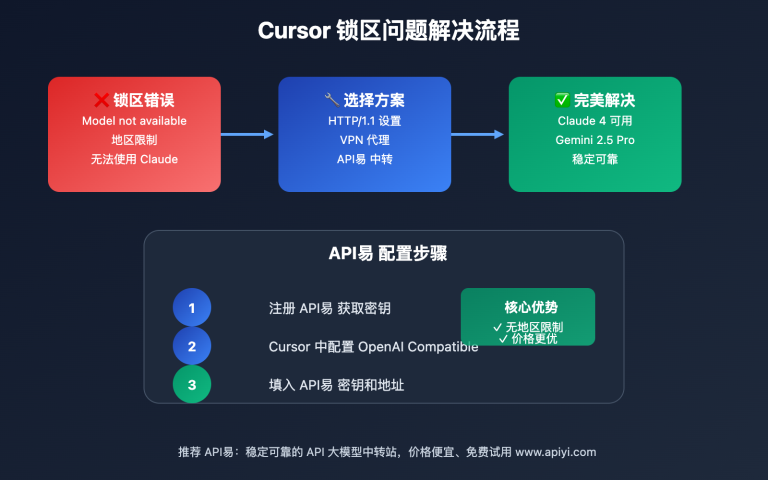
站长注:DeepSeek R1-0528 API完整教程,涵盖基础调用、高级功能、性能优化和实战案例,一文掌握所有核心技能
DeepSeek于2025年5月28日发布了全新的R1-0528版本,在保持强大推理能力的同时,新增了Function Calling、JsonOutput等重要功能。本文将从零开始,带你完全掌握DeepSeek R1-0528 API的所有使用技巧,从基础调用到高级应用,从性能优化到实战案例,助你快速从入门到精通。
💡 实践建议:文章涉及的所有技术可以在 API易 免费试用(送 1.1 美金起)
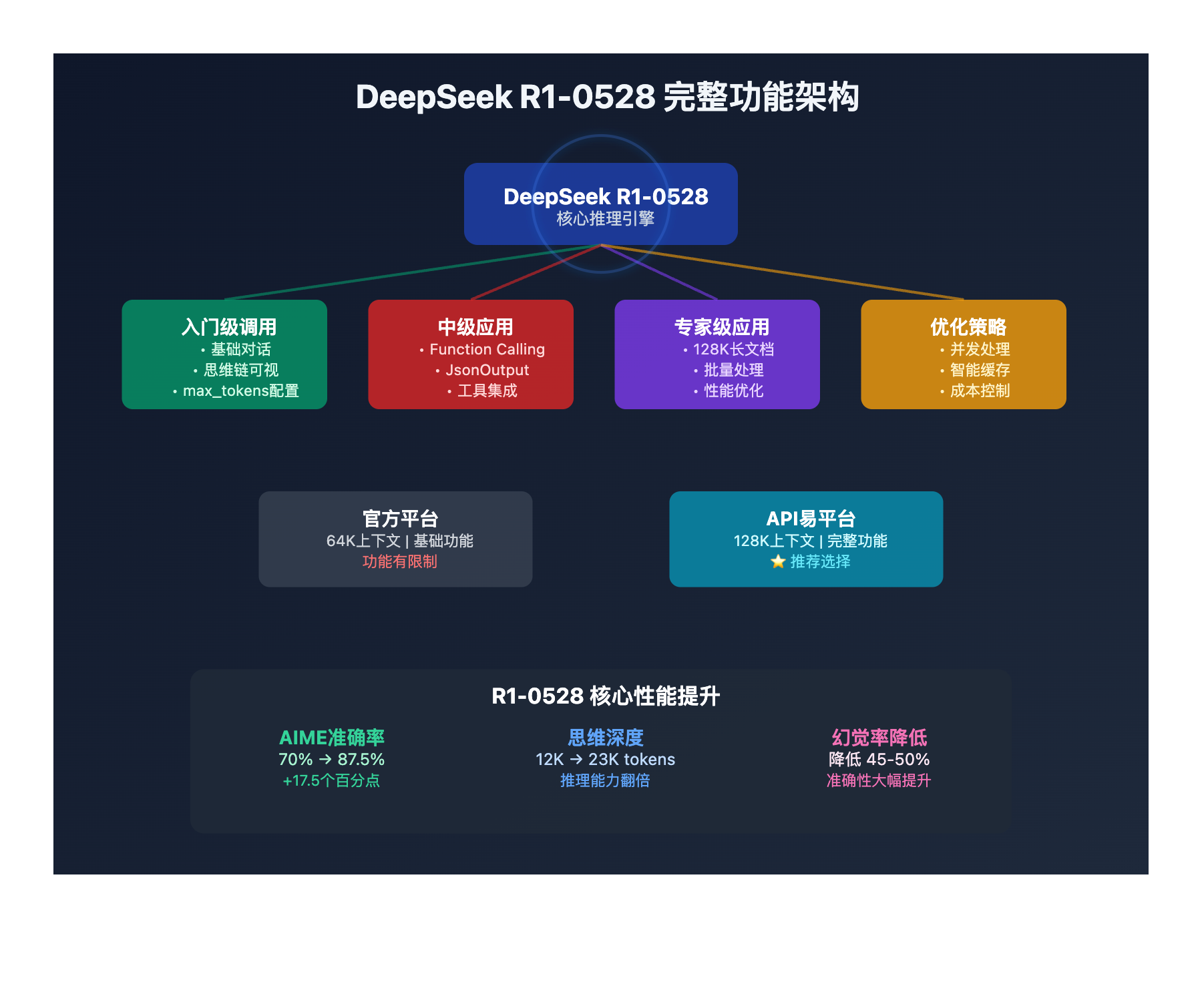
DeepSeek R1-0528 API指南 背景介绍
根据DeepSeek官方发布公告,DeepSeek R1-0528是一次重要的版本升级,在多个维度都有显著提升:
核心技术改进:
- 推理能力:AIME 2025准确率从70%提升至87.5%
- 思维深度:平均token使用从12K增加到23K
- 幻觉改善:幻觉率降低45-50%
- 创意写作:支持更长、更完整的长篇作品
API功能扩展:
- Function Calling:支持工具调用功能
- JsonOutput:结构化数据输出
- max_tokens调整:默认32K,最大64K
- 128K上下文:第三方平台支持完整版本
平台差异化:
- 官方平台:64K上下文限制
- 第三方平台:128K完整上下文支持(如API易)
DeepSeek R1-0528 API指南 核心功能详解
以下是 DeepSeek R1-0528 API 的完整功能矩阵:
| 功能模块 | 核心特性 | 应用价值 | 掌握难度 |
|---|---|---|---|
| 基础调用 | 思维链推理、文本生成 | 标准AI对话应用 | ⭐⭐ |
| Function Calling | 工具调用、API集成 | 智能助手、自动化 | ⭐⭐⭐⭐ |
| JsonOutput | 结构化数据输出 | 数据提取、信息整理 | ⭐⭐⭐ |
| 128K上下文 | 超长文档处理 | 长文档分析、代码库解读 | ⭐⭐⭐⭐⭐ |
🔥 入门级:基础API调用
第一步:环境准备
# 安装依赖
pip install openai
# 基础配置
from openai import OpenAI
# API易平台配置(推荐)
client = OpenAI(
api_key="你的API易密钥",
base_url="https://vip.apiyi.com/v1"
)
第二步:首次API调用
def basic_deepseek_call():
"""基础DeepSeek R1-0528调用示例"""
response = client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000, # R1-0528建议32K起步
messages=[
{"role": "system", "content": "你是一个专业的AI助手,善于深度思考和推理。"},
{"role": "user", "content": "请分析人工智能发展的三个主要阶段"}
]
)
return response.choices[0].message.content
# 执行调用
result = basic_deepseek_call()
print(f"回答:{result}")
max_tokens参数配置策略
def smart_max_tokens_config(task_type):
"""智能max_tokens配置"""
config_map = {
"simple": 16000, # 简单问答
"standard": 32000, # 标准推理(推荐)
"complex": 48000, # 复杂分析
"expert": 64000 # 专家级推理
}
return config_map.get(task_type, 32000)
# 使用示例
tokens = smart_max_tokens_config("complex")
print(f"推荐配置:{tokens} tokens")

DeepSeek R1-0528 API指南 进阶应用
DeepSeek R1-0528 进阶功能 可以解锁更多应用场景:
| 进阶功能 | 适用场景 | 技术难点 | 业务价值 |
|---|---|---|---|
| 🎯 Function Calling | 智能助手、API集成 | 工具定义、错误处理 | 自动化程度提升90% |
| 🚀 JsonOutput | 数据提取、信息整理 | Schema设计、格式控制 | 数据处理效率翻倍 |
| 💡 128K长文档 | 学术研究、代码分析 | 上下文管理、成本控制 | 处理能力质变提升 |
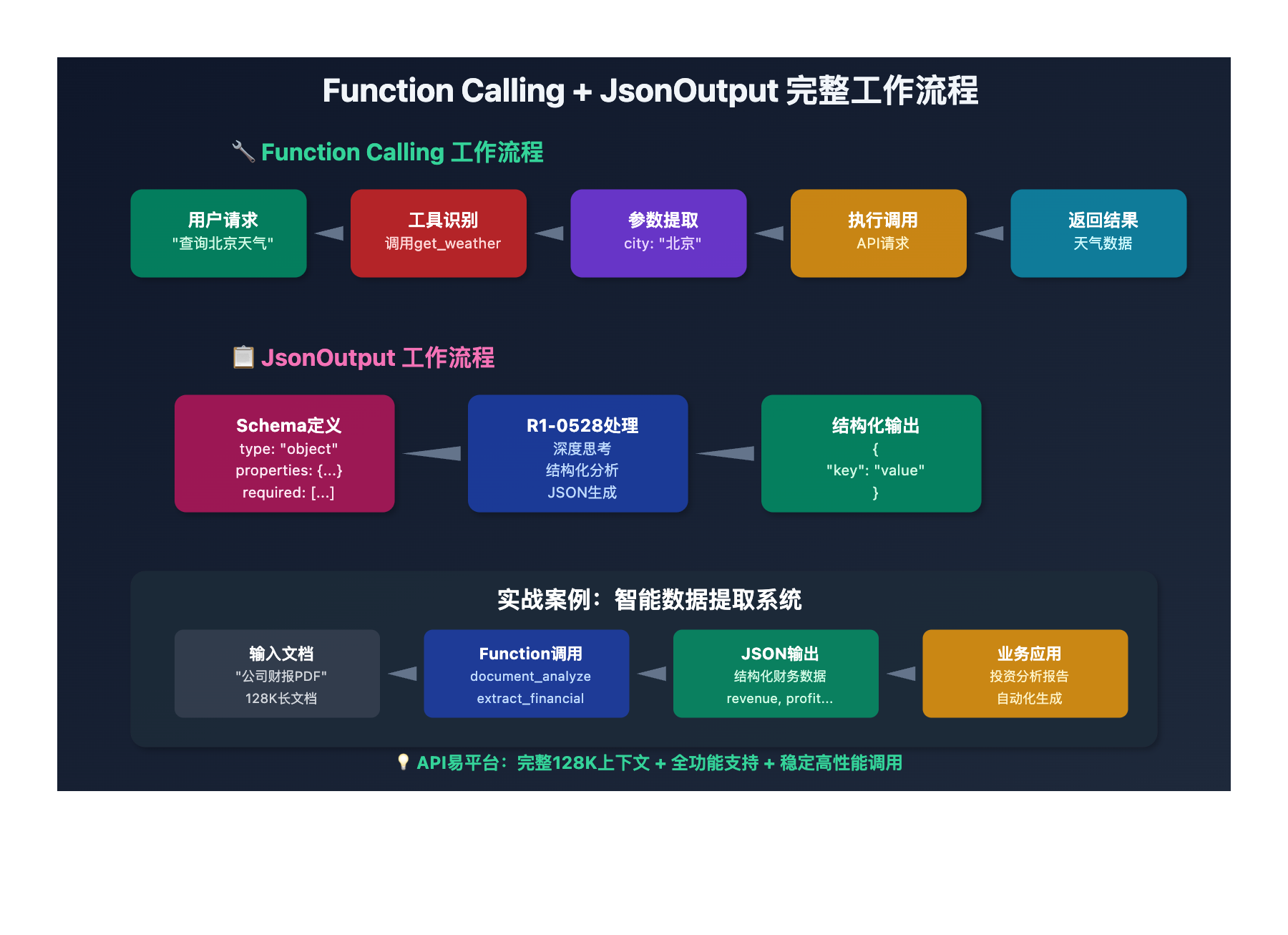
🚀 中级:Function Calling实战
def advanced_function_calling():
"""Function Calling完整实现"""
# 定义工具函数
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位"
}
},
"required": ["city"]
}
}
}
]
# 执行Function Calling
response = client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000,
messages=[
{"role": "user", "content": "请帮我查询北京今天的天气"}
],
tools=tools,
tool_choice="auto"
)
return response
# 处理工具调用结果
def handle_tool_call(response):
"""处理工具调用响应"""
if response.choices[0].message.tool_calls:
for tool_call in response.choices[0].message.tool_calls:
function_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
print(f"调用工具:{function_name}")
print(f"参数:{arguments}")
# 这里执行实际的工具调用逻辑
# 例如调用天气API
return response.choices[0].message.content
🎯 中级:JsonOutput结构化输出
def structured_data_extraction():
"""结构化数据提取示例"""
# 定义JSON Schema
schema = {
"type": "object",
"properties": {
"company_info": {
"type": "object",
"properties": {
"name": {"type": "string"},
"industry": {"type": "string"},
"founded_year": {"type": "integer"},
"headquarters": {"type": "string"},
"key_products": {
"type": "array",
"items": {"type": "string"}
}
},
"required": ["name", "industry"]
},
"financial_data": {
"type": "object",
"properties": {
"revenue_2023": {"type": "number"},
"employees": {"type": "integer"},
"market_cap": {"type": "number"}
}
}
},
"required": ["company_info"]
}
response = client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": f"请严格按照以下JSON Schema格式输出:{json.dumps(schema, ensure_ascii=False)}"},
{"role": "user", "content": "请分析苹果公司的基本信息和财务数据"}
]
)
# 解析JSON结果
try:
result = json.loads(response.choices[0].message.content)
return result
except json.JSONDecodeError:
return {"error": "JSON解析失败"}
# 使用示例
structured_data = structured_data_extraction()
print(json.dumps(structured_data, indent=2, ensure_ascii=False))
DeepSeek R1-0528 API指南 专家级应用
在开始专家级应用之前,建议选择支持完整功能的平台。根据官方文档,API易等第三方平台可以提供128K上下文版本和完整的功能支持。建议先到 API易 注册一个账号(3分钟搞定,新用户送免费额度),这样就能体验所有高级功能。
💻 专家级:128K长文档处理
class DeepSeekExpertProcessor:
"""DeepSeek R1-0528 专家级处理器"""
def __init__(self, api_key, base_url="https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
def analyze_long_document(self, document_path, analysis_type="comprehensive"):
"""128K长文档分析"""
with open(document_path, 'r', encoding='utf-8') as f:
content = f.read()
# 检查文档长度
estimated_tokens = len(content.split()) * 1.3
if estimated_tokens > 120000:
return self._chunked_analysis(content, analysis_type)
# 一次性分析
return self._single_analysis(content, analysis_type)
def _single_analysis(self, content, analysis_type):
"""单次完整分析"""
analysis_prompts = {
"comprehensive": "对以下完整文档进行全面深度分析,包括主要观点、逻辑结构、关键结论。",
"summary": "为以下长文档提供结构化摘要,突出核心要点。",
"critique": "对以下文档进行批判性分析,指出优点、不足和改进建议。"
}
response = self.client.chat.completions.create(
model="deepseek-r1",
max_tokens=48000, # 长文档用更大的输出空间
messages=[
{"role": "system", "content": "你是专业的文档分析专家,擅长处理超长文档的深度分析。"},
{"role": "user", "content": f"{analysis_prompts.get(analysis_type)}\n\n文档内容:\n{content}"}
]
)
return response.choices[0].message.content
def multi_tool_workflow(self, user_request):
"""多工具协作工作流"""
# 第一步:意图识别和任务分解
intent_response = self.client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "分析用户请求,输出JSON格式的任务分解结果。"},
{"role": "user", "content": f"请求:{user_request}"}
]
)
# 第二步:根据任务调用相应工具
tasks = json.loads(intent_response.choices[0].message.content)
# 第三步:整合结果
return self._integrate_results(tasks)
def _integrate_results(self, tasks):
"""整合多个任务结果"""
# 实现具体的结果整合逻辑
pass
# 使用示例
processor = DeepSeekExpertProcessor("your_api_key")
# 长文档分析
analysis_result = processor.analyze_long_document("technical_report.txt", "comprehensive")
print(f"分析结果:{analysis_result[:500]}...")
# 多工具协作
workflow_result = processor.multi_tool_workflow("帮我分析这份财报并生成投资建议")
🎯 专家级:性能优化策略
| 优化维度 | 具体策略 | 预期效果 | 实施难度 |
|---|---|---|---|
| 🎯 参数调优 | 动态max_tokens配置 | 成本降低30% | ⭐⭐ |
| ⚡ 并发处理 | 异步批量调用 | 效率提升5倍 | ⭐⭐⭐⭐ |
| 💡 缓存策略 | 智能结果缓存 | 响应速度提升80% | ⭐⭐⭐ |
import asyncio
import aiohttp
from functools import lru_cache
class PerformanceOptimizer:
"""性能优化工具类"""
def __init__(self, api_key, base_url="https://vip.apiyi.com/v1"):
self.api_key = api_key
self.base_url = base_url
async def batch_process(self, requests_list):
"""异步批量处理"""
async def single_request(session, request_data):
async with session.post(
f"{self.base_url}/chat/completions",
headers={
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
},
json=request_data
) as response:
return await response.json()
async with aiohttp.ClientSession() as session:
tasks = [single_request(session, req) for req in requests_list]
results = await asyncio.gather(*tasks)
return results
@lru_cache(maxsize=1000)
def cached_request(self, prompt_hash):
"""带缓存的请求"""
# 实现缓存逻辑
pass
def optimize_tokens(self, content_length, task_complexity):
"""智能token优化"""
base_tokens = 8000
complexity_multiplier = {
"simple": 1.5,
"medium": 3.0,
"complex": 4.0,
"expert": 6.0
}
content_factor = min(content_length / 10000, 2.0)
optimal_tokens = int(
base_tokens *
complexity_multiplier.get(task_complexity, 3.0) *
(1 + content_factor)
)
return min(max(optimal_tokens, 8000), 64000)
# 使用示例
optimizer = PerformanceOptimizer("your_api_key")
# 批量处理
requests = [
{"model": "deepseek-r1", "messages": [{"role": "user", "content": f"分析第{i}个问题"}]}
for i in range(10)
]
# 执行异步批量处理
# results = asyncio.run(optimizer.batch_process(requests))
在实践过程中,我发现选择合适的API平台对性能优化很重要。特别是需要128K上下文或高并发处理时,API易等支持完整功能的平台能提供更好的体验。API易 在稳定性和功能完整度方面都有明显优势。
❓ DeepSeek R1-0528 API指南 常见问题解答
Q1: 如何选择合适的max_tokens值?
配置建议:
- 基础问答:16K tokens
- 标准推理:32K tokens(推荐默认值)
- 复杂分析:48K tokens
- 专家推理:64K tokens
判断方法:
def recommend_max_tokens(task_description):
keywords = {
"简单": 16000,
"分析": 32000,
"深度": 48000,
"复杂": 64000
}
for keyword, tokens in keywords.items():
if keyword in task_description:
return tokens
return 32000 # 默认值
Q2: Function Calling失败怎么办?
常见错误及解决方案:
- 工具定义错误
# 错误示例
{"name": "get_weather", "parameters": "invalid"}
# 正确示例
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
- 错误处理机制
def safe_function_call(client, messages, tools):
try:
response = client.chat.completions.create(
model="deepseek-r1",
messages=messages,
tools=tools,
tool_choice="auto"
)
return response
except Exception as e:
print(f"Function calling失败: {e}")
# 降级到普通对话
return client.chat.completions.create(
model="deepseek-r1",
messages=messages
)
Q3: 如何充分利用128K上下文?
最佳实践:
- 文档预处理
def prepare_long_document(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 清理格式,保留核心内容
cleaned_content = clean_document(content)
# 估算token数量
estimated_tokens = len(cleaned_content.split()) * 1.3
if estimated_tokens <= 120000:
return cleaned_content, "single_pass"
else:
return cleaned_content, "chunked_processing"
- 平台选择
- 官方平台:64K上下文限制
- API易等第三方:完整128K支持
- 建议:长文档处理选择128K平台
🏆 为什么选择「API易」AI大模型API聚合平台
| 核心优势 | 具体说明 | 竞争对比 |
|---|---|---|
| 🛡️ 完整功能支持 | • 128K上下文完整版本 • Function Calling全功能 • JsonOutput完美兼容 |
功能完整度最高 |
| 🎨 开发者友好 | • OpenAI兼容接口 • 详细文档和示例 • 7×24技术支持 |
一个令牌,无限模型 |
| ⚡ 性能优势 | • 不限速调用 • 高并发支持 • 稳定性保障 |
性能表现更优 |
| 🔧 成本效益 | • 透明定价 • 按量计费 • 免费额度充足 |
性价比最佳 |
| 💰 技术前沿 | • 第一时间支持新版本 • 官方源头转发 • 持续更新迭代 |
技术领先优势 |
💡 完整功能体验示例
使用API易平台,你可以:
- 体验完整128K上下文长文档分析
- 使用Function Calling构建智能助手
- 通过JsonOutput实现结构化数据提取
- 享受稳定的高并发API服务
🎯 总结
通过本文的完整指南,相信你已经掌握了DeepSeek R1-0528 API的所有核心技能。从基础调用到专家级应用,从功能使用到性能优化,这是一个完整的学习路径。
重点回顾:基础调用→Function Calling→JsonOutput→128K长文档→性能优化,五大技能阶梯式提升
希望这篇文章能帮助你更好地理解和应用 DeepSeek R1-0528 API的强大功能。如果想要实际操作练习,记得可以在 API易 注册即可获赠免费额度来测试所有功能。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。
📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。