Note de l'auteur : Analyse approfondie de la capacité de structuration de texte du grand modèle de langage GLM-4.7. Maîtrisez les techniques pratiques pour extraire des informations clés au format JSON à partir de documents complexes tels que des contrats ou des rapports.
L'extraction rapide d'informations clés à partir d'une grande quantité de textes non structurés est un défi majeur pour le traitement des données en entreprise. Lancé en décembre 2025 par Zhipu AI, le grand modèle de langage GLM-4.7 apporte une solution révolutionnaire grâce à son support natif du JSON Schema et sa fenêtre de contexte ultra-longue de 200K.
Valeur ajoutée : Après avoir lu cet article, vous saurez comment utiliser GLM-4.7 pour extraire des données structurées de documents complexes (contrats, rapports), vous permettant ainsi d'augmenter radicalement l'efficacité du traitement de vos documents.

Points clés de la structuration de texte avec GLM-4.7
| Point clé | Description | Valeur |
|---|---|---|
| JSON Schema natif | Support de sortie structurée intégré, sans ingénierie d'invite complexe | Précision d'extraction améliorée de plus de 40 % |
| Fenêtre de contexte de 200K | Supporte l'entrée de documents longs complets, sans segmentation | Traite un contrat ou un rapport entier en une fois |
| Capacité de sortie de 128K | Peut générer des résultats structurés ultra-longs | Idéal pour l'extraction d'informations en masse |
| Support du Function Calling | Capacité native de Tool Calling | Intégration transparente avec les systèmes métiers |
| Avantage de coût | 0,10 $/M tokens, soit 4 à 7 fois moins cher que les modèles équivalents | Coûts de déploiement à grande échelle maîtrisés |
Détails sur la structuration de texte avec GLM-4.7
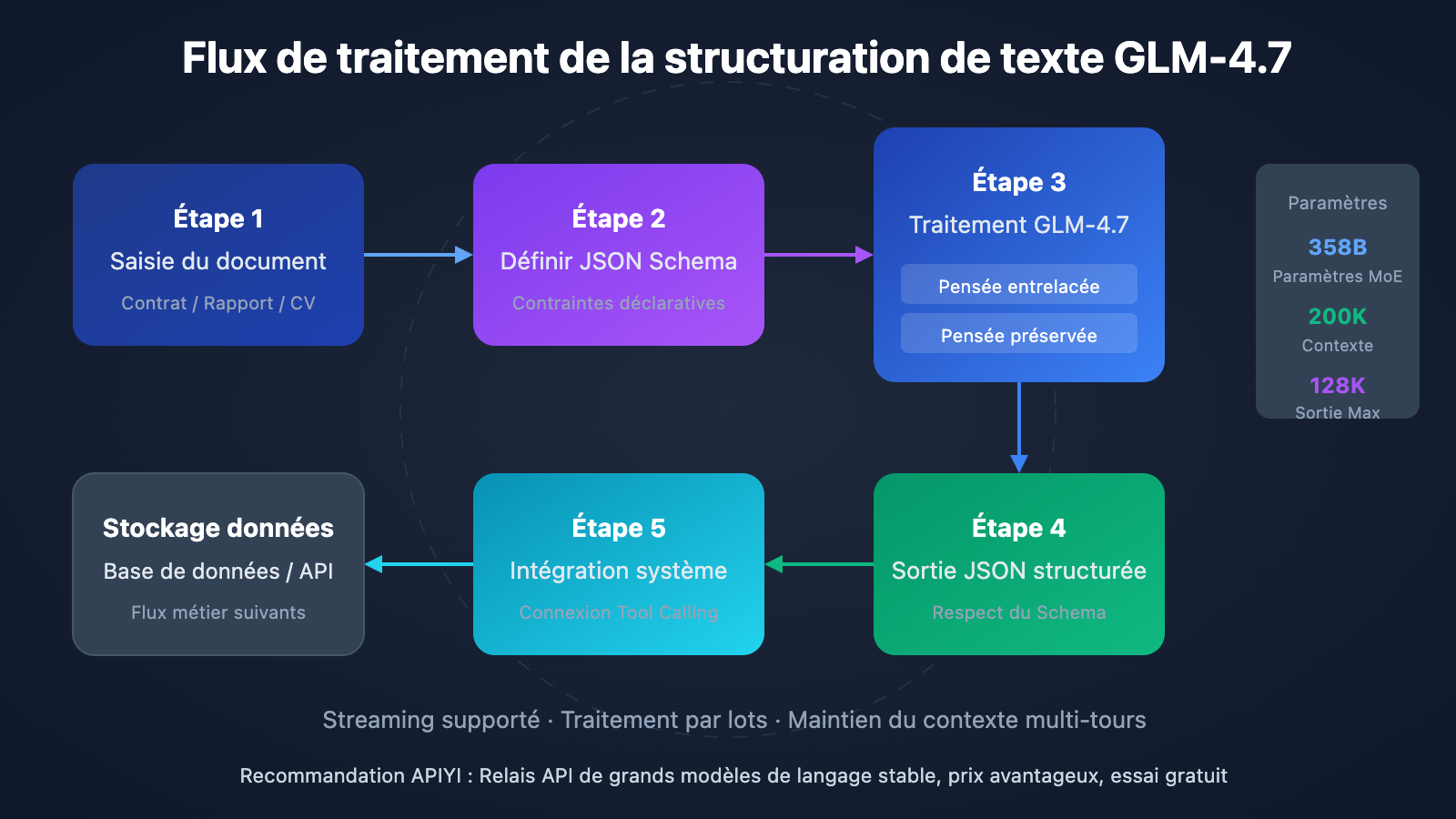
GLM-4.7 est le nouveau fleuron des grands modèles de langage (LLM) publié par Zhipu AI le 22 décembre 2025. Ce modèle adopte une architecture Mixture-of-Experts (MoE) avec un total d'environ 358 milliards de paramètres, tout en garantissant une inférence efficace grâce à un mécanisme d'activation clairsemée. En matière de structuration de texte, GLM-4.7 réalise un véritable bond en avant par rapport à la version 4.6 : ses performances au benchmark HLE ont progressé de 38 % pour atteindre 42,8 %, se plaçant ainsi au niveau du GPT-5.1 High.
La capacité de sortie structurée de GLM-4.7 s'articule autour de trois dimensions. D'abord, la pensée entrelacée (Interleaved Thinking) : le modèle planifie automatiquement son chemin de raisonnement avant chaque sortie, garantissant la cohérence de la logique d'extraction. Ensuite, la pensée préservée (Preserved Thinking), qui maintient le raisonnement contextuel lors de dialogues multi-tours, ce qui est parfait pour les tâches d'extraction d'informations itératives et complexes. Enfin, le contrôle au niveau du tour (Turn-level Control) permet d'ajuster dynamiquement la profondeur de raisonnement de chaque requête, offrant un équilibre flexible entre vitesse et précision.
GLM-4.7 Structuration de texte : Démarrage rapide
Exemple minimaliste
Voici la méthode la plus simple pour l'utiliser : seulement 10 lignes de code suffisent pour extraire des données structurées d'un texte :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Voir l’implémentation complète (avec contraintes JSON Schema)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
Conseil : Obtenez des crédits de test gratuits via APIYI (apiyi.com) pour valider rapidement l'efficacité de la structuration de texte de GLM-4.7. La plateforme prend en charge une interface unifiée pour plusieurs modèles majeurs, facilitant la comparaison des taux d'extraction entre GLM-4.7 et d'autres modèles.
Scénarios d'application de la structuration de texte GLM-4.7
La capacité de structuration de texte de GLM-4.7 est adaptée à de nombreux scénarios d'entreprise :
| Scénario | Données d'entrée | Format de sortie | Gain d'efficacité typique |
|---|---|---|---|
| Extraction d'infos contractuelles | Contrat PDF/Word | Données structurées JSON | De plusieurs heures → quelques minutes |
| Analyse de rapports financiers | Rapports annuels/trimestriels | Tableaux d'indicateurs financiers | Précision de 95%+ |
| Tri de CV | Texte de CV | Profil candidat en JSON | Efficacité de tri x10 |
| Veille de l'opinion publique | Contenu web/réseaux sociaux | Graphe de relations d'entités | Capacité de traitement en temps réel |
| Interprétation de rapports d'études | Rapports d'études sectorielles | Extraction des points clés | Couverture augmentée de 5x |
Avantages techniques de la structuration de texte avec GLM-4.7
1. Support natif de JSON Schema
À l'instar de la série de modèles GPT, GLM-4.7 permet de spécifier directement un JSON Schema dans response_format. Le modèle produira alors des résultats respectant strictement la structure définie. Cela signifie que vous n'avez pas besoin de rédiger des invites complexes pour "convaincre" le modèle d'adopter un format spécifique, mais que vous contraignez la structure de sortie de manière déclarative.
2. Traitement de contextes ultra-longs
Une fenêtre de contexte de 200K tokens signifie que GLM-4.7 peut traiter en une seule fois des documents d'environ 150 000 caractères chinois, soit l'équivalent d'un contrat complet ou d'un cahier des charges technique. Cela évite les processus complexes consistant à découper de longs documents en blocs pour ensuite fusionner les résultats, réduisant ainsi les risques de perte d'informations et de rupture de contexte.
3. Pensée entrelacée pour une précision accrue
Lors du traitement de tâches d'extraction complexes, le mode de pensée entrelacé de GLM-4.7 effectue automatiquement un raisonnement en plusieurs étapes avant de fournir une réponse. Par exemple, lors de l'extraction d'un montant de contrat, le modèle identifiera d'abord les paragraphes liés au montant, puis effectuera une vérification croisée entre les chiffres et le montant écrit en toutes lettres, pour enfin sortir le résultat avec le plus haut niveau de confiance.
Conseil pratique : Nous vous recommandons d'effectuer des tests réels via la plateforme APIYI (apiyi.com) afin d'évaluer les performances de GLM-4.7 dans votre contexte métier spécifique. La plateforme propose des crédits gratuits et des journaux d'appels détaillés, ce qui facilite le débogage et l'optimisation.
Comparaison des solutions de structuration de texte GLM-4.7
| Solution | Caractéristiques clés | Scénarios d'utilisation | Performance |
|---|---|---|---|
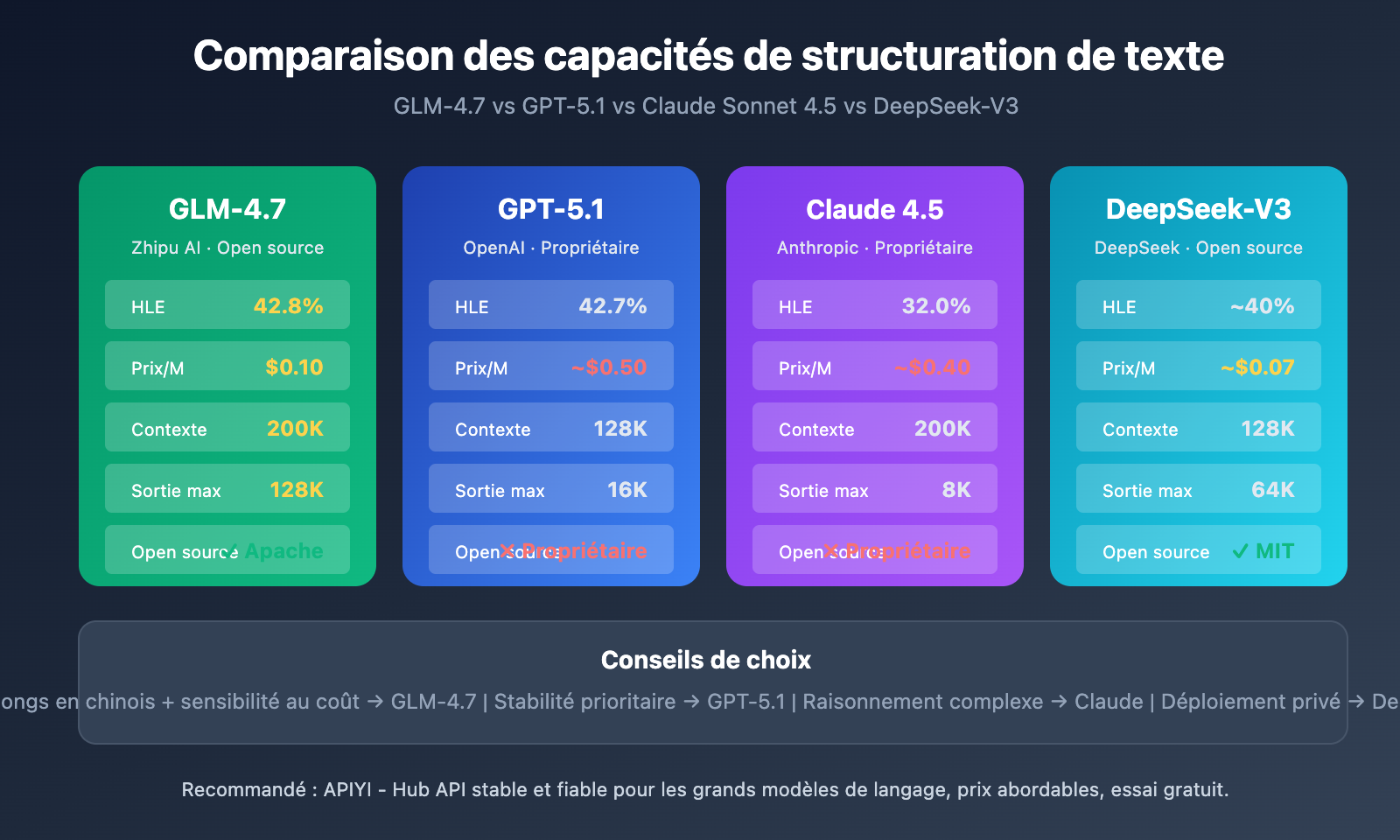
| GLM-4.7 | JSON Schema natif, contexte de 200K, faible coût | Extraction de documents longs, traitement à grande échelle, sensible aux coûts | HLE 42,8 %, SWE-bench 73,8 % |
| GPT-5.1 | Sortie stable, écosystème mature, réponse rapide | Exigences de haute fiabilité, scénarios de livraison rapide | HLE 42,7 %, temps de réponse optimal |
| Claude Sonnet 4.5 | Raisonnement logique puissant, compréhension contextuelle profonde | Tâches d'analyse complexes, raisonnement multi-étapes | HLE 32,0 %, excellente profondeur de raisonnement |
| DeepSeek-V3 | Open-source et déployable, excellent rapport performance-prix | Déploiement privé, besoins personnalisés | Excellentes performances dans les benchmarks |
Différences clés entre GLM-4.7 et ses concurrents
| Dimension de comparaison | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Statut open-source | Open-source (Apache 2.0) | Propriétaire | Propriétaire |
| Prix (/M tokens) | 0,10 $ | ~0,50 $ | ~0,40 $ |
| Fenêtre contextuelle | 200K | 128K | 200K |
| Sortie maximale | 128K | 16K | 8K |
| Optimisation du chinois | Forte | Moyenne | Moyenne |
| Déploiement local | Supporté | Non supporté | Non supporté |
Conseils de sélection :
- Si vous avez besoin de traiter de gros volumes de documents en chinois tout en étant sensible aux coûts, GLM-4.7 est le meilleur choix.
- Si vous recherchez la stabilité des résultats et la facilité d'intégration à l'écosystème, GPT-5.1 est plus mature.
- Si la tâche implique un raisonnement complexe en plusieurs étapes, la capacité logique de Claude Sonnet 4.5 est plus robuste.
Note de comparaison : Les données ci-dessus proviennent de benchmarks publics tels que HLE et SWE-bench. Vous pouvez effectuer vos propres tests de comparaison via la plateforme APIYI (apiyi.com). La plateforme prend en charge l'appel unifié de tous les modèles mentionnés ci-dessus via une interface unique.
Astuces avancées pour la structuration de texte avec GLM-4.7
Traitement de documents par lots
Pour les tâches de structuration impliquant un grand nombre de documents, vous pouvez exploiter la sortie en streaming et les capacités de concurrence de GLM-4.7 :
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""批量异步提取文档信息"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Intégration de l'appel de fonctions (Tool Calling)
La capacité de Tool Calling de GLM-4.7 permet de connecter directement les résultats de l'extraction à vos systèmes métier :
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "将提取的合同信息保存到数据库",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
FAQ
Q1 : Quelle est la précision de GLM-4.7 pour l’extraction de texte structuré ?
Dans des scénarios tels que les contrats types, les CV ou les rapports financiers, la précision d'extraction de GLM-4.7, associée aux contraintes JSON Schema, peut dépasser 95 %. Pour les documents complexes, il est recommandé d'intégrer un mécanisme de vérification humaine. Le mode de réflexion entrelacé du modèle effectue automatiquement une vérification en plusieurs étapes, ce qui améliore encore la précision.
Q2 : Quelles sont les limites de GLM-4.7 pour le traitement de documents longs ?
GLM-4.7 prend en charge une fenêtre de contexte de 200K tokens, ce qui équivaut à environ 150 000 caractères chinois. Pour les documents ultra-longs, nous conseillons de segmenter le contenu par chapitres logiques ou d'utiliser les outils de découpage fournis par la plateforme APIYI. La sortie maximale par requête est de 128K tokens, ce qui est amplement suffisant pour la grande majorité des besoins d'extraction structurée.
Q3 : Comment commencer rapidement à tester les capacités de structuration de texte de GLM-4.7 ?
Nous vous recommandons d'utiliser une plateforme d'agrégation d'API multi-modèles pour vos tests :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte.
- Obtenez votre clé API et vos crédits gratuits.
- Utilisez les exemples de code de cet article pour une vérification rapide.
- Comparez les performances des différents modèles selon vos cas d'usage spécifiques.
Résumé
Les points clés de la structuration de texte avec GLM-4.7 :
- Support structuré natif : Sortie contrainte par JSON Schema, évitant ainsi une ingénierie d'invite complexe.
- Capacité de contexte étendu : Fenêtre de 200K tokens pour traiter des documents longs d'un seul trait.
- Rentabilité exceptionnelle : Un coût de seulement 1/4 à 1/7 par rapport aux modèles de même catégorie, idéal pour un déploiement à grande échelle.
- Optimisation pour le chinois : Ce modèle national offre une compréhension plus fine des contrats et rapports en chinois.
En tant que modèle phare de Zhipu AI, GLM-4.7 démontre des capacités comparables à GPT-5.1 dans le domaine de la structuration de texte, tout en offrant les avantages uniques de l'open source, d'un coût réduit et d'une optimisation linguistique poussée. Pour les entreprises ayant d'importants besoins de traitement documentaire, GLM-4.7 constitue une option qui mérite d'être sérieusement évaluée.
N'hésitez pas à tester les résultats via APIYI (apiyi.com). La plateforme propose des crédits gratuits et une interface unifiée pour plusieurs modèles, facilitant ainsi vos tests en conditions réelles.
Ressources
⚠️ Note sur le format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com. Ils sont faciles à copier mais ne sont pas cliquables, afin d'éviter la perte de poids SEO.
-
Documentation officielle de GLM-4.7 : Documentation développeur de Zhipu AI
- Lien :
docs.z.ai/guides/llm/glm-4.7 - Description : Contient la description complète des paramètres de l'API et les meilleures pratiques.
- Lien :
-
Analyse technique de GLM-4.7 : Analyse approfondie de l'architecture et des capacités du modèle
- Lien :
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Description : Évaluation technique tierce, incluant une comparaison des données de benchmark.
- Lien :
-
Page du modèle sur Hugging Face : Téléchargement des poids open-source
- Lien :
huggingface.co/zai-org/GLM-4.7 - Description : Fournit les fichiers du modèle nécessaires au déploiement local ainsi qu'un guide de déploiement.
- Lien :
-
OpenRouter GLM-4.7 : Accès API multi-canaux
- Lien :
openrouter.ai/z-ai/glm-4.7 - Description : Offre des options d'accès via plusieurs fournisseurs et une comparaison des prix.
- Lien :
Auteur : Équipe technique
Échanges techniques : N'hésitez pas à partager votre expérience sur la structuration de texte avec GLM-4.7 dans l'espace commentaires. Pour plus de ressources, vous pouvez consulter la communauté technique APIYI sur apiyi.com.