作者注:深度对比 Kimi K2.5 与 Claude Opus 4.5 在编程、推理、Agent 能力等维度的表现,分析 9 倍价差背后的性价比差异,帮你做出最佳选择
Kimi K2.5 对比 Claude Opus 4.5 到底怎么样?这是 2026 年开发者最关心的选型问题之一。本文从 基准测试、实际能力、价格成本、适用场景 四个维度进行深度对比,给出明确的选择建议。
核心结论:Claude Opus 4.5 在代码质量上略胜一筹 (SWE-Bench 80.9% vs 76.8%),但 Kimi K2.5 在 Agent 自动化、视觉编程、数学推理上更强,且成本仅为 Claude 的 1/9。

Kimi K2.5 vs Claude Opus 4.5 核心对比
| 对比维度 | Kimi K2.5 | Claude Opus 4.5 | 胜出方 |
|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.9% | Claude +4.1% |
| AIME 2025 数学 | 96.1% | 92.8% | Kimi +3.3% |
| LiveCodeBench v6 | 83.1% | 64.0% | Kimi +19.1% |
| BrowseComp 网页交互 | 60.2% | 24.1% | Kimi +36.1% |
| Agent Swarm | ✅ 100 并行 | ❌ 不支持 | Kimi |
| 视觉编程 | ✅ 原生支持 | ❌ 仅文本 | Kimi |
| 上下文窗口 | 256K | 200K | Kimi +28% |
| API 价格 | $0.60/$3.00 | $5.00/$25.00 | Kimi 便宜 ~9x |
一句话总结
- 追求极致代码质量 → 选 Claude Opus 4.5
- 追求性价比和多功能 → 选 Kimi K2.5
- 需要 Agent 自动化 → 必选 Kimi K2.5
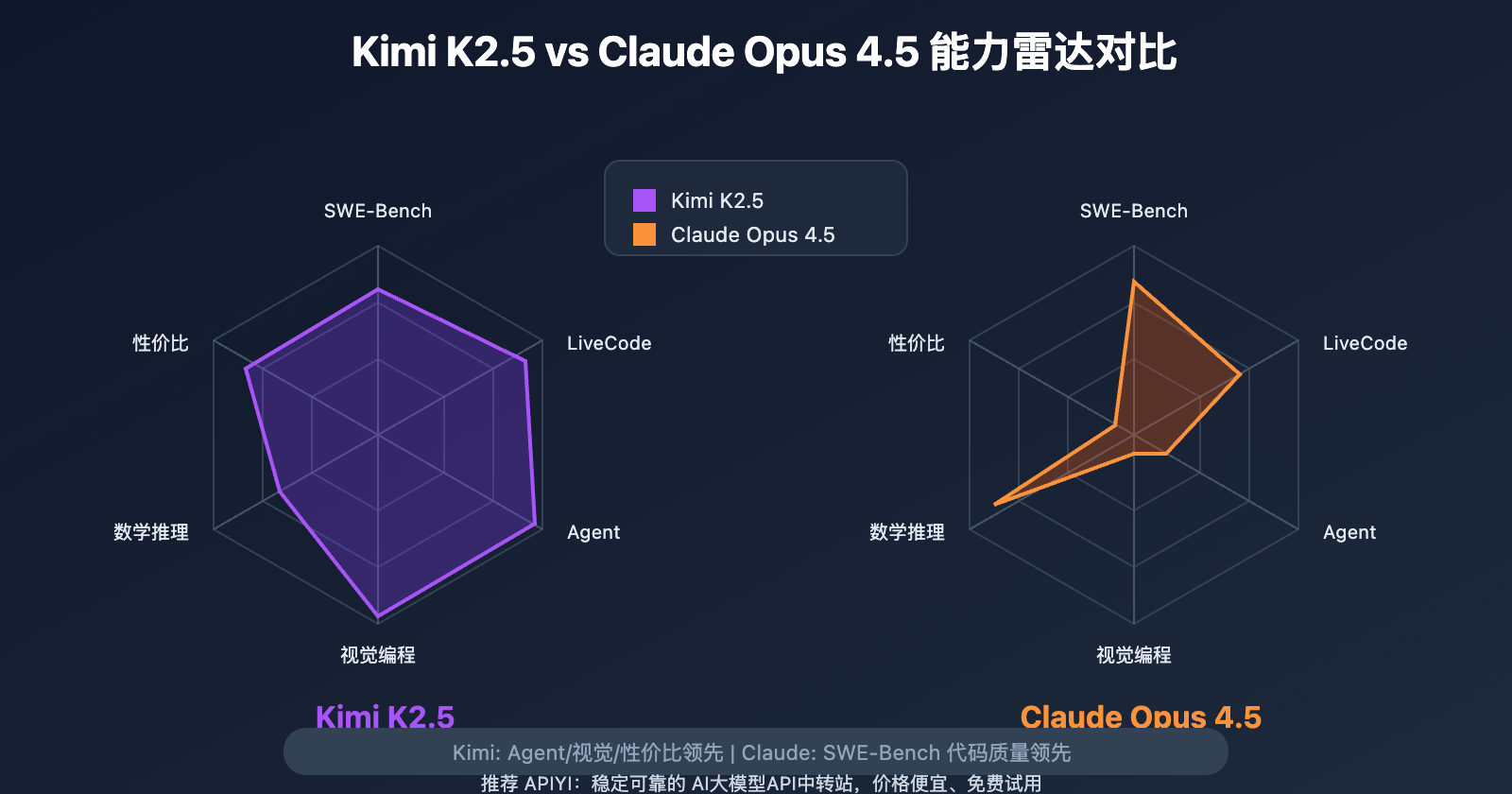
Kimi K2.5 vs Claude Opus 4.5 编程能力详解
代码修复能力 (SWE-Bench)
SWE-Bench Verified 是衡量模型修复真实 GitHub Issue 能力的权威基准:
| 模型 | SWE-Bench Verified | SWE-Bench Multi | Terminal-Bench |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | – | 59.3% |
| Kimi K2.5 | 76.8% | 73.0% | 50.8% |
| GPT-5.2 | 80.0% | – | 54.0% |
Claude Opus 4.5 在 SWE-Bench 上以 80.9% 的成绩领先,这意味着在修复复杂代码 Bug 时,Claude 的成功率更高,调试周期更短。
Claude 的优势场景:
- 关键系统的代码审查
- 复杂的重构任务
- 需要极低容错率的生产代码
实时交互编程 (LiveCodeBench)
LiveCodeBench v6 测试模型在实时交互环境下的编程能力:
| 模型 | LiveCodeBench v6 | 说明 |
|---|---|---|
| GPT-5.2 | 87.0% | 最强 |
| Kimi K2.5 | 83.1% | 开源最强 |
| Claude Opus 4.5 | 64.0% | 明显落后 |
在实时编程对话场景中,Kimi K2.5 以 83.1% 大幅领先 Claude 的 64.0%,这说明 Kimi 更擅长在交互式开发中快速响应和迭代。
前端与视觉编程
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| UI 设计转代码 | ✅ 原生支持 | ❌ 不支持 |
| 视频转代码 | ✅ 支持 | ❌ 不支持 |
| 复杂动画生成 | ✅ 强 | ⚠️ 一般 |
Kimi K2.5 的 Vibe Coding 能力是 Claude 完全不具备的——直接从 Figma 设计稿或操作视频生成完整前端代码。
Kimi K2.5 vs Claude Opus 4.5 推理能力对比
数学推理 (AIME/GPQA)
| 基准 | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|---|
| AIME 2025 | 96.1% | 92.8% | 100% |
| GPQA-Diamond | 87.6% | – | 92.4% |
| HMMT 2025 | 95.4% | – | 93.3% |
在数学竞赛级别的推理任务中,Kimi K2.5 (96.1%) 超越了 Claude Opus 4.5 (92.8%),展现出更强的逻辑推理能力。
工具增强推理
当模型可以使用搜索和代码执行工具时:
| 模型 | 无工具 | 有工具 | 提升幅度 |
|---|---|---|---|
| Kimi K2.5 | 31.5% | 51.8% | +20.1% |
| Claude Opus 4.5 | – | – | +12.4% |
| GPT-5.2 | – | – | +11.0% |
Kimi K2.5 在工具增强推理上的提升幅度 (+20.1%) 远超 Claude (+12.4%),这得益于其 Agent Swarm 架构对工具调用的优化。
Kimi K2.5 vs Claude Opus 4.5 Agent 能力
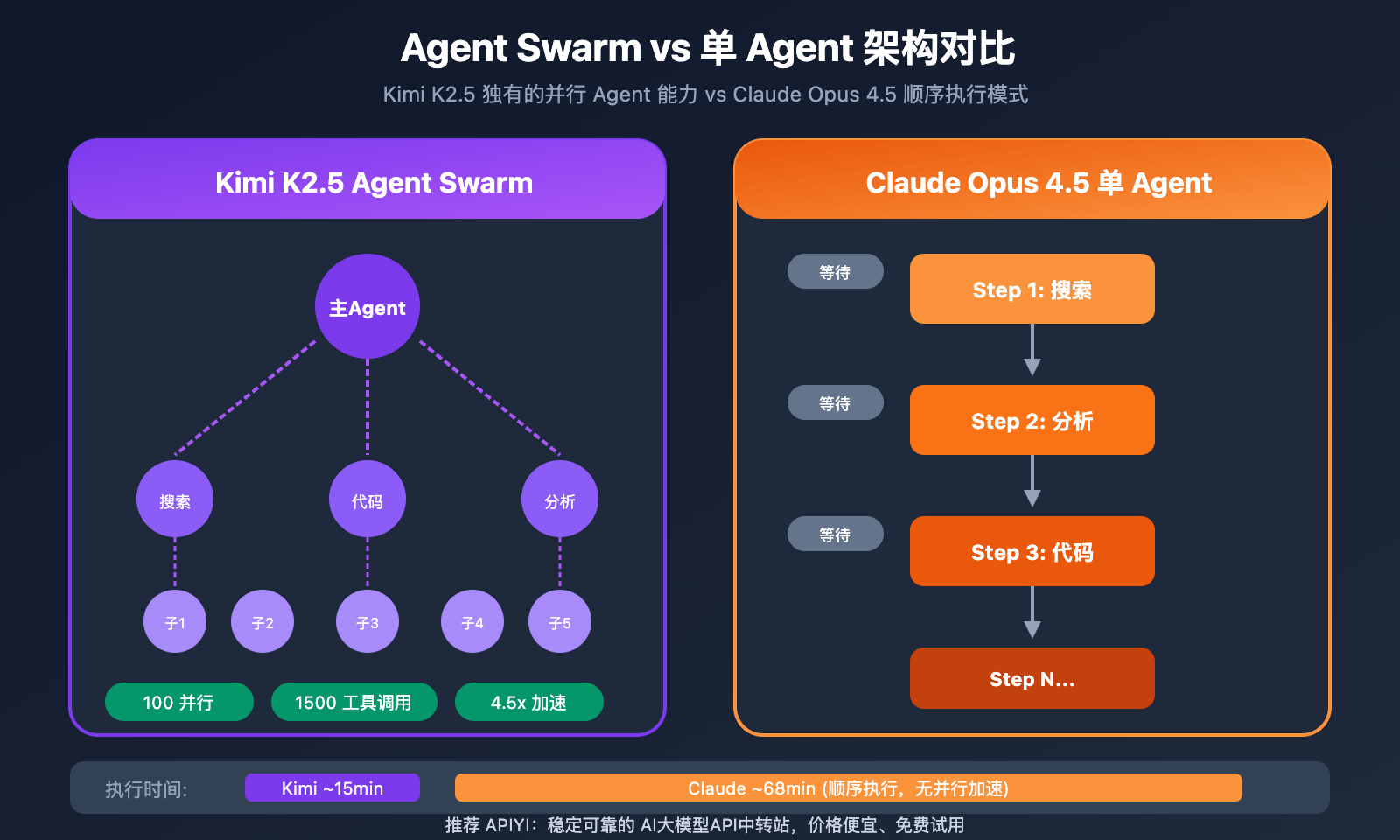
Agent Swarm:Kimi K2.5 独有优势
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| 并行 Agent | 最多 100 个 | 单 Agent |
| 工具调用 | 最多 1500 次/任务 | 受限 |
| 执行效率 | 4.5x 加速 | 基准 |
| 自动任务拆分 | ✅ 无需预设 | ❌ 需手动编排 |
Kimi K2.5 的 Agent Swarm 是其最大差异化优势:
- 自动将复杂任务拆分为并行子任务
- 动态实例化专业子 Agent
- 无需预定义角色或工作流
- 复杂研究任务完成时间缩短至 1/4.5
实际案例:一个需要数小时的跨领域市场调研任务,Kimi K2.5 可以在十几分钟内完成,而 Claude 需要顺序执行多轮对话。
Comparativa de costes y precios: Kimi K2.5 vs. Claude Opus 4.5
Comparativa de precios de API
| Modelo | Precio de entrada | Precio de salida | Coste relativo |
|---|---|---|---|
| Kimi K2.5 | $0.60/M | $3.00/M | Referencia |
| Claude Opus 4.5 | $5.00/M | $25.00/M | ~9x |
| GPT-5.2 | $0.90/M | $3.80/M | ~1.4x |
Estimación de costes anuales (1 millón de solicitudes, 5K de salida/solicitud)
| Modelo | Coste anual | Comparativa |
|---|---|---|
| Kimi K2.5 | ~$13.800 | Referencia |
| GPT-5.2 | ~$56.500 | 4.1x |
| Claude Opus 4.5 | ~$150.000 | 10.9x |
El coste anual de Claude Opus 4.5 es más de 10 veces superior al de Kimi K2.5. Para equipos con presupuestos limitados, esta diferencia es lo suficientemente grande como para condicionar la elección tecnológica.
Análisis de coste-beneficio
| Escenario | Modelo recomendado | Razón |
|---|---|---|
| Startups | Kimi K2.5 | Coste de solo $13.800/año con rendimiento suficiente |
| Sistemas críticos de grandes empresas | Claude Opus 4.5 | Prioridad en la calidad del código, coste aceptable |
| Tareas de Agentes de alta frecuencia | Kimi K2.5 | Agent Swarm + Bajo coste |
| Desarrollo frontend | Kimi K2.5 | Ventaja exclusiva en programación visual |
Sugerencia de costes: En la mayoría de los escenarios, el resultado de 76,8% en SWE-Bench de Kimi K2.5 ya es excelente; una diferencia del 4% no justifica un sobreprecio de 9 veces. Puedes acceder a ambos modelos simultáneamente a través de APIYI (apiyi.com): utiliza Claude para tareas críticas y Kimi para el desarrollo diario.
Guía de selección: Kimi K2.5 vs. Claude Opus 4.5
Cuándo elegir Kimi K2.5
| Escenario | Razón |
|---|---|
| Proyectos sensibles al presupuesto | El coste es solo 1/9 del de Claude |
| Flujos de trabajo automatizados con Agentes | Capacidad exclusiva de Agent Swarm |
| Desarrollo frontend y replicación de UI | Soporte nativo para programación visual |
| Tareas de razonamiento matemático | AIME 96,1% > Claude 92,8% |
| Necesidad de contexto ultralargo | 256K > 200K |
| Llamadas de API frecuentes | Mayor eficiencia de costes |
Cuándo elegir Claude Opus 4.5
| Escenario | Razón |
|---|---|
| Revisión de código de sistemas críticos | El SWE-Bench más alto (80,9%) |
| Refactorización de backend complejo | Calidad de código más estable |
| Requisitos de cumplimiento empresarial | Reputación de seguridad de Anthropic |
| Cero tolerancia a errores | Ciclos de depuración más cortos |
快速接入示例
通过 APIYI 同时接入两个模型
import openai
# 创建客户端 - 指向 APIYI
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
# 日常开发用 Kimi K2.5 (高性价比)
response_kimi = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "实现一个 React 购物车组件"}]
)
# 关键代码审查用 Claude (高质量)
response_claude = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "审查这段支付接口代码的安全性..."}]
)
接入建议:通过 APIYI apiyi.com 获取免费测试额度,用同一个 API Key 同时调用 Kimi K2.5 和 Claude Opus 4.5,按需切换,灵活控制成本。
常见问题
Q1: Kimi K2.5 对比 Claude Opus 4.5,编程能力差多少?
在 SWE-Bench Verified 基准上,Claude (80.9%) 比 Kimi (76.8%) 高 4.1%。但在 LiveCodeBench 实时交互编程中,Kimi (83.1%) 大幅领先 Claude (64.0%)。结论:Claude 更适合复杂代码修复,Kimi 更适合快速迭代开发。
Q2: 9 倍的价格差距,Claude Opus 4.5 值得吗?
取决于场景。对于年薪 $200K+ 的工程师团队,Claude 4% 更高的代码质量可能减少调试时间,ROI 为正。但对于预算敏感的初创公司或高频 API 调用场景,Kimi K2.5 的性价比更优。建议:关键代码用 Claude,日常开发用 Kimi。
Q3: 如何同时使用 Kimi K2.5 和 Claude Opus 4.5?
推荐通过 APIYI apiyi.com 统一接入:
- 注册获取一个 API Key
- 设置 base_url 为
https://vip.apiyi.com/v1 - 通过 model 参数切换:
kimi-k2.5或claude-opus-4-5-20251101 - 根据任务类型动态选择,灵活控制成本
总结
Kimi K2.5 对比 Claude Opus 4.5 的核心结论:
- 代码质量:Claude 略优 (SWE-Bench 80.9% vs 76.8%),但差距仅 4%
- 综合性价比:Kimi K2.5 成本仅为 Claude 的 1/9,大多数场景更划算
- 独家能力:Kimi 拥有 Agent Swarm、视觉编程等 Claude 不具备的能力
- 推荐策略:日常开发用 Kimi K2.5,关键代码审查用 Claude Opus 4.5
两个模型均已上线 APIYI apiyi.com,建议通过平台获取免费额度,实际测试后根据业务需求选择。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
Kimi K2.5 官方技术报告: 完整基准测试数据
- 链接:
kimi.com/blog/kimi-k2-5.html - 说明: 获取 SWE-Bench、AIME 等官方测试结果
- 链接:
-
Claude Opus 4.5 模型卡: Anthropic 官方性能数据
- 链接:
anthropic.com/claude - 说明: 查看 Claude 的官方基准成绩
- 链接:
-
AI Model Benchmarks 2026: 第三方独立评测
- 链接:
artificialanalysis.ai - 说明: 多模型横向对比数据
- 链接:
-
Four Giants Comparison 深度评测: 详细场景对比分析
- 链接:
medium.com(搜索 "Kimi K2.5 vs Claude Opus 4.5") - 说明: 实际使用体验和成本分析
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区分享你的模型选型经验,更多对比评测可访问 APIYI apiyi.com 技术社区