¡Un descubrimiento interesante! Recientemente, muchos desarrolladores que han estado probando el modelo M2.7 de MiniMax, lanzado en marzo de 2026, se han topado con un problema contraintuitivo: este modelo insignia, apodado el "rey del código y los flujos de trabajo de agentes", no admite entradas de imagen. Teniendo en cuenta que en la era actual de Claude 4, GPT-5 y Gemini 3 la capacidad multimodal es un estándar, resulta sorprendente que un modelo insignia de 230B de parámetros no pueda procesar imágenes. Este artículo, basado en la documentación oficial de MiniMax, las tarjetas de modelo de NVIDIA NIM y las especificaciones públicas de OpenRouter, junto con las observaciones de APIYI (apiyi.com) en despliegues reales, analiza a fondo la lógica de producto detrás del enfoque "solo texto" del M2.7.
I. ¿Es cierto que el MiniMax M2.7 no admite entrada de imágenes?
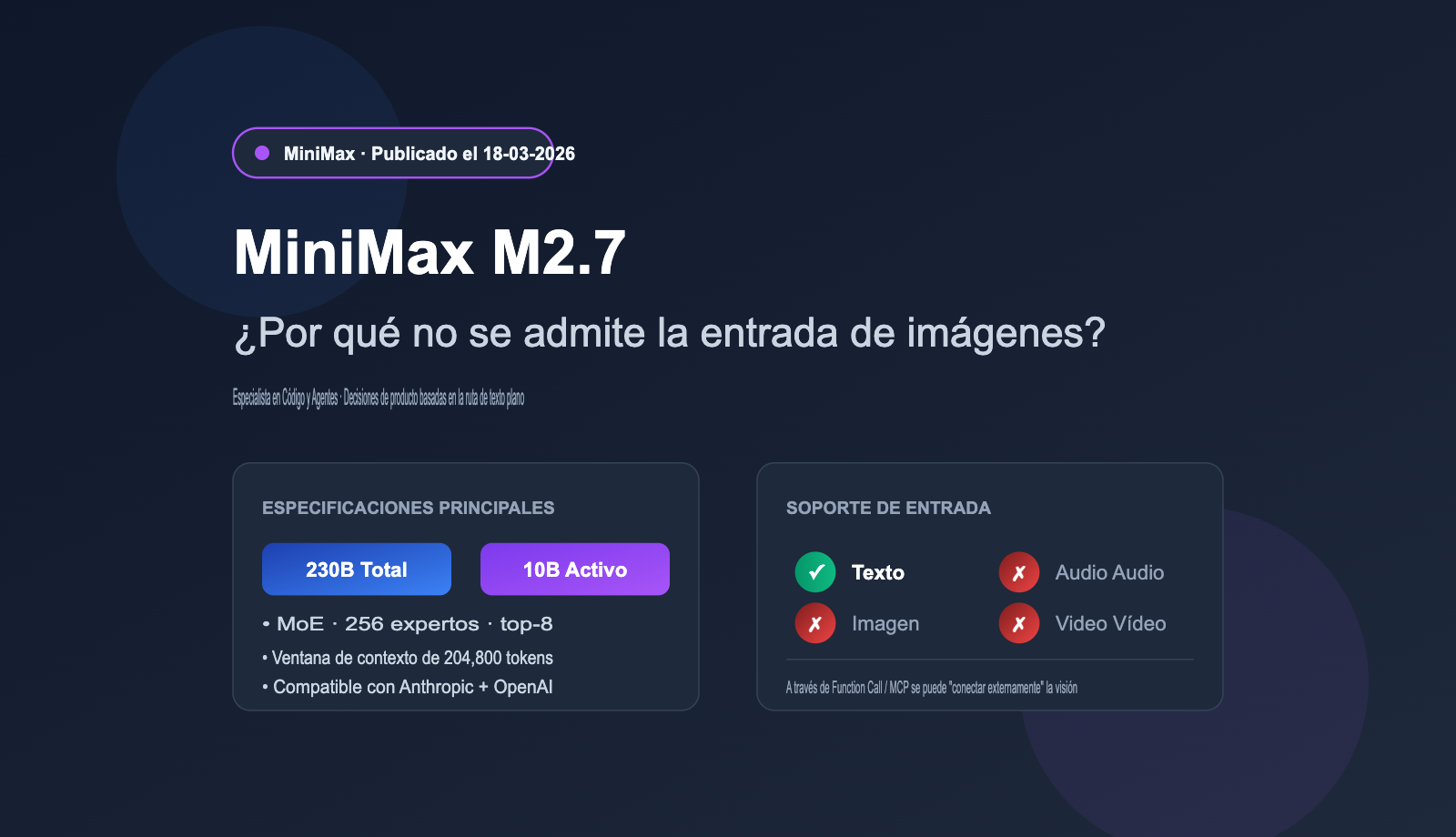
Respondamos a la pregunta más directa: Es cierto. Según las especificaciones públicas de la plataforma oficial de MiniMax y la tarjeta de modelo de NVIDIA NIM, el M2.7 (incluida la versión M2.7-highspeed) actualmente solo admite entrada de texto y no puede procesar directamente imágenes, audio o video. Esto es consistente con el enfoque de solo texto de la generación anterior M2.5, pero contrasta fuertemente con la corriente principal de modelos "multimodales nativos" lanzados en el mismo periodo, como Claude 4 Opus, GPT-5 y la serie Gemini 3.
1.1 Resumen de especificaciones clave del MiniMax M2.7
El M2.7 abrió sus interfaces oficialmente el 18 de marzo de 2026. Utiliza una arquitectura MoE (Mezcla de Expertos), con 230B de parámetros totales y 10B de parámetros activos, centrándose en "alto rendimiento + bajo costo".
| Especificación | Parámetro |
|---|---|
| Fecha de lanzamiento | 18-03-2026 |
| Tipo de arquitectura | MoE Transformer (256 expertos, 8 activados por token) |
| Parámetros totales / activos | 230B / 10B |
| Ventana de contexto | 204,800 tokens |
| Salida máxima | 131,072 tokens |
| Precio de entrada | $0.279 / M tokens |
| Precio de salida | $1.20 / M tokens |
| Soporte multimodal | ❌ Solo texto |
| Compatibilidad API | Anthropic API + OpenAI API |
1.2 ¿En qué escenarios te encontrarás con problemas?
Si tu aplicación involucra preguntas sobre capturas de pantalla, análisis de capturas de PDF, comprensión de imágenes de productos, detección visual de automatización de UI, o recuperación de imágenes en RAG multimodal, llamar directamente al M2.7 fallará o producirá resultados sin sentido. Se recomienda realizar una evaluación del tipo de modelo en la capa de enrutamiento (como LiteLLM, One API o una pasarela de servicio proxy de API como APIYI apiyi.com) y enrutar las solicitudes de imagen a las series Claude, GPT-5 o Gemini 3 para su procesamiento.
二、为什么 MiniMax M2.7 选择"纯文本"路线
La orientación de texto puro del M2.7 no se debe a una falta de capacidad técnica, sino a una decisión de producto muy clara. MiniMax ya había lanzado anteriormente la serie de modelos abab con capacidades multimodales, por lo que tenían la capacidad técnica para añadir un módulo visual a la serie M. Sin embargo, decidieron invertir toda la capacidad de cómputo de entrenamiento del M2.7 en los campos de "código + agentes" para lograr un rendimiento excepcional en estas dos áreas.
2.1 El código y los agentes son el campo de batalla principal del M2.7
Según el README oficial y el blog técnico de NVIDIA, el M2.7 está optimizado específicamente para "edición de múltiples archivos, ciclos de código-ejecución-corrección, reparaciones basadas en pruebas y llamadas a herramientas de cadena larga que involucran Shell, navegador, recuperación y ejecutores de código". En tareas de programación reales como SWE-bench, Aider Polyglot y Terminal Bench, los resultados del M2.7 se acercan a los del Claude 4 Sonnet, pero con solo 10B de parámetros activos, lo que reduce el costo de inferencia a aproximadamente 1/8 del de este último.
2.2 El equilibrio entre la ruta de texto puro y la ruta multimodal
Concentrar los recursos de entrenamiento en una sola dirección conlleva beneficios y pérdidas deterministas. La siguiente tabla resume los puntos clave de equilibrio entre ambas rutas:
| Dimensión | Ruta de texto puro (M2.7 / DeepSeek-R1) | Ruta multimodal (Claude/GPT/Gemini) |
|---|---|---|
| Costo de entrenamiento | Concentrado, alta eficiencia | Disperso, alto costo de datos |
| Precio por token | Más bajo ($0.28-2 / M) | Más alto ($3-15 / M) |
| Profundidad de razonamiento de texto/código | Generalmente más fuerte | Ligeramente más débil pero suficiente |
| Comprensión de imagen/video | No compatible | Compatible de forma nativa |
| Amplitud de casos de uso | Enfocado | Más general |
| Complejidad de integración técnica | Baja | Baja-Media |
2.3 "Completar" las capacidades multimodales mediante llamadas a herramientas
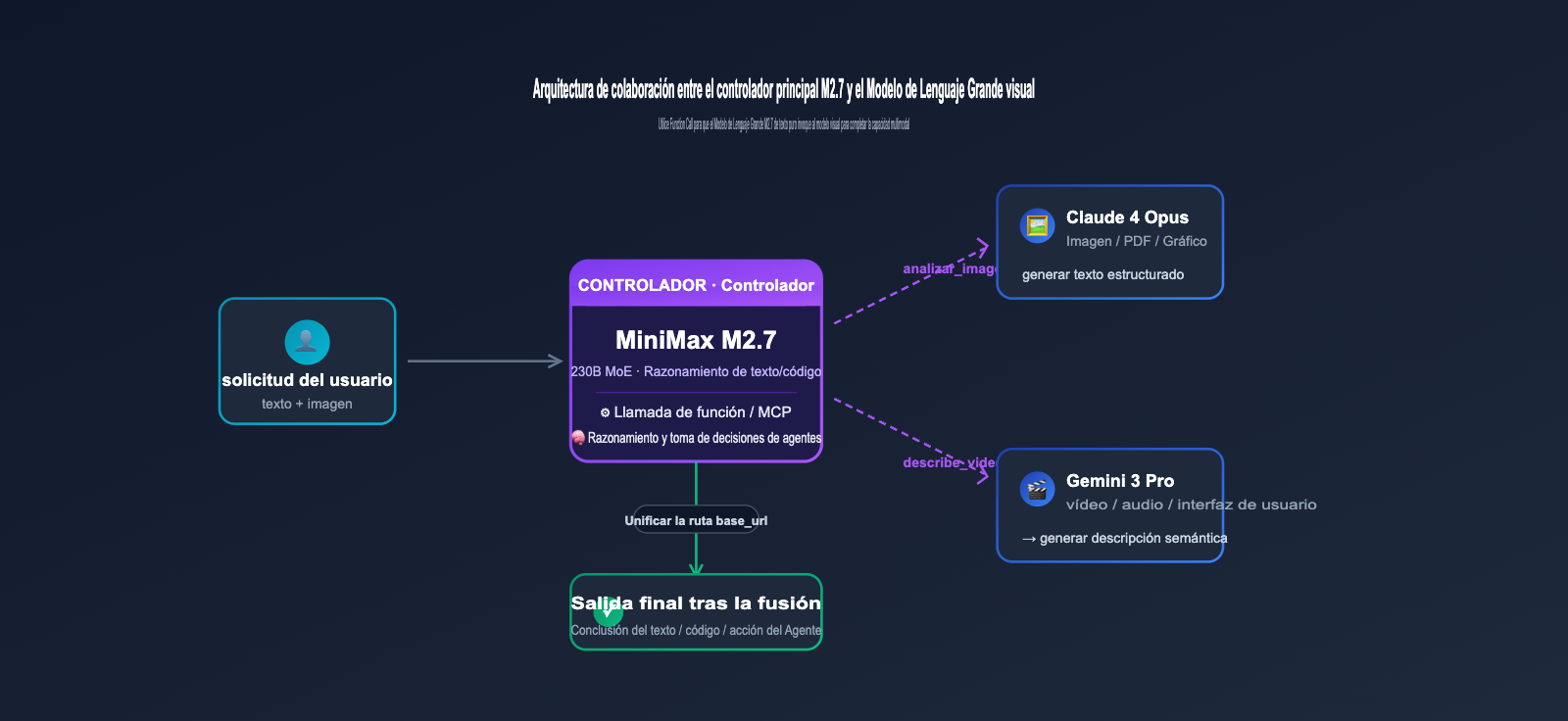
Aunque el M2.7 no puede "ver" imágenes por sí mismo, admite de forma nativa MCP (Model Context Protocol) y la invocación de funciones (Function Calling). Esto significa que los desarrolladores pueden permitir que el M2.7 "subcontrate" las tareas de comprensión de imágenes a modelos visuales especializados (como Claude 4 Opus o Gemini 3 Vision), encargándose él mismo solo de la orquestación y el razonamiento final. Esta arquitectura de "controlador principal + colaboración visual" es muy común en los sistemas de agentes.
三、¿Son realmente las API multimodales el estándar de la industria en 2026?
A primera vista, parece que "multimodal = estándar" se ha convertido en un consenso de la industria en 2026. Sin embargo, al observar de cerca el panorama de los modelos principales, se hace evidente que este juicio requiere una comprensión estratificada.
3.1 Los modelos insignia cerrados casi todos admiten capacidades multimodales
La serie Claude 4 de Anthropic, la serie GPT-5 de OpenAI y Gemini 3 Pro/Ultra de Google ya han establecido la imagen como una capacidad de entrada básica. En la prueba ScreenSpot-Pro, Gemini 3 saltó del 11.4% de la generación anterior al 72.7%, siendo capaz de "entender" capturas de pantalla y operar la interfaz de usuario directamente; Claude 4 también ha reforzado sus capacidades de reconocimiento de gráficos y análisis de PDF.
3.2 La división es evidente en el campo de código abierto y relación costo-beneficio
El campo del código abierto muestra una clara división: por un lado, modelos "multimodales de pila completa" como Llama 3.2 Vision, Qwen3-VL e InternVL; y por otro, modelos "especializados en texto/razonamiento" como DeepSeek-R1 y MiniMax M2.7, que obtienen ventajas de costo-beneficio a través del enfoque. Estas dos categorías no son simplemente una cuestión de "mejor o peor", sino opciones diferenciadas para diferentes formas de aplicación.
3.3 Comparativa de capacidades multimodales de los modelos principales
La siguiente tabla resume las diferencias en las capacidades multimodales de los principales modelos de lenguaje grande en mayo de 2026, lo que permite ver rápidamente el posicionamiento del M2.7 en el mercado:
| Modelo | Entrada de imagen | Entrada de video | Entrada de audio | Posicionamiento principal |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Razonamiento de código/Agente |
| Claude 4 Opus | ✅ | ❌ | ❌ | General + Textos largos + Código |
| GPT-5 | ✅ | ✅ | ✅ | Multimodal general |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodal + Comprensión de UI |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Razonamiento matemático/lógico |
| Qwen3-VL | ✅ | ✅ | ❌ | Multimodal de código abierto |
Como se puede observar, el "estándar multimodal" se concentra principalmente en los modelos insignia cerrados. En el campo del código abierto y de alta relación costo-beneficio, la especialización en texto sigue siendo una ruta de diferenciación efectiva.

IV. Sin visión nativa, ¿cómo hacer que MiniMax M2.7 procese imágenes?
Aunque M2.7 no procesa imágenes por sí mismo, mediante el uso de herramientas y enrutamiento, es totalmente posible construir una arquitectura híbrida de "M2.7 como controlador principal + modelos de visión". De esta forma, aprovechas el bajo costo de M2.7 sin sacrificar la experiencia multimodal.
4.1 Arquitectura de invocación híbrida recomendada
La práctica más común es utilizar una puerta de enlace unificada (como el enrutamiento multimodelo que ofrece APIYI en apiyi.com) para distribuir las solicitudes según el tipo de contenido. Las solicitudes de texto o código se dirigen a M2.7, mientras que las solicitudes de imágenes se envían a Claude 4 o Gemini 3. Luego, el texto resultante del modelo de visión se devuelve a M2.7 para el razonamiento y la toma de decisiones final. Esta arquitectura es transparente para el frontend y no requiere modificar la forma en que el lado del negocio realiza las llamadas al SDK.
4.2 Integración de modelos de visión mediante Function Calling
Si tu aplicación utiliza Function Calling, puedes registrar una herramienta analyze_image para M2.7 que invoque internamente la interfaz de visión de Claude, GPT o Gemini, devolviendo el resultado del análisis en formato JSON. M2.7 determinará automáticamente cuándo llamar a esta herramienta según la solicitud del usuario, sin necesidad de realizar juicios explícitos en la capa de indicación. Este modelo es ideal para marcos de trabajo de agentes (como LangGraph, CrewAI o el SDK de OpenAI Agents).
🎯 Consejo de integración: Recomendamos utilizar un
base_urlde APIYI (apiyi.com) para acceder tanto a M2.7 como a modelos multimodales (como Claude 4 Opus o Gemini 3 Pro) simultáneamente. Esto evita tener que mantener SDKs y claves API por separado para cada proveedor, reduciendo significativamente la complejidad de ingeniería de la arquitectura híbrida y facilitando la observación unificada del consumo de tokens y los costos.
4.3 Parámetros de inferencia recomendados
MiniMax recomienda oficialmente utilizar parámetros de muestreo relativamente altos para M2.7: temperature=1.0, top_p=0.95 y top_k=40. Esto difiere de las recomendaciones de baja temperatura de la mayoría de los modelos. En pruebas realizadas en escenarios de codificación y agentes, esta configuración genera una finalización de código de mayor calidad y más creativa. Si tu plantilla de indicación anterior tenía una temperature=0 por defecto, es posible que obtengas resultados rígidos o repetitivos en M2.7, por lo que será necesario realizar un reajuste.
V. Toma de decisiones: MiniMax M2.7 vs. Modelos Multimodales
¿Cuándo elegir M2.7 y cuándo optar por un modelo multimodal insignia? La clave no es simplemente comparar quién tiene más parámetros, sino determinar si tu aplicación está orientada principalmente a "texto/código" o a "multimodalidad".
5.1 Escenarios orientados a texto/código: M2.7 es la mejor opción
Si más del 90% de las solicitudes de tu producto son de tipo texto (generación de código, preguntas y respuestas sobre documentos, orquestación de agentes, resúmenes de textos largos), M2.7 es actualmente una de las opciones con mejor relación costo-beneficio. Sus 230B de parámetros totales ofrecen un límite de capacidad cercano al de Claude 4 Sonnet, pero con un precio por token que es solo una fracción de este último, lo cual es especialmente ventajoso para el backend de aplicaciones SaaS de alta concurrencia.
5.2 Escenarios de alta frecuencia multimodal: Claude / Gemini
Si tu caso de uso principal es la comprensión de imágenes (OCR, automatización de UI, reconocimiento de productos, asistencia en imágenes médicas), análisis de video o procesamiento de audio, elegir directamente Claude 4 Opus, GPT-5 o Gemini 3 Pro será más sencillo y fiable que una arquitectura híbrida de "M2.7 + modelo visual", ya que reduce la latencia y la tasa de fallos de las invocaciones entre modelos.
5.3 Recomendaciones de selección según el escenario
| Caso de uso | Modelo prioritario | Alternativa |
|---|---|---|
| Generación / refactorización de código | MiniMax M2.7 | Claude 4 Sonnet |
| Invocación de herramientas de Agente | MiniMax M2.7 | GPT-5 |
| Preguntas sobre documentos largos (hasta 200K) | MiniMax M2.7 | Claude 4 Opus |
| OCR de imágenes / Q&A de capturas | Gemini 3 Pro | Claude 4 Opus |
| Análisis de video | Gemini 3 Pro | GPT-5 |
| RAG multimodal | Claude 4 Opus | Gemini 3 Pro |
| Tareas mixtas (texto + pocas imágenes) | Combinación M2.7 + modelo visual | Modelo único Claude 4 Opus |
🎯 Consejo de selección: Elegir un modelo no se trata de ver "quién es más fuerte", sino de "quién se ajusta mejor a la distribución de tus solicitudes". Te sugerimos realizar pruebas A/B con tráfico real a través de la plataforma APIYI (apiyi.com) para comparar los costos y la calidad de diferentes modelos en tareas idénticas antes de definir tu combinación principal.
VI. Preguntas frecuentes sobre MiniMax M2.7
6.1 ¿Es cierto que M2.7 no puede procesar imágenes en absoluto?
Así es. Si incluyes archivos de imagen (base64 o URL) directamente en los messages, la interfaz los rechazará o devolverá un error. La única forma viable es utilizar primero otro modelo visual para convertir la imagen en una descripción textual y luego pasar dicha descripción a M2.7 para el razonamiento posterior.
6.2 ¿Cuál es la diferencia entre M2.7 y M2.7-highspeed?
Ambos ofrecen los mismos resultados, la diferencia radica en la velocidad de respuesta. M2.7-highspeed es ideal para escenarios sensibles a la latencia (como el autocompletado en tiempo real en un IDE), mientras que la versión estándar de M2.7 es adecuada para tareas asíncronas de gran volumen. Puedes cambiar entre ambas versiones en el panel de control de APIYI (apiyi.com) mediante el nombre del modelo; los parámetros de la interfaz son totalmente compatibles.
6.3 ¿Es M2.7 un modelo de código abierto? ¿Se puede implementar localmente?
Sí, M2.7 es un modelo de pesos abiertos que se puede descargar desde HuggingFace y autohospedar. Sin embargo, se requieren al menos 8 tarjetas A100 / H100 para aprovechar al máximo la ventana de contexto de 200K. El costo de la implementación local es mucho mayor que el de la invocación por API, por lo que, a menos que existan requisitos estrictos de cumplimiento de datos, no se recomienda la autoconstrucción.
6.4 ¿Es M2.7 compatible con los SDK oficiales de Anthropic / OpenAI?
Es totalmente compatible. Puedes usar directamente los SDK oficiales de anthropic u openai simplemente apuntando el base_url al gateway de servicio proxy de API (como el punto de acceso unificado de APIYI, apiyi.com) y cambiando el nombre del modelo; no es necesario reescribir ninguna lógica de negocio. Esta es la forma más eficiente de integrar una arquitectura híbrida.
6.5 Si mi equipo tiene muchas necesidades multimodales, ¿debería descartar M2.7?
No necesariamente. Incluso en aplicaciones multimodales, el razonamiento y la orquestación de texto siguen representando un gran volumen de solicitudes. Recomendamos dejar la parte multimodal a Claude/Gemini y delegar la orquestación y toma de decisiones textuales a M2.7, lo que puede reducir significativamente el costo total de inferencia. Si necesitas una solución mixta personalizada, puedes contactar al equipo comercial de APIYI (apiyi.com) para obtener asesoramiento sobre la arquitectura.
VII. Conclusión: La multimodalidad es tendencia, pero la "especialización" sigue siendo una ruta eficaz
El hecho de que el MiniMax M2.7 no soporte entrada de imágenes no es solo una realidad, sino una estrategia de producto deliberada. En este punto de 2026, donde la multimodalidad se ha convertido en el estándar de los modelos insignia de código cerrado, MiniMax ha optado por concentrar todos sus recursos de entrenamiento en los dos campos más diferenciados: código y agentes. Esto le ha permitido alcanzar una capacidad de programación cercana a la de Claude 4 Sonnet, con un coste de inferencia significativamente menor.
Para los desarrolladores, esto significa que la selección del modelo ya no es una simple comparación de "quién es más completo", sino de "quién se ajusta mejor a la distribución de tus peticiones". En escenarios dominados por texto o código, el M2.7 sigue siendo una de las opciones con mejor relación calidad-precio del mercado; mientras que para escenarios de alta frecuencia multimodal, lo ideal es recurrir a especialistas como Claude 4 Opus, GPT-5 o Gemini 3. Combinar ambos mediante una pasarela unificada suele ser la mejor forma de lograr el equilibrio óptimo entre coste y rendimiento.
Si necesitas integrar el M2.7 junto con los modelos multimodales insignia de otros proveedores bajo una misma base_url, puedes visitar la documentación oficial de APIYI en apiyi.com para consultar la lista completa de modelos y ver ejemplos de integración.
Autor: Equipo de APIYI — Proporcionamos continuamente servicios de proxy de API y enrutamiento multimodelo estables y eficientes para desarrolladores de IA en todo el mundo. Para más detalles, visita apiyi.com