Die Wahl eines schnellen und kostengünstigen KI-Modells ist für jeden Entwickler bei hochfrequenten Abfragen eine zentrale Herausforderung. Google hat am 3. März 2026 offiziell das Gemini 3.1 Flash Lite Preview veröffentlicht. Es ist das schnellste und wirtschaftlichste Modell der Gemini 3-Serie, das speziell für Szenarien mit hohem Durchsatz wie Übersetzungen, Zusammenfassungen und Klassifizierungen entwickelt wurde.
Kernnutzen: Nach dem Lesen dieses Artikels werden Sie die technischen Parameter, Leistungsvorteile und optimalen Einsatzszenarien von Gemini 3.1 Flash Lite vollständig verstehen und das Modell anhand von Beispielcode schnell in Ihre Anwendungen integrieren können.

Gemini 3.1 Flash Lite: Wichtige Parameter im Überblick
Bevor wir tiefer in Gemini 3.1 Flash Lite eintauchen, werfen wir einen Blick auf die wichtigsten technischen Spezifikationen des Modells:
| Parameter | Spezifikation Gemini 3.1 Flash Lite | Erläuterung |
|---|---|---|
| Modell-ID | gemini-3.1-flash-lite-preview |
Aktuell als Preview-Version |
| Kontextfenster | 1.000.000 Token | Langer Kontext im Millionenbereich |
| Max. Ausgabe | 64.000 Token | Unterstützt lange Textgenerierung |
| Eingabepreis | 0,25 $ / Mio. Token | Extrem niedrige Kosten |
| Ausgabepreis | 1,50 $ / Mio. Token | Hohes Preis-Leistungs-Verhältnis |
| Ausgabegeschwindigkeit | ~382 Token/Sek. | Blitzschnelle Antwortzeit |
| Eingabemodalität | Text, Bild, Audio, Video | Nativ multimodal |
| Ausgabemodalität | Text | Textgenerierung |
| Veröffentlichungsdatum | 3. März 2026 | Neueste Version |
🚀 Schnellstart: Gemini 3.1 Flash Lite Preview ist bereits auf der APIYI-Plattform (apiyi.com) verfügbar. Es unterstützt OpenAI-kompatible Schnittstellen und lässt sich ohne zusätzliche Konfiguration schnell einbinden.
Die 5 Kernvorteile von Gemini 3.1 Flash Lite
Vorteil 1: 2,5-fache Geschwindigkeitssteigerung
Gemini 3.1 Flash Lite hat bei der Geschwindigkeit einen Quantensprung vollzogen. Laut den Benchmark-Daten von Artificial Analysis gilt:
- Time to First Token (TTFT): 2,5-mal schneller als Gemini 2.5 Flash
- Ausgabegeschwindigkeit: Erreicht 382 Token/Sekunde, eine Steigerung um 64 % gegenüber den 232 Token/Sekunde von Gemini 2.5 Flash
- Gesamtdurchsatz: Um ca. 45 % gesteigert
Dies bedeutet, dass Benutzer bei latenzempfindlichen Anwendungen wie Echtzeitübersetzungen, Chatbots oder Inhaltszusammenfassungen eine nahezu sofortige Antwort erhalten.
Vorteil 2: Ultimatives Preis-Leistungs-Verhältnis
Die Preisstrategie von Gemini 3.1 Flash Lite ist äußerst wettbewerbsfähig:
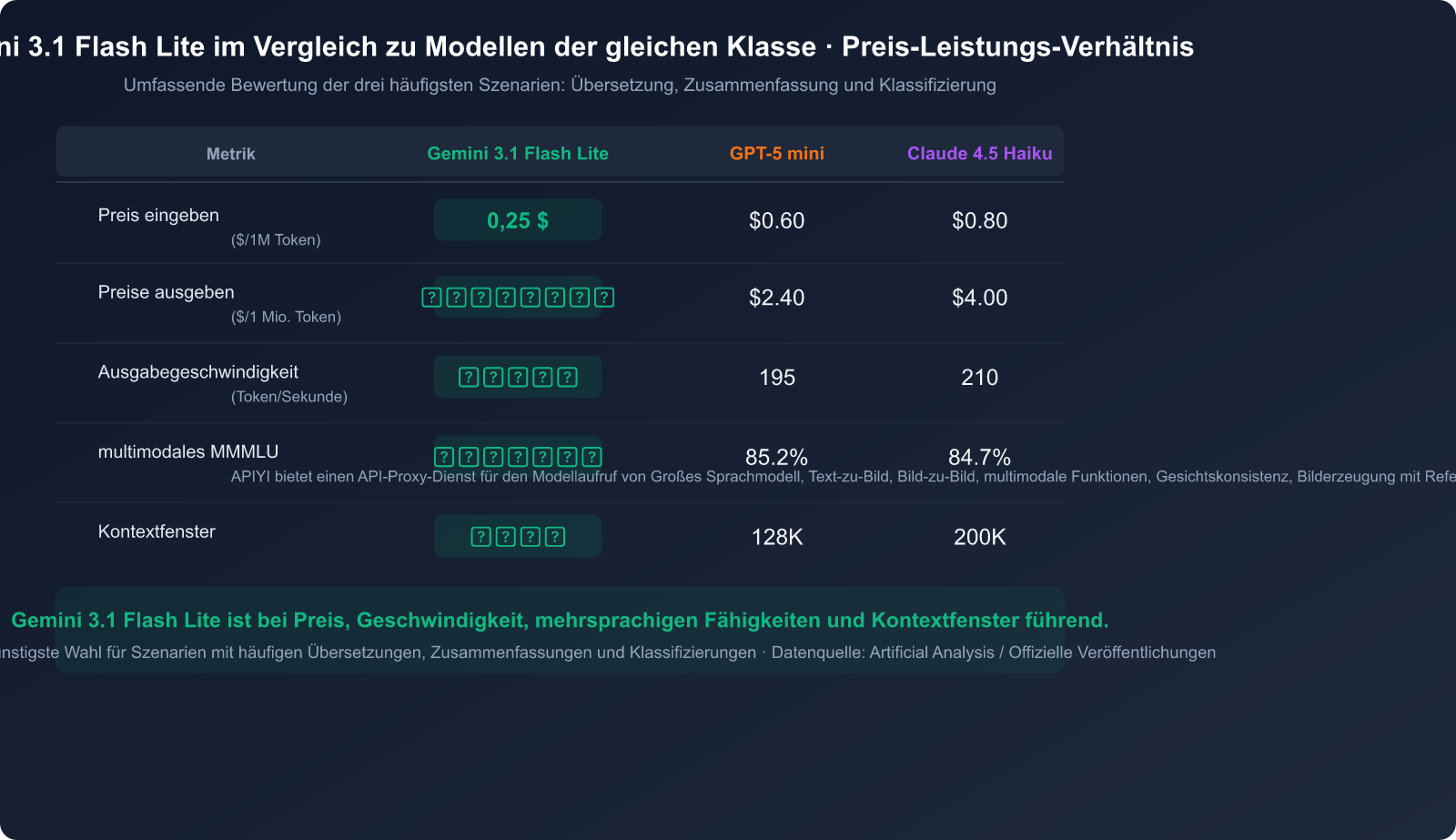
| Preisvergleich | Eingabepreis ($/1M Token) | Ausgabepreis ($/1M Token) | Gesamtkosten |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0,25 | $1,50 | ⭐ Niedrigste |
| Gemini 3 Flash | $1,00 | $4,00 | Mittel |
| Gemini 3 Pro | $2,50 | $15,00 | Hoch |
| Claude 4.5 Haiku | $0,80 | $4,00 | Mittel |
| GPT-5 mini | $0,60 | $2,40 | Mittel |
Bei einer täglichen Verarbeitung von 1 Million Token betragen die monatlichen Kosten für Gemini 3.1 Flash Lite nur etwa 52,50 $, was eine Ersparnis von über 80 % gegenüber Gemini 3 Pro bedeutet.
Vorteil 3: Kontextfenster von einer Million Token
Gemini 3.1 Flash Lite unterstützt ein Kontextfenster von 1M Token, was in dieser Preisklasse äußerst selten ist. Das bedeutet für Sie:
- Übersetzung oder Zusammenfassung ganzer Bücher in einem Durchgang
- Analyse von stundenlangen Transkripten aus Konferenzaufzeichnungen
- Verständnis umfangreicher Codebasen und Dokumentationserstellung
- Mehrsprachige Vergleichsübersetzungen langer Dokumente
Vorteil 4: Native multimodale Unterstützung
Obwohl es als leichtgewichtiges Modell positioniert ist, behält Gemini 3.1 Flash Lite die volle multimodale Eingabefähigkeit bei:
- Text: Standard-Textverständnis und -generierung
- Bild: Bilderkennung und -analyse
- Audio: Verarbeitung von Sprachinhalten
- Video: Verständnis von Videoinhalten
Dadurch eignet es sich nicht nur für reine Textaufgaben, sondern auch für multimodale Szenarien wie die Übersetzung von Bild-Text-Kombinationen oder die Erstellung von Videountertiteln.
Vorteil 5: Einstellbare Denktiefe
Gemini 3.1 Flash Lite unterstützt die Funktion Thinking Levels, mit der Entwickler die logische Tiefe des Modells flexibel an die Komplexität der Aufgabe anpassen können:
- Geringe Denktiefe: Geeignet für einfache Übersetzungen, Klassifizierungen usw., bei denen maximale Geschwindigkeit im Vordergrund steht
- Mittlere Denktiefe: Geeignet für Zusammenfassungen, inhaltliche Umformulierungen und Aufgaben, die ein gewisses Verständnis erfordern
- Hohe Denktiefe: Geeignet für komplexe Schlussfolgerungen, Codegenerierung und Aufgaben, die tiefgreifendes Denken erfordern

Performance-Benchmark von Gemini 3.1 Flash Lite
Gemini 3.1 Flash Lite hat im Arena.ai-Ranking einen Elo-Wert von 1432 Punkten erreicht und überzeugt damit als Spitzenreiter in seiner Modellklasse.
| Benchmark | Gemini 3.1 Flash Lite | Erläuterung |
|---|---|---|
| GPQA Diamond | 86,9% | Wissenschaftliches Schlussfolgern |
| MMMU-Pro | 76,8% | Multimodales Schlussfolgern |
| MMMLU | 88,9% | Mehrsprachige Fragenbeantwortung |
| LiveCodeBench | 72,0% | Codegenerierung |
| Video-MMMU | 84,8% | Videoverständnis |
| SimpleQA | 43,3% | Parametrisiertes Wissen |
| MRCR v2 (128k) | 60,1% | Verständnis langer Kontextfenster |
Bemerkenswert ist, dass Gemini 3.1 Flash Lite in sechs Benchmarks, darunter GPQA Diamond und MMMLU, GPT-5 mini und Claude 4.5 Haiku übertrifft. Dies beweist, dass auch leichtgewichtige Modelle eine Intelligenz auf dem neuesten Stand der Technik bieten können.
🎯 Technischer Hinweis: Die oben genannten Benchmark-Daten zeigen, dass Gemini 3.1 Flash Lite besonders bei der mehrsprachigen Verarbeitung glänzt (MMMLU 88,9%), was es ideal für Übersetzungsaufgaben macht. Über APIYI (apiyi.com) können Sie das Modell schnell für mehrsprachige Aufgaben testen.
Schnelleinstieg in Gemini 3.1 Flash Lite
Minimalistisches Code-Beispiel
Dank der OpenAI-kompatiblen Schnittstelle lässt sich Gemini 3.1 Flash Lite mit nur wenigen Zeilen Code aufrufen:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
# Beispiel für ein Übersetzungsszenario
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Sie sind ein professioneller Übersetzer. Bitte übersetzen Sie die chinesischen Eingaben des Nutzers ins Englische und bewahren Sie dabei die ursprüngliche Bedeutung und den Tonfall."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen: Batch-Übersetzung + Zusammenfassung
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""Übersetzt Text in die Zielsprache"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Translate the following text to {target_lang}. Keep the original meaning and tone."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Erstellt eine Textzusammenfassung"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Fassen Sie die Kernpunkte des folgenden Inhalts in maximal {max_words} Wörtern zusammen."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Textklassifizierung"""
cats = "、".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Klassifizieren Sie den folgenden Text in eine dieser Kategorien: {cats}. Geben Sie nur den Namen der Kategorie zurück."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Anwendungsbeispiel
texts = [
"Quantencomputing wird das Feld der Kryptographie im nächsten Jahrzehnt grundlegend verändern",
"Neues Elektroauto knackt die 1000-Kilometer-Marke bei der Reichweite",
"Zentralbank kündigt Senkung des Leitzinses um 25 Basispunkte an"
]
categories = ["Technologie", "Auto", "Finanzen", "Sport", "Unterhaltung"]
for text in texts:
# Übersetzung
translated = translate_text(text)
# Klassifizierung
category = classify_text(text, categories)
# Zusammenfassung
summary = summarize_text(text, max_words=30)
print(f"Original: {text}")
print(f"Übersetzung: {translated}")
print(f"Kategorie: {category}")
print(f"Zusammenfassung: {summary}")
print("---")
💰 Kostenoptimierung: Für häufige Modellaufrufe wie Übersetzungen, Zusammenfassungen oder Klassifizierungen bietet Gemini 3.1 Flash Lite eine extrem niedrige Preisgestaltung (Input ab $0,25 pro Million Token), was die Betriebskosten erheblich senkt. Über die Plattform APIYI (apiyi.com) erhalten Sie zudem zusätzliche Preisvorteile und kostenlose Testguthaben.
Optimale Einsatzszenarien für Gemini 3.1 Flash Lite
Szenario 1: Hochfrequente Stapelübersetzung
Mit einem beeindruckenden Wert von 88,9 % im mehrsprachigen Benchmark MMMLU, extrem niedrigen Kosten und einer rasanten Reaktionsgeschwindigkeit ist Gemini 3.1 Flash Lite die ideale Wahl für Übersetzungsaufgaben im großen Stil:
- Übersetzung von E-Commerce-Produktbeschreibungen: Mehrsprachige Übersetzung von zehntausenden Produktinformationen täglich.
- Übersetzung von Nutzerbewertungen: Echtzeit-Übersetzung von Kundenfeedback aus dem Ausland.
- Internationalisierung technischer Dokumentationen: Erstellung mehrsprachiger Versionen umfangreicher Dokumente.
- Untertitelübersetzung: Schnelle mehrsprachige Konvertierung von Video-Untertiteln.
Szenario 2: Echtzeit-Inhaltszusammenfassung
Die Ausgabegeschwindigkeit von 382 Token pro Sekunde macht das Modell perfekt für Echtzeit-Zusammenfassungen:
- Erstellung von Nachrichtenzusammenfassungen: Automatisierte Extraktion von Kurzfassungen aus riesigen Nachrichtenmengen.
- Besprechungsprotokolle: Schnelle Zusammenfassung langer Meeting-Aufzeichnungen.
- Literaturübersichten: Stapelweise Erstellung von Abstracts für wissenschaftliche Arbeiten.
- E-Mail-Zusammenfassungen: Automatisierte Zusammenfassung und Kategorisierung von geschäftlichen E-Mails.
Szenario 3: Umfangreiche Inhaltsprüfung und Klassifizierung
Die geringe Latenz und die niedrigen Kosten machen es zur idealen Wahl für Content-Moderations-Pipelines:
- Prüfung nutzergenerierter Inhalte: Sicherheitsfilter für Inhalte auf sozialen Plattformen.
- Automatisierte Ticket-Klassifizierung: Intelligentes Routing in Kundensupport-Systemen.
- Stimmungsanalyse: Echtzeit-Überwachung der Markenwahrnehmung.
- Automatisierte Tag-Generierung: Automatische Verschlagwortung für Content-Management-Systeme.
Entscheidungsleitfaden für Einsatzszenarien
| Einsatzszenario | Empfehlungsgrund | Hauptvorteil | Geschätzte monatliche Kosten |
|---|---|---|---|
| Stapelübersetzung | Herausragende mehrsprachige MMMLU-Fähigkeiten | Niedriger Preis + hohe Qualität | ~50 $ (1 Mio. Token/Tag) |
| Echtzeit-Zusammenfassung | 382 Token/Sek. Hochgeschwindigkeitsausgabe | Geringe Latenz + schnell | ~30 $ (500.000 Token/Tag) |
| Inhaltsprüfung | Hohe Klassifizierungsgenauigkeit, schnelle Antwort | Niedrige Kosten + Stapelverarbeitung | ~20 $ (300.000 Token/Tag) |
| Chatbot | 2,5x schnelleres TTFT | Sofortige Reaktion | ~80 $ (2 Mio. Token/Tag) |
| Langdokument-Verarbeitung | 1 Mio. Token Kontextfenster | Ein ganzes Buch in einem Durchgang | Abrechnung nach Bedarf |
💡 Empfehlung: Wenn Ihr Anwendungsfall hochfrequente, stapelweise und kostensensible Textverarbeitungsaufgaben umfasst, ist Gemini 3.1 Flash Lite derzeit die wirtschaftlichste Wahl. Wir empfehlen, praktische Tests über die Plattform APIYI (apiyi.com) durchzuführen, da diese den einfachen Wechsel zu anderen Modellen für einen direkten Leistungsvergleich unterstützt.
Hinweise zur Nutzung von Gemini 3.1 Flash Lite
Aktuelle Einschränkungen
Da es sich um ein Vorschaumodell handelt, sollten Sie folgende Punkte beachten:
- Vorschauphase: Das Modell befindet sich noch im Preview-Status; API-Schnittstellen und das Verhalten können sich noch ändern.
- Ausgabebeschränkung: Die maximale Ausgabe beträgt 64K Token. Sehr lange Generierungsaufgaben sollten daher in Abschnitte unterteilt werden.
- Leistung bei extrem langem Kontext: Bei einem extrem langen Kontext von 1M Token ist die Leistung eher durchschnittlich (MRCR v2 1M Test erreicht nur 12,3 %). Wir empfehlen, den Kontext auf 128K zu begrenzen, um optimale Ergebnisse zu erzielen.
- Sicherheitsgrenzen: Die Sicherheitsbewertung für Bild-zu-Text-Aufgaben muss noch verbessert werden. Bei sensiblen Inhalten sollte eine zusätzliche Prüfungsebene implementiert werden.
Nutzungsempfehlungen
- Temperatur-Parameter: Für Übersetzungsaufgaben empfehlen wir
temperature=0.3, für Zusammenfassungentemperature=0.5. - System-Eingabeaufforderung: Klare Rollendefinitionen und Anforderungen an das Ausgabeformat können die Qualität der Ergebnisse deutlich steigern.
- Stapelverarbeitung: Nutzen Sie asynchrone Aufrufe, um den Durchsatz zu erhöhen und die Geschwindigkeitsvorteile des Modells voll auszuschöpfen.
- Kontextkontrolle: Obwohl 1M Token Kontext unterstützt werden, empfehlen wir für Standardaufgaben eine Begrenzung auf 128K, um das beste Preis-Leistungs-Verhältnis zu erzielen.
Häufig gestellte Fragen (FAQ)
Q1: Was ist der Unterschied zwischen Gemini 3.1 Flash Lite und Gemini 3 Flash?
Gemini 3.1 Flash Lite ist die leichtgewichtige Version der Gemini 3-Serie, die speziell für Szenarien mit hoher Frequenz und niedrigen Kosten optimiert wurde. Im Vergleich zu Gemini 3 Flash sind die Eingabekosten um 75 % niedriger ($0,25 vs. $1,00) und die Ausgabegeschwindigkeit ist etwa 64 % höher, allerdings ist die Leistungsfähigkeit bei komplexen Schlussfolgerungen etwas geringer. Kurz gesagt: Wenn Sie ein optimales Preis-Leistungs-Verhältnis benötigen, wählen Sie Flash Lite; wenn Sie eine stärkere Schlussfolgerungsfähigkeit benötigen, wählen Sie Flash. Über die APIYI-Plattform (apiyi.com) können Sie beide Modelle testen, um schnell die beste Wahl für Ihr Szenario zu finden.
Q2: Eignet sich Gemini 3.1 Flash Lite für Übersetzungen?
Sehr gut sogar. Gemini 3.1 Flash Lite erreichte im mehrsprachigen Benchmark MMMLU einen hohen Wert von 88,9 % und führt damit in seiner Modellklasse. Zusammen mit dem extrem niedrigen Eingabepreis von $0,25 pro Million Token und einer Ausgabegeschwindigkeit von 382 Token/Sekunde ist es eines der kosteneffizientesten Modelle für Stapelübersetzungen. Wir empfehlen, über APIYI (apiyi.com) kostenlose Testguthaben zu beziehen, um die tatsächliche Übersetzungsqualität zu validieren.
Q3: Wie rufe ich Gemini 3.1 Flash Lite über die OpenAI-kompatible Schnittstelle auf?
Setzen Sie einfach die base_url auf die Schnittstellenadresse von APIYI und verwenden Sie gemini-3.1-flash-lite-preview als model-Parameter. Sie müssen die bestehende OpenAI SDK-Codestruktur nicht ändern, was einen nahtlosen Wechsel ermöglicht. Details finden Sie im Codebeispiel im Abschnitt „Schnellstart“ dieses Artikels.
Q4: Ist das 1M-Kontextfenster von Gemini 3.1 Flash Lite in der Praxis nützlich?
Innerhalb eines Bereichs von 128K Token ist die Leistung exzellent (MRCR v2 128K Score 60,1 %), bei extremen 1M Token-Szenarien sinkt die Leistung jedoch deutlich (MRCR v2 1M Score 12,3 %). Wir empfehlen, den Kontext im täglichen Gebrauch auf 128K zu begrenzen und bei der Verarbeitung extrem langer Dokumente eine Segmentierungsstrategie anzuwenden.
Zusammenfassung
Mit seinem extrem günstigen Preis von 0,25 $ pro 1 Million Eingabe-Tokens, einer rasanten Ausgabegeschwindigkeit von 382 Tokens/Sekunde, einem 1M-Token-Kontextfenster sowie herausragenden Ergebnissen in Benchmarks wie der mehrsprachigen Verarbeitung (MMMLU 88,9 %) und wissenschaftlichem Schlussfolgern (GPQA Diamond 86,9 %) ist Gemini 3.1 Flash Lite der Preis-Leistungs-Sieger für häufige Anwendungsfälle wie Übersetzung, Zusammenfassung und Klassifizierung im Jahr 2026.
Egal, ob Sie täglich Millionen von Tokens für Batch-Übersetzungen verarbeiten oder einen Echtzeit-Zusammenfassungsdienst mit geringer Latenz aufbauen müssen, Gemini 3.1 Flash Lite ist die erste Wahl.
Wir empfehlen die schnelle Anbindung von Gemini 3.1 Flash Lite Preview über APIYI (apiyi.com). Die Plattform bietet eine OpenAI-kompatible Schnittstelle und unterstützt das einfache Umschalten zwischen verschiedenen gängigen Modellen, was die Validierung der Ergebnisse und den Modellvergleich erheblich beschleunigt.
Referenzen
-
Google DeepMind – Gemini 3.1 Flash-Lite Model Card: Offizielle technische Spezifikationen und Benchmark-Daten des Modells
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Link:
-
Google AI for Developers – Gemini 3.1 Flash-Lite Preview: Offizielle API-Dokumentation und Entwicklerhandbuch
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Link:
-
Artificial Analysis – Leistungsbewertung: Unabhängige Benchmarks zu Geschwindigkeit und Performance
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Link:
📝 Autor: APIYI Technik-Team | Weitere Anleitungen zur Nutzung von KI-Modellen und technische Tutorials finden Sie im APIYI-Hilfezentrum unter help.apiyi.com