2026-04-24,DeepSeek 同时开源 V4-Pro 和 V4-Flash。如果说 Flash 是"便宜就够用"的性价比甜点,那 V4-Pro 是一件完全不同的产品:
它是当前代码能力最强的开源模型。
不是"在开源里最强"的委婉表达,而是硬数据直接碾过 GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro 的冠军:
- LiveCodeBench 93.5 — 全场第一,超过 Gemini 3.1-Pro(91.7)和 Claude Opus 4.6(88.8)
- Codeforces Rating 3206 — 超过 GPT-5.4(3168)和 Gemini 3.1-Pro(3052)
- Apex Shortlist Pass@1 90.2 — 大幅领先 GPT-5.4(78.1)、Claude(85.9)
- IMOAnswerBench 89.8 — 数学竞赛题上把 Claude Opus 4.6(75.3)拉开整整 14 分
对应的配置是:1.6T 总参数 / 49B 激活 / 32T tokens 预训练 / 1M 上下文 / 384K 输出,再加上 DeepSeek 为 V4 系列专门设计的四大架构创新:Hybrid Attention、Manifold-Constrained Hyper-Connections (mHC)、Engram Conditional Memory、Muon Optimizer。
deepseek-v4-pro 已在 API易 apiyi.com 上架,你可以用 OpenAI 或 Anthropic 协议 SDK 零改造接入,价格只有 GPT-5.4 的 1/7。
本文不再重复"怎么迁移/怎么选便宜模型"这些 Flash 篇已经讲过的基础——这是一份专为 deepseek-v4-pro 的技术信徒准备的旗舰解读:
- 3 分钟搞懂 Pro 为什么有资格称作"旗舰"(架构 + 数据 + 规模)
- 4 张 Benchmark 对决表,看清 Pro 在哪些战场赢、哪些战场输
- 5 分钟接入 + 2 个真实代码/数学场景实战
一、deepseek-v4-pro 的四大旗舰能力
1.1 核心规格一览表
| 维度 | deepseek-v4-pro |
|---|---|
| 发布日期 | 2026-04-24(预览版) |
| 开源仓库 | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| 总参数 | 1.6T(Mixture of Experts) |
| 激活参数 | 49B |
| 预训练数据 | > 32T tokens |
| 上下文窗口 | 1M tokens |
| 最大输出 | 384K tokens |
| 架构创新 | Hybrid Attention + mHC + Engram Memory + Muon |
| 推理模式 | Thinking / Non-Thinking 双模式 |
| Function Calling | ✅ 支持 |
| JSON 模式 | ✅ 支持 |
| API 协议 | OpenAI + Anthropic 双兼容 |
| 输入价格 | $1.74 / M tokens |
| 输出价格 | $3.48 / M tokens |
把最核心的 4 个数字记住:1.6T / 49B / 32T / 1M——这是旗舰的底气。
1.2 1.6T / 49B MoE:规模上的"开源天花板"
DeepSeek-V4-Pro 总参数 1.6 万亿,采用 Mixture of Experts 架构,每 token 只激活 49B 参数。这组数字的含义:
| 模型 | 总参数 | 激活参数 | 类型 |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense(全激活) |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | 未公开 | 未公开 | 闭源 |
1.6T 总参数让模型拥有接近 GPT-5.4 / Claude Opus 级别的知识面,而 49B 激活参数让单 token 推理成本可控——这是 MoE 架构能跑通前沿性能的本质原因。
1.3 32T tokens 预训练:数据总量直接拉满
预训练数据 > 32T tokens
这是一个足以震撼的数字:
- GPT-4 预训练数据量约 13T tokens(业界推测)
- Llama 3 15T tokens
- DeepSeek-V3 14.8T tokens
- DeepSeek-V4-Pro:>32T tokens ⭐
数据量翻倍带来的直接收益是:长尾知识覆盖更全、代码语料更新更及时、数学题库更深——这也是 V4-Pro 在 LiveCodeBench 和 IMOAnswerBench 上屠榜的根源。
1.4 四大架构创新:Pro 的真正护城河
这是 V4-Pro 和"又一个 MoE 模型"拉开差距的关键。官方披露的四项核心创新:
| 创新 | 全名 | 解决什么问题 |
|---|---|---|
| Hybrid Attention | CSA + HCA 混合注意力 | 长上下文(1M)推理的 FLOPs 与显存问题 |
| mHC | Manifold-Constrained Hyper-Connections | 深层残差连接稳定性,防梯度消失/爆炸 |
| Engram | Engram Conditional Memory | 解耦"静态事实"和"推理能力",事实更新更便宜 |
| Muon | Muon Optimizer | 训练收敛速度和稳定性,降训练成本 |
每一项都值得展开讲一下:
-
Hybrid Attention(CSA + HCA):传统 Transformer 的 attention 复杂度是 O(n²),1M 上下文直接爆炸。V4 用压缩稀疏注意力(CSA) 做粗粒度筛选,高度压缩注意力(HCA) 做细粒度聚焦,组合起来把 FLOPs 砍到 V3.2 的 27%,KV 缓存只要 10%。这是 deepseek-v4-pro 能把 1M 上下文"开出来还能跑"的关键。
-
mHC(Manifold-Constrained Hyper-Connections):深度 MoE 模型训练时,残差连接的信号在几十层之后会出现失真。mHC 在 manifold 空间加约束,让信号传播更稳定。实用表达:模型可以训得更深、更久,而不崩溃。
-
Engram Conditional Memory:一个非常工程化的创新。它把"模型记忆中的事实"和"推理能力"解耦开——事实存放在专门的记忆模块里,推理链走另一条路径。结果是当世界知识要更新时,不需要重训全模型,这会极大降低 Pro 未来版本的发布成本。
-
Muon Optimizer:DeepSeek 自研的优化器,相比 AdamW 收敛更快、稳定性更好。在万亿参数训练规模下,这意味着同样算力下训得更充分。
🎯 技术启示:deepseek-v4-pro 不是把旧架构放大,而是把基础设施重写了一遍。这是它能在开源状态下达到闭源巨头水平的根本原因。接入后如果你打算深度使用,建议通过 API易 apiyi.com 先跑一组业务典型 prompt 感受一下架构升级带来的差异——尤其是长上下文和多步推理场景。
1.5 1M 上下文 + 384K 输出:长文生成的分水岭
Pro 和 Flash 的上下文规格一致:1M tokens 输入、384K tokens 输出。但 Pro 的优势不在"能读多长",而在"在 1M 下能想多深"。
对长文场景的实际意义:
| 任务 | V3.2 时代 | V4-Pro 时代 |
|---|---|---|
| 50 万字书稿全文修改 | 要分 10+ 块拼接 | 一次性 1M 窗口处理 |
| 200 页技术文档问答 | 要构建 RAG | 直接喂进去 |
| 中型代码仓库审计 | 摘要式分析 | 跨文件一致性检查 |
| 小说写作连贯性 | 要自己管理记忆 | 384K 输出一气呵成 |
二、deepseek-v4-pro 的 Benchmark 王座
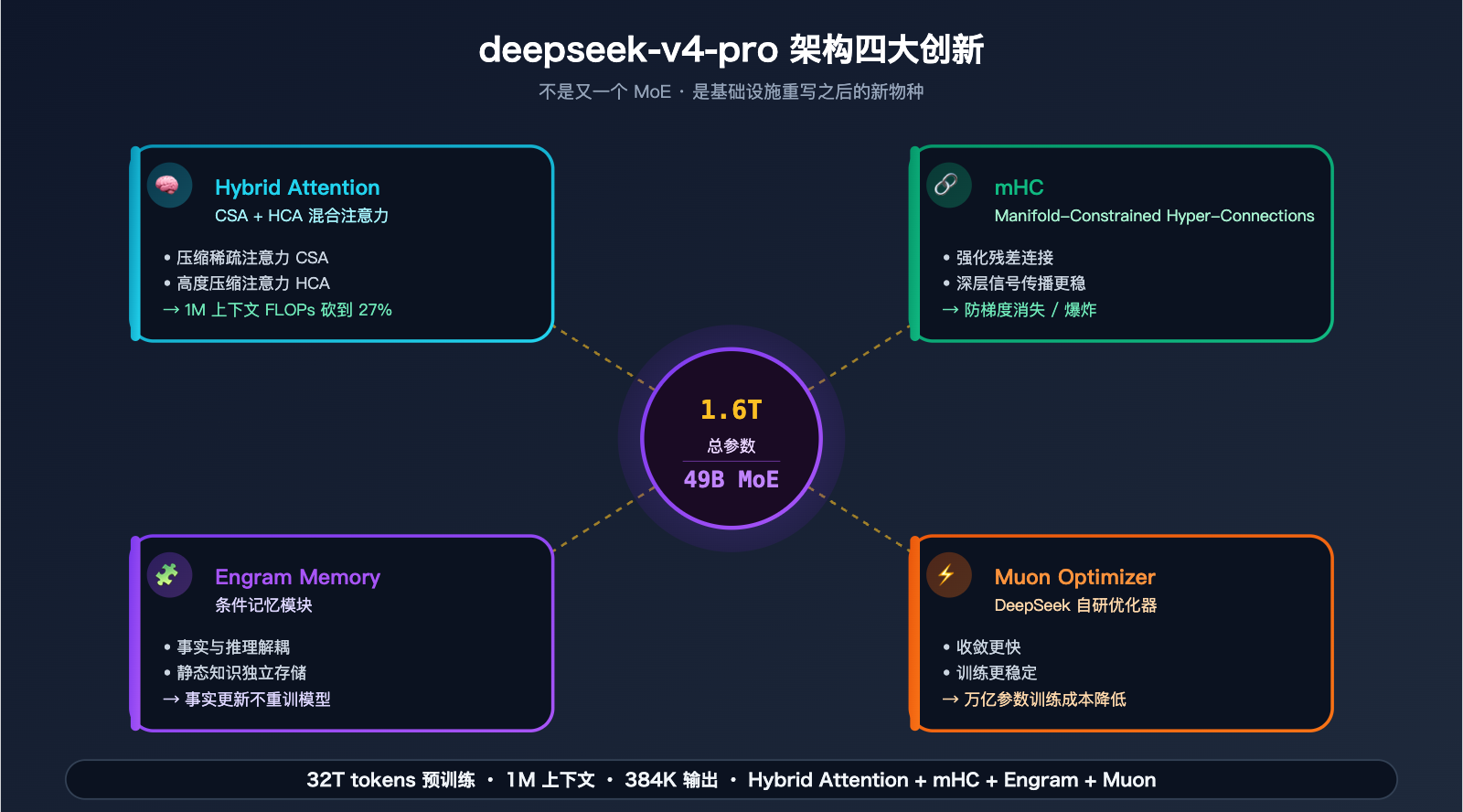
2.1 代码能力:deepseek-v4-pro 三项屠榜
先看最硬的数据——代码编程能力:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | 第一名 |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | 并列 |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
三项领跑,两项"并列第一或略输"。开源模型在代码能力上第一次全面压制闭源旗舰——这是 2026 年非常标志性的事件。
具体解读:
- LiveCodeBench 93.5:LiveCodeBench 每月更新题目,避免训练集污染。V4-Pro 的 93.5 说明它的代码能力是泛化的、能写新题的,不是记题库
- Codeforces 3206:竞赛编程评分,3206 分接近 IGM(国际特级大师)水平。这个分数做日常业务代码完全是降维打击
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1:这个差距是系统性的。Apex Shortlist 是高难度面试题集,V4-Pro 领先了整整 12 个百分点
- Terminal-Bench 2.0 稍弱:这是多步命令行工具使用能力。GPT-5.4 在这里仍然领先,说明"多步复杂 Agent"场景 GPT-5.4 有护城河
2.2 数学与推理:deepseek-v4-pro 接近前沿
数学维度 Pro 和闭源巨头"你追我赶",并非全面领先:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
亮点在 IMOAnswerBench:国际数学奥林匹克题集,V4-Pro 89.8 分领先 Claude Opus 4.6 整整 14.5 分,领先 Gemini 3.1-Pro 8.8 分。对数学推理、形式证明这类高阶任务,Pro 是目前开源模型的天花板。
弱项在 MMLU-Pro 通用知识:Pro 的 87.5 与 GPT-5.4 持平,但比 Gemini 3.1-Pro 的 91.0 差 3.5 分。通用知识问答场景 Gemini 仍有一定优势。
2.3 战场分布图:deepseek-v4-pro 赢在哪里、输在哪里
| 战场 | 冠军 | V4-Pro 位置 |
|---|---|---|
| 代码生成(LiveCodeBench) | V4-Pro 🏆 | 冠军 |
| 竞赛编程(Codeforces) | V4-Pro 🏆 | 冠军 |
| 高难面试(Apex) | V4-Pro 🏆 | 冠军(大幅领先) |
| 软件工程(SWE-bench) | 并列 | 并列第一 |
| 数学竞赛(IMO) | GPT-5.4 | 第二(远超 Claude/Gemini) |
| 通用知识(MMLU-Pro) | Gemini 3.1-Pro | 第三 |
| 多步工具链(Terminal-Bench) | GPT-5.4 | 第二 |
| 一致性推理(HMMT) | GPT-5.4 | 第三 |
结论:如果你的工作负载以代码为主,deepseek-v4-pro 是目前地球上最强的选择之一(含开源和闭源)。如果以多步 Agent 工具链为主,GPT-5.4 仍有微弱优势;如果以通用知识问答为主,Gemini 3.1-Pro 更强。
🎯 选型建议:我们建议先用自己业务的典型 prompt 在 API易 apiyi.com 上跑一组 V4-Pro vs 现有模型 的 AB 对比(20–50 条够了)。不要相信公共 Benchmark 直接决定选型——你自己的 prompt 分布才是真实的 Benchmark。批量 AB 跑图建议走
vip.apiyi.com高并发线路。
三、5 分钟在 API易 apiyi.com 调用 deepseek-v4-pro
3.1 Step 1:拿 Key 和选线路
前置环境:Python 3.8+ 或 Node.js 18+,官方 OpenAI SDK 或 Anthropic SDK 任选其一。
拿 Key:
- 访问 API易
apiyi.com,控制台 → API Keys → 新建密钥 - 建议给 Pro 用的 Key 单独设置日额度(¥200–500,视业务规模)
- 复制
sk-开头的密钥
选线路(三线路共用一把 Key):
| base_url | 适用 |
|---|---|
https://api.apiyi.com/v1 |
日常调用、交互场景 |
https://vip.apiyi.com/v1 |
批量任务、高并发 |
https://b.apiyi.com/v1 |
主站抖动时备用 |
3.2 Step 2:Python 最小调用(Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Write a production-ready LRU cache in 30 lines."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
改两处:base_url 和 model — 其余 OpenAI SDK 代码不动。
3.3 Step 3:启用 Thinking 推理模式(Pro 的价值高光)
deepseek-v4-pro 的真正价值在 Thinking 模式下才完全释放。对应 IMOAnswerBench 89.8、LiveCodeBench 93.5 这些 Benchmark 都是在 Thinking 模式下测出来的。
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
请实现一个并发安全的 token bucket 限流器,要求:
1. 支持动态调整速率
2. 支持突发流量预留
3. 无锁实现(CAS 或原子操作)
4. 包含完整的单元测试
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- 推理过程 ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- 最终答案 ---")
print(resp.choices[0].message.content)
effort=high 时 Pro 会做非常深入的规划——你会看到它先分析需求、再设计 API、再讨论不同实现方案、最后才给出代码。这是 deepseek-v4-pro 相对 Flash 最值得付差价的地方。
3.4 Step 4:代码修复场景实战
真实业务场景:让 Pro 修一个 bug。
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG here
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior code reviewer. Identify bugs, explain root cause, and give fixed code."},
{"role": "user", "content": f"Review this code:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro 会指出:索引应该是 -k(排序后第 k 大在倒数第 k 个位置),并给出修复 + 边界条件处理(k <= 0、k > len(nums))+ 测试用例。
SWE-bench 80%+ 的数据在这种场景里就是真实体感。
3.5 Step 5:Function Calling / Tool Use
Pro 在单次工具调用上非常稳定,多步工具链虽弱于 GPT-5.4 但领先 Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Execute a read-only SQL query on the analytics DB.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT-only SQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "过去 30 天 DAU 前 5 的城市?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Step 6:Anthropic 协议(Claude Code 接入 Pro)
这条路径是 deepseek-v4-pro 最容易被低估的价值:你现有的所有 Claude SDK / Claude Code 项目,可以把底层模型换成 V4-Pro 且不改任何业务代码。
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # 注意无 /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "重构这段 Python 代码为 async/await 风格..."},
],
)
print(resp.content[0].text)
Claude Code 终端:在配置里把 ANTHROPIC_BASE_URL=https://api.apiyi.com + ANTHROPIC_API_KEY=sk-... + 模型换成 deepseek-v4-pro,立刻获得一个代码能力领先的终端 Agent。
3.7 Step 7:Cursor 里接入 deepseek-v4-pro
Cursor 的 Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
完成后 Cursor 的 Chat / Cmd+K / Composer 三个入口都会走 V4-Pro,代码补全和重构的质量会有明显提升。
🎯 IDE 接入建议:Cursor、Windsurf、Cline、Continue 等主流 AI 编程工具都兼容 OpenAI 协议,把
base_url指向 API易api.apiyi.com/v1、模型换成deepseek-v4-pro就能无缝迁移。详细 IDE 配置样例可以在 API易官方文档docs.apiyi.com的 DeepSeek V4 专栏查阅。
四、deepseek-v4-pro 什么时候选、什么时候不选
4.1 选 Pro 的决策条件
✅ 下列场景直接选 deepseek-v4-pro:
| 场景 | 为什么 |
|---|---|
| 代码生成、重构、审查 | LiveCodeBench 93.5 全场冠军 |
| 竞赛编程、算法题训练 | Codeforces 3206 等效 IGM 水平 |
| 面试题批量解答 | Apex Shortlist 90.2 大幅领先 |
| 数学推理、形式证明 | IMOAnswerBench 89.8 领先 Claude 14 分 |
| 大仓库整仓理解 | 1M 上下文 + 49B 激活 |
| 长文写作与编辑 | 384K 输出一次到位 |
| 本地部署 / 二次训练 | 开源权重 + Engram 模块便于微调 |
| 替代 Cursor / Claude Code 的底层模型 | Anthropic 协议零改造接入 |
4.2 不选 Pro 的情况
❌ 以下场景别浪费 Pro 的算力:
| 场景 | 建议 |
|---|---|
| 日常对话、FAQ | 用 Flash(省 12 倍) |
| 短文本分类、抽取 | 用 Flash 或更小模型 |
| 多步复杂 Agent 工具链 | 优先考虑 GPT-5.4(Terminal-Bench 领先) |
| 以通用知识问答为主 | Gemini 3.1-Pro 更强 |
| 对延迟敏感的在线交互 | 用 Flash(Non-Thinking 模式)或加缓存 |
4.3 混合路由建议
生产环境的最优解通常是分层路由:
def pick_model(request_type: str, complexity: str) -> str:
# 代码类重活 → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# 数学推理 → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# 长文档深度理解 → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# 其他日常 → Flash
return "deepseek-v4-flash"
在 API易 apiyi.com 上这两个模型共用一把 Key,切换只动 model 字段,不动别的配置。
五、deepseek-v4-pro 常见问题 FAQ
Q1:为什么 Pro 的代码能力这么强?
三个原因叠加:
- 32T tokens 预训练 里包含了大量高质量代码语料
- 1.6T MoE / 49B 激活 让代码知识能存下、能调出
- Thinking 模式 + Engram Memory 把"记代码范式"和"推理新代码"解耦
这三件事任何一件单独做不到这个分数,合起来才有了 LiveCodeBench 93.5。
Q2:1.6T 参数会不会响应很慢?
单次响应速度由激活参数决定,不是总参数。Pro 每 token 只激活 49B,加上 Hybrid Attention 的 FLOPs 优化,首 token 延迟和 Flash 接近。Thinking 模式会慢一些(因为要输出推理过程),但这是设计上的取舍——你是为推理质量付时间。
Q3:Thinking 模式必须开吗?
不必须。普通对话、简单代码、日常问答都可以关掉。但你付 Pro 的钱大部分价值在 Thinking 模式——复杂代码、数学题、多步逻辑推理务必打开 reasoning.enabled=true + effort=high。
Q4:在 Cursor / Claude Code 里怎么用?
- Cursor:Settings → Models → Custom OpenAI-Compatible,Base URL 填
https://api.apiyi.com/v1,Model 填deepseek-v4-pro - Claude Code:环境变量
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-...,启动时 model 指定deepseek-v4-pro
具体截图步骤可以在 docs.apiyi.com 的 IDE 接入专栏找到。
Q5:和 GPT-5.4 相比到底谁更值?
二选一的话:
- 日常代码 / 竞赛 / 数学 / 成本敏感 → deepseek-v4-pro(代码冠军、价格 1/7)
- 多步工具链 Agent / 通用知识问答 → GPT-5.4
- 混用 是最优解(通过 API易 apiyi.com 同一把 Key 切两个模型)
Q6:可以本地部署吗?
可以,V4-Pro 开源了完整权重到 Hugging Face(deepseek-ai/DeepSeek-V4-Pro)。但自部署要求:
- 单机 ≥ 8×H200 或等效 GPU
- 1M 上下文需要额外 KV 缓存(虽然 Pro 已把缓存压到 V3.2 的 10%)
- 维护推理服务的工程成本
成本测算:除非你月调用量超过 500 亿 tokens,走 API易 apiyi.com 的托管调用比自部署更经济。
Q7:多并发上限多少?
生产环境建议:
- 主站
api.apiyi.com:50 并发安全 - 高并发线路
vip.apiyi.com:200+ 并发 - 备用
b.apiyi.com:主线路抖动时自动 fallback
Pro 对复杂 Thinking 任务延迟较高,并发数不是越大越好——按 QPS × 平均响应时间 估算所需并发窗口更合适。
Q8:Pro 会不会很快出正式版?
2026-04-24 发布的是预览版(Preview)。按 DeepSeek 过去的节奏,正式版通常在预览版之后 1–2 个月发布,可能会有小幅 Benchmark 提升。现在用预览版在 API易 apiyi.com 上跑也没问题——model id 正式版大概率保持 deepseek-v4-pro 不变,向后兼容。
六、deepseek-v4-pro 上架总结
如果你跳过中间只看结论,这就是:
- ✅ deepseek-v4-pro 是当前代码能力最强的开源模型——LiveCodeBench / Codeforces / Apex 三项硬核 Benchmark 击败 GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro
- ✅ 架构四大创新(Hybrid Attention / mHC / Engram Memory / Muon)让它不是"又一个大模型",而是基础设施重写之后的新物种
- ✅ 1.6T / 49B MoE + 32T tokens 预训练 + 1M 上下文 规模上达到开源天花板
- ✅ 已在 API易 apiyi.com 上架,兼容 OpenAI + Anthropic 双协议,Cursor / Claude Code / Cline 等所有主流工具零改造接入
- ✅ 价格仅 GPT-5.4 的 1/7,Thinking 模式下才是它真正的高光
对代码为主的开发团队来说,deepseek-v4-pro 值得立刻测试——它不是"再便宜一点的替代品",而是可能会成为新默认的旗舰模型。
🎯 行动建议:建议今天就从 API易
apiyi.com申请一把 Key(给 Pro 专用、日额度设 ¥200–500),先跑 20 条最能代表你业务的代码 / 数学 / 长文 prompt,把 V4-Pro(Thinking 模式)和你现在的主力模型做 AB 对比。如果代码任务质量提升明显,就把 Cursor / Claude Code 的默认模型切过来;需要日常便宜模型分流,就再装一个 V4-Flash(见上一篇迁移指南)。批量跑测试时走vip.apiyi.com,主站抖动时b.apiyi.com自动 fallback。完整接入样例、IDE 配置、Benchmark 复现脚本都能在docs.apiyi.com找到。
deepseek-v4-pro 的意义超越了"又一个便宜的 SOTA 模型"。它标志着开源模型第一次在核心代码能力上全面压制闭源旗舰——这件事本身就值得每个严肃对待 AI 工程的团队认真测一次。
作者: API易技术团队
相关资源:
- DeepSeek 官方公告: api-docs.deepseek.com/news/news260424
- Hugging Face 开源仓库: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- API易官网: apiyi.com
- API易文档: docs.apiyi.com
- API易主站: api.apiyi.com(备用 vip.apiyi.com / b.apiyi.com)