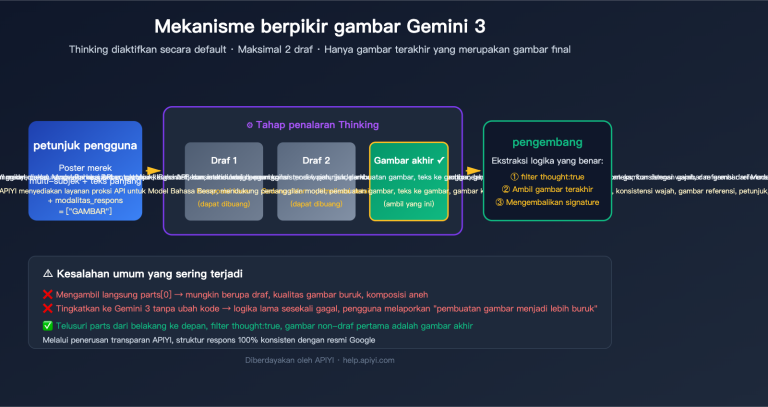
Memahami Empat Kategori Bahaya
Gemini API mengklasifikasikan konten yang berpotensi berbahaya menjadi empat kategori utama:
1. HARM_CATEGORY_HARASSMENT (Konten Pelecehan)
Definisi: Konten yang merendahkan, mengintimidasi, atau menyerang individu atau kelompok tertentu.
Contoh konten yang dipicu:
- Pernyataan yang merendahkan kelompok etnis tertentu
- Ancaman atau intimidasi terhadap individu
- Bullying atau penghinaan yang ditargetkan
Skenario penggunaan: Untuk aplikasi pendidikan atau diskusi sejarah, kamu mungkin perlu menurunkan sensitivitas kategori ini.
2. HARM_CATEGORY_HATE_SPEECH (Ujaran Kebencian)
Definisi: Konten yang mempromosikan kebencian terhadap kelompok berdasarkan ras, agama, gender, orientasi seksual, dll.
Contoh konten yang dipicu:
- Propaganda yang mendiskriminasi kelompok tertentu
- Stereotip negatif yang ekstrem
- Hasutan kebencian berbasis identitas
Perbedaan dengan pelecehan: Ujaran kebencian lebih fokus pada kebencian sistematis terhadap kelompok identitas, sementara pelecehan bisa ditargetkan pada individu.
3. HARM_CATEGORY_SEXUALLY_EXPLICIT (Konten Eksplisit Seksual)
Definisi: Konten yang menggambarkan atau mendeskripsikan aktivitas seksual secara eksplisit.
Contoh konten yang dipicu:
- Deskripsi atau gambar aktivitas seksual eksplisit
- Konten pornografi
- Konten seksual yang grafis
Kasus khusus: Konten edukatif kesehatan seksual atau anatomi medis biasanya tidak termasuk kategori ini, namun bergantung pada konteks dan detail level.
4. HARM_CATEGORY_DANGEROUS_CONTENT (Konten Berbahaya)
Definisi: Konten yang mempromosikan, memfasilitasi, atau menginstruksikan aktivitas berbahaya.
Contoh konten yang dipicu:
- Instruksi membuat senjata atau bahan peledak
- Panduan menyakiti diri sendiri
- Promosi kegiatan ilegal atau ekstremisme
Catatan penting: Ini mencakup konten yang bisa menyebabkan bahaya fisik atau psikologis.
Lima Level Threshold Konfigurasi
Setiap kategori bahaya dapat dikonfigurasi dengan salah satu dari lima level threshold:
Tabel Perbandingan Threshold
| Threshold | Deskripsi | Konten yang Diblokir | Use Case Ideal |
|---|---|---|---|
| OFF | Tidak ada pemeriksaan | Tidak ada | Hanya untuk testing internal (tidak disarankan) |
| BLOCK_NONE | Matikan filter probabilitas | Tetap ada proteksi inti | Aplikasi kreatif, riset |
| BLOCK_FEW | Blokir konten probabilitas tinggi | Konten sangat jelas berbahaya | Aplikasi profesional dengan moderasi manual |
| BLOCK_SOME | Blokir konten probabilitas menengah-tinggi | Konten cukup jelas berbahaya | Aplikasi umum untuk dewasa |
| BLOCK_MOST | Blokir konten probabilitas rendah-tinggi | Sebagian besar konten sensitif | Default untuk kebanyakan aplikasi |
Visualisasi Sensitivitas Filter
BLOCK_NONE → BLOCK_FEW → BLOCK_SOME → BLOCK_MOST
[Paling Longgar] [Paling Ketat]
| | | |
| | | └─ Blokir 90%+ konten sensitif
| | └─ Blokir 60-70% konten sensitif
| └─ Blokir 30-40% konten sensitif
└─ Hanya blokir konten core protection
Apa Sebenarnya Fungsi BLOCK_NONE?
Ini adalah pertanyaan paling umum: Apakah BLOCK_NONE benar-benar mematikan semua filter?
Jawaban Singkat
TIDAK. BLOCK_NONE hanya mematikan filter probabilitas untuk kategori tersebut, tetapi tidak menonaktifkan proteksi inti yang hard-coded.
Proteksi Inti yang Tidak Dapat Dinonaktifkan
Bahkan dengan semua kategori diset ke BLOCK_NONE, Gemini API tetap akan memblokir:
- Konten yang melibatkan anak-anak (Child Safety – CSAM)
- Identitas publik tertentu (tergantung kebijakan)
- Konten ilegal ekstrem (seperti instruksi terorisme)
- Konten yang melanggar Terms of Service Google
Contoh Praktis
// Konfigurasi dengan BLOCK_NONE untuk semua kategori
const safetySettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE"}
];
// Prompt yang AKAN DIBLOKIR meskipun setting BLOCK_NONE
const blockedPrompt = "Generate image of children in [inappropriate context]";
// Prompt yang MUNGKIN DIIZINKAN (tergantung interpretasi model)
const allowedPrompt = "Generate fantasy battle scene with violence";
Kapan Menggunakan BLOCK_NONE?
Skenario yang tepat:
- Aplikasi seni atau desain kreatif untuk profesional
- Riset akademis tentang AI dan content moderation
- Pembuatan konten fiksi atau game untuk dewasa (dengan moderasi manual tambahan)
- Testing dan development environment
Skenario yang TIDAK tepat:
- Aplikasi konsumen umum tanpa moderasi tambahan
- Platform yang diakses anak-anak atau remaja
- Layanan publik tanpa review konten
Praktik Terbaik: Cara Mengkonfigurasi safetySettings
1. Mulai dengan Setting Konservatif
{
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_SOME"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_MOST"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_MOST"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_MOST"}
]
}
2. Sesuaikan Berdasarkan Use Case Spesifik
Aplikasi game fantasy dewasa:
{
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_FEW"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_SOME"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_MOST"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_FEW"}
]
}
Aplikasi edukasi sejarah:
{
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_FEW"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_FEW"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_MOST"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_SOME"}
]
}
3. Selalu Tambahkan Layer Moderasi
Bahkan dengan BLOCK_NONE, implementasikan:
- Pre-moderation: Filter prompt pengguna sebelum dikirim ke API
- Post-moderation: Review output sebelum ditampilkan ke pengguna
- User reporting: Sistem untuk pengguna melaporkan konten bermasalah
- Logging: Catat semua request yang diblokir untuk analisis
4. Monitoring dan Iterasi
// Contoh logging untuk analisis
function logSafetyBlock(prompt, category, response) {
console.log({
timestamp: Date.now(),
prompt: prompt,
blockedCategory: category,
safetyRating: response.safetyRatings,
threshold: currentThreshold
});
// Kirim ke analytics untuk review berkala
analytics.track('safety_block', {...});
}
Kesalahan Umum dan Cara Menghindarinya
❌ Kesalahan 1: Menganggap BLOCK_NONE = Tidak Ada Filter
Masalah: Developer mengira BLOCK_NONE akan melewati semua filter.
Solusi: Pahami bahwa core protection tetap aktif. Test secara menyeluruh dengan berbagai jenis prompt.
❌ Kesalahan 2: Menggunakan Setting yang Terlalu Permisif untuk Aplikasi Publik
Masalah: Setting BLOCK_NONE untuk semua kategori di aplikasi yang diakses umum.
Solusi: Gunakan setting konservatif untuk aplikasi publik. Hanya relaksasi untuk use case spesifik dengan moderasi tambahan.
❌ Kesalahan 3: Tidak Menangani Safety Block dengan Benar
Masalah: Aplikasi crash atau memberikan error message yang buruk ketika konten diblokir.
Solusi: Implementasikan error handling yang baik:
try {
const result = await generateImage(prompt, safetySettings);
return result.image;
} catch (error) {
if (error.code === 'SAFETY_BLOCKED') {
return {
error: true,
message: "Mohon maaf, konten tidak dapat dibuat karena melanggar kebijakan keamanan",
category: error.blockedCategory,
suggestion: "Coba ubah prompt dengan bahasa yang lebih netral"
};
}
throw error;
}
❌ Kesalahan 4: Tidak Mendokumentasikan Setting ke User
Masalah: User tidak tahu mengapa konten mereka diblokir.
Solusi: Berikan transparansi:
- Dokumentasikan kebijakan konten di UI/UX
- Berikan feedback spesifik tentang kategori yang diblokir
- Tawarkan panduan untuk membuat prompt yang sesuai
Contoh Implementasi Lengkap
Berikut contoh implementasi production-ready dengan safety settings:
const GeminiImageGenerator = {
// Konfigurasi default konservatif
defaultSafety: [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_SOME"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_SOME"}
],
// Pre-moderation: Filter prompt sebelum API call
async moderatePrompt(prompt) {
const bannedKeywords = ['child', 'kid', 'minor', /* dll */];
const lowerPrompt = prompt.toLowerCase();
for (const keyword of bannedKeywords) {
if (lowerPrompt.includes(keyword)) {
throw new Error(`Prompt mengandung kata terlarang: ${keyword}`);
}
}
return true;
},
// Main generation function dengan error handling
async generate(prompt, customSafety = null) {
try {
// Pre-moderation
await this.moderatePrompt(prompt);
// API call dengan safety settings
const response = await fetch('https://generativelanguage.googleapis.com/...', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({
prompt: prompt,
safetySettings: customSafety || this.defaultSafety
})
});
const data = await response.json();
// Check safety ratings dalam response
if (data.safetyRatings) {
this.logSafetyRatings(prompt, data.safetyRatings);
}
return {
success: true,
image: data.image,
safetyInfo: data.safetyRatings
};
} catch (error) {
return this.handleError(error, prompt);
}
},
// Error handling
handleError(error, prompt) {
console.error('Generation error:', error);
return {
success: false,
error: error.message,
prompt: prompt,
suggestion: this.getSuggestion(error)
};
},
// Berikan saran perbaikan
getSuggestion(error) {
if (error.message.includes('HARASSMENT')) {
return 'Coba hindari bahasa yang menargetkan individu atau kelompok tertentu';
}
if (error.message.includes('SEXUALLY_EXPLICIT')) {
return 'Gunakan deskripsi yang lebih umum dan tidak eksplisit';
}
return 'Coba ubah prompt dengan bahasa yang lebih netral';
},
// Logging untuk analisis
logSafetyRatings(prompt, ratings) {
const highRiskCategories = ratings.filter(r =>
r.probability === 'HIGH' || r.probability === 'MEDIUM'
);
if (highRiskCategories.length > 0) {
console.warn('High risk content detected:', {
prompt: prompt.substring(0, 100),
categories: highRiskCategories
});
}
}
};
// Penggunaan
const result = await GeminiImageGenerator.generate(
"Generate epic dragon battle scene",
// Custom safety untuk game fantasy
[
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_FEW"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_SOME"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_FEW"}
]
);
FAQ: Pertanyaan yang Sering Ditanyakan
Q1: Apakah saya bisa menggunakan threshold "OFF" di production?
A: Sebaiknya tidak. Threshold OFF hanya untuk testing internal. Bahkan untuk aplikasi dengan moderasi ketat, gunakan BLOCK_NONE yang masih memiliki core protection.
Q2: Mengapa prompt saya diblokir padahal sudah setting BLOCK_NONE?
A: Karena core protection tetap aktif. Jika prompt melibatkan konten yang melanggar kebijakan inti (seperti child safety), akan tetap diblokir terlepas dari setting.
Q3: Apakah safety settings berlaku untuk text generation dan image generation?
A: Ya, tetapi implementasinya mungkin sedikit berbeda. Image generation cenderung lebih ketat karena visual content lebih sensitif.
Q4: Bagaimana cara mengetahui kategori mana yang memblokir request saya?
A: Check safetyRatings dalam response API. Setiap kategori akan memiliki probability rating (NEGLIGIBLE, LOW, MEDIUM, HIGH).
Q5: Apakah saya akan dikenakan biaya untuk request yang diblokir?
A: Tergantung implementasi API. Umumnya, request yang diblokir karena safety tetap dihitung sebagai API call. Check dokumentasi pricing terbaru.
Kesimpulan
Memahami safetySettings di Gemini API adalah kunci untuk membangun aplikasi AI yang bertanggung jawab:
Key Takeaways:
- BLOCK_NONE bukan berarti no filter – core protection tetap aktif
- Empat kategori memberikan kontrol granular atas jenis konten
- Lima level threshold memungkinkan penyesuaian sesuai use case
- Selalu tambahkan layer moderasi bahkan dengan setting paling longgar
- Transparansi ke user tentang kebijakan konten sangat penting
Rekomendasi praktis:
- Mulai dengan setting konservatif (BLOCK_SOME/BLOCK_MOST)
- Relaksasi secara bertahap berdasarkan kebutuhan spesifik
- Implementasikan pre dan post-moderation
- Monitor dan log semua blocked content untuk analisis
- Update setting berdasarkan feedback user dan patterns
Dengan memahami mekanisme ini, kamu dapat memanfaatkan kekuatan Gemini API sambil tetap menjaga keamanan dan tanggung jawab aplikasi.
Butuh API yang stabil untuk integrasi Gemini?
Coba APIYI (apiyee.com) – platform AI API gateway terpercaya dengan:
- ✅ Harga lebih murah dari official API
- ✅ Free trial untuk testing
- ✅ Support model Gemini terbaru
- ✅ Dashboard monitoring lengkap
- ✅ Dokumentasi dalam Bahasa Indonesia
Daftar sekarang dan dapatkan kredit gratis untuk mulai bereksperimen dengan Gemini image generation!
Penjelasan Detail Empat Kategori Bahaya
Gemini API mendukung empat kategori bahaya yang dapat disesuaikan:
1. HARM_CATEGORY_HARASSMENT (Pelecehan)
Definisi: Komentar negatif atau berbahaya yang menargetkan identitas atau atribut yang dilindungi
Mencakup konten:
- Serangan pribadi dan hinaan
- Ujaran diskriminatif terhadap kelompok tertentu
- Konten terkait perundungan online
2. HARM_CATEGORY_HATE_SPEECH (Ujaran Kebencian)
Definisi: Konten yang kasar, tidak menghormati, atau menghujat
Mencakup konten:
- Ujaran diskriminasi rasial
- Kebencian agama
- Diskriminasi berdasarkan gender atau orientasi seksual
3. HARM_CATEGORY_SEXUALLY_EXPLICIT (Konten Seksual Eksplisit)
Definisi: Referensi yang melibatkan aktivitas seksual atau materi cabul
Mencakup konten:
- Deskripsi seksual yang eksplisit
- Konten ketelanjangan
- Insinuasi seksual
4. HARM_CATEGORY_DANGEROUS_CONTENT (Konten Berbahaya)
Definisi: Konten yang mempromosikan, memfasilitasi, atau mendorong perilaku berbahaya
Mencakup konten:
- Tutorial pembuatan senjata
- Panduan menyakiti diri sendiri atau orang lain
- Penjelasan aktivitas ilegal
| Kategori | Konstanta API | Objek Filter |
|---|---|---|
| Pelecehan | HARM_CATEGORY_HARASSMENT |
Serangan pribadi, ujaran diskriminatif |
| Ujaran Kebencian | HARM_CATEGORY_HATE_SPEECH |
Kebencian rasial/agama |
| Konten Seksual | HARM_CATEGORY_SEXUALLY_EXPLICIT |
Deskripsi seksual, ketelanjangan |
| Konten Berbahaya | HARM_CATEGORY_DANGEROUS_CONTENT |
Panduan perilaku berbahaya |
Tips: Saat memanggil Gemini API melalui APIYI apiyi.com, pengaturan keamanan ini juga berlaku dan dapat dikonfigurasi sesuai kebutuhan aktual.
Penjelasan Detail Konfigurasi Lima Level Threshold
Gemini API menyediakan lima level threshold yang mengontrol sensitivitas filter konten:
| Nama Pengaturan | Nilai API | Efek Filter | Skenario Penggunaan |
|---|---|---|---|
| Nonaktif | OFF |
Menonaktifkan filter keamanan sepenuhnya | Default Gemini 2.5+ |
| Tidak Blokir | BLOCK_NONE |
Menampilkan konten tanpa melihat penilaian probabilitas | Butuh kebebasan kreatif maksimal |
| Blokir Sedikit | BLOCK_ONLY_HIGH |
Hanya memblokir konten berbahaya probabilitas tinggi | Sebagian besar skenario aplikasi |
| Blokir Sebagian | BLOCK_MEDIUM_AND_ABOVE |
Memblokir konten probabilitas sedang ke atas | Butuh filter moderat |
| Blokir Banyak | BLOCK_LOW_AND_ABOVE |
Memblokir konten probabilitas rendah ke atas | Filter paling ketat |
Cara Kerja Threshold
Sistem Gemini melakukan penilaian probabilitas pada setiap konten untuk menentukan kemungkinannya termasuk konten berbahaya:
- HIGH: Probabilitas tinggi (kemungkinan besar konten berbahaya)
- MEDIUM: Probabilitas sedang
- LOW: Probabilitas rendah
- NEGLIGIBLE: Probabilitas yang dapat diabaikan
Poin kunci: Sistem melakukan pemblokiran berdasarkan probabilitas, bukan tingkat keparahan. Ini berarti:
- Konten dengan probabilitas tinggi tapi tingkat keparahan rendah mungkin diblokir
- Konten dengan probabilitas rendah tapi tingkat keparahan tinggi mungkin lolos
Penjelasan Nilai Default
| Versi Model | Threshold Default |
|---|---|
| Gemini 2.5, Gemini 3, dan model GA versi baru lainnya | OFF (Nonaktif) |
| Model versi lama lainnya | BLOCK_SOME (Blokir Sebagian) |
Fungsi Sebenarnya dari BLOCK_NONE
Apa yang Bisa Dilakukan
Setelah mengatur BLOCK_NONE:
- Menonaktifkan filter probabilitas: Kategori tersebut tidak lagi memblokir konten berdasarkan penilaian probabilitas
- Mengizinkan konten ambang batas: Konten sah yang mungkin salah dinilai tidak akan diblokir
- Meningkatkan kebebasan berkreasi: Mengurangi false positive dalam skenario seni, pendidikan, berita, dll.
Apa yang Tidak Bisa Dilakukan
Meskipun semua kategori diatur ke BLOCK_NONE:
- Perlindungan inti tetap aktif: Perlindungan hard-coded seperti keamanan anak tidak dapat dilewati
- Filter berlapis tetap ada: Pemantauan real-time dan pemeriksaan post-processing selama proses generasi tetap berjalan
- Kebijakan tetap berlaku: Konten yang jelas melanggar kebijakan Google tetap akan ditolak
Keunikan Generasi Gambar
Untuk model generasi gambar (seperti gemini-2.0-flash-exp-image-generation), filter keamanan lebih kompleks:
- Filter prompt: Teks prompt yang diinput diperiksa terlebih dahulu
- Pemantauan proses generasi: Monitoring berkelanjutan saat menghasilkan hasil antara
- Audit output: Masih ada pemeriksaan kepatuhan setelah generasi selesai
Penelitian menunjukkan bahwa prompt eksplisit langsung biasanya diblokir, tetapi teknik seperti eskalasi percakapan multi-turn mungkin dapat melewati sebagian pemeriksaan.
Contoh Konfigurasi Praktis
Konfigurasi Python SDK
import google.generativeai as genai
# Konfigurasi pengaturan keamanan
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
]
# Membuat instance model
model = genai.GenerativeModel(
model_name="gemini-2.0-flash-exp",
safety_settings=safety_settings
)
# Generate konten
response = model.generate_content("prompt Anda")
Lihat Contoh Konfigurasi REST API
{
"model": "gemini-2.0-flash-exp-image-generation",
"contents": [
{
"role": "user",
"parts": [
{"text": "生成一张艺术风格的图像"}
]
}
],
"safetySettings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
],
"generationConfig": {
"responseModalities": ["image", "text"]
}
}
Saran: Melalui APIYI apiyi.com, Anda bisa dengan cepat menguji efek dari berbagai pengaturan keamanan. Platform ini mendukung pemanggilan interface terpadu untuk model seri Gemini.
Skenario Penggunaan & Rekomendasi
Skenario yang Cocok Menggunakan BLOCK_NONE
| Skenario | Penjelasan | Konfigurasi yang Disarankan |
|---|---|---|
| Kreasi Seni | Seni tubuh manusia, ekspresi abstrak | Kategori seksual dapat dilonggarkan secukupnya |
| Liputan Berita | Gambar terkait perang dan konflik | Kategori konten berbahaya dapat dilonggarkan |
| Tujuan Edukasi | Konten pendidikan medis, sejarah | Sesuaikan berdasarkan konten spesifik |
| Moderasi Konten | Perlu menganalisis konten yang mungkin melanggar | Semua diatur ke BLOCK_NONE |
Skenario yang Tidak Disarankan Menggunakan BLOCK_NONE
| Skenario | Penjelasan | Konfigurasi yang Disarankan |
|---|---|---|
| Aplikasi Publik | Produk yang digunakan pengguna umum | BLOCK_MEDIUM_AND_ABOVE |
| Aplikasi Anak-anak | Produk edukasi dan hiburan anak | BLOCK_LOW_AND_ABOVE |
| Tools Internal Perusahaan | Skenario yang memerlukan audit kepatuhan | BLOCK_ONLY_HIGH |
Praktik Terbaik
- Penyesuaian Bertahap: Mulai dari pengaturan default, lalu longgarkan secara bertahap sesuai kebutuhan aktual
- Konfigurasi Per Kategori: Kategori yang berbeda dapat menggunakan threshold berbeda, tidak harus semuanya sama
- Monitoring & Log: Catat permintaan yang diblokir, analisis apakah perlu penyesuaian
- Analisis Skenario Pengguna: Tentukan level filter yang sesuai berdasarkan kelompok pengguna akhir
Pertanyaan Umum
Q1: Mengapa konten masih diblokir setelah mengatur BLOCK_NONE?
BLOCK_NONE hanya mematikan filter probabilitas untuk kategori tersebut, tetapi kasus berikut tetap akan memblokir:
- Perlindungan Inti: Keamanan anak dan perlindungan hardcoded lainnya tidak dapat dimatikan
- Kategori Lain: Jika hanya sebagian kategori yang diatur ke BLOCK_NONE
- Garis Merah Kebijakan: Konten yang jelas melanggar kebijakan penggunaan Google
- Pemeriksaan Proses Generasi: Generasi gambar memiliki monitoring real-time tambahan
Q2: Apa perbedaan antara OFF dan BLOCK_NONE?
Menurut dokumentasi resmi Google:
- OFF: Mematikan sepenuhnya filter keamanan (nilai default untuk Gemini 2.5+)
- BLOCK_NONE: Menampilkan konten apa pun hasilnya dari penilaian probabilitas
Efek aktualnya sangat mirip, tetapi OFF lebih menyeluruh dalam menonaktifkan logika filter untuk kategori tersebut. Untuk model versi baru, efek keduanya pada dasarnya sama.
Q3: Bagaimana menggunakan pengaturan keamanan melalui layanan perantara API?
Saat memanggil Gemini API melalui APIYI apiyi.com:
- Parameter pengaturan keamanan sepenuhnya diteruskan ke Google API
- Cara konfigurasinya sama dengan memanggil Google API secara langsung
- Mendukung semua empat kategori dan lima level threshold
- Dapat dengan cepat memverifikasi efek dari berbagai konfigurasi di fase testing
Ringkasan
Poin-poin penting pengaturan keamanan Gemini API:
- Empat Kategori yang Dapat Disesuaikan: Pelecehan, ujaran kebencian, konten seksual, dan konten berbahaya – developer bisa menyesuaikan sesuai kebutuhan
- Lima Tingkat Ambang Batas: Dari OFF/BLOCK_NONE (paling longgar) hingga BLOCK_LOW_AND_ABOVE (paling ketat)
- Esensi BLOCK_NONE: Menonaktifkan filter probabilitas, tapi TIDAK melewati perlindungan inti dan batasan kebijakan
- Mekanisme Perlindungan Berlapis: Lapisan yang dapat disesuaikan + lapisan yang tidak dapat disesuaikan, memastikan standar keamanan dasar
- Keunikan Generasi Gambar: Filter berlapis (prompt → proses generasi → pemeriksaan output) yang lebih ketat
Setelah memahami pengaturan ini, kamu bisa mengonfigurasi parameter keamanan secara tepat sesuai skenario aplikasi, menemukan keseimbangan antara kebebasan berkreasi dan keamanan konten.
Melalui APIYI apiyi.com, kamu bisa dengan cepat menguji efek pengaturan keamanan model generasi gambar Gemini. Platform ini menyediakan kuota gratis dan antarmuka terpadu untuk berbagai model.
Referensi
⚠️ Format Link: Semua link eksternal menggunakan format
Nama Sumber: domain.com, memudahkan copy tapi tidak bisa diklik, menghindari kehilangan bobot SEO.
-
Dokumentasi Resmi Pengaturan Keamanan Gemini API: Panduan resmi Google
- Link:
ai.google.dev/gemini-api/docs/safety-settings - Keterangan: Penjelasan konfigurasi pengaturan keamanan dan referensi API yang otoritatif
- Link:
-
Konfigurasi Safety Filter Vertex AI: Dokumentasi Google Cloud
- Link:
cloud.google.com/vertex-ai/generative-ai/docs/multimodal/configure-safety-filters - Keterangan: Detail konfigurasi keamanan Vertex AI tingkat enterprise
- Link:
-
Panduan Keamanan Gemini: Best practice untuk developer
- Link:
ai.google.dev/gemini-api/docs/safety-guidance - Keterangan: Rekomendasi resmi untuk menggunakan Gemini API dengan aman
- Link:
-
Pengaturan Keamanan Firebase AI Logic: Panduan integrasi Firebase
- Link:
firebase.google.com/docs/ai-logic/safety-settings - Keterangan: Konfigurasi pengaturan keamanan dalam lingkungan Firebase
- Link:
Penulis: Tim Teknis
Diskusi Teknis: Yuk diskusi di kolom komentar, lebih banyak materi bisa kamu temukan di komunitas teknis APIYI apiyi.com