最近 OpenAI 官方 Cookbook 聯合 Fractional AI 發佈了一份非常硬核的實戰案例: 用 AI 自動審覈報銷單據。乍聽是個普通的 OCR 任務, 真正點開 Notebook 才發現, 這其實是一份關於"如何把 AI 應用從 demo 推向生產"的方法論聖經, 也是當前業界討論最熱的 Eval-Driven System Design (評估驅動系統設計) 最完整的開源示例。
更有意思的是這套方法論解決的不是技術問題, 而是一個困擾所有 AI 工程師的根本問題: 如何確認我改的 prompt 是真的變好了, 還是隻是看起來變好了? 本文將用最通俗的方式拆解這個 OpenAI 收據審覈 案例, 提煉出 5 個對所有 AI 應用開發者都有啓發的工程經驗。
🎯 快速導覽: 案例來自 cookbook.openai.com 的 eval_driven_system_design 目錄, 作者是 Fractional AI 團隊 (Hugh Wimberly / Joshua Marker / Eddie Siegel) 與 OpenAI Shikhar Kwatra。完整代碼位於 OpenAI 官方 Cookbook 倉庫, 通過 API易 apiyi.com 這類 OpenAI 官轉網關可以一字不改地復現整套流程, 適合國內開發者直接學習。
OpenAI 收據審覈案例的業務背景: 爲什麼這是真問題
在直接講技術之前, 我們先把案例的商業背景講清楚。這不是一個爲了演示 API 而硬造的玩具問題, 而是一個非常真實、有明確 ROI 數字的企業場景。
| 業務維度 | 具體數字 | 含義 |
|---|---|---|
| 年處理量 | 約 100 萬張 | 中型企業典型規模 |
| AI 單張處理成本 | $0.20 | 模型調用費 |
| 人工審覈單價 | $2.00 | 財務人員複覈 |
| 漏審罰款 | $30 / 單 | 合規/稅務處罰 |
| 當前人工審覈率 | 5% | 僅疑難單據 |
把這些數字相乘你會發現, 哪怕是 1% 的審覈準確率提升, 落到 100 萬單的體量上就是 數十萬美元的年化收益。這就是 Fractional AI 團隊反覆強調的"把評估指標綁定到美元 (Dollar Impact)"——不是爲了卷指標, 而是爲了讓每一次 prompt 改動都對應得上業務賬本。
整個 AI 系統的目標也非常明確: 用 GPT-4o 自動審覈大部分單據, 只把"低置信度"的少量單據交給人工, 讓審覈成本和漏審風險都降下來。聽起來簡單, 但魔鬼藏在細節裏。
Eval-Driven Design 是什麼: 一個喫過虧纔會懂的方法論
如果你問 100 個 AI 工程師"你們怎麼驗證 prompt 改得對不對", 99 個會告訴你"跑幾個例子看看輸出感覺對不對"。這就是 Fractional AI 團隊抨擊的 vibe-coding (憑感覺調), 也是 Eval-Driven Design (以下簡稱 EDD) 想要徹底取代的開發方式。
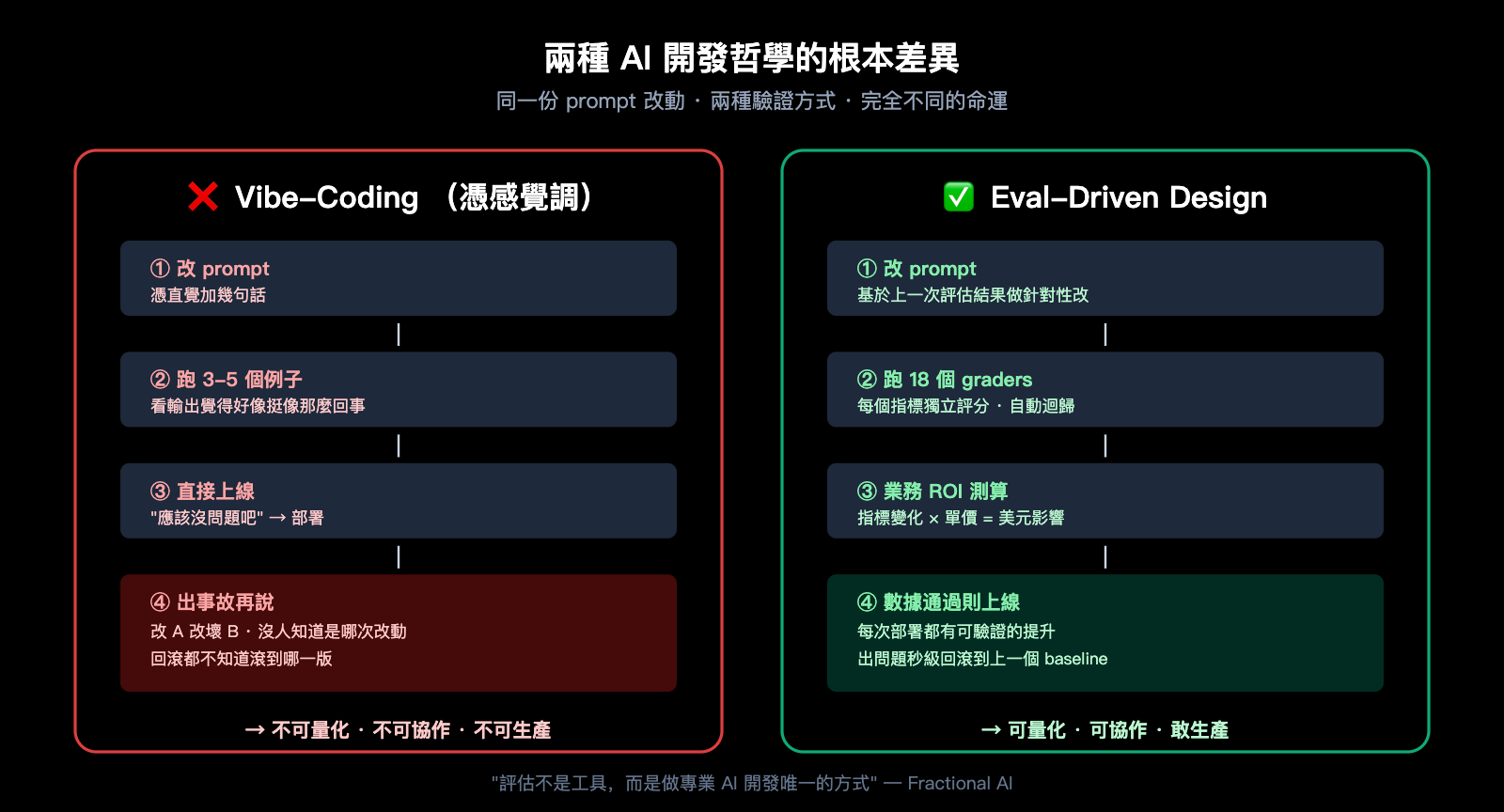
兩種開發方式的差異可以用下面這張表說清楚:
| 對比維度 | Vibe-Coding (憑感覺調) | Eval-Driven Design (評估驅動) |
|---|---|---|
| 驗證方式 | 跑 3-5 個例子看輸出 | 跑 20-100+ 個標註樣本算指標 |
| 改動判斷 | "感覺好像變好了" | "準確率從 78% 提升到 85%" |
| 業務對齊 | 憑感覺是否重要 | 直接換算成美元影響 |
| 迴歸風險 | 改 A 可能改壞 B 沒人知道 | 全套指標自動跑過 |
| 協作擴展性 | 只有原作者看得懂 | 任何工程師能 debug |
Fractional AI 在文章裏有一句話被廣泛引用: "評估不是工具, 而是做專業 AI 開發唯一的方式"。這句話聽起來誇張, 但在收據審覈這種業務關鍵場景中, 沒有 evals 等於在生產環境玩抽獎, 沒人敢真正放心地 ship。
💡 類比理解: Eval-Driven Design 就像考試有標準答案, 你能算出每次改動讓"卷子總分"提升了多少。Vibe-Coding 則像憑感覺答題, 改完一道題不知道是變好還是變差。生產級 AI 必須是前者。
OpenAI 收據審覈案例的三階段實施流程
OpenAI Cookbook 把整個案例拆成三個非常清晰的階段, 這個流程幾乎可以套到任何"圖像/文檔輸入 + 結構化決策輸出"的 AI 應用上。
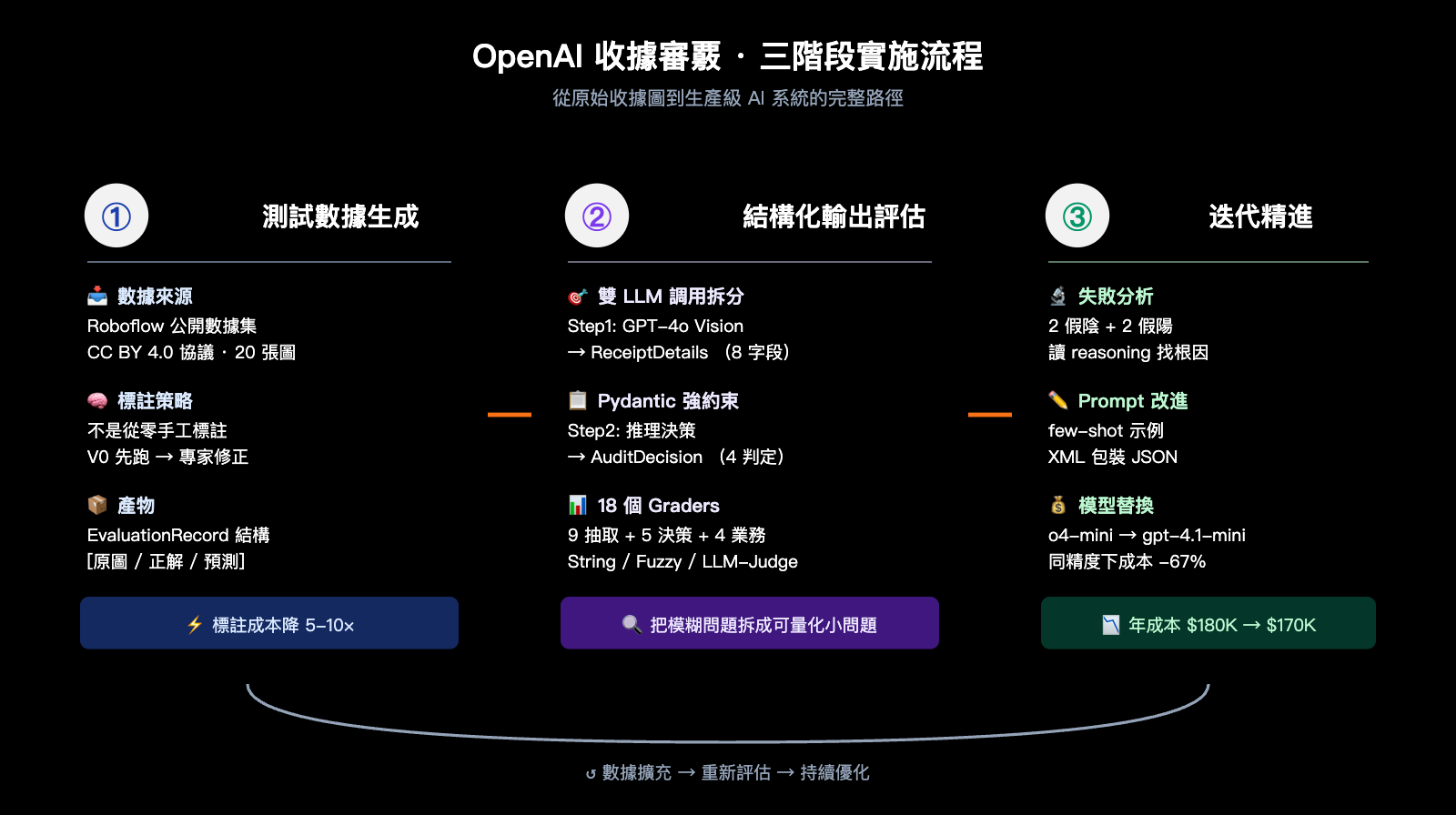
下面我用最通俗的方式把每個階段拆開來講。
階段一: 測試數據生成,聰明地省下 80% 標註成本
如果你以爲團隊是從 0 開始手工標註幾千張收據圖, 那就太低估工程師的偷懶能力了。Fractional AI 用了一個非常聰明的策略: 先讓 V0 模型跑一遍, 再讓專家修正。
具體流程是這樣的: 從 Roboflow 公開數據集 (CC BY 4.0 協議) 拿 20 張真實收據圖, 直接餵給一個簡單版本的 GPT-4o + Pydantic 抽取流程, 拿到 V0 的輸出。然後讓財務領域專家在這個輸出基礎上做"找錯改錯", 而不是從零開始一字一句敲數據。
這種"先生成再修正"的方法把領域專家的時間利用率提升了 5-10 倍, 因爲大部分字段 V0 已經識別對了, 專家只需要修正錯的部分。最終產出的 EvaluationRecord 數據結構也很優雅, 同時記錄了"原圖路徑、正確細節、模型預測細節、正確審覈決策、模型預測審覈決策", 一條記錄覆蓋整條流水線。
🔧 複用建議: 這套"V0 先跑一遍 → 專家修正"的標註策略, 幾乎可以套到所有 AI 應用的冷啓動階段。你只需要通過 OpenAI 官轉 API 平臺快速跑出 V0 輸出, 就能把領域專家的精力集中在最值錢的判斷環節。
階段二: 結構化輸出評估,Pydantic 是真正的英雄
整個 AI 系統由兩次 LLM 調用串成, 這種職責分離的設計是 EDD 的精髓之一。
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""第一步: 從圖像抽取結構化收據信息"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Pydantic 模型強約束
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""第二步: 基於結構化數據做審覈決策"""
# ... 調用 LLM 輸出 AuditDecision Pydantic 模型
爲什麼要拆成兩步? 因爲這兩個任務的能力要求完全不同: 第一步是"讀圖識字" (vision + 信息抽取), 第二步是"邏輯判斷" (推理決策)。把它們混在一個 prompt 裏調用, 不僅模型容易混淆任務邊界, 你想 debug 也找不到出錯的環節。
ReceiptDetails 和 AuditDecision 這兩個 Pydantic 模型的字段設計, 是這個案例最值得學習的地方:
| 模型 | 關鍵字段 | 業務含義 |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | 收據上能看到的所有信息 |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 審覈 4 個判斷條件 + 推理過程 + 最終結論 |
特別注意 AuditDecision 裏的 reasoning 字段——它強制讓模型在給出最終決策前寫出推理過程, 這是後續做 chain-of-thought 評估的關鍵。也注意 needs_audit 是前面四個 bool 字段的邏輯 OR, 這種"先打分項再合成決策"的設計讓評估指標可以拆得很細。
🚀 接入提示: 上面這段
client.responses.parse()是 OpenAI 最新的結構化輸出接口, 能直接把 Pydantic 模型當成輸出格式約束, 幾乎完全消除了 JSON 解析失敗的風險。我們建議通過 apiyi.com 這類 OpenAI 官轉 API 平臺調用, 因爲該接口對 SDK 版本有要求, 官轉網關確保協議同步更新。
階段三: 迭代精進,18 個 grader 讓改動都可量化
這一階段是 EDD 真正發光的地方。Fractional AI 團隊爲這個收據審覈系統設置了 18 個獨立的評估指標 (graders), 把"系統好不好"這個模糊問題分解成 18 個可量化的小問題。
這 18 個 grader 大致分爲三類:
| Grader 類型 | 代表指標 | 評估方式 |
|---|---|---|
| 抽取準確性 (9 個) | 商家名 / 地址 / 總金額匹配 | 字符串精確匹配 / 模糊匹配 |
| 審覈決策準確性 (5 個) | 差旅判定 / 超額判定 / 算錯檢測 / 手寫X識別 / 最終決策 | 二元分類準確率 |
| 業務對齊指標 (4 個) | 缺失商品 / 多出商品 / 商品準確度 / 推理質量 | LLM-as-Judge (0-10 分) |
初始評估在 20 個樣本上發現了 2 個假陰性 + 2 個假陽性, 這個數字看上去不大, 但放到年 100 萬單的規模就是數千起漏審。Fractional 團隊的處理方式非常工程化:
- 根因分析: 看每個錯例的 reasoning 字段, 找出模型卡在哪個判斷
- 針對性改 prompt: 加 few-shot 示例、明確"差旅相關"定義、把 JSON 示例用 XML 包起來
- 重新跑評估集: 驗證改動是真的修了 bug 而不是引入了新 bug
- 模型替換實驗: 同一套 prompt 在 o4-mini 和 gpt-4.1-mini 上分別跑, 選 ROI 更優的
最後一步的結果非常震撼: 從 o4-mini 切換到 gpt-4.1-mini, 成本降低 67%, 年成本從約 $180K 降到 $170K, 而準確率幾乎沒有下降。如果沒有完整的評估集, 誰敢做這個降本決策?
📊 關鍵洞察: 18 個 grader 不是爲了湊數, 而是把一個看起來無法量化的問題"AI 準確不準確"分解成 18 個可獨立修復、可獨立度量的小問題。在 apiyi.com 上調用 OpenAI Evals API 也能創建類似的 grader 體系, 接口與官方完全兼容。
OpenAI 收據審覈案例的 5 個工程啓示
讀完整個案例, 我提煉出 5 個對任何 AI 應用都通用的啓示, 這些是花真金白銀買來的經驗。
啓示一: 把評估綁定到美元, 不要追求所有指標都 100%
案例裏有個非常反直覺的發現——商家名字識別的準確率提升對最終審覈決策幾乎沒有影響, 因爲審覈規則不依賴商家名。如果團隊執着於把商家名識別從 92% 提到 98%, 那是在浪費工程資源。
相反, 手寫"X"的識別錯誤每年導致約 $75,000 的漏審損失, 這纔是優先級最高的指標。所以指標的選擇永遠要回答一個問題: "改對這個錯, 我能省多少錢?"
啓示二: 先用最強模型跑通, 再考慮省錢
案例裏 V0 階段直接選了 o4-mini 這種當時最強的模型, 不是因爲團隊不在意成本, 而是因爲他們知道讓一個能力不足的模型勉強工作, 遠比讓一個能力過剩的模型便宜地工作要難。先跑通業務邏輯、建立完整的評估體系, 再做模型替換實驗, 這個順序不能顛倒。
啓示三: 抽取和決策一定要拆開, 別貪心寫一個萬能 prompt
很多新手會想: 一次調用就能從圖片直接得到"是否需審覈"的結論, 多省錢啊! 但這種設計有兩個致命缺陷: 不可調試——出錯了不知道是看錯圖還是判錯邏輯; 不可複用——抽取結果只能用於這一個決策。拆成兩步看起來多調一次 API, 實際上讓整個系統的可維護性提升了一個數量級。
啓示四: chain-of-thought 評估能抓出"答對了但理由錯"的隱患
AuditDecision 裏那個看似冗餘的 reasoning 字段, 在評估時被用來識別一種危險情況: 模型給出了正確的最終答案, 但推理過程是錯的。這種"運氣式正確"在小樣本下看不出來, 一旦數據分佈稍微變化就會大面積翻車。強制輸出推理 + 用 LLM-as-Judge 評估推理質量, 是生產級 AI 應用的必備保險。
啓示五: 標註成本可以工程化降低
不要被"AI 項目需要海量標註數據"這種刻板印象嚇到。20 張 + 專家修正 V0 輸出的策略已經能支撐出有用的評估集, 關鍵是讓評估集和真實業務數據分佈一致, 而不是追求樣本數量。Fractional 的經驗是用初期 V0 輸出做"種子標註", 比從 0 開始手工標註效率提升 5-10 倍。
國內復現 OpenAI 收據審覈案例的注意事項
國內開發者要復現這套 cookbook 需要解決三個問題: 能不能調到 o4-mini / gpt-4.1-mini 這些新模型、能不能用 responses.parse 這個最新接口、能不能調通 Evals API 端點。
直連 OpenAI 在國內體驗非常不穩定, 尤其圖像類接口因爲 payload 大, 失敗率比文本接口更高。用官轉 API 網關基本可以一鍵解決這三個問題, 關鍵代碼只需要改一行 base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # 唯一需要改的一行
api_key="你的 API易 Key"
)
# 後續所有代碼與 cookbook 一字不差
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
這就是"OpenAI 官轉 API"和"OpenAI 兼容 API"的關鍵差異——前者保證接口與 OpenAI 官方同步, 後者只兼容基礎接口, 像 responses.parse、Evals API 這類高級能力可能不支持。復現 cookbook 這種官方案例時, 選官轉網關能避免一堆兼容性坑。
OpenAI 收據審覈案例 FAQ
Q1: 這套方法只能用於收據嗎?
完全不是。Eval-Driven Design 適用於任何"輸入相對開放、輸出需要結構化決策"的場景: 合同審覈、醫療影像分診、客服質檢、招聘簡歷篩選、欺詐檢測都可以套這套三階段流程。換湯不換藥的就是 Pydantic schema 和評估 grader 的設計。
Q2: 18 個 grader 是不是太多了, 小團隊搞不動?
可以從 5-6 個核心 grader 起步, 例如最終決策準確率 + 關鍵字段抽取準確率。重要的不是數量, 而是每個 grader 都對應一個具體的失敗模式。我們建議在 apiyi.com 控制檯先跑 GPT-4o 的少量樣本, 等業務跑通後再擴充評估維度。
Q3: V0 直接用 o4-mini 不會很貴嗎?
V0 階段調用量通常是幾十到幾百次, 總成本幾美元到幾十美元, 完全可以承受。真正要省錢的是生產環境的百萬級調用, 那時候已經有完整評估集做模型替換實驗了, 就像案例裏 o4-mini → gpt-4.1-mini 那一刀降了 67%。
Q4: GPT-4o Vision 讀手寫中文收據效果怎麼樣?
英文打印收據準確率非常高 (95%+), 中文打印也不錯 (90%+), 中文手寫則取決於字跡清晰度。建議先用 100 張真實樣本建立評估集, 而不是相信 demo 視頻。通過官轉 API 調用 GPT-4o Vision 的成本與官方一致, 適合做大規模評估實驗。
Q5: 如果我沒有 Evals API 權限, 能跑這個 cookbook 嗎?
可以。Evals API 主要是把 grader 配置和運行管理託管給 OpenAI, 實際評估邏輯你自己用 Python 跑也完全等效。cookbook 裏的 grader 函數全部開源, 複製到本地就能用。後續如果業務規模上來了, 再考慮遷移到託管 Evals。
Q6: APIYI 調用這套案例和官方有什麼區別?
接口協議、模型版本、參數支持都與 OpenAI 官方完全同步, 這是"官轉"的核心承諾。區別主要在網絡層面: 國內直連 OpenAI 經常出現 SSL 握手失敗、超時, 而官轉網關在國內 IDC 部署, 圖像類接口的穩定性提升尤爲明顯。這對於跑長時間評估任務非常關鍵。
總結
OpenAI 收據審覈 這個案例之所以值得反覆研讀, 是因爲它把"如何用 AI 解決一個真實業務問題"這個抽象命題, 拆解成了三階段、18 個評估指標、可量化到美元影響的具體工程實踐。這是中文社區目前最缺的 AI 工程化範本。
如果你正在做任何"輸入文檔/圖像、輸出結構化決策"的 AI 應用, 強烈建議把這份 cookbook 完整跑一遍。不要只看不動手, eval-driven design 真正的價值要在你看到指標變化的瞬間才能感受到。我們建議通過 apiyi.com 這類 OpenAI 官轉 API 平臺直接復現, 可以省去環境調試的所有麻煩, 把精力集中在方法論本身。
把"評估驅動"這四個字刻進開發流程, 你的 AI 系統就從"看着挺像那麼回事"的玩具, 升級成了"敢放上生產、敢算 ROI"的工程產物。這中間的差距, 可能就是 $75,000。
📌 作者: APIYI Team — 長期跟蹤 OpenAI / Anthropic / Google 多模態 API 的工程實踐案例, 更多 cookbook 實戰解讀和官轉 API 接入指南見 apiyi.com 文檔中心。