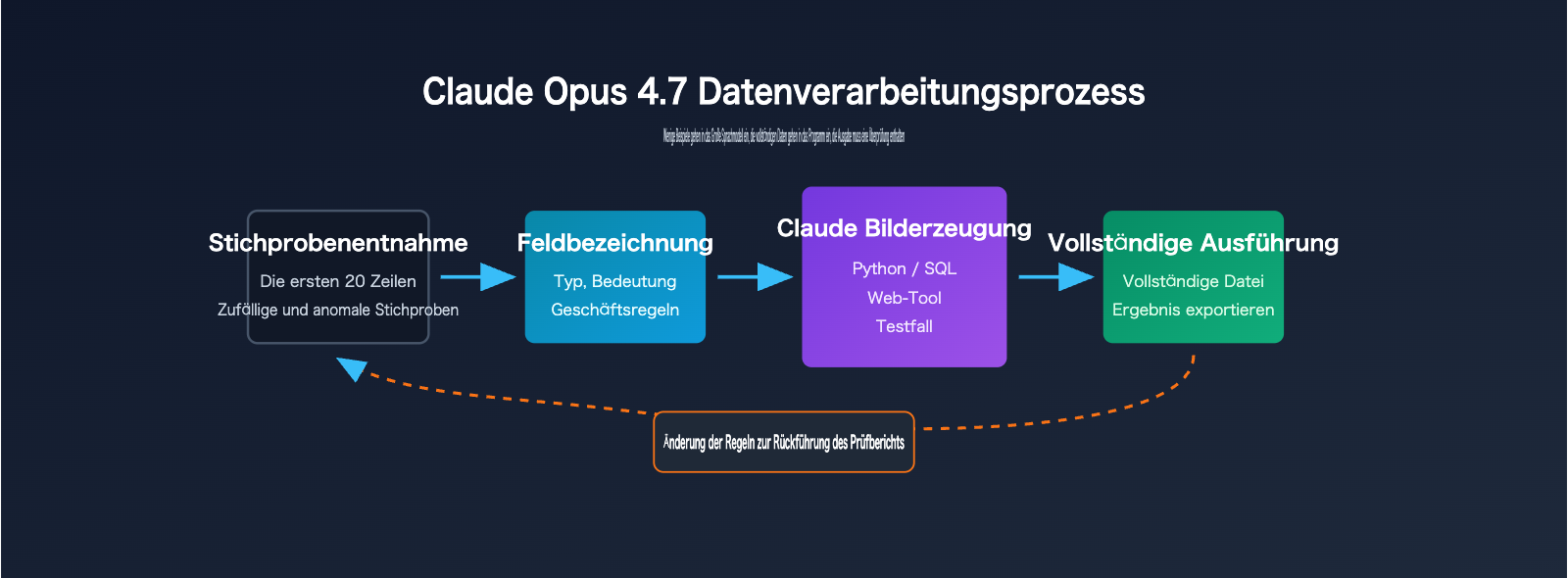
Anmerkung des Autors: Ich teile hier meine Praxiserfahrungen mit Claude Opus 4.7 bei der Verarbeitung von CSV- und Excel-Dateien. Ich erkläre, warum man große Tabellen nicht einfach ungefiltert an eine KI übergeben sollte, sondern die KI stattdessen Skripte schreiben, Tools bauen und Validierungen durchführen lassen sollte.
Wenn Sie eine CSV- oder Excel-Datei mit über 900 Zeilen und 50 Spalten haben und Claude Opus 4.7 einfach fragen: „Verarbeite diese Tabelle für mich“, erhalten Sie höchstwahrscheinlich eine Antwort, die zwar klug klingt, aber nicht reproduzierbar ist. Das Problem liegt nicht an der Leistungsfähigkeit von Claude Opus 4.7, sondern daran, dass Sie es als menschlichen Tabellenleser behandeln, anstatt als Designer für Datenverarbeitungsprozesse.
Der bessere Ansatz: Geben Sie Claude Opus 4.7 einen kleinen Datenausschnitt, eine vollständige Feldbeschreibung und das gewünschte Zielergebnis. Lassen Sie die KI Python-Skripte schreiben, Web-Tools generieren oder reproduzierbare Datenpipelines entwerfen, mit denen Sie dann den gesamten Datensatz verarbeiten. So nutzen Sie die Schlussfolgerungs- und Programmierfähigkeiten des Modells optimal aus, während Berechnungen, Filterungen, Aggregationen und Validierungen von deterministischen Programmen übernommen werden.

Kernpunkte bei der CSV-Verarbeitung mit Claude Opus 4.7
Claude Opus 4.7 ist bereits ein sehr leistungsfähiges Modell für Coding und agentische Workflows. Auch offiziell wird betont, dass es sich für komplexen Code, Unternehmens-Workflows und Tabellenkalkulationsszenarien eignet. Aber ein „größeres Kontextfenster“ bedeutet nicht, dass man die gesamte Tabelle in den Chat kopieren sollte – insbesondere dann nicht, wenn die Daten viele Duplikate, Ausreißer, versteckte Spalten, inkonsistente Formate oder komplexe Geschäftsregeln enthalten. Das manuelle Füttern von Rohdaten ist ineffizient und macht die Ergebnisse schwer nachvollziehbar.
Die wirklich effiziente Methode zur CSV-Verarbeitung mit Claude Opus 4.7 besteht darin, das Modell an drei Stellen einzusetzen: beim Verständnis der Geschäftsziele, beim Generieren von Verarbeitungsprogrammen und bei der Interpretation der Ergebnisse. Aufgaben wie zeilenweises Lesen, Typkonvertierung, Deduplizierung, Aggregation, Sortierung und Dateiexport sollten hingegen Python, SQL, browserbasierten Tools oder der integrierten Datenanalyse-Toolchain von Claude überlassen werden.
| Szenario | Probleme beim direkten Einlesen durch die KI | Empfohlene Vorgehensweise mit Claude Opus 4.7 | Ergebnisvorteile |
|---|---|---|---|
| 900 Zeilen × 50 Spalten CSV | Hoher Kontextverbrauch, Gefahr von Spalten-/Zeilenverlust | Geben Sie 20 Beispielzeilen und Felddefinitionen vor, lassen Sie Claude ein Pandas-Skript schreiben | Reproduzierbar, stapelverarbeitungsfähig |
| Excel mit mehreren Tabellenblättern | Versteckte Formeln, verbundene Zellen und Formatierungen erschweren das Verständnis | Lassen Sie Claude zuerst ein Skript zur Strukturprüfung schreiben, um eine Übersicht zu erhalten | Erst Struktur verstehen, dann verarbeiten |
| Filterung nach Geschäftsregeln | Natürliche Sprache führt oft zum Übersehen von Randbedingungen | Lassen Sie Claude die Regeln in Funktionen und Testfälle umwandeln | Klare, verifizierbare Regeln |
| Berichterstellung | Einmalige Antworten sind schwer zu überprüfen | Lassen Sie Claude ein Export-Skript und eine Validierungszusammenfassung erstellen | Stabiler Output, einfacher zu übergeben |
Hier ist eine wichtige Erkenntnis: Claude Opus 4.7 kann „an der Datenanalyse mitwirken“, sollte aber nicht die „einzige Ausführungsumgebung für die Daten selbst“ sein. Wenn Sie Ihre Eingabeaufforderungen (Prompts) oder Modellentscheidungen wiederholt über eine API validieren müssen, empfehlen wir die Nutzung des API-Proxy-Dienstes von APIYI (apiyi.com) für Tests mit kleinen Stichproben. Die stabilen Prompts können dann in Skripte integriert werden, anstatt jedes Mal die große Tabelle neu kopieren zu müssen.
Arbeitsteilungsprinzipien bei der CSV-Verarbeitung mit Claude Opus 4.7
Claude Opus 4.7 eignet sich am besten für Entscheidungen auf hoher Ebene, wie z. B. die Ableitung von Feldbedeutungen, das Design von Bereinigungsstrategien, die Identifizierung von Anomalien, die Codegenerierung und die Interpretation von Ergebnissen. Es ist nicht dafür geeignet, deterministische Berechnungen direkt im Chatfenster durchzuführen, da Tabellendaten im Chat oft ihre Struktur verlieren und eine wiederholte Ausführung oder Versionsverwaltung schwierig ist.
Ein bewährtes Prinzip lautet: „Kleine Stichproben an das Modell, große Datenmengen an das Programm.“ Sie können die ersten 20 Zeilen, 20 zufällige Zeilen und 20 Zeilen mit Anomalien bereitstellen, ergänzt durch ein Feldwörterbuch und das gewünschte Zielformat. Nachdem Claude Opus 4.7 basierend auf diesen Informationen ein Skript generiert hat, lassen Sie dieses Skript über die vollständige CSV- oder Excel-Datei laufen. So übernimmt das Modell das Design, während das Programm die Ausführung übernimmt.
Warum man Claude Opus 4.7 nicht einfach große Excel-Tabellen „füttern“ sollte
Excel und CSV sehen zwar wie Tabellen aus, ihre Komplexität unterscheidet sich jedoch grundlegend. CSV ist ein reines Textformat für Zeilen und Spalten, während Excel mehrere Tabellenblätter (Sheets), Formeln, Formatierungen, Filterzustände, ausgeblendete Spalten, verbundene Zellen, Datumsreihen und lokalisierte Zahlenformate enthalten kann. Wenn man Excel-Daten einfach als Text in eine KI kopiert, gehen diese entscheidenden Informationen meist verloren. Das Modell sieht dann keine strukturierte Arbeitsmappe mehr, sondern nur noch einen zerstörten, flachen Text.
Offizielle englischsprachige Dokumentationen zeigen, dass Claude-Produkte bereits Analyse-Tools, Code-Ausführung, Data-Plugins und Excel-Funktionen unterstützen. Dies unterstreicht eine Tatsache: Die Tabellenverarbeitung sollte in einer kontrollierten Tool-Umgebung stattfinden und nicht durch „Kopfrechnen“ des Sprachmodells im Chat-Fenster. Selbst wenn Claude Opus 4.7 ein größeres Kontextfenster unterstützt, sollte dieser Speicherplatz für Geschäftsregeln, Felddefinitionen, Beispiele und Validierungsanforderungen genutzt werden – nicht für die rohen Daten einer riesigen Tabelle.
| Datenmerkmal | Risiko beim direkten Hochladen | Empfohlene Eingabe für Claude Opus 4.7 | Empfohlenes Tool |
|---|---|---|---|
| Viele Spalten | Modell vergisst Bedeutung der Spalten | Feldwörterbuch, Spaltentypen, Erläuterungen | pandas, SQL |
| Viele Zeilen | Hohe Token-Kosten, nicht reproduzierbar | Kopfzeilen-Stichproben, Zufallsstichproben | Python (Batch-Verarbeitung) |
| Mehrere Sheets | Beziehungen gehen leicht verloren | Zusammenfassung der Struktur, Sheet-Zweck | openpyxl, Excel-Plugins |
| Unsaubere Daten | Ausreißer verfälschen Ergebnisse | Statistik zu fehlenden Werten, Duplikate | Datenqualitäts-Skripte |
| Komplexe Regeln | Natürliche Sprache führt zu Fehlern | Klare Regeln, Gegenbeispiele, Ziel-Output | Unit-Tests, Validierung |
Technischer Hinweis: Wenn Sie Claude Opus 4.7 in bestehende Datenverarbeitungssysteme integrieren möchten, empfiehlt sich eine Validierung auf Schnittstellenebene über den API-Proxy-Dienst APIYI (apiyi.com). Testen Sie Eingabeaufforderungen, Modellparameter und Fehlerbehandlung zunächst mit kleinen Stichproben, bevor Sie die vollständige Dateiverarbeitung anbinden.
Wichtige Irrtümer bei der Excel-Verarbeitung mit Claude Opus 4.7
Der erste Irrtum besteht darin, „das Modell kann Tabellen verstehen“ mit „das Modell sollte große Tabellen direkt verarbeiten“ gleichzusetzen. Bei kleinen Dateien oder explorativen Fragen ist das Hochladen von CSV oder Excel praktisch. Bei Aufgaben wie Massenbereinigung, Kundenbewertungen, Auftragsabgleich oder Finanzkategorisierung benötigen Sie jedoch reproduzierbare Regeln und keine einmaligen Antworten in natürlicher Sprache.
Der zweite Irrtum ist die Beschränkung auf die ersten 20 Zeilen. Diese zeigen meist nur die normale Struktur, decken aber keine Ausnahmefälle ab. Eine bessere Kombination ist: „Erste 20 Zeilen + 20 zufällige Zeilen + 20 Ausnahmezeilen + Feldwörterbuch + 3 Ziel-Output-Beispiele“. Nur so kann Claude Opus 4.7 eine Logik entwickeln, die der realen Geschäftspraxis entspricht.
5-Schritte-Workflow für die CSV-Verarbeitung mit Claude Opus 4.7
Dieser Workflow eignet sich für die meisten CSV- und Excel-Automatisierungen, insbesondere bei Dateien mit mehr als 500 Zeilen, über 20 Spalten und Regeln, die häufig angepasst werden müssen. Sie müssen dem Modell nicht sofort die komplette Datei übergeben. Es reicht, Stichproben, Strukturen und Ziele zu definieren und das Modell dann Skripte, Tests und Output-Beschreibungen erstellen zu lassen.
| Schritt | Material für Claude Opus 4.7 | Erwarteter Output | Zu bestätigen durch den Nutzer |
|---|---|---|---|
| 1. Strukturanalyse | Dateiformat, Spaltennamen, Stichproben | Annahmen zu Datentypen, Bereinigungsplan | Korrektheit der Feldbedeutung |
| 2. Regeldefinition | Geschäftsziele, Filter, Gegenbeispiele | Regelwerk und Randbedingungen | Abdeckung von Ausnahmefällen |
| 3. Skriptgenerierung | Stichprobendaten, Ziel-Format | Python- oder SQL-Skript | Lokale Ausführbarkeit |
| 4. Validierung | 20 bis 60 Stichproben | Erwarteter Output und Tests | Plausibilität der Ergebnisse |
| 5. Ausführung | Pfad zur vollständigen Datei | Ergebnisdatei, Logs, Prüfbericht | Korrektheit von Summen, Beträgen |
Der Kern dieses Workflows ist die Umwandlung einer „einmaligen Frage“ in ein „ausführbares Asset“. Wenn sich Geschäftsregeln ändern, müssen Sie nur das Skript und die Tests durch Claude Opus 4.7 anpassen lassen, anstatt die gesamten Daten neu hochzuladen oder das Modell erneut mit Kontext zu überladen.
Prompt-Vorlage für die CSV-Verarbeitung mit Claude Opus 4.7
Sie können die folgende Struktur direkt verwenden. Achten Sie darauf, nicht nur den CSV-Inhalt zu kopieren, sondern auch Feldbedeutungen, Ziele, Ausnahmebeispiele und Abnahmekriterien zu definieren.
Ich habe eine CSV/Excel-Verarbeitungsaufgabe. Bitte gib nicht direkt das Ergebnis aus.
Ziel:
Kundenliste nach Branche, Position und Unternehmensgröße bewerten und Top-Leads ausgeben.
Datenstichproben:
1. Erste 20 Zeilen: ...
2. 20 zufällige Zeilen: ...
3. 20 Ausnahmezeilen: ...
Felddefinitionen:
- company_name: Firmenname
- title: Position des Kontakts
- employee_count: Mitarbeiterzahl, kann leer sein
- industry: Branche, kann Synonyme enthalten
Bitte erledige Folgendes:
1. Erkläre die Felder und potenzielle Datenqualitätsprobleme.
2. Schreibe ein Python-Skript zum Einlesen von input.csv.
3. Erstelle cleaned.csv und scored.csv.
4. Füge grundlegende Validierungen hinzu: Zeilenanzahl, Leerwerte, Duplikate, Score-Verteilung.
5. Nimm keine Annahmen bei unbekannten Feldern vor; markiere unsichere Regeln als TODO.
Wenn Sie diesen Prozess als API-Dienst aufbauen möchten, können Sie die Prompt-Vorlage, das Feldwörterbuch und die Stichproben als feste Eingaben über den API-Proxy-Dienst APIYI (apiyi.com) an Claude Opus 4.7 senden, um verschiedene Modelle auf ihre Leistung bei der Code-Generierung und Regelinterpretation zu testen.
Python-Beispiel für die CSV-Verarbeitung mit Claude Opus 4.7
Dies ist eine minimalistische Version, die den richtigen Ansatz verdeutlicht: Claude Opus 4.7 schreibt das Skript, das Skript liest die vollständige Datei und gibt Ergebnisse sowie einen Validierungsbericht aus.
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Fehlende Spalten: {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
# Beispiel-Regeln für das Scoring
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"rows": len(df), "duplicates": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
Für automatisierte Workflows empfiehlt es sich, die Modellaufrufe, Fehlerbehandlung und Protokollierung zentral über den API-Proxy-Dienst APIYI (apiyi.com) zu verwalten, um die Wartbarkeit der Datenverarbeitungskette zu gewährleisten.
Werkzeugauswahl für die Excel-Verarbeitung mit Claude Opus 4.7
Für unterschiedliche Aufgaben sollten unterschiedliche Werkzeuge gewählt werden. Für explorative Analysen eignen sich die Analysefunktionen von Claude oder Daten-Plugins, während für Produktionsabläufe Python-Skripte, SQL-Pipelines oder Web-Tools besser geeignet sind. Wenn es im Team Kollegen ohne technisches Hintergrundwissen gibt, können Sie Claude Opus 4.7 anweisen, ein lokales Web-Tool zu erstellen, das Uploads, Regelkonfigurationen und den Download von Ergebnissen über eine visuelle Oberfläche ermöglicht.
| Werkzeug-Ansatz | Geeignet für | Nicht geeignet für | Empfohlene Nutzung |
|---|---|---|---|
| Python-Skript | Batch-Bereinigung, Scoring, Abgleich, Export | Teams ohne Kommandozeilen-Erfahrung | Claude Skripte und README schreiben lassen |
| Lokales Web-Tool | Wiederkehrende Aufgaben für Nicht-Techniker | Komplexe Backend-Rechte & Zusammenarbeit | Claude HTML/JS oder leichtgewichtige Dienste erstellen lassen |
| SQL-Pipeline | Data Warehouses, Bestellungen, Log-Analyse | Temporäre kleine Excel-Tabellen | Claude Abfrage- und Validierungs-SQL schreiben lassen |
| Claude Daten-Tools | Explorative Analysen, Diagramme, Berichte | Strenge Compliance oder Langzeit-Automatisierung | Erst explorieren, dann in Skripte überführen |
| API-Workflow | Modellvergleich, Systemintegration | Einmalige manuelle Aufgaben | Über einheitliche Schnittstellen debuggen |

Konzept für ein Web-Tool zur Excel-Verarbeitung mit Claude Opus 4.7
Wenn Anwender kein Python beherrschen, ist es oft praktischer, Claude ein Web-Tool erstellen zu lassen, anstatt es direkt CSV-Dateien lesen zu lassen. Ein Web-Tool kann Upload-Buttons, Feldzuordnungen, Regelkonfigurationen, eine Ergebnisvorschau und Download-Buttons bereitstellen. Der Anwender muss dann nur noch die Datei austauschen, ohne jedes Mal erneut mit der KI kommunizieren zu müssen.
Sie können Claude Opus 4.7 wie folgt anweisen: Erstelle ein HTML-Tool als Einzeldatei, das Papa Parse zum Lesen von CSV-Dateien verwendet, im Frontend die Feldzuordnung und das Scoring übernimmt und schließlich eine neue CSV-Datei exportiert. Für Aufgaben mit geringem Datenvolumen, nicht vertraulichen Regeln und lokaler Ausführung im Browser ist dieser Ansatz sehr wirtschaftlich. Bei komplexeren Berechtigungen, Audit-Anforderungen oder großen Dateien sollte jedoch auf einen Backend-Dienst umgestiegen werden.
Empfehlung für die Umsetzung: Wenn Sie das Web-Tool mit Modellinterpretation, Vorschlägen zur Feldzuordnung oder Fehlerdiagnose erweitern möchten, können Sie über APIYI (apiyi.com) Modell-Schnittstellen aufrufen. Das Frontend kümmert sich dann nur um die Interaktion, während das Backend die Modellanfragen und das Logging übernimmt.
Checkliste für die CSV-Verarbeitung mit Claude Opus 4.7
Das größte Risiko bei der Datenverarbeitung ist nicht, dass der Code abstürzt, sondern dass er im Stillen fehlerhafte Ergebnisse liefert. Daher sollten Sie bei jedem Auftrag an Claude Opus 4.7 – egal ob Python, SQL oder Web-Tool – verlangen, dass eine begleitende Checkliste erstellt wird. Diese muss nicht komplex sein, sollte aber Zeilenanzahl, Felder, Nullwerte, Duplikate, Schlüsselkennzahlen und stichprobenartige Überprüfungen abdecken.
| Prüfpunkt | Warum wichtig? | Empfohlene Prüfmethode | Empfehlung bei Abweichungen |
|---|---|---|---|
| Zeilenanzahl (Ein/Aus) | Verhindert Löschungen/Duplikate | Vergleich len(input) und len(output) |
Dokumentation der Differenz |
| Erforderliche Felder | Verhindert Fehlberechnungen | Prüfung der Spaltenmenge | Abbruch bei fehlenden Feldern |
| Anteil Nullwerte | Verhindert Scoring-Verzerrungen | Statistik pro Spalte | Warnung bei Überschreitung des Schwellenwerts |
| Doppelte Datensätze | Verhindert doppelte Abrechnung | Deduplizierung über Primärschlüssel | Bericht über Duplikate erstellen |
| Summen (Betrag/Menge) | Verhindert Logikfehler | Vergleich vor/nach Aggregation | Abbruch bei Inkonsistenz |
| Stichprobenprüfung | Erkennt Fehlinterpretationen | Manuelle Prüfung von 20 Zeilen | Feedback an Claude zur Regelanpassung |
In der Praxis können Sie diese Tabelle direkt als Teil Ihrer Eingabeaufforderung verwenden, damit Claude Opus 4.7 automatisch die entsprechenden Prüfungen in das Skript integriert. Wenn wir bei APIYI (apiyi.com) Modellaufrufe testen, empfehlen wir ebenfalls, die Validierungsausgabe als feste Anforderung zu definieren. So lässt sich die Stabilität verschiedener Modelle besser vergleichen, anstatt nur zu bewerten, ob eine einzelne Antwort "schön" aussieht.
Negativbeispiel für Eingabeaufforderungen bei der CSV-Verarbeitung
Sagen Sie nicht einfach: "Hilf mir, diese Tabelle zu bereinigen." Besser ist: "Bitte nenne mir zuerst, welche Feldinformationen du benötigst, bevor du das Skript schreibst; gib nicht direkt das Endergebnis aus; gib jeden Schritt im Log aus; markiere unklare Regeln mit TODO; erstelle 5 Unit-Test-Beispiele." Solche Einschränkungen zwingen das Modell dazu, implizite Annahmen explizit zu machen, und helfen Ihnen, Fehlinterpretationen der Geschäftslogik schneller zu erkennen.
Betrachten Sie zudem die ersten 20 Zeilen nicht als vollständige Wahrheit. Diese eignen sich zwar, um die Struktur zu verstehen, decken aber keine "schmutzigen" Daten ab. Sie sollten zusätzlich Ausnahmeszenarien bereitstellen, wie z. B. Nullwerte, Duplikate, inkonsistente Datumsformate, negative Beträge, unterschiedliche Schreibweisen bei Aufzählungswerten oder gemischte chinesische und englische Zeichen.
FAQ zur CSV-Verarbeitung mit Claude Opus 4.7
Reichen die ersten 20 Zeilen als Stichprobe für die CSV-Verarbeitung mit Claude Opus 4.7 aus?
Nicht ganz, aber es ist ein guter Anfang. Die ersten 20 Zeilen eignen sich gut, um die Feldstruktur und normale Datensätze zu zeigen, decken jedoch keine anomalen Daten ab. Empfehlenswerter ist eine Kombination aus „den ersten 20 Zeilen + 20 zufälligen Zeilen + 20 anomalen Zeilen“. Nachdem Sie die Stichprobe an Claude Opus 4.7 übergeben haben, sollten Sie das Modell anweisen, ein Skript für die Verarbeitung der vollständigen Datei zu schreiben, anstatt sich nur auf Basis der Stichprobe auf eine Schlussfolgerung zu verlassen.
Sollte ich die gesamte Datei hochladen, wenn Claude Opus 4.7 Excel-Dateien verarbeitet?
Für eine explorative Analyse können Sie die Datei hochladen und die Analyse-Tools nutzen. Für langfristig wiederverwendbare Geschäftsprozesse sollten Sie Claude Opus 4.7 jedoch zunächst ein Skript zur Strukturerkennung schreiben lassen und anschließend ein Skript zur Datenverarbeitung generieren. Für API-Automatisierungsszenarien können Sie über APIYI (apiyi.com) zunächst kleine Stichproben testen, um sicherzustellen, dass das Modell die Felder und Regeln stabil versteht, bevor Sie den gesamten Prozess integrieren.
Brauche ich bei Claude Opus 4.7 wegen des 1-Million-Kontextfensters keine Skripte mehr für CSV-Dateien?
Nein. Ein größeres Kontextfenster kann zwar mehr Feldbeschreibungen, Stichproben und Geschäftshintergründe aufnehmen, ersetzt jedoch kein reproduzierbares Berechnungsprogramm. Besonders bei Berechnungen von Beträgen, Rankings, Gruppierungen, Deduplizierungen und statistischen Definitionen sind Skripte und Validierungen die Grundlage für verlässliche Ergebnisse.
Was unterscheidet die Excel-Verarbeitung mit Claude Opus 4.7 von klassischem BI?
Claude Opus 4.7 eignet sich besser dazu, vage Anforderungen in Regeln, Code und Erklärungen umzuwandeln. Klassische BI-Tools sind hingegen besser für stabile Berichte, Berechtigungsmanagement, Datenmodellierung und Zusammenarbeit im Team geeignet. Beide Ansätze schließen sich nicht aus: Sie können Claude nutzen, um Bereinigungsskripte und Analyselogiken zu erstellen und die stabilen Ergebnisse anschließend in BI-Systeme oder Data Warehouses einzuspeisen.
Lohnt sich die CSV-Verarbeitung mit Claude Opus 4.7 auch ohne Programmierkenntnisse?
Ja, aber es empfiehlt sich, das Modell lokale Web-Tools oder detaillierte Bedienungsanleitungen erstellen zu lassen, anstatt sich das Endergebnis direkt im Chat ausgeben zu lassen. Sie können Claude anweisen, die Verarbeitungslogik in Form von Schaltflächen, Formularen und Download-Funktionen bereitzustellen, sodass Sie nur noch die Datei hochladen und das Ergebnis prüfen müssen. Wenn Sie Modell-Schnittstellen benötigen, können Sie APIYI (apiyi.com) nutzen, um die Code-Generierung verschiedener Modelle schnell zu testen.
Worauf sollte ich bei der Verarbeitung sensibler Excel-Dateien mit Claude Opus 4.7 achten?
Sensible Daten sollten vorab anonymisiert oder in einer kontrollierten Umgebung verarbeitet werden. Senden Sie keine Ausweisnummern, Telefonnummern, Kundenverträge oder Finanzdetails im Originalzustand an ungesicherte Umgebungen. Der sicherere Weg ist die Bereitstellung anonymisierter Stichproben und der Feldstruktur, damit Claude ein Skript schreibt, das Sie dann lokal oder in Ihrer Unternehmensumgebung auf den vollständigen Datensatz anwenden.
Wichtige Erkenntnisse zur CSV-Verarbeitung mit Claude Opus 4.7
- Die beste Methode für die CSV-Verarbeitung mit Claude Opus 4.7 besteht nicht darin, die gesamte Tabelle direkt einzulesen, sondern auf Basis von Stichproben und Regeln ein ausführbares Skript zu generieren.
- Die ersten 20 Zeilen helfen dem Modell nur beim Verständnis der Struktur; für echte Aufgaben sind zudem zufällige Stichproben, anomale Daten und ein Feld-Wörterbuch erforderlich.
- Excel ist komplexer als CSV; mehrere Tabellenblätter, Formeln, ausgeblendete Spalten und Formatierungen können das Ergebnis beeinflussen. Führen Sie daher zuerst eine Strukturerkennung durch.
- Für Batch-Aufgaben sind Python, SQL oder lokale Web-Tools reproduzierbarer als eine einmalige Antwort im Chat-Fenster.
- Eine Checkliste zur Validierung muss zusammen mit dem Verarbeitungsskript erstellt werden, wobei der Fokus auf Zeilenanzahl, Feldern, Leerwerten, Duplikaten und wichtigen Summen liegen sollte.
- Für API-Automatisierungsszenarien empfiehlt es sich, erst kleine Stichproben-Tests mit dem Modell durchzuführen, bevor die stabile Lösung in die Produktionskette integriert wird.
Zusammenfassung und Empfehlungen für die Arbeit mit Claude Opus 4.7 und Excel
Claude Opus 4.7 eignet sich hervorragend für Datenaufgaben. Der effizienteste Ansatz besteht jedoch nicht darin, dem KI-Modell einfach die gesamte Tabelle „vorzuwerfen“, sondern es als Werkzeugentwickler einzusetzen, der die Verarbeitung übernimmt. Sobald Datenmengen in den Bereich von Hunderten von Zeilen und Dutzenden von Spalten wachsen oder Geschäftsregeln wiederholt angewendet werden müssen, sind Skripte, Web-Tools, SQL-Pipelines und Validierungsberichte die wirtschaftlichere Wahl.
Betrachten Sie Claude Opus 4.7 als Ihren Data-Engineering-Assistenten: Lassen Sie das Modell kleine Stichproben analysieren, klären Sie die Geschäftsregeln, generieren Sie Verarbeitungsskripte, erstellen Sie Tests und lassen Sie sich die Ergebnisse erläutern. Auf diese Weise nutzen Sie die Stärken des Großen Sprachmodells beim Verständnis semantischer Zusammenhänge, während Sie gleichzeitig die Ineffizienz und mangelnde Nachvollziehbarkeit vermeiden, die durch das direkte Einspeisen von Rohdaten entstehen.
Wenn Sie an Entwicklungen rund um Claude Opus 4.7, CSV, Excel oder Datenautomatisierung arbeiten, empfiehlt es sich, für den Modellaufruf und die Validierung der Eingabeaufforderung zunächst APIYI (apiyi.com) zu nutzen. Sobald der Prozess stabil ist, können Sie ihn in Form von Skripten oder Tools festigen. Dies sorgt für besser kontrollierbare Kosten und macht die Ergebnisse für Ihr Team leichter überprüfbar und langfristig wartbar.
Referenzmaterialien:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Claude Opus 4.7 Benutzerhandbuch: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Claude Code Execution Tool: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Claude Data Plugin: claude.com/plugins/data