.5 | Claude Opus 4.7 をわずかに上回る |
| MCP Atlas | 74.2 | ツール呼び出しと MCP エコシステムへの適応力が高い |
| SWE-fficiency | 34.8 | パッチの品質と効率を両立 |
| PostTrainBench | 0.37 | Opus 4.7 (0.42) 未満、GPT-5.5 (0.39) と同等 |
これらの数値を横断的に検証したい場合は、APIYI プラットフォーム上で同じプロンプトを使用して、MiniMax-M3、GPT-5.5、Claude Opus 4.7 を同時に呼び出すことができます。プラットフォーム側でインターフェース形式が統一されているため、モデルの切り替えは model パラメータを変更するだけで済み、A/B テストに最適です。
MiniMax-M3 アーキテクチャ解析:MSA 疎なアテンションが 1M コンテキストを支える仕組み
100 万トークンのコンテキスト自体は珍しくありませんが、それを経済的に実現している点が画期的です。MiniMax-M3 の答えは、自社開発の MSA(MiniMax Sparse Attention)にあります。従来型の全量アテンションの計算量はコンテキスト長の二乗で増加しますが、MSA は KV キャッシュをブロック単位に分割し、各クエリが最も関連性の高い KV ブロックのみを正確に検索することで、より高い有効コンテキストカバレッジを実現しました。
公式が発表したエンジニアリングデータは非常に意欲的です。1M トークンのコンテキスト下において、MiniMax-M3 のトークンあたりの計算量は前世代の M2 の 1/20 に抑えられています。プリフィル(prefill)は 9 倍以上、デコード(decode)は 15 倍以上の高速化を実現し、演算子レベルではオープンソースの Flash-Sparse-Attention よりも 4 倍高速です。言い換えれば、コードリポジトリ全体や数百ページの PDF、あるいは 1 時間の会議動画をコンテキストに放り込んでも、遅延やコストが障壁になることはありません。
開発者にとっての直接的なメリットは、これまで RAG によるチャンク分割やベクトル検索、複数回の要約が必要だった長文ドキュメントタスクを、そのままプロンプトに「一括投入」できるようになったことです。長距離のエージェントタスクにおいても、頻繁に履歴を圧縮する必要がなくなり、タスクの連続性が著しく向上します。
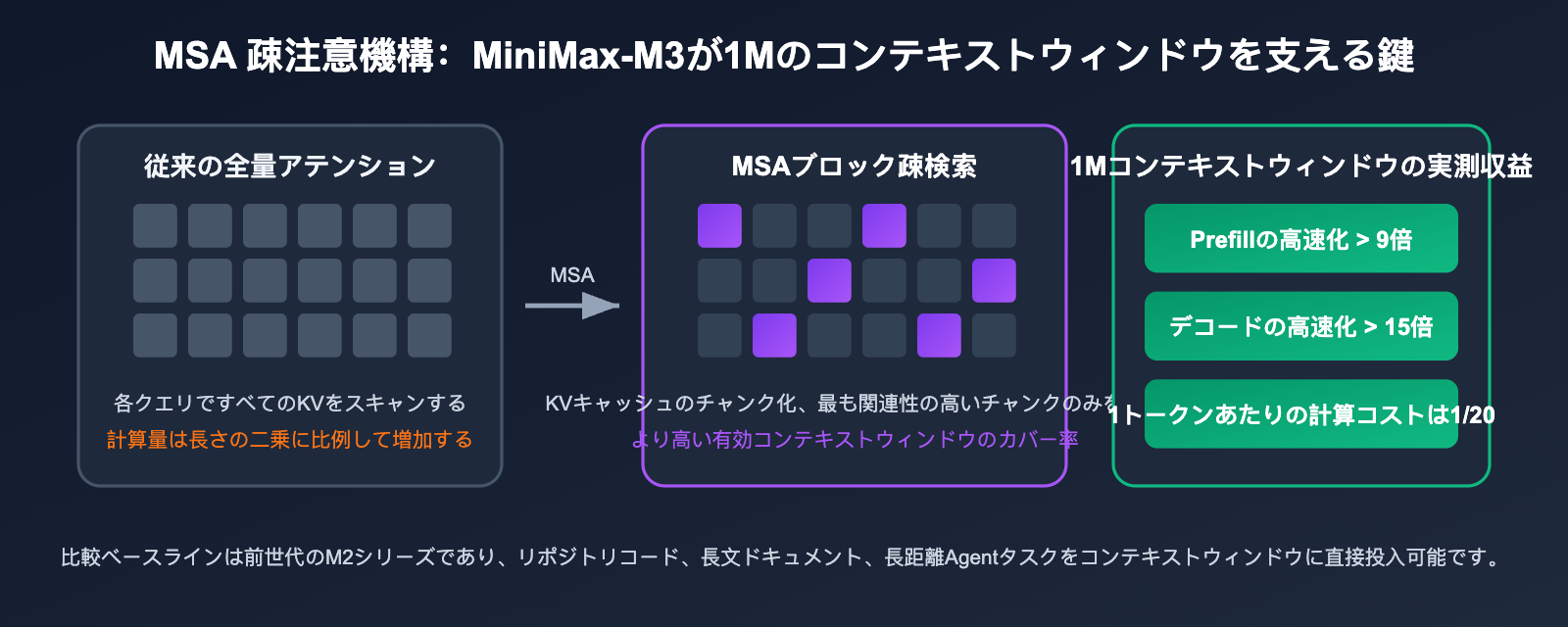
💡 長コンテキスト実測のヒント:1M コンテキストの課金は 2 段階制となっており、入力が 512K を超えると単価が倍になります。APIYI (apiyi.com) のコンソールで、まずは 200K〜400K 規模の実際のドキュメントで効果をテストし、品質が基準を満たしていることを確認してから、より長い入力を試すことをお勧めします。プラットフォームの利用量統計機能を使えば、呼び出しごとのトークンコストを正確に算出できます。
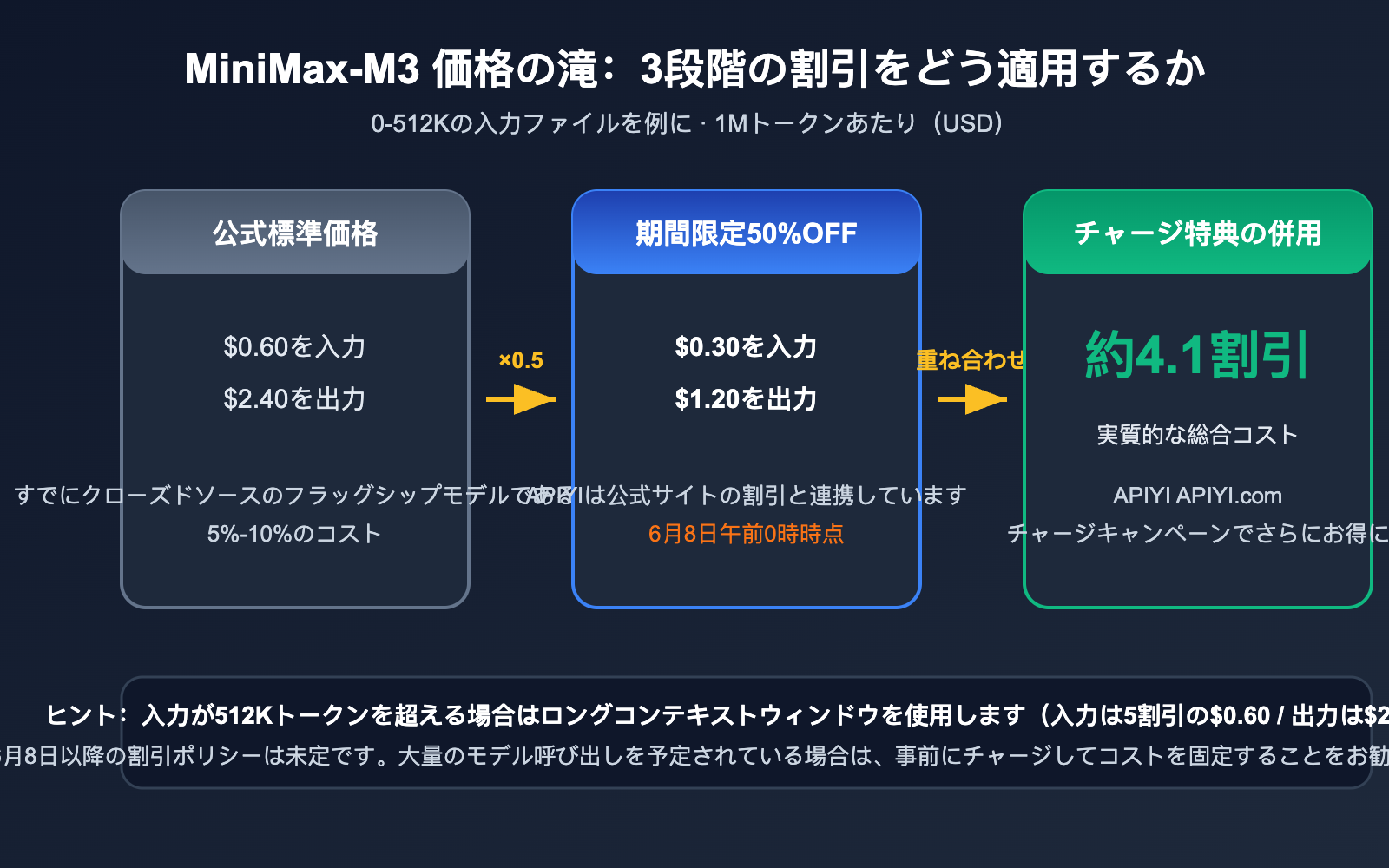
MiniMax-M3 API 価格:期間限定 50% OFF + チャージ特典で実質約 41% OFF
MiniMax-M3 の料金体系は、入力長に応じた段階的なモデルを採用しています。0〜512K トークンの入力は標準レート、512K トークンを超える入力は長文コンテキストレートが適用されます。リリース記念として全ラインナップが 50% OFF となっており、APIYI (apiyi.com) でも公式の割引価格を即時反映しています。このキャンペーンは 2026 年 6 月 8 日午前 0 時(UTC+8)まで実施され、それ以降の割引ポリシーは未定です。
MiniMax-M3 API 料金表(1M トークンあたり)
| 料金区分 | 入力(50% OFF 現行価格) | 出力(50% OFF 現行価格) | 通常価格(入力/出力) |
|---|---|---|---|
| 0-512K 入力 | $0.30 | $1.20 | $0.60 / $2.40 |
| 512K 以上入力 | $0.60 | $2.40 | $1.20 / $4.80 |
この価格を具体的にイメージしてみましょう。100 万トークン規模のコードレビュータスクをフラッグシップモデルで実行する場合、通常は十数ドルかかりますが、MiniMax-M3 のキャンペーン価格ならわずか 1 ドル以下となり、コストを 10〜20 分の 1 に抑えられます。高頻度で呼び出す Agent パイプライン、大量のコード移行、長文ドキュメント処理などの用途では、この差額だけで 1 ヶ月で開発用マシンが 1 台買えるほどの節約になります。
APIYI プラットフォームでは、さらにコストを抑えることが可能です。プラットフォームのチャージ特典(ボーナス付与)と 50% OFF のモデル価格を組み合わせることで、実質コストを最大で約 41% OFF まで引き下げられます。チームで安定したモデル呼び出し量が見込まれる場合は、6 月 8 日までにチャージを済ませるのが最も賢い選択です。
MiniMax-M3 API クイックスタート:5 分で接続完了
MiniMax-M3 は APIYI プラットフォーム上で標準の OpenAI 互換プロトコルを採用しているため、カスタム base_url をサポートするあらゆる SDK、フレームワーク、クライアントからシームレスに接続可能です。唯一の注意点は、モデル名 MiniMax-M3 は大文字と小文字を厳密に区別することです。M は必ず大文字にする必要があり、minimax-m3 と記述するとモデルが存在しないというエラーが発生します。
接続は 3 ステップで完了します:APIYI (apiyi.com) に登録して API キーを作成し、base_url を https://api.apiyi.com/v1 に設定し、model パラメータに MiniMax-M3 を指定するだけです。以下にシンプルな Python のサンプルコードを示します。
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI 共通インターフェース
)
response = client.chat.completions.create(
model="MiniMax-M3", # 大文字小文字に注意、M は必ず大文字
messages=[
{"role": "user", "content": "Python で LRU キャッシュ付きのフィボナッチ関数を実装してください"}
]
)
print(response.choices[0].message.content)
画像や動画を送信する場合は、OpenAI のマルチモーダルメッセージ形式をそのまま利用し、content を image_url を含む配列に変更してください。MiniMax-M3 は同一セッション内で視覚理解とコード生成を完結させます。Cline、Cursor、OpenClaw などの Agent ツールも、設定画面で base_url とモデル名を変更するだけで、プログラミングアシスタントの基盤を MiniMax-M3 に切り替えることができます。
MiniMax-M3 適用シナリオ早見表
| シナリオ | 適合度 | 説明 |
|---|---|---|
| Agent プログラミング / 自動バグ修正 | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0、長タスクでもコンテキストを維持 |
| リポジトリ全体のコード分析と移行 | ⭐⭐⭐⭐⭐ | 1M のコンテキストで中規模リポジトリ全体を収容可能 |
| 長文ドキュメント / マルチモーダル解析 | ⭐⭐⭐⭐⭐ | OmniDocBench で Gemini 3.1 Pro を上回る性能 |
| 自律ブラウジングとツール呼び出し Agent | ⭐⭐⭐⭐ | BrowseComp 83.5、MCP Atlas 74.2 |
| 研究用後学習 / 先端推論 | ⭐⭐⭐ | PostTrainBench は Opus 4.7 に劣るため、混合運用を推奨 |
混合運用はより現実的な活用方法です。日常的な高頻度のコーディングやドキュメントタスクは MiniMax-M3 に 80% の呼び出し量を任せ、最も難易度の高い推論タスクは Claude Opus 4.7 や GPT-5.5 に割り当てます。APIYI の共通インターフェースを通じてモデルルーティングを行えば、複数のベンダーのキーや SDK を管理することなく、コードベースだけでこのような「コストパフォーマンスを最適化した階層化」戦略を実現できます。
MiniMax-M3 よくある質問(FAQ)
Q1:MiniMax-M3 の50%OFFキャンペーンはいつ終了しますか?
キャンペーンは2026年6月8日午前0時(UTC+8)に終了します。これはAPIYIプラットフォームとMiniMax公式サイトで共通です。それ以降の割引ポリシーは公式から発表されていませんが、慣例通り標準価格に戻る可能性があります。大量のモデル呼び出しを予定されている場合は、終了前にチャージを完了させることをお勧めします。チャージ時のボーナスを組み合わせることで、実質コストを最大約59%OFF(約4.1割の価格)まで抑えることが可能です。
Q2:MiniMax-M3 は本当にオープンソースですか?今すぐウェイト(重み)をダウンロードできますか?
公式はリリース後10日以内にモデルのウェイトと技術レポートを公開すると約束しており、HuggingFaceのMiniMaxAIページで公開される予定です。本記事執筆時点では、ウェイトのアップロードは完了していません。自前でのデプロイを急ぐチームは、まずAPIで効果を検証し、ウェイト公開後にプライベート環境への移行に必要なハードウェア投資を評価することをお勧めします。230Bの総パラメータを持つMoEモデルであるため、ローカルデプロイにはかなりのビデオメモリ(VRAM)が必要です。
Q3:1Mのコンテキストウィンドウは宣伝文句ですか、それとも実用的ですか?
MSAアーキテクチャにより、1Mのコンテキストはエンジニアリングの観点から実用レベルに達しています。プリフィル(prefill)は9倍以上、デコード(decode)は15倍高速化され、1トークンあたりの計算量は前世代の20分の1に削減されました。ただし、料金体系には注意が必要です。入力が512Kを超えると単価が倍になるため、無闇に詰め込むのではなく、タスクの実際の必要性に応じてコンテキストの長さを調整することをお勧めします。
Q4:MiniMax-M3 と GPT-5.5、Claude Opus 4.7 はどう選べばいいですか?
タスクの種類と予算で判断してください。プログラミングエージェント、長大なコンテキスト、マルチモーダルドキュメントの処理においては、現時点でMiniMax-M3のコストパフォーマンスに敵うものはありません。一方で、最高レベルの複雑な推論や科学研究タスクでは、依然としてOpus 4.7に優位性があります。実際の業務で使用するプロンプトを使い、APIYIプラットフォームで小規模な比較テストを行うことをお勧めします。どのような評価ランキングよりも、自社のデータが最も説得力を持つはずです。
まとめ:MiniMax-M3 がフラッグシップ級の性能を「破格」で提供
MiniMax-M3のリリースは、2026年のAIモデル市場に大きな衝撃を与えました。オープンソースのウェイト、SWE-Bench Proで59.0を記録しGPT-5.5を上回る性能、100万トークンのコンテキスト、そしてネイティブマルチモーダル対応。これらを、クローズドなフラッグシップモデルのわずか5%〜10%という公式価格で実現しています。今後、第三者による再テストでスコアが多少変動したとしても、「コストパフォーマンス」という側面におけるその圧倒的な存在感は揺るぎないでしょう。
短期的に最も重要なのは価格の窓口です。期間限定の50%OFF(入力 $0.30 / 出力 $1.20 per 1M tokens)は6月8日午前0時までとなっており、APIYI(apiyi.com)のチャージキャンペーンを併用すれば、実質約4.1割のコストで利用可能です。まずは最小限のコストで評価を走らせ、その後に本番環境への移行を判断するのが、現時点での最も賢明な戦略です。
キャンペーンの詳細や最新のモデル動向については、APIYIの公式アナウンスをご確認ください: docs.apiyi.com/news/minimax-m3-launch
著者: APIYI Team
AI大規模言語モデルAPIの集約とベストプラクティスを専門としています。その他のモデル評価や接続ガイドについては、APIYI(apiyi.com)をご覧ください。