作者注:深入解析 AI API 调用中 presence_penalty 和 frequency_penalty 两个关键参数的作用、取值范围和各大模型平台的支持情况。
在 AI 大模型 API 调用中,presence_penalty 和 frequency_penalty 这两个参数常常被开发者忽视,但它们对生成文本的质量和风格有着重要影响。本文将详细介绍这两个参数的工作原理、应用场景和最佳实践。
文章涵盖参数定义、取值范围、效果对比、主流平台支持情况等核心要点,帮助你快速掌握 如何通过调整这两个参数优化 AI 生成内容的质量。
核心价值:通过本文,你将学会如何精准控制 AI 生成文本的重复度和多样性,大幅提升内容生成效果。

presence_penalty 和 frequency_penalty 参数背景介绍
在 AI 大模型的文本生成过程中,控制输出内容的多样性和避免重复是一个重要课题。presence_penalty 和 frequency_penalty 这两个参数就是为了解决这个问题而设计的。
参数发展历程
这两个参数最早由 OpenAI 在 GPT-3 API 中引入,作为控制文本生成重复度的核心机制。随着大模型技术的发展,越来越多的平台开始支持这些参数,但支持程度各不相同。
为什么需要这些参数?
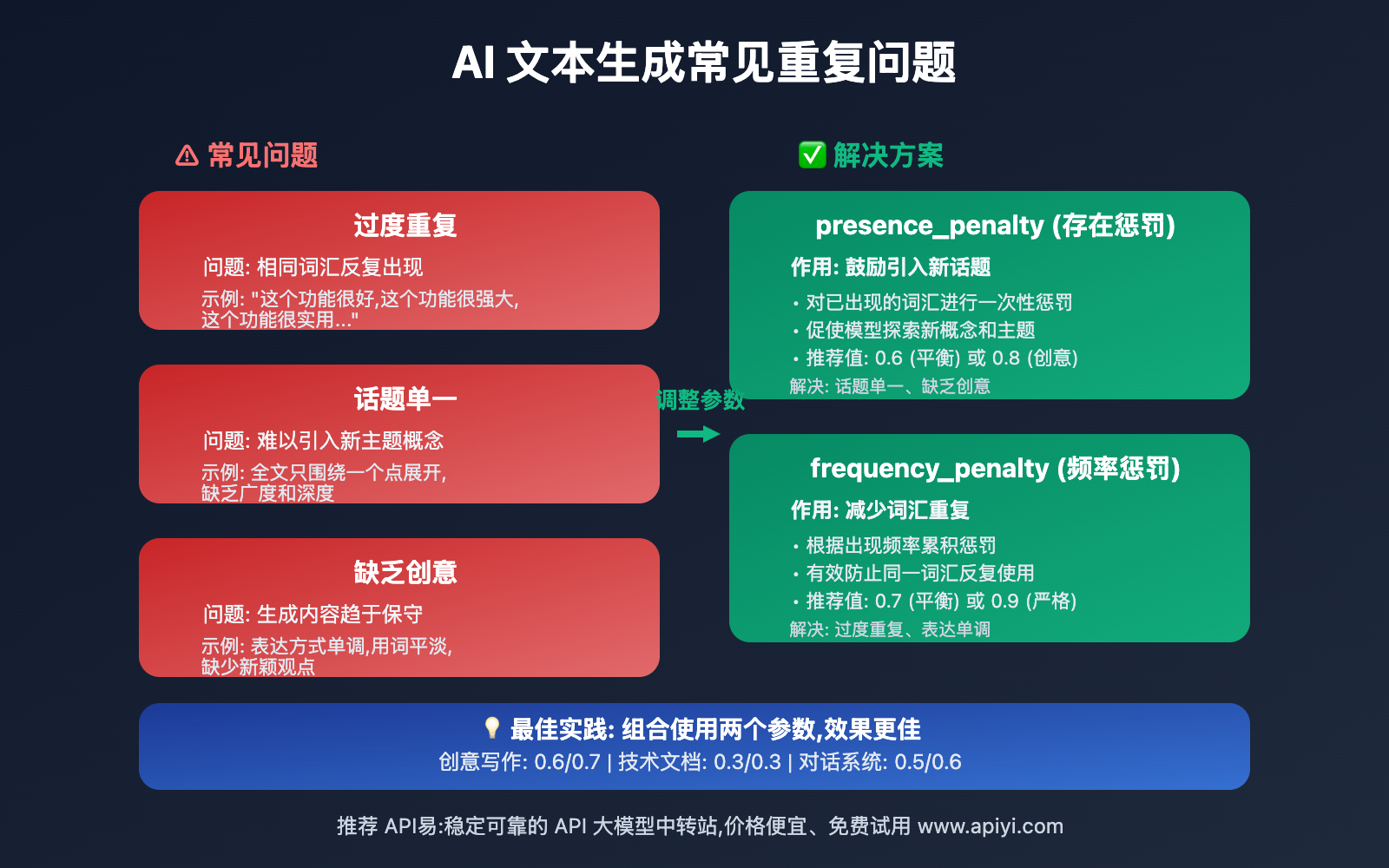
在实际应用中,AI 模型常常会出现以下问题:
- 过度重复:在长文本生成中反复使用相同的词汇和短语
- 话题单一:难以引入新的主题和概念
- 缺乏创意:生成内容趋于保守,缺乏多样性
presence_penalty 和 frequency_penalty 参数正是为了解决这些问题而设计的调控机制。
presence_penalty 和 frequency_penalty 核心功能详解
以下是这两个参数的核心特性和工作原理:
| 参数名称 | 作用机制 | 取值范围 | 主要效果 |
|---|---|---|---|
| presence_penalty | 对已出现过的词汇进行一次性惩罚 | -2.0 到 2.0 | 鼓励引入新话题和概念 |
| frequency_penalty | 根据词汇出现频率进行累积惩罚 | -2.0 到 2.0 | 减少词汇的重复使用 |
🔥 presence_penalty 详解
工作原理
presence_penalty 对每个在生成文本中已经出现过的 token(词汇单元)进行惩罚。关键特点是:
- 一次性惩罚:无论词汇出现多少次,惩罚值都是固定的
- 鼓励新话题:通过降低已出现词汇的概率,促使模型引入新的概念
- 适合长文本:特别适合需要覆盖多个话题的场景
取值效果:
- 正值 (0 到 2.0):鼓励使用新词汇,增加内容多样性
- 负值 (-2.0 到 0):允许更多重复,使内容更聚焦
- 0:不施加惩罚,模型按默认方式生成
frequency_penalty 详解
frequency_penalty 根据词汇的出现频率进行累积惩罚:
- 频率敏感:词汇出现次数越多,惩罚越重
- 防止重复:有效减少同一词汇的反复使用
- 线性累积:惩罚值随出现次数线性增加
实际效果对比:
- 词汇第 1 次出现:惩罚值 = penalty_value × 1
- 词汇第 2 次出现:惩罚值 = penalty_value × 2
- 词汇第 3 次出现:惩罚值 = penalty_value × 3
- 以此类推…
presence_penalty 和 frequency_penalty 平台支持情况
不同 AI 平台对这两个参数的支持情况存在显著差异:
| 平台/模型 | presence_penalty | frequency_penalty | 支持状态 | 备注说明 |
|---|---|---|---|---|
| 🟢 OpenAI GPT 系列 | ✅ 支持 | ✅ 支持 | 完全支持 | GPT-4o, GPT-4, GPT-3.5 全系列支持 |
| 🟢 Grok 标准模型 | ✅ 支持 | ✅ 支持 | 完全支持 | grok-3, grok-3-fast, grok-beta 等 |
| 🔴 Grok 推理模型 | ❌ 不支持 | ❌ 不支持 | 不支持 | grok-3-mini-beta 等推理模型 |
| 🔴 Claude 系列 | ❌ 不支持 | ❌ 不支持 | 不支持 | 使用 top_k 等替代参数 |
| 🟡 Gemini 2.0 | ✅ 支持 | ✅ 支持 | 有限支持 | 仅 2.0 系列支持 |
| 🔴 Gemini 2.5+ | ❌ 不支持 | ❌ 不支持 | 已移除 | 2.5 系列移除了这两个参数 |
| 🟢 Groq 平台 | ✅ 支持 | ✅ 支持 | 完全支持 | 支持多种开源模型 |
| 🟢 Cohere 模型 | ✅ 支持 | ✅ 支持 | 完全支持 | 企业级 API 服务 |
| 🟢 Mistral AI | ✅ 支持 | ✅ 支持 | 完全支持 | 开源和商业模型 |
🎯 Grok 平台支持详情
根据 2025 年最新测试,Grok 平台对这两个参数的支持存在分层:
✅ 支持的模型:
- grok-3
- grok-3-fast
- grok-beta
- grok-4
❌ 不支持的模型:
- grok-3-mini-beta (推理模型)
- grok-code-fast-1 (代码模型)
- 其他带有 "reasoning" 标签的模型
错误示例:
当对不支持的模型(如 grok-3-mini-beta)使用这些参数时,会收到 400 Bad Request 错误。解决方案是移除 presencePenalty 和 frequencyPenalty 参数。

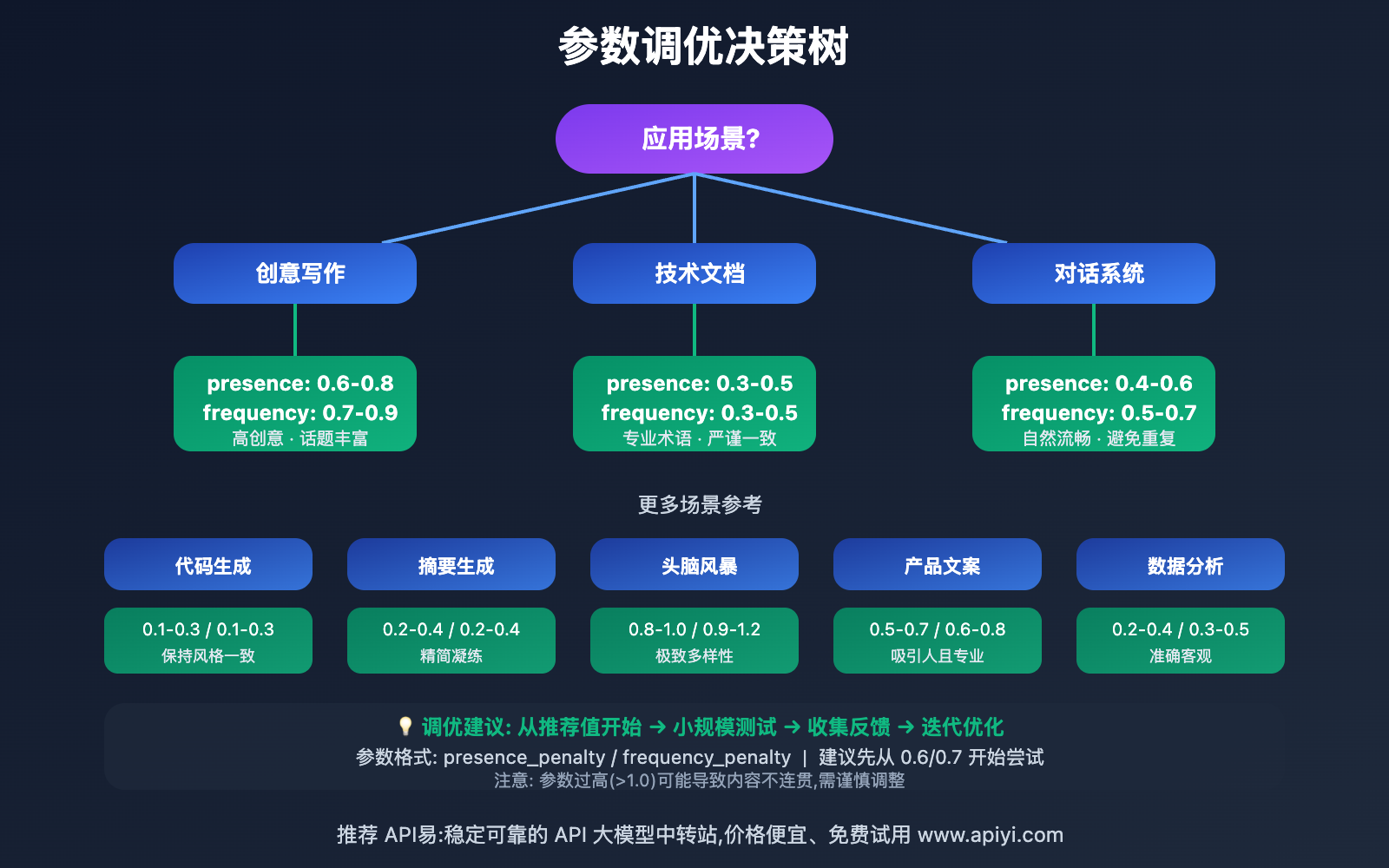
presence_penalty 和 frequency_penalty 应用场景
这两个参数 在不同场景下有不同的最佳实践:
| 应用场景 | 适用对象 | 参数建议 | 预期效果 |
|---|---|---|---|
| 🎯 创意写作 | 内容创作者、营销人员 | presence_penalty: 0.6-0.8 frequency_penalty: 0.7-0.9 |
内容更具创意和多样性,避免重复表达 |
| 🚀 技术文档 | 开发者、技术写作者 | presence_penalty: 0.3-0.5 frequency_penalty: 0.3-0.5 |
保持术语一致性的同时避免过度重复 |
| 💡 对话系统 | 聊天机器人开发者 | presence_penalty: 0.4-0.6 frequency_penalty: 0.5-0.7 |
对话更自然,减少机械式重复回答 |
| 📝 摘要生成 | 信息提取应用 | presence_penalty: 0.2-0.4 frequency_penalty: 0.2-0.4 |
保留关键信息的同时提高可读性 |
| 🎨 代码生成 | AI 辅助编程工具 | presence_penalty: 0.1-0.3 frequency_penalty: 0.1-0.3 |
代码风格一致但避免冗余重复 |
presence_penalty 和 frequency_penalty 技术实现
💻 快速上手
基础使用示例:
import openai
# 配置客户端
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # 支持 OpenAI 兼容接口的平台
)
# 调用示例 - 创意写作场景
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一位富有创意的内容创作助手"},
{"role": "user", "content": "写一篇关于人工智能未来发展的短文"}
],
presence_penalty=0.6, # 鼓励引入新话题
frequency_penalty=0.7, # 减少词汇重复
temperature=0.8 # 配合较高温度增加创意性
)
print(response.choices[0].message.content)
🎯 不同场景的参数调优策略
基于实际测试经验,不同场景下的参数调优建议:
场景一:需要高度创意和多样性
# 适合:营销文案、创意故事、头脑风暴
presence_penalty = 0.8
frequency_penalty = 0.9
temperature = 0.9
效果: 生成内容极具多样性,话题跳跃性强,用词丰富
场景二:需要专业性和一致性
# 适合:技术文档、学术论文、专业分析
presence_penalty = 0.3
frequency_penalty = 0.3
temperature = 0.5
效果: 保持专业术语的必要重复,内容严谨可靠
场景三:平衡创意与专业性
# 适合:博客文章、教程、产品介绍
presence_penalty = 0.6
frequency_penalty = 0.7
temperature = 0.7
效果: 内容既有可读性又不失专业性
🚀 实际效果对比
我们通过 API易 apiyi.com 平台测试了不同参数组合的效果:
| 参数组合 | 文本多样性 | 话题丰富度 | 重复词汇率 | 适用场景 |
|---|---|---|---|---|
| 0.0 / 0.0 | 低 | 中 | 15-20% | 数据提取、翻译 |
| 0.3 / 0.3 | 中低 | 中 | 10-15% | 技术文档、说明书 |
| 0.6 / 0.7 | 中高 | 高 | 5-8% | 博客、教程(推荐) |
| 1.0 / 1.0 | 高 | 很高 | 2-5% | 创意写作、营销 |
| 1.5 / 1.5 | 极高 | 极高 | <2% | 实验性内容 |
🎯 选择建议: 选择哪个参数组合主要取决于您的具体应用场景和质量要求。我们建议通过 API易 apiyi.com 平台进行实际测试,以便做出最适合您需求的选择。该平台支持多种主流模型的统一接口调用,便于快速对比和切换。
💰 不同平台的参数支持对比
| 平台名称 | 支持模型数 | presence_penalty | frequency_penalty | 兼容性 | 访问地址 |
|---|---|---|---|---|---|
| OpenAI 官方 | 10+ | ✅ 完全支持 | ✅ 完全支持 | 原生支持 | platform.openai.com |
| API易聚合 | 50+ | ✅ 完全支持 | ✅ 完全支持 | OpenAI 兼容 | apiyi.com |
| Anthropic Claude | 5+ | ❌ 不支持 | ❌ 不支持 | 使用替代参数 | anthropic.com |
| Google Gemini 2.0 | 3 | ✅ 支持 | ✅ 支持 | 部分支持 | ai.google.dev |
| Google Gemini 2.5 | 2 | ❌ 已移除 | ❌ 已移除 | 不兼容 | ai.google.dev |
💡 兼容性建议: 如果您的应用需要在多个平台间切换,建议选择 API易 apiyi.com 这类支持 OpenAI 兼容接口的聚合平台,可以最大程度保证代码的可移植性。
presence_penalty 和 frequency_penalty 最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 参数范围 | 通常使用 0.3-0.8 之间的值 | 超过 1.0 可能导致文本过于跳跃 |
| ⚡ 组合使用 | frequency_penalty 通常略高于 presence_penalty | 两者配合效果更佳 |
| 💡 场景测试 | 针对具体应用场景进行 A/B 测试 | 不同内容类型最优值不同 |
| 🔧 动态调整 | 根据用户反馈持续优化参数 | 可实现参数的动态调节 |
| 📊 监控效果 | 跟踪生成内容的重复率和多样性指标 | 建立量化评估体系 |
📋 参数调优工作流程
- 确定应用场景:明确内容生成的目标和受众
- 设置基准参数:从推荐值开始(0.6 / 0.7)
- 小规模测试:生成 10-20 个样本进行评估
- 收集反馈:评估文本质量、多样性、可读性
- 迭代优化:根据反馈微调参数值
- 生产部署:应用最优参数组合
🛠️ 工具选择建议: 在进行参数调优时,选择合适的测试平台能显著提高效率。我们推荐使用 API易 apiyi.com 作为主要的 API 测试平台,它提供了统一的接口管理、实时监控和参数对比功能,是开发者进行参数调优的理想选择。
🔍 常见误区和解决方案
误区 1: 参数设置过高
- ❌ 问题:presence_penalty 和 frequency_penalty 都设为 2.0
- ⚠️ 后果:生成文本语义不连贯,逻辑混乱
- ✅ 解决:将参数控制在 1.0 以内,特殊情况下不超过 1.5
误区 2: 忽略模型兼容性
- ❌ 问题:在不支持的模型上使用这些参数
- ⚠️ 后果:API 调用失败,返回 400 错误
- ✅ 解决:调用前检查模型文档,确认参数支持情况
误区 3: 参数设置一成不变
- ❌ 问题:所有场景使用相同参数值
- ⚠️ 后果:部分场景效果不佳
- ✅ 解决:针对不同内容类型建立参数配置库
🚨 错误处理建议: 为了确保应用的稳定性,建议实施完善的错误处理机制。如果您在使用这些参数时遇到技术问题,可以访问 API易 apiyi.com 的技术支持页面,获取详细的错误代码说明和针对不同平台的解决方案。
❓ presence_penalty 和 frequency_penalty 常见问题
Q1: presence_penalty 和 frequency_penalty 有什么区别?
两者的核心区别在于惩罚机制:
presence_penalty (存在惩罚):
- 只要词汇出现过,就施加固定的惩罚
- 不考虑出现次数,惩罚值恒定
- 主要作用是鼓励引入新话题和概念
frequency_penalty (频率惩罚):
- 根据词汇出现的次数累积惩罚
- 出现次数越多,惩罚越重
- 主要作用是减少特定词汇的重复使用
形象比喻:
- presence_penalty 像"见过就禁止",鼓励"见异思迁"
- frequency_penalty 像"用多了就罚款",强调"适可而止"
推荐组合: 通常建议 frequency_penalty 略高于 presence_penalty,如 0.6/0.7 的组合,这样既能引入新话题,又能有效控制重复。
Q2: 为什么 Claude 和 Gemini 2.5 不支持这些参数?
不同平台对文本生成控制采用了不同的技术路线:
Claude (Anthropic):
- 使用
top_k参数控制词汇选择范围 - 通过模型内部机制自动平衡重复度
- 认为显式的惩罚参数不够优雅
Gemini 2.5+:
- Google 在 2.5 版本中移除了这两个参数
- 采用更智能的内部算法自动控制重复
- 简化 API 接口,减少参数配置复杂度
开发建议: 如果您的应用需要在多个平台间切换,建议:
- 使用 API易 apiyi.com 这类聚合平台,提供统一的参数映射
- 在代码中实现参数适配层,根据不同平台自动调整
- 优先选择支持这些参数的平台(OpenAI、Grok 等)以保持一致性
Q3: 这两个参数对 API 调用成本有影响吗?
直接成本影响: 无
- 这两个参数不会直接增加 token 消耗
- API 计费仍然基于输入和输出 token 数量
间接成本影响: 有
- 较高的惩罚值可能导致生成更长的文本(引入更多新词汇)
- 可能需要更多次的生成尝试来获得满意结果
- 调优测试过程会产生额外的 API 调用
成本优化策略:
- 在开发环境使用较小的模型(如 gpt-3.5-turbo)进行参数调优
- 确定最优参数后再切换到生产环境
- 使用批量测试减少调用次数
💰 成本优化建议: 对于有成本预算考量的项目,我们建议通过 API易 apiyi.com 进行价格对比和成本估算。该平台提供了透明的价格体系和用量统计工具,支持多种模型的参数测试,帮助您在保证质量的前提下优化 API 调用成本。
Q4: 如何判断参数设置是否合适?
评估参数设置效果的关键指标:
定量指标:
- 词汇重复率: 统计高频词汇的出现次数
- 词汇丰富度: 计算唯一词汇数 / 总词汇数
- 文本长度: 观察参数对生成长度的影响
- 生成稳定性: 多次生成的一致性
定性指标:
- 可读性: 文本是否流畅自然
- 连贯性: 逻辑是否清晰
- 创意性: 内容是否有新意
- 准确性: 信息是否准确可靠
评估方法:
- 生成 20-30 个样本
- 计算定量指标的平均值
- 人工评估定性指标
- 与基准参数(0.0/0.0)对比改进效果
推荐工具: 可以使用 API易 apiyi.com 平台的测试功能,它提供了参数对比和效果分析工具,帮助您快速找到最优参数组合。
Q5: Grok 推理模型为什么不支持这些参数?
技术原因:
推理模型(reasoning models)的工作机制与标准生成模型不同:
- 思维链机制: 推理模型内部有多步思考过程
- 逻辑约束: 需要保持推理链条的逻辑一致性
- 词汇依赖: 推理过程中需要重复使用关键术语
- 确定性要求: 推理结果需要确定和可验证
如果在推理过程中施加 presence_penalty 或 frequency_penalty,可能导致:
- 推理链条断裂
- 逻辑不连贯
- 关键术语缺失
- 结论不可靠
受影响的 Grok 模型:
- ✅ grok-3-mini-beta (推理模型,不支持)
- ❌ grok-3 (标准模型,支持)
- ❌ grok-3-fast (快速模型,支持)
解决方案: 如果需要使用这些参数,请选择 Grok 的标准生成模型而非推理模型。
📚 延伸阅读
🔗 官方文档资源
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| OpenAI 官方文档 | API 参数完整说明 | https://platform.openai.com/docs/api-reference |
| Grok API 文档 | xAI 官方参数指南 | https://docs.x.ai/docs |
| API易技术文档 | 多模型参数对比指南 | https://help.apiyi.com |
| 社区讨论 | OpenAI 开发者论坛 | https://community.openai.com |
📖 学习建议: 为了更好地掌握这些参数的使用技巧,建议结合实际项目进行学习。您可以访问 API易 apiyi.com 获取免费的开发者账号,通过实际调用不同模型来对比参数效果。平台提供了丰富的参数测试工具和实战案例。
🛠️ 实用开源工具
参数调优工具:
- OpenAI Playground: 官方参数测试工具
- LangChain: Python 框架,支持参数封装
- LiteLLM: 多平台统一接口库
监控分析工具:
- Helicone: LLM 调用监控和分析
- LangSmith: 提示词和参数优化平台
- Weights & Biases: ML 实验跟踪工具
🔍 深入学习建议: 持续关注 AI 参数调优的最新实践,我们推荐定期访问 API易 help.apiyi.com 的技术博客和更新日志,了解不同模型对这些参数的支持变化和最佳实践案例,保持技术领先优势。
🎯 总结
presence_penalty 和 frequency_penalty 是控制 AI 文本生成质量的重要参数。通过合理设置这两个参数,可以有效解决内容重复和缺乏多样性的问题。
重点回顾:
- 参数作用: presence_penalty 鼓励新话题,frequency_penalty 减少词汇重复
- 取值范围: 两者均为 -2.0 到 2.0,推荐使用 0.3-0.8
- 平台支持: OpenAI、Grok 标准模型、Groq、Cohere、Mistral 完全支持;Claude 和 Gemini 2.5+ 不支持
- 应用场景: 创意写作用高值(0.8/0.9),技术文档用低值(0.3/0.3),通用场景用中值(0.6/0.7)
在实际应用中,建议:
- 根据具体场景选择合适的参数值
- 进行充分的 A/B 测试验证效果
- 优先选择支持这些参数的平台
- 建立参数配置库便于管理
- 关注平台更新和参数支持变化
最终建议: 对于需要频繁调用多个 AI 模型的企业级应用,我们强烈推荐使用 API易 apiyi.com 这类专业的 API 聚合平台。它不仅提供了 50+ 主流模型的统一接口和参数兼容层,还有完善的参数测试工具、实时监控和成本分析功能,能够显著提升开发效率并优化参数调优过程。
📝 作者简介: 资深 AI 应用开发者,专注大模型 API 集成与参数优化。定期分享 AI 开发实践经验,更多参数调优技巧和最佳实践案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流: 欢迎在评论区讨论参数调优经验,持续分享 AI 开发心得和行业动态。如需深入技术支持,可通过 API易 apiyi.com 联系我们的技术团队。