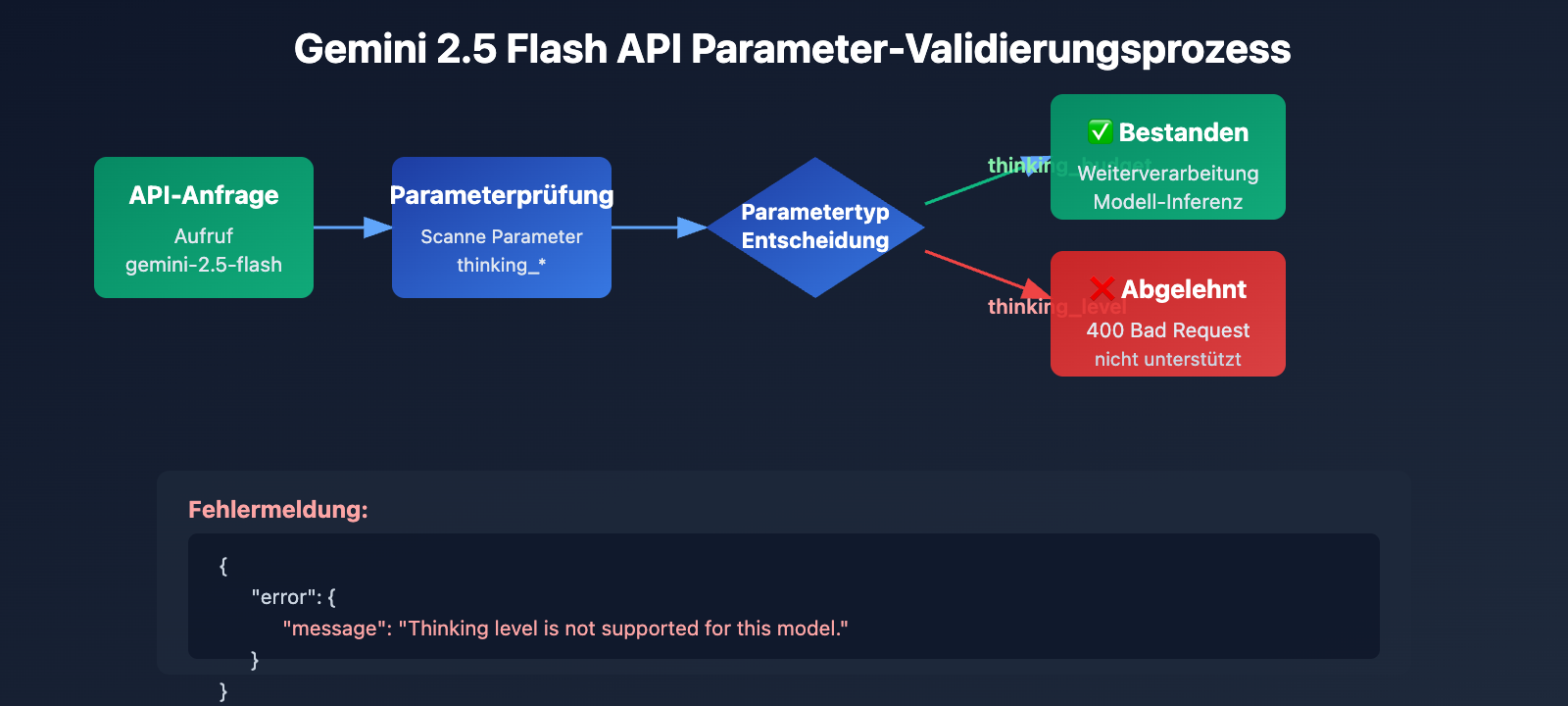
Wenn Sie beim Aufruf von gemini-2.5-flash die Fehlermeldung Thinking level is not supported for this model erhalten, der Wechsel zu gemini-3-flash-preview jedoch reibungslos funktioniert, liegt das an einer grundlegenden Änderung des Parameter-Designs beim Generationswechsel der Google Gemini API. In diesem Artikel analysieren wir systematisch die Unterschiede in der Unterstützung der Thinking-Modus-Parameter zwischen Gemini 2.5 und 3.0.
Kernbotschaft: Nach der Lektüre dieses Artikels werden Sie die essenziellen Unterschiede im Design der Thinking-Modus-Parameter der Modellserien Gemini 2.5 und 3.0 verstehen. Sie lernen die korrekten Konfigurationsmethoden kennen, um API-Aufruffehler durch vermischte Parameter zu vermeiden.

Kernpunkte der Gemini Thinking-Modus Parameter-Evolution
| Modellserie | Unterstützter Parameter | Parametertyp | Verfügbarer Bereich | Standardwert | Deaktivierbar? |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Integer (128-32768) | Präzises Token-Budget | 8192 | ❌ Nein |
| Gemini 2.5 Flash | thinking_budget |
Integer (0-24576) oder -1 | Präzises Budget oder dynamisch | -1 (dynamisch) | ✅ Ja (auf 0 setzen) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Integer (512-24576) | Präzises Token-Budget | 0 (deaktiviert) | ✅ Standardmäßig aus |
| Gemini 3.0 Pro | thinking_level |
Enum ("low"/"high") | Semantische Stufe | "high" | ❌ Nicht vollständig |
| Gemini 3.0 Flash | thinking_level |
Enum ("minimal" bis "high") | Semantische Stufe | "high" | ⚠️ Nur "minimal" |
Parameter-Unterschiede: Gemini 2.5 vs. 3.0
Hauptunterschied: Die Gemini 2.5 Serie verwendet thinking_budget (Token-basiertes Budget), während die Gemini 3.0 Serie auf thinking_level (semantische Stufen) setzt. Diese beiden Parameter sind absolut inkompatibel. Die Verwendung des falschen Parameters für die jeweilige Modellversion führt unweigerlich zu einem 400 Bad Request Fehler.
Google hat thinking_level in Gemini 3.0 eingeführt, um die Konfigurationskomplexität zu reduzieren und die Inferenz-Effizienz zu steigern. Während das Token-Budget in Gemini 2.5 von Entwicklern verlangte, die Anzahl der Thinking-Tokens präzise zu schätzen, abstrahiert Gemini 3.0 diese Komplexität in vier semantische Stufen. Das Modell weist intern automatisch das optimale Token-Budget zu, was zu einer bis zu zweifachen Steigerung der Inferenzgeschwindigkeit führt.
💡 Technischer Tipp: Für die praktische Entwicklung empfehlen wir, Modellwechsel-Tests über die Plattform APIYI (apiyi.com) durchzuführen. Die Plattform bietet eine einheitliche API-Schnittstelle, die alle Modelle der Gemini 2.5 und 3.0 Serien unterstützt. So lassen sich Kompatibilität und Effekte der verschiedenen Thinking-Parameter schnell und unkompliziert validieren.
Hauptursache 1: Die Gemini 2.5 Serie unterstützt den Parameter thinking_level nicht
Generationen-Trennung im API-Parameterdesign
Die Gemini 2.5 Modellserie (einschließlich Pro, Flash, Flash-Lite) erkennt den Parameter thinking_level in ihrem API-Design überhaupt nicht. Wenn Du den Parameter thinking_level beim Aufruf von gemini-2.5-flash übergibst, gibt die API den folgenden Fehler zurück:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Fehlerauslösemechanismus:
- Die API-Validierungsebene der Gemini 2.5 Modelle enthält keine Definition für den Parameter
thinking_level. - Jede Anfrage, die
thinking_levelenthält, wird direkt abgelehnt; es erfolgt kein Versuch eines Mappings aufthinking_budget. - Es handelt sich um eine hardcodierte Parameter-Isolation, es gibt keine automatische Konvertierung oder Abwärtskompatibilität.
Der korrekte Parameter für die Gemini 2.5 Serie: thinking_budget
Parameterspezifikation für Gemini 2.5 Flash:
# Beispiel für korrekte Konfiguration
extra_body = {
"thinking_budget": -1 # Dynamischer Denkmodus
}
# Oder Denken deaktivieren
extra_body = {
"thinking_budget": 0 # Vollständig deaktiviert
}
# Oder präzise Steuerung
extra_body = {
"thinking_budget": 2048 # Genaues Budget von 2048 Token
}
Wertebereich für thinking_budget bei Gemini 2.5 Flash:
| Wert | Bedeutung | Empfohlenes Szenario |
|---|---|---|
0 |
Denkmodus vollständig deaktiviert | Einfache Anweisungsbefolgung, Anwendungen mit hohem Durchsatz |
-1 |
Dynamischer Denkmodus (bis zu 8192 Tokens) | Allgemeine Szenarien, automatische Anpassung an die Komplexität |
512-24576 |
Präzises Token-Budget | Kostenkritische Anwendungen, die eine exakte Kontrolle erfordern |
🎯 Empfehlung: Wenn Du auf Gemini 2.5 Flash umsteigst, empfiehlt es sich, zunächst über die Plattform APIYI (apiyi.com) zu testen, wie sich verschiedene Werte für
thinking_budgetauf die Antwortqualität und Latenz auswirken. Die Plattform ermöglicht einen schnellen Wechsel der Parameterkonfigurationen, um den optimalen Budgetwert für Deinen Anwendungsfall zu finden.
Hauptursache 2: Die Gemini 3.0 Serie unterstützt den Parameter thinking_budget nicht
Vorwärts-Inkompatibilität im Parameterdesign
Obwohl die offizielle Google-Dokumentation behauptet, dass Gemini 3.0 aus Gründen der Abwärtskompatibilität weiterhin den Parameter thinking_budget akzeptiert, zeigen Praxistests:
- Die Verwendung von
thinking_budgetkann zu Leistungseinbußen führen. - Die offizielle Dokumentation empfiehlt ausdrücklich die Verwendung von
thinking_level. - Einige API-Implementierungen lehnen
thinking_budgetunter Umständen vollständig ab.
Der korrekte Parameter für Gemini 3.0 Flash: thinking_level
# Beispiel für korrekte Konfiguration
extra_body = {
"thinking_level": "medium" # Mittlere Inferenzstärke
}
# Oder minimales Denken (fast deaktiviert)
extra_body = {
"thinking_level": "minimal" # Minimaler Denkmodus
}
# Oder hohe Inferenzstärke (Standard)
extra_body = {
"thinking_level": "high" # Tiefen-Inferenz
}
Erläuterung der thinking_level-Stufen für Gemini 3.0 Flash:
| Stufe | Inferenzstärke | Latenz | Kosten | Empfohlenes Szenario |
|---|---|---|---|---|
"minimal" |
Kaum Inferenz | Am niedrigsten | Am niedrigsten | Einfache Anweisungen, hoher Durchsatz |
"low" |
Flache Inferenz | Niedrig | Niedrig | Chatbots, leichtgewichtige QA |
"medium" |
Mittlere Inferenz | Mittel | Mittel | Allgemeine Inferenzaufgaben, Codegenerierung |
"high" |
Tiefen-Inferenz | Hoch | Hoch | Komplexe Problemlösungen, tiefe Analysen (Standard) |
Besondere Einschränkungen bei Gemini 3.0 Pro
Wichtig: Gemini 3.0 Pro unterstützt keine vollständige Deaktivierung des Denkmodus. Selbst wenn thinking_level: "low" eingestellt ist, bleibt eine gewisse Inferenzleistung erhalten. Wenn Du Antworten ohne jegliches Denken (Zero-Thinking) für maximale Geschwindigkeit benötigst, musst Du auf Gemini 2.5 Flash mit thinking_budget: 0 ausweichen.
# Verfügbare Stufen für Gemini 3.0 Pro (nur 2 Optionen)
extra_body = {
"thinking_level": "low" # Niedrigste Stufe (immer noch mit Inferenz)
}
# Oder
extra_body = {
"thinking_level": "high" # Standardmäßig hohe Inferenzstärke
}
💰 Kostenoptimierung: Für budgetsensitive Projekte, bei denen der Denkmodus zur Kostensenkung vollständig deaktiviert werden soll, empfehlen wir den Aufruf der Gemini 2.5 Flash API über die Plattform APIYI (apiyi.com). Die Plattform bietet flexible Abrechnungsmodelle und günstigere Preise, ideal für Szenarien, die eine präzise Kostenkontrolle erfordern.
Ursache 3: Parameterbeschränkungen für Bildmodelle und spezielle Varianten
Das Gemini 2.5 Flash Image Modell unterstützt keinen Denkmodus
Wichtige Erkenntnis: Visuelle Modelle wie gemini-2.5-flash-image unterstützen keinerlei Denkmodus-Parameter, weder thinking_budget noch thinking_level.
Fehlerhaftes Beispiel:
# Beim Aufruf von gemini-2.5-flash-image
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analysiere dieses Bild"}],
extra_body={
"thinking_budget": -1 # ❌ Fehler: Bildmodelle unterstützen dies nicht
}
)
# Rückgabe: "This model doesn't support thinking"
Richtige Vorgehensweise:
# Beim Aufruf eines Bildmodells keine Denkparameter übergeben
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analysiere dieses Bild"}],
# ✅ Weder thinking_budget noch thinking_level übergeben
)
Spezielle Standardwerte für Gemini 2.5 Flash-Lite
Die Kernunterschiede zwischen Gemini 2.5 Flash-Lite und der Standard-Flash-Version:
- Denkmodus standardmäßig deaktiviert (
thinking_budget: 0) - Erfordert eine explizite Einstellung von
thinking_budgetauf einen Wert ungleich Null, um das Denken zu aktivieren - Unterstützter Budgetbereich: 512 bis 24.576 Tokens
# Denkmodus für Gemini 2.5 Flash-Lite aktivieren
extra_body = {
"thinking_budget": 512 # Minimaler Wert ungleich Null, aktiviert leichtgewichtiges Denken
}

| Modell | thinking_budget | thinking_level | Bild-Support | Standard-Denkstatus |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Unterstützt (128-32768) | ❌ Nicht unterstützt | ❌ | Standardmäßig aktiviert (8192) |
| gemini-2.5-flash | ✅ Unterstützt (0-24576, -1) | ❌ Nicht unterstützt | ❌ | Standardmäßig aktiviert (dynamisch) |
| gemini-2.5-flash-lite | ✅ Unterstützt (512-24576) | ❌ Nicht unterstützt | ❌ | Standardmäßig deaktiviert (0) |
| gemini-2.5-flash-image | ❌ Nicht unterstützt | ❌ Nicht unterstützt | ✅ | Kein Denkmodus |
| gemini-3.0-pro | ⚠️ Kompatibel, nicht empfohlen | ✅ Empfohlen (low/high) | ❌ | Standard: high |
| gemini-3.0-flash | ⚠️ Kompatibel, nicht empfohlen | ✅ Empfohlen (minimal/low/medium/high) | ❌ | Standard: high |
🚀 Schnellstart: Wir empfehlen die Nutzung der APIYI Plattform (apiyi.com), um die Kompatibilität der Denkparameter verschiedener Modelle schnell zu testen. Die Plattform bietet direkt einsatzbereite Schnittstellen für die gesamte Gemini-Serie, erfordert keine komplexe Konfiguration und ermöglicht die Integration sowie Parameter-Validierung in nur 5 Minuten.
Lösung 1: Parameter-Anpassungsfunktion basierend auf der Modellversion
Intelligenter Parameter-Selektor (Unterstützt die gesamte Modellserie)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
Wählt automatisch die korrekten Parameter für den Thinking-Modus basierend auf dem Gemini-Modellnamen aus.
Args:
model_name: Gemini Modellname
intensity: Thinking-Intensität ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
Ein Parameter-Dictionary für extra_body. Gibt ein leeres Dictionary zurück,
wenn das Modell Thinking nicht unterstützt.
"""
# Gemini 3.0 Modellliste
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Gemini 2.5 Standard-Modellliste
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# Liste der Bildmodelle (unterstützen kein Thinking)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# Prüfen, ob es sich um ein Bildmodell handelt
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ Warnung: {model_name} unterstützt keine Thinking-Modus-Parameter, leere Konfiguration wird zurückgegeben")
return {}
# Gemini 3.0 Serie verwendet thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0 kann nicht vollständig deaktiviert werden, 'minimal' wird verwendet
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro unterstützt nur low und high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash unterstützt alle 4 Stufen
return {"thinking_level": level_map.get(intensity, "medium")}
# Gemini 2.5 Serie verwendet thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # Vollständig deaktiviert
"minimal": 512, # Minimales Budget
"low": 2048, # Niedrige Intensität
"medium": 8192, # Mittlere Intensität
"high": 16384, # Hohe Intensität
"dynamic": -1 # Dynamische Anpassung
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro unterstützt keine Deaktivierung (Minimum 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ Warnung: {model_name} unterstützt keine Deaktivierung von Thinking, automatisch auf Minimum 128 angepasst")
budget = 128
# Gemini 2.5 Flash-Lite hat ein Minimum von 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ Warnung: Minimales Budget für {model_name} ist 512, wird automatisch angepasst")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ Warnung: Unbekanntes Modell {model_name}, Standardwerte für Gemini 3.0 werden verwendet")
return {"thinking_level": "medium"}
# Anwendungsbeispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Test mit Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"{model_2_5} Konfiguration: {config_2_5}")
# Ausgabe: gemini-2.5-flash Konfiguration: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "Erkläre Quantenverschränkung"}],
extra_body=config_2_5
)
# Test mit Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"{model_3_0} Konfiguration: {config_3_0}")
# Ausgabe: gemini-3.0-flash-preview Konfiguration: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "Erkläre Quantenverschränkung"}],
extra_body=config_3_0
)
# Test mit Bildmodell
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"{model_image} Konfiguration: {config_image}")
# Ausgabe: ⚠️ Warnung: gemini-2.5-flash-image unterstützt keine Thinking-Modus-Parameter, leere Konfiguration wird zurückgegeben
# Ausgabe: gemini-2.5-flash-image Konfiguration: {}
💡 Best Practice: In Szenarien, in denen ein dynamischer Wechsel zwischen Gemini-Modellen erforderlich ist, wird empfohlen, Parameter-Anpassungstests über die Plattform APIYI (apiyi.com) durchzuführen. Die Plattform unterstützt die vollständigen Gemini 2.5 und 3.0 Modellserien, was es einfach macht, die Antwortqualität und Kostenunterschiede bei verschiedenen Parameterkonfigurationen zu validieren.
Lösung 2: Migrationsstrategie von Gemini 2.5 zu 3.0
Vergleichstabelle für die Migration der Thinking-Modus-Parameter
| Gemini 2.5 Flash Konfiguration | Gemini 3.0 Flash Äquivalent | Latenzvergleich | Kostenvergleich |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 ist schneller (ca. 2x) | Ähnlich |
thinking_budget: 512 |
thinking_level: "low" |
3.0 ist schneller | Ähnlich |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 ist schneller | Ähnlich |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 ist schneller | Etwas höher |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 ist schneller | Etwas höher |
thinking_budget: -1 (dynamisch) |
thinking_level: "high" (Standard) |
3.0 ist deutlich schneller | 3.0 ist teurer |
Beispiel für Migrations-Code
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
Migration von Gemini 2.5 zu Gemini 3.0
Args:
old_model: Gemini 2.5 Modellname
old_config: extra_body Konfiguration von Gemini 2.5
Returns:
(Neuer Modellname, Neues Konfigurations-Dictionary)
"""
# Mapping der Modellnamen
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# Parameter-Konvertierung
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# Konvertierung in thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro unterstützt nur low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# Standardkonfiguration
new_config = {"thinking_level": "medium"}
return new_model, new_config
# Migrationsbeispiel
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"Vor Migration: {old_model} {old_config}")
print(f"Nach Migration: {new_model} {new_config}")
# Ausgabe:
# Vor Migration: gemini-2.5-flash {'thinking_budget': -1}
# Nach Migration: gemini-3.0-flash-preview {'thinking_level': 'high'}
# Aufruf mit neuer Konfiguration
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "Ihre Frage"}],
extra_body=new_config
)
🎯 Migrationsvorschlag: Beim Umstieg von Gemini 2.5 auf 3.0 wird empfohlen, zunächst A/B-Tests über die Plattform APIYI (apiyi.com) durchzuführen. Die Plattform ermöglicht den schnellen Wechsel zwischen Modellversionen, sodass Sie Antwortqualität, Latenz und Kosten vor und nach der Migration vergleichen können, um einen reibungslosen Übergang zu gewährleisten.
Häufig gestellte Fragen (FAQ)
Q1: Warum funktioniert mein Code mit Gemini 3.0 einwandfrei, meldet aber bei Version 2.5 einen Fehler?
Grund: In Ihrem Code wird wahrscheinlich der Parameter thinking_level verwendet. Dies ist ein exklusiver Parameter für Gemini 3.0, der von der 2.5-Serie überhaupt nicht unterstützt wird.
Lösung:
# Fehlerhafter Code (nur für 3.0 geeignet)
extra_body = {
"thinking_level": "medium" # ❌ 2.5 erkennt dies nicht
}
# Korrekter Code (für 2.5 geeignet)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5 nutzt budget
}
Es wird empfohlen, die oben erwähnte Funktion get_gemini_thinking_config() zur automatischen Anpassung zu verwenden oder die Parameter-Kompatibilität schnell über die Plattform APIYI (apiyi.com) zu validieren.
Q2: Wie groß ist der Performance-Unterschied zwischen Gemini 2.5 Flash und Gemini 3.0 Flash?
Basierend auf offiziellen Google-Daten und Community-Tests:
| Metrik | Gemini 2.5 Flash | Gemini 3.0 Flash | Steigerung |
|---|---|---|---|
| Inferenz-Geschwindigkeit | Basis | 2x schneller | +100% |
| Latenz | Basis | Deutlich reduziert | ca. -50% |
| Denk-Effizienz | Festes Budget oder dynamisch | Automatisch optimiert | Qualitätssteigerung |
| Kosten | Basis | Etwas höher (hohe Qualität) | +10-20% |
Kernunterschied: Gemini 3.0 nutzt eine dynamische Zuweisung des Denkprozesses – es "denkt" nur so lange wie nötig. Das feste Budget von 2.5 kann hingegen zu unnötig langem oder unzureichendem Nachdenken führen.
Wir empfehlen praktische Tests über die APIYI-Plattform (apiyi.com). Dort finden Sie Echtzeit-Performance-Monitoring und Kostenanalysen, um die tatsächliche Leistung verschiedener Modelle bequem zu vergleichen.
Q3: Wie kann ich den Denkmodus in Gemini 3.0 komplett deaktivieren?
Wichtig: Bei Gemini 3.0 Pro lässt sich der Denkmodus nicht vollständig deaktivieren. Selbst mit der Einstellung thinking_level: "low" bleibt eine leichtgewichtige Reasoning-Fähigkeit erhalten.
Verfügbare Optionen:
- Gemini 3.0 Flash: Nutzen Sie
thinking_level: "minimal", was fast keinem Denken entspricht (bei komplexen Coding-Aufgaben kann es dennoch zu leichtem Nachdenken kommen). - Gemini 3.0 Pro: Die niedrigste Stufe ist
thinking_level: "low".
Falls eine vollständige Deaktivierung erforderlich ist:
# Nur Gemini 2.5 Flash unterstützt die vollständige Deaktivierung
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Denkmodus komplett deaktiviert
}
Für Szenarien, die extreme Geschwindigkeit erfordern und keine Reasoning-Fähigkeiten benötigen (wie einfaches Instruction-Following), empfiehlt es sich, Gemini 2.5 Flash über APIYI (apiyi.com) mit
thinking_budget: 0aufzurufen.
Q4: Unterstützen Gemini-Bildmodelle den Denkmodus?
Nein. Alle Gemini-Bildverarbeitungsmodelle (wie gemini-2.5-flash-image, gemini-pro-vision) unterstützen keine Parameter für den Denkmodus.
Fehlerbeispiel:
# ❌ Bildmodelle unterstützen keine Denk-Parameter
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Löst einen Fehler aus
}
)
Richtige Vorgehensweise:
# ✅ Beim Aufruf von Bildmodellen keine Denk-Parameter übergeben
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# extra_body weglassen oder andere, nicht denkbezogene Parameter übergeben
)
Technischer Hintergrund: Die Architektur der Bildmodelle ist auf visuelles Verständnis spezialisiert und enthält nicht den Chain-of-Thought-Mechanismus von Sprachmodellen.
Zusammenfassung
Die Kernpunkte zur Fehlermeldung thinking_level not supported bei Gemini 2.5 Flash:
- Parameter-Trennung: Gemini 2.5 unterstützt nur
thinking_budget, Gemini 3.0 nurthinking_level. Beide sind absolut inkompatibel zueinander. - Modell-Identifikation: Unterscheiden Sie die Version anhand des Modellnamens. Nutzen Sie für die 2.5-Serie
thinking_budgetund für die 3.0-Seriethinking_level. - Einschränkungen bei Bildmodellen: Alle Bildmodelle (z. B.
gemini-2.5-flash-image) unterstützen keinerlei Parameter für den Denkmodus. - Unterschiede beim Deaktivieren: Nur Gemini 2.5 Flash erlaubt das vollständige Abschalten des Denkens (
thinking_budget: 0). Bei der 3.0-Serie istminimaldas Minimum. - Migrationsstrategie: Bei einem Wechsel von 2.5 auf 3.0 muss
thinking_budgetaufthinking_levelgemappt werden, wobei auch Performance- und Kostenänderungen zu berücksichtigen sind.
Wir empfehlen die Nutzung von APIYI (apiyi.com), um die Kompatibilität der Denk-Parameter und die tatsächlichen Effekte verschiedener Modelle schnell zu validieren. Die Plattform unterstützt die gesamte Gemini-Modellreihe, bietet eine einheitliche Schnittstelle und flexible Abrechnungsmodelle – ideal für schnelle Vergleichstests und den Einsatz in Produktionsumgebungen.
Autor: APIYI Technik-Team | Bei technischen Fragen besuchen Sie uns gerne auf APIYI (apiyi.com) für weitere Lösungen zur Integration von KI-Modellen.