Une découverte intéressante~ Récemment, de nombreux développeurs testant le modèle M2.7 de MiniMax, sorti en mars 2026, ont été confrontés à un problème contre-intuitif : ce modèle phare, présenté comme le "roi du code et des flux de travail d'agents", ne prend pas en charge les entrées d'images. À l'heure où Claude 4, GPT-5 et Gemini 3 font de la multimodalité un standard, il est surprenant qu'un grand modèle de langage de 230 milliards de paramètres ne puisse pas traiter d'images. Cet article analyse la logique produit derrière le positionnement "texte uniquement" du M2.7, en s'appuyant sur la documentation officielle de MiniMax, les fiches techniques NVIDIA NIM, les spécifications publiques d'OpenRouter et les observations d'APIYI (apiyi.com) lors de déploiements réels.
I. Le MiniMax M2.7 ne supporte-t-il vraiment pas les entrées d'images ?
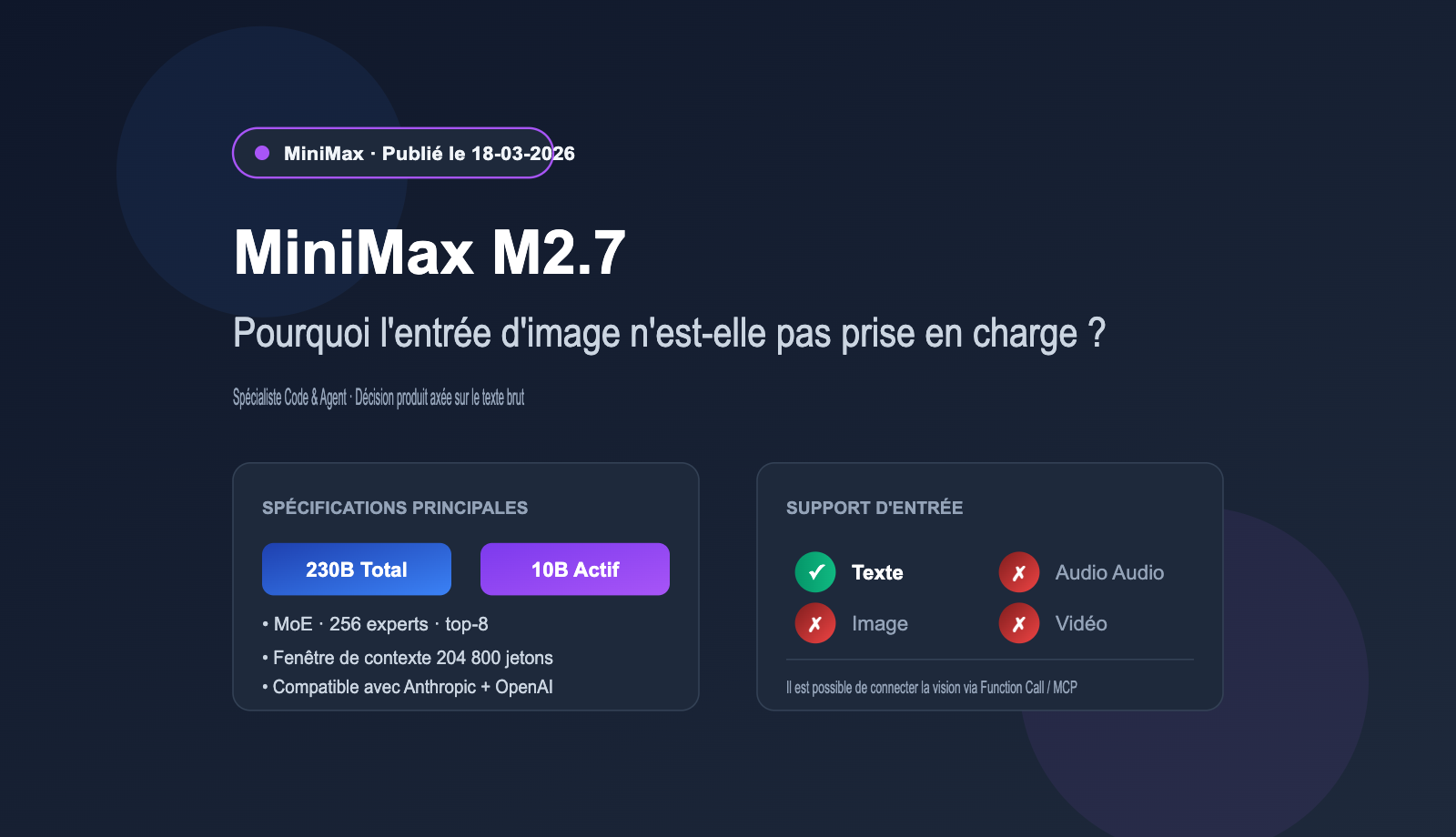
Répondons directement à la question : c'est vrai. Selon les spécifications publiques de la plateforme officielle MiniMax et de la fiche technique NVIDIA NIM, le M2.7 (y compris la version M2.7-highspeed) ne prend actuellement en charge que les entrées textuelles. Il est incapable de traiter directement des images, de l'audio ou de la vidéo. Cela reste cohérent avec le positionnement "texte uniquement" de la génération précédente (M2.5), mais contraste fortement avec la tendance actuelle des modèles "multimodaux natifs" comme Claude 4 Opus, GPT-5 et la série Gemini 3.
1.1 Aperçu des spécifications clés du MiniMax M2.7
Le M2.7 a ouvert ses API le 18 mars 2026. Il utilise une architecture MoE (Mixture of Experts), avec 230 milliards de paramètres au total et 10 milliards de paramètres activés, misant sur une "haute performance et un faible coût".
| Spécification | Paramètre |
|---|---|
| Date de sortie | 18/03/2026 |
| Type d'architecture | MoE Transformer (256 experts, 8 activés par jeton) |
| Total paramètres / activés | 230B / 10B |
| Fenêtre de contexte | 204 800 jetons |
| Sortie maximale | 131 072 jetons |
| Prix d'entrée | 0,279 $ / M jetons |
| Prix de sortie | 1,20 $ / M jetons |
| Support multimodal | ❌ Texte uniquement |
| Compatibilité API | API Anthropic + API OpenAI |
1.2 Dans quels scénarios risquez-vous de rencontrer des problèmes ?
Si votre application implique des questions sur des captures d'écran, l'analyse de PDF par capture, la compréhension d'images de produits, la détection visuelle pour l'automatisation d'UI ou la recherche d'images dans un RAG multimodal, l'appel direct au M2.7 échouera ou produira des résultats incohérents. Il est recommandé d'effectuer une vérification du type de modèle au niveau de la couche de routage (comme LiteLLM, One API ou une passerelle de service proxy API comme APIYI apiyi.com) afin de diriger les requêtes contenant des images vers les séries Claude, GPT-5 ou Gemini 3.
二、Pourquoi MiniMax M2.7 a choisi la voie du "texte pur"
Le positionnement "texte pur" du M2.7 n'est pas dû à un manque de capacités techniques, mais à une décision produit très claire. MiniMax avait déjà publié la série de modèles abab dotés de capacités multimodales et était tout à fait capable d'intégrer un module visuel à la série M. Cependant, ils ont choisi de consacrer toute la puissance de calcul d'entraînement du M2.7 aux domaines du "code + Agent", afin d'obtenir des performances exceptionnelles dans ces deux directions.
2.1 Le code et les Agents : le champ de bataille principal du M2.7
Selon le README officiel et le blog technique de NVIDIA, le M2.7 est spécifiquement optimisé pour "l'édition multi-fichiers, les boucles code-exécution-correction, la réparation pilotée par les tests et les appels d'outils en chaîne longue (Shell/navigateur/recherche/exécuteur de code)". Sur des tâches de codage réelles comme SWE-bench, Aider Polyglot ou Terminal Bench, les résultats du M2.7 sont proches de ceux de Claude 4 Sonnet, alors que ses paramètres activés ne sont que de 10B, pour un coût d'inférence d'environ 1/8e de celui de son concurrent.
2.2 Le compromis entre la voie du texte pur et la voie multimodale
Concentrer les ressources d'entraînement sur une seule direction entraîne des gains et des pertes déterminés. Le tableau ci-dessous résume les principaux compromis entre ces deux approches :
| Dimension | Voie texte pur (M2.7 / DeepSeek-R1) | Voie multimodale (Claude/GPT/Gemini) |
|---|---|---|
| Coût d'entraînement | Concentré, haute efficacité | Dispersé, coût des données élevé |
| Prix par token | Plus faible (0,28 $ – 2 $ / M) | Plus élevé (3 $ – 15 $ / M) |
| Profondeur de raisonnement texte/code | Généralement plus forte | Légèrement plus faible mais suffisante |
| Compréhension image/vidéo | Non supportée | Support natif |
| Étendue des cas d'usage | Focalisée | Plus généraliste |
| Complexité d'intégration technique | Faible | Faible à moyenne |
2.3 "Compléter" les capacités multimodales par l'appel d'outils
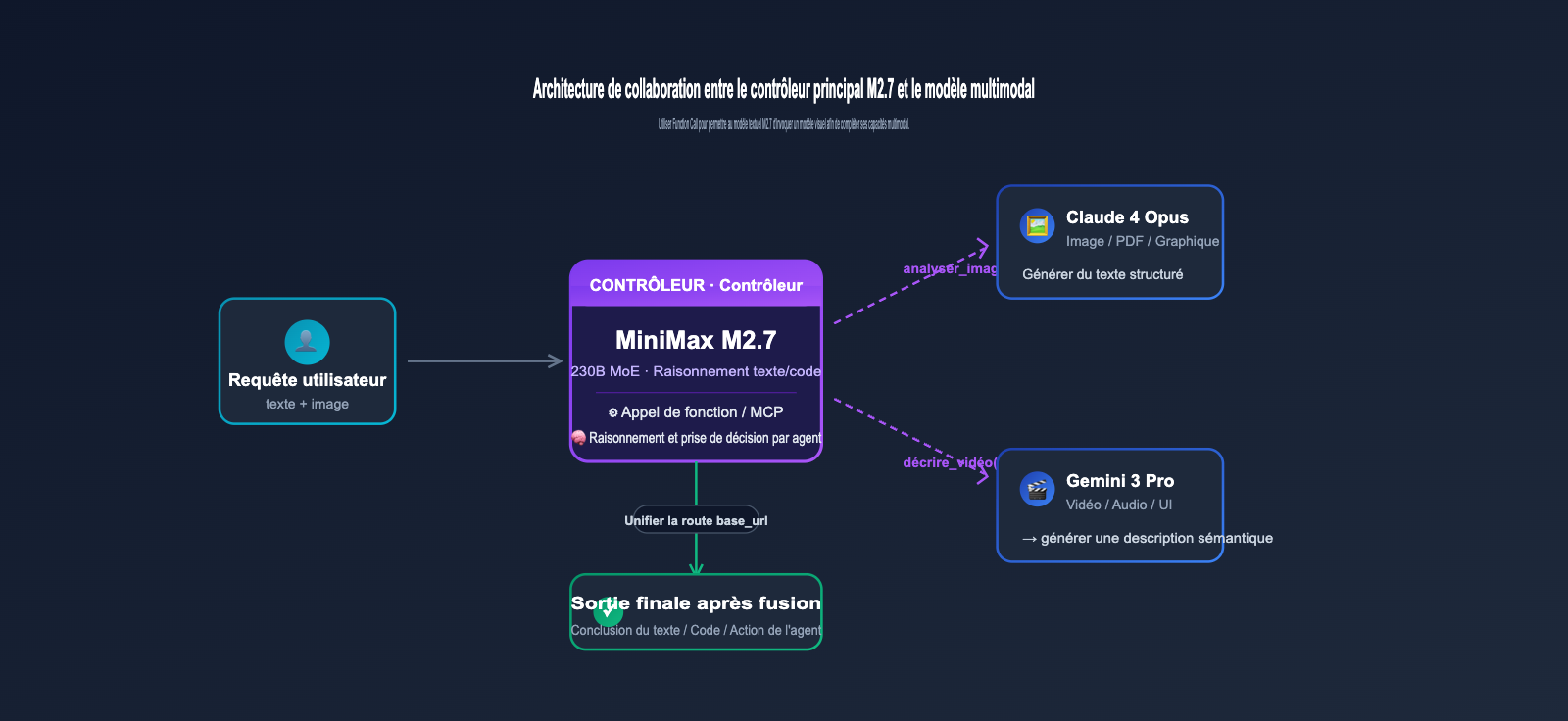
Bien que le M2.7 ne puisse pas traiter les images nativement, il supporte le MCP (Model Context Protocol) et l'appel de fonctions (Function Calling). Cela signifie que les développeurs peuvent laisser le M2.7 "sous-traiter" les tâches de compréhension d'image à des modèles visuels spécialisés (comme Claude 4 Opus ou Gemini 3 Vision), tout en se chargeant uniquement de la coordination et du raisonnement final. Cette architecture de type "contrôleur + collaboration visuelle" est très courante dans les systèmes d'Agents.
三、L'API multimodale est-elle vraiment la norme de l'industrie en 2026 ?
À première vue, l'idée que "multimodal = norme" est devenue un consensus industriel en 2026. Mais en observant de plus près les principaux camps de modèles, on s'aperçoit que ce jugement doit être nuancé.
3.1 Les modèles phares fermés supportent presque tous le multimodal
Les séries Claude 4 d'Anthropic, GPT-5 d'OpenAI et Gemini 3 Pro/Ultra de Google ont toutes fait de l'image une capacité d'entrée fondamentale. Gemini 3 est passé de 11,4 % à 72,7 % sur le test ScreenSpot-Pro, capable de "comprendre" directement les captures d'écran et d'interagir avec l'interface utilisateur ; Claude 4 a également renforcé ses capacités de reconnaissance de graphiques et d'analyse de PDF.
3.2 Une différenciation marquée dans le camp open source / rapport qualité-prix
Le camp open source présente une nette divergence : d'un côté, les modèles "multimodaux full-stack" comme Llama 3.2 Vision, Qwen3-VL et InternVL ; de l'autre, les modèles "spécialisés texte/raisonnement" comme DeepSeek-R1 et MiniMax M2.7, qui misent sur la spécialisation pour obtenir un avantage en termes de rapport qualité-prix. Ces deux types de modèles ne sont pas simplement une question de "haut ou bas de gamme", mais des choix différenciés adaptés à des formes d'applications différentes.
3.3 Comparaison des capacités multimodales des modèles principaux
Le tableau ci-dessous résume les différences de capacités multimodales des principaux grands modèles de langage en mai 2026, permettant de situer rapidement le M2.7 :
| Modèle | Entrée image | Entrée vidéo | Entrée audio | Positionnement principal |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Raisonnement code/Agent |
| Claude 4 Opus | ✅ | ❌ | ❌ | Généraliste + longs textes + code |
| GPT-5 | ✅ | ✅ | ✅ | Multimodal généraliste |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodal + compréhension UI |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Raisonnement mathématique |
| Qwen3-VL | ✅ | ✅ | ❌ | Multimodal open source |
On peut constater que la "norme multimodale" se concentre principalement sur les modèles phares fermés. Dans le camp open source et celui du rapport qualité-prix, la spécialisation textuelle reste une stratégie de différenciation efficace.

IV. Comment permettre à MiniMax M2.7 de traiter des images sans vision native
Bien que le M2.7 ne puisse pas lire les images nativement, il est tout à fait possible de construire une architecture hybride combinant « un contrôleur M2.7 + un modèle de vision » grâce à l'invocation d'outils et au routage. Vous bénéficiez ainsi du faible coût du M2.7 sans sacrifier l'expérience multimodale.
4.1 Architecture d'invocation hybride recommandée
La méthode la plus courante consiste à utiliser une passerelle unifiée (comme le routage multi-modèles proposé par APIYI apiyi.com) pour distribuer les requêtes en fonction du type de contenu. Les requêtes texte/code sont dirigées vers le M2.7, tandis que les requêtes d'images sont envoyées à Claude 4 ou Gemini 3. Le texte généré par le modèle de vision est ensuite renvoyé au M2.7 pour le raisonnement et la décision finale. Cette architecture est transparente pour le front-end et ne nécessite aucune modification de la manière dont le SDK est appelé côté métier.
4.2 Intégration d'un modèle de vision via Function Calling
Si votre application utilise le Function Calling, vous pouvez enregistrer un outil analyze_image pour le M2.7. En interne, cet outil appelle l'interface de vision de Claude/GPT/Gemini et renvoie le résultat de l'analyse au format JSON. Le M2.7 déterminera automatiquement, en fonction de la demande de l'utilisateur, quand appeler cet outil, sans qu'il soit nécessaire de le définir explicitement dans votre invite. Ce modèle est parfaitement adapté aux frameworks d'agents (comme LangGraph, CrewAI ou l'OpenAI Agents SDK).
🎯 Conseil d'intégration : Nous vous recommandons d'utiliser une seule
base_urlvia APIYI apiyi.com pour accéder à la fois au M2.7 et aux modèles multimodaux (comme Claude 4 Opus ou Gemini 3 Pro). Cela vous évite de maintenir des SDK et des clés API distincts pour chaque fournisseur, réduit considérablement la complexité technique de votre architecture hybride et facilite le suivi unifié de la consommation de jetons et des coûts.
4.3 Paramètres d'inférence recommandés
MiniMax recommande officiellement d'utiliser des paramètres d'échantillonnage relativement élevés pour le M2.7 : temperature=1.0, top_p=0.95, top_k=40. Contrairement aux recommandations de faible température pour la plupart des modèles, nos tests montrent que dans les scénarios de codage et d'agents, cette configuration produit un code de meilleure qualité et plus créatif. Si vos modèles d'invites précédents utilisaient une temperature=0 par défaut, vous pourriez obtenir des résultats rigides ou répétitifs avec le M2.7 ; il est donc conseillé de procéder à un ajustement.
V. Prise de décision : MiniMax M2.7 vs modèles multimodaux
Comment choisir entre le M2.7 et un modèle multimodal phare ? La clé réside dans la nature de votre application — est-elle principalement axée sur le "texte/code" ou sur le "multimodal" ? Il ne s'agit pas simplement de comparer le nombre de paramètres.
5.1 Scénarios axés sur le texte/code : privilégiez le M2.7
Si plus de 90 % des requêtes de votre produit sont textuelles (génération de code, questions-réponses sur documents, orchestration d'agents, résumé de longs textes), le M2.7 est actuellement l'un des choix les plus rentables. Avec 230 milliards de paramètres, ses capacités plafonnent près de celles de Claude 4 Sonnet, mais pour une fraction du prix par jeton, ce qui est particulièrement avantageux pour les backends SaaS à haute concurrence.
5.2 Scénarios multimodaux à haute fréquence : privilégiez Claude / Gemini
Si votre cœur de métier repose sur la compréhension d'images (OCR, automatisation d'interface, reconnaissance de produits, aide au diagnostic médical), l'analyse vidéo ou le traitement audio, opter directement pour Claude 4 Opus, GPT-5 ou Gemini 3 Pro sera plus simple et plus fiable qu'une architecture hybride "M2.7 + modèle visuel", réduisant ainsi la latence et le taux d'échec liés aux invocations entre modèles.
5.3 Recommandations de sélection selon les scénarios
| Cas d'usage | Modèle prioritaire | Alternative |
|---|---|---|
| Génération / Refactorisation de code | MiniMax M2.7 | Claude 4 Sonnet |
| Appel d'outils par agent | MiniMax M2.7 | GPT-5 |
| Questions-réponses sur longs documents (jusqu'à 200K) | MiniMax M2.7 | Claude 4 Opus |
| OCR d'images / Questions sur captures d'écran | Gemini 3 Pro | Claude 4 Opus |
| Analyse vidéo | Gemini 3 Pro | GPT-5 |
| RAG multimodal | Claude 4 Opus | Gemini 3 Pro |
| Tâches mixtes (texte dominant + peu d'images) | Combinaison M2.7 + modèle visuel | Modèle unique Claude 4 Opus |
🎯 Conseil de sélection : Le choix d'un modèle ne dépend pas de "qui est le plus puissant", mais de "qui correspond le mieux à la distribution de vos requêtes". Nous vous recommandons d'effectuer des tests A/B avec du trafic réel via la plateforme APIYI (apiyi.com) pour comparer les coûts et la qualité sur des tâches identiques avant de définir votre combinaison de modèles principale.
VI. Foire aux questions sur le MiniMax M2.7
6.1 Le M2.7 est-il vraiment incapable de traiter des images ?
Oui, si vous insérez directement des fichiers image (base64 ou URL) dans les messages, l'interface les rejettera ou renverra une erreur. La seule méthode viable consiste à utiliser d'abord un autre modèle visuel pour convertir l'image en description textuelle, puis à transmettre cette description au M2.7 pour le raisonnement ultérieur.
6.2 Quelle est la différence entre le M2.7 et le M2.7-highspeed ?
Les résultats de sortie sont identiques, seule la vitesse de réponse diffère. Le M2.7-highspeed est adapté aux scénarios sensibles à la latence (comme la complétion de code en temps réel dans un IDE), tandis que la version standard du M2.7 convient aux tâches asynchrones en masse. Les deux versions peuvent être commutées via le nom du modèle dans la console APIYI (apiyi.com), et les paramètres de l'interface sont totalement compatibles.
6.3 Le M2.7 est-il un modèle open source ? Peut-on l'héberger localement ?
Oui, le M2.7 est un modèle à poids ouverts, téléchargeable sur HuggingFace pour un auto-hébergement. Cependant, il nécessite au moins 8 cartes A100 / H100 pour exploiter pleinement la fenêtre de contexte de 200K. Le coût d'un déploiement local est bien plus élevé que celui d'une invocation via API ; sauf en cas d'exigences strictes de conformité des données, l'auto-hébergement n'est pas recommandé.
6.4 Le M2.7 est-il compatible avec les SDK officiels d'Anthropic / OpenAI ?
Il est parfaitement compatible. Vous pouvez utiliser directement les SDK officiels anthropic ou openai en pointant simplement le base_url vers la passerelle du service proxy API (comme le point d'accès unifié d'APIYI apiyi.com) et en changeant le nom du modèle, sans avoir à réécrire votre logique métier. C'est la méthode d'intégration la plus simple pour une architecture hybride.
6.5 Les équipes ayant des besoins multimodaux élevés doivent-elles éviter le M2.7 ?
Pas nécessairement. Même dans les applications multimodales, le raisonnement textuel et l'orchestration représentent une grande partie du volume de requêtes. Nous suggérons de confier la partie multimodale à Claude/Gemini et la partie orchestration et décision textuelle au M2.7, ce qui peut réduire considérablement les coûts globaux d'inférence. Si vous avez besoin d'une solution hybride personnalisée, contactez l'équipe commerciale d'APIYI (apiyi.com) pour obtenir des conseils d'architecture.
VII. Conclusion : Le multimodal est une tendance, mais la "spécialisation" reste une stratégie efficace
Le fait que le MiniMax M2.7 ne prenne pas en charge les entrées d'images n'est pas seulement un constat, c'est un choix stratégique délibéré. En 2026, alors que le multimodal est devenu la norme pour les modèles phares propriétaires, MiniMax a fait le choix de concentrer toutes ses ressources d'entraînement sur le code et les agents, deux domaines où la différenciation est la plus forte. Résultat : des capacités de codage proches de celles de Claude 4 Sonnet, pour un coût d'inférence bien inférieur.
Pour les développeurs, cela signifie que le choix d'un modèle ne se résume plus à une simple comparaison de "qui est le plus polyvalent", mais plutôt à "qui correspond le mieux à la répartition de vos requêtes". Dans les scénarios dominés par le texte ou le code, le M2.7 reste l'un des choix les plus rentables du moment. Pour les besoins fréquents en multimodal, il vaut mieux se tourner vers des spécialistes comme Claude 4 Opus, GPT-5 ou Gemini 3. L'utilisation combinée des deux via une passerelle unifiée permet souvent d'atteindre le meilleur équilibre entre coût et performance.
Si vous souhaitez intégrer le M2.7 et les différents modèles multimodaux phares sous une même base_url, vous pouvez consulter la documentation officielle d'APIYI sur apiyi.com pour accéder à la liste complète des modèles et à des exemples d'intégration.
Auteur : L'équipe APIYI — Nous fournissons en continu aux développeurs IA du monde entier des services de proxy API stables et performants ainsi que du routage multi-modèles. Pour en savoir plus, visitez apiyi.com