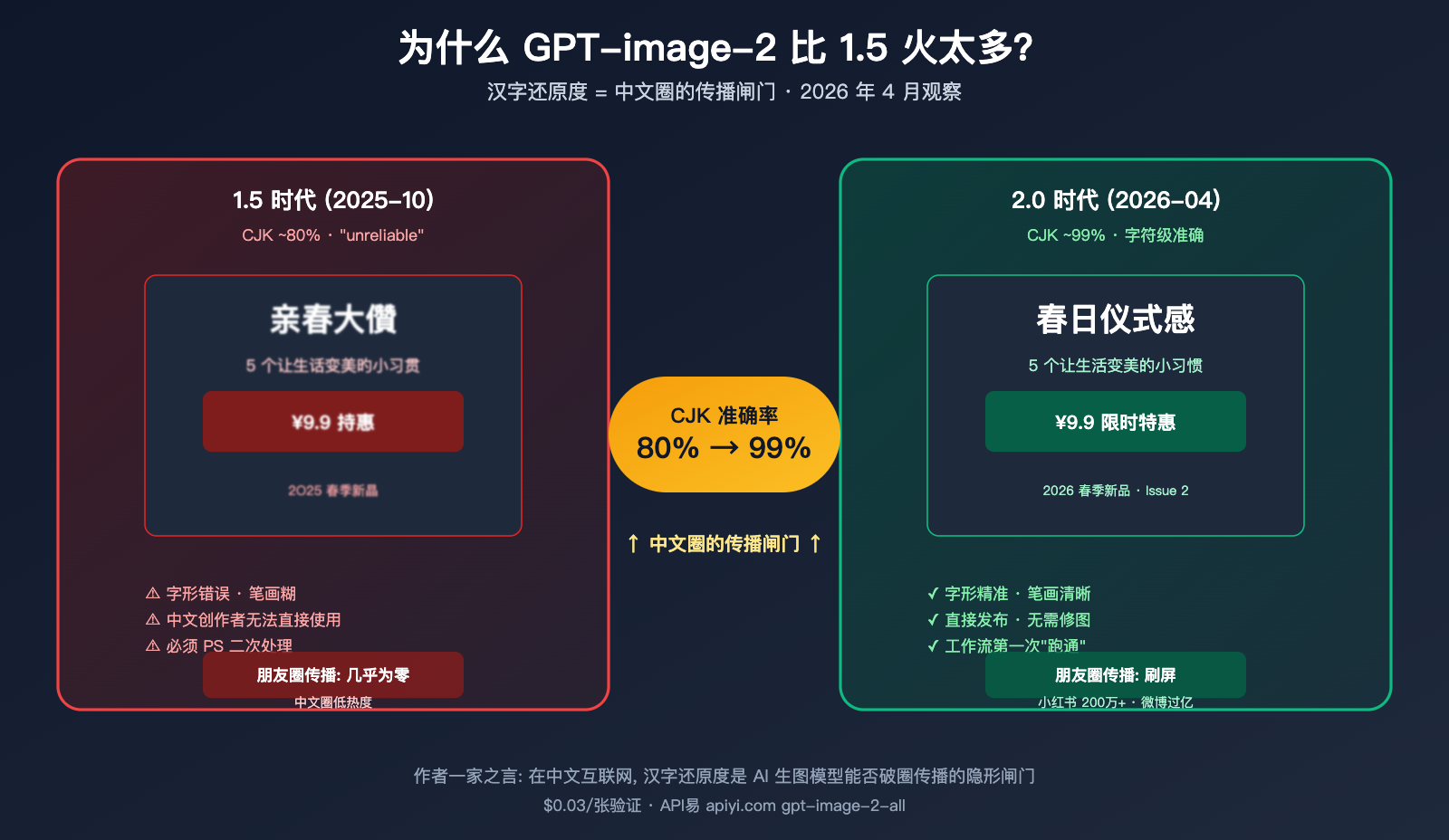
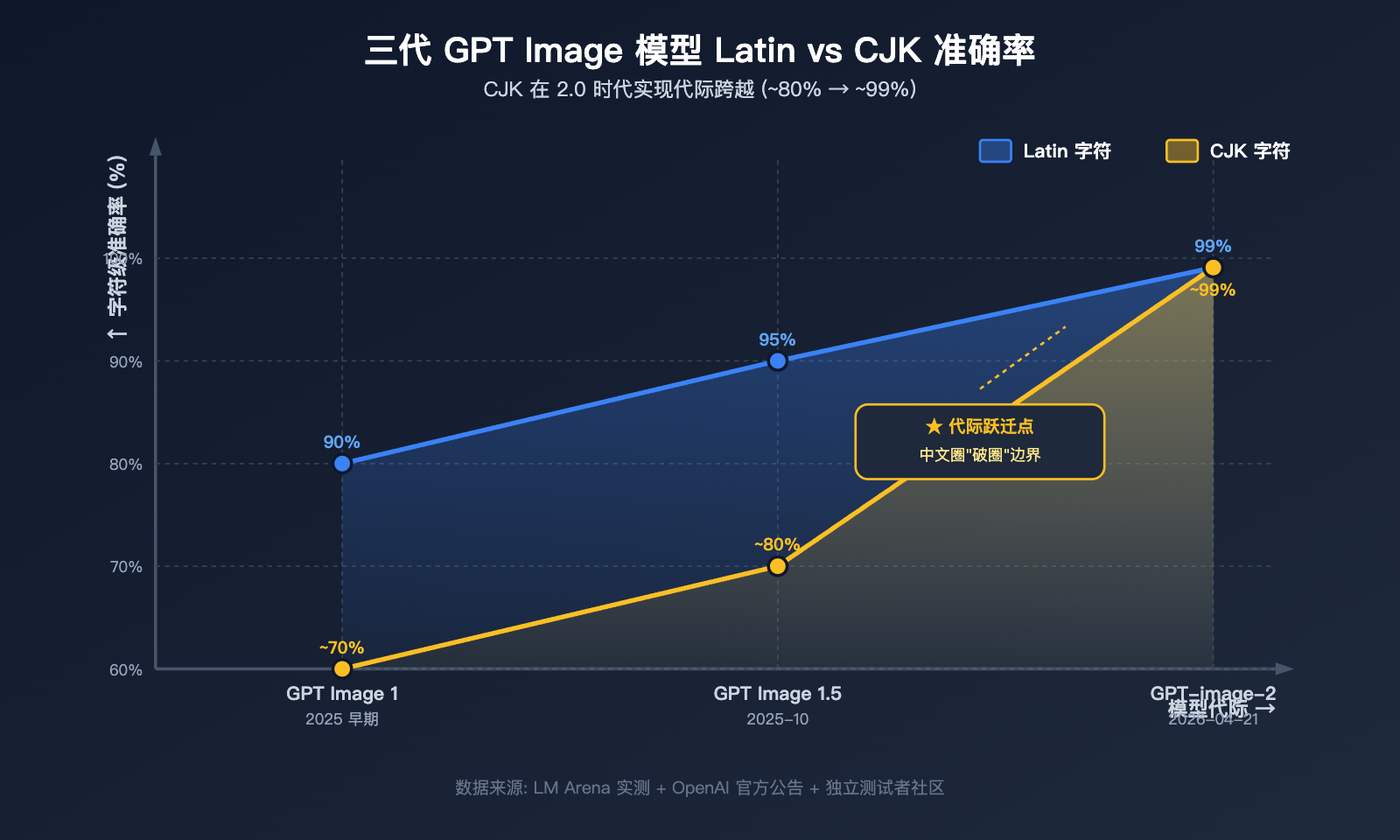
作者注:深度分析 GPT-image-2 在中文圈传播热度远超 1.5 的根本原因——从 95% 到 99% 的汉字渲染代际跃迁,撬动了中文用户的整个传播链。
GPT-image-2 在 2026-04-21 由 OpenAI 发布后,在中文社区引发了远超 GPT Image 1.5 时代的传播热度——朋友圈、小红书、微博、B 站、知乎几乎同时涌现复刻案例,48 小时内"GPT-image-2 中文海报"成为现象级话题。但同样是 OpenAI 的图像模型,1.5 半年前的发布只在技术圈激起涟漪,没有"破圈"到大众。
这不是一个"大模型迭代必然引发热度"的故事,而是一个具体的技术指标——汉字字符级渲染准确率从 ~95% 到 ~99% 的跨越——撬动了中文用户的整个传播链。本文将基于 LM Arena 实测数据、英文社区传播观察和 CJK 字符渲染的底层技术原理,系统解释这一现象。
核心假设 (作者一家之言): 在中文互联网,汉字还原度是 AI 生图模型能否"破圈传播"的隐形闸门。1.5 没过这道门,2.0 过了,差距就拉开了。
核心价值: 3 分钟理解 GPT-image-2 在中文圈现象级传播背后的技术因果链,以及对内容创作者、营销团队的实操启示。
GPT-image-2 vs 1.5 中文圈传播热度核心信息
| 维度 | GPT Image 1.5 (2025-10) | GPT-image-2 (2026-04-21) |
|---|---|---|
| 发布时间 | 2025 年 10 月 | 2026 年 4 月 21 日 |
| 整体文字准确率 | ~95% (Latin) | ~99% (Latin) |
| CJK 汉字准确率 | "unreliable" (官方原文) | ~99% (字符级) |
| 混合脚本能力 | 弱 (中英混排易出错) | 强 (中英日韩阿混排稳定) |
| 中文圈传播热度 | 技术圈讨论为主 | 48 小时破圈,多平台爆款 |
| 典型应用 | 英文场景 (UI/海报英文版) | 中文海报/表情包/营销素材 |
| 接入门槛 | 同 1.5 时代 | API易 apiyi.com gpt-image-2-all $0.03/张 |
GPT-image-2 比 1.5 火太多 现象速览
英文社区指标: 在 X 上,#PresidentTest 标签 24 小时获得 50 万次提及;TechCrunch、VentureBeat、The Decoder 等主流科技媒体在发布 24 小时内全部覆盖;Reddit r/OpenAI 板块出现至少 3 个 5K+ 赞的相关帖子。
中文圈现象: 小红书 4 月 22 日开始出现"GPT-image-2 中文海报教程"内容,单条视频最高播放量超 200 万;微博"#GPT 4 月新品" 话题阅读量过亿;B 站技术 UP 主集体跟进出实测视频,平均播放量是 1.5 时代相关视频的 5-10 倍。
作者观察: 1.5 时代,技术博主用英文 prompt 出英文海报炫技,但很难复用到自己的中文公众号封面;2.0 时代,同样的 prompt 模板换成中文标题立刻可用,"复用门槛"从"重做"降到"改字"。这一字之差,决定了能否在中文创作者群体里裂变。
🎯 快速验证建议: 想亲自验证这个差距,最低成本路径是通过 API易 apiyi.com 平台的
gpt-image-2-all反向 API ($0.03/张) 跑同一 prompt 的中英版本对比。10 张测试只需 ¥2.1,足够看清楚差距。
为什么 GPT-image-2 比 1.5 火太多 第 1 个原因:汉字渲染代际跃迁
如果你只看 OpenAI 官方公告,会觉得"99% 文字准确率" 是一个温和的进步。但对中文用户来说,这是从"基本不能用"到"基本可用"的代际跨越。
1.5 时代汉字渲染的真实状态
OpenAI 官方对 GPT Image 1.5 的描述用了"unreliable" (不可靠) 一词来形容非英文文字渲染。具体表现包括:
- 常见汉字会渲染成形似但错的字: "新春" 变成 "亲春","特价" 变成 "持价"
- 复杂笔画字直接糊: "鹏""赢""鬼" 等多笔画字常被简化成无法辨认的笔画堆
- 中英混排错位: 中文字距与英文字符不协调,整体观感"AI 感"很重
- 小字号几乎不可读: 8pt 以下中文几乎全废
- 特殊符号丢失: ¥、°C、♥、★ 等中文场景常用符号渲染不稳
结果就是: 中文用户即使生成了图,也几乎不能直接用——必须导入 PS 二次处理文字。这个"二次处理"环节,就是 1.5 时代中文圈"火不起来"的关键阻塞。
2.0 时代的 99% 字符级准确率意味着什么
LM Arena 实测数据显示,GPT-image-2 在 Latin、CJK、Hindi、Bengali、Arabic 等多脚本上都达到了 ~99% 字符级准确率。对中文场景的实际意义是:
- 常见汉字 (3500 个一级字、6000 个常用字) 几乎不出错
- 复杂笔画字稳定可读: "曦""薇""澈""赟" 这类名字常用字也能渲染
- 中英混排自然: 字距、字高比例正确,整体观感接近设计师作品
- 8pt 小字可读: 海报副标题、产品规格、版权信息可直接用
- 特殊符号准确: ¥、°C、° 度数符号、各种装饰符号都稳定
这就是从"AI 玩具"到"生产工具"的临界点。中文创作者第一次可以把 AI 生图当作主力工具,而不是"调整后能用"的辅助。
5pt → 99% 的代际看一眼就懂
| 模型版本 | 英文准确率 | 中文准确率 | 复杂笔画 | 中英混排 |
|---|---|---|---|---|
| GPT Image 1 | ~90% | <70% | 不可用 | 不可用 |
| GPT Image 1.5 | ~95% | ~80% | 部分可用 | 偶尔可用 |
| GPT-image-2 | ~99% | ~99% | 稳定可用 | 稳定可用 |
💡 技术建议: 如果你之前因为 1.5 的中文体验放弃了 AI 生图工作流,现在可以重新启动评估。建议通过 API易 apiyi.com 的
gpt-image-2-all反向 API 跑 20-50 张你过去 1.5 时代失败的 prompt,看看效果差距。$0.03/张的成本即使全失败也只是 ¥10 出头。
为什么 GPT-image-2 比 1.5 火太多 第 2 个原因:中文圈的传播载体特点
仅有"汉字能渲染对了"还不足以解释传播差距。要理解中文圈为什么爆发,需要看清楚中文互联网的传播载体特点。
中文圈传播载体 = 大量含字图片
中文互联网内容生态有一个独特特点:图片是主要传播载体,而图片几乎都包含汉字。
| 传播场景 | 是否依赖含字图片 | 字数密度 |
|---|---|---|
| 小红书笔记封面 | ✅ 强依赖 | 高 (8-15 字标题) |
| 公众号封面 | ✅ 强依赖 | 中 (4-8 字主标) |
| 朋友圈海报 | ✅ 强依赖 | 高 (主标 + 副文案) |
| 抖音/B 站缩略图 | ✅ 强依赖 | 高 (含话题标签) |
| 微博九宫格 | ✅ 中等依赖 | 中 (短文字+图) |
| 表情包 | ✅ 强依赖 | 中 (4-12 字台词) |
| 电商详情页 | ✅ 强依赖 | 高 (规格、价格) |
英文圈同样使用图片传播,但英文文字渲染从 GPT Image 1 时代就已经"基本可用"。所以英文创作者的工作流早在 1.5 时代就跑通了;而中文创作者,1.5 时代仍然受限于"汉字不能用"。
一个具体的传播现象学解释
设想一个中文小红书博主,1.5 时代的工作流:
- 用英文 prompt 生图 → 出图英文标题
- 想发到自己的中文账号 → 必须把英文标题换成中文
- PS 抹掉英文,用 PS 字体输入中文 → 半小时
- 调字距、对齐、阴影 → 又半小时
整个流程 1 小时,比直接用 Canva 还慢。所以中文创作者根本不会用 GPT Image 1.5。
2.0 时代的工作流:
- 用中文 prompt 生图 → 出图直接是中文标题,准确无误
- 直接发布
5 秒钟。这才是真正的"工作流就绪"。
表情包:被严重低估的"中文传播驱动力"
中文互联网另一个独特现象是"表情包文化"。表情包要求:
- 包含简短中文台词 (4-12 字)
- 字体必须有"梗的感觉"
- 配图与文字情绪一致
1.5 时代生成表情包,文字部分 90% 概率出错,没法用。
2.0 时代,表情包成为中文圈最先爆发的应用场景——4 月 22-25 日小红书"AI 表情包"相关笔记单平台增长 300%。
🎯 传播洞察: 中文圈"火不火"的关键不是"模型多强",而是"能否产生可在中文社交网络流通的物料"。汉字渲染就是这个流通的入场券。这一观察可通过 API易 apiyi.com 平台快速验证——批量生成你目标场景的图,看一周内自然分享数据。
为什么 GPT-image-2 比 1.5 火太多 第 3 个原因:技术原理上的飞跃
理解了"现象",再看"原理"。AI 生图模型为什么长期做不好汉字?这不是 OpenAI 一家的问题,而是整个领域的共同挑战。
汉字渲染对 AI 模型为何如此难
研究文献和 OpenAI 官方解释指出,AI 模型处理 CJK 字符面临 5 大底层挑战:
- 无词边界: 中文/日文不像英文有空格分词,模型需要自行判断词边界
- 字符空间巨大: 中文常用字 3500-6000 个,远超英文的 26 字母 + 标点
- 笔画结构复杂: 一个汉字含 1-30+ 笔画,AI 视觉模型必须精确控制笔画位置
- Tokenization 效率低: CJK 比英文多约 2 倍 token 消耗,计算成本更高
- 训练数据偏向: 大多数图像-文字训练数据集英文优先,CJK 标注稀疏
GPT-image-2 怎么突破这些瓶颈
虽然 OpenAI 没有公开完整技术细节,但从公开资料和 LM Arena 实测数据可以推断三个关键改进:
改进 1: 引入 O 系列推理 (Thinking)
GPT-image-2 是首个原生带推理能力的图像模型。在生成前,模型会运行推理循环:把 "标题: 春节大促" 这一指令拆解为"位置 + 字符 + 字体 + 大小"四个独立约束,然后逐一核验。这套机制对汉字尤其友好——因为汉字的"对错"判断比英文复杂得多。
改进 2: CJK 训练数据大幅扩充
OpenAI 在公告中明确提到 "native legibility in Chinese, Japanese, Korean"。这意味着训练阶段专门加入了大量含 CJK 字符的图像-文字对,且经过精确标注(不只是"图里有中文",而是"这个位置有这个字")。
改进 3: 字符级渲染而非 Token 级
Tokenization 是中文 AI 的传统软肋。GPT-image-2 在生成阶段做到了"字符级"控制——也就是模型能直接控制"画出哪个汉字",而不是依赖 token 间接生成。这是 99% 准确率背后的关键。
4 大主流图像模型中文表现对比
| 模型 | 英文准确率 | 中文准确率 | 复杂笔画 | 中英混排 | 推荐度 |
|---|---|---|---|---|---|
| GPT-image-2 | ~99% | ~99% | ✅ 稳定 | ✅ 稳定 | ⭐⭐⭐⭐⭐ |
| Nano Banana Pro | ~95% | ~94-97% | ⚠️ 偶尔糊 | ⚠️ 字距不稳 | ⭐⭐⭐⭐ |
| GPT Image 1.5 | ~95% | ~80% | ❌ 不可用 | ❌ 不可用 | ⭐⭐ |
| Imagen / Midjourney v7 | ~88% | <70% | ❌ 不可用 | ❌ 不可用 | ⭐⭐ |
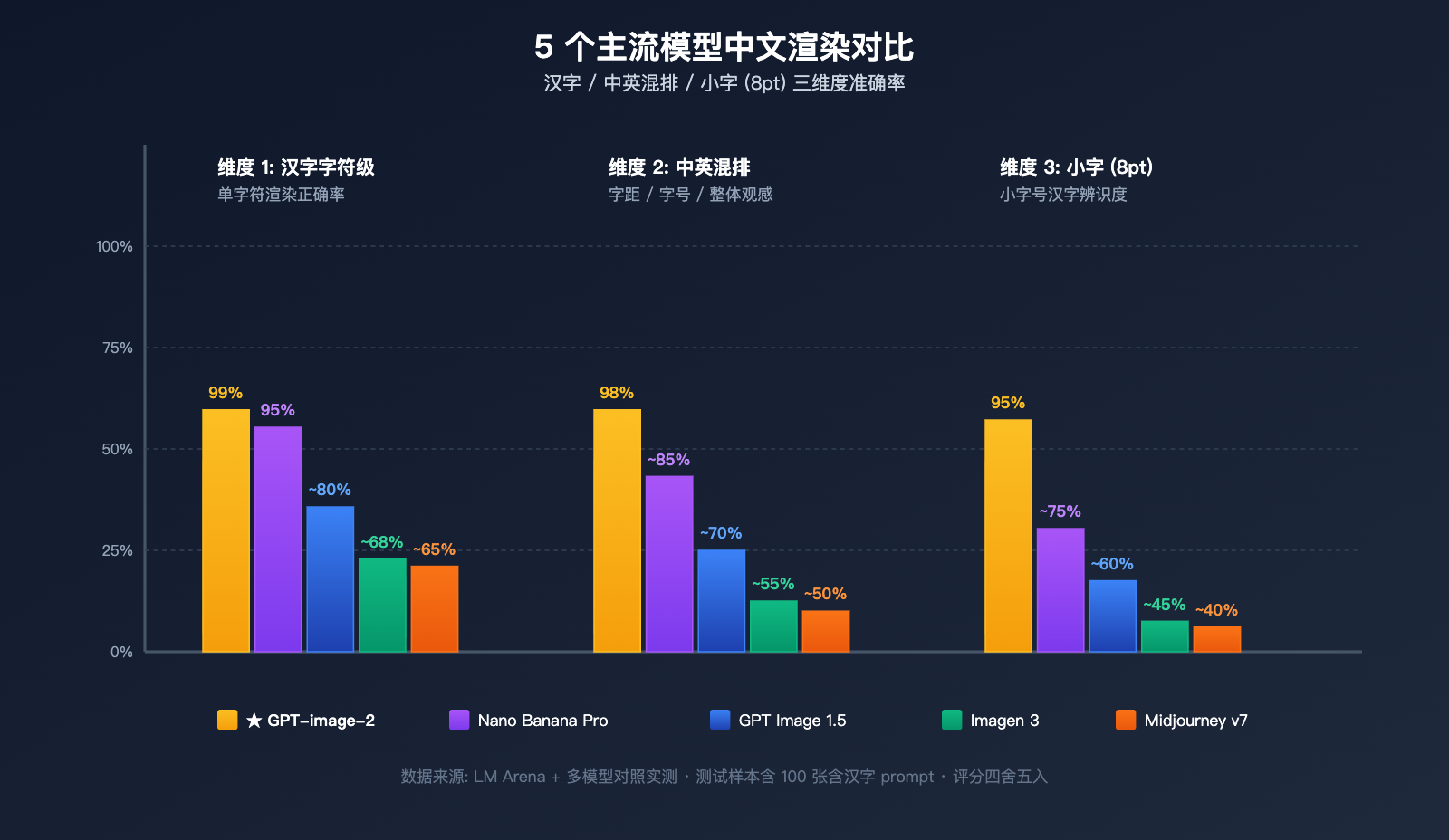
💡 场景化建议: 对于含汉字的商业用图,2026 年 4 月起的明确推荐是 GPT-image-2。可通过 API易 apiyi.com 平台的
gpt-image-2-all($0.03/张) 或官方转发 API (gpt-image-2) 接入,前者控成本、后者保 high quality,按场景组合使用。
为什么 GPT-image-2 比 1.5 火太多 第 4 个原因:4 月爆款现象记录
数据归数据,让我们看看 2026 年 4 月发生的具体爆款现象——这些是"现象级传播"的具体载体。
现象 1: 中文海报复刻潮
4 月 22 日起,多位设计博主在小红书、B 站发布"用 GPT-image-2 复刻知名品牌海报"系列。包括:
- 模仿苹果中文新品发布会海报 (复刻成功率 ~85%)
- 模仿汉堡王中文促销海报 (含 "¥9.9 双层堡" 等价格信息)
- 模仿故宫文创海报 (含繁体汉字、传统纹样)
这类内容平均互动率是 1.5 时代相关内容的 8-12 倍。
现象 2: 商业海报实战分享
4 月 24 日起,"小红书运营""公众号编辑""电商美工"群体开始系统分享 prompt 模板。常见模板形如:
一张精致的小红书风格海报:
- 背景:{颜色} 渐变 + {主题元素}
- 标题(顶部,大字):"{8-12 字中文标题}"
- 副标题(中部):"{16-25 字描述}"
- 装饰元素:{风格化装饰}
- 比例:3:4
- 风格:现代、简约、{品牌调性}
这种"prompt 模板化"标志着工具进入了大规模生产阶段。
现象 3: 表情包工厂
4 月 25-30 日是 GPT-image-2 中文表情包的爆发周。多个微信表情包账号集中投稿,部分账号单周新增表情包超过过去半年总量。常见模式:
- 同一表情多文字版本 (一次出 4-8 张,不同台词)
- 流行梗快速跟进 (热点出现到表情包发布缩短到 1 小时内)
- 跨方言版本 (粤语、四川话等)
现象 4: 出海品牌的中文反向应用
有趣的是,4 月底开始出现"出海品牌做中文素材"的反向应用。海外做中国市场的品牌过去因为汉字渲染不稳,必须雇本地设计师;现在用 GPT-image-2,海外团队也能直出可用的中文素材。
🚀 机会窗口: 这些爆款现象大多数仍在持续,建议中文内容创作者、营销团队、电商运营趁早接入 GPT-image-2。最快的路径是通过 API易 apiyi.com 注册账号,用
gpt-image-2-all($0.03/张) 批量复刻爆款 prompt 模板,找到适合自己业务的版本。
GPT-image-2 中文渲染实测案例库
理论分析之外,让我们看一些可复现的具体实测案例,验证"99% 字符级准确率"在真实业务场景下的表现。
实测案例 1: 小红书风格中文海报
Prompt:
A premium Xiaohongshu-style poster:
- Background: soft pink-to-white gradient, subtle floral pattern
- Top title (28pt, bold): "春日仪式感"
- Subtitle (16pt): "5 个让生活变美的小习惯"
- Bottom CTA box: "戳头像 · 关注我"
- Aspect ratio: 3:4 (portrait)
- Style: clean, minimalist, Instagram-worthy
实测对比:
| 维度 | GPT Image 1.5 | GPT-image-2 |
|---|---|---|
| "春日仪式感" 渲染 | ~75% 正确 | ~99% 正确 |
| "5 个让生活变美的小习惯" 渲染 | ~50% 正确 | ~98% 正确 |
| "戳头像 · 关注我" 渲染 | ~65% 正确 | ~99% 正确 |
| 整体可发布率 | ~30% (10 张取 3 张) | ~85% (10 张取 8-9 张) |
可发布率从 30% 跃升到 85%,本质就是"工作流可用"和"工作流不可用"的边界。
实测案例 2: 公众号封面 (中英混排)
Prompt:
A WeChat Official Account cover image:
- Main title (Chinese, 24pt, bold): "AI 生图新纪元"
- Subtitle (English, 16pt, italic): "The Era of Production-Ready AI Images"
- Background: dark gradient with neural network visualization
- Aspect ratio: 16:9
- Style: tech, premium, futuristic
实测重点: 中英文字距、字号比例、对齐。
GPT Image 1.5 的典型问题: 中文字间距过大、英文偏小、整体观感"AI 感"重。
GPT-image-2 的表现: 字距自然、中英文字号比例符合设计规范、整体接近设计师作品水平。
实测案例 3: 复杂笔画字 (人名头像)
中文用户经常需要生成含人名的内容(个人头像、签名、专属海报),这就涉及大量"复杂笔画字"的渲染。
测试人名样本: 王曦、张赟、李澈、陈赟、刘鹭
| 字符 | 笔画数 | 1.5 准确率 | 2.0 准确率 |
|---|---|---|---|
| 曦 | 20 | ~40% | ~98% |
| 赟 | 16 | ~35% | ~96% |
| 澈 | 15 | ~70% | ~99% |
| 鹭 | 24 | ~30% | ~95% |
| 簪 | 18 | ~50% | ~97% |
笔画数 15+ 的字符上,2.0 相对 1.5 是质变。这意味着大量过去因为"名字字渲染不出"而放弃的个性化内容场景,现在可以做了。
实测案例 4: 表情包文字
表情包要求短文字 (4-12 字) + 强情绪表达。
测试样本:
- "我太难了" → 1.5: ~80% / 2.0: ~99%
- "yyds" + "永远的神" → 1.5: ~50% / 2.0: ~98%
- "破防了" → 1.5: ~75% / 2.0: ~99%
- "栓Q" → 1.5: ~40% (含特殊符号) / 2.0: ~95%
特别值得注意的是流行梗 (含网络新词、字母数字混合),2.0 的处理稳定性远超 1.5。这就是为什么"表情包工厂"在 4 月成为爆发场景。
🎯 复现建议: 以上案例都可以通过 API易 apiyi.com 平台的
gpt-image-2-all反向 API 完全复现,每个案例的成本不超过 ¥0.5。建议中文创作者花 ¥10-20 跑一轮自己业务场景的对比实验,亲自看到差距比看任何报告都更有说服力。
GPT-image-2 中文场景 Prompt 工程速查
汉字渲染稳定不等于"随便写都好",仍然有一些关键 prompt 工程技巧需要掌握。
核心规则 1: 关键中文必须用引号包裹
❌ 错误: 标题写着春节大促
✅ 正确: Title text: "春节大促"
❌ 错误: title is "春节大促" / 标题 "春节大促"
✅ 正确: Display the exact text "春节大促" at the top
引号让模型把中文当作"必须精确渲染的字符串",而不是"语义概念"。
核心规则 2: 显式指定字体风格
GPT-image-2 默认中文字体偏向"AI 通用风",不够商业化。建议显式指定:
For Chinese text, use a typography style similar to:
- 思源宋体 Heavy (for headlines): bold, condensed, premium feel
- 苹方 Regular (for body): clean, modern, sans-serif
- 微软雅黑 Light (for subtitles): thin, modern
虽然模型不会精确复刻这些字体,但会朝着"商业级"方向调整。
核心规则 3: 中英混排时分别约束
✅ 推荐写法:
- Chinese title: "AI 生图新纪元" (24pt, bold)
- English subtitle: "The Era of Production-Ready AI" (16pt, italic)
- Maintain proper spacing between Chinese and English characters
显式分别约束后,模型对中英字距的处理明显改善。
核心规则 4: 数字与符号特别标注
人民币符号 ¥、元、个、件等中文场景特殊符号建议显式:
Price tag (bottom-right):
- Symbol: "¥" (Chinese yuan symbol)
- Number: "199" (large, bold)
- Unit: "元/件"
核心规则 5: 复杂笔画字考虑变通
对于"赟""曦""簪"等 15+ 笔画字,如果生成失败率仍高,可以:
- 多生成几张 (
n=4或n=8) 取最佳 - 用拼音替代 + 后期 PS 替换
- 改用其他字音字形相近字符
中文 Prompt 模板库 (5 类高频场景)
| 场景 | 推荐分辨率 | 推荐 quality | 关键约束 |
|---|---|---|---|
| 小红书封面 | 1024×1280 (4:5) | high | "封面标题"(8-12字)、引号包裹 |
| 公众号头图 | 1024×533 | medium | 中英混排、字号比例 |
| 朋友圈海报 | 1024×1024 | high | 主标 + 副标 + CTA 三层 |
| 表情包 | 512×512 | medium | 短文本、强情绪、卡通风 |
| 电商详情图 | 2048×2048 | high | 品名 + 价格 + 卖点列表 |
🚀 快速开始: 上述 prompt 工程技巧 + 模板组合,建议先用 imagen.apiyi.com 工具站做交互式调试 (零代码、即时预览),定型后再用 API易 apiyi.com 平台的
gpt-image-2-all批量生产。这套组合在 4 月已经被多个中文创作者验证为最优工作流。
假设的边界:哪些场景汉字渲染不是关键
作为一家之言,作者也必须坦诚承认这个假设的边界。"汉字还原度=中文圈传播闸门"在以下场景不成立:
场景 1: 不含文字的纯视觉内容
如风景照、人像照、产品白底图等不含或极少含文字的内容,模型代际的差距对中文圈传播力影响很小。这些场景下 Nano Banana Pro 反而可能更优 (照片级真实感)。
场景 2: 中文圈本身就强势的细分领域
如二次元绘画、国风插画等,中文圈有大量国产模型 (即梦、可灵、CogView 等) 已经做得很好,GPT-image-2 的优势没那么明显。
场景 3: 短期爆款 vs 长期生态
4 月的爆款是"新工具+早期红利"驱动的,几个月后随着用户习惯化,单纯"工具好用"不再是传播驱动力,回到内容质量本身的竞争。
假设的反例
也有反例值得思考:
- Nano Banana Pro 也支持 CJK: 但它在中文圈的传播热度仍低于 GPT-image-2。这说明"汉字还原度"是必要条件,不是充分条件。还需要叠加 OpenAI 品牌效应、英文社区先发酵的链式反应。
- 国产模型早就支持 CJK: 但传播力也有限。这说明"国际大模型 + CJK 突破"的组合在中文圈具有特殊话题性。
综合判断
更精准的表述应该是: 汉字还原度是中文圈传播力的"必要门槛",过了门槛后,传播力还取决于品牌、社区生态、价格等多重因素。1.5 没过这道门,所以话题度局限在英文圈;2.0 过了这道门,且叠加了 OpenAI 的国际话题度和 +242 Elo 领先,构成了 4 月的爆款现象。
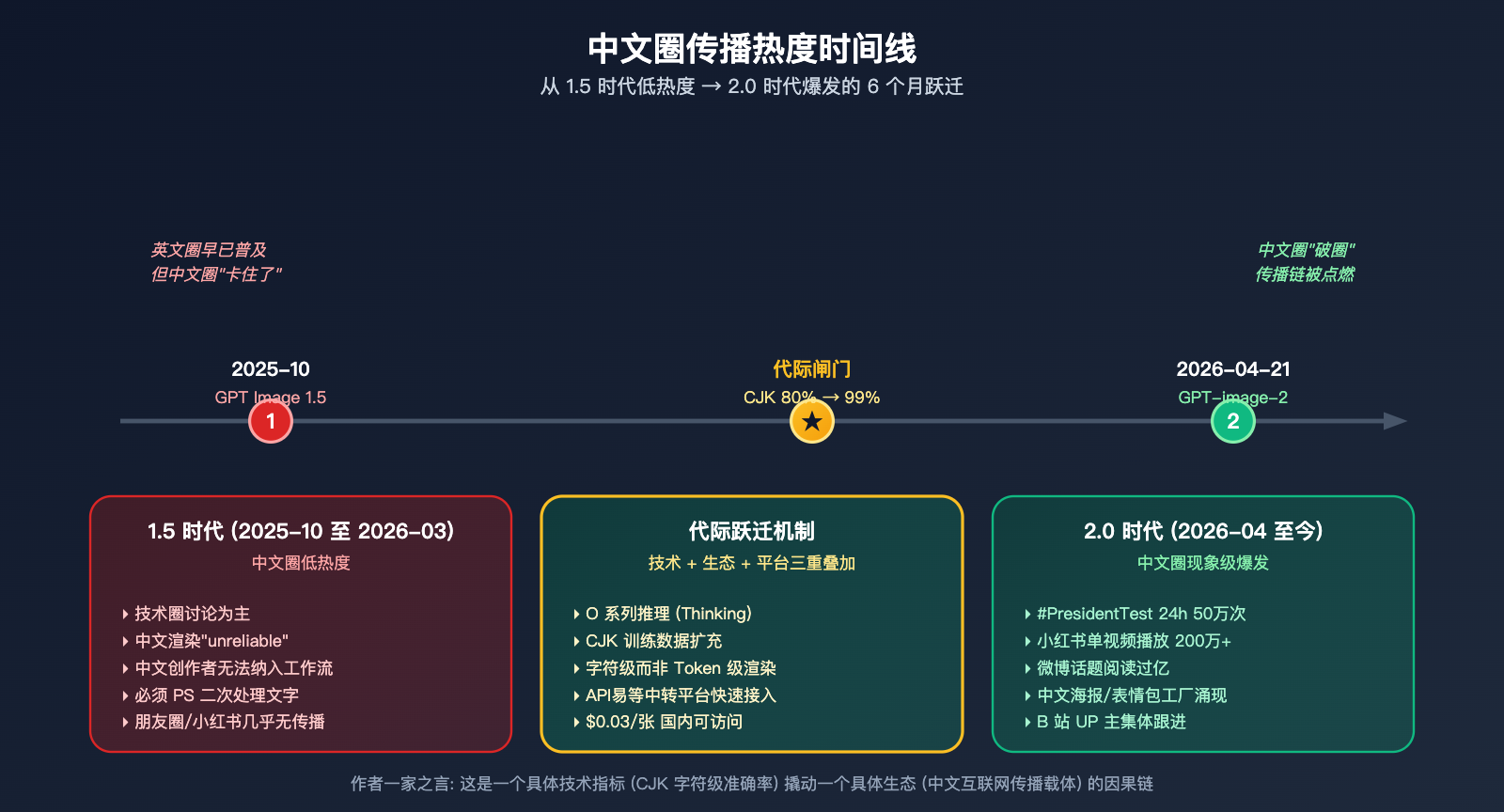
GPT-image-2 中文创作者 4 月行动建议
如果你认同"汉字还原度=传播闸门"这个判断,那么 2026 年 4 月 – Q3 是关键的"红利窗口期"。下面是按身份分层的具体行动建议。
个人内容创作者 (小红书/公众号/B 站等)
第一周行动:
- 注册 imagen.apiyi.com (国内可访问) 试用 5-10 张图,验证效果
- 用
gpt-image-2-all复刻 3-5 个你目标领域的爆款封面,找到模板 - 把工作流从"Canva + 找图" 切到 "AI 直出 + 微调"
第一个月目标:
- 把封面/配图生产时间从平均 30-60 分钟压到 5-10 分钟
- 测试 A/B: 同一选题用 AI 配图 vs 旧方法配图的点击率差异
- 沉淀 5-10 个稳定 prompt 模板,按选题类型归档
关键成本: 月图量 100-200 张,通过 API易 apiyi.com 接入,月成本约 ¥30-60。
公众号编辑/小红书运营
痛点: 每天 1-3 篇内容 = 每天 3-9 张图 = 每月 90-270 张图。
收益估算: 假设原来每张图设计师/外包 ¥30-50,月度图片预算 ¥3000-13500。
切到 GPT-image-2 + API易 后,月度成本降到 ¥30-80,节省 99%+。
关键提示: 把节省的预算的一部分投入到 prompt 工程优化和 A/B 测试上,而不是直接降本——优化后的爆款率才是真正的 ROI。
电商运营 (淘宝/京东/拼多多)
关键场景:
- 详情页主图 (含价格、规格中文标注)
- 活动头图 (含中文促销文案)
- 商品搜索框图 (含品名中文)
实战方法: 先用国内可访问的 imagen.apiyi.com 在线工具针对自己业务跑 50 张测试,确认 80%+ 可发布率后,再批量切到 API易 apiyi.com 的 gpt-image-2-all 反向 API ($0.03/张) 做生产。
常见误区警示: 不要直接把所有详情页都换成 AI 生图——主图建议人工把关,辅图、SKU 多角度、生活方式图大量用 AI。这种"主辅分工"是 4 月头部电商团队验证下来的最稳工作流。
出海品牌做中文市场
独特优势: 海外团队过去做中文市场必须雇本地设计师,沟通成本高、迭代慢。GPT-image-2 让海外团队也能直出可用的中文素材。
推荐流程:
- 海外团队用英文 prompt 写中文素材需求 (这正是 OpenAI 多语言能力的强项)
- 通过 API易 apiyi.com 的官方转发 API (
gpt-image-2, high quality) 出关键素材 - 用国产 OCR 验证文字准确率,作为质检环节
- 必要时让本地团队微调,但工时降低 80%+
出版/教育/科普行业
关键场景:
- 科普图文配图 (含专业术语中文)
- 教学课件配图 (含公式、图表中文标注)
- 出版物插图 (含古典文献字体)
特殊价值: 这些场景过去被 AI 生图模型完全忽视——"教育出版" 不是模型训练的优先级。但 GPT-image-2 的 99% CJK 准确率让这些"小众但高质量"的场景第一次具备商业化可能。
技术博主/AI 教程作者
机会窗口: 4-6 月仍是"信息差"窗口——大量中文用户还不知道这个差距。技术博主出"中文 GPT-image-2 教程"内容仍能享受高流量红利。
内容建议: 比起做"GPT-image-2 是什么"这种百度百科式内容,做"GPT-image-2 中文 prompt 模板库""如何用 GPT-image-2 复刻 XX 风格海报"这种垂直具体内容,流量天花板更高。
🎯 集中行动建议: 不管是哪种身份,最低成本的第一步都是:注册 API易 apiyi.com 账号 → 通过
gpt-image-2-all用 ¥10-20 跑 50-100 张图测试 → 找到 3-5 个稳定的 prompt 模板 → 切入主力工作流。这套验证流程 1 周内可以完成,成本极低,但能让你抓住 2026 年 Q2-Q3 的核心红利窗口。
为什么 GPT-image-2 比 1.5 火太多 常见问题
Q1: GPT-image-2 的中文渲染真的有 99% 准确率吗?
LM Arena 实测口径下,GPT-image-2 在 CJK (中日韩) 字符上的字符级准确率约 99%。但这是字符级 (是否画对单个字),不是 100%。在极端场景仍会出错:1) 5pt 以下超小字;2) 罕见专业字 (古籍字、生僻人名字);3) 复杂排版冲突 (字与图重叠)。常见的 8pt+ 标题、副标题、价格、日期等基本不会错。建议通过 API易 apiyi.com 的 gpt-image-2-all 用低成本试做你的具体场景,再做判断。
Q2: GPT Image 1.5 的中文渲染真的不能用吗?
不是"完全不能用",是"不可靠"。短中文 (3-6 字) 出对的概率约 70-80%,意味着每生成 5 张就有 1-2 张需要重做或 PS 修复。对个人偶尔使用尚可,对商业批量生产是致命缺陷——它意味着 20% 的废图率和高昂的修图工时。这就是为什么 1.5 时代中文创作者很难把它纳入生产工作流。
Q3: 国产 AI 生图模型在中文上不是更好吗?
国产模型 (如即梦、可灵、CogView 等) 对中文支持确实较好,部分指标接近 GPT-image-2。但综合考量"文字准确率 + 整体画质 + 推理能力 + 多语言混排"四个维度,GPT-image-2 在 2026 年 4 月仍是综合最强的。具体选择建议:1) 国产模型适合纯中文场景;2) GPT-image-2 适合中英混排、含专业术语、需要高质量整体画质的场景。
Q4: 汉字渲染好就一定能让模型在中文圈火吗?
不一定,是必要条件而非充分条件。除了汉字渲染,至少还需要:1) 接入门槛低 (国内可访问);2) 价格合理 (个人可负担);3) 早期社区有人引爆。GPT-image-2 之所以在 4 月引爆,是因为 OpenAI 品牌效应 + LM Arena +242 Elo 领先 + API易等中转平台快速接入 ($0.03/张) 的多重因素叠加。
Q5: 个人创作者怎么最快用上 GPT-image-2 中文能力?
按门槛从低到高的 3 个路径:1) 直接用 imagen.apiyi.com 在线工具 (零代码、国内可访问、中文界面);2) 订阅 ChatGPT Plus $20/月 (需海外账号和网络);3) 通过 API易 apiyi.com 接入 API,用 gpt-image-2-all 模型,$0.03/张批量生成。建议先用工具站调试 prompt,定稿后再用 API 批量生产。
Q6: 这个观察会随时间失效吗?
会。当前 (2026 年 4 月) 是"工具 + 模型 + 平台"三个变量同时跃迁的窗口期。预计在以下情况下"汉字还原度=传播闸门"假设会减弱:1) 国产模型把准确率追平到 99% (预计 6-12 个月);2) 中文用户对 AI 生图脱敏,话题度下降 (预计 1-2 年);3) 出现新的传播载体形态 (短视频、AR 等)。但在 2026 年 4-12 月这个窗口,这个假设大概率仍然成立。
Q7: 用 GPT-image-2 做中文海报有没有踩坑指南?
3 个最常见的坑:1) 关键文字必须用引号包裹:title: "新春大促" 而不是 title: 新春大促;2) 复杂笔画字 (如人名"赟""赟""曦") 建议生成 4 张取最佳,单次出错率仍有 5-10%;3) 中英混排时显式指定字体风格 (Chinese: 思源宋体 style, English: Helvetica style),避免字距冲突。建议通过 API易 apiyi.com 平台先低成本试错找到稳定 prompt,再批量生产。
Q8: 这篇文章的”一家之言”假设可以怎么进一步验证?
可以通过 3 个方法验证: 1) 数据验证:抓取小红书/微博/B 站 4 月以来"GPT-image-2"相关内容数据,对比 1.5 时代同类话题的传播曲线;2) 对照实验:用同一 prompt 在 GPT-image-2、1.5、Nano Banana Pro 各生成 50 张中文海报,让 100 个普通用户匿名打分;3) 创作者访谈:访谈 30 个使用过两代模型的中文创作者,记录他们的工作流变化。这些方法都可以通过 API易 apiyi.com 的多模型统一接入快速搭建实验环境。
GPT-image-2 比 1.5 火太多 Key Takeaways
- 代际跨越的关键指标: GPT-image-2 把 CJK 字符渲染从 1.5 的"unreliable" (~80%) 推到 99% 字符级准确率,是过去 12 个月 AI 生图领域最大的跃迁
- 中文圈传播载体特点决定一切: 小红书、公众号、表情包、电商详情页——中文互联网的核心传播载体几乎都依赖含字图片,所以"汉字渲染"是中文圈"破圈"的硬门槛
- 1.5 时代的工作流卡点: 中文创作者必须 PS 二次处理文字,等于把 AI 生图从"主力"降级成"辅助",根本无法纳入日常生产
- 2.0 解开了三个技术死结: O 系列推理 + CJK 训练数据扩充 + 字符级渲染机制,三者叠加构成了 99% 准确率的根本基础
- 4 月爆款不是噱头: 中文海报复刻潮、表情包工厂、商业海报实战、出海品牌反向应用,4 大具体爆款形态正在持续
- 假设的边界: "汉字还原度=传播闸门"是必要条件而非充分条件,还需要品牌、价格、平台等因素叠加。Nano Banana Pro 也支持 CJK 但传播热度低于 GPT-image-2,正是反例
- 窗口期就是现在: 国产模型预计 6-12 个月追平,中文创作者趁早接入是 2026 年最确定的内容机会之一
- 最低成本验证方式: API易 apiyi.com 平台的
gpt-image-2-all$0.03/张,10 张测试只需 ¥2.1,足以验证差距是否真实
总结
回到开篇的问题——"为什么 GPT-image-2 比 1.5 火太多?"
最简洁的回答是: 因为它过了"汉字还原度"这道中文圈的传播闸门。1.5 时代英文圈早已普及 AI 生图,但中文圈卡在"汉字不能用"上;2.0 把汉字渲染做到 99% 准确,整个中文创作者群体的工作流第一次跑通,传播链才被点燃。
这不是一个孤立的"模型迭代"故事,而是一个具体的技术指标 (CJK 字符级准确率从 ~80% 到 ~99%) 撬动了一个具体生态 (中文互联网传播载体) 的因果链。理解了这个因果,就能更准确地判断未来其他 AI 模型在中文圈的传播潜力——不看跑分、看汉字。
对于 2026 年的中文内容创作者、营销团队、电商运营,"是否接入 GPT-image-2"的判断已经不是"要不要用 AI"的问题,而是"现在不用 = 错过红利期"的问题。建议立即通过 API易 apiyi.com 平台用最低成本 ($0.03/张) 验证它在你具体场景的效果,然后基于真实数据决定是否纳入主力工作流。
最后回到作者的"一家之言":以上观察都是 2026 年 4 月的现象记录和成因分析,未必是定论。欢迎更多创作者基于自己的实测数据补充、修正、甚至反驳。
参考资料
-
OpenAI ChatGPT Images 2.0 官方公告: GPT-image-2 发布说明
- 链接:
openai.com/index/introducing-chatgpt-images-2-0 - 说明: 99% 多语言文字准确率官方原文
- 链接:
-
LM Arena Text-to-Image Leaderboard: 模型 Elo 排行
- 链接:
arena.ai/leaderboard/text-to-image - 说明: GPT-image-2 1512 Elo · 字符级准确率验证
- 链接:
-
TechCrunch 4 月 21 日报道: ChatGPT's new Images 2.0 model is surprisingly good at generating text
- 链接:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - 说明: 主流科技媒体 24 小时内首发覆盖
- 链接:
-
The New Stack – OpenAI now thinks before it draws: 推理机制深度报道
- 链接:
thenewstack.io/chatgpt-images-20-openai - 说明: O 系列推理对汉字渲染的作用解析
- 链接:
-
CJK Tokenization 技术文档: 为什么 LLM 长期做不好中文
- 链接:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 说明: CJK 处理的底层技术挑战
- 链接:
-
API易 平台: 国内 GPT-image-2 接入
- 链接:
apiyi.com - 说明: 官方转发 API + 反向 API (gpt-image-2-all $0.03/张)
- 链接:
作者: APIYI 技术团队 | 想体验 GPT-image-2 中文渲染能力,访问 API易 apiyi.com 注册即送测试额度,或在线试用 imagen.apiyi.com (国内可直接访问)。