Note de l'auteur : Une comparaison objective des capacités de programmation, de la qualité du code, de la fenêtre de contexte, du prix et de l'expérience développeur entre Claude Code et GPT-5.4, pour vous aider à déterminer s'il est temps de changer d'outil.
Le jour du lancement de GPT-5.4, une tendance a rapidement émergé sur les réseaux sociaux : "Résiliez votre abonnement à Claude Code !" Les arguments semblent solides : une fenêtre de contexte de 1M, des performances de pointe sur tous les tableaux, et le problème du "ton trop robotique" enfin résolu.
Mais la réalité est plus complexe. Les données de benchmark indiquent que Claude Opus 4.6 domine toujours le benchmark de programmation SWE-Bench avec un score de 80,8 %, contre 77,2 % pour GPT-5.4. Quant aux retours réels de la communauté des développeurs, ils sont pour le moins partagés.
Valeur ajoutée : Cet article compare objectivement Claude Code et GPT-5.4 selon 6 dimensions clés pour vous aider à décider s'il faut switcher — ou si la stratégie la plus intelligente ne serait pas d'utiliser les deux en complément.
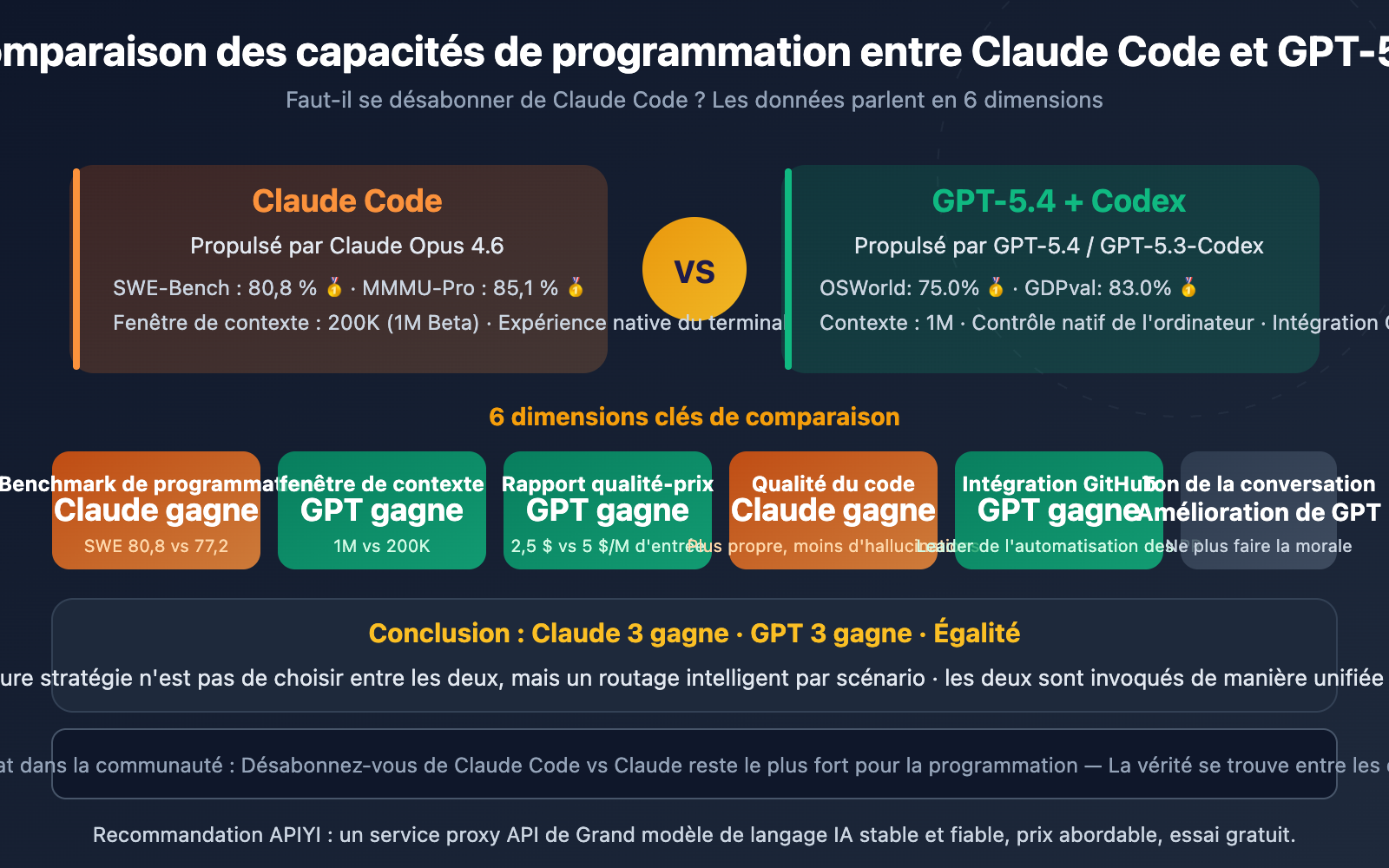
Comparaison des données clés : Claude Code vs GPT-5.4
| Dimension de comparaison | Claude Code (Opus 4.6) | GPT-5.4 / Codex | Vainqueur |
|---|---|---|---|
| Programmation SWE-Bench | 80,8 % | 77,2 % | Claude |
| Raisonnement visuel MMMU-Pro | 85,1 % | 81,2 % | Claude |
| Travail intellectuel GDPval | 78,0 % | 83,0 % | GPT |
| Contrôle de l'ordinateur OSWorld | 72,7 % | 75,0 % | GPT |
| Mathématiques FrontierMath | 27,2 % | 47,6 % | GPT |
| Terminal Terminal-Bench | 65,4 % | 75,1 % | GPT |
| Fenêtre de contexte | 200K (1M Beta) | 1 000K | GPT |
| Prix d'entrée API | 5,00 $/M | 2,50 $/M | GPT |
| Prix de sortie API | 25,00 $/M | 15,00 $/M | GPT |
| Propreté du code | Plus propre, plus normé | Standard | Claude |
| Refactorisation et débogage | En tête | Standard | Claude |
| Automatisation des PR GitHub | Moyen | Intégration profonde | GPT |
Le score est de 4 victoires pour Claude contre 8 pour GPT — mais ne tirez pas de conclusions hâtives. Dans un contexte de programmation, le poids du SWE-Bench, de la qualité du code et des capacités de refactorisation est bien plus important que celui du travail intellectuel général ou du contrôle de l'ordinateur. Décortiquons cela point par point.
Analyse approfondie des capacités de programmation : Claude Code vs GPT-5.4
Dimension 1 : Benchmarks de programmation — Claude Code en tête
Sur le benchmark de programmation le plus suivi, SWE-Bench Verified (capacité à corriger de réels tickets GitHub) :
| Modèle | SWE-Bench Verified | SWE-Bench Pro |
|---|---|---|
| Claude Opus 4.6 | 80,8 % 🥇 | — |
| Gemini 3.1 Pro | 80,6 % | — |
| GPT-5.4 | 77,2 % | 57,7 % |
Claude Opus 4.6 devance GPT-5.4 de 3,6 points de pourcentage. Dans des scénarios de correction de code en production — compréhension d'architectures multi-fichiers, suivi de chaînes de dépendances complexes — Claude fait preuve d'une meilleure compréhension structurelle du code.
Cependant, GPT-5.4 domine largement sur Terminal-Bench 2.0 (tâches intensives en ligne de commande) avec 75,1 % contre 65,4 % pour Claude. Si votre flux de travail dépend fortement des opérations en terminal, GPT a l'avantage.
Dimension 2 : Qualité du code et expérience développeur — Claude Code est plus propre
Les retours de nombreuses communautés de développeurs convergent vers la même conclusion : le code généré par Claude est plus propre, suit de meilleurs patterns et présente moins d'hallucinations.
Concrètement :
- Tâches de refactorisation : Claude est plus performant pour les refactorisations complexes et le débogage.
- Compréhension d'architecture : Lors de l'analyse de gros dépôts et d'architectures en couches, la chaîne de raisonnement de Claude est plus stable, avec moins de dérive contextuelle.
- Vitesse de génération : La vitesse initiale de Claude Code est plus rapide (environ 1200 lignes en 5 minutes contre environ 200 lignes en 10 minutes pour Codex).
L'avantage de GPT-5.4 réside plutôt dans la génération de documentation et l'écriture de code "boilerplate" (modèles de code) — des tâches qui ne nécessitent pas une compréhension profonde de l'architecture du projet.
Dimension 3 : Fenêtre de contexte — GPT-5.4 écrase la concurrence
C'est l'atout structurel majeur de GPT-5.4 :
| Capacité | Claude Code | GPT-5.4 |
|---|---|---|
| Contexte standard | 200K | 1 000K |
| Contexte Beta | 1M | — |
| Sortie maximale | 32K | 128K |
Une fenêtre de 1M de tokens signifie que vous pouvez injecter l'intégralité d'un codebase de production en une seule fois. Attention toutefois : les requêtes dépassant 272K tokens sont facturées au double du prix d'entrée et 1,5 fois le prix de sortie. En pratique, la plupart des tâches de programmation ne nécessitent pas un contexte supérieur à 200K.
🎯 Conseil pratique : La fenêtre de contexte est l'atout majeur de GPT-5.4, mais elle n'est réellement utile que pour manipuler des codebases gigantesques. Pour des projets de taille petite ou moyenne, les 200K de Claude, couplés à sa meilleure compréhension architecturale, constituent probablement un meilleur choix. Les deux sont accessibles via l'invocation du modèle unifiée sur APIYI (apiyi.com).
Dimension 4 : Prix — GPT-5.4 offre un meilleur rapport qualité-prix
Le tarif de l'API de GPT-5.4 est globalement inférieur à celui de Claude Opus 4.6 :
- Entrée (Input) : 2,50 $ vs 5,00 $/M (50 % moins cher)
- Sortie (Output) : 15,00 $ vs 25,00 $/M (40 % moins cher)
- Entrée en cache : 0,25 $ vs 0,50 $/M (50 % moins cher)
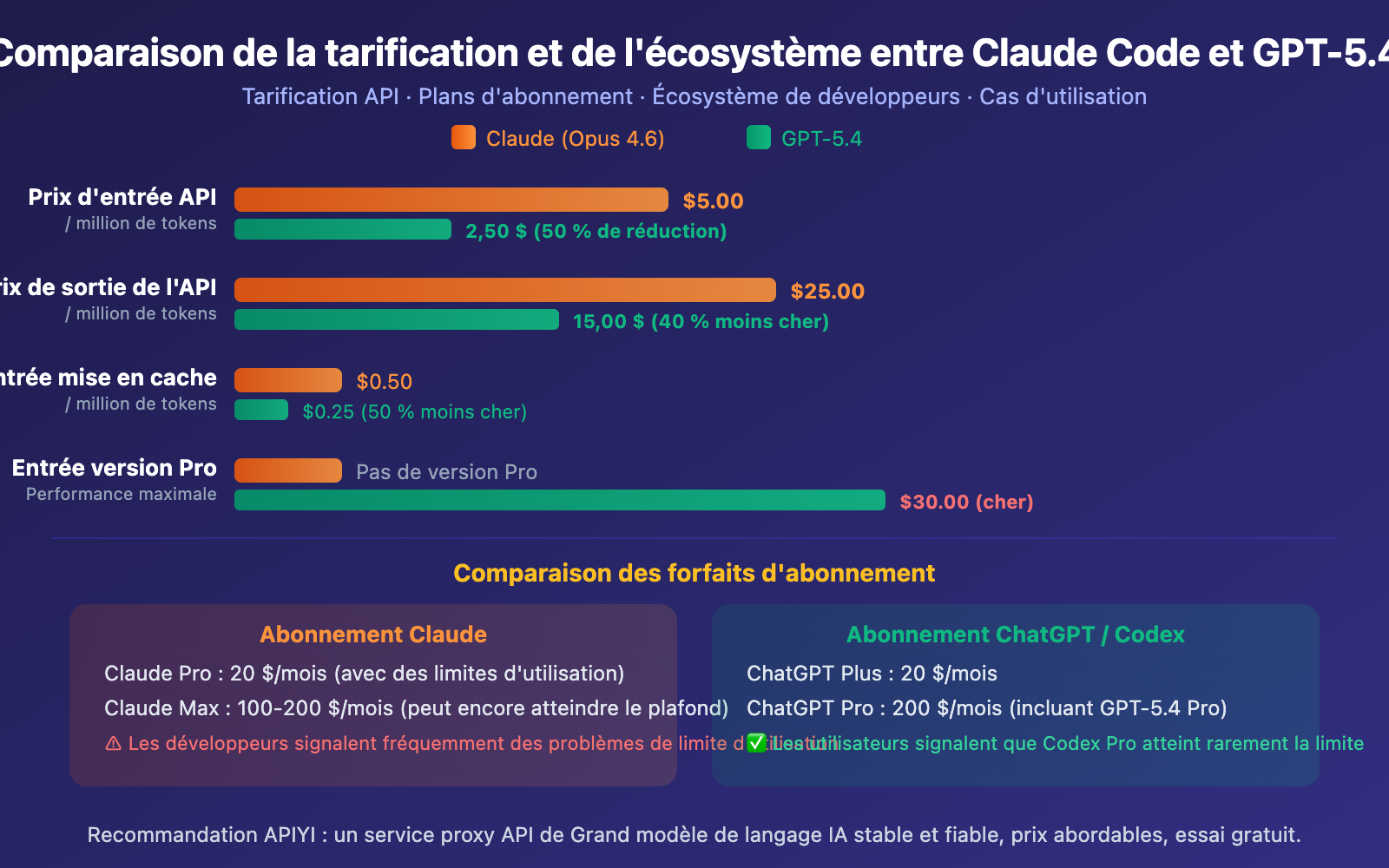
Au niveau des abonnements, la communauté des développeurs s'accorde à dire que les restrictions d'utilisation de Claude sont plus sévères. Le forfait Codex à 20 $/mois offre des quotas d'utilisation bien plus généreux que le forfait Claude Pro à 17 $/mois. De nombreux développeurs rapportent que Codex Pro n'atteint presque jamais ses limites, alors que les utilisateurs de Claude rencontrent fréquemment des limitations de débit, même sur des forfaits plus coûteux.
Dimension 5 : Intégration GitHub — GPT Codex prend une avance nette
C'est une différence souvent négligée, mais qui a un impact énorme sur le flux de travail des développeurs.
Selon les retours d'expérience : les revues de PR (Pull Request) de Claude Code "donnent des commentaires verbeux mais passent à côté de bugs évidents", tandis que Codex parvient à détecter des "bugs réellement difficiles à débusquer", incluant des commentaires en ligne et des flux de travail de correction exploitables. L'application GitHub de Codex assure également une cohérence de comportement parfaite entre l'interface CLI et l'interface Web.
Dimension 6 : Ton de la conversation — Le problème du "parler robotique" de GPT-5.x s'estompe
C'est le troisième point souvent soulevé sur les réseaux sociaux. La série GPT-5 a effectivement évolué, passant d'un style "très robotique" à une amélioration progressive :
- GPT-5.0 : Critiqué pour être un "robot froid".
- GPT-5.1 : Ajout de plus de chaleur et de fluidité conversationnelle.
- GPT-5.3 Instant : Mise en avant du "less cringe" (moins gênant), avec une réduction des hallucinations de 26,8 %.
- GPT-5.4 : Hérite des améliorations de ton de la version 5.3 tout en renforçant ses capacités professionnelles.
Cependant, pour être objectif, Claude est toujours considéré comme supérieur en termes de conversation naturelle et de lisibilité des explications de code. Sur ce point, GPT-5.4 s'est amélioré mais reste encore un peu en retrait.
🎯 Optimisation des coûts : Quel que soit le modèle que vous choisissez, passer par le service proxy API de APIYI (apiyi.com) vous permet de bénéficier d'une facturation plus flexible. Les tarifs de GPT-5.4 sont synchronisés avec le site officiel (2,50 $ / 15,00 $), et vous recevez 10 % de bonus à partir de 100 $ de recharge.
Claude Code vs GPT-5.4 : Conseils de sélection par scénario

Exemple d'invocation de l'API Claude Code vs GPT-5.4
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# Refactorisation complexe → utilisez Claude Opus 4.6 (meilleure qualité de code)
refactor_result = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "Refactoriser l'architecture d'injection de dépendances de ce module"}]
)
# Analyse de base de code massive → utilisez GPT-5.4 (fenêtre de contexte de 1M)
analysis_result = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Analyser les failles de sécurité de l'ensemble du projet"}]
)
Conseil : En créant un compte sur APIYI (apiyi.com), vous pouvez invoquer simultanément Claude et GPT-5.4. Les tarifs de GPT-5.4 sont alignés sur le site officiel, avec un bonus de 10 % à partir de 100 $ de recharge. Pour changer de modèle selon le scénario, il suffit de modifier un seul paramètre.
Questions Fréquentes
Q1 : Dois-je résilier mon abonnement à Claude Code ?
Cela dépend de votre scénario de travail principal. Si votre besoin central est la refactorisation de code complexe et la correction de bugs de niveau production, Claude reste le choix le plus puissant (leader avec 80,8 % sur SWE-Bench). Si vous avez besoin d'une fenêtre de contexte ultra-large, d'une intégration GitHub et de coûts réduits, GPT-5.4 / Codex est plus avantageux. La meilleure stratégie n'est pas de choisir l'un ou l'autre, mais d'invoquer les deux via API selon le scénario.
Q2 : Les capacités de programmation de GPT-5.4 sont-elles vraiment supérieures sur tous les plans ?
Non. GPT-5.4 mène sur des dimensions comme GDPval (travail intellectuel), OSWorld (contrôle de l'ordinateur) et FrontierMath (mathématiques), mais sur le benchmark de programmation le plus crucial, SWE-Bench, Claude Opus 4.6 garde l'avantage avec 80,8 % contre 77,2 %. En termes de qualité de code, de capacité de refactorisation et de compréhension d'architecture, la communauté des développeurs a tendance à préférer Claude. Les deux peuvent être invoqués et comparés de manière unifiée via APIYI (apiyi.com).
Q3 : Comment utiliser Claude et GPT-5.4 simultanément ?
Inscrivez-vous sur APIYI (apiyi.com) pour :
- Obtenir une clé API unifiée.
- Définir
base_urlsurhttps://vip.apiyi.com/v1. - Utiliser
model="claude-opus-4-6"pour les tâches de refactorisation. - Utiliser
model="gpt-5.4"pour l'analyse de grands projets. - Utiliser
model="gpt-5.3-chat-latest"pour les tâches quotidiennes (le plus économique).
Bonus de 10 % dès 100 $ de recharge, un seul compte couvre tous les modèles majeurs.
Résumé
Voici les conclusions clés du duel Claude Code vs GPT-5.4 :
- Claude reste en tête sur les benchmarks de programmation : Avec 80,8 % sur SWE-Bench contre 77,2 % pour GPT, Claude produit un code plus propre et se montre plus performant pour le refactoring et le débogage. Dire qu'il faut "résilier Claude Code" est donc bien trop prématuré.
- GPT-5.4 écrase la concurrence sur le contexte et le rapport qualité-prix : Une fenêtre de contexte de 1M de tokens (5 fois celle de Claude), des tarifs API 40 à 50 % moins chers et une intégration GitHub plus profonde. C'est l'outil idéal pour les projets massifs et les budgets serrés.
- La stratégie gagnante est l'usage hybride : Utilisez Claude pour le refactoring et la correction de bugs complexes, GPT-5.4 pour l'analyse de bases de code volumineuses et les opérations en terminal, et GPT-5.3 Instant pour les tâches quotidiennes afin d'économiser vos crédits.
Ne vous laissez pas influencer par les titres "putaclic" qui vous poussent à abandonner l'un pour l'autre. Un développeur malin choisit l'outil le plus adapté à la situation, sans prêter allégeance à une seule marque.
Nous vous recommandons de passer par APIYI (apiyi.com) pour centraliser vos accès à Claude et GPT-5.4. Une seule clé API pour tous les modèles, avec un bonus de 10 % dès 100 $ de recharge.
📚 Ressources et Références
-
Comparaison approfondie Claude Code vs Codex : Le point de vue de l'équipe Builder.io.
- Lien :
builder.io/blog/codex-vs-claude-code - Description : Comparaison pratique incluant les tarifs, la qualité du code et l'intégration GitHub.
- Lien :
-
Analyse concurrentielle : GPT-5.4 cible Claude : Comment GPT-5.4 se positionne face à son rival.
- Lien :
trendingtopics.eu/gpt-5-4-targets-anthropics-claude-with-premium-pricing-and-coding-muscle/ - Description : Analyse poussée du positionnement premium de GPT-5.4 Pro et de ses ambitions en programmation.
- Lien :
-
Duel multidimensionnel GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro : Données sur 12 benchmarks.
- Lien :
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - Description : La comparaison la plus complète des trois géants, avec analyse de compétitivité et conseils de sélection.
- Lien :
-
Benchmark développeur Claude Sonnet 4.6 vs GPT-5 : Tests en conditions réelles par SitePoint.
- Lien :
sitepoint.com/claude-sonnet-4-6-vs-gpt-5-the-2026-developer-benchmark/ - Description : Données comparatives sur des tâches spécifiques comme le refactoring, le débogage et la génération de documentation.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à débattre dans la section commentaires. Pour plus de ressources, visitez notre centre de documentation sur docs.apiyi.com.