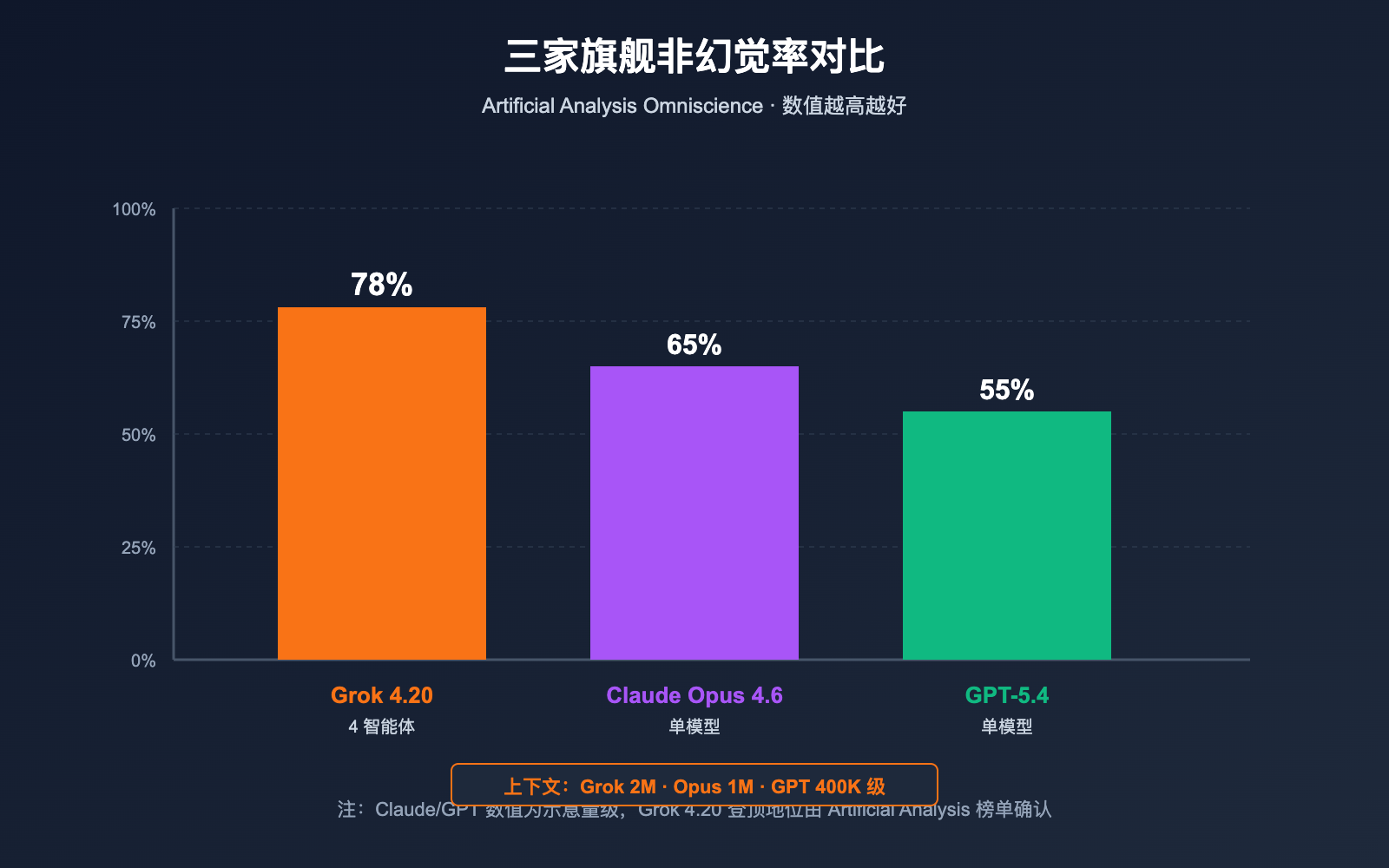
2026 年 2 月 17 日,xAI 正式发布 Grok 4.20 Beta,以一种非常反常规的思路在"非幻觉率"这个长期被 Claude 与 GPT 系列霸占的榜单上实现反超:它并没有单纯堆参数或堆推理步数,而是让 4 个专业化智能体(Grok / Harper / Benjamin / Lucas)在每次复杂查询中并行工作、互相辩论、最后合成答案。独立第三方 Artificial Analysis Omniscience 测评给出 78% 非幻觉率,xAI 官方称综合测试可达 83%,在公开测评中超过 Claude Opus 4.6 与 GPT-5.4。同时 Grok 4.20 将上下文窗口推进到 2M token,在超长文档与长周期代理任务上取得显著优势。
背后的算力支撑也在升级:xAI 的 Colossus 2 超算集群 正逐步扩容至 1.5GW 级别,为 Grok 5 及后续多智能体规模化做准备。本文基于英文一手资料系统梳理 Grok 4.20 的架构设计、关键跑分、Heavy 模式、API 上线情况以及典型落地场景,帮助你在 10 分钟内判断是否值得切换。
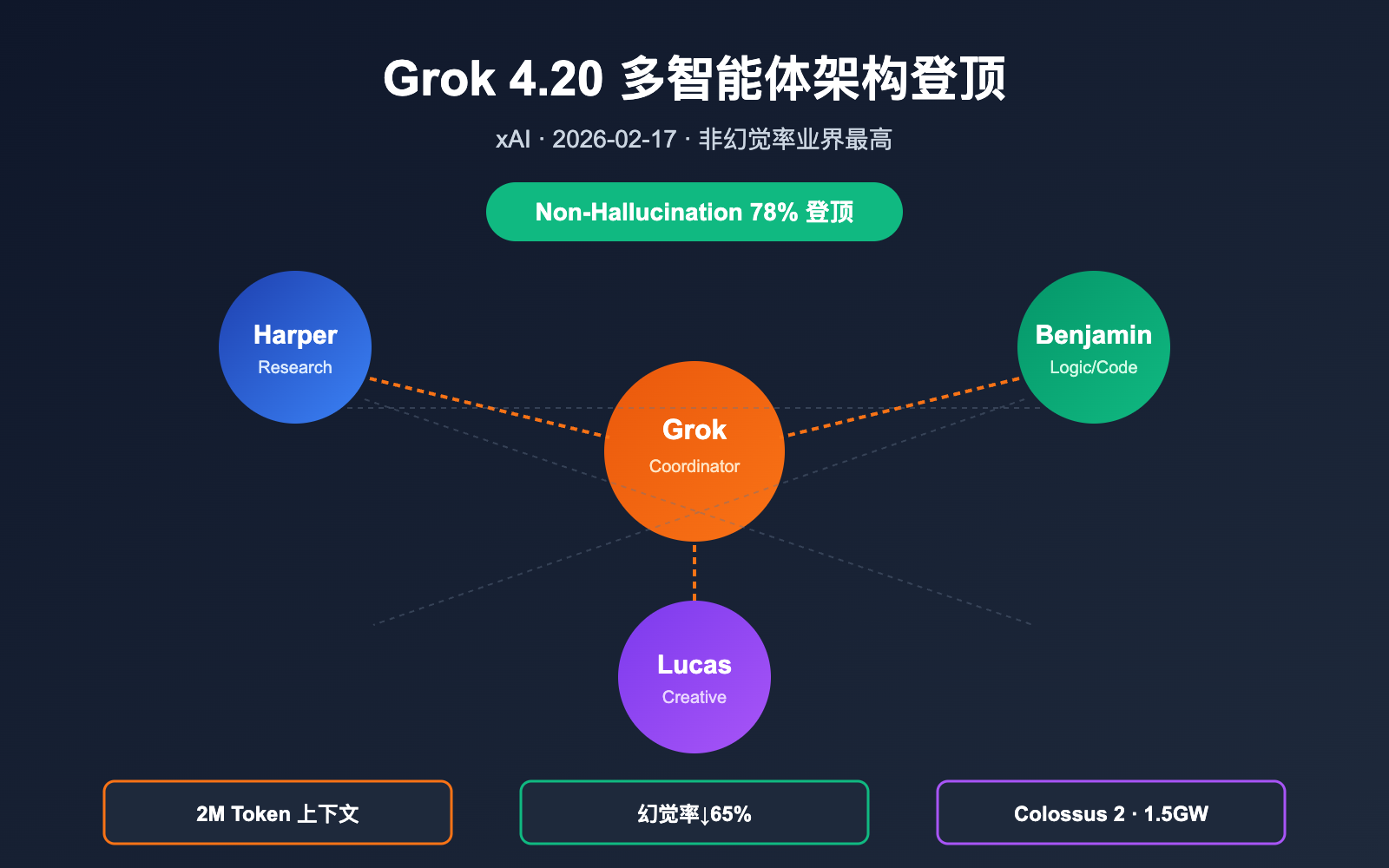
Grok 4.20 多智能体架构的核心突破
相比"单个更大模型 + 更深推理链"的主流思路,Grok 4.20 选择了一条**群体智能(Swarm-style Reasoning)**路线。
4 个智能体的分工
| 角色 | 名字 | 职责 | 关键能力 |
|---|---|---|---|
| 协调者 | Grok | 任务分解、辩论裁决、最终合成 | Orchestration / Arbiter |
| 研究员 | Harper | 实时 Web 搜索 + X Firehose 数据检索 | 事实补全、时效校验 |
| 逻辑员 | Benjamin | 数学、代码、结构化推理与验证 | 代码执行校验、形式化推理 |
| 发散员 | Lucas | 创意输出、方案扩展、语言润色 | 多候选生成、答案优化 |
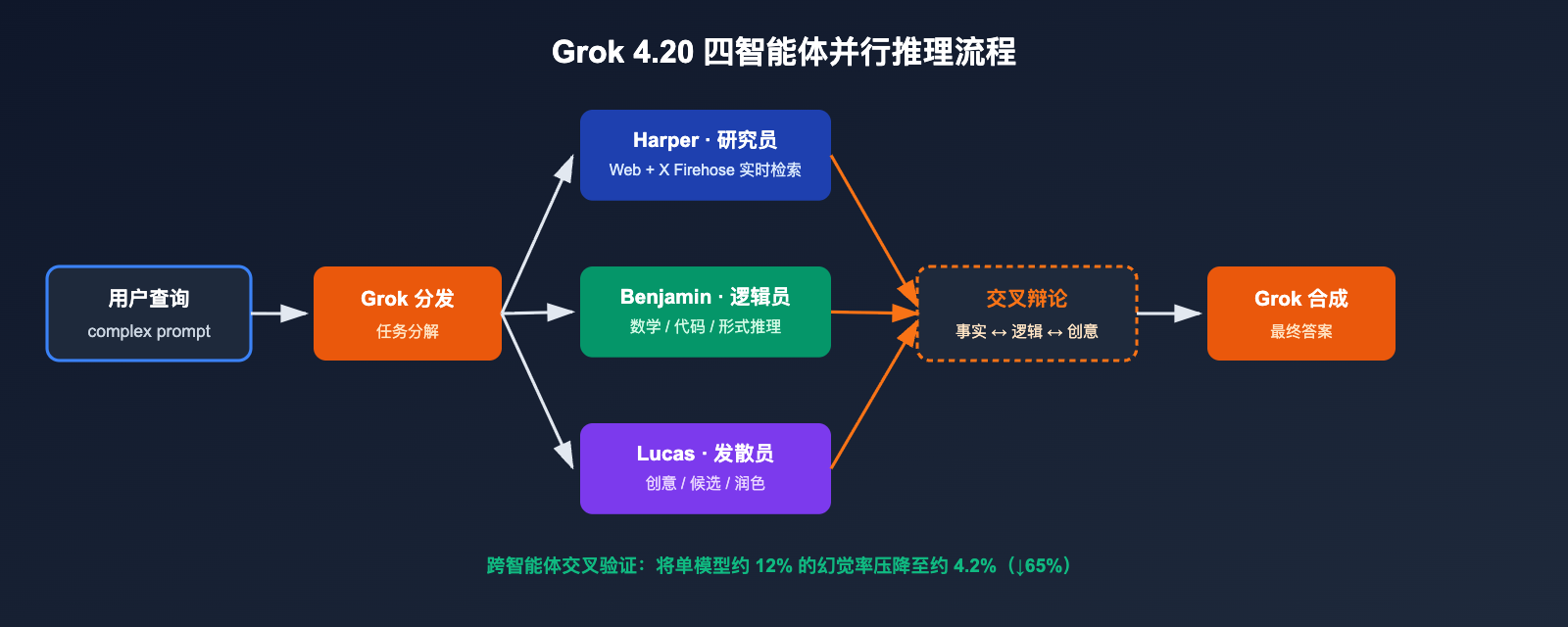
每次复杂查询进入模型后,Harper 先拉取实时上下文,Benjamin 同步进行逻辑与代码推理,Lucas 输出多组候选答案,最后由 Grok 协调辩论并合成终稿。这套机制把"一个模型一次前向推理"升级为"四个专业角色的内部多轮协商"。
为什么能降低幻觉
传统 LLM 的幻觉主要来自:模型对自己"不知道的事情"缺乏自我校验;Grok 4.20 通过 跨智能体交叉验证 形成自然的事实校对机制:
- Harper 发现 Benjamin 的推断与最新网页/X 实时数据相矛盾 → 打回;
- Benjamin 发现 Lucas 的创意方案数学不成立 → 否决;
- Grok 作为协调者只会输出三方都无反对的结论。
官方披露:这种机制把原本约 12% 的单模型幻觉率压到约 4.2%,相当于 65% 的幻觉下降。
🎯 架构理解提示:多智能体不是"4 次单模型串联",而是一次前向中 4 路并行+辩论。想快速体验差异的团队,可以通过 API易 apiyi.com 直接调用 Grok 4.20,与其他模型并列跑同一批 prompt,对比幻觉率差异。
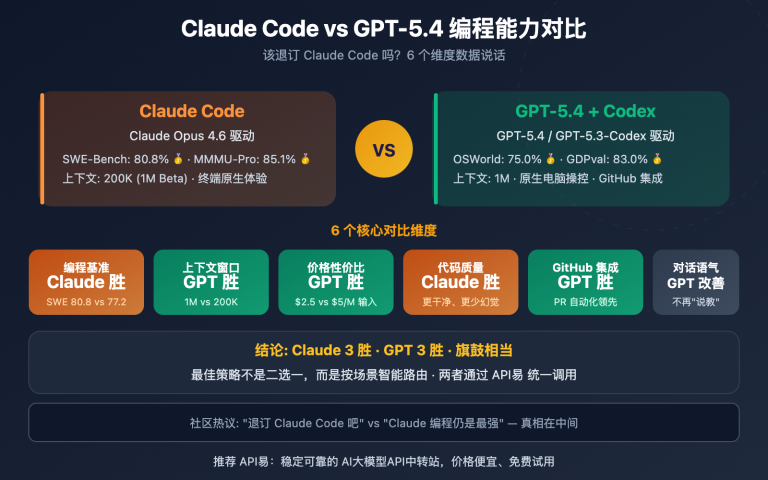
Grok 4.20 关键指标与行业对比
跑分的含金量很大程度上取决于评测集,下面将自报告与独立测评分开列出。
公开跑分概览
| 指标 | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience(非幻觉率) | 78%(登顶) | 次席 | 第三 |
| xAI 自测综合非幻觉率 | 约 83% | — | — |
| 幻觉率(相对 Grok 4.1 基线) | 4.22%(↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| 上下文窗口 | 2,000,000 tokens | 200K(1M 扩展) | 400K 级 |
| 架构 | 4 智能体并行(Heavy 模式 16) | 单模型 | 单模型 |
Heavy 模式:4 → 16 智能体扩展
除默认 4 智能体配置,Grok 4.20 还提供 Heavy 模式:在需要更强推理深度时,智能体数量从 4 扩展到 16,覆盖更广的辩论空间与更高维的证据链交叉验证。代价是单次请求成本与延迟上升,适合"对正确率苛刻、成本不敏感"的场景(投研、合规审计、安全分析等)。
模式与场景速查
| 模式 | 智能体数 | 适用场景 | 特征 |
|---|---|---|---|
| Grok 4.20 非推理模式 | 1 | 聊天、问答 | 低延迟、低成本 |
| Grok 4.20 推理模式 | 1 + CoT | 数学、代码 | 中等成本 |
| Grok 4.20 多智能体(默认) | 4 | 复杂查询、事实核验 | 幻觉显著下降 |
| Grok 4.20 Heavy | 16 | 专业研究、合规审计 | 最高正确率 |
🎯 跑分阅读建议:同一模型的自测和第三方测评可能有 5~10 个百分点的落差,选型时优先参考 Artificial Analysis 等独立基准。通过 API易 apiyi.com 在同一套 prompt 上对比 Grok 4.20 / Opus 4.6 / GPT-5.4,可以更真实地看到业务语境下的表现。
Grok 4.20 的 2M 上下文与 Colossus 2 算力底座
架构创新需要硬件支撑,这次 Grok 4.20 的两个底层升级同样值得关注。
2M token 上下文的价值
Grok 4.20 把上下文窗口拉到 2,000,000 tokens,这意味着:
- 整本书级文档 可以一次性塞入 prompt,无需手工拆分;
- 长对话 / 长代理会话 可保持完整历史;
- 多文件代码审查 可覆盖中型 monorepo;
- 与 Harper 的实时检索能力叠加,形成"长记忆 + 实时事实"的组合优势。
Colossus 2 超算集群升级到 1.5GW
xAI 为 Grok 系列打造的 Colossus 2 超算集群正在升级至 1.5GW 级 算力规模,这一基础设施目标瞄准 Grok 5 与更大规模多智能体群。对开发者的直接影响:
- 推理可用性与并发上限更高;
- 新版本模型迭代速度加快;
- Grok 4.20 已经能承载"16 智能体 × 2M 上下文"的 Heavy 模式,对应的算力基线就来自这一集群。

快速上手:Grok 4.20 API 调用与 API易接入
基础调用示例(OpenAI 兼容)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# 默认 4 智能体多智能体模式
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a factual research assistant."},
{"role": "user", "content": "总结一下 2026 年 Q1 全球 AI 芯片出货量数据,并列出关键来源。"},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
调用 Heavy 模式(16 智能体)
# Heavy 模式适合高正确率场景,延迟与成本更高
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "对这份 800 页合规文档做风险要点汇总与交叉引用核验。"},
],
max_tokens=16384,
)
📎 展开查看 2M 超长上下文调用示例
# 2M 上下文可一次性吃下整本书 / 整个仓库
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # 可达百万级 token
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a senior code reviewer."},
{"role": "user", "content": f"以下是整个仓库代码,请找出最严重的 5 个问题:\n\n{repo_text}"},
],
max_tokens=8192,
)
API易平台接入优势
Grok 4.20 的 API 已在 API易 apiyi.com 正式上线,价格与官网一致,同时提供以下差异化:
- 充值活动最低 85 折,长期使用成本低于直连;
- 不限并发,适合 Heavy 模式批量跑任务;
- OpenAI 兼容接口,无需改造现有代码,仅替换
base_url与model字段即可; - 与 Claude / GPT 等其他模型同账号计费,便于多模型并行 A/B。
🎯 接入建议:Heavy 模式单次 token 消耗是普通模式的数倍,不限并发的优势在这种场景最明显。新接入团队建议先在 API易 apiyi.com 用非推理模式跑通基本逻辑,再把关键链路切到多智能体或 Heavy 模式。
Grok 4.20 的典型应用场景
最适合 Grok 4.20 的 5 类工作负载
| 场景 | 推荐模式 | 关键收益 |
|---|---|---|
| 新闻/研报事实核验 | 多智能体(默认) | Harper 实时检索 + 跨智能体交叉验证 |
| 投研与合规审查 | Heavy | 16 智能体降低关键事实出错率 |
| 整本书 / 整库级长文档分析 | 多智能体 + 2M | 一次性吃入,无须切分 |
| 多步 Agent 工作流 | 多智能体 | 自带协调者,减少外层工程 |
| 实时舆情 / 社媒监控 | 多智能体 | Harper 原生对接 X Firehose |
不推荐的场景
- 毫秒级 IDE 补全:多智能体并行带来的延迟不适合 Tab 级交互;
- 极端低成本批处理:Heavy 模式价格高,改用非推理模式或 Haiku 级模型更划算;
- 需要严格本地化部署:Grok 4.20 当前以 API 形式提供,无自托管权重。
🎯 迁移路径建议:将"高幻觉敏感度"的链路(合规、医疗、金融研究等)优先切到 Grok 4.20 多智能体模式,通过 API易 apiyi.com 的计费面板按链路拆分统计,可量化幻觉下降带来的业务增益。
常见问题 FAQ
Q1:非幻觉率 78% 与 83% 哪个更可信?
78% 来自独立第三方 Artificial Analysis Omniscience 测试集,是目前最具公信力的数据;83% 是 xAI 在更广测试集上的自测结果。选型建议以独立基准为主、官方数据为辅。两者的一致结论是:Grok 4.20 在非幻觉维度已超越 Claude Opus 4.6 与 GPT-5.4。
Q2:4 个智能体是不是就是调 4 次 API?
不是。多智能体调度在 xAI 服务端内部完成,对用户只暴露一次 API 调用。token 计费会高于单智能体模式,但远低于"自己在客户端串 4 次请求"的方案,且延迟更低。
Q3:Heavy 模式和普通多智能体差多少?
Heavy 把并行智能体从 4 扩到 16,在复杂推理、长证据链任务上正确率进一步提升,代价是单请求成本与延迟大幅上升。建议仅在"每错一条损失很大"的场景启用,例如合规、医学、投研。通过 API易 apiyi.com 按请求路由到不同模式可做到"按价值用算力"。
Q4:2M 上下文真的可以吃满吗?
可以。Grok 4.20 宣称的是实际可用上下文,不是理论上限。但同样要注意:上下文越长、每 token 成本与延迟线性上升;超大上下文建议结合上下文压缩 + 多智能体的 Harper 检索一起使用。
Q5:API易上线和官网有什么差别?
价格与官网一致,充值活动可做到 85 折,关键优势是不限并发,适合 Heavy 模式批量调用。接口保持 OpenAI schema 兼容,代码层只需把 base_url 指向 apiyi.com 即可。
Q6:Grok 4.20 会取代 Grok 5 吗?
不会。Grok 5 仍是 xAI 的下一代主力目标,由 Colossus 2 1.5GW 集群支撑。Grok 4.20 的定位更像是"把多智能体范式先在 4 代架构上跑通",为 Grok 5 的规模化多智能体提供工程验证。
总结:多智能体范式开始真正改变旗舰模型格局
Grok 4.20 带来的不只是一次版本更新,而是旗舰模型竞争维度的变化:从"单模型更大、更深推理链"转向"多角色群体推理 + 实时证据校验"。78% 的独立非幻觉率与 2M 上下文叠加,意味着高风险业务(合规、投研、医学、法律)第一次有了可以在通用 API 上获得的"低幻觉首选"方案。
对开发者来说,落地的第一步不是替换全部模型,而是把最怕出错的链路优先迁到 Grok 4.20 多智能体模式,把常规链路保留在成本更低的模型上,做成混合编排。行业趋势上,Grok 5 与 Colossus 2 的 1.5GW 集群会继续放大这一优势,早接入意味着更早积累多智能体调用经验。
🎯 行动建议:Grok 4.20 API 已在 API易 apiyi.com 正式上线,价格与官网一致,充值活动 85 折,关键是不限并发,非常适合多智能体、Heavy 模式和 2M 上下文的大吞吐需求。用一段 OpenAI 兼容代码即可接入,今天就把"最怕幻觉"的链路切过去。
— APIYI Team(API易 apiyi.com 技术团队)