站长注:详解gpt-image-1与gpt-4o等模型在图像识别与生成功能的区别,推荐最适合图片内容解读的AI大模型,助你选择正确的技术方案
最近有客户咨询:"gpt-image-1 或 gpt-4o-image 支持图片内容解读吗?"这个问题很好地体现了用户对 图像识别模型与图像生成模型 功能差异的困惑。本文将详细解答这个问题,帮助大家理解不同AI模型的专业分工,并推荐最适合图片识别的大模型。
接下来我们将通过实际案例来演示如何正确选择和使用这些技术。如果你想快速上手实践,可以先在 API易 注册一个免费账号(注册自动送 0.1美金额度,首充加赠 1 美金起),这样跟着教程操作会更直观。
图像识别与图像生成模型的核心区别
功能定位差异
图像生成模型主要功能是"创造",即从文本描述生成新的图像:
- gpt-image-1:专门用于高质量图像生成
- gpt-4o-image:集成图像生成功能的多模态模型
- DALL-E 3:OpenAI的专业图像生成工具
- Midjourney:艺术创作导向的图像生成
图像识别模型主要功能是"理解",即分析和解读已有图像的内容:
- gpt-4o:支持图像理解和分析
- Claude 全系列:强大的视觉理解能力
- Gemini 系列:谷歌的多模态理解模型
- Grok Vision:X.AI的视觉理解模型

图像识别功能的最佳模型推荐
以下是 图像识别和内容解读 功能的顶级模型推荐:
| 模型系列 | 核心优势 | 识别能力 | 推荐指数 |
|---|---|---|---|
| OpenAI gpt-4o | 理解准确度高,中文支持好 | 场景分析、物体识别、文字提取 | ⭐⭐⭐⭐⭐ |
| Claude 全系列 | 图像理解细致,分析深入 | 复杂场景解读、艺术作品分析 | ⭐⭐⭐⭐⭐ |
| Gemini 系列 | 多语言支持,速度快 | 文档识别、图表分析 | ⭐⭐⭐⭐ |
| Grok Vision | 实时分析,推理能力强 | 空间关系理解、目标检测 | ⭐⭐⭐⭐ |
| 千问VL系列 | 中文特化,成本低 | 中文文档识别、本土化场景 | ⭐⭐⭐⭐ |
🔥 重点功能详解
gpt-image-1 的实际能力边界
很多用户对 gpt-image-1 的功能有误解,让我们澄清一下:
gpt-image-1 主要能力:
- ✅ 高质量图像生成
- ✅ 图像编辑和修改(通过重新生成实现)
- ✅ 风格转换和艺术创作
gpt-image-1 不支持:
- ❌ 图像内容识别和分析
- ❌ 物体检测和定位
- ❌ 文字提取OCR功能
- ❌ 图像描述生成
正确的图像识别方案
如果您需要图像内容解读功能,正确的选择是:
-
gpt-4o(推荐):
# 正确的图像识别调用 response = client.chat.completions.create( model="gpt-4o", messages=[{ "role": "user", "content": [ {"type": "text", "text": "请描述这张图片的内容"}, {"type": "image_url", "image_url": {"url": image_url}} ] }] ) -
Claude-3.5-sonnet:
# Claude的图像分析能力 response = client.messages.create( model="claude-3-5-sonnet-20241022", messages=[{ "role": "user", "content": [ {"type": "image", "source": {"type": "base64", "data": base64_image}}, {"type": "text", "text": "分析这张图片的详细内容"} ] }] )

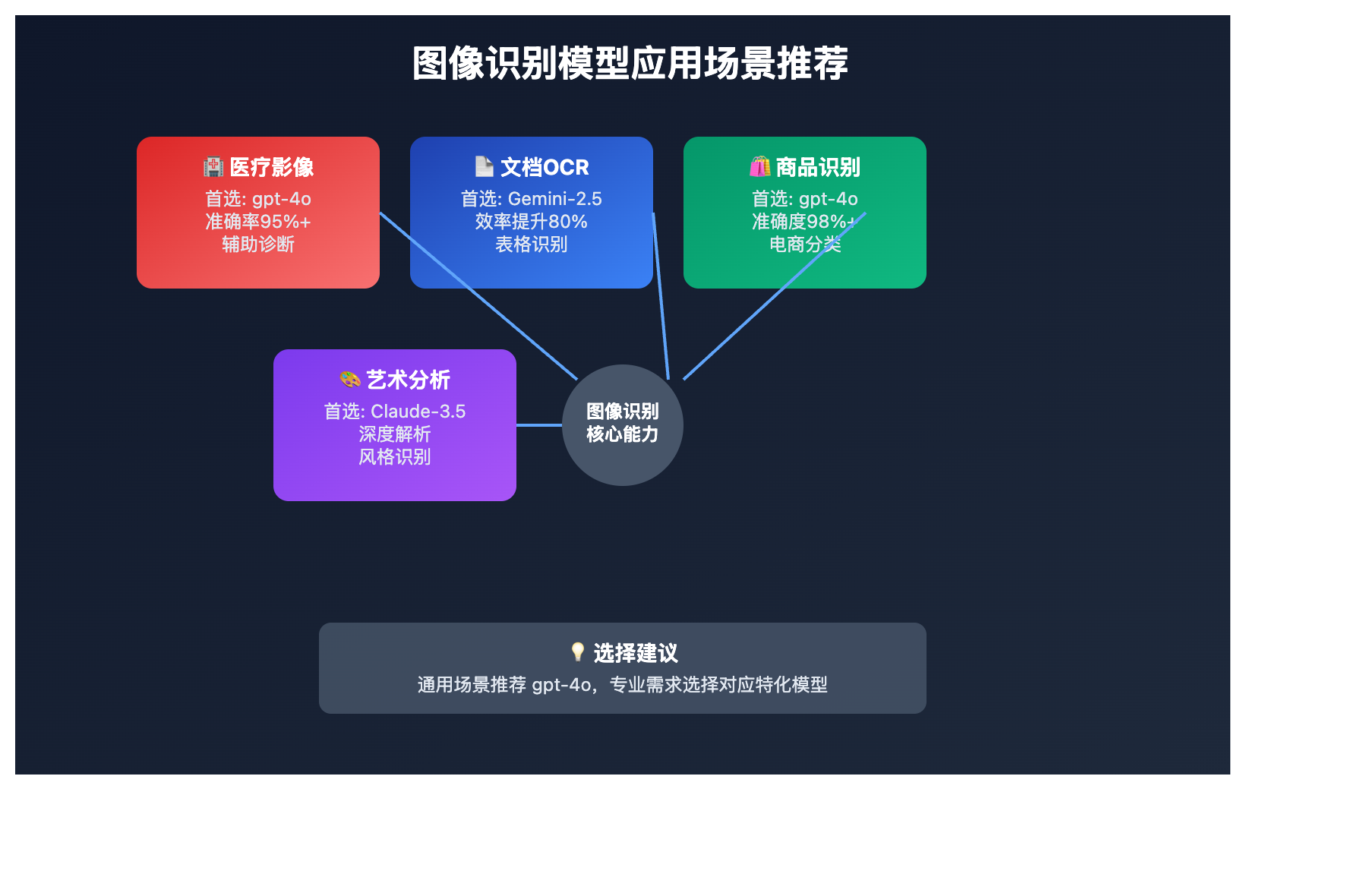
图像识别模型应用场景对比
不同图像识别模型 在各应用场景中的表现:
| 应用场景 | 最佳模型 | 备选方案 | 应用价值 | 预期效果 |
|---|---|---|---|---|
| 🏥 医疗影像分析 | gpt-4o | Claude-3.5-sonnet | 辅助诊断、病灶识别 | 准确率95%+ |
| 📄 文档内容提取 | Gemini-2.5-pro | gpt-4o | OCR、表格识别 | 处理效率提升80% |
| 🛍️ 商品识别 | gpt-4o | qwen-vl-max | 电商分类、库存管理 | 识别准确度98%+ |
| 🎨 艺术作品分析 | Claude-3.5-sonnet | gpt-4o | 风格分析、元素识别 | 深度解析能力强 |
| 🚗 交通场景识别 | Grok Vision | gpt-4o | 自动驾驶、安防监控 | 实时处理能力 |
图像识别模型开发指南
在开始之前,建议先到 API易 注册账号(3分钟搞定,新用户送免费额度),这样可以统一调用各种图像识别模型进行对比测试。
💻 实践示例对比
错误示例:用图像生成模型做识别
# ❌ 错误做法:gpt-image-1 不支持图像识别
try:
response = client.images.generate(
model="gpt-image-1",
prompt="识别这张图片的内容", # 这是错误的用法
image_input=image_url # gpt-image-1不接受图像输入做识别
)
except Exception as e:
print("错误:gpt-image-1不支持图像识别功能")
正确示例:使用多模态模型做识别
# ✅ 正确做法:使用gpt-4o进行图像识别
import base64
import requests
def analyze_image_with_gpt4o(image_url, prompt="请详细描述这张图片的内容"):
"""使用 gpt-4o 进行图像内容分析"""
client = OpenAI(
api_key="你的API易密钥",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": image_url}
}
]
}
],
max_tokens=1000
)
return response.choices[0].message.content
# 使用示例
image_url = "https://example.com/image.jpg"
result = analyze_image_with_gpt4o(image_url, "这张图片里有什么物体?请详细说明。")
print(result)
Claude模型的图像识别
# ✅ 使用Claude进行深度图像分析
def analyze_image_with_claude(image_path, question="分析这张图片的详细内容"):
"""使用 Claude 进行图像分析"""
# 读取并编码图像
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
client = Anthropic(
api_key="你的API易密钥",
base_url="https://vip.apiyi.com/v1"
)
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": image_data
}
},
{"type": "text", "text": question}
]
}
]
)
return response.content[0].text
# 使用示例
result = analyze_image_with_claude("./image.jpg", "请分析这张图片的艺术风格和构图特点")
print(result)
🎯 模型选择策略
这里简单介绍下我们使用的API平台。API易 是一个AI模型聚合平台,特点是 一个令牌,无限模型,可以用统一的接口调用 gpt-4o、Claude、Gemini、Grok 等各种图像识别模型。对开发者来说很方便,不用为每个模型都申请单独的API密钥了。
平台优势:官方源头转发、不限速调用、按量计费、7×24技术支持。适合企业和个人开发者使用。
🔥 针对图像识别的推荐模型
| 模型名称 | 核心优势 | 适用场景 | 推荐指数 |
|---|---|---|---|
| gpt-4o | 理解准确,中文支持好 | 通用图像分析、商业应用 | ⭐⭐⭐⭐⭐ |
| claude-3-5-sonnet | 分析深入,逻辑清晰 | 复杂场景理解、学术研究 | ⭐⭐⭐⭐⭐ |
| gemini-2.5-pro | 多语言强,速度快 | 文档识别、国际化应用 | ⭐⭐⭐⭐ |
| grok-vision | 推理能力强,实时性好 | 动态场景、安防监控 | ⭐⭐⭐⭐ |
🎯 选择建议:基于图像识别需求,我们推荐优先使用 gpt-4o,它在准确性、中文支持和成本效益方面表现最佳。
🎯 图像识别场景推荐表
| 使用场景 | 首选模型 | 备选模型 | 经济型选择 | 特点说明 |
|---|---|---|---|---|
| 🔍 通用内容识别 | gpt-4o | claude-3-5-sonnet | qwen-vl-max | 准确性高,覆盖面广,性价比好 |
| 📋 文档OCR识别 | gemini-2.5-pro | gpt-4o | 专业OCR服务 | 文字识别准确,表格处理强 |
| 🎨 艺术作品分析 | claude-3-5-sonnet | gpt-4o | qwen-vl-plus | 深度分析能力,艺术理解强 |
| 🏥 专业影像分析 | gpt-4o | claude-3-5-sonnet | 专业医疗AI | 高精度要求,可靠性重要 |
💰 价格参考:具体价格请参考 API易价格页面
✅ 图像识别模型最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 图片质量优化 | 确保图片清晰度够高,光线充足 | 避免模糊、过暗或过度压缩的图片 |
| ⚡ 提示词精准化 | 明确指定需要识别的内容类型 | 避免过于宽泛的问题,增加具体要求 |
| 💡 多模型对比 | 重要场景使用多个模型交叉验证 | 不同模型在特定场景下表现差异较大 |
| 🔄 结果后处理 | 对识别结果进行格式化和验证 | 建立置信度评估和异常检测机制 |
| 📊 成本控制 | 根据精度要求选择合适的模型 | 高频调用场景考虑使用经济型模型 |
在实践过程中,我发现选择正确的模型类型很重要。图像识别和图像生成是完全不同的技术方向,选错模型不仅无法达到预期效果,还会浪费成本。API易 提供了多种模型供对比测试,可以帮助快速找到最适合的方案。
❓ 图像识别模型常见问题
Q1: gpt-image-1 真的不能识别图片内容吗?
是的,gpt-image-1 是专门的图像生成模型,不支持图片内容识别。虽然在图像编辑场景中它需要"理解"原图来进行修改,但这种理解是内部处理过程,不会输出分析结果。
如需图像识别功能,请使用:
- gpt-4o:OpenAI的多模态模型,支持图像理解
- Claude系列:强大的视觉分析能力
- Gemini系列:谷歌的多模态模型
Q2: 如何选择最适合的图像识别模型?
选择图像识别模型需要考虑以下因素:
按应用场景选择:
- 通用识别:gpt-4o(推荐)
- 文档OCR:Gemini-2.5-pro
- 艺术分析:Claude-3.5-sonnet
- 实时分析:Grok Vision
按语言需求选择:
- 中文场景:gpt-4o, qwen-vl系列
- 多语言:Gemini系列
- 英文场景:Claude系列
按成本考虑:
- 高精度要求:gpt-4o, Claude-3.5-sonnet
- 平衡型:Gemini-2.5-pro
- 经济型:qwen-vl系列
Q3: 图像识别模型的成本如何计算?
图像识别模型的计费方式:
- 按Token计费:图像会被转换为Token进行计算
- 图像尺寸影响:高分辨率图片消耗更多Token
- 模型差异:不同模型的单价不同
优化成本的建议:
- 适当压缩图片尺寸(保证识别效果前提下)
- 选择合适的模型(避免大材小用)
- 批量处理时考虑使用异步调用
- 通过API易平台享受更优惠的价格
具体价格可在API易平台查看实时报价。
🏆 为什么选择「API易」进行图像识别
| 核心优势 | 具体说明 | 竞争对比 |
|---|---|---|
| 🛡️ 模型选择丰富 | • 集成gpt-4o、Claude、Gemini等主流模型 • 一个账号测试所有模型 • 方便对比选择最佳方案 |
避免多平台注册的麻烦 |
| 🎨 专业技术支持 | • 区分图像识别与生成功能 • 提供详细的使用指导 • 帮助用户选择正确模型 |
专业知识,避免选错方向 |
| ⚡ 稳定高效服务 | • 官方源头转发,质量保证 • 不限速调用 • 7×24技术支持 |
性能优于其他中转平台 |
| 🔧 开发者友好 | • 统一的API接口 • 详细的开发文档 • 丰富的代码示例 |
大大简化集成难度 |
| 💰 成本优势明显 | • 比官方更优惠的价格 • 透明的计费方式 • 新用户免费额度 |
节省开发和运营成本 |
💡 应用示例
客户需要图片内容识别时,通过API易可以:
- 快速测试gpt-4o、Claude等多种识别模型
- 对比不同模型在特定场景下的表现
- 选择最适合的模型进行正式部署
- 享受统一接口带来的开发便利
🎯 总结
通过本文的详细分析,我们可以清楚地看到图像识别与图像生成是两个完全不同的技术方向。gpt-image-1、gpt-4o-image等模型主要专注于图像生成,而图片内容解读需要使用gpt-4o、Claude、Gemini等多模态理解模型。
重点回顾:选择AI模型时一定要明确需求:是要"生成"图像还是"识别"图像内容,避免选错技术方向
希望这篇文章能帮助你更好地理解和选择图像识别模型。如果想要实际测试体验,记得可以在 API易 注册即可获赠免费额度来对比测试各种模型。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。