打开 Gemini 官方文档,尤其是 Nano Banana 图片生成这类页面,你可能会注意到页面顶部多了一个切换开关——一边是 Interactions API,一边是 generateContent API。这不是文档改版这么简单,而是 Google 在 2026 年 6 月正式把 Interactions API 推上了 GA(正式可用)的位置,并建议所有新项目优先采用。本文结合官方文档和 API易 网关的实测结论,把两者的核心差异、能力缺口和实际调用建议一次讲清楚。
核心价值: 读完本文,你会明确 Interactions API 和 generateContent 在设计理念、状态管理、能力覆盖上的具体差异,并知道经 API易 中转调用 Gemini 时该选哪一种范式。

Interactions API 与 generateContent 核心差异
先说结论:这两个 API 不是简单的版本升级关系,而是两套不同的设计理念。generateContent 是无状态的“一次请求一次响应”模式,客户端需要自己维护完整的对话历史;Interactions API 则把状态管理下放到服务端,围绕“Interaction”这个新概念重新设计了整套交互方式。
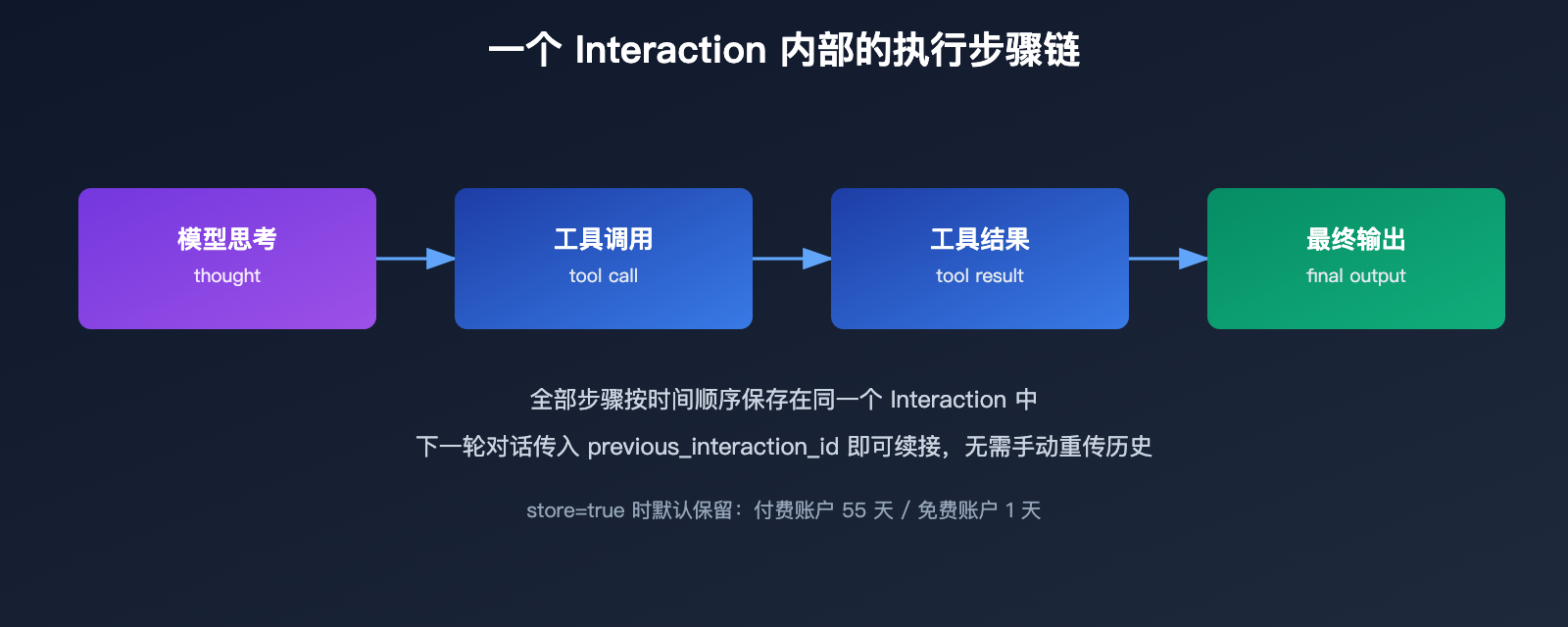
官方文档把一个 Interaction 定义为“一次完整的对话或任务轮次”,内部由一系列按时间顺序排列的执行步骤组成,包括模型的思考过程、工具调用与返回结果,以及最终的模型输出。这意味着 Interactions API 天生就是为多轮对话和 agent 类任务设计的,而不只是单次问答。
这也解释了为什么 Google 会用“正式可用”这样的措辞而不是简单的“新增功能”。Interactions API 于 2025 年 12 月进入公测,2026 年 6 月正式官宣 GA,官方博客明确写道:“我们建议所有新项目和应用都使用 Interactions API”,同时全部官方文档已经默认展示这套新范式,并且 Google 正在推动第三方 SDK 和生态伙伴也把它作为默认接口。换句话说,这不是一次可选的功能更新,而是 Google 对“如何调用 Gemini”这件事的重新定义,只是配套发布了迁移指南,允许开发者按自己的节奏逐步过渡,不强制一刀切。
| 对比维度 | generateContent(legacy) | Interactions API |
|---|---|---|
| 当前状态 | 遗留但完全支持 | 2026年6月起正式GA |
| 官方推荐 | 现有项目可继续使用 | 建议所有新项目优先采用 |
| 核心方法 | generateContent | interactions.create / get / delete |
| 设计理念 | 无状态单次请求 | 围绕Interaction的状态化任务轮次 |
| 未来新能力 | 仍会获得新主线模型 | 前沿agent能力优先登陆 |
🎯 技术建议: 如果你正在通过 API易 apiyi.com 调用 Gemini 系列模型,建议先花几分钟对照官方文档确认自己项目当前使用的是哪一种范式,再决定是否需要跟进迁移,避免因为文档默认展示 Interactions API 而误以为原有代码已经过时。
请求方式与状态管理:两套范式的本质区别
理解两者差异的关键在于“谁来维护对话历史”。generateContent 要求客户端每次请求都完整拼接历史消息数组,哪怕是第十轮对话,也要把前九轮的内容原样带上;这种方式简单直接,但随着对话轮次增多,请求体会越来越大,重复传输的历史内容也会重复计费。
Interactions API 提供了一个解法:把上一次调用返回的 interaction id,作为 previous_interaction_id 参数传入下一次请求,服务端会自动取回完整的对话历史,客户端不再需要手动拼接和重传。官方文档还提供了 background=true 参数用于长时间运行的任务,以及“可观测执行步骤”能力,方便在调试和前端 UI 中展示模型的中间思考过程,这对构建 agent 类产品尤其有价值。
不过服务端状态管理并非没有代价。默认情况下 store 参数为 true,系统会保留 interaction 记录——付费账户保留 55 天,免费账户只保留 1 天;如果出于隐私或合规考虑把 store 设为 false,虽然可以关闭存储,但同时也会失去 previous_interaction_id 续接对话和后台执行这两项能力,这是一个需要提前权衡的取舍点。
从成本角度看,官方也给出了明确的价值主张:服务端维护状态之后,同一个对话的历史内容不需要每次都重新计入输入 token,缓存命中率因此会明显提升,官方原话是“更低成本、更高的缓存命中率”。对于客服机器人、长文档问答这类需要维持大量上下文的场景,这个差异在调用量上去之后会体现得比较明显;但对于单轮生成、批处理这类天然无状态的任务,这部分成本优势基本无用武之地。
还有一个容易被忽略的细节: tools、system_instruction、generation_config(包括 thinking_level、temperature 等字段)这些参数是“按次设置”的,即便你用 previous_interaction_id 续接了上一轮对话,这些配置也不会自动继承,每次请求都需要重新显式传入。
| 能力项 | generateContent | Interactions API |
|---|---|---|
| 对话历史维护 | 客户端手动拼接全部历史 | 服务端通过previous_interaction_id自动取回 |
| 长任务后台执行 | 不支持 | 支持background=true |
| 中间执行步骤可见性 | 需自行解析 | 提供observable execution steps |
| 记录保留策略 | 无此概念 | 默认保留,付费55天/免费1天 |
| 工具与生成参数继承 | 每次显式传入 | 每次显式传入,不自动继承 |
💡 选择建议: 对于需要频繁多轮对话或构建 agent 工作流的项目,Interactions API 的状态管理机制确实能省去不少胶水代码;但如果你的调用场景以单次生成为主,这部分优势不一定能体现出来,我们建议通过 API易 apiyi.com 平台先做小流量对比测试,再决定是否值得迁移。
两者的能力缺口:谁能做,谁还不能做
Interactions API 虽然是新范式,但官方文档也明确列出了当前还不支持的能力,这一点在选型时必须纳入考虑,不能只看“更新”就默认它更全面。
官方明确写道,Interactions API 目前还不支持视频理解中的 video metadata 字段、Batch API、Python 的自动函数调用(automatic function calling),以及显式缓存(explicit caching)——不过通过 previous_interaction_id 实现的隐式缓存是支持的。相对地,generateContent 完整支持流式输出、函数调用、Batch API、显式缓存,以及文本、图片、音频、视频、文档在内的全量多模态输入。
| 能力 | generateContent | Interactions API |
|---|---|---|
| Batch API | ✅ 支持 | ❌ 暂不支持 |
| 显式缓存(explicit caching) | ✅ 支持 | ⚠️ 仅隐式缓存 |
| 视频 metadata 字段 | ✅ 支持 | ❌ 暂不支持 |
| Python 自动函数调用 | ✅ 支持 | ❌ 暂不支持 |
| 流式输出 / 函数调用 | ✅ 支持 | ✅ 支持 |
| 声称的成本与缓存命中率 | 常规计费 | 官方称成本更低、命中率更高 |
以 Nano Banana 图片生成这个具体场景为例,两种范式最直观的差异体现在取结果的方式上。Interactions API 提供了 interaction.output_image、interaction.output_text 这类便捷属性,可以直接拿到最后生成的图片或文本块;而 generateContent 走的是更底层的 candidates[0].content.parts 数组遍历方式,需要自己判断每个 part 的类型。对已经写好 generateContent 解析逻辑的项目来说,这种底层结构差异往往意味着一次不小的代码改造,不是简单换个 endpoint 就能完事。
这几项缺口并不是无关紧要的边角能力。Batch API 通常是成本敏感型项目批量处理离线任务的核心手段,一旦迁移后发现新范式不支持,相当于要重新设计整条离线处理链路;显式缓存则直接关系到长上下文场景的调用成本,如果业务里有大段固定的 system prompt 或参考资料需要反复复用,缺少显式缓存意味着无法精确控制哪些内容被缓存、缓存多久。这也是为什么官方文档会同时保留两条技术路线,而不是直接让 generateContent 退役——至少在这几项能力补齐之前,它仍然是无法被替代的。
🔧 实践建议: 如果你的业务重度依赖 Batch API 批量处理或显式缓存降本,现阶段贸然切到 Interactions API 可能会丢失这些能力,建议继续观察官方迁移指南的更新节奏,而不是急于替换生产环境代码。
API易网关实测:当前该用哪个范式
结论说在前面:截至 2026 年 7 月 4 日的实测,经 API易 网关调用 Gemini,应当继续使用 generateContent 原生格式。

API易 技术团队针对 Interactions API 的关键路径做了直接测试,覆盖了两种主流鉴权方式,结果如下。
| 测试端点 | 鉴权方式 | 结果 |
|---|---|---|
| POST /v1beta2/interactions | Bearer token | ❌ 404(Invalid URL) |
| POST /v1beta/interactions | Bearer token | ❌ 404(Invalid URL) |
| POST /v1beta2/interactions | x-goog-api-key header | ❌ 404(Invalid URL) |
| POST /v1beta/models/{model}:generateContent | Bearer token | ✅ 正常返回 |
API易 官方文档原话是:“API易 网关暂不支持 Interactions API 中转——/v1beta2/interactions 与 /v1beta/interactions 路径均返回 404”,并给出明确建议:“经 API易 调用 Gemini 请继续使用 generateContent 原生格式”。这也是为什么 API易 站内目前全部 Gemini 相关文档都统一基于 generateContent 格式编写,这样能保证读者复制代码就能直接跑通,不会遇到路径 404 的问题。
需要强调的是,这是一个动态状态,而不是永久限制。随着 Interactions API 逐渐成为官方默认范式,网关侧后续大概率会跟进支持;届时 API易 会更新对应文档,目前可以关注 docs.apiyi.com/api-capabilities/gemini/interactions-api 这个页面获取最新的支持状态,不需要每次都自己动手测试端点。
这组测试结果也提醒了一个容易被忽视的现实:官方文档层面的“正式可用”,和某个具体中转网关或第三方 SDK 是否已经完成适配,完全是两回事。开发者如果只看官方文档的默认展示,直接照抄 Interactions API 的代码示例塞进现有的中转配置里,大概率会先撞上 404,再花时间排查究竟是自己的代码写错了,还是网关本身还没跟上。遇到类似情况时,先确认自己的调用链路(直连官方还是经第三方中转)对新范式的支持状态,往往比反复检查业务代码更快定位问题。
🚀 快速开始: 如果你现在就想验证自己的 Gemini 调用链路是否正常,推荐直接使用 API易 apiyi.com 的 generateContent 格式接入,该平台提供统一的 base_url,支持文本、图片等多种 Gemini 模型的调用,不需要额外处理认证细节。
该怎么选:场景化决策建议
结合前面的能力对比和实测结论,给出一份简单的场景化建议表。

| 使用场景 | 推荐方案 | 理由 |
|---|---|---|
| 经 API易 网关调用 Gemini | generateContent | 网关当前仅支持该格式,Interactions API 路径返回404 |
| 依赖 Batch API 批量处理 | generateContent | Interactions API 暂不支持 Batch API |
| 需要显式缓存降低成本 | generateContent | Interactions API 目前只有隐式缓存 |
| 构建多轮对话 agent,直连官方API | 可评估 Interactions API | 服务端状态管理能省去历史拼接逻辑 |
| 需要观察模型中间执行步骤调试 | Interactions API | 提供observable execution steps原生支持 |
| 现有项目已用generateContent跑通 | 暂不迁移 | legacy仍完全支持,短期内还会获得新模型 |
简单来说,是否迁移不取决于“新不新”,而取决于你的具体依赖是否被 Interactions API 完整覆盖,以及你调用 Gemini 的链路(直连官方还是经中转网关)当前是否已经支持这套新范式。对大多数经 API易 中转调用的开发者来说,现阶段维持 generateContent 是更稳妥的选择。
常见问题
Q1: generateContent 会被下线吗?现在还值得基于它开发新项目吗?
短期内不会。官方明确表示 generateContent 虽然被标记为 legacy,但“仍然完全支持”,并且在可预见的未来还会持续获得新的主线 Gemini 模型。如果你经 API易 apiyi.com 调用 Gemini,现阶段基于 generateContent 开发新项目完全没有问题,不必因为文档默认展示 Interactions API 就产生焦虑。
Q2: API易 网关什么时候会支持 Interactions API?
目前没有确切时间表,这取决于该范式在官方生态的普及程度和网关侧的适配进度。建议关注 API易 apiyi.com 平台的官方文档更新,一旦支持 Interactions API 中转,相关文档会第一时间同步更新,不需要自行反复测试端点状态。
Q3: 两种 API 可以在同一个项目里混用吗?
从技术上讲,只要调用链路支持,两种范式可以并存,比如用 generateContent 处理 Batch API 批量任务,同时在直连官方 API 的多轮对话场景试用 Interactions API。但经 API易 网关调用时,由于 Interactions API 路径当前返回 404,建议暂时统一使用 generateContent 格式,避免同一项目里出现两套不一致的调用逻辑增加维护成本。
总结
Interactions API 在 2026 年 6 月转正后,确实代表了 Google 对 Gemini 调用方式的长期方向,服务端状态管理、可观测执行步骤这些能力对 agent 类应用很有吸引力,但它在 Batch API、显式缓存、视频 metadata 等方面还有明显缺口,generateContent 依旧完全支持且短期内还会持续更新。更重要的是,经 API易 网关调用 Gemini 时,截至目前的实测结果是 Interactions API 相关路径均返回 404,generateContent 才是当前唯一可用的格式。如果你需要稳定可靠地调用 Gemini 系列模型,推荐通过 API易 apiyi.com 使用 generateContent 原生格式接入,后续网关支持新范式后会及时更新文档。
本文实测数据和官方信息核实均由 API易 技术团队完成,如需了解 Gemini 系列模型更多调用细节,欢迎通过 API易 apiyi.com 联系技术支持。
参考资料
-
Google AI for Developers – Interactions API 概览: Interaction 概念、核心方法与能力说明
- 链接:
ai.google.dev/gemini-api/docs/interactions-overview
- 链接:
-
Google AI for Developers – generateContent(Legacy): 遗留API的支持状态与能力范围
- 链接:
ai.google.dev/gemini-api/docs/interactions
- 链接:
-
API易官方文档 – Gemini Interactions API 支持状态: 网关实测端点结果与调用建议
- 链接:
docs.apiyi.com/api-capabilities/gemini/interactions-api
- 链接: