作者注:全面解讀 Claude Opus 4.7 全新 xhigh effort 等級,對比 low/medium/high/xhigh/max 五檔差異,給出編程與 Agentic 場景下的最佳實踐與代碼示例。
很多開發者在升級到 Claude Opus 4.7 後,發現 effort 參數多了一個陌生的取值:xhigh。它既不是默認的 high,也不是封頂的 max,到底什麼時候該用?本文將深入講解 Claude Opus 4.7 xhigh 模式 的設計原理、性能曲線和實戰配置,幫助你在 Agentic Coding 與長程任務中拿到最佳的「智能 / 成本」平衡點。
核心價值: 讀完本文,你將清楚地知道 xhigh 與其他四檔 effort 的差異、何時切換、如何在 Claude Code 與 Messages API 中正確啓用,並避免「過度推理」與「token 浪費」兩大常見坑。
Claude Opus 4.7 xhigh模式 核心要點
| 要點 | 說明 | 適用場景 |
|---|---|---|
| 新檔位定位 | 位於 high 與 max 之間的全新 effort 等級 |
需要更深推理但不願付出 max 成本的任務 |
| 官方推薦起點 | Anthropic 推薦 xhigh 作爲編程與 Agentic 任務的起手檔 | Claude Code、長程 Agent、知識庫檢索 |
| token 消耗 | 比 high 顯著增加,但遠低於 max |
長程任務中可減少 50% 以上的 token 浪費 |
| 專屬支持 | 僅 Claude Opus 4.7 支持,4.6 不可用 | 需升級 model id 至 claude-opus-4-7 |
| 配套機制 | 與 adaptive thinking、task budgets 協同工作 | 任務自調度、token 預算可見 |
Claude Opus 4.7 xhigh模式 設計動機
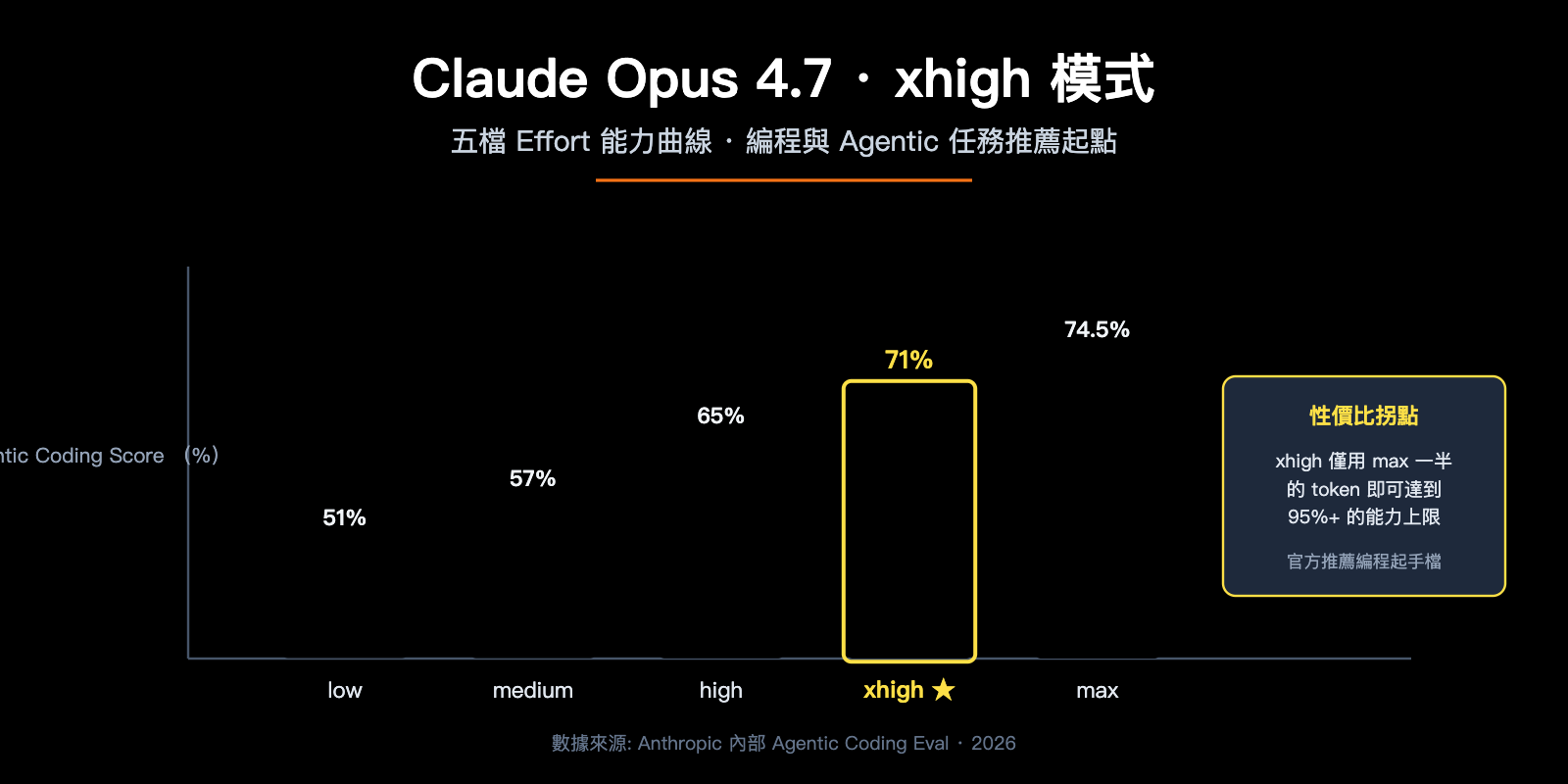
xhigh 的引入解決了一個真實的痛點:在 Opus 4.6 時代,開發者跑長程 Agentic 編程任務時只能在 high 與 max 之間二選一。high 在複雜多步推理上偶爾「火候不足」,而 max 又會導致 token 飆升、成本失控。Anthropic 在 4.7 版本中專門設計了一檔「長程偏向」的 effort,讓模型在多輪工具調用、長上下文檢索、跨會話記憶等場景下仍保持高質量輸出,同時把 token 消耗控制在可接受範圍。
根據官方公開的內部 Agentic Coding 評測曲線,Opus 4.7 在 xhigh 等級下的得分約爲 71%(消耗約 100k tokens),而 max 等級僅提升到 ~74.5%(但消耗超過 200k tokens)。換句話說,從 xhigh 升到 max 平均只能多拿 3 個百分點,卻要付出近一倍的 token 成本。這是 xhigh 成爲「官方推薦起點」的核心原因。
Claude Opus 4.7 xhigh模式 五檔對比
下表對照了 Opus 4.7 全部五檔 effort 的官方定位和實戰建議:
| Effort 等級 | 定位描述 | 推薦場景 | 相對 token 消耗 |
|---|---|---|---|
low |
最高效率檔,明顯減少推理 | 短任務、子 Agent、分類任務 | 基準 1x |
medium |
平衡檔,減少成本同時保留質量 | 常規聊天、單步代碼生成 | 約 1.3x |
high |
API 默認檔,複雜推理與編程 | 一般智能敏感任務 | 約 2x |
xhigh |
長程編程與 Agentic 推薦起點 | Claude Code、多輪工具調用 | 約 3x |
max |
絕對能力上限,無 token 約束 | 真正前沿難題、研究類任務 | 約 6x+ |
🎯 選擇建議: 對於編程類任務,建議直接從 xhigh 起步評測,再根據效果決定是否上調到 max 或下調到 high。可通過 API易 apiyi.com 平臺直接調用
claude-opus-4-7模型快速對比不同 effort 的效果差異,平臺提供統一的 OpenAI 兼容接口,便於切換 effort 參數測試。
Claude Opus 4.7 xhigh模式 與 high 的關鍵區別
許多人會問:既然 high 已經是默認檔,爲什麼還需要 xhigh?關鍵差異有三點:
第一,推理深度不同。Opus 4.7 在 xhigh 下會更頻繁地觸發 adaptive thinking 的深度模式,模型會主動反思中間結果、回溯失敗的工具調用路徑。而 high 傾向於「一次走通」,遇到中等複雜度任務可能跳過深度思考。
第二,工具調用策略不同。xhigh 鼓勵模型多發起探索性工具調用(例如 grep、讀多個文件、追溯依賴),而 high 傾向於減少調用次數以節省 token。在大型代碼庫重構、跨文件 bug 定位等場景,xhigh 的探索能力優勢明顯。
第三,長程任務表現不同。對於運行時間超過 30 分鐘、token 預算達到百萬級的 Agentic 任務,xhigh 的穩定性顯著高於 high,模型不容易在中段「走偏」或提前終止。
Claude Opus 4.7 xhigh模式 快速上手
極簡調用示例
下面是通過 OpenAI 兼容接口調用 Opus 4.7 xhigh 模式的最小代碼(10 行內):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "幫我重構這段Python代碼:..."}],
extra_body={"effort": "xhigh"}
)
print(response.choices[0].message.content)
查看 Anthropic 原生 SDK 完整調用示例
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=64000,
messages=[
{
"role": "user",
"content": "請分析這個倉庫的代碼結構,並提出三處可優化的設計模式問題。"
}
],
output_config={
"effort": "xhigh"
},
thinking={
"type": "adaptive",
"display": "summarized"
}
)
# 4.7 默認隱藏 thinking 內容,需要顯式 opt-in
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "thinking":
print(f"[思考摘要]: {block.thinking}")
關鍵參數說明:
model: 必須使用claude-opus-4-7,舊版claude-opus-4-6不支持 xhighoutput_config.effort: 設置爲"xhigh"max_tokens: xhigh 推薦至少 64k,給模型留足思考與工具調用空間thinking.display: 設置"summarized"可看到推理摘要,"omitted"爲默認隱藏
建議: xhigh 模式下建議把
max_tokens提高到 64k 以上,否則模型可能因輸出空間不足而提前截斷。可以在 API易 apiyi.com 註冊賬號免費測試 Opus 4.7 xhigh 的實際效果,平臺已經預置好與 Anthropic 一致的 effort 參數透傳。
Claude Opus 4.7 xhigh模式 在 Claude Code 中的使用
Claude Code 默認值變化
Claude Code 在升級 Opus 4.7 後,把內置默認 effort 從 high 調整爲 xhigh。也就是說,如果你只是輸入 claude 命令進入交互模式,背後的請求已經自動啓用了 xhigh。這一變化帶來的最直接體感:
- 複雜任務的解決率明顯提升(特別是跨多文件的 bug 修復)
- 單次會話的 token 消耗會比 4.6 時代翻倍以上
- 長任務(如全倉庫重構)成功率從約 55% 提升到約 71%
手動指定 effort 等級
如果想在 Claude Code 中顯式控制 effort,可以在配置文件中調整:
{
"model": "claude-opus-4-7",
"effort": "xhigh",
"max_tokens": 96000,
"thinking_display": "summarized"
}
不同任務類型的推薦 effort:
| 任務類型 | 推薦 effort | 原因 |
|---|---|---|
| 單文件 bug 修復 | high 或 xhigh |
需要紮實推理但不需要廣泛探索 |
| 跨文件重構 | xhigh |
需要多輪 grep、讀文件、依賴追蹤 |
| 全倉庫設計審查 | xhigh 或 max |
長程多步推理,質量優先 |
| 簡單代碼格式化 | low |
模式化任務,節省 token |
| 文檔生成 | medium |
平衡質量與速度 |
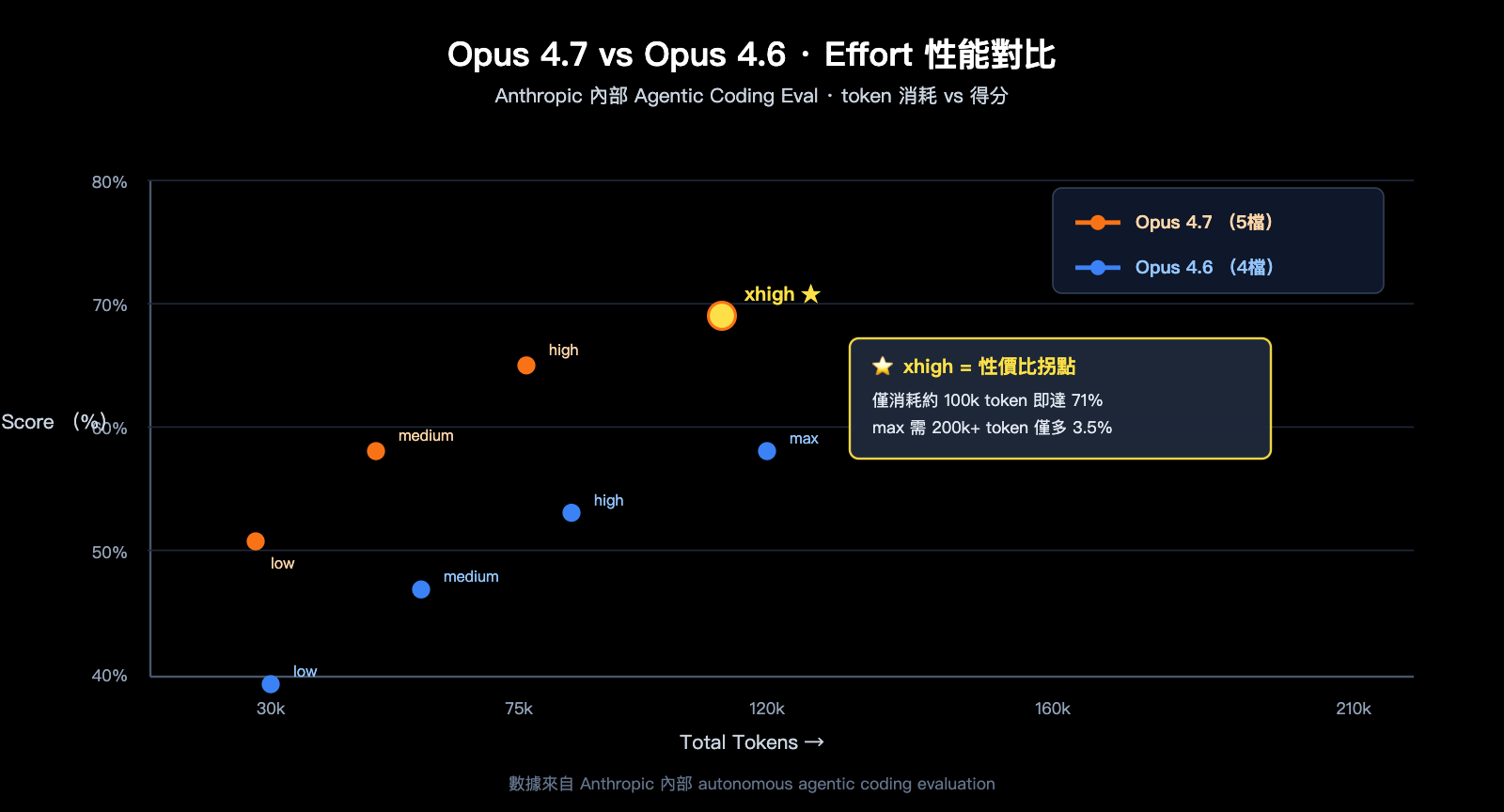
數據說明: 上圖基於 Anthropic 公開的內部 Agentic Coding Eval 數據繪製,可通過 API易 apiyi.com 平臺用相同的 prompt 進行復現驗證。
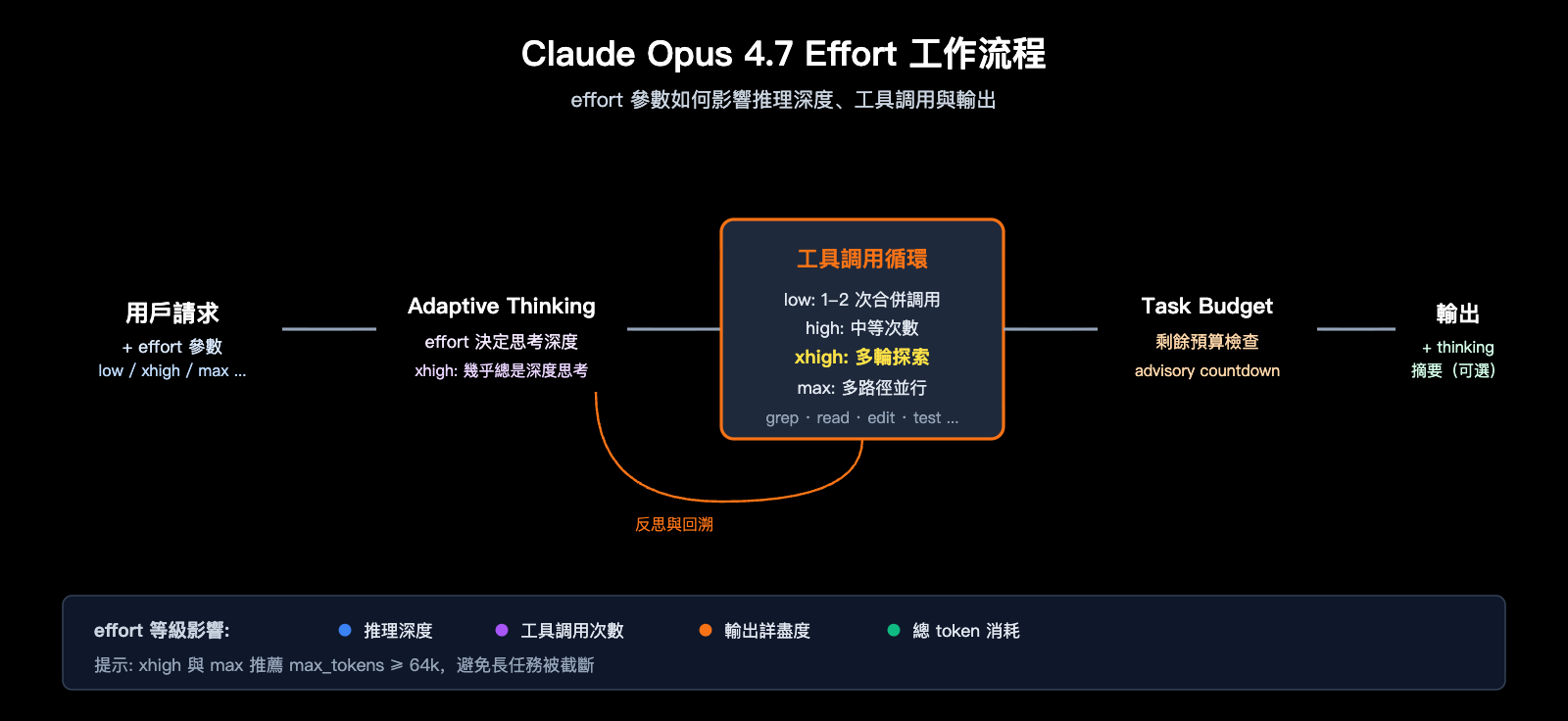
Claude Opus 4.7 xhigh模式 與配套機制
與 adaptive thinking 的協同
Opus 4.7 移除了舊版的 budget_tokens 思考預算參數,唯一支持的思考模式是 adaptive thinking。effort 參數實際上成了「思考深度」的主控旋鈕:
| Effort | adaptive thinking 行爲 |
|---|---|
low |
多數請求跳過思考,直接輸出 |
medium |
僅在複雜問題上觸發思考 |
high |
幾乎總是思考,深度中等 |
xhigh |
幾乎總是深度思考,會反思和回溯 |
max |
深度思考 + 多路徑探索 |
注意:4.7 默認隱藏 thinking 內容(response stream 中 thinking 字段爲空)。如果你的應用需要給用戶展示思考過程,必須顯式設置 thinking.display = "summarized",否則用戶會看到一段較長的「無響應空窗期」。
與 task budgets 配合
Opus 4.7 還引入了 beta 階段的 task_budget 參數,配合 xhigh 使用尤其有用:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "xhigh",
"task_budget": {"type": "tokens", "total": 200000}
},
messages=[{"role": "user", "content": "重構整個用戶認證模塊"}],
betas=["task-budgets-2026-03-13"]
)
task_budget 是「軟建議」(advisory),模型會看到剩餘預算並據此優先排序工作;max_tokens 是「硬上限」,超過即截斷。兩者配合,xhigh 模式可以在長程任務中自我節制,避免 token 失控。
xhigh 與 1M 上下文窗口
Opus 4.7 支持 1M token 上下文窗口,且無長上下文溢價。xhigh 模式下,模型可以在 1M context 內執行復雜的代碼庫理解任務而不必頻繁壓縮歷史。這意味着:
- 可以一次性載入數十萬行代碼進行整體分析
- 跨會話的 memory 工具能穩定保留上下文
- 減少了上下文壓縮帶來的信息損失
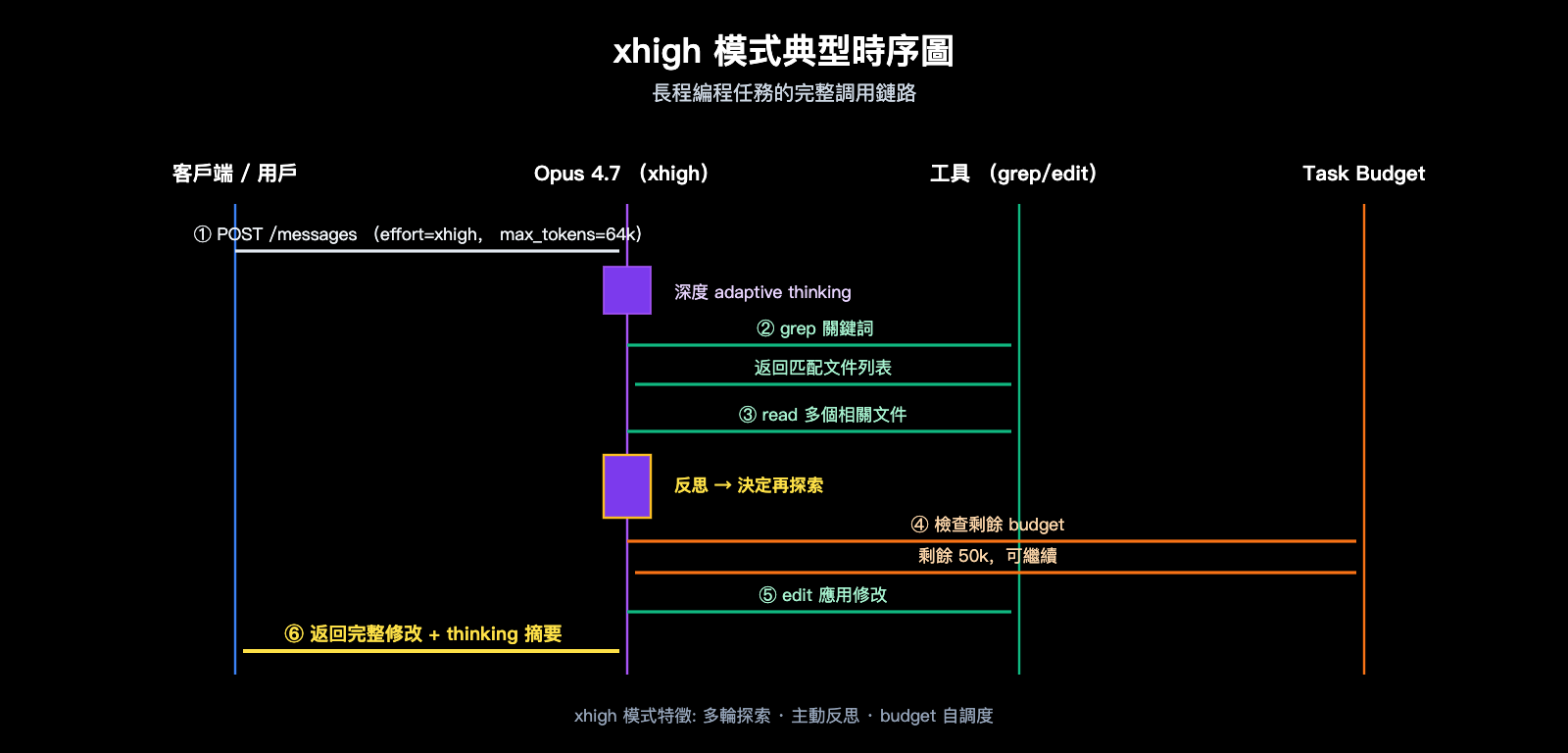
Claude Opus 4.7 xhigh模式 實戰最佳實踐
推薦 1:編程任務從 xhigh 起步
Anthropic 官方文檔明確寫道:「Start with xhigh for coding and agentic use cases」。這是因爲編程任務通常涉及多文件讀取、依賴分析、測試運行等多輪工具調用,xhigh 在這些場景下的探索能力比 high 強得多。
如果你之前在 Opus 4.6 上習慣使用 high 作爲編程默認值,遷移到 4.7 時建議直接切到 xhigh,再根據實際效果決定是否回調。
推薦 2:max_tokens 至少設到 64k
xhigh 與 max 都需要充足的輸出空間。官方建議從 64k 起步,根據任務複雜度向上調整。如果你的 max_tokens 仍停留在 4096,xhigh 會在長任務中頻繁截斷,體驗會比 high 還差。
推薦 3:開啓 thinking 摘要
thinking = {
"type": "adaptive",
"display": "summarized"
}
雖然 4.7 默認隱藏 thinking,但在調試與產品化場景中開啓 summarized 顯示能讓用戶感知到模型在工作,避免「看起來卡住了」的體驗問題。
推薦 4:根據任務複雜度動態選擇
不要全程用同一個 effort 跑所有請求。一個推薦的策略:
def pick_effort(task_type: str, complexity: str) -> str:
if task_type == "classification" or complexity == "trivial":
return "low"
elif task_type == "chat" and complexity == "simple":
return "medium"
elif task_type == "coding" and complexity == "moderate":
return "high"
elif task_type == "coding" and complexity in ("complex", "agentic"):
return "xhigh"
elif task_type == "research" and complexity == "frontier":
return "max"
return "high"
優化建議: 通過 API易 apiyi.com 接入 Opus 4.7 時,可以在請求層根據業務標籤動態切換 effort,結合統一的用量統計儀表盤觀察不同檔位的成本效益比。
推薦 5:注意 tokenizer 變化
Opus 4.7 使用了新的 tokenizer,相同文本可能比 4.6 多消耗 1.0~1.35 倍 token。在做成本預估時,記得在 4.6 的基礎上預留 35% 的 token buffer,否則可能出現「計費比預期高」的情況。
Claude Opus 4.7 xhigh模式 常見誤區
誤區 1:xhigh 永遠比 high 好
不一定。在簡單的單輪問答、結構化輸出(如 JSON 提取)任務中,xhigh 可能引發「過度推理」,反而拖慢響應速度且不提升質量。這類任務應該使用 medium 或 low。
誤區 2:max 永遠是最強的
雖然 max 在評測分數上確實最高,但提升有限(約 3 個百分點)而成本翻倍。Anthropic 官方建議:「Reserve max for genuinely frontier problems」。日常編程任務用 xhigh 已經足夠,盲目用 max 是典型的資源浪費。
誤區 3:可以繼續用 budget_tokens
Opus 4.7 已經移除了 thinking.budget_tokens 參數,傳入會返回 400 錯誤。所有思考深度控制必須通過 effort 參數完成。
誤區 4:xhigh 在 Sonnet 4.6 也能用
xhigh 是 Opus 4.7 專屬。Sonnet 4.6 的 effort 等級僅支持 low/medium/high/max 四檔,調用 xhigh 會被拒絕。
| 模型 | 支持的 effort 等級 |
|---|---|
| Claude Opus 4.7 | low / medium / high / xhigh / max |
| Claude Opus 4.6 | low / medium / high / max |
| Claude Sonnet 4.6 | low / medium / high / max |
| Claude Opus 4.5 | low / medium / high |
常見問題
Q1: xhigh 比 high 貴多少?什麼情況下值得?
根據官方曲線,xhigh 的 token 消耗約爲 high 的 1.5 倍左右(具體取決於任務複雜度),但在 Agentic Coding 評測上提升約 5-6 個百分點。對於跨文件重構、長程任務、多輪工具調用場景,這個性價比是值得的。但對於單步代碼生成、文檔撰寫等任務,high 已經足夠。
Q2: 我用 OpenAI 兼容接口怎麼傳 effort 參數?
OpenAI SDK 默認不識別 effort,需要通過 extra_body 字段透傳。例如:
client.chat.completions.create(
model="claude-opus-4-7",
messages=[...],
extra_body={"effort": "xhigh"}
)
如果使用 API易 apiyi.com 這類聚合平臺,請確認平臺已經支持 effort 參數透傳(API易已經支持)。
Q3: xhigh 模式下響應延遲會不會很慢?
會比 high 慢約 50-80%,因爲模型需要更深的思考和更多的工具調用。但對於長程 Agentic 任務,整體完成時間反而可能縮短,因爲減少了人工糾錯和重試次數。如果對延遲敏感,可以開啓 thinking 摘要 (display: "summarized") 讓用戶感知進度。
Q4: 如何快速測試 Opus 4.7 xhigh 的效果?
推薦使用支持 effort 參數透傳的聚合平臺快速對比:
- 訪問 API易 apiyi.com 註冊賬號
- 選擇
claude-opus-4-7模型 - 用同一個 prompt 分別測試 high / xhigh / max 三檔
- 對比輸出質量、token 消耗、響應延遲
通過實際對比,可以快速找到最適合你業務的 effort 配置。
Q5: 4.6 升級到 4.7 還需要改什麼代碼?
除了添加 effort: xhigh 之外,還需注意幾個 breaking change:
- 移除
thinking.budget_tokens,改用thinking.type: "adaptive" - 移除
temperature/top_p/top_k(設置非默認值會報 400) - thinking 內容默認隱藏,需 opt-in 設置
display: "summarized" - max_tokens 建議提高到 64k 以上
總結
Claude Opus 4.7 xhigh 模式的核心要點:
- 定位精準: 介於 high 與 max 之間,專爲長程編程與 Agentic 任務設計
- 性價比拐點: 比 high 顯著強,比 max 顯著省,是官方推薦的編程起手檔
- 配套完善: 與 adaptive thinking、task budgets、1M 上下文協同工作
- 專屬 4.7: 僅
claude-opus-4-7支持,4.6 / Sonnet 4.6 均無此檔 - 使用門檻低: 只需在
output_config.effort設置"xhigh"即可啓用
對於希望升級到 Opus 4.7 的開發者,建議從 xhigh 起步評測,搭配 64k+ 的 max_tokens 與 adaptive thinking,在大多數編程任務上你會立刻感受到 4.7 的能力躍遷。
推薦通過 API易 apiyi.com 快速接入 Claude Opus 4.7 xhigh 模式,平臺已支持 effort 參數透傳與 1M 上下文調用,提供免費測試額度,便於橫向對比 4.7 與 4.6 在你業務場景下的真實表現。
📚 參考資料
-
Anthropic 官方 effort 參數文檔: 詳細說明五檔 effort 的定義與推薦用法
- 鏈接:
platform.claude.com/docs/en/build-with-claude/effort - 說明: xhigh 等級的官方權威定義和最佳實踐
- 鏈接:
-
What's new in Claude Opus 4.7: 4.7 版本完整變更清單
- 鏈接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-6 - 說明: 包含 xhigh 引入背景、breaking changes 和遷移建議
- 鏈接:
-
Adaptive Thinking 文檔: 4.7 唯一支持的思考模式
- 鏈接:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 說明: 理解 effort 與 thinking 協同工作機制的關鍵
- 鏈接:
-
Task Budgets Beta 文檔: 與 xhigh 配合使用的預算控制
- 鏈接:
platform.claude.com/docs/en/build-with-claude/task-budgets - 說明: 長程任務中控制 token 消耗的實用工具
- 鏈接:
-
API易 Claude 模型接入文檔: 國內開發者快速上手指南
- 鏈接:
help.apiyi.com - 說明: 包含 effort 參數透傳、1M 上下文調用等實用配置
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論 xhigh 模式在你實際場景的表現,更多 Claude Opus 4.7 配置技巧可訪問 API易 docs.apiyi.com 文檔中心





