站长注:了解如何在Cherry Studio、Chatbox等对话客户端中通过新开对话避免上下文自动带入,有效节省API调用的Token消耗和费用。
在使用Cherry Studio、Chatbox等对话客户端连接大模型API时,很多用户习惯在同一个对话中连续提问不同主题,却忽略了这会导致Token用量激增,不仅影响响应速度,还会大幅增加API调用成本。本文将分享一个简单却非常实用的技巧:不同主题时新开对话,帮助你优化Token使用,避免不必要的费用浪费。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 Claude、GPT、Gemini 等全系列模型,让AI对话更经济更高效
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
API Token消耗问题背景介绍
当我们使用对话客户端如Cherry Studio或Chatbox调用大模型API时,每次请求都会消耗一定数量的Token。Token是计费的基本单位,通常按照输入Token和输出Token分别计费。许多用户在使用过程中会遇到以下问题:
- 对话越长,费用越高:长对话历史会被完整传递给API
- Context窗口限制:模型存在上下文窗口大小限制
- 错误频发:超出限制时出现400错误,如下图所示
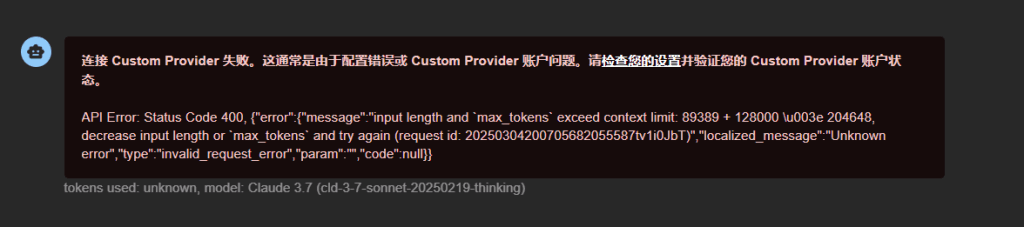
上图展示了一个典型的Token超限错误:
API Error: Status Code 400. {"error":{"message":"input length and `max_tokens` exceed context limit: 89389 + 128000 \u003e 204648. decrease input length or `max_tokens` and try again (request id: 202503042007058820555871vi0JbT)","localized_message":"Unknown error","type":"invalid_request_error","param":"","code":null}}
tokens used: unknown, model: Claude 3.7 (cid-3-7-sonnet-20250219-thinking)
这个错误表明,输入长度(89389 tokens)加上请求的最大输出长度(128000 tokens)超过了模型的上下文限制(204648 tokens)。这种情况下,即使API调用失败,很多平台仍会按输入Token收费,造成不必要的浪费。
API Token优化核心方法
不同主题新开对话的原则
最重要的Token节省技巧是:当切换到新主题时,应当新建对话,而不是在原对话中继续。
为什么这个简单的习惯如此重要?
- 避免历史累积:每次在同一对话中发送新消息,客户端会将整个对话历史作为上下文发送给API
- 减少无关信息:不同主题的对话混在一起,导致大量与当前提问无关的Token被计费
- 提高响应速度:减少输入Token数量,API处理速度更快
让我们通过一个实例来理解这个问题:
API Token消耗对比实例
假设用户连续进行三个不同主题的对话:
| 对话主题 | 单次提问Token | 在同一对话中累积Token | 分别新开对话的Token |
|---|---|---|---|
| Python编程问题 | 200 | 200 | 200 |
| 历史知识咨询 | 150 | 200+150+300=650 | 150 |
| 旅游建议 | 180 | 650+180+400=1230 | 180 |
| 总计费Token | 530 | 2080 | 530 |
可以看到,同样的三个问题:
- 在同一对话中累积提问:消耗2080个Token
- 分别新开对话:仅消耗530个Token
差距高达393%!
API Token消耗优化的最佳实践
1. 何时应该新开对话
遵循以下原则来决定是否新开对话:
- 主题完全不同:从技术问题切换到创意写作
- 时间间隔较长:上次对话已经过去数小时或数天
- 参考不同资料:需要模型关注新的信息源
- 收到Context限制警告:API返回任何与上下文长度相关的警告
2. 何时可以继续当前对话
以下情况可以继续在当前对话中:
- 主题紧密相关:对同一问题进行深入探讨
- 需要模型记住之前的细节:如编程过程中的代码修改
- 需要引用前文内容:如”基于我之前提到的那个方案…”
3. API Token优化实用技巧
除了新开对话外,还可以采用以下技巧进一步优化Token使用:
- 精简提问:避免冗长铺垫,直接切入主题
- 分段提问:将复杂问题拆分为多个简单问题
- 使用文件上传:支持文件上传的客户端可减少文本复制粘贴
- 选择合适模型:不同任务选择适合的模型版本
- 利用客户端摘要功能:部分客户端提供对话摘要功能,可减少历史传递
API Token优化应用场景
Cherry Studio中的Token优化
Cherry Studio是一款功能强大的AI对话客户端,在使用时可以:
- 点击左上角”+”按钮创建新对话
- 使用文件夹功能组织不同主题的对话
- 利用内置的对话导出功能保存重要对话记录
Chatbox中的Token优化
Chatbox作为轻量级客户端,可以通过以下方式优化Token使用:
- 点击侧边栏”New Chat”按钮开始新对话
- 利用会话存档功能保存重要对话
- 合理设置”Max Tokens”参数控制输出长度
API开发者的Token优化
对于直接调用API的开发者:
- 实现对话管理机制,为用户提供”新建对话”选项
- 设计上下文压缩算法,只保留重要历史信息
- 实现智能分流,根据主题自动决定是否传递完整历史
API Token消耗常见问题
Q1: 如何知道我当前对话已经消耗了多少Token?
大多数客户端会显示当前对话的Token使用情况。例如,Cherry Studio在每次回复后会显示输入和输出Token数量。也可以通过API响应的usage字段查看详细用量。
Q2: 有没有自动检测应该新开对话的工具?
目前部分高级客户端正在开发基于主题变化的自动对话分割功能。在此之前,可以留意:
- 对话长度超过一定条数时的提醒
- API返回的Token用量警告
- 系统提示中的相关建议
Q3: 新开对话会不会影响模型对我需求的理解?
对于真正新主题的提问,新开对话反而会减少噪音,提高理解准确度。如果需要保持连贯性,可以在新对话开始时简要总结前文关键信息。
为什么选择 API易 AI大模型聚合平台
在实践Token优化技巧时,选择合适的API提供商同样重要。API易作为领先的大模型API聚合平台,提供以下优势:
- 精确的Token计费
- 透明的Token计数机制
- 失败请求不计费策略
- 详细的用量分析报告
- 丰富的模型支持
- 支持Claude、GPT、Gemini等主流模型
- 不同价格档位满足各种需求
- 一键切换不同模型比较效果
- 专业的开发支持
- 提供Token优化最佳实践指南
- 技术团队协助解决超限问题
- 定制企业级解决方案
- 性价比优势
- 新用户赠送体验额度
- 大客户折扣政策
- 不限速调用体验
提示:在API易平台,可以通过以下方式进一步节省Token:
- 使用经济型模型处理简单任务
- 批量请求享受更优惠的价格
- 利用流式请求提前终止不需要的长回复
- 定期查看用量报告,优化使用习惯
API Token优化总结
掌握”不同主题新开对话”这一简单技巧,可以显著降低API调用成本,提高模型响应速度,避免上下文限制错误。在日常使用对话客户端时:
- 养成主题切换时新建对话的习惯
- 定期整理和归档已完成的对话
- 关注Token用量,做到心中有数
- 根据不同任务选择合适的模型和参数
通过这些实践,你可以在不降低AI助手质量的前提下,将API调用成本降低高达75%,同时获得更流畅的使用体验。
欢迎免费试用 API易,3 分钟跑通 API 调用,体验高效经济的大模型服务 www.apiyi.com
加站长个人微信:8765058,获取更多AI使用技巧与优惠。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和使用技巧。