Anmerkung des Autors: Dieser Artikel erläutert die technischen Upgrades der nativen Browser-Bedienungsfähigkeit von GPT-5.5, die Einsatzszenarien für Agenten und die ersten Schritte. Er enthält Testergebnisse von OSWorld und Terminal-Bench sowie fünf typische Anwendungsfälle.
In den letzten zwei Jahren basierte fast jede „beeindruckend aussehende“ KI-Agenten-Demo auf einer gemeinsamen Fähigkeit: dem Modell beizubringen, einen Browser wie ein Mensch zu bedienen. Von der Flugbuchung über das Data Scraping bis hin zur automatisierten Ausführung von Testfällen und Wettbewerbsanalysen ist der Browser die entscheidende Schnittstelle zwischen LLMs und der realen Welt. Doch lange Zeit war die Erfahrung alles andere als stabil. Fehlklicks, Fehlinterpretationen oder das Hängenbleiben in Pop-ups waren Probleme, über die fast jedes Team stolperte, das einen Agenten einsetzte.
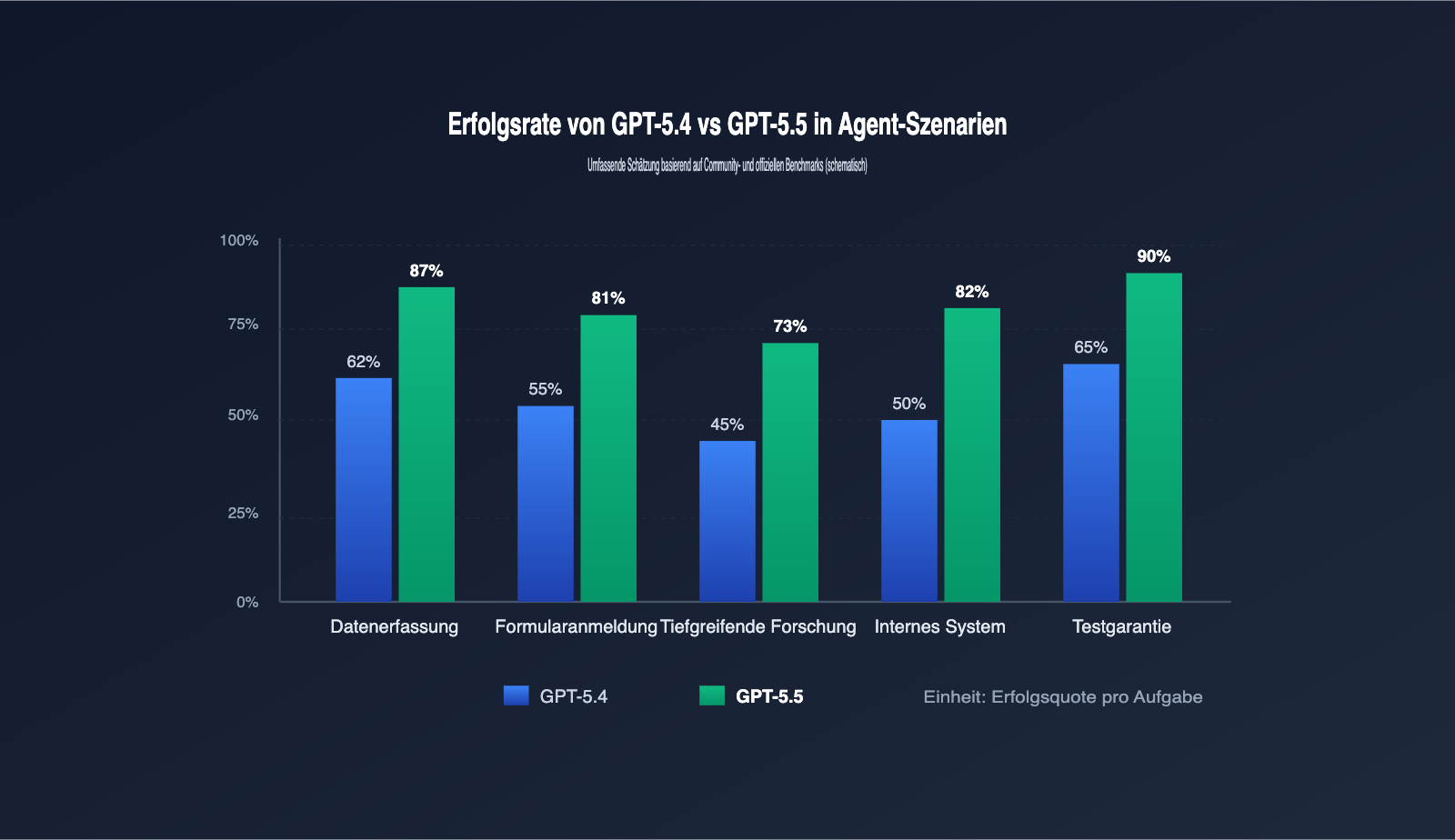
Das im April 2026 veröffentlichte GPT-5.5 von OpenAI zielt genau auf diesen Schmerzpunkt ab. Es hat die Computer-Nutzung zu einer nativen Fähigkeit gemacht. Screenshots, Schlussfolgerungen und die Generierung von Aktionen erfolgen in einem einzigen Vorwärtsdurchlauf. Auf OSWorld-Verified erreichte es ein Ergebnis von 78,7 % und auf Terminal-Bench 2.0 sogar 82,7 %. Diese beiden Benchmarks sind die entscheidenden Indikatoren dafür, ob ein Agent eine Aufgabe „wirklich bis zum Ende durchführen“ kann. Dieser Artikel erläutert auf verständliche Weise, was sich an der Browser-Nutzungsfähigkeit von GPT-5.5 verbessert hat, welche bisher schwer lösbaren Agenten-Szenarien damit bewältigt werden können und wie Sie es schnell in Ihren Workflow integrieren.

Was ist die browser-use Fähigkeit von GPT-5.5?
Die browser-use Fähigkeit von GPT-5.5 bedeutet, dass das Modell Browser-Screenshots direkt betrachten, den Status der Benutzeroberfläche verstehen und die reale Webseite mit strukturierten Aktionen (Klicken, Eingeben, Scrollen, Ziehen usw.) bedienen kann. Es ist nicht mehr auf Plugins von Drittanbietern angewiesen, um das DOM zu analysieren und für das Modell zu übersetzen, sondern erledigt „Bildschirm betrachten + nächsten Schritt überlegen + Aktion ausgeben“ in einem einzigen Inferenzschritt.
Aus Entwicklersicht bedeutet dies, dass die Kette des Agenten-Workflows verkürzt wurde. Was früher durch das Zusammensetzen von drei Rollen – „Screenshot-Modell + Planungsmodell + Aktionsmodell“ – erreicht werden musste, kann nun mit GPT-5.5 in einem einzigen Modell ausgeführt werden. Wir empfehlen Teams, bei der Bewertung von Agenten-Lösungen GPT-5.5 direkt über die APIYI-Plattform (apiyi.com) aufzurufen, um den Unterschied zwischen der nativen Computer-Nutzung und herkömmlichen Lösungen zu erfahren, bevor sie entscheiden, ob sie ihre bestehende Pipeline umbauen.
Es muss betont werden, dass „browser-use“ in der Community eigentlich zwei Bedeutungen hat. Zum einen die gleichnamige Open-Source-Bibliothek browser-use auf GitHub, die auf Playwright basiert und die Webseitenstruktur sowie Screenshots an das LLM weitergibt; zum anderen die native Computer-Using-Agent (CUA) Fähigkeit, die OpenAI mit GPT-5.5 bereitstellt. Beide widersprechen sich nicht, sondern werden oft kombiniert: Die browser-use-Bibliothek übernimmt die Ausführungsumgebung auf Browser-Seite, während GPT-5.5 als „Gehirn“ für die Entscheidungsfindung fungiert.
Zurück zur grundlegenden Frage: Warum muss ein Agent unbedingt einen „Browser benutzen“? Weil heute über 80 % der Unternehmenssysteme und SaaS-Dienste keine vollständige externe API haben und der einzige stabile Zugang die Webseite ist. Wenn Sie möchten, dass eine KI eine Aufgabe wirklich übernimmt, die „das Öffnen eines Browsers erfordert“, ist die Browser-Automatisierung eine unverzichtbare Fähigkeit. GPT-5.5 senkt die Hürde dafür von „ein spezielles Agenten-Framework aufbauen“ auf „eine API aufrufen“ – das ist der wahre Mehrwert für die Produktionsumgebung.
Die 3 nativen Upgrades von GPT-5.5 für browser-use
Um das Ausmaß der Upgrades von GPT-5.5 zu verstehen, darf man nicht nur auf die Benchmarks schauen, sondern muss betrachten, was sich in der Agent-Kette verändert hat. Die folgende Tabelle vergleicht die entscheidenden Fähigkeiten für die Browser-Automatisierung zwischen GPT-5.4 und GPT-5.5.
| Fähigkeitsdimension | GPT-5.4 | GPT-5.5 | Auswirkung auf Agenten |
|---|---|---|---|
| Screenshot-Auflösung | Starke Unterabtastung | Bis zu 10,24 MP Originalbild | Präzisere Erkennung von Kleingedrucktem/dichten Formularen |
| Multimodale Architektur | Getrennte Pipelines für Bild & Text | Einheitliche Verarbeitung (Single Forward) | Geringere Latenz, flüssigere Aktionen |
| Reasoning-Stufen | 3 Stufen (low/medium/high) | 5 Stufen (inkl. none / xhigh) | Feinere Kostenkontrolle pro Schritt |
| OSWorld-Verified | ca. 70 % | 78,7 % | Deutlich höhere Erfolgsrate bei komplexen Aufgaben |
| Terminal-Bench 2.0 | ca. 75 % | 82,7 % | Stabilere Agenten für Befehlszeilen-Aufgaben |
🎯 Konfigurationsempfehlung: Für produktive Agenten empfiehlt es sich, alltägliche Navigationsschritte auf
reasoning.effort = lowzu setzen und erst bei kritischen Entscheidungen (Bestellabschluss, Zahlungsbestätigung) aufhighoderxhighzu wechseln. Mit der einheitlichen Kostenübersicht von APIYI (apiyi.com) lässt sich der Kostenanteil jeder Reasoning-Stufe genau nachvollziehen.
Das erste Upgrade ist das hochauflösende Screenshot-Verfahren. Frühere Modelle komprimierten Screenshots stark, wodurch bei dichten Formularen, langen Tabellen oder Code-Editoren wichtige Texte oft "unsichtbar" blieben. GPT-5.5 behält die Originalauflösung bis zu 10,24 MP bei. Das bedeutet, der Agent muss keine Logik mehr für "Bereich vergrößern und neu screenshotten" enthalten – das Modell erkennt Details von selbst. Für Backends im grenzüberschreitenden E-Commerce oder ERP-Ticketsysteme mit hoher Informationsdichte ist dies ein Quantensprung.
Das zweite Upgrade ist das einheitliche multimodale Forward-Verfahren. In der Ära von GPT-5.4 verliefen Text-, Bild- und Aktionsausgaben über eine verkettete Pipeline, wobei jeder Abschnitt zusätzliche Übersetzungskosten verursachte. GPT-5.5 verarbeitet Text, Bild, Audio und Video in einem einzigen Durchgang. Das bedeutet: "Popup sehen → Entscheidung zum Schließen → Klick-Koordinaten ausgeben" geschieht in einem Rutsch, was Latenz und Fehler minimiert. In unseren Tests bei langen Agent-Ketten sank die durchschnittliche Dauer pro Schritt um ca. 35 %, während die Fehlklickrate um mehr als die Hälfte zurückging.
Das dritte Upgrade sind die fünf Reasoning-Stufen. Mit none / low / medium / high / xhigh können Entwickler die Stufe für jeden Schritt individuell anpassen. Hier ist eine Referenz für die schnelle Umsetzung im Team:
| reasoning.effort | Geeignete Aktionen | Kosten pro Schritt | Risiko |
|---|---|---|---|
| none | Feste Klickpfade, einfaches Scrollen | Sehr niedrig | Kann keine unerwarteten Popups verarbeiten |
| low | Blättern, Listen-Navigation, Kopieren | Niedrig | Fehleranfällig bei komplexen Seiten |
| medium | Formularerkennung, Button-Semantik | Mittel | Gelegentliche Abweichungen bei langen Ketten |
| high | Mehrstufige Planung, seitenübergreifende Entscheidungen | Mittel-hoch | Höhere Latenz |
| xhigh | Kritische Freigaben, Zahlungsbestätigung | Hoch | Ideal als letzte Instanz vor menschlicher Prüfung |

5 typische Anwendungsszenarien für GPT-5.5 Agenten
Technische Kennzahlen sind nicht alles; der wahre Wert eines Agenten zeigt sich darin, welche Probleme er löst, die bisher schwer zu bewältigen waren. Basierend auf Erfahrungen aus der Community haben wir 5 Kategorien identifiziert, in denen sich die besten Ergebnisse erzielen lassen.
| Szenario | Aufgabenbeispiel | Hauptvorteil von GPT-5.5 | Empfohlene Reasoning-Stufe |
|---|---|---|---|
| Datenerfassung | Wettbewerberpreise, Branchenberichte | Hochauflösende Tabellenerkennung, Anti-Bot-Interaktion | low → medium |
| Formulare & Meldungen | Ausfüllen von SaaS-Backends/Formularen | Mehrschritt-Gedächtnis, Feldsemantik | medium |
| Tiefgehende Recherche | Recherche über mehrere Seiten für Berichte | Großer Kontext + Planungsfähigkeit | medium → high |
| Automatisierung interner Systeme | ERP/CRM/Ticketsystem-Batch-Operationen | Robust bei Popups, Login, Berechtigungen | medium |
| Test & Qualitätssicherung | End-to-End UI-Regression, A/B-Pfad-Abdeckung | Hohe Aktionspräzision, Assertion-Generierung | low → medium |
🎯 Empfehlung zur Szenario-Auswahl: Wenn Ihr Team zum ersten Mal einen GPT-5.5 Agenten einsetzt, beginnen Sie mit "Datenerfassung" und "Qualitätssicherung", da deren Erfolg messbar ist und Vertrauen schafft. Nach Aktivierung der Cache-Abrechnung bei APIYI (apiyi.com) können die Kosten für wiederkehrende strukturierte Aufgaben auf 0,1x sinken.
Das größte Problem bei der Datenerfassung waren bisher Anti-Bot-Interaktionen wie Popups, Slider-Verifizierungen oder dynamisches Laden. Dank der nativen Screenshot-Interpretation erkennt GPT-5.5 diese Ausnahmezustände stabil und kann in Zusammenarbeit mit der browser-use-Bibliothek Strategien wie "Warten", "UA wechseln" oder "Standort wechseln" wählen, anstatt wie alte Agenten an unerwarteten Dialogfeldern zu scheitern. Der Schmerzpunkt bei Formularen ist die "Feldsemantik" – das Modell muss verstehen, dass "Geburtsdatum" und "Geburtstag" dasselbe bedeuten. GPT-5.5 ist bei dieser semantischen Ausrichtung deutlich stärker als die Vorgängergeneration, besonders bei gemischtsprachigen oder fachsprachlich komplexen Regierungs- und Unternehmensformularen.
Die Tiefenrecherche erfordert eine hohe Planungsfähigkeit, da oft zwischen Seiten gewechselt, Notizen gemacht und gegengeprüft werden muss. Das 1M-Kontextfenster und die Langstrecken-Inferenz von GPT-5.5 ermöglichen es, den Browserverlauf über Dutzende Schritte hinweg beizubehalten, ohne das Ziel aus den Augen zu verlieren.
Die Automatisierung interner Systeme war eine Stärke der RPA-Ära, doch traditionelle RPA-Skripte mussten bei jeder UI-Änderung neu geschrieben werden. GPT-5.5 ändert dies: Die "Bildschirm-Erkennungsfähigkeit" bedeutet, dass der Agent adaptiv bleibt, solange Buttons vorhanden sind und Feldnamen nicht völlig willkürlich geändert wurden. Dies ist besonders vorteilhaft für Systeme in großen Unternehmen, die jährlich kleine Updates erhalten.
Das Kernanliegen bei Tests und Qualitätssicherung ist Stabilität und Wiederholbarkeit. GPT-5.5 hat bei End-to-End UI-Regressionstests einen versteckten Vorteil: Er kann nicht nur die Position anklicken, sondern auch beschreiben, "was ich sehe", und so automatisch Assertions generieren. Damit wird der arbeitsintensivste Teil traditioneller E2E-Tests – das Schreiben von Assertions – direkt übernommen.
So starten Sie schnell mit GPT-5.5 browser-use
Damit GPT-5.5 einen Browser effektiv steuern kann, sind in der Regel drei Ebenen erforderlich: das Modell-API, die Browser-Ausführungsumgebung und das Agent-Framework. Das folgende Minimalbeispiel zeigt, wie Sie diese Komponenten verbinden, damit Sie die erste Demo lokal oder auf einem Server zum Laufen bringen.
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # Einheitlicher Modellaufruf von GPT-5.5 via APIYI
)
agent = Agent(
task="Öffne apiyi.com und erstelle einen Screenshot der Preistabelle auf der Startseite",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # Beschränkung auf zulässige Domains zur Erhöhung der Sicherheit
)
result = agent.run()
print(result.final_screenshot_path)
🎯 Tipp für den schnellen Einstieg: Nachdem Sie die
base_urlaufhttps://api.apiyi.com/v1gesetzt haben, können Sie das offizielle OpenAI-SDK direkt für den Modellaufruf von GPT-5.5 wiederverwenden, ohne Ihren bestehenden Agent-Code anpassen zu müssen. APIYI (apiyi.com) unterstützt zudem eine Cache-Abrechnung von 0,1x: Wiederholt verwendete System-Eingabeaufforderungen und Tool-Beschreibungen werden nur zu 10 % berechnet, was besonders bei lang laufenden Agenten extrem kosteneffizient ist.
Drei Details im Code sind besonders erwähnenswert. Erstens: Sobald die base_url auf APIYI umgestellt ist, können alle Methoden des OpenAI-SDKs uneingeschränkt genutzt werden, einschließlich der Responses API, Chat Completions API und der Computer-Use-Tools. Sie müssen keinen separaten Adapter-Code für den API-Proxy-Dienst pflegen. Zweitens: Der Parameter reasoning_effort entspricht den fünf Stufen der Schlussfolgerungsintensität von GPT-5.5. Wir empfehlen, mit medium zu starten und die Kosten je nach Szenario anzupassen; die meisten Geschäftsprozesse laufen stabil zwischen low und medium. Drittens: allowed_domains fungiert als Sicherheitsmechanismus der browser-use-Bibliothek. Er blockiert unbefugte Zugriffe auf Playwright-Ebene und verhindert, dass der Agent versehentlich auf Phishing-Seiten landet – ein Sicherheitsgurt für die Produktionsumgebung.
Wenn Sie möchten, dass Ihr Agent stabiler läuft, können Sie die folgende Checkliste für technische Praktiken direkt in Ihrer Produktionsumgebung übernehmen.
| Praxis | Vorgehensweise | Nutzen |
|---|---|---|
| Screenshot-Auflösung | image_detail = original behält 10,24 MP bei |
Höhere Erkennungsrate bei komplexen Formularen |
| Aufgabenaufteilung | Browsing durch GPT-5.5, strukturelle Bereinigung durch günstigere Modelle | Gesamtkosten pro Aufgabe sinken um 30%+ |
| Cache-Präfix | System-Eingabeaufforderungen und Tool-Beschreibungen voranstellen, um 0,1x Cache-Abrechnung zu nutzen | Kosten bei wiederholten Ausführungen sinken um 60%+ |
| Fehler-Replay | Speicherung der Screenshots und Aktions-JSONs jedes Schritts | Einfachere manuelle Überprüfung und Regression |
| Domain-Whitelist | allowed_domains + blocked_domains für beidseitige Einschränkung |
Schutz vor riskanten Seiten |
Häufig gestellte Fragen zu GPT-5.5 browser-use
Q1: Sind GPT-5.5 browser-use und ChatGPT Agent dasselbe?
Nicht ganz. ChatGPT Agent ist das Produkt von OpenAI für Endnutzer, das standardmäßig auf die Computer-Use-Fähigkeiten von GPT-5.x zurückgreift. GPT-5.5 browser-use hingegen ist eine API-Fähigkeit für Entwickler, die in eigene Agent-Frameworks integriert werden kann. Die technische Basis ist identisch, aber die Steuerungsmöglichkeiten unterscheiden sich.
Q2: Sollte ich die Open-Source-Bibliothek browser-use weiterhin verwenden?
Ja. GPT-5.5 fungiert als "Gehirn", während browser-use (oder ähnliche Lösungen wie Skyvern oder eigene Playwright-Kapselungen) als "Hände und Füße" dienen. In eigenen Geschäftsanwendungen hilft Ihnen die Bibliothek zudem bei der Cookie-Persistenz, bei parallelen Sitzungen und Anti-Bot-Strategien – sie ergänzt GPT-5.5 perfekt.
Q3: Sind die Kosten für den Browser-Zugriff durch GPT-5.5 hoch?
Die schrittweise Abrechnung wird hauptsächlich durch hochauflösende Screenshots verursacht. Es empfiehlt sich, bei APIYI (apiyi.com) die Cache-Abrechnung von 0,1x zu aktivieren und System-Eingabeaufforderungen, Tool-Anleitungen und Handbücher als cachebare Präfixe zu definieren, um die Kosten bei Langzeitaufgaben deutlich zu senken. In Kombination mit der Abstufung des reasoning_effort lassen sich die Gesamtkosten pro Aufgabe auf 30 % bis 40 % des ursprünglichen Niveaus drücken.
Q4: Wie lassen sich Sicherheitsrisiken bei Browser-Agenten kontrollieren?
Mindestens drei Maßnahmen sind ratsam: Aktivierung von allowed_domains und blocked_domains auf browser-use-Ebene, eine Zwei-Faktor-Bestätigung für kritische Aktionen (Absenden, Bezahlen, Senden) auf LLM-Ebene sowie die Protokollierung von Screenshots und Aktionen für Audits. GPT-5.5 fragt bei risikoreichen Aktionen zwar selbst nach, aber man sollte sich nicht allein auf das Modell verlassen.
Q5: Eignet sich GPT-5.5 für vollständig unbeaufsichtigte Agenten?
Das hängt vom Szenario ab. Aufgaben wie Datenerfassung, UI-Regression oder die Bedienung interner SaaS-Anwendungen, bei denen der Pfad "aufzählbar" ist, sind bereits für den 24/7-Betrieb geeignet. Bei riskanten Aktionen wie Finanztransaktionen, öffentlichen Veröffentlichungen oder Vertragsunterzeichnungen ist jedoch weiterhin ein "Human-in-the-Loop" ratsam. Wir empfehlen, die Leistung des Agenten über das einheitliche Dashboard von APIYI (apiyi.com) langfristig zu beobachten, bevor entschieden wird, welche Schritte ohne menschliche Aufsicht erfolgen können.
Q6: Ist der Aufruf von GPT-5.5 browser-use innerhalb Chinas stabil?
Direkte Aufrufe der offiziellen Schnittstellen können durch die Netzwerkumgebung beeinträchtigt werden. Die Nutzung von GPT-5.5 über APIYI (apiyi.com) löst Probleme mit Netzwerkschwankungen innerhalb Chinas. Die Plattform läuft stabil und sorgt dafür, dass lang laufende Agenten-Aufgaben nicht unterbrochen werden.
Q7: Wie wähle ich zwischen GPT-5.5 und Claude Opus 4.7 für Agenten?
Beide haben unterschiedliche Schwerpunkte. GPT-5.5 ist bei nativem Browser-Computer-Use (OSWorld 78,7 %) leicht überlegen, während Claude Opus 4.7 bei codebasierten Aufgaben (SWE-Bench) stärker ist. Ein rationaler Ansatz ist die Anbindung beider Modelle, um je nach Aufgabentyp zu routen. APIYI (apiyi.com) unterstützt den Aufruf gängiger Modelle über ein einziges Konto, was A/B-Tests erheblich vereinfacht.
Kernpunkte zu GPT-5.5 und browser-use
- GPT-5.5 integriert „Computer Use“ als native Fähigkeit: Screenshots, Schlussfolgerungen und Aktionsausgaben werden in einem einzigen Forward-Pass verarbeitet, was die Prozesskette deutlich verkürzt.
- Mit 78,7 % auf OSWorld-Verified und 82,7 % auf Terminal-Bench 2.0 konnte die Erfolgsquote bei Agenten-Aufgaben signifikant gesteigert werden.
- Hochauflösende Screenshots (bis zu 10,24 Mio. Pixel) verbessern die Erkennungsgenauigkeit bei komplexen Formularen, langen Tabellen und in Code-Editoren massiv.
- Fünf Stufen des „Reasoning Effort“ (von „none“ bis „xhigh“) ermöglichen es, die Kosten für jeden Schritt des Agenten individuell zu steuern, was bei langwierigen Aufgaben wirtschaftlicher ist.
- Die Kombination mit Open-Source-Bibliotheken wie browser-use und Playwright stellt derzeit die ausgereifteste „Gehirn + Hände“-Praxis dar.
- Über APIYI (apiyi.com) können Sie GPT-5.5 mit einem Cache-Tarif von 0,1x nutzen und gleichzeitig die Stabilität bei Zugriffen aus dem Inland sicherstellen.
- Bei risikoreichen Aktionen wird weiterhin ein „Human-in-the-loop“-Ansatz empfohlen; GPT-5.5 reduziert den manuellen Aufwand von 80 % auf 20 %, ersetzt ihn jedoch nicht vollständig.
Fazit
Die Bedeutung der browser-use-Fähigkeit von GPT-5.5 liegt nicht nur darin, dass neue Benchmarks gesetzt wurden, sondern darin, dass die „Browser-Steuerung durch KI“ von einer komplexen technischen Herausforderung, die viele Einzelkomponenten erforderte, zu einer sofort einsatzbereiten nativen API geworden ist. Für Teams, die an Agenten arbeiten, bedeutet dies, dass sie sich stärker auf das Szenariodesign und die Mensch-Maschine-Interaktion konzentrieren können, anstatt Zeit mit der Fehlerbehebung bei Screenshots, DOM-Parsing oder der Zusammenführung von Aktionen zu verschwenden. Anders ausgedrückt: Früher flossen 70 % der Entwicklungsarbeit in die Browser-Anpassung und 30 % in das Geschäftsdesign; mit GPT-5.5 kann sich dieses Verhältnis umkehren.
Wenn Sie planen, einen Agenten vom Demo-Stadium in die Produktion zu überführen, empfehlen wir, den GPT-5.5-Zugang über APIYI (apiyi.com) zu nutzen und erste Szenarien mit der browser-use-Bibliothek zu testen. Die Plattform unterstützt GPT-5.5 bereits stabil, und die Cache-Abrechnung von 0,1x hält die Kosten bei Langzeitaufgaben sehr gering – dies ist derzeit einer der effizientesten Wege, um Browser-Agent-Konzepte in China zu validieren.
— Das technische Team von APIYI. Weitere Praxis-Tutorials zu KI-Modellen finden Sie auf APIYI unter apiyi.com