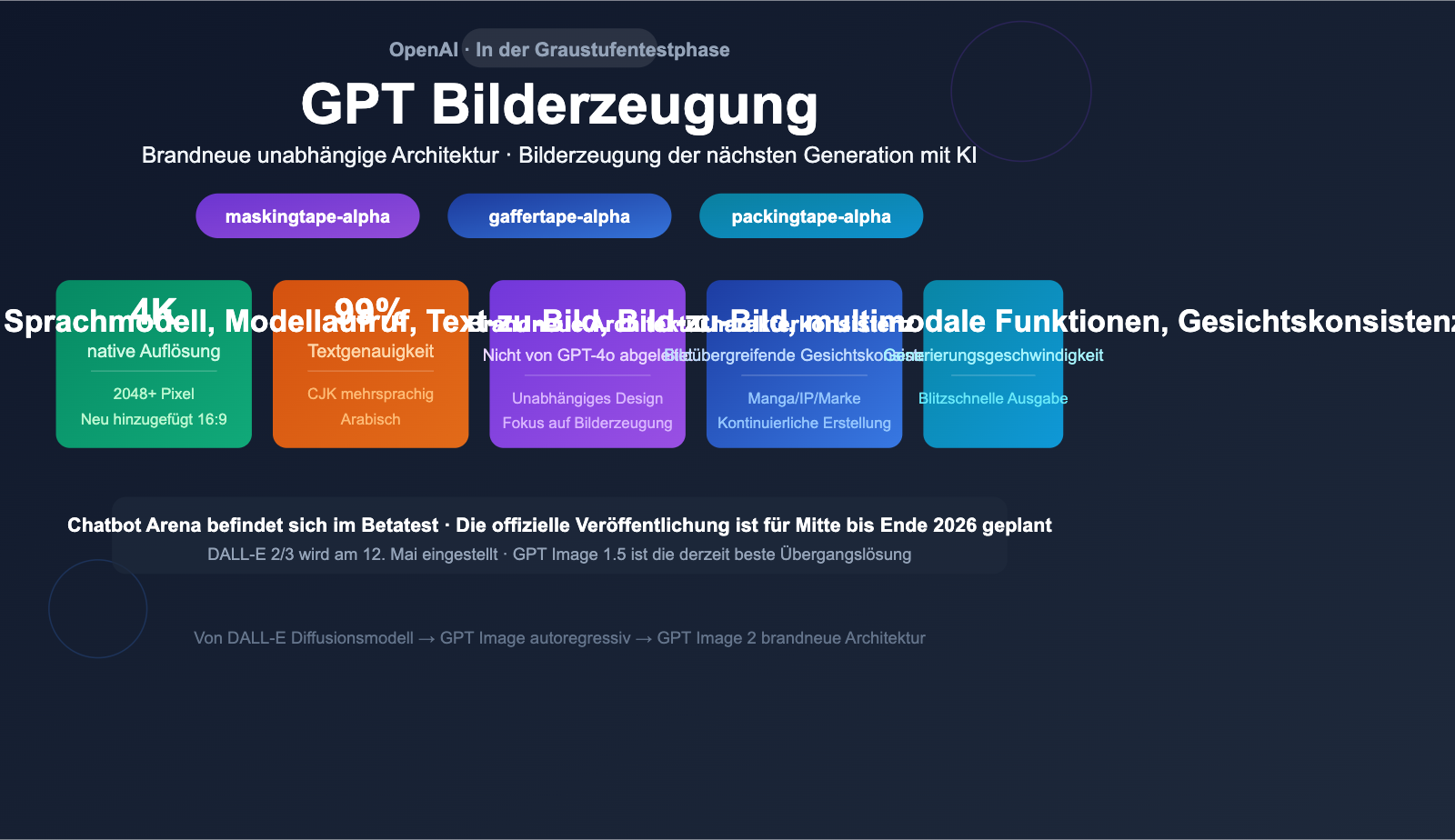
Das nächste Bilderzeugungsmodell von OpenAI, GPT Image 2, befindet sich derzeit in der Graustufen-Testphase. Drei Codenamen-Modelle (maskingtape/gaffertape/packingtape) sind bereits in anonymen Bewertungen im Chatbot Arena aufgetaucht. Obwohl eine offizielle Veröffentlichung noch aussteht, deuten geleakte Informationen darauf hin, dass GPT Image 2 auf einer völlig neuen, eigenständigen Architektur basiert. Es wird erwartet, dass es bei der Textwiedergabe, der Auflösung, der Unterstützung mehrerer Sprachen sowie der Gesichtskonsistenz einen qualitativen Sprung machen wird.
Kernnutzen: Erfahren Sie in 3 Minuten alles über die neuesten Informationen zu GPT Image 2, die erwarteten Leistungssteigerungen und die vollständige Entwicklung der Bilderzeugungsproduktlinie von OpenAI, von DALL-E bis hin zu GPT Image.
GPT Image 2: Aktuelle Informationen im Überblick
GPT Image 2 befindet sich derzeit in der Beta-Phase und die API wurde noch nicht offiziell veröffentlicht. Die folgenden Informationen stammen aus Leaks der Arena-Benchmarks und verschiedenen Analysen; sie wurden von OpenAI nicht offiziell bestätigt.
| Informationspunkt | Details |
|---|---|
| Aktueller Status | In der Beta-Phase, noch nicht offiziell veröffentlicht |
| Arena-Codename | maskingtape-alpha / gaffertape-alpha / packingtape-alpha |
| Architektur | Komplett neue, eigenständige Architektur, keine Ableitung von GPT-4o |
| Erwartete Auflösung | Nativ 4K (2048×2048 oder 4096×4096) |
| Text-Rendering | Erwartete Genauigkeit >99 %, Unterstützung für CJK/Arabisch und andere nicht-lateinische Schriften |
| Generierungsgeschwindigkeit | Voraussichtlich unter 3 Sekunden |
| Voraussichtliche Veröffentlichung | Mitte bis Ende 2026 |
Interpretation der 3 Beta-Codenamen
In den anonymen Arena-Benchmarks von Chatbot sind drei bisher unbekannte Codenamen für Bildmodelle aufgetaucht:
| Codename | Analyse |
|---|---|
| maskingtape-alpha | „Abklebeband“ – deutet möglicherweise auf verbesserte Funktionen zur lokalen Bearbeitung/Maskierung hin |
| gaffertape-alpha | „Gewebeband“ – könnte einer professionellen/High-End-Variante entsprechen |
| packingtape-alpha | „Paketband“ – könnte für eine Variante für Stapelverarbeitung stehen |
Alle drei Codenamen basieren auf dem Thema „Tape“ (Klebeband), wobei das Suffix „alpha“ auf ein frühes Teststadium hinweist. Einige ChatGPT-Nutzer haben das neue Modell bereits zufällig während der Nutzung ausgelöst.
🎯 Technischer Hinweis: Sobald GPT Image 2 offiziell veröffentlicht wird, können Entwickler über die APIYI-Plattform (apiyi.com) darauf zugreifen. Die Plattform unterstützt bereits die gesamte GPT Image 1.5-Modellreihe und wird neue Modelle nach deren Veröffentlichung schnell integrieren.
Die vollständige Evolution der GPT Image-Produktlinie
Um die Positionierung von GPT Image 2 zu verstehen, muss man die Entwicklung der Bildgenerierungs-Produktlinie von OpenAI betrachten.

Zeitstrahl der Produktlinie
| Modell | Veröffentlichung | Architektur | Kernmerkmale |
|---|---|---|---|
| DALL-E 2 | 2022 | Diffusionsmodell | Wegweisende KI-Bilderzeugung |
| DALL-E 3 | Okt. 2023 | Diffusionsmodell | Deutlich verbessertes Verständnis von Eingabeaufforderungen |
| GPT Image 1 | März/April 2025 | Autoregressiv (nativ GPT-4o) | Revolutionäres Text-Rendering, Bildbearbeitung |
| GPT Image 1 Mini | Okt. 2025 | Autoregressiv (leicht) | 80 % Kostensenkung |
| GPT Image 1.5 | Dez. 2025 | Autoregressiv (optimiert) | 4-fache Geschwindigkeit, Korrektur von Farbstichen |
| GPT Image 2 | 2026 (erwartet) | Neue eigenständige Architektur | 4K/Mehrsprachiger Text/Gesichtskonsistenz |
Architekturwandel: Von den Diffusionsmodellen bei DALL-E über die autoregressiven Modelle bei GPT Image 1 bis hin zur neuen eigenständigen Architektur von GPT Image 2 hat OpenAI bei jeder Generation grundlegende architektonische Veränderungen vorgenommen.
Countdown zur Einstellung der DALL-E-Serie
OpenAI hat angekündigt, dass der Dienst für DALL-E 2 und DALL-E 3 am 12. Mai 2026 eingestellt wird. Das bedeutet, dass alle Anwendungen, die auf der DALL-E-API basieren, bis zu diesem Datum auf die GPT Image-Serie migriert werden müssen.
Die 5 erwarteten Kernfähigkeiten des GPT Image 2 Upgrades
Basierend auf Leaks aus Arena-Tests und verschiedenen Analysen wird für GPT Image 2 ein bedeutender Sprung in den folgenden fünf Bereichen erwartet.
Upgrade 1: Native 4K-Auflösung
Die maximale Auflösung von GPT Image 1.5 liegt bei 1536×1024. GPT Image 2 wird voraussichtlich eine native 4K-Ausgabe (2048×2048 oder 4096×4096) sowie ein 16:9-Breitbildformat unterstützen, um professionellen Anforderungen in der Content-Erstellung und im kommerziellen Druck gerecht zu werden.
| Dimension | GPT Image 1.5 | GPT Image 2 (erwartet) |
|---|---|---|
| Max. Auflösung | 1536×1024 | Nativ 4K |
| Seitenverhältnis | 1:1, 3:2, 2:3 | Neu: 16:9 Breitbild |
| Ausgabequalität | Hoch | Nahezu fotorealistisch |
Upgrade 2: Über 99 % Präzision bei der Textdarstellung
Die Textdarstellung ist das Markenzeichen der GPT Image-Serie. GPT Image 1.5 erreicht bereits eine Genauigkeit von etwa 95 % bei englischem Text, weist jedoch bei CJK- (Chinesisch, Japanisch, Koreanisch) und arabischen Schriftzeichen noch Schwächen auf. GPT Image 2 soll die Präzision auf über 99 % steigern und eine umfassende Unterstützung für mehrsprachige Texte bieten.
Dieses Upgrade ist besonders für chinesischsprachige Nutzer wichtig – es bedeutet, dass die Generierung von Bildern mit korrektem chinesischem Text erstmals zuverlässig wird.
Upgrade 3: Gesichtskonsistenz
Aktuell hat GPT Image 1.5 Schwierigkeiten, das Aussehen von Charakteren über mehrere Generierungen hinweg konsistent zu halten. GPT Image 2 soll eine bildübergreifende Gesichtskonsistenz unterstützen, was Szenarien wie fortlaufende Illustrationen, Comicserien oder Markencharaktere endlich praxistauglich macht.
Upgrade 4: Regionale Steuerung
Die Komposition bei GPT Image 1.5 hängt vollständig von der Eingabeaufforderung ab. GPT Image 2 könnte eine bereichsbasierte Eingabeaufforderung (Region-based Prompting) einführen, die es Nutzern ermöglicht, Inhalte für verschiedene Bildbereiche festzulegen und so eine präzisere Kontrolle über die Komposition zu erhalten.
Upgrade 5: Generierungsgeschwindigkeit unter 3 Sekunden
Im Vergleich zur ersten Generation konnte GPT Image 1.5 die Geschwindigkeit bereits vervierfachen. Dank einer völlig neuen Architektur wird GPT Image 2 voraussichtlich hochwertige Bilder in unter 3 Sekunden generieren und damit den kreativen Prozess weiter beschleunigen.
Zusammenfassender Vergleich der 5 Upgrades
| Fähigkeit | GPT Image 1.5 (aktuell) | GPT Image 2 (erwartet) | Steigerung |
|---|---|---|---|
| Max. Auflösung | 1536×1024 | Nativ 4K (2048+) | 2-4x |
| Englische Textgenauigkeit | ~95 % | 99 %+ | +4 Pkt |
| CJK Textgenauigkeit | Mäßig | Erwartet gut | Quantensprung |
| Gesichtskonsistenz | Nicht unterstützt | Bildübergreifend | Neue Funktion |
| Kompositionskontrolle | Nur Text-Prompt | Bereichs-Prompt | Neue Funktion |
| Generierungszeit | ~5-10 Sek. | <3 Sek. | 2-3x |
| Seitenverhältnis | 3 Typen | Neu: 16:9 | Vielfältiger |
💡 Empfehlung: Falls Sie derzeit DALL-E 3 oder GPT Image 1 nutzen, sollten Sie zeitnah auf GPT Image 1.5 umsteigen. Die DALL-E-Serie wird zum 12. Mai eingestellt, während GPT Image 1.5 bei Qualität und Geschwindigkeit deutlich überlegen ist. Über die Plattform APIYI (apiyi.com) können Sie nahtlos zwischen den Versionen wechseln.
Aktuelle API-Preisgestaltung für GPT Image 1.5 (Vergleichsreferenz)
Während wir auf die offizielle Veröffentlichung von GPT Image 2 warten, hilft ein Blick auf die aktuelle Preisgestaltung von GPT Image 1.5, um zukünftige Trends einzuschätzen.
Abrechnung pro Bild
| Qualität | 1024×1024 | 1024×1536 / 1536×1024 |
|---|---|---|
| Niedrig | $0,009 | $0,013 |
| Mittel | $0,034 | $0,050 |
| Hoch | $0,133 | $0,200 |
Abrechnung pro Token
| Token-Typ | Preis |
|---|---|
| Bildeingabe | $8,00/M Token |
| Bildeingabe (Cache) | $2,00/M Token |
| Bildausgabe | $32,00/M Token |
| Texteingabe | $5,00/M Token |
| Textausgabe | $10,00/M Token |
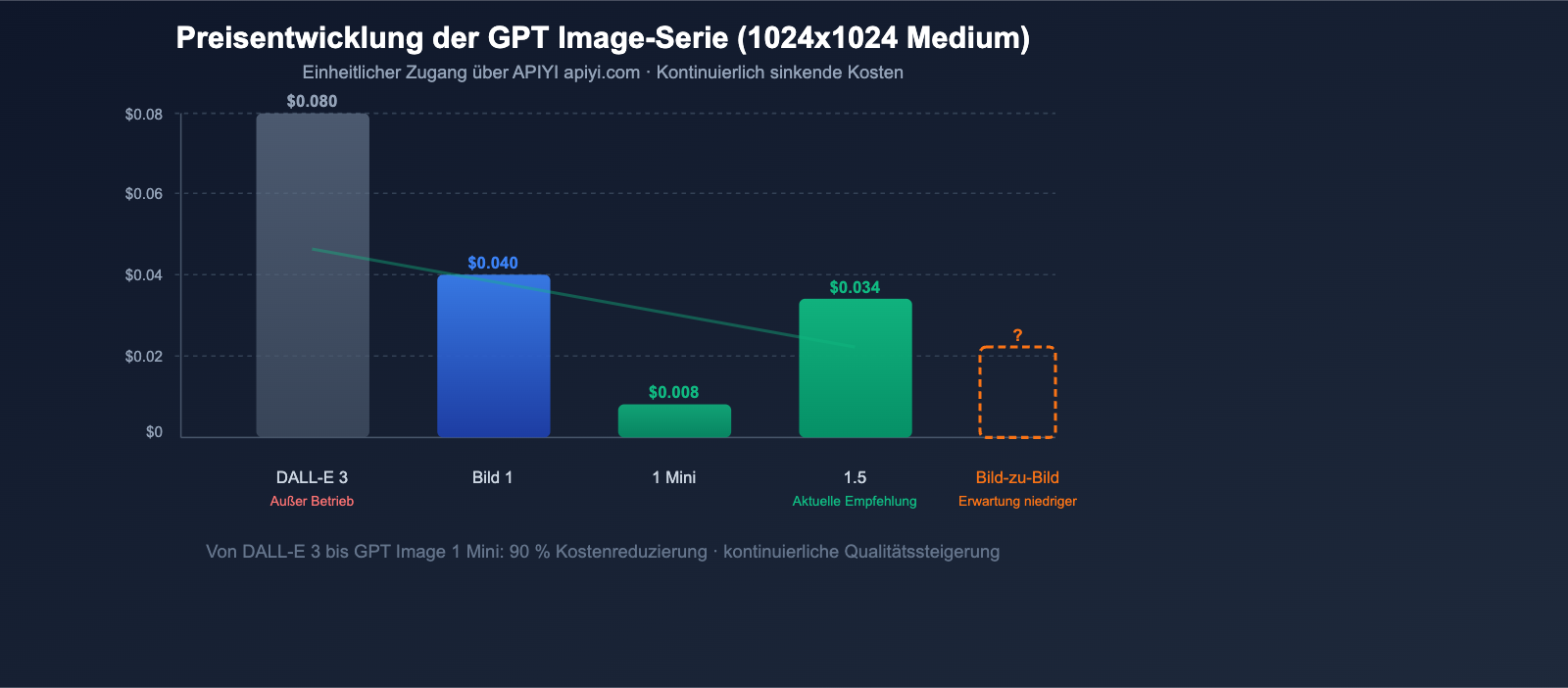
Analyse der Preistrends
Von DALL-E 3 bis GPT Image 1.5 sind die Kosten für die Bilderzeugung bei OpenAI kontinuierlich gesunken:
| Modell | 1024×1024 (Standard) | Relative Kosten |
|---|---|---|
| DALL-E 3 | $0,040-$0,080 | Basiswert |
| GPT Image 1 | ~$0,040 (Mittel) | Gleichbleibend, Qualität stark verbessert |
| GPT Image 1 Mini | ~$0,008 | 80 % günstiger |
| GPT Image 1.5 | $0,034 (Mittel) | Preis gesunken + 4x Geschwindigkeit |
Es wird erwartet, dass GPT Image 2 diesen Trend fortsetzt und möglicherweise eine neue "Turbo"-Preisstufe einführt.
💰 Kostenoptimierung: Die Qualität "Niedrig" von GPT Image 1.5 kostet aktuell nur $0,009 pro Bild, was die Kosten für Massengenerierungen extrem niedrig hält. Über die Plattform APIYI (apiyi.com) können Sie die Aufrufstrategien für verschiedene Qualitätsstufen flexibel verwalten.
Schnellstart-Anleitung für die GPT Image API
Während wir auf GPT Image 2 warten, können Entwickler bereits GPT Image 1.5 für ihre Anwendungen nutzen. Die API-Schnittstelle ist vollständig kompatibel; für den späteren Umstieg auf GPT Image 2 muss lediglich der Modellname angepasst werden.
Beispiel für einen Text-zu-Bild-Aufruf
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Über die einheitliche APIYI-Schnittstelle
)
# Bild generieren
result = client.images.generate(
model="gpt-image-1.5",
prompt="Ein Shiba Inu in einem Raumanzug steht auf der Mondoberfläche, im Hintergrund die blaue Erde, realistischer Stil",
size="1536x1024",
quality="high",
n=1,
)
# Bilddaten abrufen
image_base64 = result.data[0].b64_json
Beispiel für Bildbearbeitung (Inpainting)
# Lokale Bildbearbeitung
result = client.images.edit(
model="gpt-image-1.5",
image=open("original.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Ersetze den Hintergrund durch einen Strand bei Sonnenuntergang",
size="1024x1024",
)
Erläuterung der wichtigsten Parameter
| Parameter | Typ | Beschreibung | Optionale Werte |
|---|---|---|---|
model |
string | Modell-ID | gpt-image-1.5 / gpt-image-1 |
prompt |
string | Textbeschreibung | Beschreibung in natürlicher Sprache |
size |
string | Ausgabeformat | 1024x1024 / 1536x1024 / 1024x1536 / auto |
quality |
string | Qualitätsstufe | low / medium / high |
n |
int | Anzahl der Bilder | 1 (derzeit nur ein Bild unterstützt) |
output_format |
string | Ausgabeformat | png / jpeg / webp |
Alle GPT Image-Modelle enthalten C2PA-Metadaten, um KI-generierte Inhalte zu kennzeichnen, und unterstützen transparente Hintergründe (PNG-Alpha).
Tipps für das Text-Rendering mit GPT Image
Das Rendern von Text ist eine Kernstärke der GPT Image-Serie. Hier sind praktische Tipps zur Verbesserung der Genauigkeit:
| Tipp | Beschreibung | Beispiel |
|---|---|---|
| Text explizit zitieren | Den anzuzeigenden Text in Anführungszeichen setzen | "Im Bild steht 'Welcome Home'" |
| Schriftstil angeben | Visuelle Merkmale der Schrift beschreiben | "Fette serifenlose Schrift" |
| Position festlegen | Position des Textes im Bild beschreiben | "Titel oben zentriert anzeigen" |
| Textmenge begrenzen | Maximal 20 Zeichen pro Durchgang | Längere Texte in mehreren Schritten generieren |
| Englisch verwenden | Derzeit ist das englische Rendering am zuverlässigsten | GPT Image 2 wird mehrsprachige Unterstützung verbessern |
🚀 Schnellstart: Wir empfehlen die Nutzung der Plattform APIYI (apiyi.com) für den Zugriff auf die GPT Image API. Sie unterstützt OpenAI-kompatible Schnittstellen und wird direkt nach der Veröffentlichung von GPT Image 2 angepasst.
GPT Image 2 im Vergleich mit Wettbewerbern
Der Markt für KI-Bilderzeugung ist 2026 hart umkämpft. GPT Image 2 muss sich zahlreichen Herausforderungen stellen.
Vergleich gängiger Modelle zur Bilderzeugung
| Modell | Hersteller | Architektur | Text-Rendering | Max. Auflösung | Preismodell |
|---|---|---|---|---|---|
| GPT Image 2 (erwartet) | OpenAI | Neue, eigenständige Architektur | 99%+ | Nativ 4K | Token/Bild |
| GPT Image 1.5 | OpenAI | Autoregressiv | ~95% | 1536×1024 | Token/Bild |
| Imagen 3 | Diffusionsmodell | Gut | 1024×1024 | Token | |
| FLUX 1.1 Pro | Black Forest | Diffusionsmodell | Exzellent | 2048×2048 | Pro Bild |
| Ideogram 3.0 | Ideogram | Diffusionsmodell | Exzellent | 2048×2048 | Pro Bild |
| Midjourney V7 | Midjourney | Diffusionsmodell | In Verbesserung | 2048×2048 | Abonnement |
Die Kernvorteile der GPT Image-Serie liegen in der Präzision des Text-Renderings, dem Weltwissen (Kenntnis über das Aussehen spezifischer Objekte/Marken), der nativen Bildbearbeitung und der tiefen Integration in das ChatGPT-Ökosystem.
Erwartete Anwendungsbereiche für GPT Image 2
Die Kapazitätserweiterungen von GPT Image 2 werden zahlreiche bisher schwer umsetzbare Szenarien ermöglichen:
| Anwendungsbereich | Abhängigkeit | Aktuelle Machbarkeit | Erwartung GPT Image 2 |
|---|---|---|---|
| Chinesische Plakate/Banner | CJK-Text-Rendering | ❌ Hohe Fehlerrate | ✅ 99%+ Präzision |
| Fortlaufende Comics/Illustrationen | Gesichtskonsistenz | ❌ Jedes Mal anders | ✅ Konsistenz über Bilder hinweg |
| 4K-Werbedruck | Hohe Auflösung | ❌ Max. 1536px | ✅ Nativ 4K |
| Batch-Generierung von E-Commerce-Bildern | Geschwindigkeit + Qualität | ⚠️ Bedingt möglich | ✅ <3 Sek. + höhere Qualität |
| UI/UX-Designentwürfe | Präzises Layout | ⚠️ Begrenzt | ✅ Bereichsbasierte Steuerung |
| Mehrsprachige Marketingmaterialien | Mehrsprachiger Text | ❌ Schlecht bei Nicht-Lateinisch | ✅ Volle Sprachunterstützung |
| Marken-IP-Merchandise | Gesichtskonsistenz + HD | ❌ Schwer umsetzbar | ✅ Vollständige Unterstützung |
Für chinesischsprachige Entwickler und Content-Ersteller wird der Durchbruch beim CJK-Text-Rendering der wertvollste Fortschritt von GPT Image 2 sein.
Autoregressiv vs. Diffusion: Grundlegende Unterschiede der Architekturen
Die von der GPT Image-Serie verwendete autoregressive Architektur unterscheidet sich grundlegend von den Diffusionsmodellen, die von DALL-E, Midjourney oder FLUX genutzt werden:
| Dimension | Diffusionsmodell (DALL-E/MJ/FLUX) | Autoregressives Modell (GPT Image) |
|---|---|---|
| Generierungsweise | Schrittweise Entrauschung | Pixel für Pixel, wie beim Schreiben |
| Text-Rendering | Eher schwach (kein Verständnis der Semantik) | Extrem stark (erbt Fähigkeiten des Sprachmodells) |
| Weltwissen | Begrenzt (nur Trainingsdaten) | Reichhaltig (erbt LLM-Wissen) |
| Bildbearbeitung | Erfordert zusätzliche Modelle | Nativ unterstützt |
| Prompt-Verständnis | Gut | Exzellent (auf LLM-Niveau) |
| Generierungsgeschwindigkeit | Eher schnell (parallele Entrauschung) | Eher langsam (serielle Generierung) |
💡 Technischer Einblick: Die "neue, eigenständige Architektur" von GPT Image 2 könnte ein hybrider Ansatz aus autoregressiven und Diffusionsmethoden sein, um die Vorteile beider Welten zu vereinen. Über die Plattform APIYI (apiyi.com) können Sie sowohl GPT Image als auch Diffusionsmodelle wie FLUX aufrufen, um die tatsächlichen Ergebnisse beider Architekturen direkt zu vergleichen.
DALL-E Migrationsleitfaden: Abschluss bis zum 12. Mai erforderlich
DALL-E 2 und DALL-E 3 werden am 12. Mai 2026 offiziell eingestellt. Alle Entwickler müssen die Migration bis zu diesem Datum abgeschlossen haben.
Migrationspfad
| Aktuelles Modell | Empfohlene Migration | Migrationsaufwand |
|---|---|---|
| DALL-E 2 | GPT Image 1.5 | Gering (API-Schnittstellenkompatibilität) |
| DALL-E 3 | GPT Image 1.5 | Gering (Ersetzung des Modellnamens) |
| GPT Image 1 | GPT Image 1.5 | Sehr gering (direkter Austausch) |
Hinweise zur Migration
- Schnittstellenkompatibilität: Die GPT Image-Serie verwendet denselben
/v1/images/generations-Endpunkt; es muss lediglich dermodel-Parameter angepasst werden. - Parameterunterschiede: GPT Image 1.5 führt den neuen
quality-Parameter (low/medium/high) ein, während DALL-E 3quality(standard/hd) verwendet. - Abrechnungsänderungen: Umstellung von der bildbasierten Abrechnung bei DALL-E auf ein duales Modell bei GPT Image (Token + Bild).
- Ausgabeformate: GPT Image bietet nun Unterstützung für das WebP-Format und transparente Hintergründe.
🎯 Migrationsempfehlung: Nutzen Sie die APIYI-Plattform (apiyi.com) für Migrationstests. So können Sie die Unterschiede in der Bilderzeugung zwischen DALL-E und GPT Image vergleichen, ohne Ihre Produktionsumgebung zu beeinträchtigen. Die Plattform unterstützt eine einheitliche Schnittstelle für mehrere Modelle, was die Umstellungskosten minimiert.
Häufig gestellte Fragen (FAQ)
Q1: Wann wird GPT Image 2 offiziell veröffentlicht?
Es gibt derzeit kein offiziell bestätigtes Veröffentlichungsdatum. Basierend auf dem Fortschritt der Arena-Betatests und historischen Veröffentlichungszyklen wird mit einer Veröffentlichung zwischen Mitte und Ende 2026 gerechnet. Da zwischen GPT Image 1 und 1.5 etwa 9 Monate lagen, könnte die 2. Generation im Sommer erscheinen. Nach der offiziellen Veröffentlichung wird die APIYI-Plattform (apiyi.com) diese sofort unterstützen.
Q2: Sollte ich auf GPT Image 2 warten oder jetzt GPT Image 1.5 nutzen?
Wir empfehlen, sofort auf GPT Image 1.5 umzusteigen. Es ist derzeit das leistungsfähigste Bilderzeugungsmodell von OpenAI, wobei die "Low"-Qualität nur 0,009 $ pro Bild kostet. Die API-Schnittstelle ist kompatibel, sodass eine spätere Migration auf GPT Image 2 lediglich den Austausch des Modellnamens erfordert. Warten würde nur dazu führen, dass Sie das Migrationsfenster vor der DALL-E-Abschaltung verpassen.
Q3: Was bedeutet die neue Architektur von GPT Image 2?
GPT Image 1/1.5 basieren auf den Fähigkeiten zur Bilderzeugung des multimodalen GPT-4o-Modells. GPT Image 2 soll Berichten zufolge eine völlig neue, eigenständige Architektur nutzen und nicht mehr von GPT-4o abhängig sein. Dies könnte eine gezieltere Optimierung der Bilderzeugung, höhere Auflösungsgrenzen und geringere Inferenzkosten bedeuten. Über die APIYI-Plattform (apiyi.com) können Sie nach der Veröffentlichung der 2. Generation schnell die tatsächlichen Unterschiede zwischen der alten und neuen Architektur vergleichen.
Q4: Unterstützt die GPT Image-Serie die Darstellung chinesischer Schriftzeichen?
Die Unterstützung für chinesische Schriftzeichen ist bei GPT Image 1.5 begrenzt; es kann häufig zu Fehlern oder Zeichensalat kommen. Es wird erwartet, dass GPT Image 2 die Genauigkeit bei der Darstellung nicht-lateinischer Schriften (einschließlich Chinesisch, Japanisch, Koreanisch und Arabisch) erheblich verbessert, was ein großer Vorteil für Content-Ersteller im chinesischsprachigen Raum ist.
Zusammenfassung
Der Betatest von GPT Image 2 markiert den Beginn einer neuen Ära für die Bilderzeugung bei OpenAI. Mit einer völlig neuen, eigenständigen Architektur, nativer 4K-Auflösung, einer Textdarstellung in über 99 % der Sprachen, Gesichtskonsistenz und einer präzisen regionalen Steuerung werden diese erwarteten Upgrades die Leistungsgrenzen der KI-Bilderzeugung neu definieren.
Die wichtigsten Punkte im Überblick:
- Status: In der Betaphase, 3 Arena-Codenamen wurden bekannt.
- Architektur: Komplett neue, eigenständige Architektur, keine Ableitung von GPT-4o.
- Erwartete Upgrades: 4K-Auflösung / >99 % Textgenauigkeit / Gesichtskonsistenz / regionale Steuerung / 3 Sekunden Generierungszeit.
- Aktuelle Lösung: GPT Image 1.5 (günstig ab 0,009 $ pro Bild) ist derzeit die beste Wahl.
- Dringend: DALL-E 2/3 werden am 12. Mai eingestellt, eine Migration sollte zeitnah erfolgen.
- Voraussichtliche Veröffentlichung: Mitte bis zweite Jahreshälfte 2026.
Wir empfehlen den schnellen Zugriff auf die gesamte GPT Image-Modellreihe über APIYI (apiyi.com), um direkt nach der offiziellen Veröffentlichung von GPT Image 2 den API-Zugriff zu erhalten.
Referenzen
- OpenAI API-Dokumentation zur Bilderzeugung:
developers.openai.com/api/docs/guides/image-generation - OpenAI Modellliste:
developers.openai.com/api/docs/models - OpenAI API-Preisgestaltung:
developers.openai.com/api/docs/pricing
Dieser Artikel wurde vom technischen Team von APIYI verfasst. Weitere Tutorials zur Nutzung von KI-Modellen finden Sie auf APIYI unter apiyi.com.