L'utilisation de l'invite de cache (Prompt Caching) est devenue un sujet incontournable pour tous les utilisateurs d'API de grands modèles de langage en 2026. Pour une application RAG utilisant une invite système de 8 000 jetons, l'activation ou non du cache peut faire varier votre facture mensuelle d'un facteur 10, voire plus. Cependant, de nombreux développeurs, en passant d'OpenAI à Anthropic, se font piéger par un détail technique crucial : les modèles de facturation du cache diffèrent radicalement entre les deux fournisseurs.
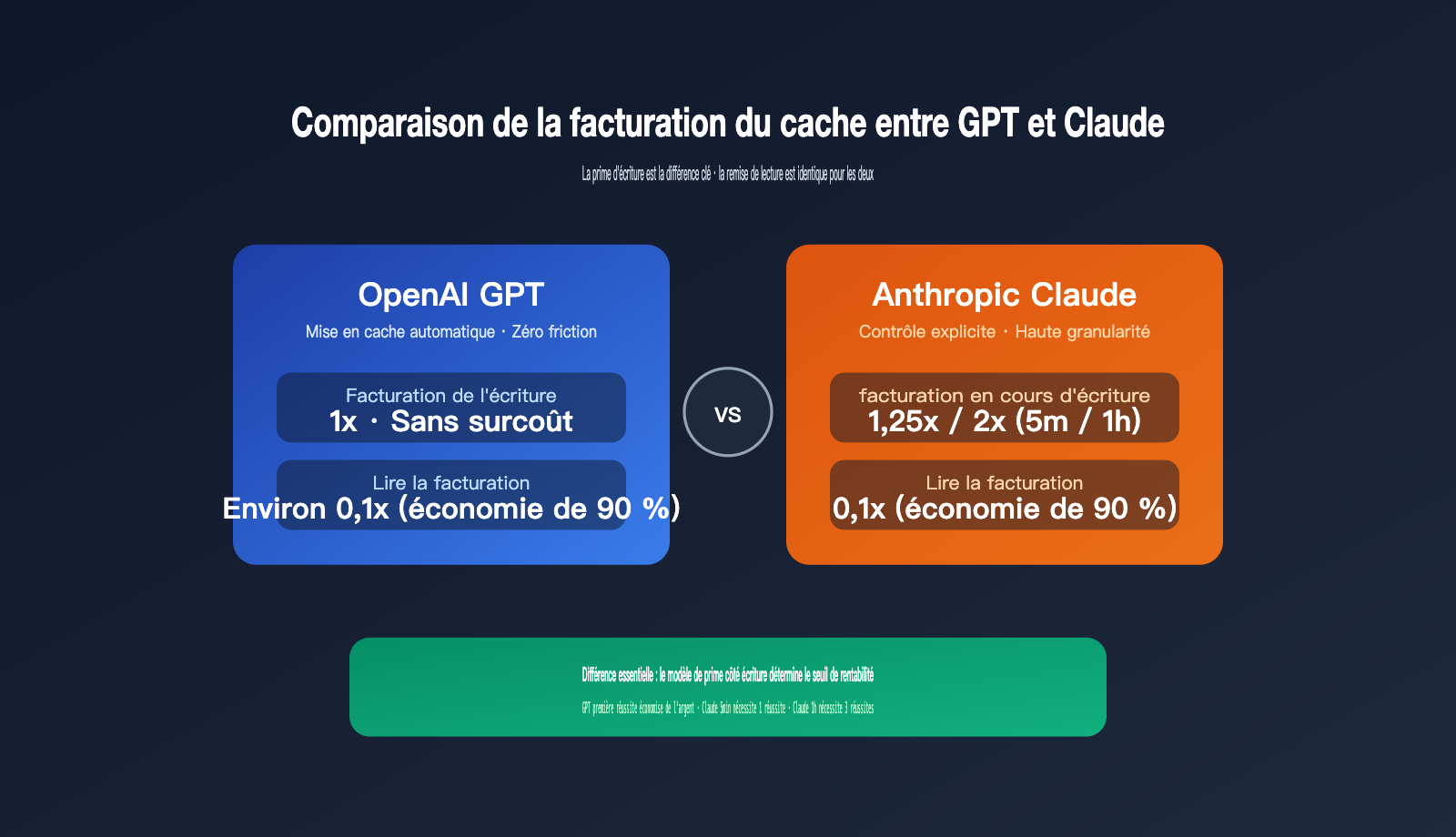
La différence fondamentale tient en une phrase : l'écriture dans le cache de la série GPT est facturée au prix de base (1x) sans surcoût, tandis que l'écriture dans le cache de la série Claude entraîne une majoration de 1,25x (pour 5 minutes) ou 2x (pour 1 heure). Cette nuance peut sembler minime, mais elle impacte significativement le seuil de rentabilité sur des volumes réels. Cet article, basé sur une vérification croisée des documentations officielles, détaille les règles de facturation, les conditions de déclenchement, les remises sur lecture et les stratégies de TTL pour vous aider à estimer vos coûts avec précision.
5 différences majeures entre le cache d'invite GPT et Claude
Voici les conclusions. Le tableau ci-dessous est le plus important à retenir : il regroupe les 5 points critiques souvent négligés concernant la couche de cache.
| Dimension | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Facturation écriture | 1x prix de base, sans surcoût | 5min : 1,25x ; 1h : 2x |
| Facturation lecture | ~0,1x (jusqu'à 90 % de remise) | 0,1x (prix après 10 % de remise) |
| Déclenchement | Entièrement automatique, sans code | Opt-in explicite, via cache_control |
| Seuil min. de jetons | Fixé à 1024 jetons | 1024 / 2048 / 4096 (selon le modèle) |
| TTL du cache | 5–10 min d'inactivité par défaut, max 1h ; mode étendu 24h | 5 minutes par défaut, 1 heure en option (2x écriture) |
La clé pour comprendre ce tableau réside dans la ligne "Facturation écriture". La logique d'OpenAI est la suivante : le cache est gratuit pour vous, la première écriture est facturée au prix de base, et les accès suivants bénéficient d'une remise. Dès la première réutilisation, vous entrez dans une zone de profit pur. La logique de Claude est différente : vous payez d'abord une prime à l'écriture, puis vous récupérez une remise lors des accès, ce qui nécessite un "nombre suffisant de hits" pour amortir le surcoût.
🎯 Conseil de configuration : Si votre trafic est imprévisible et votre taux de succès instable, privilégiez le mécanisme de cache automatique de GPT pour réduire les risques. Si votre taux de succès est très stable (service client, Agents, analyse de longs documents), le contrôle explicite de Claude permet d'obtenir des remises plus importantes. Les API des deux modèles sont disponibles sur APIYI (apiyi.com) ; vous pouvez effectuer des tests comparatifs avec la même clé API pour éviter de multiplier les comptes.
Explication détaillée du mécanisme de facturation de la mise en cache des invites GPT d'OpenAI
La documentation officielle d'OpenAI concernant la mise en cache des invites (Prompt Caching) est très claire : "La mise en cache se fait automatiquement, sans aucune action explicite requise ni coût supplémentaire pour utiliser cette fonctionnalité." En résumé : activation automatique, aucun coût additionnel, et pas une ligne de code à modifier.
Facturation de l'écriture et de la lecture du cache GPT
GPT ne facture aucune surprime pour l'écriture dans le cache. Lorsque vous envoyez une invite système de 8 000 tokens pour la première fois, elle est facturée au prix d'entrée de base, exactement comme si le cache était désactivé. À partir de la deuxième fois, si le système reconnaît que ce préfixe a été mis en cache, la partie correspondante est facturée avec une remise d'environ 90 % par rapport au prix de base.
| Élément | Méthode de facturation | Ratio par rapport au prix de base |
|---|---|---|
| Première écriture en cache | Prix d'entrée de base | 1x (sans surprime) |
| Lecture avec succès (hit) | Remise sur cache | env. 0,1x |
| Frais d'activation | Entièrement gratuit | 0 |
| Modification du code | Aucune | Néant |
La remise réelle est officiellement annoncée comme étant "jusqu'à 90 %", avec de légères variations selon le modèle et la grille tarifaire. Par exemple, le prix d'entrée de base du GPT-5.4 est de 2 $ / 1M de tokens, et le prix en cas de succès de cache est de 0,20 $ / 1M, soit exactement 10 %. Les modèles déjà pris en charge comme GPT-4.1 et GPT-4o suivent globalement ce ratio.
🎯 Vérification des prix : En raison des itérations fréquentes des modèles OpenAI, le prix réel après remise doit être vérifié dans la grille tarifaire officielle. Nous vous recommandons de consulter directement les prix en vigueur sur le tableau de bord d'APIYI (apiyi.com). La plateforme synchronise les ajustements officiels sans facturer de frais de transfert supplémentaires ; les développeurs règlent simplement leur consommation réelle de jetons.
Conditions de succès (hit) du cache GPT
Pour déclencher une mise en cache, deux conditions doivent être remplies simultanément :
- La longueur de l'invite doit être ≥ 1024 tokens (en dessous, elle n'est pas mise en cache).
- Le préfixe de l'invite doit être strictement identique aux requêtes précédentes, avec un découpage par tranches de 128 tokens.
OpenAI a fixé la granularité minimale du cache à 128 tokens. Cela signifie que pour un préfixe stable de 1 500 tokens, tant que les 1 024 premiers tokens sont identiques, la partie restante sera progressivement mise en cache par tranches de 128. Le revers de cette automatisation est un contrôle limité : les développeurs ne peuvent pas spécifier explicitement "quelle partie doit être mise en cache", ils doivent donc placer tout le contenu stable au début.
Comportement du TTL (Time-To-Live) du cache GPT
OpenAI fournit une précision cruciale sur le TTL : le préfixe mis en cache est généralement récupéré après 5 à 10 minutes d'inactivité, avec une conservation maximale de 1 heure. Les modèles plus récents comme GPT-5 et GPT-4.1 prennent également en charge une "rétention étendue" pouvant aller jusqu'à 24 heures.
🎯 Conseil d'utilisation : Lorsque vous accédez à la série GPT via APIYI (apiyi.com), la stratégie de mise en cache automatique d'OpenAI est transparente pour la liaison proxy. Le taux de succès est identique à celui d'une connexion directe aux points de terminaison officiels. Cela signifie que vous pouvez gérer vos factures et jetons OpenAI et Claude de manière unifiée via APIYI, sans aucun coût supplémentaire.
Explication détaillée du mécanisme de facturation de la mise en cache des invites d'Anthropic Claude
La philosophie de conception de Claude est à l'opposé de celle d'OpenAI : elle considère la mise en cache comme une "capacité d'optimisation configurable activement". Les développeurs doivent déclarer explicitement quel contenu mettre en cache et pour quelle durée. Le coût est une surprime à l'écriture, mais le bénéfice est une granularité de contrôle très élevée.
Surprime à l'écriture et remise à la lecture du cache Claude
| Élément | Multiplicateur de facturation | Explication |
|---|---|---|
| Écriture 5 min | 1,25x prix d'entrée de base | TTL par défaut, couvre la plupart des cas |
| Écriture 1 heure | 2x prix d'entrée de base | Adapté aux longues sessions, agents, etc. |
| Lecture avec succès (hit) | 0,1x prix d'entrée de base | Remise de 90 % |
| Frais d'activation | 0 | Aucun frais supplémentaire |
| Modification de configuration | cache_control requis |
Opt-in explicite |
Prenons un exemple concret : le prix d'entrée de base du Claude Opus 4.7 est de 5 $ / 1M de tokens. L'écriture pour 5 min coûte 6,25 $ / 1M, l'écriture pour 1h coûte 10 $ / 1M, et la lecture en cas de succès ne coûte que 0,50 $ / 1M. Cette grille tarifaire est documentée officiellement par Anthropic et est stable depuis plusieurs trimestres.
Seuil minimal de tokens pour le cache Claude
Le nombre minimal de tokens pouvant être mis en cache chez Claude varie selon le modèle, ce qui est le premier piège pour de nombreux utilisateurs.
| Modèle | Tokens minimaux pour le cache |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Si votre préfixe stable est inférieur au seuil minimal du modèle, même avec cache_control, il ne sera pas réellement mis en cache. La requête sera traitée silencieusement comme une requête sans cache : aucune erreur ne sera générée, mais vous penserez avoir activé le cache alors que ce n'est pas le cas. C'est particulièrement important pour l'Opus 4.7 : 4 096 tokens représentent un seuil élevé, difficile à atteindre pour des conversations courtes.
🎯 Conseil de sélection de modèle : Si la longueur de votre contexte métier est instable, nous vous recommandons de privilégier Claude Sonnet 4.5 ou 4.6, dont le seuil minimal est plus bas et le succès de mise en cache plus facile à obtenir. Via APIYI (apiyi.com), vous pouvez basculer entre Sonnet et Opus en un clic, évitant ainsi que la mise en cache ne devienne inutile à cause des seuils de modèle.
Points de rupture (breakpoint) et limites de concurrence pour le cache Claude
Claude permet de définir jusqu'à 4 points de rupture de cache (cache breakpoints) dans une seule requête, avec des TTL différents pour chaque point. C'est la capacité la plus puissante qui distingue Claude de GPT : vous pouvez définir une mise en cache d'1 heure pour l'"invite système", de 5 minutes pour les "fragments de base de connaissances", et ne pas mettre en cache le "contexte utilisateur". Chaque segment est facturé et expire indépendamment.
Dans les scénarios concurrents, une attention particulière est requise : les entrées de cache de Claude ne deviennent effectives pour d'autres requêtes qu'une fois que la première réponse commence à être renvoyée. Si vous envoyez N requêtes identiques en parallèle, seule la première écrira dans le cache, tandis que les N-1 autres seront facturées au prix de base, sans remise. Par conséquent, lors d'appels par lots, il est nécessaire d'envoyer une première requête pour déclencher l'écriture dans le cache avant de lancer les autres en parallèle.
🎯 Conseil pour les appels par lots : Lorsque vous appelez Claude via APIYI (apiyi.com), nous vous recommandons d'envoyer une requête de "préchauffage" pour déclencher l'écriture dans le cache avant de lancer vos lots concurrents. Une fois la réponse amorcée, vous pouvez lancer les requêtes parallèles, ce qui évite les surprimes d'écriture répétées et permet de réaliser des économies substantielles.
L'impact de la prime d'écriture sur la facture réelle : calcul du seuil de rentabilité
Cette section convertit les taux abstraits en montants réels. Supposons une invite système stable de 10 000 tokens, sollicitée N fois sur une fenêtre d'une heure, avec une sortie fixe de 500 tokens. Comparons les coûts totaux pour les deux fournisseurs selon différentes valeurs de N.
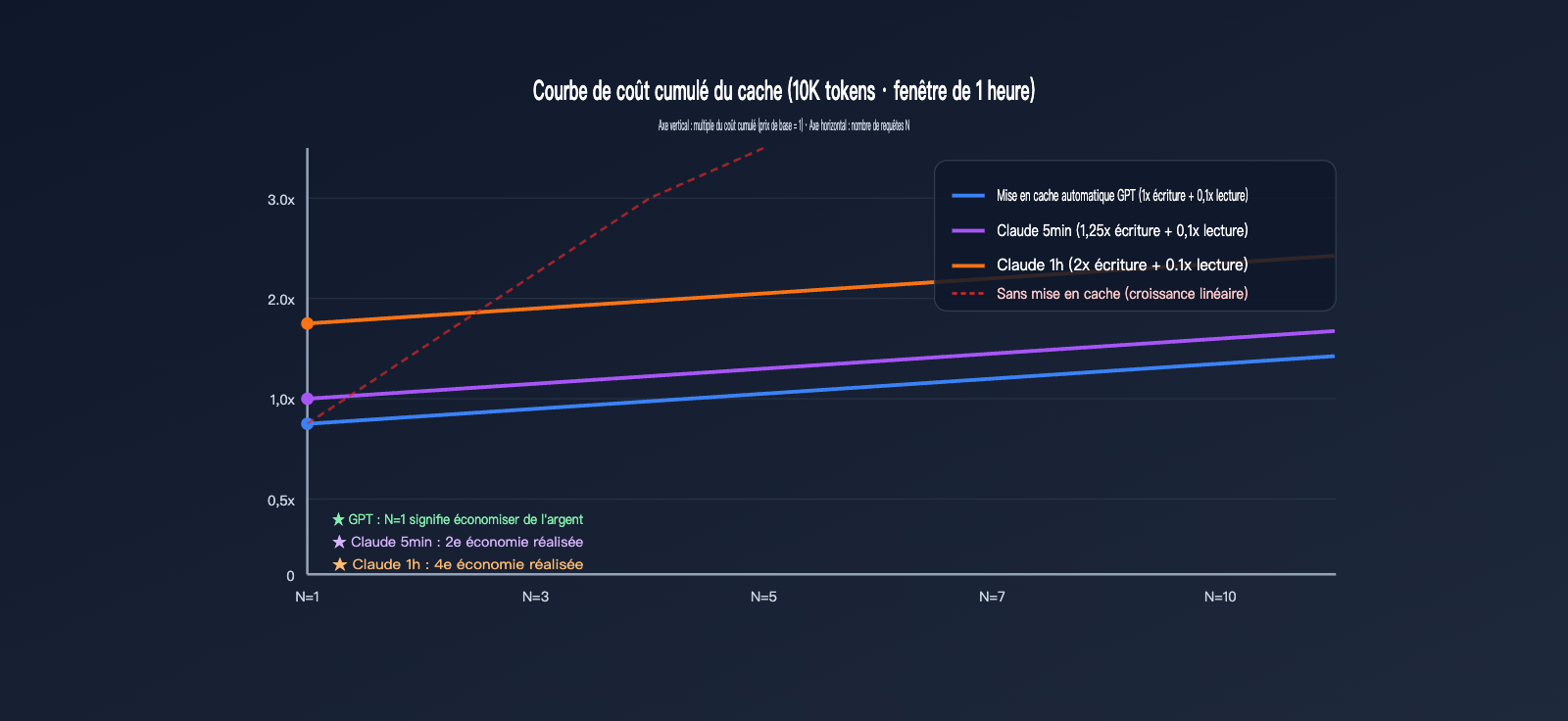
Pour faciliter la comparaison, supposons que les prix de base en entrée des deux fournisseurs soient normalisés à $X/1M tokens. Le coût de base pour 10 000 tokens = 10 × $X / 1000 = $0,01X. Nous ne regardons ici que la partie facturation du cache en entrée, en ignorant la sortie (calculée selon les tarifs propres à chaque fournisseur).
| Nombre de requêtes N | Cache auto GPT | Cache 5min Claude | Cache 1h Claude |
|---|---|---|---|
| N=1 (écriture initiale) | $0,01X | $0,0125X | $0,02X |
| N=2 | $0,011X | $0,0135X | $0,021X |
| N=5 | $0,014X | $0,0165X | $0,024X |
| N=10 | $0,019X | $0,0215X | $0,029X |
| Sans cache (référence) | $0,01X × N | $0,01X × N | $0,01X × N |
| Lectures pour rentabiliser | 0 fois (gain dès la 1ère) | 1 fois (gain dès la 2ème) | 3 fois (gain dès la 4ème) |
Un fait clé se dégage : le cache GPT est rentable dès N=1 — car l'écriture est facturée à 1x et les hits bénéficient de remises, c'est donc toujours gagnant. Le cache 5min de Claude nécessite au moins 1 hit pour amortir la prime d'écriture de 0,25x, et le cache 1h nécessite 3 hits. Si votre préfixe stable n'est utilisé qu'une fois par jour, le cache 1h de Claude sera plus coûteux que l'absence de cache.
Comment choisir le TTL dans un contexte métier réel
Ce calcul offre des conseils pratiques très clairs :
- Fréquence faible ou irrégulière : privilégiez le cache automatique de GPT, c'est une économie sans effort.
- Fréquence élevée, hits multiples en 5 minutes (ex: service client, applications Web) : le cache 5min de Claude maximise les gains, avec une faible prime d'écriture et des remises importantes sur la lecture.
- Tâches longues, réutilisation sur plusieurs heures (ex: Agent de codage, dialogue sur documents longs) : le cache 1h de Claude est pertinent, à condition de garantir au moins 3 hits.
- Taux de hit incertain : commencez toujours par le 5min, et envisagez de passer à 1h une fois le flux stabilisé.
🎯 Conseil d'analyse : Le backend d'APIYI (apiyi.com) fournit des statistiques sur le champ
cached_tokenspar requête, ce qui permet de voir directement votre taux de hit réel. Nous vous recommandons de faire tourner votre trafic de production pendant une semaine avant de décider d'augmenter agressivement le TTL à 1 heure.
Stratégies de cache recommandées selon les scénarios métier
Une fois les différences de facturation comprises, il est temps de les appliquer à vos cas d'usage. Voici les scénarios courants classés par stratégie recommandée.
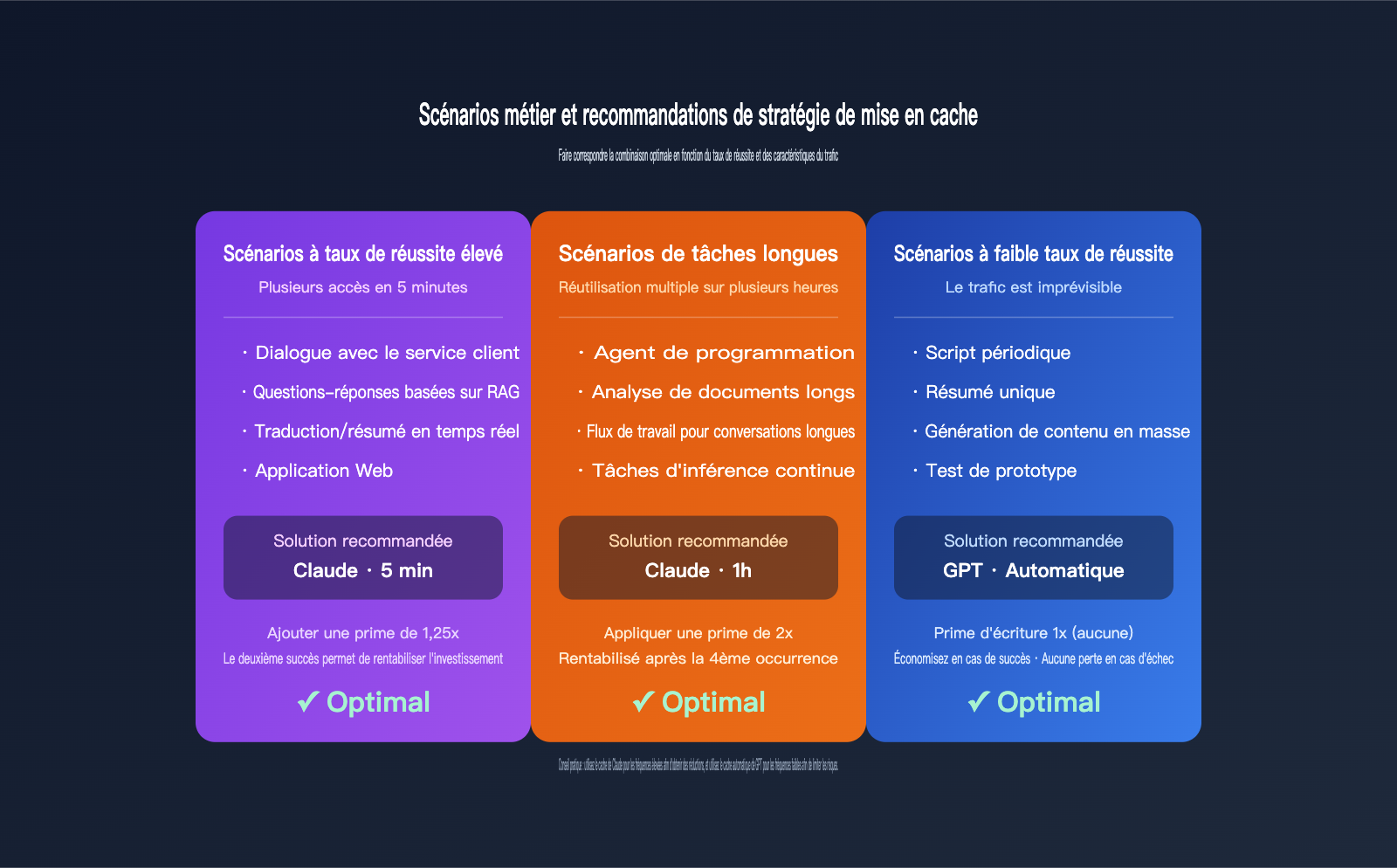
Scénario 1 : RAG à haute fréquence et questions-réponses d'entreprise
Dans ces scénarios, le préfixe stable contient généralement l'invite système et des fragments de base de connaissances. Les hits sont fréquents au sein d'une même session, dépassant facilement 10 requêtes en 5 minutes. Le cache 5min de Claude permet ici de réduire les coûts d'entrée de plus de 80 %, ce qui est le plus rentable. Pour une session longue d'une heure, envisagez le cache 1h.
Scénario 2 : Agents de programmation et flux de travail longs
Pour les agents de codage comme Claude Code ou OpenCode, une tâche peut durer une demi-heure, voire plusieurs heures, avec des lectures répétées de la structure du projet, du fichier CLAUDE.md et des résultats d'appels d'outils précédents. Dans ce cas, le cache 1h de Claude est la solution optimale, car le nombre de hits dépasse largement le seuil de rentabilité de 3.
Scénario 3 : Requêtes à faible fréquence ou imprévisibles
Par exemple, pour des scripts périodiques, la génération par lots d'articles SEO ou le résumé de longs documents ponctuels, l'intervalle entre chaque requête peut largement dépasser 5 minutes. Nous recommandons de privilégier la famille GPT avec son cache automatique : si ça hit, c'est gagné, et si ça ne hit pas, vous ne perdez rien. C'est beaucoup plus tolérant que le cache explicite de Claude.
Scénario 4 : Compression d'entrée purement sensible aux coûts
Si votre objectif principal est de réduire au maximum le coût d'une invite de 10K+ tokens, utilisez directement Claude Sonnet 4.6 avec le cache 5min : la prime d'écriture n'est que de 25 %, et un seul hit suffit pour rentabiliser l'opération, ramenant le prix de lecture à $0,075/1M (base $3 × 0,025).
| Scénario métier | Modèle recommandé | TTL recommandé | Raison |
|---|---|---|---|
| Service client/RAG/Q&R | Claude Sonnet | 5 minutes | Hits fréquents, rentabilité rapide |
| Programmation/Agents | Claude Sonnet/Opus | 1 heure | Plus de 3 hits par heure |
| Scripts/Batch | GPT-4.1 / GPT-5.x | Automatique | Hits instables, prime d'écriture nulle |
| Analyse de documents | GPT-5.x | Automatique | Tâche unique, taux de hit faible |
| Sensible aux coûts | Claude Sonnet 4.6 | 5 minutes | Prix de cache efficace le plus bas |
🎯 Conseil d'architecture hybride : En production, GPT et Claude ne sont pas mutuellement exclusifs, ils se complètent selon les cas d'usage. Nous recommandons d'utiliser une passerelle unique comme APIYI (apiyi.com) pour accéder aux deux modèles, et de router dynamiquement le trafic : les flux à fort taux de hit vers le cache Claude, et les flux à faible taux de hit vers le cache automatique de GPT. Vous pouvez ainsi réduire votre facture globale de plus de 40 %.
FAQ : Questions fréquentes
Q1 : GPT ne facture-t-il vraiment pas de surcoût pour l'écriture en cache ? Est-ce caché dans un autre frais ?
Oui, la documentation officielle d'OpenAI est claire : « No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature. » L'écriture en cache est facturée au prix de base des entrées, sans aucun surcoût caché. Vous ne payez que le tarif réduit pour la partie mise en cache (le "hit"), et le tarif de base pour ce qui n'est pas mis en cache. C'est comme si la fonctionnalité de cache était offerte.
Q2 : Le surcoût d'écriture de 1,25x ou 2x chez Claude s'applique-t-il à toute l'invite ou seulement à la partie mise en cache ?
Seulement à la partie marquée par cache_control. Par exemple, si vous avez une invite de 10 000 jetons dont 8 000 sont marqués pour le cache, le surcoût de 1,25x ne s'applique qu'à ces 8 000 jetons, les 2 000 restants étant facturés au tarif de base 1x. Il est donc conseillé de définir vos points de rupture (breakpoints) avec précision pour éviter d'inclure inutilement du contenu dans le surcoût.
Q3 : Le service proxy API APIYI répercute-t-il fidèlement la facturation du cache des deux fournisseurs ?
APIYI (apiyi.com) assure une transparence totale pour la facturation du cache de GPT et de Claude. Les remises sur les "hits" de cache automatique de GPT, ainsi que les surcoûts d'écriture (1,25x/2x) et les réductions de lecture (0,1x) de Claude, correspondent exactement aux tarifs officiels sur votre facture. Le champ cache_control est également transmis tel quel, vous permettant de réutiliser directement le code du SDK officiel.
Q4 : Dans quel cas le cache 1h de Claude est-il moins rentable que de ne pas utiliser de cache ?
Lorsque le nombre réel de "hits" dans la fenêtre d'une heure est inférieur à 3, le surcoût du cache 1h (écriture 2x) n'est pas amorti. Par exemple, si une invite n'est appelée qu'au début et à la fin de la session utilisateur (soit 2 fois au total), activer le cache 1h vous coûtera plus cher qu'une requête sans cache. Dans ce scénario, il vaut mieux passer à un cache de 5 minutes ou le désactiver complètement.
Q5 : Le cache automatique de GPT peut-il divulguer mes données d'invite ?
La documentation d'OpenAI précise que le cache est isolé au niveau de l'organisation et n'est pas partagé entre les comptes. Depuis le 05/02/2026, Claude a renforcé cette isolation au niveau de l'espace de travail (workspace-level). Les deux fournisseurs offrent des garanties de sécurité des données équivalentes, adaptées aux besoins des entreprises. En passant par APIYI (apiyi.com), l'isolation au niveau des jetons renforce encore cette protection.
Q6 : Comment surveiller le taux de réussite (hit rate) du cache ? Les deux fournisseurs exposent-ils des champs dédiés ?
OpenAI renvoie le champ cached_tokens dans l'objet usage, tandis que Claude renvoie cache_creation_input_tokens et cache_read_input_tokens. Le premier indique le volume écrit en cache, le second le volume de "hits". Nous vous recommandons d'enregistrer ces champs dans vos journaux d'activité pour créer un tableau de bord de suivi et ajuster vos stratégies de TTL (Time To Live).
Q7 : Si mon projet utilise à la fois GPT et Claude, comment configurer mes jetons ?
Nous recommandons la solution de jeton unifié d'APIYI (apiyi.com), qui permet d'utiliser une seule clé sk-xxx pour accéder à la fois à GPT et à Claude. Vous pouvez consulter la facturation par modèle dans votre tableau de bord, évitant ainsi la gestion fastidieuse de plusieurs comptes, soldes et rapprochements bancaires. Cette approche unifiée facilite également les tests A/B pour comparer les coûts réels des deux modèles sur vos cas d'usage.
Conclusion : Comprendre le surcoût d'écriture est la première étape de l'optimisation
Pour revenir au point central de cet article : la différence fondamentale entre la gestion du cache de GPT et de Claude réside dans leur modèle de surcoût à l'écriture. GPT privilégie une activation automatique sans friction et sans surcoût, tandis que Claude mise sur un contrôle explicite, échangeant un surcoût à l'écriture contre une réduction plus fine à la lecture. Aucune approche n'est supérieure à l'autre ; tout dépend des caractéristiques de votre trafic.
Si votre application nécessite un contrôle précis avec un trafic stable et un taux de "hit" élevé, le surcoût de 1,25x/2x de Claude sera facilement amorti, et ses options de TTL (5min/1h) offrent une flexibilité que GPT ne propose pas. Si votre application est axée sur un trafic sporadique avec un besoin de simplicité immédiate, le modèle de cache automatique sans surcoût de GPT est le choix le plus sûr.
🎯 Conseil final : La meilleure pratique en matière d'optimisation des coûts est de ne pas choisir un seul camp. Utilisez APIYI (apiyi.com) pour accéder aux deux modèles et router vos requêtes en fonction du scénario : privilégiez Claude pour les flux à haute fréquence afin de maximiser les remises, et GPT pour les flux à basse fréquence afin de limiter les risques. Une seule clé, une seule facture, une comparaison facile : c'est la stratégie la plus efficace pour les équipes techniques en 2026.
— L'équipe technique APIYI | Suivi continu des évolutions tarifaires des grands modèles de langage. Plus de comparatifs approfondis sur le centre d'aide d'APIYI (apiyi.com).