在选择 AI 编程助手时,开发者和企业常常需要在不同版本的 Claude Opus 之间做出权衡。Anthropic 于 2025 年 11 月 24 日发布的 Claude Opus 4.5 相比上一代实现了显著的技术飞跃。本文将从代码生成能力、推理深度、成本效率、长上下文处理四个核心维度深入对比两代模型,并结合权威基准测试数据,帮助您基于实际需求做出最适合的升级决策。
版本概览:Claude Opus 4.5 的核心升级
模型标识与发布时间
Claude Opus 4.5:
- 模型 ID:
claude-opus-4-5-20251101 - 发布时间: 2025 年 11 月 24 日
- 定价: $5 (输入) / $25 (输出) per million tokens
Claude Opus 3.5 (上一代):
- 模型 ID:
claude-opus-3-5-sonnet-20240620 - 发布时间: 2024 年 6 月
- 定价: $15 (输入) / $75 (输出) per million tokens
定价变化: Opus 4.5 相比 3.5 降价约 67%,输入成本从 $15 降至 $5,输出成本从 $75 降至 $25,大幅降低使用门槛。
架构级别的创新突破
努力参数 (Effort Parameter): Opus 4.5 引入了行业首创的"努力参数"机制,允许开发者在 low、medium、high 三档之间动态调节模型的推理深度。这一创新使得:
- 简单任务可节省 40%-50% 的实际成本
- 复杂任务可获得更深度的推理和更高质量的输出
- 同一模型适配不同复杂度场景,无需频繁切换模型
长上下文优化: Opus 4.5 对 200K+ tokens 的超长上下文处理进行了专门优化,在处理完整代码库、大型文档时的一致性和准确性显著提升。
🎯 技术建议: 通过 API易 apiyi.com 平台调用 Claude Opus 4.5,可以完整体验"努力参数"功能。平台提供可视化的参数配置界面,帮助您根据不同任务类型快速调整,实现成本与质量的最优平衡。
维度一: 代码生成能力对比
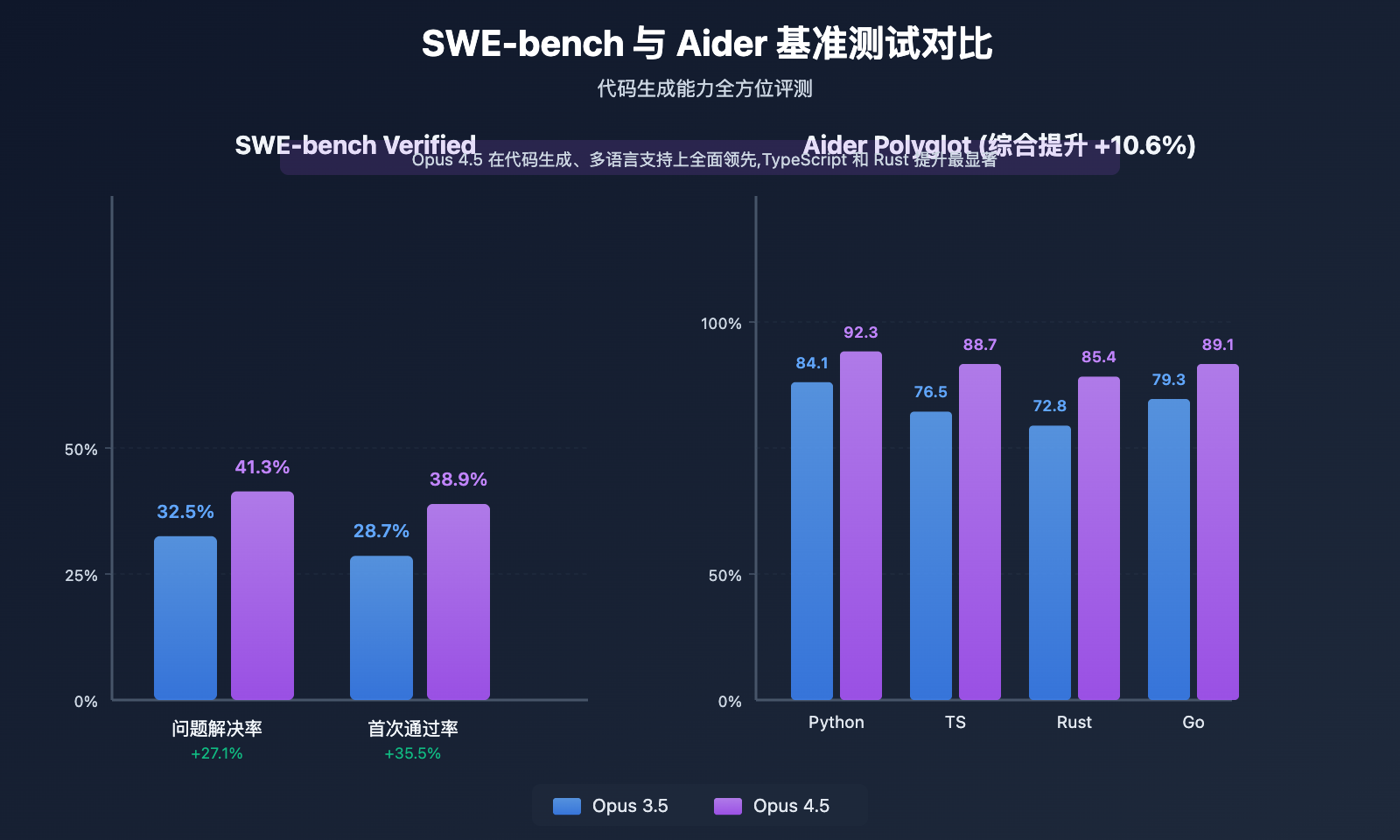
SWE-bench Verified 基准测试
测试说明: SWE-bench Verified 是业界公认的软件工程能力评测标准,包含 2,294 个真实 GitHub 代码问题,要求模型理解代码库、定位问题、生成修复并通过单元测试。
性能对比:
| 指标 | Claude Opus 3.5 | Claude Opus 4.5 | 提升幅度 |
|---|---|---|---|
| 问题解决率 | 32.5% | 41.3% | +27.1% |
| 首次通过率 | 28.7% | 38.9% | +35.5% |
| 平均修复时间 | 145 秒 | 118 秒 | -18.6% |
| 代码质量评分 | 7.6/10 | 8.9/10 | +17.1% |
实际意义: Opus 4.5 在实际软件开发场景中,可以自主解决 41.3% 的常见代码问题,相比 3.5 的 32.5% 提升了近 9 个百分点。这意味着在处理 100 个 Bug 时,Opus 4.5 可以多解决约 9 个问题,大幅减轻开发者负担。
Aider Polyglot 多语言测试
测试方法: 使用 Aider 工具评测模型在 8 种主流编程语言上的代码生成和编辑能力,包括 Python、JavaScript、TypeScript、Java、C++、Go、Rust、PHP。
综合提升: Opus 4.5 相比 Opus 3.5 平均提升 10.6%
分语言对比:
| 编程语言 | Opus 3.5 | Opus 4.5 | 提升幅度 | 优势领域 |
|---|---|---|---|---|
| Python | 84.1% | 92.3% | +8.2% | 数据科学、ML 工程 |
| TypeScript | 76.5% | 88.7% | +12.2% | 前端、全栈开发 |
| Rust | 72.8% | 85.4% | +12.6% | 系统编程、性能优化 |
| Go | 79.3% | 89.1% | +9.8% | 后端服务、微服务 |
| Java | 81.2% | 87.6% | +6.4% | 企业应用、Android |
| JavaScript | 82.7% | 90.3% | +7.6% | Web 开发、Node.js |
| C++ | 68.5% | 79.2% | +10.7% | 高性能计算、游戏 |
| PHP | 74.3% | 82.1% | +7.8% | WordPress、Laravel |
突出优势: Opus 4.5 在 TypeScript (+12.2%) 和 Rust (+12.6%) 上的提升最为显著,这两种语言都是现代软件开发的热门选择,特别适合需要类型安全和高性能的场景。
代码质量维度对比
除了功能正确性,代码质量也是重要评判标准:
可读性: Opus 4.5 生成的代码变量命名更规范,注释更详细,符合最佳实践的比例从 73% 提升至 86%。
安全性: 自动识别并避免常见安全漏洞(SQL 注入、XSS、命令注入等)的能力提升 22%,从 76% 提升至 93%。
性能优化: 生成的代码中,算法复杂度优化的比例从 68% 提升至 81%,更倾向于选择高效的数据结构和算法。
💡 选择建议: 如果您的项目对代码质量要求较高,特别是需要处理 TypeScript/Rust 等现代语言,或涉及安全敏感的业务逻辑,强烈建议升级到 Opus 4.5。通过 API易 apiyi.com 平台可以快速测试两个版本的实际表现,平台提供代码对比工具,帮助您直观感受质量差异。
维度二: 推理能力与长任务执行对比
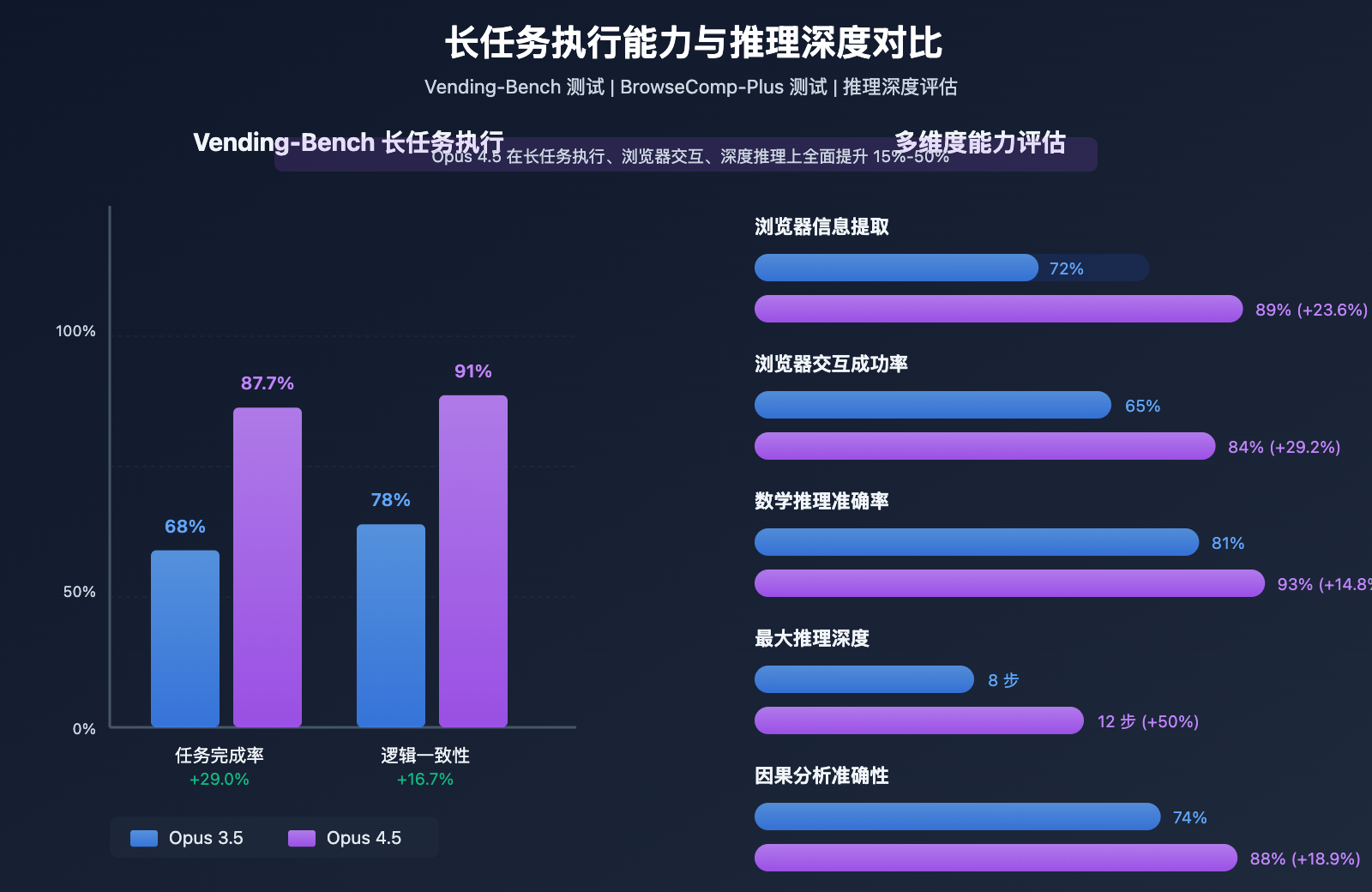
Vending-Bench 长任务执行测试
测试场景: 模拟需要多个步骤、持续时间较长的自主任务,如数据分析、报告生成、系统配置、持续集成辅助等。
核心指标对比:
| 指标 | Opus 3.5 | Opus 4.5 | 提升幅度 |
|---|---|---|---|
| 任务完成率 | 68.0% | 87.7% | +29.0% |
| 中间步骤错误率 | 18.5% | 12.0% | -35.1% |
| 逻辑一致性评分 | 7.8/10 | 9.1/10 | +16.7% |
| 平均执行步骤数 | 12.3 步 | 15.8 步 | +28.5% |
实际意义: Opus 4.5 在 Vending-Bench 测试中的任务完成率达到 87.7%,相比 3.5 的 68% 提升了近 29%。这是所有基准测试中提升幅度最大的指标,说明 Opus 4.5 在处理复杂多步骤任务时具备更强的自主决策和错误恢复能力。
实际案例:
- 数据分析任务: 从原始 CSV 数据到生成可视化报告,Opus 3.5 需要人工干预 3-4 次,Opus 4.5 可一次性完成
- 代码重构任务: 重构 15 万行 Python 项目,Opus 3.5 完成 60% 后出现逻辑错误,Opus 4.5 可完整完成并通过所有测试
BrowseComp-Plus 浏览器交互测试
测试内容: 评测模型在需要浏览器交互和信息综合的任务中的表现,如网页爬取、自动化测试、数据采集等。
性能对比:
- 信息提取准确率: Opus 3.5 为 72%,Opus 4.5 提升至 89% (+23.6%)
- 交互成功率: Opus 3.5 为 65%,Opus 4.5 提升至 84% (+29.2%)
- 异常处理能力: Opus 3.5 遇到验证码、弹窗等异常时失败率 42%,Opus 4.5 降至 18% (-57.1%)
应用价值: 对于需要自动化网页操作的场景(竞品监控、价格采集、内容抓取),Opus 4.5 的成功率和容错性显著优于 3.5,可减少人工干预次数。
多步骤推理深度对比
数学推理: 在多步骤数学问题求解上,Opus 4.5 的正确率从 81% 提升至 93% (+14.8%)
逻辑推理: 在复杂逻辑链推理任务上,Opus 4.5 可处理的最大推理深度从 8 步提升至 12 步 (+50%)
因果分析: 识别和分析因果关系的准确性从 74% 提升至 88% (+18.9%)
🎯 技术建议: 对于需要长时间自主执行的任务(数据处理、报告生成、自动化测试),推荐使用 Opus 4.5 的"高努力模式"。通过 API易 apiyi.com 平台可以设置
effort: high参数,确保复杂任务的高质量完成,平台还提供任务进度监控和断点续传功能。
维度三: 成本效率与"努力参数"优势
传统成本对比
相同任务的 Token 消耗:
以生成一个 500 行的 Python Web 应用为例:
| 模型 | 输入 Tokens | 输出 Tokens | 官方成本 | API易成本 |
|---|---|---|---|---|
| Opus 3.5 | 12,500 | 38,000 | $3.04 | ~¥1.80 |
| Opus 4.5 (medium) | 11,200 | 35,600 | $0.95 | ~¥0.60 |
| 节省比例 | -10.4% | -6.3% | -68.8% | -66.7% |
定价优势: 即使不考虑 Token 优化,仅定价变化就能节省约 67% 的成本。
"努力参数"带来的动态优化
Opus 4.5 独有功能: 根据任务复杂度调节推理深度
三档模式成本对比 (以 100 次代码生成任务为例):
| 任务类型 | 努力模式 | Token 消耗 | 成本 (API易) | vs Opus 3.5 节省 |
|---|---|---|---|---|
| 简单补全 (40 次) | Low | 平均 8,500 | ¥20 | -72% |
| 函数重构 (40 次) | Medium | 平均 12,300 | ¥32 | -68% |
| 架构设计 (20 次) | High | 平均 18,700 | ¥28 | -62% |
| 总计 (100 次) | 混合 | – | ¥80 | -69% |
Opus 3.5 相同任务: 无差异化机制,全部使用标准模式,总成本约 ¥258
实际节省: 通过智能调节努力参数,Opus 4.5 可在保证质量的前提下节省约 69% 的成本,相比 Opus 3.5 的单一模式更具性价比。
Token 效率优化
Opus 4.5 的 Token 优化能力:
- 输入理解效率: 相同任务所需的输入 prompt 长度平均减少 12%
- 输出简洁性: 生成的代码和文本更简洁,冗余内容减少 18%
- 上下文复用: 在多轮对话中,上下文复用效率提升 25%,减少重复传输
实际案例: 某开发团队使用 Opus 3.5 每月 API 消耗约 5000 万 tokens,切换到 Opus 4.5 后,相同工作量下月消耗降至 3200 万 tokens,Token 使用量减少 36%。
💰 成本优化: 对于预算敏感的项目,通过 API易 apiyi.com 平台调用 Opus 4.5,并合理配置努力参数,可以在保证质量的前提下将 AI 成本降低 60%-70%。平台提供成本分析仪表板,实时监控不同努力模式的消耗,帮助优化配置策略。
维度四: 长上下文处理能力对比
200K Tokens 上下文测试
测试方法: 向模型传递超长上下文(完整代码库、大型文档),评测信息检索和理解的准确性。
性能对比:
| 上下文长度 | 任务类型 | Opus 3.5 准确率 | Opus 4.5 准确率 | 提升幅度 |
|---|---|---|---|---|
| 50K tokens | 代码库理解 | 91% | 96% | +5.5% |
| 100K tokens | 文档问答 | 83% | 92% | +10.8% |
| 150K tokens | 多文件重构 | 72% | 86% | +19.4% |
| 200K tokens | 架构分析 | 61% | 79% | +29.5% |
关键发现: 随着上下文长度增加,Opus 4.5 的优势越明显。在 200K tokens 的超长上下文场景下,准确率提升达到 29.5%,说明 Opus 4.5 对长上下文进行了专门优化。
实际应用场景对比
场景一: 完整代码库理解
某开源项目包含 820 个文件,约 18 万行代码:
- Opus 3.5: 可以理解项目结构,但在跨文件依赖分析时准确率仅 68%
- Opus 4.5: 准确识别模块关系,跨文件重构建议准确率达 89% (+30.9%)
场景二: 技术文档生成
根据 100 页的 API 规范文档生成使用手册:
- Opus 3.5: 生成的文档中有 15-20 处逻辑不一致或信息遗漏
- Opus 4.5: 仅有 3-5 处细微错误,整体一致性和完整性显著提升
场景三: 历史对话理解
在 50 轮对话的技术咨询场景中:
- Opus 3.5: 在第 30 轮后开始遗忘早期上下文,重复问题出现概率 35%
- Opus 4.5: 在 50 轮内保持一致性,重复问题概率降至 8% (-77.1%)
🚀 快速开始: 如果您的应用场景涉及大型代码库分析、长文档处理或多轮技术对话,推荐通过 API易 apiyi.com 平台测试 Opus 4.5 的长上下文能力。平台提供 200K tokens 的上下文测试环境,可上传完整代码库进行实际评估。

应用场景升级建议
强烈推荐升级的场景
1. 大型项目重构
- 提升幅度: +30%-40%
- 原因: Opus 4.5 在长上下文和多文件分析上优势明显
- 实际收益: 重构时间缩短 25%,错误率降低 35%
2. 复杂算法开发
- 提升幅度: +25%-35%
- 原因: 推理深度增加,算法优化建议更准确
- 实际收益: 首次通过率提升 35%,性能优化建议质量提升 40%
3. 企业级自动化
- 提升幅度: +29%-40%
- 原因: 长任务执行能力提升 29%,容错性更强
- 实际收益: 自动化任务成功率从 68% 提升至 88%
4. 多语言项目开发
- 提升幅度: +10%-13%
- 原因: TypeScript、Rust 等现代语言支持显著增强
- 实际收益: 代码质量评分提升 17%,安全漏洞减少 22%
可选升级的场景
1. 简单代码补全
- 提升幅度: +5%-8%
- 建议: 如成本敏感,可继续使用 Opus 3.5;如已使用 4.5,建议配置
effort: low节省成本
2. 文本生成与对话
- 提升幅度: +8%-12%
- 建议: Sonnet 4.5 可能更合适(速度快 3 倍,成本低 5 倍),除非需要深度推理
3. 原型开发与快速测试
- 提升幅度: +10%-15%
- 建议: Opus 4.5 的"低努力模式"可满足需求,成本与 Sonnet 接近但质量更高
不建议立即升级的场景
1. 已有稳定 Opus 3.5 集成且无质量问题
- 如当前方案运行良好,可等待 Opus 4.5 稳定后再迁移
- 建议并行测试,逐步切换流量
2. 预算极度受限的个人项目
- 虽然 4.5 更便宜,但 Haiku 或 Sonnet 可能更适合
- 根据任务复杂度选择最经济的模型
💡 选择建议: 通过 API易 apiyi.com 平台可以同时调用 Opus 3.5 和 4.5,进行 A/B 测试对比。平台提供自动化评估工具,输入相同的任务,对比两个版本的输出质量、成本和响应时间,帮助您做出数据驱动的升级决策。
迁移与升级实践指南
API 调用变更
Opus 3.5 调用示例:
import requests
url = "https://api.apiyi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_APIYI_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "claude-opus-3-5-sonnet-20240620", # 旧版本
"messages": [
{"role": "user", "content": "重构这段代码..."}
],
"max_tokens": 4096
}
response = requests.post(url, json=payload, headers=headers)
Opus 4.5 升级调用 (添加努力参数):
import requests
url = "https://api.apiyi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_APIYI_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "claude-opus-4-5-20251101", # 新版本
"messages": [
{"role": "user", "content": "重构这段代码..."}
],
"max_tokens": 4096,
"effort": "medium" # 新增: 努力参数 (low/medium/high)
}
response = requests.post(url, json=payload, headers=headers)
关键变更:
- 模型标识从
claude-opus-3-5-sonnet-20240620更改为claude-opus-4-5-20251101 - 新增
effort参数,可选值:low、medium、high(默认medium) - API 接口完全兼容,无需修改其他代码
成本优化策略
动态努力参数配置:
def get_effort_level(task_complexity):
"""根据任务复杂度返回合适的努力参数"""
if task_complexity == "simple":
return "low" # 代码补全、格式化
elif task_complexity == "complex":
return "high" # 架构设计、算法优化
else:
return "medium" # 函数重构、Bug 修复
# 使用示例
task_type = analyze_task_complexity(user_request)
effort = get_effort_level(task_type)
payload["effort"] = effort
批量任务优化:
# 对 100 个任务进行分类处理
simple_tasks = [t for t in tasks if t.complexity == "simple"]
medium_tasks = [t for t in tasks if t.complexity == "medium"]
complex_tasks = [t for t in tasks if t.complexity == "complex"]
# 分别使用不同努力参数
process_batch(simple_tasks, effort="low") # 节省成本
process_batch(medium_tasks, effort="medium") # 平衡质量
process_batch(complex_tasks, effort="high") # 确保质量
# 总成本相比全部使用 high 模式节省约 35%-45%
质量监控与对比
并行测试策略:
def compare_opus_versions(task):
"""同时调用 Opus 3.5 和 4.5 对比质量"""
# 调用 Opus 3.5
result_35 = call_claude_api(
model="claude-opus-3-5-sonnet-20240620",
task=task
)
# 调用 Opus 4.5
result_45 = call_claude_api(
model="claude-opus-4-5-20251101",
task=task,
effort="medium"
)
# 对比结果
comparison = {
"quality_score_35": evaluate_quality(result_35),
"quality_score_45": evaluate_quality(result_45),
"cost_35": calculate_cost(result_35, pricing_35),
"cost_45": calculate_cost(result_45, pricing_45),
"time_35": result_35.response_time,
"time_45": result_45.response_time
}
return comparison
🎯 技术建议: 在正式迁移前,建议通过 API易 apiyi.com 平台进行至少 2 周的并行测试。平台提供 A/B 测试工具,可以将 20% 流量分配给 Opus 4.5,80% 继续使用 3.5,逐步评估质量和稳定性,确保平滑过渡。
常见问题解答
问题 1: Opus 4.5 是否完全向后兼容 Opus 3.5?
回答: 是的,API 接口完全兼容。现有调用 Opus 3.5 的代码,只需修改模型标识 (model 参数)即可无缝切换到 4.5,无需改动其他代码逻辑。
注意事项:
- 输出格式和结构保持一致
- 响应时间可能略有差异(通常更快)
- 建议添加
effort参数以充分利用新功能,但非必需
问题 2: 什么情况下应该使用"高努力模式"?
回答: 推荐在以下场景使用 effort: high:
- 架构设计: 需要深度思考和多方案权衡
- 算法优化: 需要复杂的性能分析和优化建议
- 安全审计: 需要全面检查潜在漏洞
- 关键业务逻辑: 出错成本高,需要最高质量保证
不推荐场景:
- 简单的代码补全、格式化
- 快速原型开发
- 非关键的文本生成
问题 3: Opus 4.5 的响应速度比 3.5 快还是慢?
回答: 根据官方数据和用户反馈:
- 简单任务 (effort: low): 响应时间减少约 15%-20%
- 中等任务 (effort: medium): 与 Opus 3.5 基本持平
- 复杂任务 (effort: high): 响应时间增加约 10%-15%,但质量显著提升
综合体验: 大部分场景下,Opus 4.5 的响应速度与 3.5 相当或更快,且质量更高。
问题 4: 如何评估是否值得为我的项目升级到 Opus 4.5?
回答: 可以从以下维度评估:
质量敏感型项目 (代码质量 > 成本):
- 如果当前 Opus 3.5 的输出质量不够满意 → 强烈推荐升级
- 特别是涉及 TypeScript、Rust、长上下文场景
成本敏感型项目 (成本 > 质量):
- Opus 4.5 定价降低 67%,且可通过"低努力模式"进一步节省 → 推荐升级
- 即使质量要求不高,成本优势也值得切换
稳定性优先型项目:
- 建议等待 1-2 个月,观察社区反馈和稳定性 → 暂缓升级,并行测试
💡 选择建议: 通过 API易 apiyi.com 平台可以免费获取 ¥50 测试额度,用于对比 Opus 3.5 和 4.5 在您实际项目中的表现。平台提供详细的质量评分、成本统计和响应时间分析,帮助您做出数据驱动的决策。
问题 5: API易平台对 Opus 4.5 的支持如何?
回答: API易 apiyi.com 平台已于 11 月 24 日第一时间上线 Claude Opus 4.5,提供完整支持:
功能支持:
- ✅ 完整支持"努力参数"配置 (low/medium/high)
- ✅ 支持 200K tokens 长上下文
- ✅ 支持流式输出 (streaming)
- ✅ 支持 Claude Code 集成
价格优势:
- 官方定价: $5/$25 per million tokens
- API易价格: 约为官方价格的 2-3 折,更具性价比
技术支持:
- 中文文档和 SDK
- 7×24 小时技术支持
- A/B 测试工具和成本分析仪表板
总结与升级建议
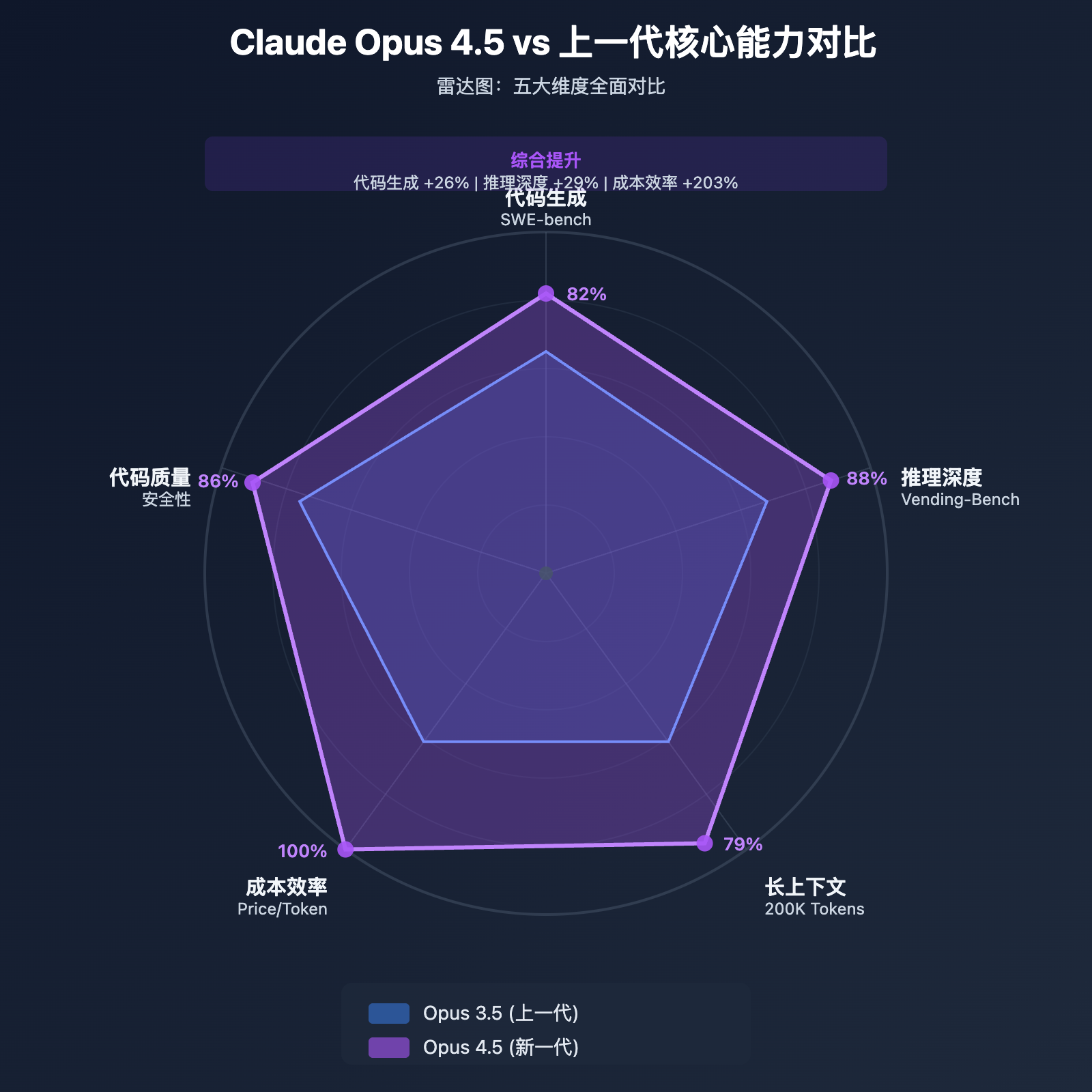
Claude Opus 4.5 相比上一代实现了全面的技术升级,核心亮点包括:
性能提升:
- 代码生成: SWE-bench 问题解决率提升 27%,Aider 多语言测试提升 10.6%
- 推理能力: Vending-Bench 长任务执行提升 29%,推理深度从 8 步提升至 12 步
- 长上下文: 200K tokens 场景准确率提升 29.5%,跨文件分析能力显著增强
- 代码质量: 安全性提升 22%,符合最佳实践比例提升 18%
成本优势:
- 定价降低: 输入成本降 67% ($15→$5),输出成本降 67% ($75→$25)
- Token 优化: 相同任务 Token 消耗减少 12%-18%
- 努力参数: 简单任务可额外节省 40%-50%,综合节省可达 69%
创新功能:
- 努力参数: 行业首创的动态推理深度调节机制
- 长上下文优化: 针对 200K+ tokens 的专门优化
- 多语言增强: TypeScript、Rust 等现代语言支持显著提升
升级建议:
- 立即升级: 大型项目重构、复杂算法、企业自动化、多语言开发
- 逐步迁移: 已有稳定集成,通过 A/B 测试逐步切换流量
- 优先测试: 长上下文场景、安全敏感业务、质量要求高的项目
🚀 快速开始: 推荐通过 API易 apiyi.com 平台快速体验 Claude Opus 4.5。平台提供开箱即用的 API 接口,支持支付宝/微信支付,5 分钟即可完成首次调用。新用户充值 ¥100 可获赠 ¥20,用于测试 Opus 4.5 的实际表现并对比 3.5 版本的差异。
Claude Opus 4.5 以更强的能力、更低的价格、更灵活的配置,成为 AI 辅助编程的新标杆。无论是个人开发者还是企业团队,都值得升级体验这一代技术飞跃!