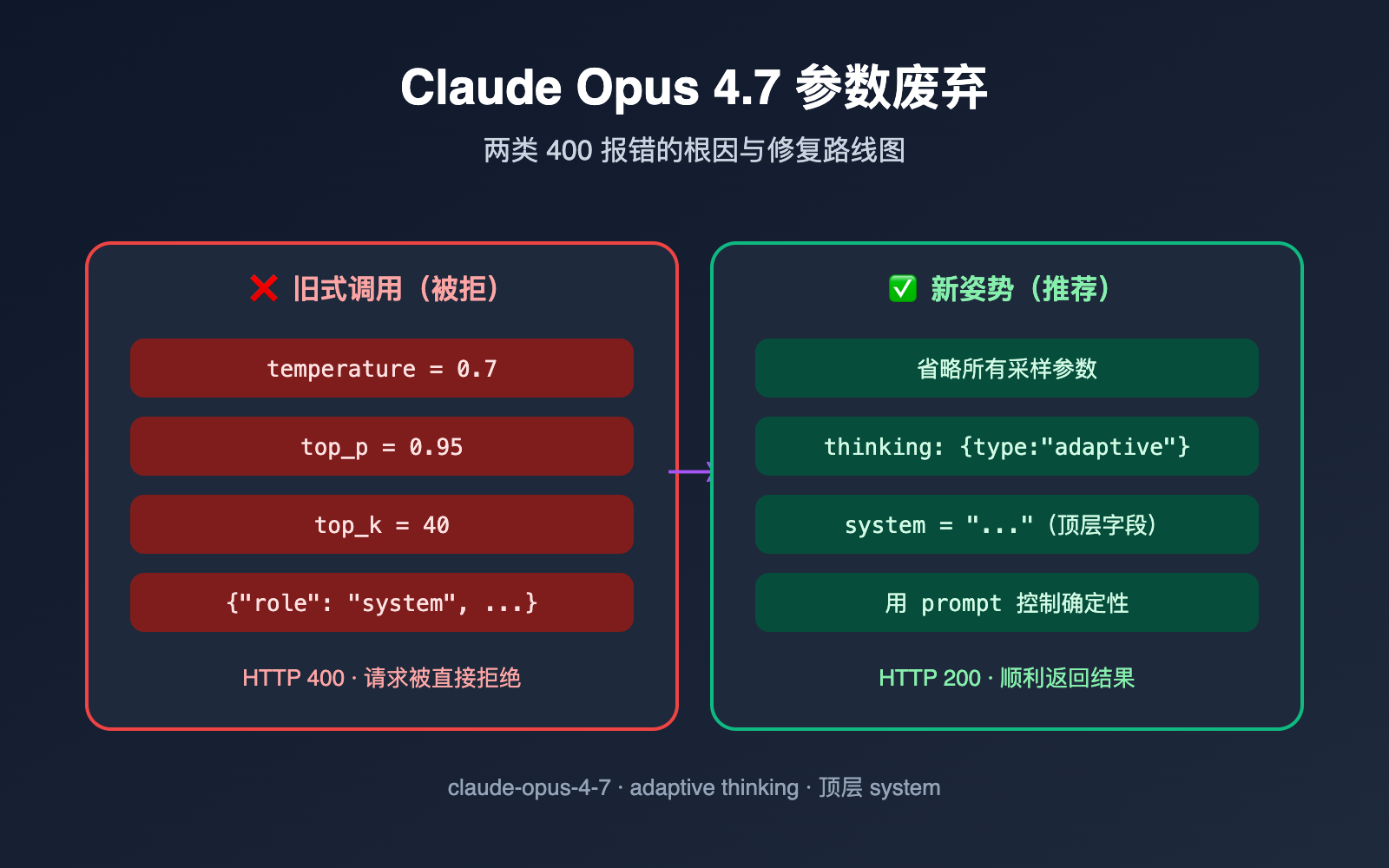
作者注:Claude Opus 4.7 废弃了 temperature、top_p、top_k 等采样参数,并要求 system 走顶层而非消息角色。本文讲清 2 大常见 400 报错的根因与代码修复方案。
升级到 Claude Opus 4.7 之后,最容易被开发者卡住的不是模型本身,而是请求参数。第一个高频报错是 temperature is deprecated for this model,第二个则是 Unexpected role "system". The Messages API accepts a top-level system parameter, not "system" as an input message role。两个错误都是 HTTP 400,看起来无关,背后却指向同一个事实:Anthropic 在 Opus 4.7 上做了一次相对激进的 API 收敛。
很多团队在没看清这次变动前,会习惯性地把"温度调到 0"或者"再加一条 system 消息"作为提高确定性的银弹。Opus 4.7 直接堵死了这两条路。这篇指南会从原因、报错、修复三个角度,把这两类问题彻底讲清楚,并附上能直接复制的迁移代码。看完之后,你不仅能在 10 分钟内排除掉手头的 400 报错,还能理解 Anthropic 这次设计变更背后的深层逻辑,避免在下一次模型升级时再次踩坑。
Claude Opus 4.7 废弃了哪些参数
理解报错之前,先看一份完整的"废弃清单"。Anthropic 在 Opus 4.7 上做的变动比看起来要多,影响面也比 4.6 时代的 deprecation 大很多。
| 参数 | 状态 | 行为 | 替代方案 |
|---|---|---|---|
temperature |
废弃 | 设置任意非默认值返回 400 | 完全省略,用 prompt 控制随机性 |
top_p |
废弃 | 同上 | 完全省略 |
top_k |
废弃 | 同上 | 完全省略 |
thinking.budget_tokens |
移除 | 显式预算返回 400 | thinking: { type: "adaptive" } |
reasoning_effort(旧式) |
移除 | 旧字段不再生效 | output_config: { effort: "max" } |
消息中的 role: "system" |
不支持 | 历来如此,但在 4.7 报错更严格 | 顶层 system 参数 |
🎯 升级前必看:若你用 Python SDK,旧代码里出现
temperature=0.7、top_p=0.95或messages=[{"role": "system", ...}]任意一项,都会在 Opus 4.7 上抛 400。我们建议通过 API易 apiyi.com 接入 Opus 4.7,平台对参数兼容做了优雅降级,可以平滑过渡到新接口。
清单里最容易忽视的是 thinking 参数。Opus 4.6 时代你可以传 thinking: {"type": "enabled", "budget_tokens": 8000} 让模型多想一会儿,但在 Opus 4.7 上这种用法直接被拒。新版本只接受 adaptive 类型,由模型自行决定推理强度,而且 adaptive thinking 默认是关闭的,需要显式打开。
另一个隐藏的变动是 tokenizer。Opus 4.7 使用了新的 tokenizer,同一段文本在新模型上的 token 数会比 4.6 多 0% 到 35%。这意味着你按 4.6 估算的成本预算,在 4.7 上很可能"无声涨价",需要重新核对账单。
为什么 Claude Opus 4.7 要废弃 temperature 参数
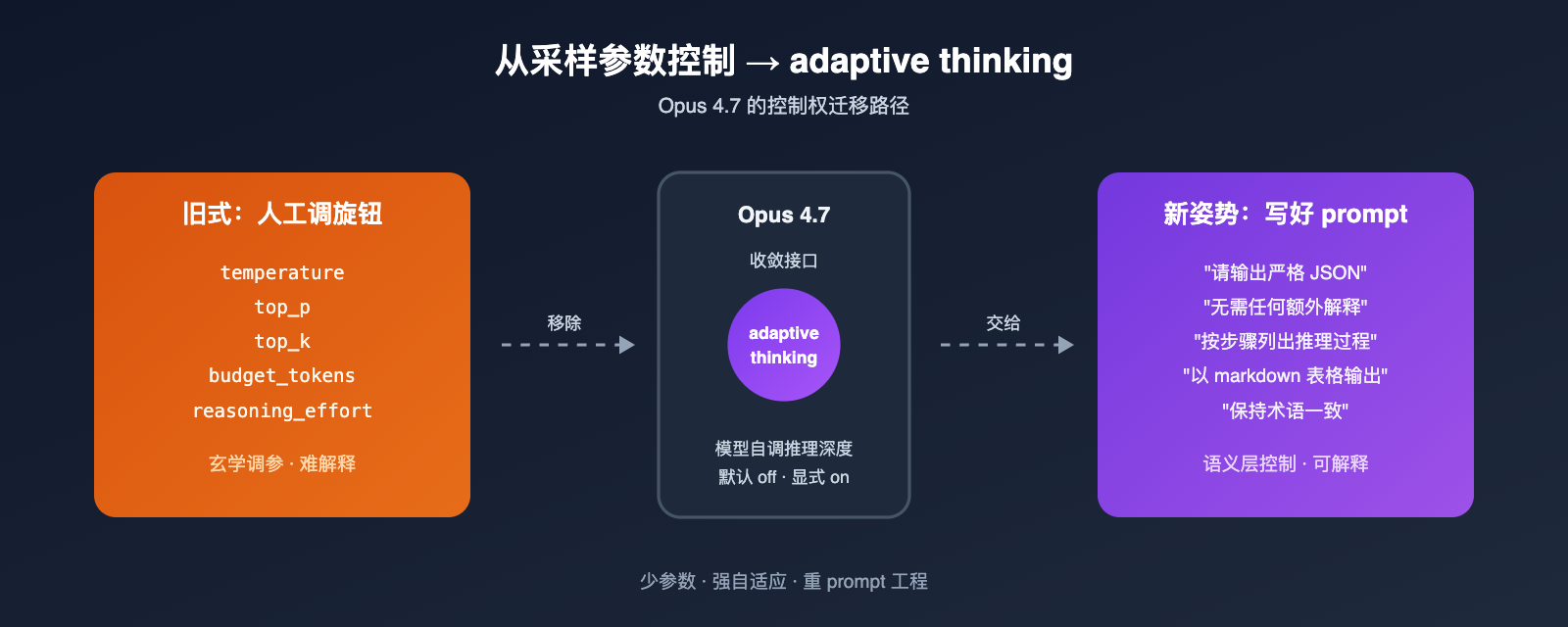
理解这次变动的内在逻辑,能让你少踩很多坑。Anthropic 之所以在 Opus 4.7 上"收回" temperature、top_p、top_k 这三个采样参数,本质上是把模型从"可调参数库"转向了"自适应黑盒"。
从模型架构来看,Opus 4.7 把推理强度的控制权交给了 adaptive thinking 模块,这一模块本身就内含了对不确定性的调度。也就是说,温度这一类"在采样层调节随机性"的手段,已经无法和模型内部的推理逻辑兼容,强行设置反而会破坏新版的优化路径。Anthropic 在文档里直接给出了结论:在内部评测里,adaptive thinking 稳定优于 extended thinking 加手动 temperature 的组合。
换个角度看,这次"砍掉旋钮"也是一次面向新手的友好升级。过去开发者调 LLM 时,最容易陷入"是不是温度调得不对"的玄学纠结,调来调去既找不到最优值,也无法解释结果差异。Opus 4.7 直接把这条"似是而非"的优化路径关上,让大家把精力放到 prompt 设计和上下文管理这些真正能稳定带来收益的事情上。
从工程实践来看,三大采样参数的废弃也意味着 Anthropic 不再鼓励"靠调温度提稳定性"这种古早做法。新版的推荐姿势是用 prompt 工程明确"你需要确定性的答案"、"请输出严格 JSON"等,让模型在语义层自我约束,而不是在采样层硬控。我们建议团队在用 API易 apiyi.com 调用 Opus 4.7 时,把原本依赖 temperature=0 的代码逐步迁移到"在 system prompt 中明确要求确定性"的写法。
这一思路其实和 GPT-5.5 的"五档 reasoning effort"形成对照。OpenAI 是"给开发者更细的开关",Anthropic 是"把开关收回去交给模型自己",两种哲学没有谁对谁错,但都明显在弱化传统 hyperparameter 调优的角色。对开发者最大的启示是:未来的 LLM 调优,重心会从"调旋钮"转向"写好提示词与上下文"。
值得一提的是,Anthropic 这次"激进收敛"并非没有先兆。Opus 4.6 时代就已经在文档里把 extended thinking 标记为 deprecated,并提示开发者向 adaptive thinking 过渡。如果你那时就开始按推荐姿势写代码,这次 4.7 升级几乎是零成本的;反之,如果你一直靠"调高 temperature 拉创意、调低 temperature 拉稳定"这套老打法,那么这次迁移会比较痛。
temperature 参数报错 400 的修复方案
知道了原因,修复就很直接。下面给出最小修复示例,配合 API易 apiyi.com 的 base_url 即可在国内稳定运行。
# pip install anthropic
from anthropic import Anthropic
client = Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com" # 通过 API易统一调用 Opus 4.7
)
# ❌ 旧代码:会触发 temperature is deprecated 400
# response = client.messages.create(
# model="claude-opus-4-7",
# max_tokens=1024,
# temperature=0.7,
# top_p=0.95,
# messages=[{"role": "user", "content": "Hello"}]
# )
# ✅ 新代码:完全省略采样参数
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
system="You must return strict JSON. No extra commentary.",
messages=[{"role": "user", "content": "Hello"}]
)
🎯 快速修复建议:把
base_url切到https://api.apiyi.com,并使用 API易 apiyi.com 发放的 Anthropic 兼容 Key,旧代码里只需删掉三行采样参数即可跑通。如果你担心一时改不完,API易 apiyi.com 默认对废弃参数做了平滑降级,可以为你的迁移留出缓冲期。
下面这张表整理了三种典型迁移姿势,帮你选择最合适的方案。
| 旧用法 | 新姿势 | 收益 |
|---|---|---|
temperature=0 追求确定性 |
system prompt 写"返回严格 JSON,不要多余文字" | 输出更稳,token 更省 |
temperature=1 追求创意 |
不设置任何采样参数,让模型自由发挥 | 更接近 4.7 的原生表现 |
top_p / top_k 限制采样 |
配合 adaptive thinking 的 effort: "max" |
用推理深度替代采样裁剪 |
如果你接的是 OpenAI 兼容协议(很多三方框架默认这一套),还需要额外检查 SDK 是否在底层强塞 temperature=1.0。社区里已经有不少 Issue 是因为框架硬编码默认值导致 Opus 4.7 拒绝请求,遇到这种情况要么升级框架,要么走 API易 apiyi.com 的兼容层。
system 角色报错的本质与修复
第二个高频 400 报错和 temperature 没关系,是个老问题在新模型上"重新被放大"。Anthropic 的 Messages API 从未支持过把 system 写成消息角色,但很多从 OpenAI Chat Completions 迁移过来的代码会下意识地这么写,于是就触发了 Unexpected role "system" 报错。
理解这件事的关键在于:Anthropic 把 system 视为"会话级配置"而不是"对话内容"。它必须出现在请求体顶层,而不是 messages 数组里。下面这张表对照了 OpenAI 和 Anthropic 的差异。
| 项目 | OpenAI Chat Completions | Anthropic Messages |
|---|---|---|
| system 位置 | messages 数组首条 |
请求体顶层 system 字段 |
| system 数量 | 可以多条 | 仅一个字符串 |
| 在 4.7 报错 | 无 | Unexpected role "system" 400 |
| 迁移难度 | — | 低,仅需移动位置 |
🎯 迁移提示:如果你的项目里有"OpenAI / Claude 双跑"逻辑,建议封装一层适配器:调 OpenAI 时把 system 放进 messages,调 Claude 时改成顶层
system。通过 API易 apiyi.com 接入两边模型,可以用同一套 Key 体系管理,避免重复配置。
修复方法非常直接。下面是错误写法与正确写法的对比,照搬即可。
# ❌ 错误写法:触发 Unexpected role "system" 400
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[
{"role": "system", "content": "You are a coding assistant."},
{"role": "user", "content": "Write a quicksort in Python."}
]
)
# ✅ 正确写法:system 走顶层参数
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
system="You are a coding assistant.",
messages=[
{"role": "user", "content": "Write a quicksort in Python."}
]
)
需要补充一句的是,如果你确实想给 Claude"多段 system 指令",正确做法是把它们合并成一个字符串,用换行或者编号分隔。Anthropic SDK 也支持把 system 字段做成数组形式的 content block,但这是高阶用法,新手按"单字符串"理解即可。这样写还有一个隐藏收益:合并成单字符串后,更容易触发 API易 apiyi.com 的提示缓存命中,长跑任务的成本会进一步下降。
Claude Opus 4.7 完整迁移代码模板
把两类报错的修复合在一起,下面这段代码就是"一份能直接跑的 Opus 4.7 起手式",包含 adaptive thinking、system 顶层参数和缓存计费友好的写法。
from anthropic import Anthropic
client = Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com" # 通过 API易调用 Opus 4.7
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
system="You are an expert Python engineer. Always return strict JSON.",
thinking={
"type": "adaptive",
"display": "summarized"
},
messages=[
{"role": "user", "content": "Refactor my quicksort to be O(n log n) average."}
]
)
print(response.content[0].text)
🎯 生产环境建议:在 API易 apiyi.com 调用 Opus 4.7 时,把稳定不变的 system prompt 与工具描述前置,触发缓存计费 0.1x,重复请求的成本能压到原价的 10%。这对长跑 Agent、文档生成类任务尤其友好。

实际迁移时还有几个小细节值得留意。第一,thinking 字段不是必填,但如果你的任务对推理深度敏感,建议显式打开 adaptive thinking,否则模型会保持默认的轻量推理模式。第二,由于新 tokenizer 会让同样的文本多算 0% 到 35% token,max_tokens 的预算要相应上调,否则可能在长输出场景被截断。第三,旧版的 thinking_budget 等周边参数也要一并清掉,残留字段不会报错但会被忽略,容易让你误以为还在生效。第四,如果你的应用同时调用 4.6 和 4.7,最好按模型名记录账单口径,避免新旧 tokenizer 混淆导致成本归因失真。
如果你正在维护一份既要兼容 Opus 4.6 又要兼容 Opus 4.7 的代码库,最稳的做法是按模型名做参数白名单。把"采样参数 + 旧 thinking 字段"在调 4.7 时跳过,在调 4.6 时保留,这样不必为不同模型维护两套调用函数。
下面这张报错速查表汇总了 Opus 4.7 升级过程中最常见的几类 400 错误,方便你按报错文本直接定位修复点。
| 报错关键字 | 报错含义 | 修复方法 |
|---|---|---|
temperature is deprecated |
传入了被废弃的 temperature 字段 | 从请求体里完全删除 temperature |
top_p is deprecated |
传入了被废弃的 top_p 字段 | 删除 top_p,让模型自适应 |
top_k is deprecated |
传入了被废弃的 top_k 字段 | 删除 top_k,让模型自适应 |
| Unexpected role "system" | system 写在了 messages 数组里 | 改为请求体顶层 system 字段 |
Invalid budget_tokens |
用了旧版 extended thinking 预算 | 改为 adaptive thinking 不传 budget |
Unknown parameter reasoning_effort |
用了旧版推理强度字段 | 改为 output_config: {effort: "max"} |
Claude Opus 4.7 参数废弃常见问题
Q1:为什么 Opus 4.7 要一次性废弃这么多参数?
核心原因是 adaptive thinking 接管了原本由 temperature、top_p、top_k、thinking budget 各自负责的"控制随机性与推理深度"职责。Anthropic 内部评测显示,adaptive thinking 稳定优于人工调参,所以选择把入口收敛。
Q2:能不能把 temperature 设成 1.0 来"绕过"报错?
不能。Opus 4.7 对采样参数的判断是"是否传了",而不是"传的是什么值"。只要请求体出现这个 key,就会被识别为非默认配置并返回 400。正确做法是请求里完全不出现这个字段,让 SDK 用模型自己的默认行为去采样。
Q3:用 OpenAI SDK 通过 API易调 Opus 4.7 会触发 temperature 报错吗?
要看 SDK 版本和上层框架。OpenAI SDK 默认会带上 temperature=1.0,如果直接转发到 Anthropic 后端,仍会被 Opus 4.7 拒绝。通过 API易 apiyi.com 调用时,平台已对这一类常见兼容性做了优雅处理,会自动把废弃字段过滤掉。
Q4:system 报错只在 4.7 出现吗?以前的 Claude 模型不会吗?
不是。Anthropic Messages API 从来不允许把 system 写进 messages 数组,但 Opus 4.7 的校验更严格了,部分早期模型可能会"宽松接收"。最佳实践始终是把 system 放在请求体顶层,迁移到顶层之后所有 Claude 模型都能正常工作。
Q5:从 OpenAI 迁过来的代码,最少改几行能跑 Opus 4.7?
通常三处:1)model 改成 claude-opus-4-7;2)messages 里的 system 条目搬到顶层 system 字段;3)删除 temperature、top_p 等采样参数。把 base_url 切到 https://api.apiyi.com,整个项目通常能在 10 分钟内跑通。如果你的项目有几十个调用点,建议先封装一个统一的 call_claude() 工具函数,把这三处修改集中收口,未来再有 API 变动也只改一个地方。
Q6:adaptive thinking 默认开吗?要不要显式打开?
默认是关闭的。如果你的任务对推理深度敏感(数学推理、代码重构、复杂规划),建议显式传 thinking: {type: "adaptive"}。可以再配合 output_config: {effort: "max"} 获得最强思考能力,代价是 token 用量上升,需要在质量与成本之间做权衡。
Q7:Opus 4.7 在国内调用稳定吗?
直连 Anthropic 接口可能受到网络环境影响,长跑任务尤其容易断。通过 API易 apiyi.com 调用 Opus 4.7 可以解决境内访问稳定性问题,平台已稳定运行,配合缓存计费 0.1x 还能显著降本。
Q8:新 tokenizer 让成本上涨多少?怎么应对?
新 tokenizer 在不同文本上的膨胀比例在 0% 到 35% 之间,平均约 10% 到 15%。最实用的应对是把可缓存的 system prompt、工具描述前置,触发缓存计费 0.1x,单次成本会反向下降而不是上涨。
Claude Opus 4.7 参数废弃核心要点
- Opus 4.7 完全废弃
temperature、top_p、top_k三大采样参数,传任意值都会触发 400 报错。 - Extended thinking 已移除,仅支持 adaptive thinking,且默认关闭,需显式启用。
Unexpected role "system"是 Messages API 的历史规则,system 必须走顶层而非消息角色。- 新 tokenizer 使同样文本的 token 数比 4.6 多 0% 到 35%,预算和 max_tokens 都要重新核算。
- 修复最少只需三步:删除采样参数、把 system 搬到顶层、模型名改为
claude-opus-4-7。 - 通过 API易 apiyi.com 调用 Opus 4.7 可享受参数兼容优雅降级、缓存计费 0.1x 与境内稳定接入。
- adaptive thinking 配合
output_config: {effort: "max"}是 Opus 4.7 上获取最强推理能力的标准姿势。
总结
Claude Opus 4.7 的参数废弃看上去是"破坏性变更",实质上是 Anthropic 把模型从一个"暴露细节的工具"演化成"自适应黑盒"的关键一步。对开发者而言,这意味着原来靠 temperature、thinking budget 等"开关"调出来的稳定性,要逐步迁移到 prompt 工程和 adaptive thinking 的组合上。短期内会带来迁移成本,长期看会让代码更简洁、模型表现更稳定。这条演化路径并不孤立,主流大模型都在朝着"少参数、强自适应"的方向走,越早适应越有红利。
如果你正在升级到 Opus 4.7 或评估这次变更对生产的影响,建议先在 API易 apiyi.com 上接入新版调试,平台已稳定支持 Opus 4.7 并对废弃参数做了兼容降级,配合缓存计费 0.1x 是当前最低门槛的迁移路径。
愿你少踩坑、早下班。
— APIYI 技术团队,更多 AI 模型实战教程见 API易 apiyi.com