Note de l'auteur : Je partage ici mon expérience pratique avec Claude Opus 4.7 pour le traitement de fichiers CSV et Excel. Je vous explique pourquoi vous ne devriez jamais envoyer de gros tableaux directement à une IA, et pourquoi il est préférable de lui demander d'écrire des scripts, de construire des outils et d'effectuer des vérifications.
Si vous avez un fichier CSV ou Excel de plus de 900 lignes et 50 colonnes et que vous demandez simplement à Claude Opus 4.7 : « Traite ce tableau pour moi », vous obtiendrez probablement une réponse qui semble intelligente, mais qui sera impossible à reproduire. Le problème ne vient pas d'un manque de puissance de Claude Opus 4.7, mais du fait que vous l'utilisez comme un simple lecteur de données humain plutôt que comme un concepteur de flux de traitement de données.
La meilleure approche consiste à fournir à Claude Opus 4.7 un petit échantillon de données, une description complète des champs et le résultat attendu. Demandez-lui ensuite d'écrire un script Python, de générer un outil web ou de concevoir un pipeline de données reproductible, puis utilisez ce script pour traiter l'intégralité de vos données. Cela permet non seulement de tirer parti des capacités de raisonnement et de codage du modèle, mais aussi de confier les calculs, le filtrage, l'agrégation et la validation à des programmes déterministes.

Points clés pour le traitement de CSV avec Claude Opus 4.7
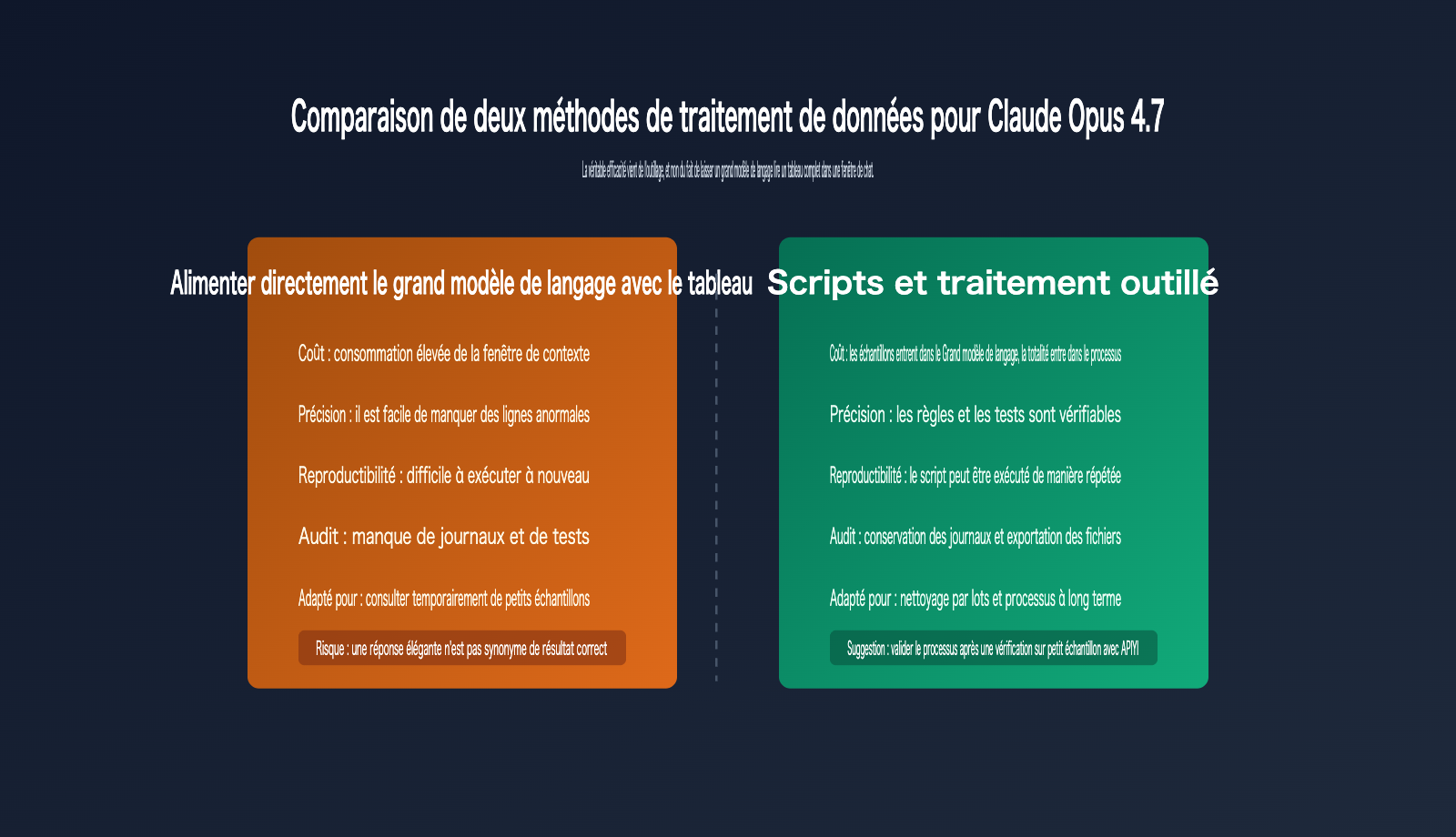
Claude Opus 4.7 est déjà un modèle très performant en matière de codage et de flux de travail agentiques. L'éditeur souligne d'ailleurs qu'il est adapté aux codes complexes, aux flux de travail en entreprise et aux scénarios de feuilles de calcul. Mais « fenêtre de contexte plus large » ne signifie pas « je devrais insérer tout le tableau dans la conversation », surtout lorsque les données contiennent de nombreuses lignes répétitives, des valeurs aberrantes, des colonnes masquées, des formats confus ou des règles métier complexes. Envoyer des données brutes directement est inefficace et rend les résultats difficiles à auditer.
La méthode vraiment efficace pour traiter des CSV avec Claude Opus 4.7 consiste à placer le modèle à trois niveaux : compréhension des objectifs métier, génération du programme de traitement et interprétation des résultats. Quant à la lecture ligne par ligne, la conversion de types, la déduplication, l'agrégation, le tri et l'exportation de fichiers, ces tâches doivent être confiées à Python, SQL, des outils côté navigateur ou à la chaîne d'outils d'analyse de données intégrée de Claude.
| Scénario | Problèmes liés à la lecture directe par l'IA | Approche recommandée avec Claude Opus 4.7 | Avantages des résultats |
|---|---|---|---|
| CSV 900 lignes × 50 colonnes | Consommation élevée du contexte, risque d'omission | Fournir 20 lignes d'échantillon et la description des champs, demander un script pandas | Reproductible, exécution par lots |
| Excel multi-feuilles | Formules masquées, cellules fusionnées, formatage impactant | Demander d'abord un script de détection de structure, puis un aperçu du classeur | Compréhension avant traitement |
| Filtrage par règles métier | Risque d'omission des conditions aux limites | Demander à Claude de convertir les règles en fonctions et tests unitaires | Règles claires, vérifiables |
| Génération de rapports | Réponse unique difficile à vérifier | Demander à Claude de générer un script d'exportation et un résumé de validation | Sortie stable, facile à livrer |
Il existe un jugement crucial à retenir : Claude Opus 4.7 peut « participer à l'analyse de données », mais ne devrait pas devenir « l'unique environnement d'exécution des données ». Si vous devez vérifier à plusieurs reprises vos invites de traitement de données ou vos choix de modèles via une API, nous vous suggérons d'utiliser le service proxy API APIYI (apiyi.com) pour effectuer des tests sur de petits échantillons, puis d'intégrer les invites stables dans vos scripts, évitant ainsi de devoir copier à nouveau le gros tableau à chaque fois.
Principes de répartition des tâches avec Claude Opus 4.7
Claude Opus 4.7 est idéal pour les jugements de haut niveau, comme l'inférence de la signification des champs, la conception de stratégies de nettoyage, la détection d'anomalies, la génération de code et l'interprétation des résultats. Il n'est pas conçu pour effectuer des calculs déterministes directement dans la fenêtre de chat, car le texte du tableau peut perdre une partie de ses informations structurelles et il n'est pas pratique d'y gérer des exécutions répétées ou des versions.
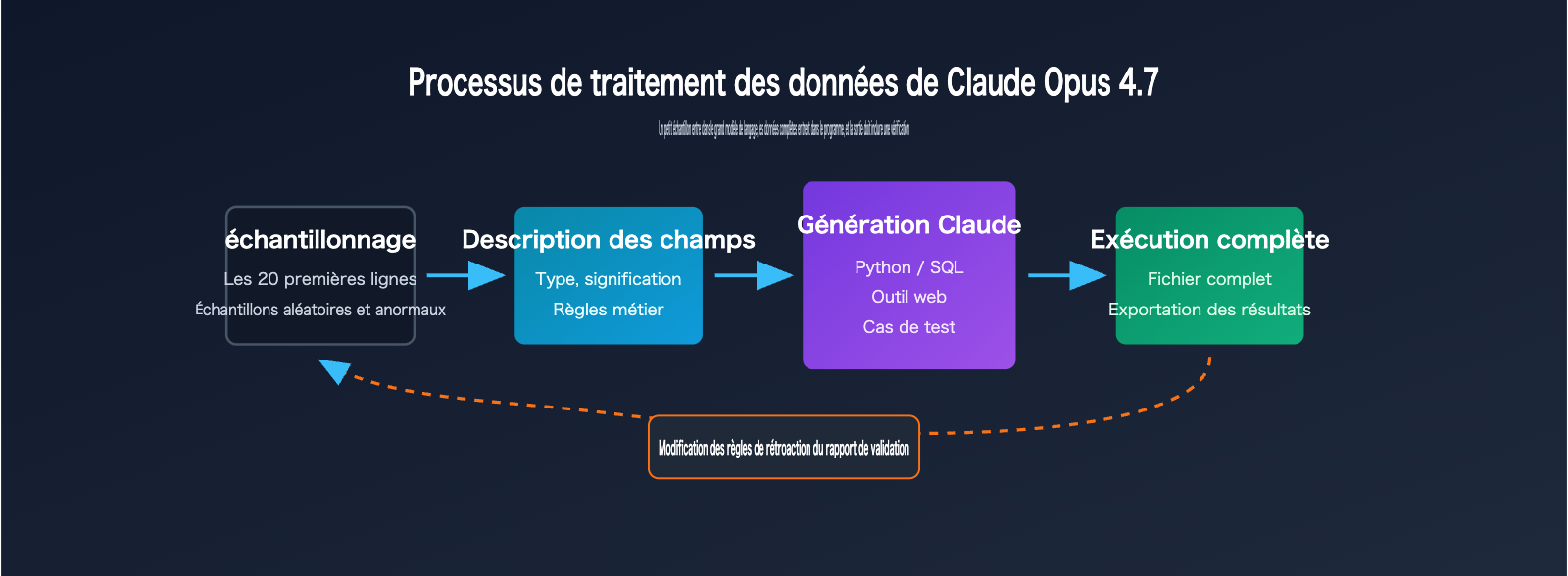
Un principe plus robuste est : « Donnez les petits échantillons au modèle, et les gros volumes de données au programme ». Vous pouvez d'abord fournir les 20 premières lignes, 20 lignes aléatoires et 20 lignes contenant des anomalies, puis compléter avec un dictionnaire de champs et le résultat attendu. Une fois que Claude Opus 4.7 a généré le script à partir de ces informations, vous pouvez laisser le script traiter l'intégralité du fichier CSV ou Excel. Ainsi, le modèle se charge de la conception et le programme de l'exécution.
Pourquoi ne pas simplement « nourrir » Claude Opus 4.7 avec de gros fichiers Excel ?
Bien que les fichiers Excel et CSV semblent similaires, leur complexité est radicalement différente. Le CSV est une structure textuelle simple, tandis qu'un fichier Excel peut contenir plusieurs feuilles, des formules, des mises en forme, des filtres, des colonnes masquées, des cellules fusionnées, des séries de dates et des formats numériques localisés. Copier-coller directement un Excel dans une IA écrase généralement ces informations cruciales, transformant votre classeur en un texte plat et corrompu que le modèle ne peut pas interpréter correctement.
La documentation officielle indique que les produits Claude prennent déjà en charge des outils d'analyse, l'exécution de code, des plugins de données et des fonctionnalités spécifiques à Excel. Cela prouve une chose : le traitement des tableaux doit reposer sur un environnement d'outils, et non sur le simple « calcul mental » du modèle dans une fenêtre de chat. Même si Claude Opus 4.7 dispose d'une fenêtre de contexte plus large, il est préférable d'utiliser cette capacité pour définir des règles métier, des descriptions de champs, des exemples et des exigences de validation, plutôt que de la gaspiller avec les lignes et colonnes brutes d'un tableau entier.
| Caractéristiques des données | Risques liés à l'import direct | Entrée recommandée pour Claude Opus 4.7 | Outil d'exécution recommandé |
|---|---|---|---|
| Beaucoup de colonnes | Difficulté à mémoriser le sens | Dictionnaire des champs, types, explications | pandas, SQL |
| Beaucoup de lignes | Coût en tokens, résultats instables | Échantillons (tête, aléatoire, anomalies) | Traitement par lots Python |
| Plusieurs feuilles | Perte des relations entre feuilles | Résumé de la structure, utilité des feuilles | openpyxl, plugins Excel |
| Données sales | Valeurs aberrantes impactant l'inférence | Statistiques de valeurs manquantes, doublons | Scripts de qualité des données |
| Règles complexes | Interprétations erronées | Règles claires, contre-exemples, sorties attendues | Tests unitaires, scripts de validation |
Conseil technique : Si vous devez intégrer Claude Opus 4.7 dans un système existant, commencez par une validation au niveau de l'interface via APIYI (apiyi.com). Il est conseillé de tester vos invites, paramètres de modèle et gestion des erreurs avec de petits échantillons avant de passer au traitement complet des fichiers.
Les erreurs classiques avec Claude Opus 4.7 et Excel
La première erreur consiste à croire que « le modèle comprend le tableau » signifie « le modèle doit traiter le gros tableau directement ». Pour des petits fichiers ou des analyses exploratoires, l'importation est pratique. Mais pour du nettoyage en masse, du scoring de listes clients ou de la réconciliation financière, vous avez besoin de règles reproductibles, pas d'une réponse unique en langage naturel.
La seconde erreur est de ne fournir que les 20 premières lignes. Celles-ci ne montrent généralement que la structure normale et ne couvrent pas les cas limites. Une meilleure approche consiste à combiner « 20 premières lignes + 20 lignes aléatoires + 20 lignes d'anomalies + dictionnaire des champs + 3 exemples de sortie cible ». C'est ainsi que Claude Opus 4.7 pourra générer une logique de traitement réellement robuste.
Flux de travail en 5 étapes pour traiter des CSV avec Claude Opus 4.7
Ce processus convient à la plupart des tâches d'automatisation, surtout pour les fichiers de plus de 500 lignes, plus de 20 colonnes ou des règles nécessitant des ajustements fréquents.
| Étape | Matériel pour Claude Opus 4.7 | Contenu généré par Claude | Points à confirmer par l'humain |
|---|---|---|---|
| 1. Détection | Format, noms de champs, échantillons | Hypothèses de types et plan de nettoyage | Sens des champs |
| 2. Définition | Objectifs, conditions, contre-exemples | Tableau de règles et conditions limites | Couverture des exceptions |
| 3. Script | Échantillons, format de sortie | Script Python ou SQL | Exécutabilité locale |
| 4. Validation | 20 à 60 lignes d'échantillons | Sortie attendue et assertions de test | Intuition des résultats |
| 5. Exécution | Chemin du fichier complet | Fichiers de résultats, logs, rapports | Cohérence des totaux/groupes |
La valeur ajoutée de ce flux est de transformer une « question unique » en un « actif exécutable ». Si les règles métier changent, il suffit de demander à Claude Opus 4.7 de modifier le script, sans avoir à recharger toutes les données ou à réexpliquer tout le contexte.
Modèle d'invite pour le traitement CSV
Vous pouvez réutiliser cette structure. Ne vous contentez pas de coller le contenu du CSV, précisez les objectifs et les standards de qualité.
J'ai une tâche de traitement de données CSV/Excel, merci de ne pas donner de conclusion directe.
Objectif :
Noter la table client par secteur, poste et taille d'entreprise pour extraire les top leads.
Échantillons de données :
1. 20 premières lignes : ...
2. 20 lignes aléatoires : ...
3. 20 lignes d'anomalies : ...
Description des champs :
- company_name : nom de l'entreprise
- title : poste du contact
- employee_count : nombre d'employés (peut être vide)
- industry : secteur (peut contenir des synonymes)
Veuillez :
1. Expliquer les champs et les problèmes potentiels de qualité
2. Écrire un script Python pour lire input.csv
3. Générer cleaned.csv et scored.csv
4. Ajouter des validations : lignes, valeurs vides, doublons, distribution des scores
5. Ne pas deviner les champs inconnus, marquer les règles incertaines avec TODO
Si vous souhaitez transformer cela en service API, utilisez APIYI (apiyi.com) pour tester Claude Opus 4.7 ou d'autres modèles. Cela permet de comparer rapidement leurs performances en génération de code et en gestion des exceptions.
Exemple Python pour Claude Opus 4.7
Voici une version minimaliste illustrant la bonne approche : Claude Opus 4.7 écrit le script, et le script traite le fichier complet.
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Colonnes manquantes : {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"lignes": len(df), "doublons": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
Pour les tâches automatisées, utilisez APIYI (apiyi.com) pour gérer les appels de modèles, les tentatives en cas d'échec et la conservation des logs, rendant votre chaîne de traitement beaucoup plus facile à maintenir.
Choix d'outils pour traiter Excel avec Claude Opus 4.7
Chaque tâche nécessite un outil spécifique. Pour une exploration ponctuelle, les capacités d'analyse de Claude ou le plugin Data sont parfaits. En revanche, pour des flux de production, privilégiez les scripts Python, les pipelines SQL ou des outils web dédiés. Si votre équipe compte des collaborateurs non techniques, demandez à Claude Opus 4.7 de générer un outil web local doté d'une interface visuelle pour le téléchargement, la sélection de règles et le téléchargement des résultats.
| Solution d'outil | Tâches adaptées | Tâches inadaptées | Usage recommandé |
|---|---|---|---|
| Script Python | Nettoyage en masse, scoring, rapprochement, export | Équipes ne maîtrisant pas la ligne de commande | Demander à Claude d'écrire le script et le README |
| Outil web local | Traitement récurrent de fichiers par des non-techniciens | Gestion complexe des droits et collaboration multi-utilisateurs | Demander à Claude de générer du HTML/JS ou un service léger |
| Pipeline SQL | Entrepôts de données, commandes, analyse de logs | Petits tableaux Excel ponctuels | Demander à Claude d'écrire les requêtes et le SQL de validation |
| Outil de données Claude | Analyse exploratoire, graphiques, rapports temporaires | Besoins de conformité stricts ou automatisation à long terme | Explorer d'abord, puis transformer en script |
| Flux de travail API | Comparaison de modèles, intégration de systèmes automatisés | Tâches manuelles uniques | Débogage via une interface unifiée |
Idées pour un outil web de traitement Excel avec Claude Opus 4.7
Lorsque les utilisateurs ne maîtrisent pas Python, « demander à Claude de créer un outil web » est souvent plus pratique que de lui demander de lire directement un CSV. Un outil web peut offrir des boutons de téléchargement, une mise en correspondance des champs, une configuration des règles, une prévisualisation et un bouton d'export. L'utilisateur n'a plus qu'à changer de fichier sans avoir à dialoguer sans cesse avec l'IA.
Vous pouvez demander à Claude Opus 4.7 : « Génère un outil HTML unique qui utilise Papa Parse pour lire le CSV, effectue la mise en correspondance des champs et le scoring côté client, puis exporte le nouveau CSV. » Pour des tâches avec peu de données, des règles non confidentielles et une exécution locale dans le navigateur, cette approche est très économique. Pour des besoins plus complexes en termes de droits, d'audit ou de gros fichiers, passez à un service backend.
Conseil de mise en œuvre : Si vous souhaitez intégrer à votre outil web l'interprétation de modèles, des suggestions de correspondance de champs ou un diagnostic d'anomalies, vous pouvez appeler les interfaces de modèles via APIYI (apiyi.com). Le frontend se charge de l'interaction, tandis que le backend gère les requêtes au modèle et la journalisation.
Liste de contrôle pour le traitement CSV avec Claude Opus 4.7
Le plus grand risque dans le traitement de données n'est pas une erreur de code, mais un code qui produit silencieusement des résultats erronés. Par conséquent, que vous demandiez à Claude Opus 4.7 d'écrire du Python, du SQL ou un outil web, exigez qu'il génère systématiquement une liste de contrôle. Cette liste n'a pas besoin d'être complexe, mais elle doit couvrir le nombre de lignes, les champs, les valeurs nulles, les doublons, les indicateurs clés et un échantillonnage pour vérification.
| Point de contrôle | Pourquoi est-ce important ? | Méthode de vérification recommandée | Suggestion de traitement des anomalies |
|---|---|---|---|
| Nombre de lignes (E/S) | Éviter les suppressions ou duplications | Comparer len(input) et len(output) |
Expliquer les différences |
| Champs requis | Éviter les erreurs de calcul dues aux changements de noms | Vérifier l'ensemble des colonnes | Erreur immédiate si champ manquant |
| Taux de valeurs nulles | Éviter les biais de scoring ou de classification | Statistiques par colonne | Écrire un avertissement si seuil dépassé |
| Enregistrements en double | Éviter la double facturation ou sollicitation | Déduplication par clé primaire ou composée | Conserver le rapport des doublons |
| Somme des montants/quantités | Éviter les erreurs de logique d'agrégation | Comparer les totaux avant/après regroupement | Arrêt en cas d'incohérence |
| Échantillonnage | Détecter les biais d'interprétation des règles | Vérification humaine sur 20 lignes aléatoires | Retourner le problème à Claude pour ajuster les règles |
En pratique, vous pouvez intégrer ce tableau directement dans votre invite pour que Claude Opus 4.7 ajoute automatiquement les contrôles correspondants lors de la génération du script. Lorsque nous effectuons des tests d'invocation du modèle sur APIYI (apiyi.com), nous recommandons également d'exiger la sortie de la validation comme retour fixe, ce qui facilite la comparaison de la stabilité des différents modèles plutôt que de se fier uniquement à l'esthétique d'une réponse.
Exemples d'invites à éviter avec Claude Opus 4.7
Ne vous contentez pas de dire « Aide-moi à nettoyer ce tableau ». Une meilleure approche serait : « Indique-moi d'abord quels champs sont nécessaires avant d'écrire le script ; ne donne pas de conclusion finale directement ; génère des logs à chaque étape ; marque par un TODO les règles indécises ; génère 5 exemples de tests unitaires ». De telles contraintes forcent le modèle à expliciter ses déductions implicites et vous permettent de détecter plus rapidement s'il a mal compris les enjeux métier.
De même, ne considérez pas les 20 premières lignes comme une vérité absolue. Elles sont utiles pour que Claude Opus 4.7 comprenne la structure, mais insuffisantes pour couvrir les données corrompues. Fournissez des échantillons d'anomalies : valeurs nulles, doublons, formats de date incohérents, montants négatifs, fautes d'orthographe dans les énumérations, ou mélange de chinois et d'anglais.
FAQ sur le traitement des fichiers CSV avec Claude Opus 4.7
Un échantillon des 20 premières lignes est-il suffisant pour que Claude Opus 4.7 traite un CSV ?
C'est un bon point de départ, mais ce n'est pas suffisant. Les 20 premières lignes permettent de comprendre la structure des champs et les enregistrements standards, mais elles ne couvrent pas les données aberrantes. Je vous recommande plutôt une combinaison : « 20 premières lignes + 20 lignes aléatoires + 20 lignes contenant des anomalies ». Une fois l'échantillon fourni à Claude Opus 4.7, demandez-lui de rédiger un script pour traiter le fichier complet, plutôt que de se baser uniquement sur l'échantillon pour tirer des conclusions.
Faut-il télécharger le fichier Excel complet pour que Claude Opus 4.7 le traite ?
Pour une exploration ponctuelle, vous pouvez télécharger le fichier et utiliser les outils d'analyse intégrés. En revanche, pour des processus métier destinés à être réutilisés, demandez d'abord à Claude Opus 4.7 de rédiger un script de détection de structure, puis de générer le script de traitement. Pour les scénarios d'automatisation via API, vous pouvez utiliser APIYI (apiyi.com) pour tester un petit échantillon et confirmer que le modèle comprend bien les champs et les règles avant de lancer le traitement complet.
La fenêtre de contexte de 1M de Claude Opus 4.7 rend-elle les scripts inutiles pour les CSV ?
Absolument pas. Une fenêtre de contexte plus large permet d'inclure davantage de descriptions de champs, d'échantillons et de contexte métier, mais elle ne remplace pas un programme de calcul reproductible. Surtout lorsqu'il s'agit de montants, de classements, de regroupements, de dédoublonnage ou de définitions statistiques, les scripts et les contrôles de validation restent la base pour garantir des résultats fiables.
Quelle est la différence entre le traitement Excel par Claude Opus 4.7 et la BI traditionnelle ?
Claude Opus 4.7 excelle à transformer des besoins flous en règles, en code et en explications, tandis que la BI traditionnelle est plus adaptée aux rapports stables, à la gestion des droits, à la modélisation des données et à la collaboration multi-utilisateurs. Les deux ne sont pas incompatibles : vous pouvez utiliser Claude pour générer des scripts de nettoyage et une logique d'analyse, puis intégrer les résultats consolidés dans votre outil de BI ou votre entrepôt de données.
Claude Opus 4.7 est-il utile pour traiter des CSV si je n'ai aucune base en programmation ?
Oui, mais je vous conseille de lui demander de générer un outil web local ou des instructions détaillées, plutôt que d'attendre qu'il affiche directement le résultat final dans le chat. Vous pouvez lui demander de transformer la logique de traitement en boutons, formulaires et fonctions de téléchargement, afin que vous n'ayez qu'à gérer l'importation du fichier et la vérification des résultats. Si vous avez besoin d'accéder à l'interface du modèle, APIYI (apiyi.com) est idéal pour tester rapidement la génération de code par différents modèles.
Quelles précautions prendre avec Claude Opus 4.7 pour des fichiers Excel sensibles ?
Les données sensibles doivent être anonymisées ou traitées dans un environnement contrôlé. Ne transmettez jamais de numéros de carte d'identité, de numéros de téléphone, de contrats clients ou de détails financiers bruts dans un environnement non sécurisé. La méthode la plus sûre consiste à fournir un échantillon anonymisé et la structure des champs, à laisser Claude rédiger le script, puis à exécuter le traitement complet des données localement ou dans votre environnement d'entreprise.
Points clés : Traitement des CSV avec Claude Opus 4.7
- La meilleure approche avec Claude Opus 4.7 n'est pas de lui faire lire un énorme tableau complet, mais de générer un script exécutable basé sur des échantillons et des règles.
- Les 20 premières lignes aident à comprendre la structure, mais les tâches réelles nécessitent des échantillons aléatoires, des cas d'anomalies et un dictionnaire de champs.
- Excel est plus complexe que le CSV (multiples feuilles, formules, colonnes masquées, formats) : commencez toujours par une détection de structure.
- Pour les tâches par lots, le Python, le SQL ou les outils web locaux sont plus reproductibles qu'une réponse unique dans une fenêtre de chat.
- Une liste de contrôle doit être générée avec le script de traitement, en se concentrant sur le nombre de lignes, les champs, les valeurs nulles, les doublons et les totaux clés.
- Pour les scénarios d'automatisation API, testez d'abord le modèle sur un petit échantillon avant d'intégrer la solution stable dans votre chaîne de production.
Conseils pour le traitement de fichiers Excel avec Claude Opus 4.7
Claude Opus 4.7 est particulièrement performant pour les tâches liées aux données, mais la bonne approche ne consiste pas à « balancer le tableau à l'IA », mais plutôt à « demander à l'IA de concevoir des outils pour traiter le tableau ». Lorsque le volume de données atteint plusieurs centaines de lignes et dizaines de colonnes, ou que les règles métier doivent être réutilisées fréquemment, les scripts, les outils web, les pipelines SQL et les rapports de validation constituent des options bien plus rentables.
Vous pouvez considérer Claude Opus 4.7 comme un assistant en ingénierie des données : laissez-le analyser un petit échantillon, clarifier les règles, rédiger des scripts de traitement, générer des tests et interpréter les résultats. Cela permet de conserver l'avantage du Grand modèle de langage dans la compréhension de la sémantique métier, tout en évitant l'inefficacité et le manque de traçabilité liés à l'alimentation directe en données brutes.
Si vous développez des solutions liées à Claude Opus 4.7, au format CSV, à Excel ou à l'automatisation des données, je vous recommande d'utiliser d'abord APIYI (apiyi.com) pour l'invocation du modèle et la validation de vos invites, puis de transformer vos processus stables en scripts ou en outils. Cela permet de mieux contrôler les coûts et rend les résultats plus faciles à vérifier par votre équipe et à maintenir sur le long terme.
Références :
- Anthropic Claude Opus 4.7 : anthropic.com/claude/opus
- Guide d'utilisation de Claude Opus 4.7 : claude.com/resources/tutorials/working-with-claude-opus-4-7
- Outil d'exécution de code Claude : platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Plugin de données Claude : claude.com/plugins/data