作者注:全面解读 Claude Opus 4.7 全新 xhigh effort 等级,对比 low/medium/high/xhigh/max 五档差异,给出编程与 Agentic 场景下的最佳实践与代码示例。
很多开发者在升级到 Claude Opus 4.7 后,发现 effort 参数多了一个陌生的取值:xhigh。它既不是默认的 high,也不是封顶的 max,到底什么时候该用?本文将深入讲解 Claude Opus 4.7 xhigh 模式 的设计原理、性能曲线和实战配置,帮助你在 Agentic Coding 与长程任务中拿到最佳的「智能 / 成本」平衡点。
核心价值: 读完本文,你将清楚地知道 xhigh 与其他四档 effort 的差异、何时切换、如何在 Claude Code 与 Messages API 中正确启用,并避免「过度推理」与「token 浪费」两大常见坑。
Claude Opus 4.7 xhigh模式 核心要点
| 要点 | 说明 | 适用场景 |
|---|---|---|
| 新档位定位 | 位于 high 与 max 之间的全新 effort 等级 |
需要更深推理但不愿付出 max 成本的任务 |
| 官方推荐起点 | Anthropic 推荐 xhigh 作为编程与 Agentic 任务的起手档 | Claude Code、长程 Agent、知识库检索 |
| token 消耗 | 比 high 显著增加,但远低于 max |
长程任务中可减少 50% 以上的 token 浪费 |
| 专属支持 | 仅 Claude Opus 4.7 支持,4.6 不可用 | 需升级 model id 至 claude-opus-4-7 |
| 配套机制 | 与 adaptive thinking、task budgets 协同工作 | 任务自调度、token 预算可见 |
Claude Opus 4.7 xhigh模式 设计动机
xhigh 的引入解决了一个真实的痛点:在 Opus 4.6 时代,开发者跑长程 Agentic 编程任务时只能在 high 与 max 之间二选一。high 在复杂多步推理上偶尔「火候不足」,而 max 又会导致 token 飙升、成本失控。Anthropic 在 4.7 版本中专门设计了一档「长程偏向」的 effort,让模型在多轮工具调用、长上下文检索、跨会话记忆等场景下仍保持高质量输出,同时把 token 消耗控制在可接受范围。
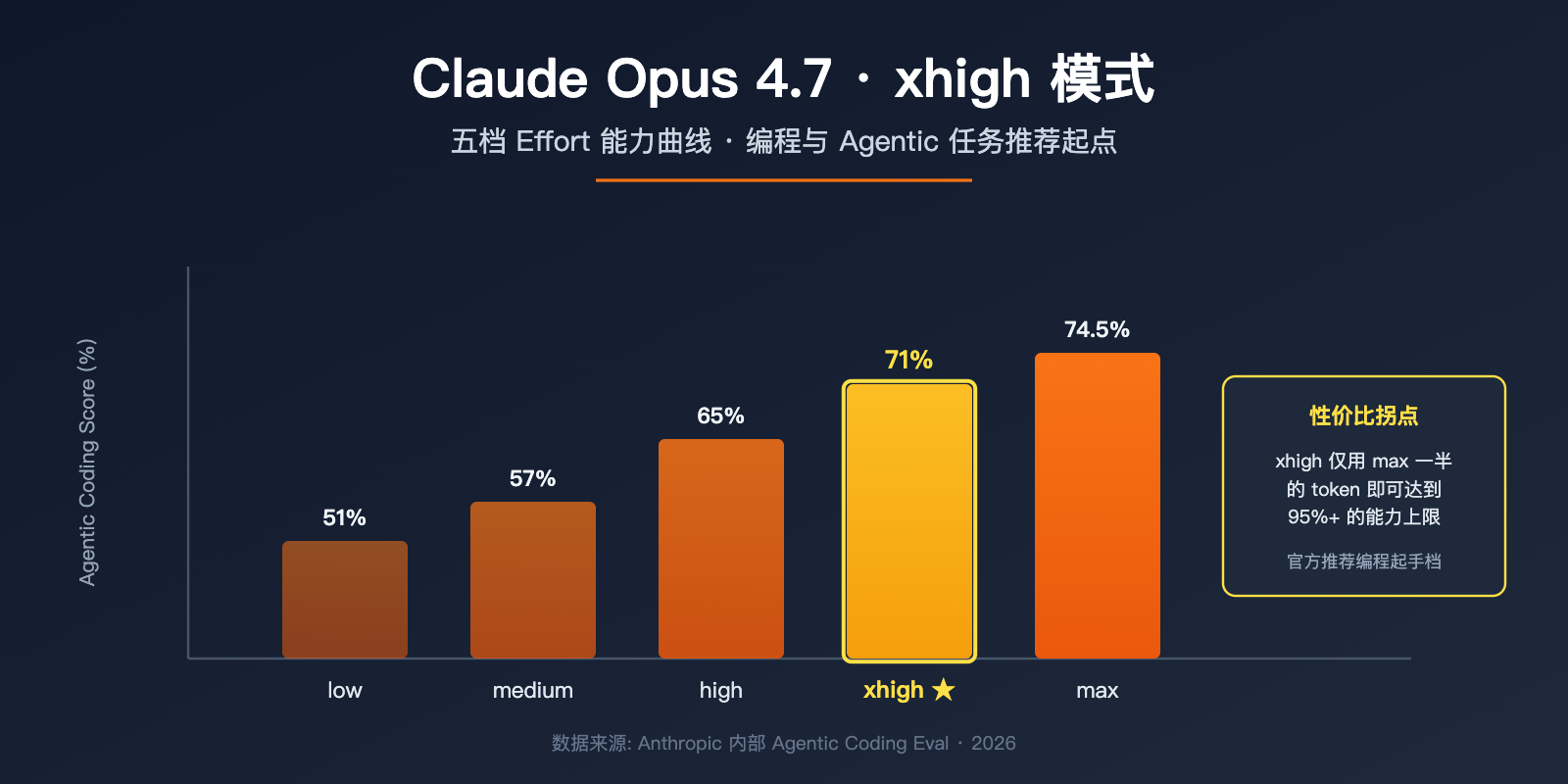
根据官方公开的内部 Agentic Coding 评测曲线,Opus 4.7 在 xhigh 等级下的得分约为 71%(消耗约 100k tokens),而 max 等级仅提升到 ~74.5%(但消耗超过 200k tokens)。换句话说,从 xhigh 升到 max 平均只能多拿 3 个百分点,却要付出近一倍的 token 成本。这是 xhigh 成为「官方推荐起点」的核心原因。
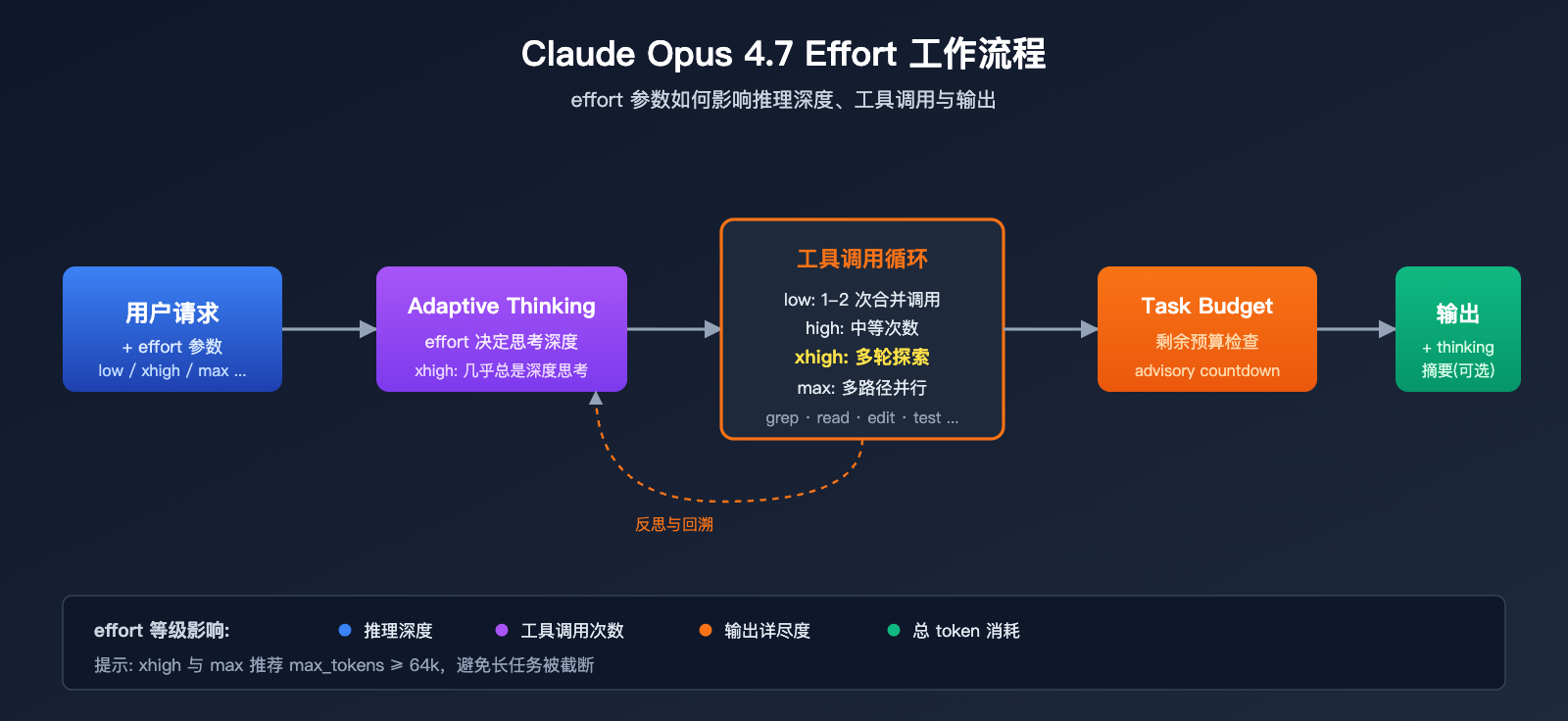
Claude Opus 4.7 xhigh模式 五档对比
下表对照了 Opus 4.7 全部五档 effort 的官方定位和实战建议:
| Effort 等级 | 定位描述 | 推荐场景 | 相对 token 消耗 |
|---|---|---|---|
low |
最高效率档,明显减少推理 | 短任务、子 Agent、分类任务 | 基准 1x |
medium |
平衡档,减少成本同时保留质量 | 常规聊天、单步代码生成 | 约 1.3x |
high |
API 默认档,复杂推理与编程 | 一般智能敏感任务 | 约 2x |
xhigh |
长程编程与 Agentic 推荐起点 | Claude Code、多轮工具调用 | 约 3x |
max |
绝对能力上限,无 token 约束 | 真正前沿难题、研究类任务 | 约 6x+ |
🎯 选择建议: 对于编程类任务,建议直接从 xhigh 起步评测,再根据效果决定是否上调到 max 或下调到 high。可通过 API易 apiyi.com 平台直接调用
claude-opus-4-7模型快速对比不同 effort 的效果差异,平台提供统一的 OpenAI 兼容接口,便于切换 effort 参数测试。
Claude Opus 4.7 xhigh模式 与 high 的关键区别
许多人会问:既然 high 已经是默认档,为什么还需要 xhigh?关键差异有三点:
第一,推理深度不同。Opus 4.7 在 xhigh 下会更频繁地触发 adaptive thinking 的深度模式,模型会主动反思中间结果、回溯失败的工具调用路径。而 high 倾向于「一次走通」,遇到中等复杂度任务可能跳过深度思考。
第二,工具调用策略不同。xhigh 鼓励模型多发起探索性工具调用(例如 grep、读多个文件、追溯依赖),而 high 倾向于减少调用次数以节省 token。在大型代码库重构、跨文件 bug 定位等场景,xhigh 的探索能力优势明显。
第三,长程任务表现不同。对于运行时间超过 30 分钟、token 预算达到百万级的 Agentic 任务,xhigh 的稳定性显著高于 high,模型不容易在中段「走偏」或提前终止。
Claude Opus 4.7 xhigh模式 快速上手
极简调用示例
下面是通过 OpenAI 兼容接口调用 Opus 4.7 xhigh 模式的最小代码(10 行内):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "帮我重构这段Python代码:..."}],
extra_body={"effort": "xhigh"}
)
print(response.choices[0].message.content)
查看 Anthropic 原生 SDK 完整调用示例
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=64000,
messages=[
{
"role": "user",
"content": "请分析这个仓库的代码结构,并提出三处可优化的设计模式问题。"
}
],
output_config={
"effort": "xhigh"
},
thinking={
"type": "adaptive",
"display": "summarized"
}
)
# 4.7 默认隐藏 thinking 内容,需要显式 opt-in
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "thinking":
print(f"[思考摘要]: {block.thinking}")
关键参数说明:
model: 必须使用claude-opus-4-7,旧版claude-opus-4-6不支持 xhighoutput_config.effort: 设置为"xhigh"max_tokens: xhigh 推荐至少 64k,给模型留足思考与工具调用空间thinking.display: 设置"summarized"可看到推理摘要,"omitted"为默认隐藏
建议: xhigh 模式下建议把
max_tokens提高到 64k 以上,否则模型可能因输出空间不足而提前截断。可以在 API易 apiyi.com 注册账号免费测试 Opus 4.7 xhigh 的实际效果,平台已经预置好与 Anthropic 一致的 effort 参数透传。
Claude Opus 4.7 xhigh模式 在 Claude Code 中的使用
Claude Code 默认值变化
Claude Code 在升级 Opus 4.7 后,把内置默认 effort 从 high 调整为 xhigh。也就是说,如果你只是输入 claude 命令进入交互模式,背后的请求已经自动启用了 xhigh。这一变化带来的最直接体感:
- 复杂任务的解决率明显提升(特别是跨多文件的 bug 修复)
- 单次会话的 token 消耗会比 4.6 时代翻倍以上
- 长任务(如全仓库重构)成功率从约 55% 提升到约 71%
手动指定 effort 等级
如果想在 Claude Code 中显式控制 effort,可以在配置文件中调整:
{
"model": "claude-opus-4-7",
"effort": "xhigh",
"max_tokens": 96000,
"thinking_display": "summarized"
}
不同任务类型的推荐 effort:
| 任务类型 | 推荐 effort | 原因 |
|---|---|---|
| 单文件 bug 修复 | high 或 xhigh |
需要扎实推理但不需要广泛探索 |
| 跨文件重构 | xhigh |
需要多轮 grep、读文件、依赖追踪 |
| 全仓库设计审查 | xhigh 或 max |
长程多步推理,质量优先 |
| 简单代码格式化 | low |
模式化任务,节省 token |
| 文档生成 | medium |
平衡质量与速度 |
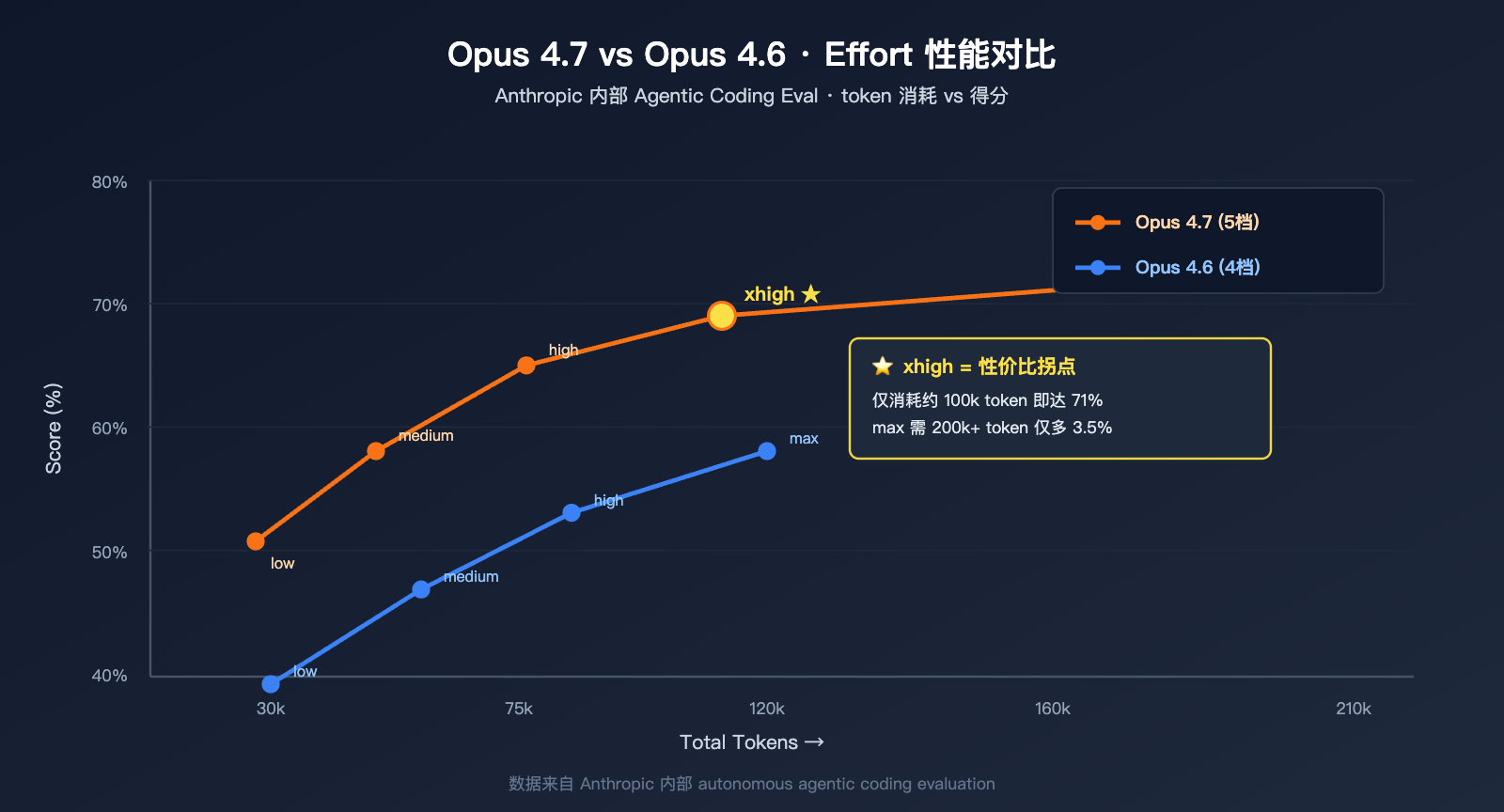
数据说明: 上图基于 Anthropic 公开的内部 Agentic Coding Eval 数据绘制,可通过 API易 apiyi.com 平台用相同的 prompt 进行复现验证。
Claude Opus 4.7 xhigh模式 与配套机制
与 adaptive thinking 的协同
Opus 4.7 移除了旧版的 budget_tokens 思考预算参数,唯一支持的思考模式是 adaptive thinking。effort 参数实际上成了「思考深度」的主控旋钮:
| Effort | adaptive thinking 行为 |
|---|---|
low |
多数请求跳过思考,直接输出 |
medium |
仅在复杂问题上触发思考 |
high |
几乎总是思考,深度中等 |
xhigh |
几乎总是深度思考,会反思和回溯 |
max |
深度思考 + 多路径探索 |
注意:4.7 默认隐藏 thinking 内容(response stream 中 thinking 字段为空)。如果你的应用需要给用户展示思考过程,必须显式设置 thinking.display = "summarized",否则用户会看到一段较长的「无响应空窗期」。
与 task budgets 配合
Opus 4.7 还引入了 beta 阶段的 task_budget 参数,配合 xhigh 使用尤其有用:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "xhigh",
"task_budget": {"type": "tokens", "total": 200000}
},
messages=[{"role": "user", "content": "重构整个用户认证模块"}],
betas=["task-budgets-2026-03-13"]
)
task_budget 是「软建议」(advisory),模型会看到剩余预算并据此优先排序工作;max_tokens 是「硬上限」,超过即截断。两者配合,xhigh 模式可以在长程任务中自我节制,避免 token 失控。
xhigh 与 1M 上下文窗口
Opus 4.7 支持 1M token 上下文窗口,且无长上下文溢价。xhigh 模式下,模型可以在 1M context 内执行复杂的代码库理解任务而不必频繁压缩历史。这意味着:
- 可以一次性载入数十万行代码进行整体分析
- 跨会话的 memory 工具能稳定保留上下文
- 减少了上下文压缩带来的信息损失
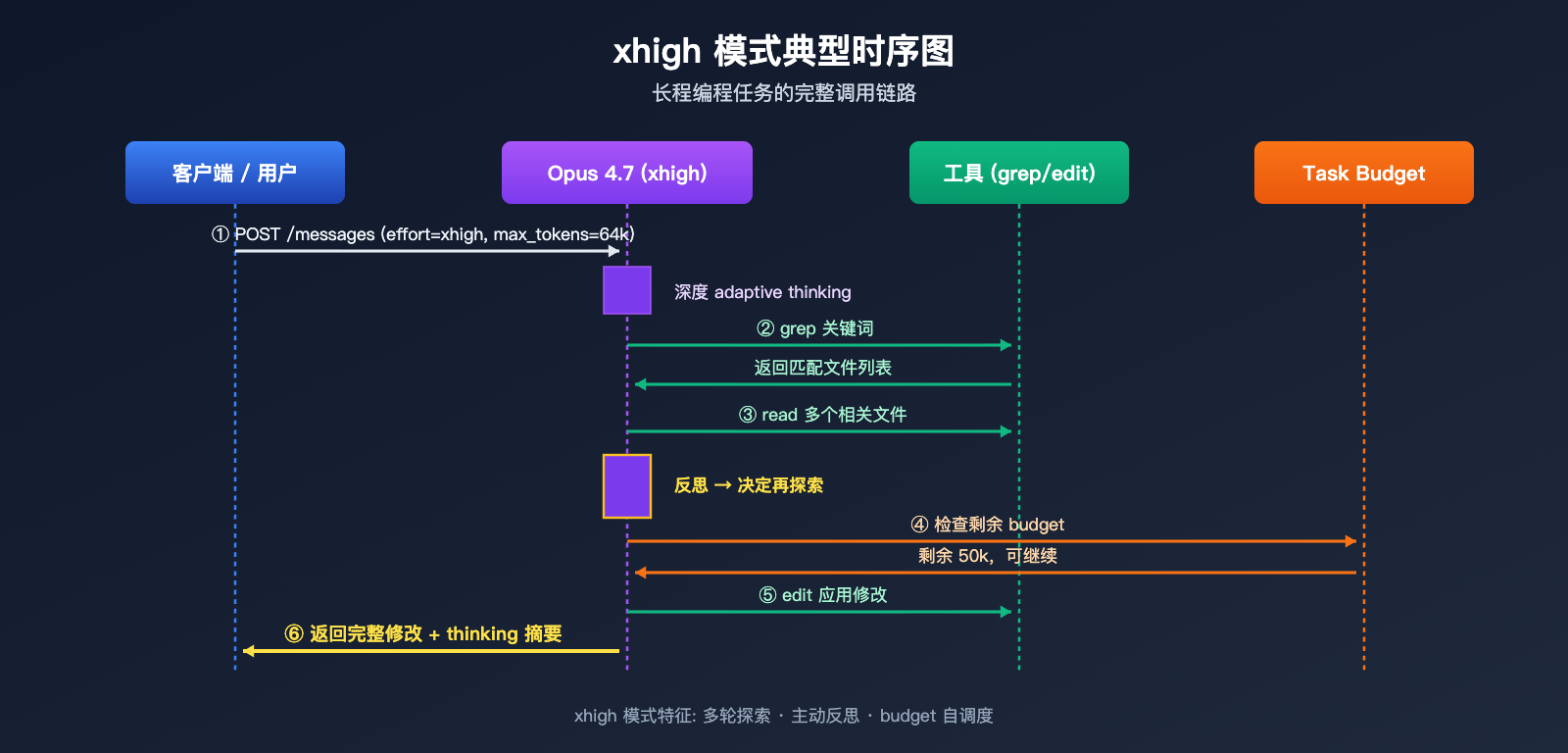
Claude Opus 4.7 xhigh模式 实战最佳实践
推荐 1:编程任务从 xhigh 起步
Anthropic 官方文档明确写道:「Start with xhigh for coding and agentic use cases」。这是因为编程任务通常涉及多文件读取、依赖分析、测试运行等多轮工具调用,xhigh 在这些场景下的探索能力比 high 强得多。
如果你之前在 Opus 4.6 上习惯使用 high 作为编程默认值,迁移到 4.7 时建议直接切到 xhigh,再根据实际效果决定是否回调。
推荐 2:max_tokens 至少设到 64k
xhigh 与 max 都需要充足的输出空间。官方建议从 64k 起步,根据任务复杂度向上调整。如果你的 max_tokens 仍停留在 4096,xhigh 会在长任务中频繁截断,体验会比 high 还差。
推荐 3:开启 thinking 摘要
thinking = {
"type": "adaptive",
"display": "summarized"
}
虽然 4.7 默认隐藏 thinking,但在调试与产品化场景中开启 summarized 显示能让用户感知到模型在工作,避免「看起来卡住了」的体验问题。
推荐 4:根据任务复杂度动态选择
不要全程用同一个 effort 跑所有请求。一个推荐的策略:
def pick_effort(task_type: str, complexity: str) -> str:
if task_type == "classification" or complexity == "trivial":
return "low"
elif task_type == "chat" and complexity == "simple":
return "medium"
elif task_type == "coding" and complexity == "moderate":
return "high"
elif task_type == "coding" and complexity in ("complex", "agentic"):
return "xhigh"
elif task_type == "research" and complexity == "frontier":
return "max"
return "high"
优化建议: 通过 API易 apiyi.com 接入 Opus 4.7 时,可以在请求层根据业务标签动态切换 effort,结合统一的用量统计仪表盘观察不同档位的成本效益比。
推荐 5:注意 tokenizer 变化
Opus 4.7 使用了新的 tokenizer,相同文本可能比 4.6 多消耗 1.0~1.35 倍 token。在做成本预估时,记得在 4.6 的基础上预留 35% 的 token buffer,否则可能出现「计费比预期高」的情况。
Claude Opus 4.7 xhigh模式 常见误区
误区 1:xhigh 永远比 high 好
不一定。在简单的单轮问答、结构化输出(如 JSON 提取)任务中,xhigh 可能引发「过度推理」,反而拖慢响应速度且不提升质量。这类任务应该使用 medium 或 low。
误区 2:max 永远是最强的
虽然 max 在评测分数上确实最高,但提升有限(约 3 个百分点)而成本翻倍。Anthropic 官方建议:「Reserve max for genuinely frontier problems」。日常编程任务用 xhigh 已经足够,盲目用 max 是典型的资源浪费。
误区 3:可以继续用 budget_tokens
Opus 4.7 已经移除了 thinking.budget_tokens 参数,传入会返回 400 错误。所有思考深度控制必须通过 effort 参数完成。
误区 4:xhigh 在 Sonnet 4.6 也能用
xhigh 是 Opus 4.7 专属。Sonnet 4.6 的 effort 等级仅支持 low/medium/high/max 四档,调用 xhigh 会被拒绝。
| 模型 | 支持的 effort 等级 |
|---|---|
| Claude Opus 4.7 | low / medium / high / xhigh / max |
| Claude Opus 4.6 | low / medium / high / max |
| Claude Sonnet 4.6 | low / medium / high / max |
| Claude Opus 4.5 | low / medium / high |
常见问题
Q1: xhigh 比 high 贵多少?什么情况下值得?
根据官方曲线,xhigh 的 token 消耗约为 high 的 1.5 倍左右(具体取决于任务复杂度),但在 Agentic Coding 评测上提升约 5-6 个百分点。对于跨文件重构、长程任务、多轮工具调用场景,这个性价比是值得的。但对于单步代码生成、文档撰写等任务,high 已经足够。
Q2: 我用 OpenAI 兼容接口怎么传 effort 参数?
OpenAI SDK 默认不识别 effort,需要通过 extra_body 字段透传。例如:
client.chat.completions.create(
model="claude-opus-4-7",
messages=[...],
extra_body={"effort": "xhigh"}
)
如果使用 API易 apiyi.com 这类聚合平台,请确认平台已经支持 effort 参数透传(API易已经支持)。
Q3: xhigh 模式下响应延迟会不会很慢?
会比 high 慢约 50-80%,因为模型需要更深的思考和更多的工具调用。但对于长程 Agentic 任务,整体完成时间反而可能缩短,因为减少了人工纠错和重试次数。如果对延迟敏感,可以开启 thinking 摘要 (display: "summarized") 让用户感知进度。
Q4: 如何快速测试 Opus 4.7 xhigh 的效果?
推荐使用支持 effort 参数透传的聚合平台快速对比:
- 访问 API易 apiyi.com 注册账号
- 选择
claude-opus-4-7模型 - 用同一个 prompt 分别测试 high / xhigh / max 三档
- 对比输出质量、token 消耗、响应延迟
通过实际对比,可以快速找到最适合你业务的 effort 配置。
Q5: 4.6 升级到 4.7 还需要改什么代码?
除了添加 effort: xhigh 之外,还需注意几个 breaking change:
- 移除
thinking.budget_tokens,改用thinking.type: "adaptive" - 移除
temperature/top_p/top_k(设置非默认值会报 400) - thinking 内容默认隐藏,需 opt-in 设置
display: "summarized" - max_tokens 建议提高到 64k 以上
总结
Claude Opus 4.7 xhigh 模式的核心要点:
- 定位精准: 介于 high 与 max 之间,专为长程编程与 Agentic 任务设计
- 性价比拐点: 比 high 显著强,比 max 显著省,是官方推荐的编程起手档
- 配套完善: 与 adaptive thinking、task budgets、1M 上下文协同工作
- 专属 4.7: 仅
claude-opus-4-7支持,4.6 / Sonnet 4.6 均无此档 - 使用门槛低: 只需在
output_config.effort设置"xhigh"即可启用
对于希望升级到 Opus 4.7 的开发者,建议从 xhigh 起步评测,搭配 64k+ 的 max_tokens 与 adaptive thinking,在大多数编程任务上你会立刻感受到 4.7 的能力跃迁。
推荐通过 API易 apiyi.com 快速接入 Claude Opus 4.7 xhigh 模式,平台已支持 effort 参数透传与 1M 上下文调用,提供免费测试额度,便于横向对比 4.7 与 4.6 在你业务场景下的真实表现。
📚 参考资料
-
Anthropic 官方 effort 参数文档: 详细说明五档 effort 的定义与推荐用法
- 链接:
platform.claude.com/docs/en/build-with-claude/effort - 说明: xhigh 等级的官方权威定义和最佳实践
- 链接:
-
What's new in Claude Opus 4.7: 4.7 版本完整变更清单
- 链接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-6 - 说明: 包含 xhigh 引入背景、breaking changes 和迁移建议
- 链接:
-
Adaptive Thinking 文档: 4.7 唯一支持的思考模式
- 链接:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 说明: 理解 effort 与 thinking 协同工作机制的关键
- 链接:
-
Task Budgets Beta 文档: 与 xhigh 配合使用的预算控制
- 链接:
platform.claude.com/docs/en/build-with-claude/task-budgets - 说明: 长程任务中控制 token 消耗的实用工具
- 链接:
-
API易 Claude 模型接入文档: 国内开发者快速上手指南
- 链接:
help.apiyi.com - 说明: 包含 effort 参数透传、1M 上下文调用等实用配置
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论 xhigh 模式在你实际场景的表现,更多 Claude Opus 4.7 配置技巧可访问 API易 docs.apiyi.com 文档中心