Anmerkung des Autors: Ein tiefgehender Vergleich zwischen Claude Opus 4.6 und Grok 4.20 Beta über sieben Dimensionen – von Multi-Agenten-Architektur und Coding-Fähigkeiten bis hin zur Reasoning-Leistung und API-Preisgestaltung – um Entwicklern bei der Auswahl des am besten geeigneten KI-Modells für ihre Szenarien zu helfen.
Im Februar 2026 erlebte die KI-Branche ein direktes Aufeinandertreffen zweier Schwergewichte: Anthropic veröffentlichte am 5. Februar Claude Opus 4.6, und xAI folgte Mitte Februar mit der Einführung von Grok 4.20 (Beta). Beide positionieren „Multi-Agenten-Kollaboration“ als zentrales Verkaufsargument, verfolgen jedoch grundlegend unterschiedliche architektonische Ansätze.
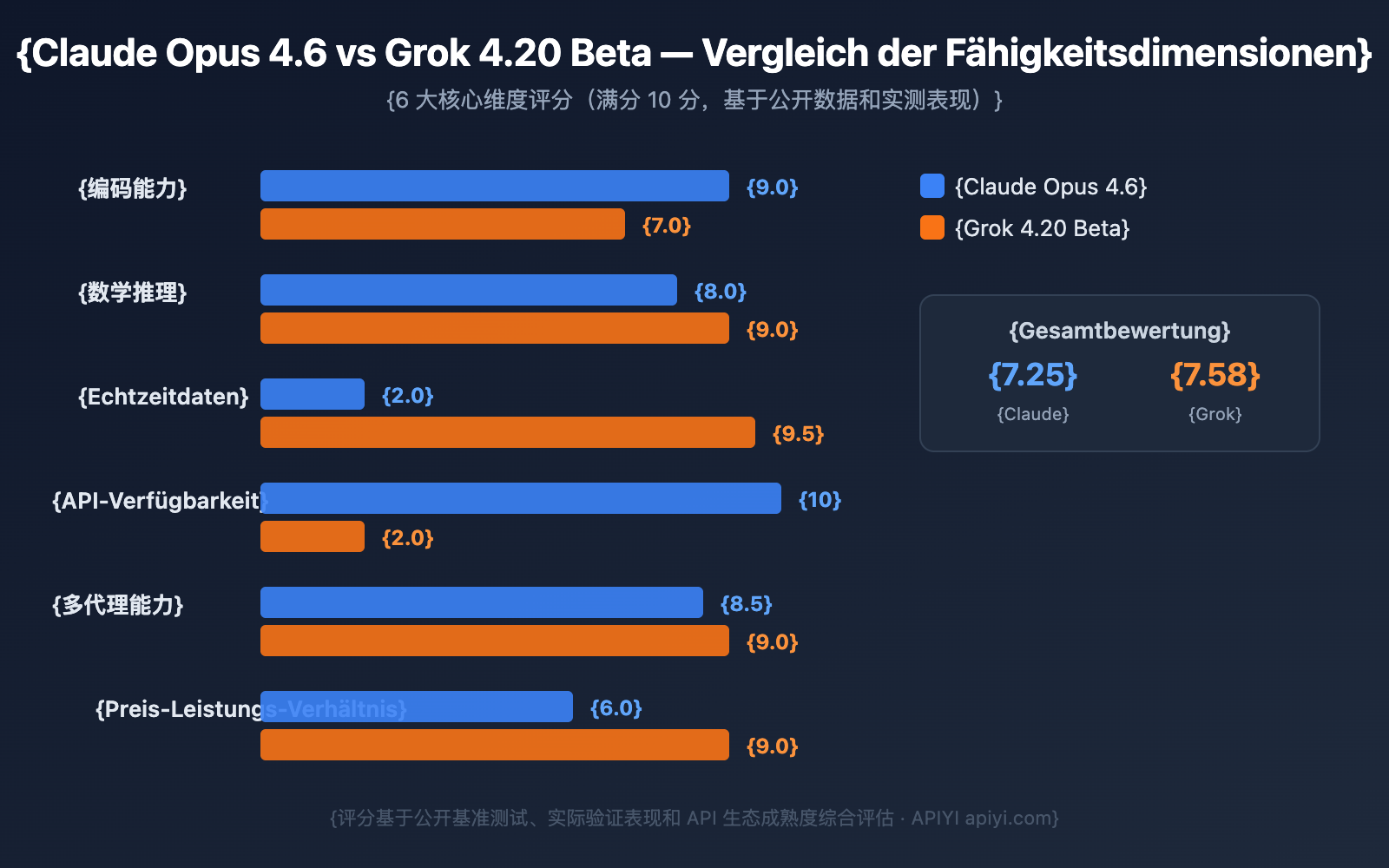
Kernwert: Nach der Lektüre dieses Artikels werden Ihnen die konkreten Unterschiede zwischen Claude Opus 4.6 und Grok 4.20 Beta in den Bereichen Coding, Reasoning, Echtzeitdaten und API-Verfügbarkeit klar sein, sodass Sie die richtige Wahl für Ihre spezifischen Anforderungen treffen können.

Claude Opus 4.6 vs Grok 4.20 Beta: Überblick über die Kernunterschiede
| Vergleichsdimension | Claude Opus 4.6 | Grok 4.20 Beta |
|---|---|---|
| Entwickler | Anthropic | xAI (Elon Musk) |
| Veröffentlichungsdatum | 5. Februar 2026 (Final) | Mitte Februar 2026 (Beta) |
| Multi-Agenten-Architektur | Agent Teams (Lead + Teammates) | 4 Agenten (Grok/Harper/Benjamin/Lucas) |
| Kontextfenster | 200K Standard / 1M Beta | 256K ~ 2M Tokens |
| Maximaler Output | 128K Tokens | Nicht veröffentlicht |
| API-Preise | $5/$25 pro MTok | Noch nicht bekannt (Ref. 4.1: $0.20/$0.50) |
| API-Verfügbarkeit | ✅ Vollständig geöffnet | ❌ Noch nicht geöffnet |
| Exklusive Datenquellen | Keine | X Firehose (Echtzeit-Tweet-Daten) |
Claude Opus 4.6 vs Grok 4.20 Beta: Unterschiedliche Positionierung
Obwohl beide Modelle auf „Multi-Agenten-Kollaboration“ setzen, unterscheiden sie sich grundlegend in ihrer Zielgruppe und den gelösten Problemstellungen:
Claude Opus 4.6 mit seinen „Agent Teams“ ist ein Produktivitätswerkzeug für Entwickler. Es ermöglicht mehreren Claude-Instanzen, in unabhängigen Kontexten parallel zu programmieren, koordiniert durch einen Lead Agent. Jeder „Teammate“ kann eigenständig Dateien lesen und schreiben sowie Tests ausführen. Dies ist eine ausgereifte Funktion, die bereits in realen Projekten eingesetzt werden kann.
Grok 4.20 Beta nutzt sein 4-Agenten-System zur Reasoning-Erweiterung für allgemeine Problemlösungen. Vier Agenten mit unterschiedlichen Expertenrollen (Forschung, Logik, Kreativität, Koordination) denken intern parallel nach und validieren sich gegenseitig, um letztlich präzisere Antworten zu liefern. Derzeit ist dies nur für SuperGrok-Nutzer über das Chat-Interface verfügbar.
🎯 Auswahl-Empfehlung: Wenn Sie Entwickler sind und KI-Unterstützung beim Schreiben von Code, Debugging oder der Verwaltung großer Projekte benötigen, ist Claude Opus 4.6 die derzeit ausgereiftere Wahl, die direkt über APIYI (apiyi.com) aufgerufen werden kann. Wenn Ihr Fokus auf komplexem Reasoning, Echtzeit-Informationsanalyse und multiperspektivischem Denken liegt, ist Grok 4.20 Beta einen Blick wert.
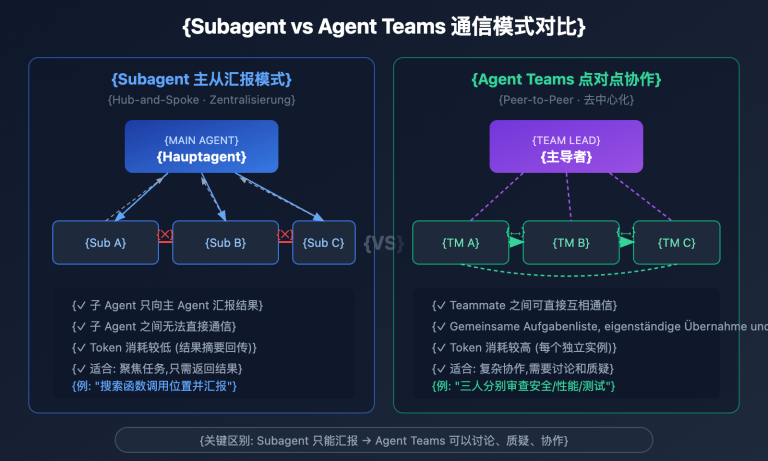
Claude Opus 4.6 vs. Grok 4.20 Beta: Vergleich der Multi-Agenten-Architekturen
Die Multi-Agenten-Architekturen dieser beiden Modelle stellen den spannendsten Kernunterschied dar, den man genauer unter die Lupe nehmen sollte.
Claude Opus 4.6 Agent-Teams-Architektur
Die Agent-Teams von Claude Opus 4.6 setzen auf ein Modell der expliziten parallelen Codierung:
| Komponente | Funktionsbeschreibung | Merkmale |
|---|---|---|
| Lead Agent | Hauptkoordinator | Aufgabenverteilung, Ergebnissynthese, Gesamtplanung |
| Teammates | Unabhängige Arbeits-Agenten | Verfügen jeweils über ein vollständiges Kontextfenster |
| Aufgabenliste | Geteilter Kollaborationsstatus | Abhängigkeitsverfolgung, automatische Freischaltung |
| Nachrichtensystem | Kommunikation zwischen Agenten | Teammates können sich direkt Nachrichten senden |
Die wichtigsten technischen Merkmale der Agent-Teams:
- Unabhängiger Kontext: Jeder Teammate besitzt ein eigenes, vollständiges Kontextfenster, wodurch gegenseitige Störungen vermieden werden.
- Parallelität auf Dateiebene: Verschiedene Teammates können gleichzeitig an unterschiedlichen Dateien arbeiten, was eine echte parallele Entwicklung ermöglicht.
- Echtzeit-Koordination: Über die gemeinsame Aufgabenliste und das Nachrichtensystem kann der Lead Agent die Arbeitsteilung dynamisch anpassen.
- Skalierbarkeit: In Tests wurde bereits die parallele Erstellung eines Rust-C-Compilers durch 16 Agenten unterstützt.
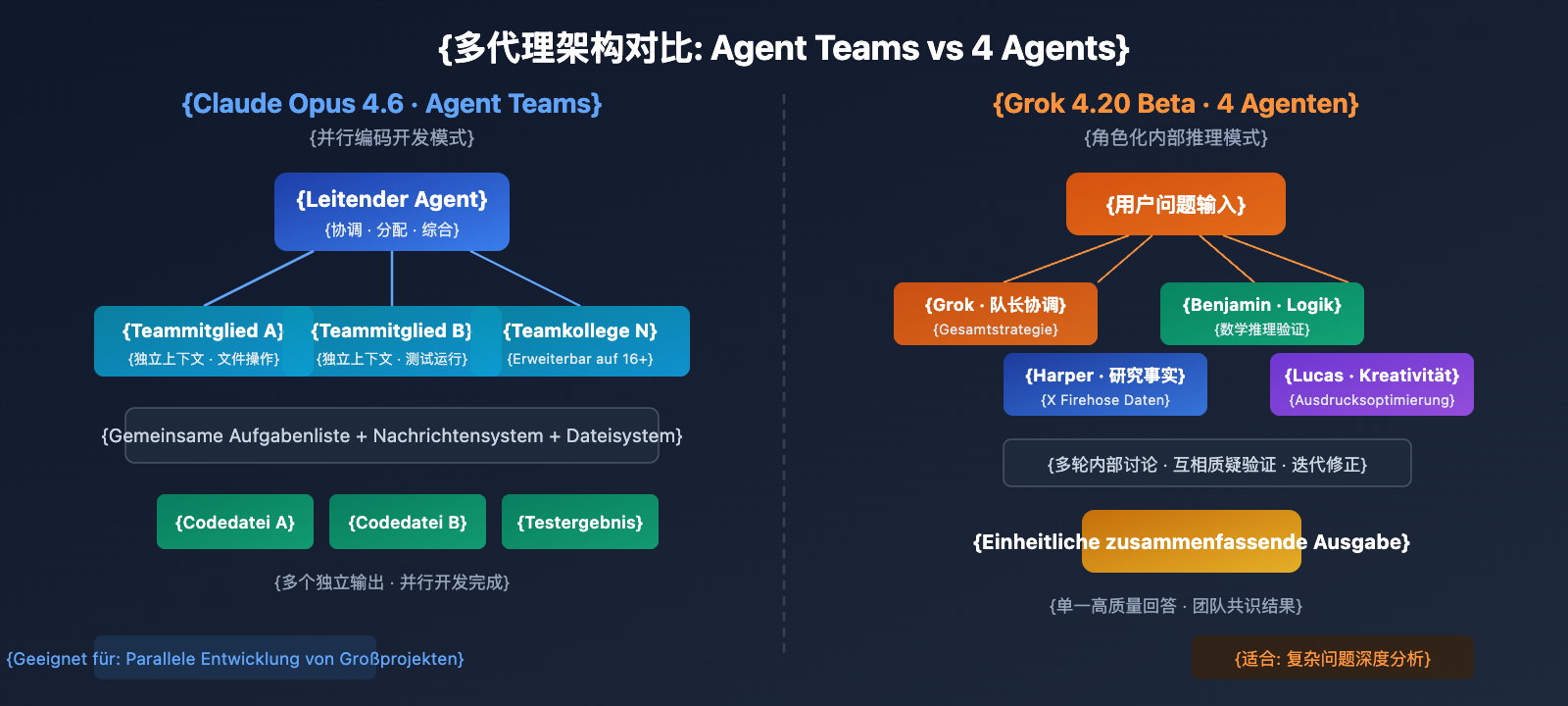
Grok 4.20 Beta 4-Agents-Architektur
Die 4 Agents von Grok 4.20 Beta nutzen ein Modell der rollenbasierten internen Inferenz:
- Grok (Teamleiter): Erstellung der Gesamtstrategie, Synthese der endgültigen Antwort.
- Harper (Forschungsexperte): Echtzeitsuche, Datenprüfung, Zugriff auf X Firehose-Daten.
- Benjamin (Logikexperte): Mathematisches Denken, Programmierverifizierung, präzise Berechnungen.
- Lucas (Kreativexperte): Divergentes Denken, Optimierung des Ausdrucks, Nutzererfahrung (UX).
Der entscheidende Unterschied der 4 Agents liegt in den internen Diskussions- und Peer-Review-Mechanismen über mehrere Runden. Die Agenten hinterfragen gegenseitig ihre Schlussfolgerungen und führen iterative Korrekturen durch, was Halluzinationen effektiv reduziert.
Kernunterschiede: Claude Opus 4.6 vs. Grok 4.20 Beta Multi-Agenten-Architektur
| Dimension | Claude Agent-Teams | Grok 4 Agents |
|---|---|---|
| Kollaborationsziel | Parallele Erledigung von Codierungsaufgaben | Multiperspektivische Analyse desselben Problems |
| Agenten-Rollen | Funktional äquivalent (jeweils Claude-Instanzen) | Rollendifferenzierung (Forschung/Logik/Kreativität/Koordination) |
| Arbeitsweise | Unabhängiger Kontext + geteiltes Dateisystem | Internes paralleles Denken + mehrstufige Diskussion |
| Skalierbarkeit | Skalierbar auf 16+ Agenten | Festgelegt auf 4 spezialisierte Agenten |
| Output-Form | Jeweils unabhängiger Output (Code/Dateien) | Einheitlicher, zusammengefasster Output (eine Antwort) |
| Anwendungsfall | Parallele Entwicklung großer Engineering-Projekte | Tiefenanalyse komplexer Fragestellungen |
| Sichtbarkeit für Nutzer | Arbeitsfortschritt jedes Teammates beobachtbar | Nur der endgültige, synthetisierte Output sichtbar |
💡 Technischer Einblick: Claude Agent-Teams ähneln eher "mehreren Entwicklungsteams in einem Unternehmen, die parallel an einem Projekt arbeiten", während Grok 4 Agents eher einer "Expertengruppe gleichen, die gemeinsam an einem Tisch über demselben schwierigen Problem brütet". Beide Architekturen lösen grundlegend unterschiedliche Problemstellungen.
Claude Opus 4.6 vs. Grok 4.20 Beta: Benchmark-Leistungsvergleich
Veröffentlichte Benchmark-Ergebnisse für Claude Opus 4.6
Claude Opus 4.6 verfügt als offiziell veröffentlichtes Modell über vollständige Benchmark-Daten:
| Benchmark | Claude Opus 4.6 | Claude Opus 4.5 | GPT-5.2 | Erläuterung |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 65,4 % | 59,8 % | — | Agentische Coding-Evaluierung, Branchenbestwert |
| ARC AGI 2 | 68,8 % | 37,6 % | 54,2 % | Für Menschen einfaches, für KI schwieriges Schlussfolgern |
| GDPval-AA | +144 Elo | Baseline | Kontrollgruppe | Wissensarbeit mit wirtschaftlichem Wert |
| OSWorld | 72,7 % | 66,3 % | — | Computer-Nutzungsfähigkeit |
| Humanity's Last Exam | Branchenführend | — | — | Komplexe multidisziplinäre Argumentation |
Die Leistung von Claude Opus 4.6 im Bereich Coding ist besonders herausragend – mit dem branchenweit höchsten Wert bei Terminal-Bench 2.0 wird es als „tasteful coder“ (ein Programmierer mit Geschmack) bezeichnet und glänzt insbesondere bei:
- Navigation und Verständnis großer Codebasen
- Code-Review und Bug-Erkennung
- Frontend-Entwicklung vom Design bis zur funktionalen Implementierung
- Kontinuierliche agentische Coding-Aufgaben
Verifizierte Praxisleistung von Grok 4.20 Beta
Für Grok 4.20 Beta liegen noch keine vollständigen Benchmark-Daten vor (da es sich noch in der Beta-Phase befindet), aber die tatsächliche Leistung wurde bereits in spezifischen Bereichen unter Beweis gestellt:
- Alpha Arena Trading-Wettbewerb: Die einzige profitable KI unter allen Teilnehmern (durchschnittliche Rendite 12,11 %, Spitzenwert 50 %)
- Mathematische Forschung: Half dem Mathematiker Paata Ivanisvili bei neuen Entdeckungen im Bereich der Bellman-Funktionen; leitete die exakte Formel für U(p,q) in etwa 5 Minuten her
- Engineering-Coding: Von Elon Musk öffentlich anerkannt dafür, „offene Engineering-Fragen korrekt zu beantworten“
- Echtzeit-Datenverarbeitung: Nutzt X Firehose für Marktstimmungsanalysen im Millisekundenbereich
Claude Opus 4.6 vs. Grok 4.20 Beta: API-Verfügbarkeit und Preisgestaltung
Für Entwickler sind die API-Verfügbarkeit und die Kosten entscheidende Faktoren bei der Wahl eines Modells.
Claude Opus 4.6 API-Preisdetails
| Posten | Preisgestaltung | Beschreibung |
|---|---|---|
| Standard-Input | $5 / MTok | Innerhalb von 200K Kontext |
| Standard-Output | $25 / MTok | Max. 128K Token |
| Long-Context-Input | $10 / MTok | Automatischer Wechsel bei über 200K |
| Long-Context-Output | $37,50 / MTok | 1M Beta-Modus |
| Prompt Caching | Bis zu 90 % Ersparnis | Caching wiederholter Eingabeaufforderungen |
| Batch-Verarbeitung | 50 % Ersparnis | Asynchrone Batch-Anfragen |
| Fast-Modus | $30/$150 pro MTok | 2,5-fache Geschwindigkeit |
Die API von Claude Opus 4.6 ist bereits auf allen wichtigen Plattformen verfügbar: claude.ai, Anthropic API, Azure, AWS Bedrock usw.
Grok 4.20 Beta API-Status
Die API für Grok 4.20 Beta ist noch nicht freigeschaltet. Als Referenz dienen die Preise von Grok 4.1:
- Input: $0,20 / MTok
- Output: $0,50 / MTok
Sollte Grok 4.20 eine ähnliche Preisstrategie beibehalten, werden die API-Kosten deutlich niedriger sein als bei Claude Opus 4.6. Angesichts der 4-Agents-Architektur, die vier parallele Agenten erfordert, könnten die tatsächlichen Preise jedoch steigen.
💰 Kostentipp: Claude Opus 4.6 ist bereits über APIYI (apiyi.com) verfügbar. Entwickler können direkt einen API-Key beziehen und mit dem Aufruf beginnen. Die Plattform bietet flexible Abrechnung und kostenlose Testguthaben sowie kostensenkende Funktionen wie Prompt Caching. Sobald die Grok 4.20 API verfügbar ist, wird APIYI diese ebenfalls umgehend integrieren.
Empfohlene Einsatzszenarien: Claude Opus 4.6 vs. Grok 4.20 Beta
Szenarien für Claude Opus 4.6
- Professionelle Softwareentwicklung: Paralleles Coding mit Agent Teams ist derzeit die stärkste Lösung für KI-gestützte Entwicklung, besonders für Großprojekte.
- Frontend-Engineering: Wird als „tasteful coder“ bezeichnet; die Präzision bei der Umwandlung von Designentwürfen in funktionalen Code ist branchenführend.
- Code-Review und Debugging: Zuverlässigeres Arbeiten in großen Codebasen, mit einer signifikanten Verbesserung der Bug-Erkennung.
- Wissensarbeit auf Unternehmensebene: Übertrifft GPT-5.2 in der GDPval-AA-Bewertung (+144 Elo), ideal für Bereiche wie Finanzen, Recht und Verwaltung.
- Sofort verfügbare API benötigt: Die API ist vollständig freigegeben und unterstützt alle gängigen Cloud-Plattformen.
Szenarien für Grok 4.20 Beta
- Echtzeit-Informationsanalyse: Der Zugriff auf X Firehose-Daten ist ein exklusiver Vorteil, ideal für die Überwachung der öffentlichen Meinung und Marktanalysen.
- Finanzhandelsstrategien: Die einzige KI, die im Alpha Arena-Wettbewerb profitabel war; die beste Kombination aus Echtzeitdaten und quantitativer Analyse.
- Mathematische und wissenschaftliche Forschung: Nachgewiesene Fähigkeit zur Unterstützung der mathematischen Spitzenforschung, geeignet für akademische Szenarien, die präzise logische Schlussfolgerungen erfordern.
- Bedarf an tiefgehender Analyse aus mehreren Perspektiven: Der interne Diskussionsmechanismus der 4 Agents eignet sich für komplexe Entscheidungsfindungen und strategische Planung.
- Budgetsensible Szenarien: Basierend auf der Preisgestaltung von Grok 4.1 könnten die API-Kosten weit unter denen von Claude Opus 4.6 liegen.
Entscheidungsmatrix: Claude Opus 4.6 vs. Grok 4.20 Beta
| Ihr Bedarf | Empfehlung | Grund |
|---|---|---|
| Code schreiben, Projekte umsetzen | Claude Opus 4.6 | Höchste Punktzahl in Agent Teams + Terminal-Bench |
| Echtzeit-Marktanalyse | Grok 4.20 Beta | Exklusive Datenquelle X Firehose |
| Mathematische/Wissenschaftliche Logik | Grok 4.20 Beta | Validierung auf Bellman-Funktionsebene |
| Wissensarbeit im Unternehmen | Claude Opus 4.6 | Branchenführend bei GDPval-AA |
| API sofort benötigt | Claude Opus 4.6 | Vollständig verfügbar, bei APIYI bereits online |
| API-Kosten kontrollieren | Grok 4.20 Beta | Referenzpreise deutlich niedriger |
| Frontend-Entwicklung | Claude Opus 4.6 | Bewertung als „tasteful coder“ |
| Komplexe strategische Entscheidungen | Grok 4.20 Beta | Analyse aus mehreren Perspektiven durch 4 Agents |
🚀 Schnell ausprobieren: Möchten Sie die tatsächliche Leistung beider Modelle vergleichen? Wir empfehlen, den API-Key für Claude Opus 4.6 über APIYI (apiyi.com) zu beziehen, um die Coding- und Reasoning-Fähigkeiten vorab zu testen. Sobald die Grok 4.20 API verfügbar ist, können Sie auf derselben Plattform schnell zwischen den Modellen wechseln und vergleichen.
Häufig gestellte Fragen
F1: Was ist leistungsfähiger: die Agent Teams von Claude Opus 4.6 oder die 4 Agents von Grok 4.20?
Beide sind keine vergleichbaren Technologien, daher lässt sich "Stärke" nicht direkt messen. Claude Agent Teams ist ein paralleles Coding-Tool, das es mehreren KI-Instanzen ermöglicht, gleichzeitig an verschiedenen Modulen eines Codes zu arbeiten – ideal für die Softwareentwicklung. Grok 4 Agents hingegen ist ein Mechanismus zur Erweiterung des Reasonings, bei dem vier spezialisierte Agenten dasselbe Problem aus verschiedenen Perspektiven analysieren, was sich besonders für komplexe Entscheidungsszenarien eignet. Die Wahl hängt also von Ihrem Anwendungsfall ab, nicht von der absoluten Performance.
F2: Kann man diese beiden Modelle bereits über eine API aufrufen?
Die API für Claude Opus 4.6 ist bereits vollständig freigegeben. Sie kann über APIYI (apiyi.com) bezogen werden, indem man einen API-Key erstellt und diesen direkt über standardmäßige, OpenAI-kompatible Schnittstellen anspricht. Die API für Grok 4.20 Beta ist noch nicht öffentlich zugänglich; derzeit ist die Nutzung nur über ein SuperGrok-Abonnement (30 $/Monat) auf der Benutzeroberfläche von grok.com möglich. Die Plattform APIYI wird die Grok 4.20 API sofort nach deren Veröffentlichung integrieren.
F3: Gibt es einen großen Kostenunterschied bei den APIs dieser beiden Modelle?
Der Unterschied ist signifikant. Die Standardpreise für Claude Opus 4.6 liegen bei 5 $ / 25 $ pro MTok (Input/Output), während die Referenzpreise für Grok 4.1 bei etwa 0,20 $ / 0,50 $ pro MTok liegen. Damit betragen die API-Kosten von Grok nur etwa 2 % bis 4 % von denen von Claude. Allerdings bietet Claude Lösungen zur Kostensenkung wie Prompt Caching (bis zu 90 % Ersparnis) und Batch-Verarbeitung (50 % Ersparnis) an, wodurch die tatsächlichen Betriebskosten erheblich gesenkt werden können. Über die Plattform APIYI (apiyi.com) erhalten Sie zudem flexiblere Abrechnungsmodelle für den Aufruf dieser Modelle.
F4: Welches Modell sollte ich bei begrenztem Budget bevorzugen?
Wenn Ihr Kernbedarf in der Programmierung und Entwicklung liegt, kann Claude Opus 4.6 trotz des höheren Preises durch die Codequalität und die Effizienzsteigerung der Agent Teams den Kostenunterschied rechtfertigen. Wenn Ihr Fokus eher auf Informationsanalyse und Reasoning liegt, empfiehlt es sich, zunächst das SuperGrok-Abonnement (30 $/Monat für unbegrenzte Dialoge) zu nutzen, um Grok 4.20 Beta zu testen, und einen Wechsel erst nach dem API-Launch zu evaluieren. Letztendlich lassen sich beide Modelle über APIYI (apiyi.com) auf derselben Plattform verwalten und aufrufen.
Fazit
Hier sind die Kernpunkte des Vergleichs Claude Opus 4.6 vs. Grok 4.20 Beta:
- Unterschiedliche Ansätze bei der Multi-Agent-Architektur: Claude Agent Teams fungiert als "paralleles Entwicklungsteam", während Grok 4 Agents eher einer "Experten-Diskussionsgruppe" gleicht – beide ergänzen sich eher, als dass sie sich gegenseitig ersetzen.
- Claude für Coding, Grok für Reasoning: Claude Opus 4.6 führt in Benchmarks wie Terminal-Bench und ARC AGI 2, während Grok 4.20 exklusive Vorteile in der mathematischen Forschung und Echtzeitanalyse bietet.
- Deutliche Unterschiede in der API-Reife: Claude Opus 4.6 ist bereits voll einsatzbereit, während Grok 4.20 sich noch in der Beta-Phase befindet und die API noch nicht offen ist.
- Kostenaspekte: Die Referenzpreise der Grok-API liegen weit unter denen von Claude, aber Claudes Prompt Caching kann diese Lücke verringern.
- Echtzeitdaten als Alleinstellungsmerkmal von Grok: Die X-Firehose-Daten sind in Szenarien wie Finanztransaktionen und Stimmungsanalysen (Opinion Mining) unersetzlich.
Für die meisten Entwickler empfiehlt es sich, zuerst Claude Opus 4.6 für Coding und den täglichen Bedarf zu nutzen und gleichzeitig die Entwicklung der Grok 4.20 API im Auge zu behalten, um diese in spezifischen Szenarien (Echtzeitanalyse, mathematisches Reasoning) ergänzend einzusetzen.
Wir empfehlen die zentrale Verwaltung Ihrer API-Aufrufe über APIYI (apiyi.com). Die Plattform unterstützt bereits Claude Opus 4.6 und wird Grok 4.20 sofort nach Erscheinen integrieren, was einen schnellen Wechsel und Kostenvergleiche über eine einzige Schnittstelle ermöglicht.
📚 Referenzen
-
Offizielle Anthropic-Ankündigung – Claude Opus 4.6: Details zu Modellfunktionen und Benchmarks
- Link:
anthropic.com/news/claude-opus-4-6 - Beschreibung: Offizielle Veröffentlichungsinformationen und technische Details zu Claude Opus 4.6
- Link:
-
Claude API Preisdokumentation: Vollständige API-Preise und Abrechnungsregeln
- Link:
platform.claude.com/docs/en/about-claude/pricing - Beschreibung: Enthält detaillierte Informationen zu Standardpreisen, Aufschlägen für lange Kontexte, Prompt Caching usw.
- Link:
-
Offizielle xAI-Release-Notes: Versions-Updates der Grok-Serie
- Link:
docs.x.ai/developers/release-notes - Beschreibung: Offizielle Modell-Updates und API-Veröffentlichungsaufzeichnungen von xAI
- Link:
-
xAI Modellpreise: Offizielle Grok API Preise
- Link:
docs.x.ai/developers/models - Beschreibung: Detaillierte Preisinformationen für die verschiedenen Versionen der Grok API
- Link:
Autor: APIYI Team
Technischer Austausch: Teilen Sie gerne Ihre Erfahrungen mit Claude Opus 4.6 und Grok 4.20 Beta im Kommentarbereich. Weitere Modellvergleiche und API-Integrationslösungen finden Sie in der APIYI (apiyi.com) Tech-Community.