إن أصعب ما يواجه صناع المحتوى على منصة "شياوهونغشو" (Xiaohongshu) ليس كتابة النصوص، بل تصميم الصور. فغلاف المنشور الواحد يجب أن يحتوي على العنوان، والعنوان الفرعي، ونقاط البيع، والعلامة التجارية، وعناصر الزينة، مما يجعل كثافة المعلومات فيه تضاهي الرسوم البيانية (Infographics). ومع استخدام أدوات مثل Canva للتصميم، وFigma للتنسيق، وPhotoshop للتعديل، تستغرق العملية برمتها ساعتين على الأقل.
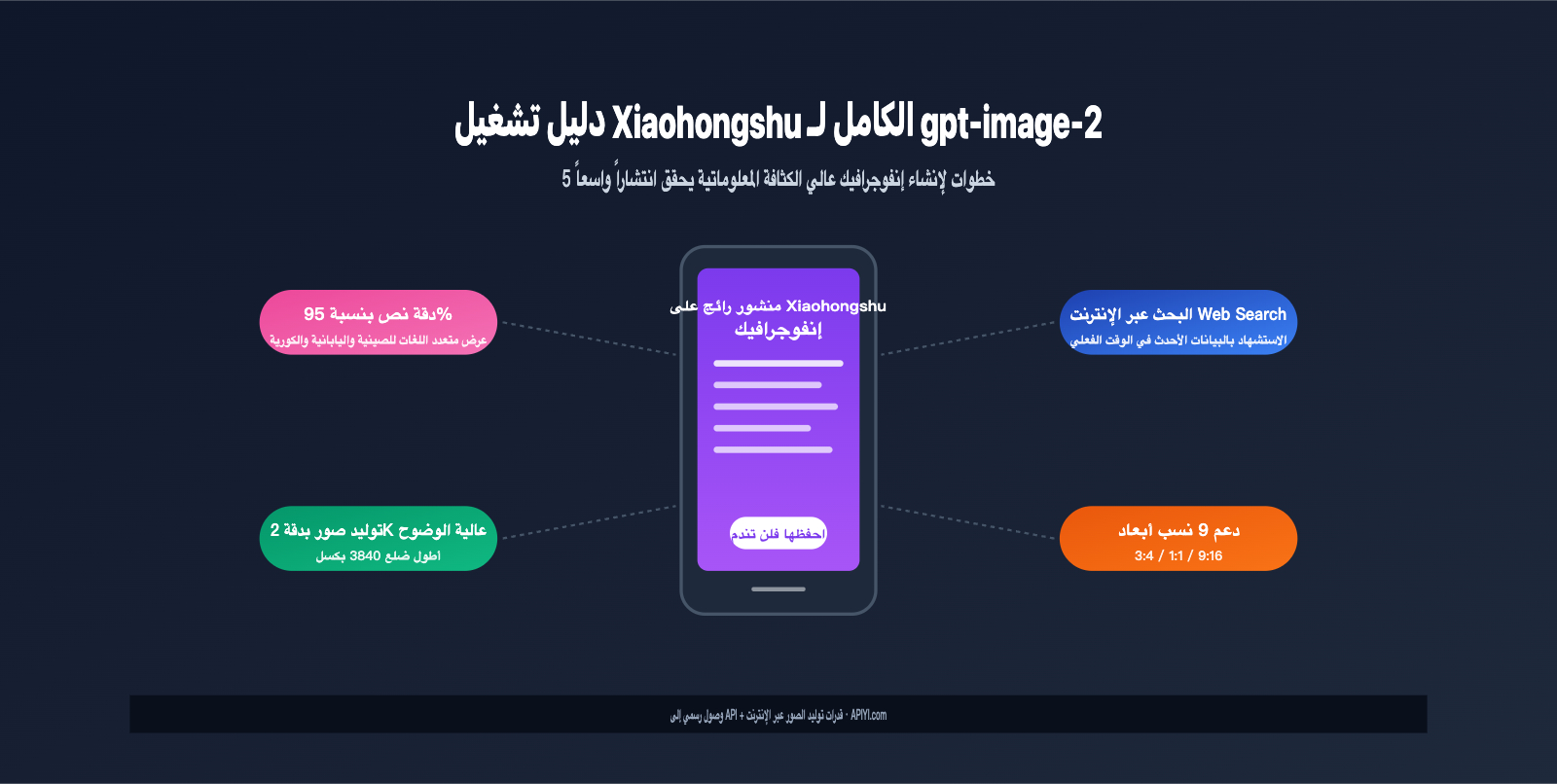
لقد غير نموذج gpt-image-2، الذي أطلقته OpenAI في أبريل 2026، قواعد اللعبة تماماً. فهو لم يرفع دقة عرض النصوص داخل الصور إلى أكثر من 95% فحسب، بل أصبح لأول مرة يتمتع بقدرات "الوكيل الذكي" (Agentic) التي تجمع بين "البحث عبر الإنترنت + الاستنتاج وتوليد الصور". فعندما تطلب منه "صنع صورة مقارنة لألوان هاتف iPhone 17 الجديد"، سيقوم النموذج أولاً بالبحث عن البيانات الرسمية، ثم يولد صورة عالية الكثافة تحتوي على الطرازات والألوان والمواصفات الحقيقية.
سيشرح هذا المقال بشكل منهجي استراتيجية إنشاء محتوى "شياوهونغشو" باستخدام gpt-image-2، بدءاً من تحليل القدرات الأساسية، مروراً بخطوات العمل الخمس، وصولاً إلى قوالب الموجه (Prompt) والأسئلة الشائعة، لمساعدتك في تقليص وقت التصميم من ساعتين إلى 5 دقائق فقط.
لماذا تعد قدرة gpt-image-2 على إنشاء محتوى "شياوهونغشو" متميزة جداً؟
قبل ظهور gpt-image-2، كان صناع المحتوى على "شياوهونغشو" يواجهون ثلاث عقبات رئيسية عند استخدام الذكاء الاصطناعي: عدم دقة عرض النصوص، عدم القدرة على استيعاب كثافة المعلومات، وتأخر حداثة المعرفة. فغلاف المنشور الناجح يتطلب عادةً ما بين 50 إلى 100 حرف، بينما كانت النماذج السابقة (بما في ذلك gpt-image-1 وMidjourney v6) تولد نصوصاً مليئة بالأخطاء الإملائية، أو نقص في الخطوط، أو تشوه في الحروف، مما يجعلها غير صالحة للاستخدام المباشر.
لقد أحدث gpt-image-2 تغييراً جذرياً في هذا الوضع بفضل ثلاث طفرات تقنية. أولاً، الترقية الشاملة لمحرك عرض النصوص؛ فوفقاً لاختبارات OpenAI الرسمية، تجاوزت دقة العرض عالي الدقة للنموذج في اللغات غير اللاتينية (مثل الصينية، اليابانية، الكورية، الهندية، والبنغالية) نسبة 95%، مما يتيح مخرجات مستقرة حتى في الخطوط الصغيرة أو التصاميم المعقدة.
ثانياً، بنية "الاستنتاج الوكيل" (Agentic Reasoning). يعد gpt-image-2 أول نموذج صور في الصناعة يمتلك حلقة استنتاج كاملة تتضمن "التفكير ← البحث ← التوليد ← التحقق"، حيث يقوم النموذج قبل التوليد بالتخطيط النشط للتكوين، والبحث عن مراجع، وتقييم الجودة.
ثالثاً، المعرفة المدمجة بالإنترنت. عند إنشاء صور تتعلق بأحدث المنتجات، أو شعارات العلامات التجارية، أو الشخصيات، أو الأحداث الرائجة، يمكن للنموذج البحث في الإنترنت لحظياً، بدلاً من الاعتماد على البيانات القديمة التي توقفت عند تاريخ التدريب (ديسمبر 2025).
💡 توصية المنصة: إذا كنت ترغب في تجربة قدرة gpt-image-2 على توليد الصور عبر الإنترنت مباشرة، يمكنك استخدام نموذج gpt-image-2-all المتاح عبر منصة APIYI (apiyi.com) — وهي نسخة تم ربطها عكسياً من واجهة ChatGPT الرسمية، حيث يتم تفعيل البحث عبر الإنترنت افتراضياً دون الحاجة إلى إعدادات إضافية، مما يجعلها مثالية لسيناريوهات إنشاء محتوى "شياوهونغشو" التي تتطلب "حداثة المعرفة".
تحليل القدرات الجوهرية لـ gpt-image-2 في منصة "شياوهونغشو" (Xiaohongshu)
لفهم سبب ملاءمة gpt-image-2 لمنصة "شياوهونغشو" بشكل خاص، نحتاج إلى تفكيك أبعاد قدراته ومدى توافقها مع طبيعة المحتوى على المنصة. يوضح الجدول التالي مقارنة بين gpt-image-2 والجيل السابق gpt-image-1 من حيث التحسينات في السيناريوهات الرئيسية لـ "شياوهونغشو".
| بُعد القدرة | gpt-image-1 | gpt-image-2 | القيمة في سيناريو شياوهونغشو |
|---|---|---|---|
| عرض النصوص الصينية | دقة 60-70%، أخطاء متكررة | دقة 95%+، استقرار في النصوص المنحنية | جاهزة للاستخدام في عناوين الغلاف والرسوم البيانية |
| عدد الصور في المرة الواحدة | صورة واحدة | 1-10 صور اختيارية | إنشاء عرض شرائح كامل من 9 صور دفعة واحدة |
| أقصى دقة | 1024×1024 | 2K (أطول ضلع 3840 بكسل) | تلبية متطلبات الغلاف عالي الدقة بنسبة 3:4 |
| دعم نسب العرض | 3 نسب | 9 نسب (بما في ذلك 3:4) | توافق مثالي مع نسب غلاف شياوهونغشو |
| المعرفة عبر الإنترنت | لا يوجد | بحث ويب مدمج | استشهاد دقيق بأحدث المنتجات والاتجاهات |
| الاستنتاج البصري | لا يوجد | استنتاج وكيلي (Agentic) | تخطيط تلقائي لتنسيق الرسوم البيانية المعقدة |
ميزة gpt-image-2 في شياوهونغشو 1: عرض الرسوم البيانية عالية الكثافة
تعد "الرسوم البيانية للمعلومات" و"بطاقات المحتوى المفيد" و"صور التوعية" من أنواع المحتوى ذات التفاعل العالي على شياوهونغشو، وتتميز عادةً باحتواء الصورة الواحدة على 80-150 كلمة، مما يتطلب تسلسلاً هرمياً واضحاً وتنسيق ألوان وأيقونات دقيقة. تأتي تحسينات gpt-image-2 في هذا السياق من ثلاث تفاصيل:
أولاً، تدرج حجم الخط. يمكن للنموذج فهم أوامر التنسيق مثل "العنوان الرئيسي 60 نقطة + العنوان الفرعي 32 نقطة + النص الأساسي 18 نقطة"، مما يضمن استقرار نسب أحجام الخطوط في النتائج.
ثانياً، التحكم في المساحات البيضاء. يقوم الاستنتاج الوكيلي (Agentic Reasoning) بإجراء "تنسيق افتراضي" قبل الرسم، لتجنب تكدس النصوص أو قصها عند الحواف.
ثالثاً، تنسيق الأيقونات والنصوص. يمكن للنموذج إدراج أيقونات مقابلة (مثل ✓، ★، →، وشارات الأرقام) في مواقع محددة، مما يضمن محاذاة الأيقونات مع النصوص بدقة.
ميزة gpt-image-2 في شياوهونغشو 2: ضمان الدقة عبر المعرفة المتصلة بالإنترنت
هذه هي القدرة الأكثر استخفافاً في gpt-image-2. تتوقف معرفة نماذج الذكاء الاصطناعي التقليدية عند بيانات التدريب، لذا عند طلب محتوى مثل "مقارنة ألوان iPhone 17" أو "ترتيب مقاهي 2026" أو "أحدث اتجاهات التجميل"، فمن المحتمل جداً أن يختلق معلومات خاطئة.
في مرحلة "التفكير" الداخلية، يحدد gpt-image-2 ما إذا كانت المهمة تتطلب معلومات خارجية. إذا لزم الأمر، فإنه يقوم تلقائياً بتشغيل بحث ويب، ويدمج البيانات الحقيقية التي تم استردادها (معلمات المنتج، شكل الشعار، الألوان الرسمية) في عملية توليد الصورة. وهذا يعني أنه يمكن لمدوني شياوهونغشو استخدامه بثقة لمقارنة المنتجات، وتوصيات المنتجات الجديدة، والمحتوى التثقيفي للعلامات التجارية، دون القلق بشأن "هلوسة" الذكاء الاصطناعي.
🎯 نصيحة للوصول إلى API: يتطلب استخدام وظيفة الاتصال بالإنترنت في gpt-image-2 منصة وسيطة تدعم قدرات API الكاملة. نوصي بالوصول إلى نموذج
gpt-image-2-allعبر APIYI (api.apiyi.com). يأتي هذا النموذج من القناة الرسمية المعكوسة، ويحمل قدرة البحث عبر الإنترنت افتراضياً، كما أن سعره أكثر ملاءمة مقارنة بالاتصال المباشر بـ API الرسمي، مما يجعله مثالياً لصناع المحتوى لإنتاج الصور بكميات كبيرة.
ميزة gpt-image-2 في شياوهونغشو 3: نسب متعددة وإخراج صور متعددة
النسبة القياسية لغلاف شياوهونغشو هي 3:4 (عمودي)، بينما المربع 1:1 مناسب لبطاقات المعلومات، و9:16 مناسب لأغلفة الفيديوهات القصيرة. يدعم gpt-image-2 هذه النسب الثلاث أصلياً (بالإضافة إلى 1:1، 2:3، 3:2، 4:3، 4:5، 16:9، 21:9، بإجمالي 9 نسب)، دون الحاجة إلى قص لاحق.
والأهم من ذلك، يدعم gpt-image-2 توليد 1-10 صور في طلب واحد. الطول الأمثل لمنشورات شياوهونغشو هو 6-9 صور (وهو ما يمنح وزناً أكبر في الخوارزمية)، ويمكن للمدونين طلب إنشاء عرض شرائح كامل بناءً على موضوع واحد دفعة واحدة، مما يحافظ على اتساق النمط البصري.

مصفوفة مواءمة محتوى Xiaohongshu لنموذج gpt-image-2
تختلف متطلبات الصور باختلاف أنواع المحتوى على منصة Xiaohongshu. يساعدك الجدول التالي في تحديد مدى ملاءمة نموذج gpt-image-2 لكل شكل من أشكال المحتوى والمعايير الموصى بها بسرعة.
| نوع المحتوى | النسبة الموصى بها | عدد الصور | كثافة النصوص | ملاءمة gpt-image-2 | الجودة الموصى بها |
|---|---|---|---|---|---|
| رسوم توضيحية معرفية | 3:4 | 6-9 صور | عالية (80-150 كلمة/صورة) | ⭐⭐⭐⭐⭐ | high |
| بطاقات تقييم المنتجات | 3:4 | 6-9 صور | متوسطة (40-80 كلمة/صورة) | ⭐⭐⭐⭐⭐ | high |
| صور خطوات تعليمية | 3:4 | 4-9 صور | متوسطة (50-100 كلمة/صورة) | ⭐⭐⭐⭐⭐ | medium-high |
| تصور البيانات | 3:4 / 1:1 | 1-3 صور | عالية (100+ كلمة/صورة) | ⭐⭐⭐⭐⭐ | high |
| ترشيحات الطعام/الأزياء | 3:4 | 6-9 صور | منخفضة (تعتمد على الوسوم) | ⭐⭐⭐⭐ | medium |
| غلاف Vlog | 9:16 | 1 صورة | متوسطة (تعتمد على العنوان) | ⭐⭐⭐⭐ | high |
| ملصقات/نكات | 1:1 | 1 صورة | منخفضة | ⭐⭐⭐ | low-medium |
من خلال مستوى الملاءمة، يتضح أن gpt-image-2 يتفوق في المحتوى المعلوماتي ذي الكثافة النصية المتوسطة إلى العالية، وهو بالضبط نوع المحتوى الذي يفضله خوارزمية Xiaohongshu بسبب "معدل الحفظ المرتفع". وفقاً لوزن خوارزمية CES المعلن رسمياً من Xiaohongshu، يُحسب إجراء الحفظ بنقطة واحدة، وهو يعادل الإعجاب في الأهمية، بينما تُحسب التعليقات والمشاركات بـ 4 نقاط لكل منهما. نظراً لـ "قيمتها العملية"، فإن معدل حفظ الرسوم التوضيحية، والدروس، وتقييمات المنتجات أعلى بكثير من الأنواع الأخرى، مما يمنحها وصولاً أكبر للمشاهدات الطبيعية في التوزيع الخوارزمي.
عملية العمل المكونة من 5 خطوات لإنشاء صور Xiaohongshu باستخدام gpt-image-2
لننتقل الآن إلى الجانب العملي. تنقسم عملية إنشاء صور Xiaohongshu الكاملة باستخدام gpt-image-2 إلى 5 خطوات، ولكل خطوة تقنيات قابلة لإعادة الاستخدام.
الخطوة 1: تفكيك الموضوع وتخطيط كثافة المعلومات
قبل فتح gpt-image-2، اقضِ 5 دقائق في تفكيك الموضوع. يجب أن تجيب ملاحظة Xiaohongshu المعلوماتية الجيدة على ثلاثة أسئلة:
- من هو القارئ المستهدف (مبتدئ / متقدم / صانع قرار)
- ما هي المعلومات الأساسية (3 نقاط / 5 نقاط / 7 نقاط)
- كمية المعلومات في كل صورة (صورة لكل فكرة / صورة للمقارنة)
مثال: عند إعداد ملاحظة حول "مقارنة أدوات الرسم بالذكاء الاصطناعي لعام 2026"، يمكن تقسيمها إلى 9 صور: غلاف واحد + جدول نظرة عامة واحد + 5 صور لتقديم الأدوات (صورة لكل أداة) + صورة واحدة للنتائج الموصى بها + صورة واحدة لدعوة لاتخاذ إجراء. يجب التحكم في المعلومات الأساسية لكل صورة بحيث لا تتجاوز 80 كلمة.
الخطوة 2: كتابة موجه (Prompt) منظم لـ gpt-image-2
توجد بنية موصى بها رسمياً لكتابة الموجه في gpt-image-2: الخلفية/المشهد ← الموضوع ← التفاصيل الرئيسية ← المحتوى النصي ← قيود النمط. لجعل صور Xiaohongshu الناتجة مستقرة وقابلة للاستخدام، هناك 4 قواعد أساسية:
- يجب وضع النصوص الصينية المراد ظهورها داخل علامات اقتباس صينية 「」 أو إنجليزية ""، حتى يتمكن النموذج من عرضها بدقة.
- حدد مستوى حجم الخط بوضوح في الموجه (مثل "العنوان الرئيسي 64pt غامق، العنوان الفرعي 28pt").
- استخدم كلمات مفتاحية مثل "high-fidelity"، "ultra-detailed"، "crisp typography" لتعزيز التفاصيل.
- ضع قيوداً سلبية (مثل "no watermark, no extra text, no duplicate words") لتجنب الإضافات غير المرغوب فيها.
الخطوة 3: استدعاء API الخاص بـ gpt-image-2 لتوليد الصور
إذا كنت تمتلك مهارات أساسية في استدعاء API، يمكنك استخدام واجهة OpenAI القياسية لاستدعاء gpt-image-2 مباشرة. فيما يلي مثال برمجي بسيط لتوليد غلاف Xiaohongshu بنسبة 3:4:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='小红书风格信息图封面,3:4 竖版,主标题 「2026 AI 绘图工具 TOP 5」 64pt 白色加粗,副标题 「博主必看,收藏不亏」 28pt 浅灰色,中央展示 5 个工具 Logo 缩略图,粉色到紫色渐变背景,high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 ملاحظة حول إعداد base_url: يستخدم الكود أعلاه
api.apiyi.com/v1الخاص بـ APIYI كنقطة اتصال، واسم النموذجgpt-image-2-allهو النسخة العكسية الرسمية، والتي تدعم البحث عبر الإنترنت افتراضياً. يمكن للمستخدمين العاديين أيضاً استخدام النموذج القياسيgpt-image-2(بدون بحث)، وهو أقل تكلفة.
الخطوة 4: التوليد الجماعي لـ 9 صور (عرض شرائح)
العدد الأمثل للصور في ملاحظات Xiaohongshu هو 6-9 صور. إذا قمت بكتابة الموجه يدوياً لكل صورة، فستكون الكفاءة منخفضة جداً. يدعم المعامل n في gpt-image-2 القيم من 1 إلى 10، مما يسمح بتوليد 9 صور دفعة واحدة.
لكن هناك خدعة هنا: لا تجعل النموذج يولد 9 صور غير مترابطة بشكل مستقل، بل وجهه عبر الموجه لتوليد "سلسلة صور". مثال:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''生成一组 9 张连贯的小红书科普轮播图,3:4 竖版,
统一深紫色背景 + 白色文字,主题"AI 绘图新手必学的 5 个 Prompt 公式",
图 1: 封面页,标题 「AI 绘图必学」 副标题 「5 个 Prompt 公式」,
图 2-6: 每张介绍一个公式,顶部编号 01-05,中部公式名称,下部 30 字解释,
图 7: 公式对比表格,
图 8: 实战案例展示,
图 9: 关注引导页,文字 「点赞收藏不迷路」 ''',
size="1024x1536",
quality="high",
n=9
)
الخطوة 5: لا تجيد البرمجة؟ استخدم أداة الويب imagen.apiyi.com
إذا كنت صانع محتوى خالصاً وليس لديك خبرة في Python أو استدعاء API، يمكنك تخطي جانب البرمجة تماماً. نوصي باستخدام أداة الويب imagen.apiyi.com، فهي تضم نماذج صور رئيسية مثل gpt-image-2، وNano Banana، وSeedream، وتوفر واجهة تعبئة نماذج سهلة الاستخدام، مع دعم اختيار النسبة، والتحكم في عدد الصور، والتحميل الجماعي، ويمكنك البدء في استخدامها خلال 5 دقائق.
🎨 نصيحة اختيار الأداة: لصناع المحتوى، نوصي باستخدام أداة الويب imagen.apiyi.com مباشرة – لا حاجة لكتابة كود أو إعداد API، فقط اختر النموذج (نوصي بـ gpt-image-2 أو gpt-image-2-all) والنسبة (3:4) للبدء في التوليد. أما بالنسبة للاستوديوهات التي تحتاج إلى أتمتة جماعية، فنوصي باستدعاء API عبر APIYI (apiyi.com)، حيث يمكن ربطه بأدوات SaaS الخاصة بك أو جداول بيانات Feishu.
مكتبة قوالب الموجه (Prompt) الأكثر رواجاً على "شياو هونغ شو" لـ gpt-image-2
فيما يلي 6 قوالب موجه تم اختبارها والتحقق من فعاليتها، وتغطي أكثر أنواع المحتوى شيوعاً على منصة "شياو هونغ شو" (Xiaohongshu). جميع القوالب محسنة لتقديم نصوص واضحة ومباشرة، يمكنك نسخها واستخدامها، مع استبدال ما بداخل الأقواس 【】 بالموضوع الخاص بك.
القالب 1: بطاقة المعرفة العلمية (أعلى كثافة معلوماتية)
小红书风格知识科普卡片,3:4 竖版,
顶部标题栏:深紫色背景,白色加粗中文标题 「【你的主标题,15 字内】」 字号 56pt,
副标题 「【一句话价值描述,20 字内】」 字号 24pt 浅紫色,
中部内容区:5 个编号要点,每个要点包含数字徽章 + 标题 + 30 字解释,
底部:粉色 CTA 按钮 「收藏不迷路」,
配色:深紫主色 #2D1B69,亮粉强调色 #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
القالب 2: بطاقة مقارنة تقييم المنتجات
小红书产品测评对比卡,3:4 竖版,白色背景,
顶部:左右两个产品图 + 产品名 「【产品 A】」 vs 「【产品 B】」,
中部:5 行对比表格,每行包含维度名 + A 评分 + B 评分,
评分使用 5 颗星图标(★)显示,
底部:推荐结论 「综合推荐:【产品名称】」,
字体清晰锐利,表格线条 1px 浅灰,主标题加粗 48pt,
high-fidelity, ultra-detailed, no extra elements
القالب 3: صورة خطوات تعليمية
小红书教程步骤示意图,3:4 竖版,米色温暖背景,
顶部主标题 「【主题】3 分钟搞定」 黑色加粗 56pt,
中部:3 个步骤区块垂直排列,
每个区块:左侧大号步骤数字(01/02/03),右侧步骤标题 + 25 字说明,
底部:成果展示图 + 文字 「完成!」,
手绘插画风格图标,温暖橙黄色强调色,
crisp typography, clear hierarchy, no watermark
القالب 4: مخطط تصور البيانات
小红书数据卡片,3:4 竖版,深蓝色渐变背景,
顶部标题 「【数据主题】2026 最新数据」 白色 52pt,
中部:1 个核心大数字 「【关键数字】」 占据画面 40% 高度,
数字下方:数据来源说明 12pt 浅蓝色,
中下部:3 行小数据补充,每行包含图标 + 数据 + 简短说明,
底部:浅色 CTA 「转发分享给同事」,
配色:深蓝 #0F172A 到 #1E40AF 渐变,白色高对比文字,
high-fidelity typography, crisp small text, no extra words
القالب 5: صورة قائمة المراجعة (قائمة المهام)
小红书干货清单封面,3:4 竖版,
顶部:荧光绿色横条,黑色加粗文字 「【数字】个【主题】」 60pt,
副标题 「博主私藏,看完直接抄作业」 24pt,
中部:【数字】个清单项目,每项包含 ✓ 图标 + 项目名,
排版紧凑但留白合理,字号梯度清晰,
底部:粉色边框 + 文字 「完整清单看下一张」,
风格:简洁现代,Notion 风格排版,
high-fidelity Chinese text, crisp icons, no decorative noise
القالب 6: مشهد خاص لتوليد الصور المتصل بالإنترنت (خاص بـ gpt-image-2-all)
小红书新品种草卡,3:4 竖版,
主题:介绍【最新产品名,如 iPhone 17 Pro Max】,
请联网查询该产品的最新官方配色、关键参数、发布日期,
顶部:产品真实外观渲染图,
中部:产品名 + 3 行核心卖点(配色/容量/价格),
底部:种草文案 「值得入手吗?看完再决定」,
风格:Apple Style 简洁,白色背景,
high-fidelity, accurate product details from web search, no fictional specs
💡 نصائح استخدام القوالب: تمت تهيئة جميع القوالب المذكورة أعلاه لتقديم نصوص صينية دقيقة. نوصي باستخدام
quality="medium"عند الاستخدام لأول مرة لاختبار التنسيق، وبعد التأكد من أن التخطيط معقول، انتقل إلىquality="high"لاستخراج النسخة النهائية، مما يوفر 30-40% من التكاليف. للإنتاج الضخم، يُنصح بالاتصال عبر خدمة وكيل API الخاص بـ APIYI (apiyi.com)، حيث يتفوق في الاستقرار والسرعة على الاتصال المباشر.
مقارنة قدرات gpt-image-2 مقابل أدوات التصميم التقليدية في "شياو هونغ شو"
يتساءل الكثير من صناع المحتوى: بوجود Canva وFigma وPhotoshop، لماذا يجب أن نتحول إلى gpt-image-2؟ يوضح الجدول أدناه الكفاءة الفعلية لكل فئة من الأدوات في سيناريوهات التشغيل الأساسية لـ "شياو هونغ شو".
| بعد المقارنة | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| وقت إنتاج صورة واحدة | 30 ثانية – دقيقة | 15-30 دقيقة | 30-60 دقيقة | 1-2 ساعة |
| وقت إنتاج 9 صور متتالية | 5 دقائق (n=9) | 3-4 ساعات | 4-6 ساعات | 8+ ساعات |
| عرض النصوص الصينية | +95% دقة | 100% (يدوي) | 100% (يدوي) | 100% (يدوي) |
| القدرة على الإبداع | عالية (توليد AI) | متوسطة (قوالب) | منخفضة (من الصفر) | منخفضة (من الصفر) |
| المعرفة بالإنترنت | ✅ مدمجة | ❌ | ❌ | ❌ |
| عتبة التعلم | منخفضة (كتابة الصينية) | منخفضة | متوسطة | عالية |
| التكلفة الشهرية | $5-30 (حسب الاستخدام) | $12.99 شهرياً | $15 شهرياً | $22.99 شهرياً |
| السيناريوهات المناسبة | إنتاج ضخم، رسوم بيانية | قوالب جاهزة | تعاون الفريق | تصميم تجاري دقيق |
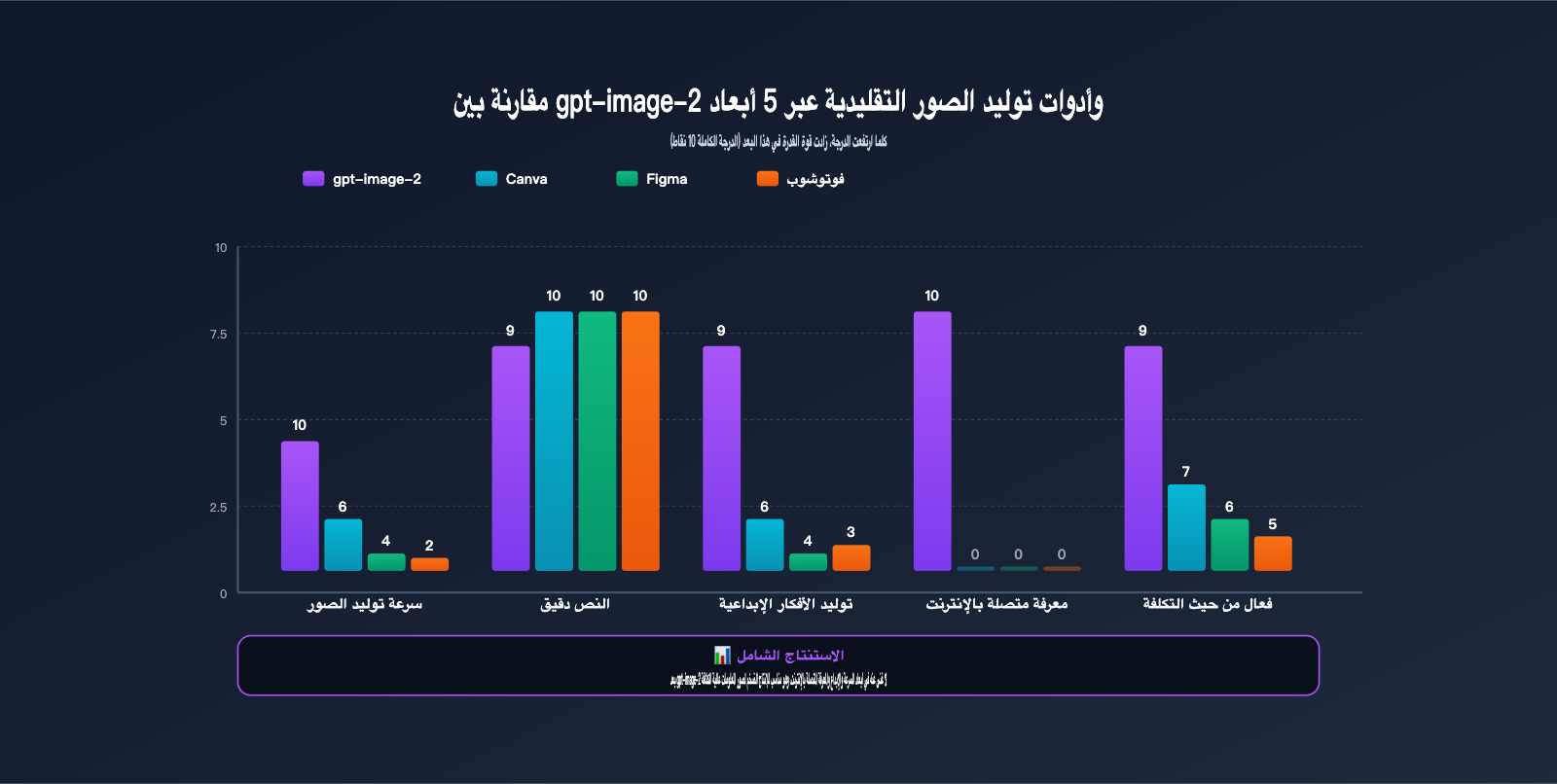
من جدول المقارنة، يمكن ملاحظة أن gpt-image-2 ليس بديلاً عن Canva/Figma، بل يغطي سيناريو جديداً تماماً: "توليد الأفكار + الإنتاج الضخم + المعرفة بالإنترنت" في حزمة واحدة. إذا كان حسابك على "شياو هونغ شو" يحتاج إلى نشر 3-5 مقالات مصورة أسبوعياً بشكل مستقر، يمكن لـ gpt-image-2 تقليص وقت عملية تصميم الصور من 8-10 ساعات إلى أقل من ساعة واحدة.
الأسئلة الشائعة حول تشغيل حسابات "شياو هونغ شو" (Xiaohongshu) باستخدام gpt-image-2
س1: هل حقاً لن يخطئ gpt-image-2 في النصوص الصينية عند توليد صور "شياو هونغ شو"؟
أظهرت الاختبارات الفعلية أن نسبة الدقة تتجاوز 95%. فقد أوضحت OpenAI في مدونتها الرسمية أن gpt-image-2 هو نموذج لغة كبير "متعدد اللغات" (polyglot)، مع تحسينات ملحوظة في اللغات الصينية واليابانية والكورية وغيرها من اللغات غير اللاتينية. ولكن تجدر الإشارة إلى أمرين: أولاً، يجب وضع النص الصيني في "الموجه" (Prompt) بين علامتي اقتباس (مثل "النص هنا")، وإلا فقد يتعامل معه النموذج كـ "فهم" بدلاً من "نسخ"؛ ثانياً، قد لا تزال هناك أخطاء في الحروف النادرة أو الصينية التقليدية، لذا يُنصح بمراجعة النصوص الحيوية قبل الاعتماد النهائي.
س2: ما هي تكلفة توليد صورة واحدة بنسبة 3:4 لـ "شياو هونغ شو" باستخدام gpt-image-2؟
وفقاً للتسعير الرسمي، تبلغ تكلفة الصورة الواحدة بجودة عالية (1024×1536، بنسبة 3:4) حوالي 0.20 إلى 0.25 دولار أمريكي. إذا قمت بإنشاء سلسلة من 9 صور، ستكون التكلفة حوالي 1.8 إلى 2.3 دولار (ما يعادل 13-17 يوان صيني). من خلال خدمة وكيل API من APIYI (apiyi.com)، عادة ما تكون الأسعار أقل، مع دعم الدفع باليوان الصيني وإصدار الفواتير، مما يجعلها مثالية للمبدعين المحليين للإنتاج الضخم.
س3: كيف يمكنني استخدام خاصية "توليد الصور المتصل بالإنترنت" في gpt-image-2؟
تكون خاصية الاتصال بالإنترنت مفعلة افتراضياً في نسخة الويب من ChatGPT (نمط التفكير)، أما عبر واجهة API، فيجب استخدام متغير النموذج الذي يدعم الاتصال بالإنترنت. عند استدعاء نموذج gpt-image-2-all عبر APIYI (apiyi.com)، يكون البحث عبر الإنترنت مفعلاً بشكل افتراضي؛ ما عليك سوى ذكر المعلومات الواقعية التي تحتاجها في الموجه (مثل "آخر إصدار"، "الألوان الرسمية"، "المواصفات الحقيقية")، وسيقوم النموذج تلقائياً بتفعيل بحث الويب ودمج النتائج في عملية توليد الصورة.
س4: أنا لا أجيد البرمجة، هل يمكنني استخدام gpt-image-2 في "شياو هونغ شو"؟
بالتأكيد. نوصي باستخدام أداة الويب imagen.apiyi.com، حيث لا تحتاج إلى إعداد مفتاح API أو بيئة Python. ما عليك سوى اختيار النموذج (gpt-image-2 أو gpt-image-2-all) من نموذج الويب، وكتابة الموجه، واختيار النسبة (3:4) والعدد، ثم الضغط على توليد. تدعم الأداة واجهة باللغة الصينية، والتحميل الجماعي، وإدارة سجل التاريخ، مما يجعلها مثالية لصناع المحتوى.
س5: هل سيتم تقييد صور "شياو هونغ شو" المولدة بـ gpt-image-2 بدعوى أنها "مولدة بالذكاء الاصطناعي"؟
في الوقت الحالي، لم تعلن منصة "شياو هونغ شو" عن قواعد تقييد للصور "المولدة بالذكاء الاصطناعي"، حيث يعتمد جوهر خوارزميتها على معدل التفاعل (الإعجابات، الحفظ، التعليقات، المشاركات، والمتابعات). طالما أن صورك تحتوي على كثافة معلومات عالية وذات قيمة للقارئ، فستحصل على ردود فعل إيجابية. يُنصح بالإشارة إلى مصدر الصور في النص (يمكنك كتابة "تمت المساعدة بواسطة الذكاء الاصطناعي") لتعزيز شفافية المحتوى.
س6: ما هو الحد الأقصى للصور التي يمكن لـ gpt-image-2 توليدها في المرة الواحدة؟
عبر API، يمكن توليد ما يصل إلى 10 صور في الطلب الواحد (n=10)، بينما يمكن لـ ChatGPT عبر الويب توليد ما يصل إلى 8 صور. بالنسبة لسلسلة 9 صور في "شياو هونغ شو"، يمكن لـ API إتمامها في دفعة واحدة، مما يجعل الكفاءة أعلى بكثير من النماذج الأخرى. لاحظ فقط أنه كلما زاد العدد (n)، زاد وقت الانتظار والمعالجة، لذا يُنصح بإعداد مهام غير متزامنة عند الإنتاج الضخم.
س7: أيهما أفضل لـ "شياو هونغ شو": gpt-image-2 أم Nano Banana Pro أم Seedream؟
ببساطة: gpt-image-2 مناسب للمحتوى "عالي كثافة المعلومات + الكثير من النصوص" (مثل صور المعلومات العلمية، بطاقات التقييم، الرسوم البيانية)، بينما Nano Banana Pro مناسب لـ "المشاهد الإبداعية + اتساق الشخصيات" (مثل القصص المسلسلة، السرد متعدد الصور)، وSeedream مناسب لـ "الجماليات الشرقية + النصوص الصينية" (مثل الملابس التقليدية "هانفو"، الطراز الوطني، الحبر الصيني). يمكنك تجربة النماذج الثلاثة على imagen.apiyi.com، وننصح بإجراء اختبار (A/B) قبل اعتماد النموذج الأساسي.
س8: كيف أجعل الصور المتعددة المولدة بواسطة gpt-image-2 موحدة في النمط؟
هناك ثلاث تقنيات أساسية: أولاً، استخدم n=9 للتوليد دفعة واحدة، حيث سيحافظ النموذج تلقائياً على اتساق النمط؛ ثانياً، حدد لوحة الألوان بدقة في الموجه (مثل "استخدام موحد للون الأرجواني #2D1B69 والوردي #FF6B9D")؛ ثالثاً، ثبّت هيكل التصميم (مثل "كل الصور تحتوي على عنوان في الأعلى + محتوى في المنتصف + دعوة لاتخاذ إجراء CTA في الأسفل"). إذا كنت بحاجة إلى اتساق أقوى للشخصيات أو المشاهد، يمكنك التفكير في استخدام ميزة تحرير الصور المتعددة في gpt-image-2، بناءً على صورة مرجعية.
الخلاصة: القواعد الثلاث الأساسية لاستخدام gpt-image-2 في "شياو هونغ شو"
من خلال ما سبق، يمكن استخلاص 3 قواعد أساسية لإنشاء محتوى "شياو هونغ شو" باستخدام gpt-image-2:
القاعدة الأولى، تعامل مع توليد الصور كـ "تصميم منتج" وليس "رسم". بفضل الاستدلال الوكيل (Agentic Reasoning) في gpt-image-2، يبدو النموذج وكأنه "مصمم مفكر"؛ كلما كان موجهك يشبه مستند متطلبات التصميم (أهداف واضحة، تسلسل هرمي للمعلومات، قيود بصرية)، كانت المخرجات أكثر دقة.
القاعدة الثانية، اتخذ من "كثافة المعلومات" سلاحاً للتميز. تكافئ خوارزمية "شياو هونغ شو" المحتوى ذو معدل الحفظ المرتفع، وجوهر معدل الحفظ هو "القيمة العملية". إن اختراق gpt-image-2 في عرض النصوص والتنسيق يتيح لك إنشاء "صور معلوماتية عالية الكثافة" لا تستطيع قوالب Canva إنجازها، وهذا هو أفضل طريق لتجاوز المنافسين للحسابات الجديدة.
القاعدة الثالثة، استخدم "المعرفة المتصلة بالإنترنت" في توقيت المحتوى. بالنسبة للمحتوى الذي يتضمن أحدث المنتجات، الأحداث الجارية، أو البيانات الرسمية، تأكد من استخدام نموذج مثل gpt-image-2-all الذي يدعم الاتصال بالإنترنت لتجنب الوقوع في فخ المعلومات المختلقة من قبل الذكاء الاصطناعي.
🚀 نصيحة عملية: إذا كنت تخطط لدمج gpt-image-2 في سير عمل "شياو هونغ شو"، نوصي ببدء رحلتك من أحد المدخلين التاليين: صناع المحتوى المستقلون يمكنهم البدء من أداة الويب imagen.apiyi.com حيث يمكنك توليد صورتك الأولى في 3 دقائق؛ أما الاستوديوهات ذات القدرات التقنية فيمكنها الربط عبر APIYI (api.apiyi.com) باستخدام نموذج gpt-image-2-all لبناء خط إنتاج جماعي. كلا المدخلين يدعمان توليد الصور عبر الإنترنت، وبأسعار معقولة، مما يجعلهما مناسبين لفرق الإنتاج المحلية.
إن إتقان gpt-image-2 لن يجعل حسابك يتصدر المشهد بين عشية وضحاها، ولكنه سيقلل تكلفة وقت إنتاج الصور بنسبة 90%، مما يتيح لك تركيز طاقتك على تخطيط المواضيع، وصقل النصوص، وعمليات التفاعل التي تؤثر حقاً على البيانات – وهذه هي القيمة الحقيقية لأدوات الذكاء الاصطناعي لصناع المحتوى.
كاتب المقال: فريق تقنية APIYI — نركز على الوصول إلى واجهات برمجة تطبيقات نماذج اللغة الكبيرة وتطوير أدوات إنشاء المحتوى. ندعوكم لزيارة apiyi.com للحصول على المزيد من تقييمات النماذج، وقوالب الموجهات، وأدلة التطوير.