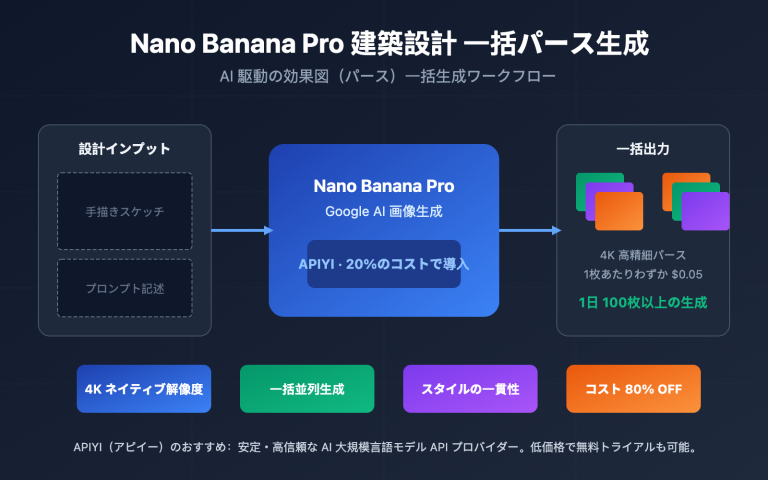
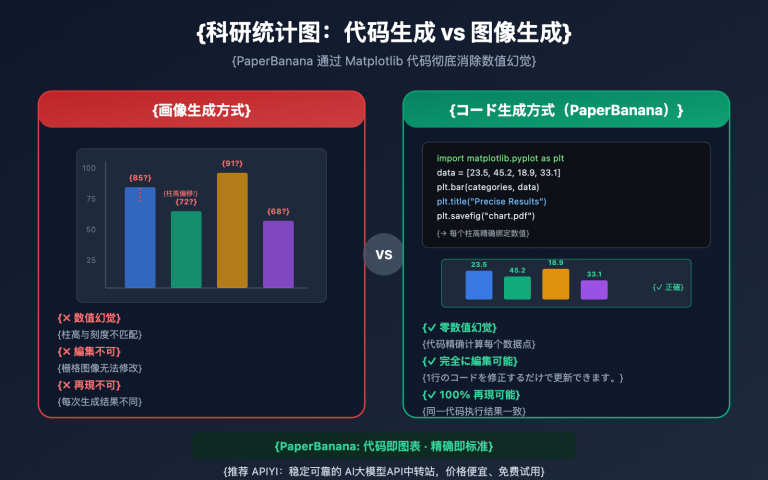
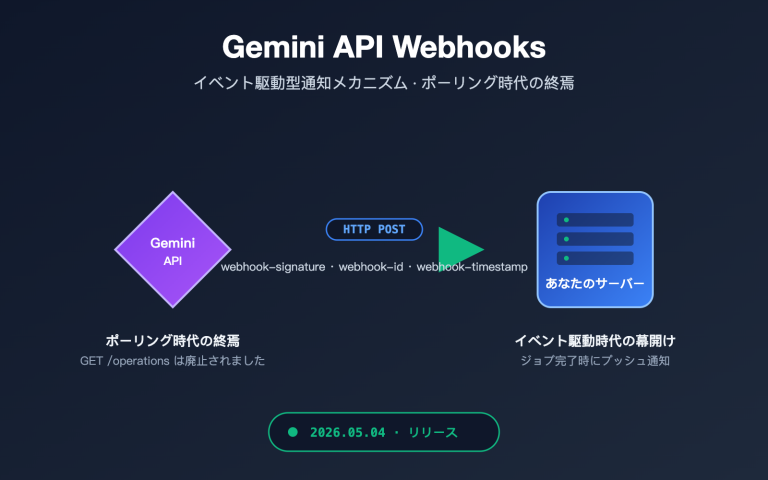
企業ユーザーが Gemini や Nano Banana Pro といった Google のモデルの導入を検討する際、「Provisioned Throughput (PT)」 という言葉は頻繁に耳にする一方で、誤解も非常に多い用語です。「PT は AI Studio のエンタープライズ版なの?」「PT は Gemini API の優先順位を買うもの?」「PT を買えば単価が安くなるの?」といった疑問がよく寄せられます。
これらの問いに対する答えは、直感とは少し異なります。本記事では、Google Cloud Vertex AI の最新の公式ドキュメントに基づき、PT について徹底解説します。PT は AI Studio ではなく Vertex AI の体系に属すること、その計測単位は GSU (Generative AI Scale Unit) であること、単価を下げるものではなく、スループットの優先度を保証するものであること、そしてそれに対応する従量課金メカニズムは DSQ (Dynamic Shared Quota) と呼ばれることなど、その全貌を明らかにします。
これらの概念を理解することは、企業として PT を導入すべきかどうかの判断だけでなく、自社での Google API 構築、PT サブスクリプションの利用、あるいは APIYI (apiyi.com) のようなアグリゲーションプラットフォームを通じた導入という3つの選択肢を合理的に比較検討する助けとなるはずです。

Google Provisioned Throughput (PT) とは
Provisioned Throughput (PT) は、Google Cloud Vertex AI プラットフォームが生成 AI モデル向けに提供する、固定コスト・固定期間のスループット予約サブスクリプションです。その核心的なロジックは、「企業が一定の処理能力を事前に購入することを約束し、Google がその分の計算リソースを個別に確保することで、呼び出し時のスループットの確実性と優先順位を保証する」というものです。
PT の公式定義と主な特徴
Google Cloud の公式ドキュメントによると:
Provisioned Throughput (PT) は、Vertex AI 上でサポートされている生成 AI モデルのスループットを予約するための、固定コスト・固定期間のサブスクリプションです。
この定義に含まれる3つのキーワードを分解します:
- Fixed-cost (固定コスト):実際の呼び出し量に関係なく、約束した分を前払いします。
- Fixed-term (固定期間):1週間 / 1ヶ月 / 3ヶ月 / 1年 の4つから選択します。
- Reserves throughput (スループットの予約):「計算リソース」そのものではなく、「1秒あたりのトークン処理能力」を予約します。
PT ではないもの:3つの誤解を解消
| よくある誤解 | 事実 |
|---|---|
| 「PT = AI Studio のエンタープライズ版」 | ❌ PT は Vertex AI にのみ存在し、AI Studio とは直接関係ありません |
| 「PT を買えば単価が安くなる」 | ❌ PT は単価を下げません。スループットの保証と優先順位を提供するものです |
| 「PT はいつでもキャンセルできる」 | ❌ 契約期間中はキャンセル不可です。GSU の追加のみ可能です |
| 「PT で GPU を独占できる」 | ❌ PT が予約するのはスループットユニット (GSU) であり、ハードウェアの独占ではありません |
| 「PT はすべての Google モデルに適用される」 | ❌ 一部のモデルのみが対象です。サポートリストを確認してください |
💡 導入シーンのアドバイス:もし貴社の主な目的が「スループットの保証」ではなく「単価の削減」である場合、PT は適していません。その場合は、APIYI (apiyi.com) の企業向けプランを通じて Gemini シリーズ(Nano Banana Pro を含む)を導入する方が経済的です。公式価格の最大 37% 程度のコストで利用可能であり、日本円での決済や適格請求書(インボイス)にも対応しています。
GSU(Generative AI Scale Unit)測定単位の解説
PT(Provisioned Throughput)を理解するためには、まずその測定単位である GSU について理解する必要があります。
GSU の公式定義
GSU とは、抽象化されたスループット容量単位です。PT をサポートするすべての Google モデル間で価格と容量が固定されていますが、モデルによって GSU を消費する効率が異なります。言い換えれば:
- 1 GSU の価格はすべてのモデルで一律です
- 1 GSU の**容量(1秒あたりのトークン処理数)**もすべてのモデルで一律です
- しかし、同じ 1 GSU でサポートできるモデルの実際の呼び出し回数は、モデルごとに異なります
GSU とモデルの対応関係の例
下表はイメージ図です(具体的な数値は Google の最新データをご確認ください):
| モデル | 1 GSU あたりのスループット | 説明 |
|---|---|---|
| Gemini 2.5 Flash-Lite | 高い | 軽量モデル、1 GSU でより多くのリクエストを処理可能 |
| Gemini 2.5 Flash | 中程度 | バランス型、多くの企業で採用 |
| Gemini 2.5 Pro | 低い | フラッグシップモデル、GSU 消費量が多い |
| Gemini 3 Pro | 最低 | 新フラッグシップ、1リクエストあたりの GSU 消費が大 |
| Gemini 3 Pro Image | 画像サイズに応じて換算 | 4K 画像は 1K に比べ消費量が著しく高い |
つまり、業務で複数のモデルを併用する場合、共有の GSU プールではなく、各モデルに対応する GSU 枠をそれぞれ購入する必要があります。
必要な GSU 数の見積もり方法
Google は公式の GSU 計算機を提供していますが、見積もりの考え方は以下のように簡略化できます:
必要な GSU = (ピーク時の QPS × リクエストあたりの平均トークン数) / (1 GSU あたりのスループット容量)
企業の実際の見積もりステップ:
- 過去のピーク時 QPS(1秒あたりのリクエスト数)を測定する
- リクエストあたりの平均トークン消費量(入力 + 出力)を測定する
- 対象モデルの 1 GSU あたりのスループット量を確認する
- 切り上げて算出し、突発的な負荷に備えて 20〜30% のバッファを確保する
GSU の最小購入単位と段階設定
PT の注文は通常、特定の GSU 数から最小購入単位が設定されています(モデルやリージョンによって異なります)。企業契約後は以下の通りです:
- ✅ GSU の追加:業務拡大時にいつでもコミット量を増やすことが可能
- ❌ GSU の削減:契約期間中は減らすことは不可
- ⚠️ 更新時の調整:契約期間終了前にスケールの再評価が必要
Vertex AI と AI Studio:PT の所属関係の整理
ここが最も多くのお客様が混同される部分です。Google には2つの独立した生成 AI プロダクトラインが存在します:

Vertex AI:企業向け Google Cloud Platform プロダクト
- 所属:Google Cloud Platform (GCP)
- ターゲット:企業、大規模開発チーム、コンプライアンス要件が厳しい顧客
- 課金:GCP 請求書で一括管理。従量課金 (DSQ) + 予約 (PT) + バッチ (Batch) をサポート
- コンソール:console.cloud.google.com → Vertex AI メニュー
- API パス:
*-aiplatform.googleapis.com - PT サポート:✅ あり
- リージョン展開:✅ グローバルマルチリージョン対応
AI Studio:開発者および個人向け Gemini 入口
- 所属:Google AI for Developers(GCP とは独立)
- ターゲット:個人開発者、迅速なプロトタイプ検証、コンテンツ作成者
- 課金:Google Pay の個人向け決済アカウントによる従量課金
- コンソール:aistudio.google.com
- API パス:
generativelanguage.googleapis.com - PT サポート:❌ なし
- リージョン展開:❌ グローバル共通プール
両者の API 接続コードの違い
AI Studio (Gemini Developer API):
from google import genai
# AI Studio の個人用 APIキー
client = genai.Client(api_key="AIzaSy-xxx")
resp = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="茶色の猫"
)
Vertex AI:
from google import genai
client = genai.Client(
vertexai=True,
project="your-gcp-project", # GCP プロジェクト ID
location="us-central1" # リージョン
)
# 認証は gcloud ADC / Service Account で完了し、APIキーは不要
両者ではモデル名、認証方式、課金対象がすべて異なります。もし最初に AI Studio の APIキーを使用していた場合、いかなる方法でも PT を購入することはできません。GCP プロジェクトで Vertex AI を有効にし、サービスアカウントを通じて認証する必要があります。
🎯 接続のアドバイス:AI Studio と Vertex AI の境界、サービスアカウント認証、マルチリージョンルーティングなどの複雑な詳細を解決する手間を省きたい場合は、APIYI (apiyi.com) を通じて Gemini シリーズのモデルを統合的に接続することをお勧めします。OpenAI 互換フォーマットの
base_url+api_keyを使用でき、アカウント体系やルーティングの最適化は当社がすべて処理いたします。
DSQ (Dynamic Shared Quota) 従量課金メカニズムの詳細解説
DSQはVertex AIにおけるデフォルトの従量課金モードであり、圧倒的多数のユーザーが実際に利用している課金方式です。DSQを理解することは、PT(Provisioned Throughput)の優先的な価値を理解することに直結します。
DSQのコアメカニズム
With DSQ, there are no predefined quota limits on your usage. Instead, DSQ provides access to a large, shared pool of resources, dynamically allocated based on real-time availability of resources and real-time demand across all customers of that model.
(DSQでは、利用に対する事前のクォータ制限はありません。代わりに、モデルを利用するすべての顧客のリアルタイムの需要とリソースの利用状況に基づいて動的に割り当てられる、大規模な共有リソースプールへのアクセスを提供します。)
重要なポイント:
- 事前クォータ設定不要:QIR (クォータ増量リクエスト) の提出は不要です。
- 共有リソースプール:すべての従量課金ユーザーが同じ大規模プールを共有します。
- 動的な割り当て:世界中の顧客のリアルタイム需要に応じて再配分されます。
- スループットの変動:ピーク時には、各ユーザーが利用できるスループットが低下する可能性があります。
DSQとPTの優先順位関係
Googleは以下のように明言しています:
Provisioned Throughput customers are prioritized and serviced first before on-demand requests.
(プロビジョニングされたスループットを利用する顧客は優先され、オンデマンドリクエストよりも先に処理されます。)
これこそがPTの核心的価値であり、Google側のリクエストスケジューリングキューにおいて優先的に処理されるということです。具体的には:
- PTリクエスト → 専用の優先度が高いキューに入り、応答が安定する
- DSQリクエスト → 共有プールに入り、ピーク時には制限や待ちが発生する可能性がある
DSQで制限が生じやすいシーン
PTを購入していない企業は、以下のシーンでトラブルに遭遇しやすくなります:
- ECサイトのセール(0時ピーク):グローバル共有プールが混雑し、P99レイテンシが倍増する。
- ライブ配信のインタラクティブな画像生成:リアルタイム性が強く求められ、DSQの変動が許容できない。
- グローバル展開事業:複数地域からの同時呼び出しにより、地域間でDSQの容量に差が出る。
- 新モデル公開の初週:Google公式のクォータが完全開放されておらず、DSQが逼迫する。
ただし強調しておきたい点:月間呼び出し回数が5万回未満、あるいは月間の画像生成枚数が5万枚未満の中小企業であれば、DSQの安定性はすでに十分であり、PTの購入は過剰投資となる可能性があります。
PTのコミットメント期間オプションと購入プロセス
PTのコミットメント期間は、試験導入から長期契約まで幅広いニーズに対応できるように設計されています。
4種類のコミットメント期間比較
| 期間 | 代表的なシーン | 総コスト比 | 柔軟性 |
|---|---|---|---|
| 1週間 | 短期イベント/セール検証 | 基準 × 1 | 最高 |
| 1ヶ月 | 安定した月次業務計画 | ~基準 × 0.95 | 中程度 |
| 3ヶ月 | 四半期単位のビジネスコミット | ~基準 × 0.88 | 低め |
| 1年 | 長期契約+予算固定 | ~基準 × 0.75 | 最低 |
具体的な価格はGCPコンソールにログイン後に確認可能です。地域やモデルによって価格が異なります。
PTの購入ステップ
企業がPTを購入する標準的なフロー:
- ニーズの算出:Google公式のGSU計算ツールを使用して必要な容量を見積もる。
- GCPプロジェクトの作成:Vertex AI APIを有効にし、サービスアカウントを設定する。
- 購入申し込み:GCPコンソール → Vertex AI → Provisioned Throughputのページから注文する。
- パラメータの選択:モデル、リージョン、GSU数、コミットメント期間を選択。
- 財務承認:米ドル建てクレジットカードまたは企業向けACH支払い。
- アクティベーション:通常1〜5営業日以内に有効化される。
- API設定:コード内で
provisioned_throughput_idパラメータを追加し、PTチャンネルへ切り替える。
PTのAPI使用例
PTを有効にした後、呼び出しコードには明示的な指定が必要です:
from google import genai
from google.genai import types
client = genai.Client(
vertexai=True,
project="your-gcp-project",
location="us-central1"
)
resp = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="猫",
config=types.GenerateContentConfig(
# PTサブスクリプションIDを指定し、リクエストを優先チャンネルに流す
labels={"dedicated-capacity": "your-pt-subscription-id"}
)
)
このパラメータを指定しない場合、アカウントにPTサブスクリプションがあっても、リクエストはDSQチャンネルを経由します。
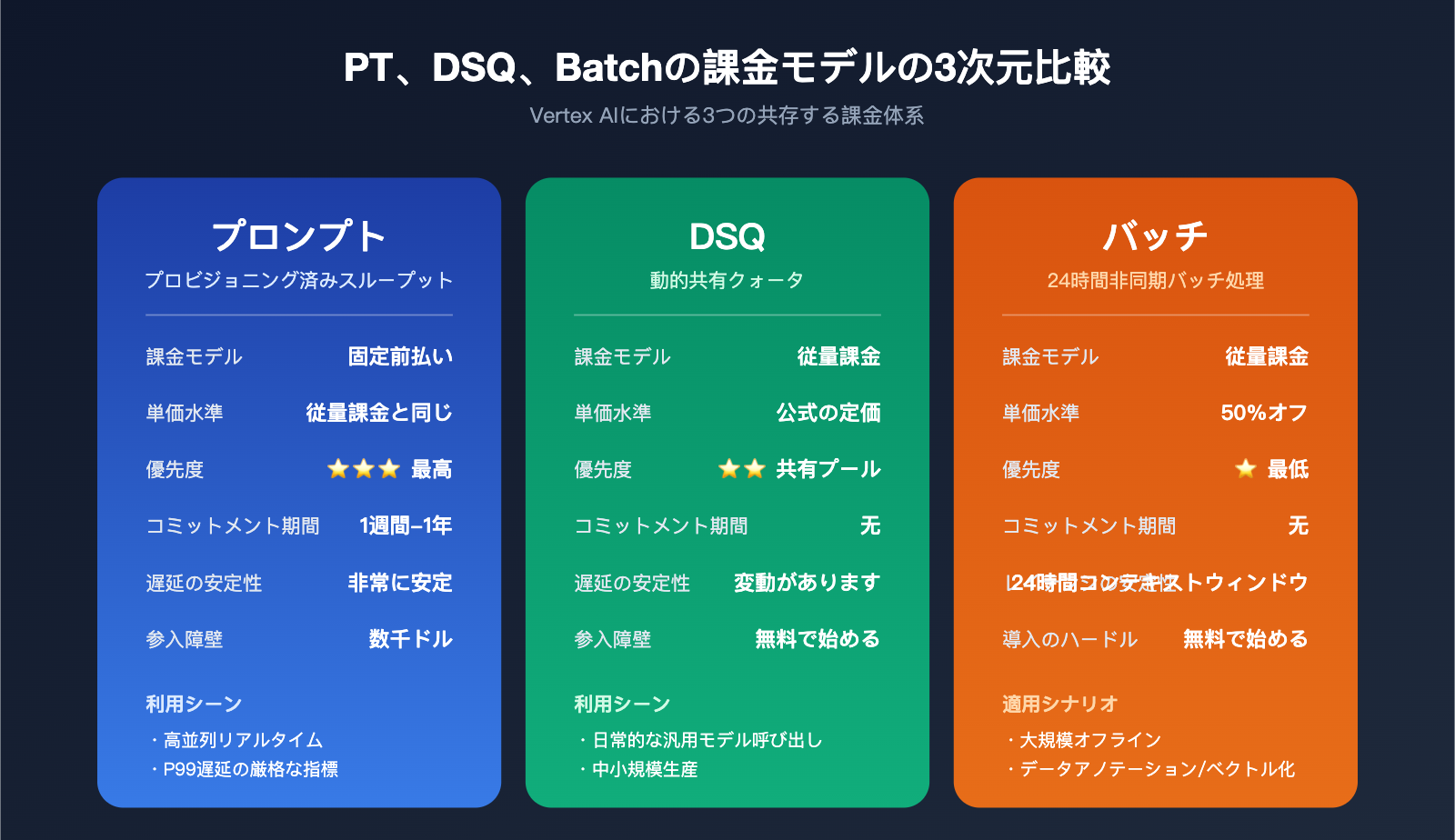
PTの3つの料金モデルの比較:PT vs DSQ vs Batch
Vertex AIが提供する3つの料金モデルについて、その境界線を理解することは企業の意思決定において不可欠です。
| 項目 | Provisioned Throughput (PT) | Dynamic Shared Quota (DSQ) | Batch API |
|---|---|---|---|
| 課金モデル | 固定前払い | 従量課金 | 従量課金 |
| 単価 | 従量課金と同じ | 公式定価 | 50%割引 |
| 優先度 | 最高(専有) | 共有プール | 最低(24時間枠) |
| コミットメント | 週/月/四半期/年 | なし | なし |
| 遅延 | 安定(低遅延) | 変動あり | 24時間非同期 |
| 適した用途 | 高並列リアルタイム処理 | 日常的な汎用処理 | 大規模オフライン処理 |
| 導入ハードル | 数千ドル〜 | 無料から開始可能 | 無料から開始可能 |
組み合わせ戦略:PT + DSQ + Batch
成熟した企業では、通常ハイブリッド課金アーキテクチャを採用しています:
- PTで基幹リアルタイム業務を保証:ライブ配信での画像生成やユーザー対話など
- DSQで日常的なトラフィックをカバー:大部分の非重要リクエストは従量課金で対応
- Batchで夜間大規模タスクを処理:レポート生成やデータアノテーションなど
⚡ ハイブリッド構成のアドバイス:チームが小規模で、複雑なマルチチャネル構築が難しい場合は、APIYI (apiyi.com) を通じた統合的なアクセスをお勧めします。当社のバックエンドではインテリジェントなルーティングを実装済みです。緊急リクエストはVIPチャネル、バッチタスクはBatchチャネル、日常の呼び出しは標準チャネルへ自動的に振り分けます。上位層からは透過的であり、単一のAPIキーでハイブリッド戦略のメリットを享受可能です。
PTの適用・非適用シナリオの詳細評価
PT購入が真に推奨される4つのケース
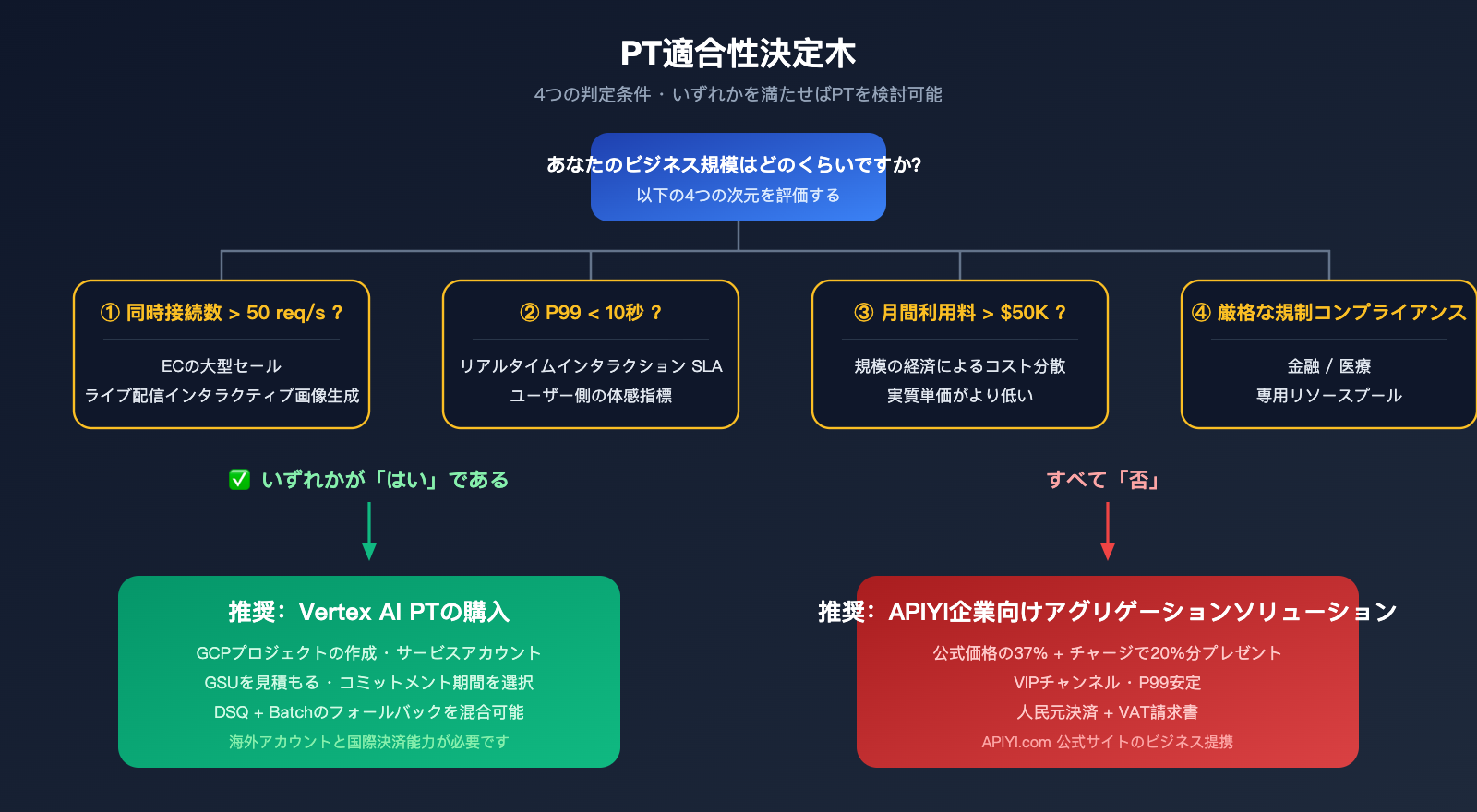
シナリオ1:高並列リアルタイム業務
ECサイトの大型セールや動画配信プラットフォーム、ライブ配信での対話型ツールなど、ピーク時の並列数が50リクエスト/秒を超える場合、DSQでは制限がかかる可能性があり、PTでの保証が不可欠です。
シナリオ2:P99遅延の厳格な要件
ユーザー体験のSLAとしてP99の初期応答時間を10秒以下に抑える必要がある場合(例:リアルタイムAI描画ツールなど)。DSQのP99は通常15〜30秒かかるため、要件を満たせません。
シナリオ3:月間消費額が閾値を超える場合
月間利用額が5万ドルを超える場合、PTの固定コミットコストは規模の経済によって希釈され、単位コストがDSQよりも低くなることがあります。この場合は、安定性を確保しつつコストも抑えられます。
シナリオ4:強固な規制・コンプライアンス要件
金融や医療業界など、リソースの占有やコンプライアンス声明が求められる場合、PTは明確なスループットの分離を保証します。
PTが不向きな5つのケース
- 月間呼び出し回数が5万回未満:PTの固定費が回収できず、従量課金の方が割安です。
- 業務量の変動が激しい:前払いコミットメントにより、リソースが無駄になる可能性が高いです。
- 単価の値下げのみが目的:PTは単価自体を下げるものではありません。アグリゲーターなどを活用した価格交渉を行うべきです。
- 複数モデルの混用:モデルごとに個別のGSUコミットメントが必要となり、運用負荷が増大します。
- 小規模チーム:長期的な米ドル建て契約を維持するための財務・運用リソースが不足しています。
PTが適していない場合は、APIYI (apiyi.com) を経由してGemini全シリーズのモデルにアクセスすることで、37%割引の企業向け価格が適用されます。さらにチャージによるボーナス特典(最大20%還元)を併用すれば、実質単価をGoogle公式の約32%まで抑えることが可能です。より低コストで、許容範囲内の安定性を確保できます。
よくある質問 (FAQ)
Q1:AI Studio で Gemini API Key を使って開発中ですが、PT を購入できますか?
購入できません。 AI Studio (Gemini Developer API) と Vertex AI はそれぞれ独立したシステムであり、PT (Provisioned Throughput) は Vertex AI 固有のものです。PT を利用するには、① GCP プロジェクトを作成し Vertex AI を有効化する、② Vertex AI のサービスアカウント認証方式へ移行する、③ API 呼び出しコードを一部書き換える、という手順が必要です。もしこの移行作業をスキップしたい場合は、APIYI (apiyi.com) を通じて OpenAI 互換の base_url を使用すれば、基盤となるアカウント体系を気にすることなく Gemini を呼び出すことができます。
Q2:PT を購入すると、従量課金よりも単価が安くなりますか?
単価自体は変わりませんが、「100万トークンあたり」の総コストに換算すると、大規模利用時には総合的なコストが抑えられる可能性があります。 具体的な仕組みとしては、PT は月額固定の利用コミットメント制です。GSU 容量を最大限活用できれば、実質的な有効単価は DSQ (Dynamic Shared Quota) の 80〜95% 程度になりますが、活用しきれない場合はかえって割高になります。PT の価値はコスト削減よりも、スループットの確保、レイテンシの安定、および優先順位の高さにあります。
Q3:PT は途中でキャンセルしたり、GSU の数を減らしたりできますか?
できません。 一度契約すると、コミットメント期間中はキャンセルや GSU の削減は不可能です。期間終了時に更新するかどうかを選択するのみとなります。唯一可能な変更は、GSU の追加(事業拡大時など)のみです。これは PT の最大の懸念点であり、先行投資型のコミットメントは慎重な利用量予測に基づいて行う必要があります。
Q4:Gemini 3 Pro Image (Nano Banana Pro) は PT に対応していますか?
2026年4月現在、Google の公式サポートリストに基づくと、Gemini 3 Pro シリーズ(gemini-3-pro-image-preview を含む)は Provisioned Throughput に対応しています。 ただし、画像モデルの GSU 消費量は画像サイズとトークン数に基づいて計算される点に注意してください。4K 画像の 1 リクエストあたりの GSU 消費量は 1K 画像よりも大幅に高くなります。詳細な消費係数は Google の公式データに従ってください。コスト比較を迅速に行いたい場合は、APIYI (apiyi.com) の営業窓口へお問い合わせいただき、企業向けプランの価格表をご請求ください。
Q5:GCP アカウントや海外発行のクレジットカードを持っていませんが、PT のような優先チャンネルを利用できますか?
可能です。APIYI (apiyi.com) の企業向けプランは、マルチアカウント集約 + VIP 専用キューによって、PT と同等の優先チャンネル効果を実現しています。日本国内の法人主体で、日本円による法人決済で利用可能です。企業向けチャンネルの P99 レイテンシは Google の標準的な従量課金チャンネルと同等であり、月間画像生成量 5 万枚以下のクライアントであれば十分なパフォーマンスを発揮し、コストは公式の従量課金価格の 32〜37% に抑えられます。
Q6:PT と Google Batch API は併用できますか?
可能です。Batch API は独立した非同期チャンネルを利用するため、PT や DSQ と競合しません。洗練されたアーキテクチャではこれらを組み合わせて運用します。例えば、リアルタイム性が重要なリクエストには PT を、日常的なリクエストには DSQ を、夜間の大量処理には Batch API(50% 割引)を活用する「3チャンネル混合構成」をとることで、コスト効率を最大化できます。
まとめ
本記事の核心である「Google Provisioned Throughput (PT) とは何か?どの体系に属するものか?」という疑問にお答えします。
簡潔に言えば、PT とは Google Cloud Vertex AI (GCP) における企業向けスループット予約サブスクリプションのことです。GSU (Generative AI Scale Unit) を単位とし、1週間/1ヶ月/3ヶ月/1年のコミットメント期間で契約します。期間中は単価が変わることはありませんが、スケジューリングの優先権と安定したスループットが提供されます。これは AI Studio (generativelanguage.googleapis.com) とは全く別物であり、従量課金の DSQ (Dynamic Shared Quota) メカニズムと対比する「優先 vs 共有」という二元構造となっています。
中小企業、個人開発者、コンテンツクリエイターの大多数にとって、PT の導入ハードルとコミットメント期間の拘束は非常に高いと言わざるを得ません。より現実的な選択肢は、APIYI (apiyi.com) のような集約プラットフォームを通じて Gemini 全モデルを利用することです。これにより、より低価格(37% 相当)で企業レベルの安定したチャンネルを享受でき、海外口座の開設や国際送金、英語でのコンプライアンス対応といった複雑な課題を回避できます。
ビジネス規模が PT の4つの適用条件(高並列処理、低 P99 レイテンシの追求、月間消費額 > 5万ドル、強力な規制要件)のいずれかに達した際に初めて、時間をかけて PT の導入を検討するのが合理的な選択となるでしょう。
📌 著者署名: 本記事は APIYI (apiyi.com) エンタープライズソリューションチームが作成しました。内容は Google Cloud Vertex AI の公式英語ドキュメントおよび 2026年4月現在の最新の企業ポリシーに基づいています。ビジネスにおいて PT が適しているか、それとも集約型プランが適しているかの個別診断をご希望の方は、公式サイトのビジネス窓口よりお気軽にお問い合わせください。