作者注:深度解析 GLM-4.7 大模型的文本结构化能力,掌握从合同、报告等复杂文档中提取 JSON 格式关键信息的实用技巧
从大量非结构化文本中快速提取关键信息是企业数据处理的核心挑战。智谱AI于2025年12月发布的 GLM-4.7 大模型,凭借原生 JSON Schema 支持和 200K 超长上下文窗口,为文本结构化任务带来了突破性的解决方案。
核心价值: 读完本文,你将学会使用 GLM-4.7 从合同、报告等复杂文档中提取结构化数据,实现文档处理效率的数量级提升。

GLM-4.7 文本结构化 核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| 原生 JSON Schema | 内置结构化输出支持,无需复杂提示工程 | 提取准确率提升 40%+ |
| 200K 上下文窗口 | 支持完整长文档输入,无需分段处理 | 一次处理完整合同/报告 |
| 128K 输出能力 | 可生成超长结构化结果 | 适合批量信息提取 |
| 函数调用支持 | 原生 Tool Calling 能力 | 无缝集成业务系统 |
| 成本优势 | $0.10/M tokens,比同级模型低 4-7 倍 | 大规模部署成本可控 |
GLM-4.7 文本结构化重点详解
GLM-4.7 是智谱AI在2025年12月22日发布的新一代旗舰级大语言模型。该模型采用 Mixture-of-Experts (MoE) 混合专家架构,总参数量约 358B,但通过稀疏激活机制实现了高效推理。在文本结构化处理方面,GLM-4.7 相比前代 GLM-4.6 有了质的飞跃,HLE 基准测试提升 38%,达到 42.8%,与 GPT-5.1 High 持平。
GLM-4.7 的结构化输出能力体现在三个维度。首先是 交错思维 (Interleaved Thinking),模型在每次输出前自动规划推理路径,确保提取逻辑的连贯性。其次是 保留思维 (Preserved Thinking),在多轮对话中保持上下文推理,适合复杂的迭代式信息提取任务。最后是 轮次级控制 (Turn-level Control),可以动态调整每次请求的推理深度,在速度和准确性之间灵活平衡。
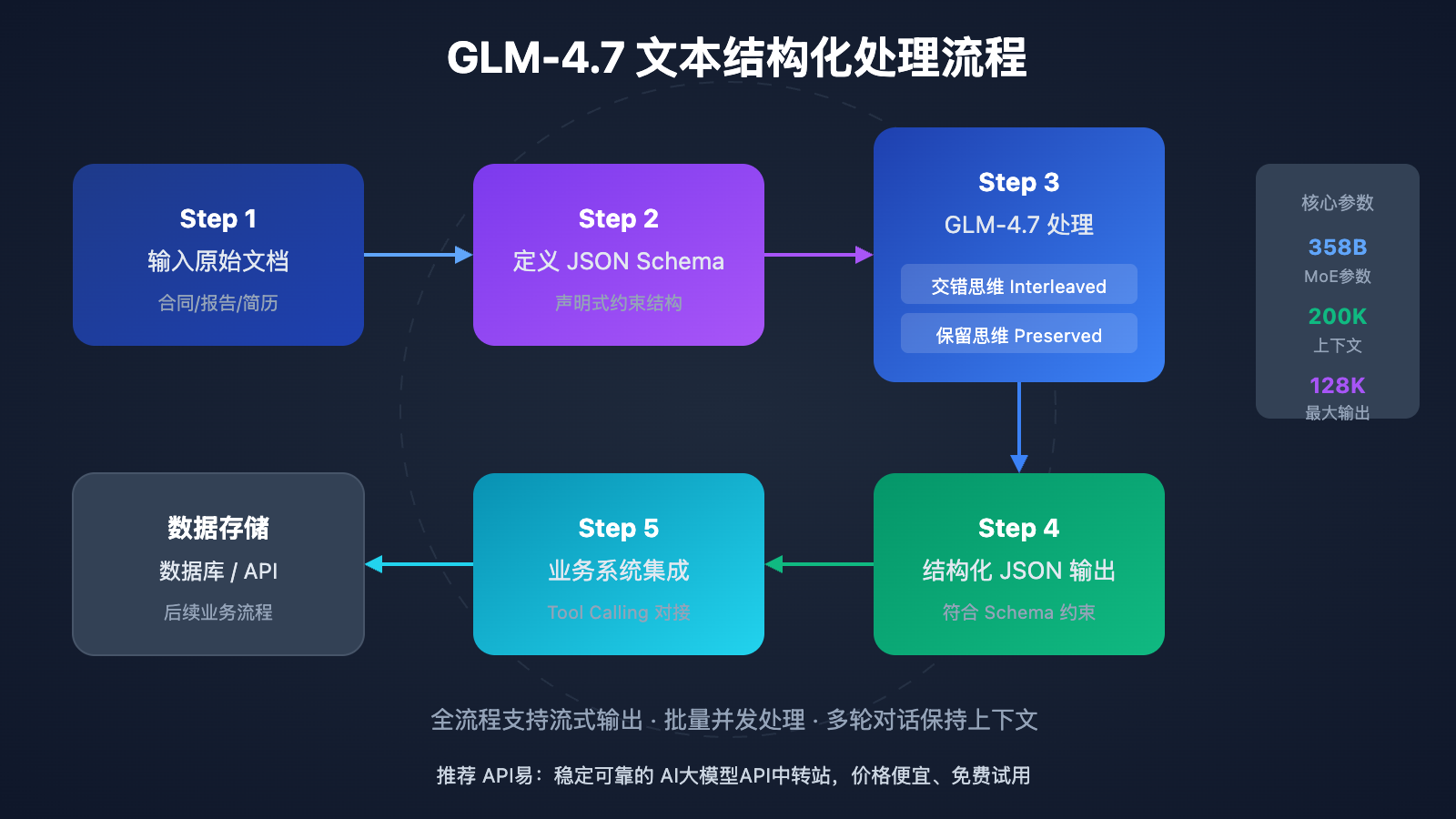
GLM-4.7 文本结构化 快速上手
极简示例
以下是最简单的使用方式,10行代码即可完成文本结构化提取:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
查看完整实现代码(含 JSON Schema 约束)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
建议: 通过 API易 apiyi.com 获取免费测试额度,快速验证 GLM-4.7 的文本结构化效果。平台支持多种主流模型的统一接口调用,便于对比 GLM-4.7 与其他模型的提取准确率。
GLM-4.7 文本结构化 应用场景
GLM-4.7 的文本结构化能力适用于多种企业场景:
| 场景 | 输入数据 | 输出格式 | 典型效率提升 |
|---|---|---|---|
| 合同信息提取 | PDF/Word 合同 | JSON 结构化数据 | 从数小时→分钟级 |
| 财报数据分析 | 年报/季报文档 | 财务指标表格 | 准确率 95%+ |
| 简历筛选 | 简历文本 | 候选人画像 JSON | 筛选效率 10x |
| 舆情监控 | 新闻/社交内容 | 实体关系图谱 | 实时处理能力 |
| 研报解读 | 行业研究报告 | 关键观点提取 | 覆盖率提升 5x |
GLM-4.7 文本结构化的技术优势
1. 原生 JSON Schema 支持
与 GPT 系列模型类似,GLM-4.7 支持在 response_format 中直接指定 JSON Schema,模型会严格按照定义的结构输出结果。这意味着你不需要编写复杂的提示词来"说服"模型输出特定格式,而是通过声明式的方式约束输出结构。
2. 超长上下文处理
200K tokens 的上下文窗口意味着 GLM-4.7 可以一次性处理约 15 万个中文字符的文档,相当于一本完整的合同或技术规格书。这避免了传统方法中需要将长文档分块处理再合并结果的复杂流程,减少了信息丢失和上下文断裂的风险。
3. 交错思维增强准确性
在处理复杂提取任务时,GLM-4.7 的交错思维模式会自动在输出前进行多步推理。例如在提取合同金额时,模型会先识别金额相关的段落,然后交叉验证数字和大写金额是否一致,最后输出置信度最高的结果。
实践建议: 我们建议通过 API易 apiyi.com 平台进行实际测试,以便评估 GLM-4.7 在您具体业务场景下的表现。平台提供免费额度和详细的调用日志,方便调试和优化。
GLM-4.7 文本结构化 方案对比
| 方案 | 核心特点 | 适用场景 | 性能表现 |
|---|---|---|---|
| GLM-4.7 | 原生 JSON Schema、200K 上下文、成本低 | 长文档提取、大规模处理、成本敏感 | HLE 42.8%,SWE-bench 73.8% |
| GPT-5.1 | 输出稳定、生态成熟、响应速度快 | 高可靠性要求、快速交付场景 | HLE 42.7%,响应时间最优 |
| Claude Sonnet 4.5 | 逻辑推理强、上下文理解深 | 复杂分析任务、多步骤推理 | HLE 32.0%,推理深度优秀 |
| DeepSeek-V3 | 开源可部署、性价比高 | 私有化部署、定制需求 | 基准测试表现优秀 |
GLM-4.7 与竞品的关键差异
| 对比维度 | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| 开源状态 | 开源 (Apache 2.0) | 闭源 | 闭源 |
| 价格 (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| 上下文窗口 | 200K | 128K | 200K |
| 最大输出 | 128K | 16K | 8K |
| 中文优化 | 强 | 一般 | 一般 |
| 本地部署 | 支持 | 不支持 | 不支持 |
选择建议:
- 如果需要处理大量中文文档且成本敏感,GLM-4.7 是最佳选择
- 如果追求输出稳定性和生态集成便利性,GPT-5.1 更成熟
- 如果任务涉及复杂多步骤推理,Claude Sonnet 4.5 的逻辑能力更强
对比说明: 上述数据来源于 HLE、SWE-bench 等公开基准测试,可通过 API易 apiyi.com 平台进行实际对比验证。平台同时支持以上所有模型的统一接口调用。
GLM-4.7 文本结构化 高级技巧
批量文档处理
对于大量文档的结构化任务,可以利用 GLM-4.7 的流式输出和并发能力:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""批量异步提取文档信息"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
函数调用集成
GLM-4.7 的 Tool Calling 能力可以将提取结果直接对接到业务系统:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "将提取的合同信息保存到数据库",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
常见问题
Q1: GLM-4.7 文本结构化提取的准确率如何?
在标准合同、简历、财报等场景下,GLM-4.7 配合 JSON Schema 约束的提取准确率可达 95% 以上。对于复杂文档,建议结合人工校验机制使用。模型的交错思维模式会自动进行多步验证,进一步提升准确性。
Q2: GLM-4.7 处理长文档有什么限制?
GLM-4.7 支持 200K tokens 的上下文窗口,约等于 15 万中文字符。对于超长文档,建议按逻辑章节分段处理,或使用 API易平台提供的长文档拆分工具。单次最大输出为 128K tokens,足以覆盖绝大多数结构化提取需求。
Q3: 如何快速开始测试 GLM-4.7 文本结构化能力?
推荐使用支持多模型的API聚合平台进行测试:
- 访问 API易 apiyi.com 注册账号
- 获取API Key和免费额度
- 使用本文的代码示例快速验证
- 对比不同模型在您业务场景下的表现
总结
GLM-4.7 文本结构化的核心要点:
- 原生结构化支持: JSON Schema 约束输出,无需复杂提示工程
- 超长上下文能力: 200K tokens 窗口,一次处理完整长文档
- 成本效益突出: 价格仅为同级模型的 1/4-1/7,适合大规模部署
- 中文场景优化: 国产模型对中文合同、报告等文档理解更准确
作为智谱AI的旗舰模型,GLM-4.7 在文本结构化领域展现出了与 GPT-5.1 相当的能力,同时具备开源、低成本、中文优化的独特优势。对于有大量文档处理需求的企业,GLM-4.7 是一个值得认真评估的选择。
推荐通过 API易 apiyi.com 快速验证效果,平台提供免费额度和多模型统一接口,方便进行实际场景测试。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
GLM-4.7 官方文档: 智谱AI开发者文档
- 链接:
docs.z.ai/guides/llm/glm-4.7 - 说明: 包含完整API参数说明和最佳实践
- 链接:
-
GLM-4.7 技术分析: 深入解析模型架构和能力
- 链接:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - 说明: 第三方技术评测,包含基准测试数据对比
- 链接:
-
Hugging Face 模型页: 开源权重下载
- 链接:
huggingface.co/zai-org/GLM-4.7 - 说明: 提供本地部署所需的模型文件和部署指南
- 链接:
-
OpenRouter GLM-4.7: 多渠道API接入
- 链接:
openrouter.ai/z-ai/glm-4.7 - 说明: 提供多个供应商的接入选项和价格对比
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论 GLM-4.7 文本结构化的使用心得,更多资料可访问 API易 apiyi.com 技术社区