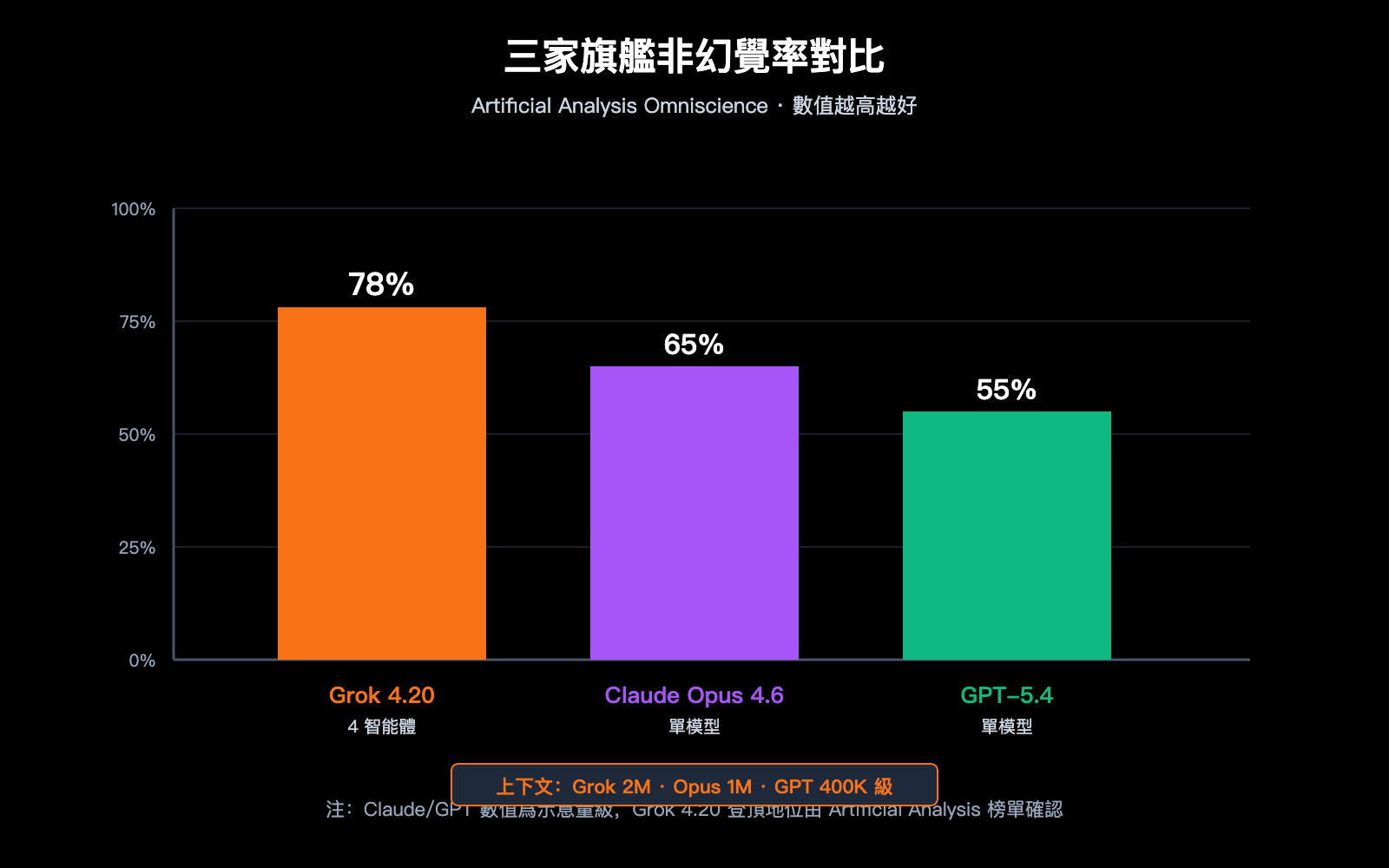
2026 年 2 月 17 日,xAI 正式發佈 Grok 4.20 Beta,以一種非常反常規的思路在"非幻覺率"這個長期被 Claude 與 GPT 系列霸佔的榜單上實現反超:它並沒有單純堆參數或堆推理步數,而是讓 4 個專業化智能體(Grok / Harper / Benjamin / Lucas)在每次複雜查詢中並行工作、互相辯論、最後合成答案。獨立第三方 Artificial Analysis Omniscience 測評給出 78% 非幻覺率,xAI 官方稱綜合測試可達 83%,在公開測評中超過 Claude Opus 4.6 與 GPT-5.4。同時 Grok 4.20 將上下文窗口推進到 2M token,在超長文檔與長週期代理任務上取得顯著優勢。
背後的算力支撐也在升級:xAI 的 Colossus 2 超算集羣 正逐步擴容至 1.5GW 級別,爲 Grok 5 及後續多智能體規模化做準備。本文基於英文一手資料系統梳理 Grok 4.20 的架構設計、關鍵跑分、Heavy 模式、API 上線情況以及典型落地場景,幫助你在 10 分鐘內判斷是否值得切換。
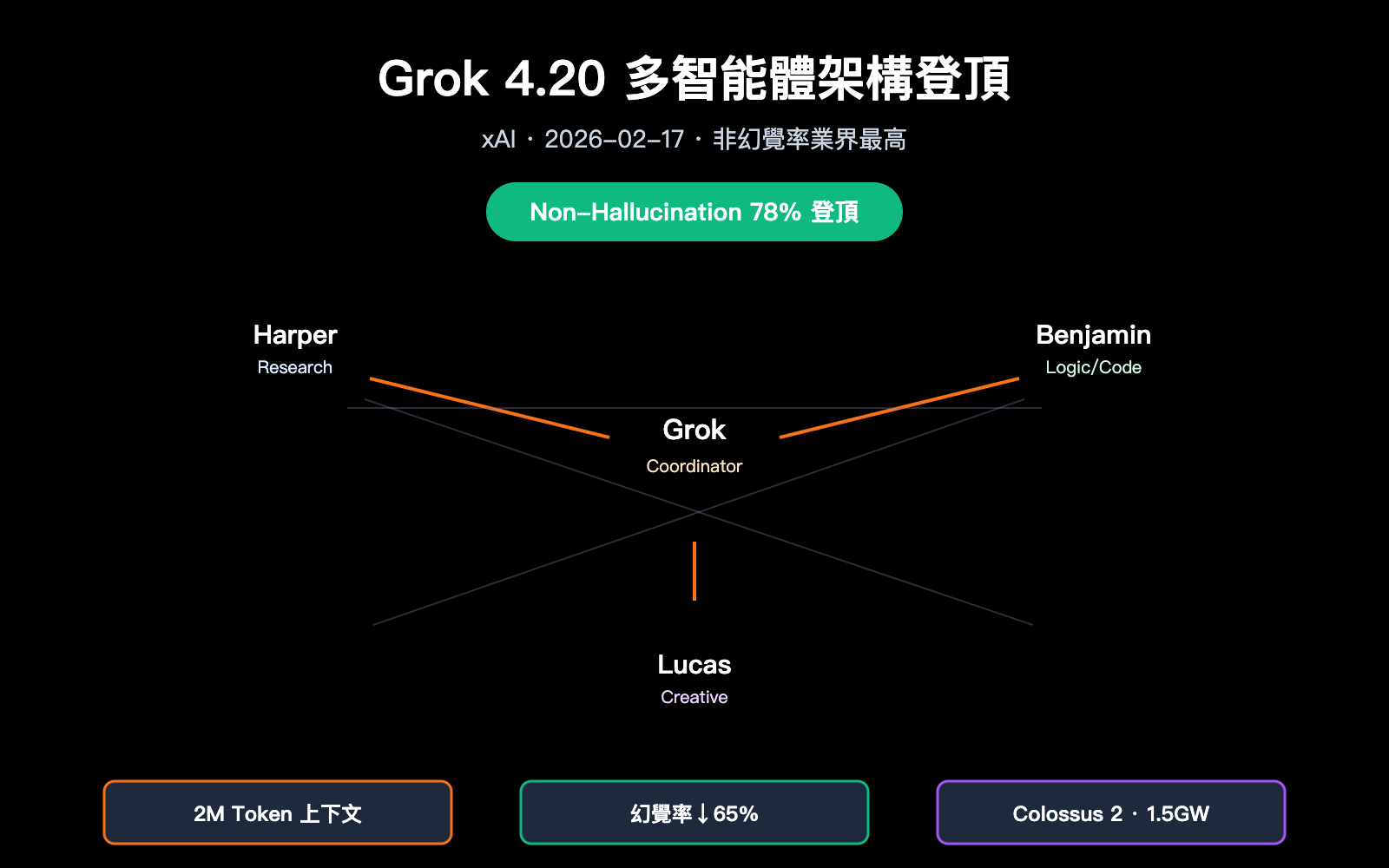
Grok 4.20 多智能體架構的核心突破
相比"單個更大模型 + 更深推理鏈"的主流思路,Grok 4.20 選擇了一條**羣體智能(Swarm-style Reasoning)**路線。
4 個智能體的分工
| 角色 | 名字 | 職責 | 關鍵能力 |
|---|---|---|---|
| 協調者 | Grok | 任務分解、辯論裁決、最終合成 | Orchestration / Arbiter |
| 研究員 | Harper | 實時 Web 搜索 + X Firehose 數據檢索 | 事實補全、時效校驗 |
| 邏輯員 | Benjamin | 數學、代碼、結構化推理與驗證 | 代碼執行校驗、形式化推理 |
| 發散員 | Lucas | 創意輸出、方案擴展、語言潤色 | 多候選生成、答案優化 |
每次複雜查詢進入模型後,Harper 先拉取實時上下文,Benjamin 同步進行邏輯與代碼推理,Lucas 輸出多組候選答案,最後由 Grok 協調辯論併合成終稿。這套機制把"一個模型一次前向推理"升級爲"四個專業角色的內部多輪協商"。
爲什麼能降低幻覺
傳統 LLM 的幻覺主要來自:模型對自己"不知道的事情"缺乏自我校驗;Grok 4.20 通過 跨智能體交叉驗證 形成自然的事實校對機制:
- Harper 發現 Benjamin 的推斷與最新網頁/X 實時數據相矛盾 → 打回;
- Benjamin 發現 Lucas 的創意方案數學不成立 → 否決;
- Grok 作爲協調者只會輸出三方都無反對的結論。
官方披露:這種機制把原本約 12% 的單模型幻覺率壓到約 4.2%,相當於 65% 的幻覺下降。
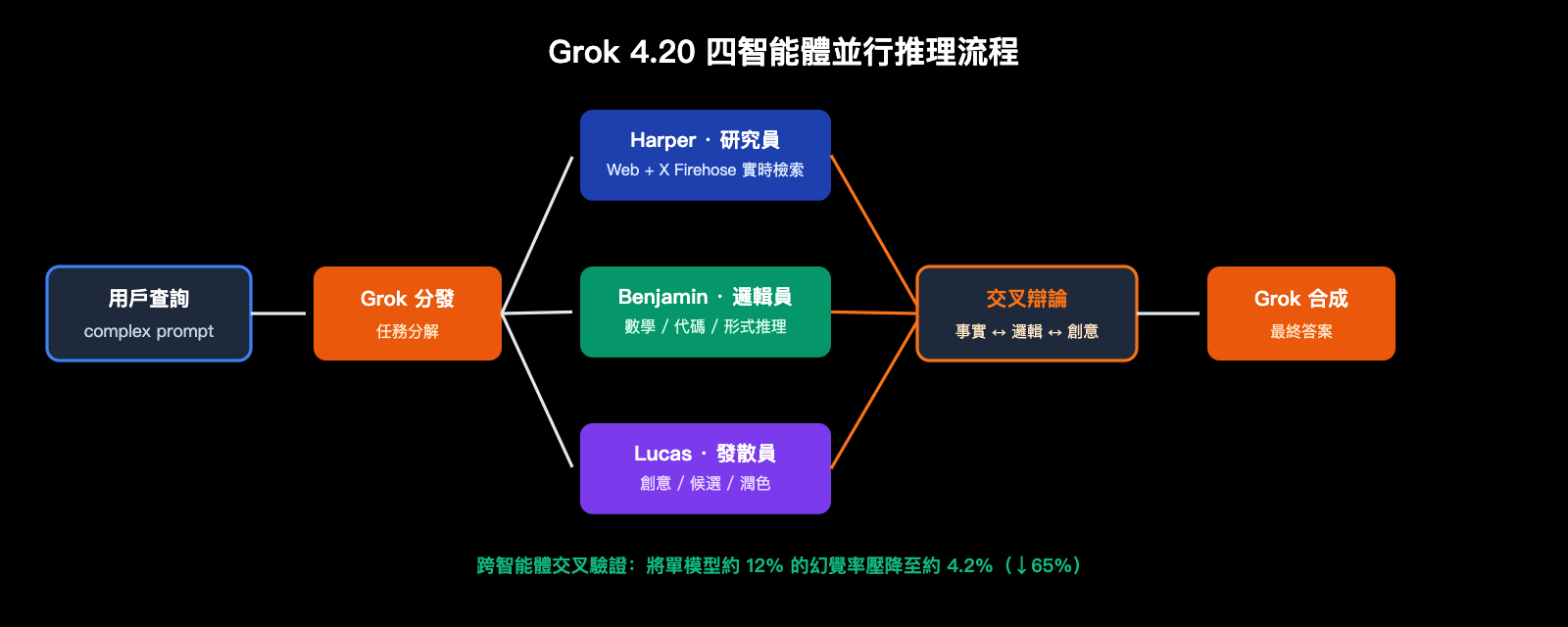
🎯 架構理解提示:多智能體不是"4 次單模型串聯",而是一次前向中 4 路並行+辯論。想快速體驗差異的團隊,可以通過 API易 apiyi.com 直接調用 Grok 4.20,與其他模型並列跑同一批 prompt,對比幻覺率差異。
Grok 4.20 關鍵指標與行業對比
跑分的含金量很大程度上取決於評測集,下面將自報告與獨立測評分開列出。
公開跑分概覽
| 指標 | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience(非幻覺率) | 78%(登頂) | 次席 | 第三 |
| xAI 自測綜合非幻覺率 | 約 83% | — | — |
| 幻覺率(相對 Grok 4.1 基線) | 4.22%(↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| 上下文窗口 | 2,000,000 tokens | 200K(1M 擴展) | 400K 級 |
| 架構 | 4 智能體並行(Heavy 模式 16) | 單模型 | 單模型 |
Heavy 模式:4 → 16 智能體擴展
除默認 4 智能體配置,Grok 4.20 還提供 Heavy 模式:在需要更強推理深度時,智能體數量從 4 擴展到 16,覆蓋更廣的辯論空間與更高維的證據鏈交叉驗證。代價是單次請求成本與延遲上升,適合"對正確率苛刻、成本不敏感"的場景(投研、合規審計、安全分析等)。
模式與場景速查
| 模式 | 智能體數 | 適用場景 | 特徵 |
|---|---|---|---|
| Grok 4.20 非推理模式 | 1 | 聊天、問答 | 低延遲、低成本 |
| Grok 4.20 推理模式 | 1 + CoT | 數學、代碼 | 中等成本 |
| Grok 4.20 多智能體(默認) | 4 | 複雜查詢、事實覈驗 | 幻覺顯著下降 |
| Grok 4.20 Heavy | 16 | 專業研究、合規審計 | 最高正確率 |
🎯 跑分閱讀建議:同一模型的自測和第三方測評可能有 5~10 個百分點的落差,選型時優先參考 Artificial Analysis 等獨立基準。通過 API易 apiyi.com 在同一套 prompt 上對比 Grok 4.20 / Opus 4.6 / GPT-5.4,可以更真實地看到業務語境下的表現。
Grok 4.20 的 2M 上下文與 Colossus 2 算力底座
架構創新需要硬件支撐,這次 Grok 4.20 的兩個底層升級同樣值得關注。
2M token 上下文的價值
Grok 4.20 把上下文窗口拉到 2,000,000 tokens,這意味着:
- 整本書級文檔 可以一次性塞入 prompt,無需手工拆分;
- 長對話 / 長代理會話 可保持完整歷史;
- 多文件代碼審查 可覆蓋中型 monorepo;
- 與 Harper 的實時檢索能力疊加,形成"長記憶 + 實時事實"的組合優勢。
Colossus 2 超算集羣升級到 1.5GW
xAI 爲 Grok 系列打造的 Colossus 2 超算集羣正在升級至 1.5GW 級 算力規模,這一基礎設施目標瞄準 Grok 5 與更大規模多智能體羣。對開發者的直接影響:
- 推理可用性與併發上限更高;
- 新版本模型迭代速度加快;
- Grok 4.20 已經能承載"16 智能體 × 2M 上下文"的 Heavy 模式,對應的算力基線就來自這一集羣。

快速上手:Grok 4.20 API 調用與 API易接入
基礎調用示例(OpenAI 兼容)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# 默認 4 智能體多智能體模式
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a factual research assistant."},
{"role": "user", "content": "總結一下 2026 年 Q1 全球 AI 芯片出貨量數據,並列出關鍵來源。"},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
調用 Heavy 模式(16 智能體)
# Heavy 模式適合高正確率場景,延遲與成本更高
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "對這份 800 頁合規文檔做風險要點彙總與交叉引用覈驗。"},
],
max_tokens=16384,
)
📎 展開查看 2M 超長上下文調用示例
# 2M 上下文可一次性喫下整本書 / 整個倉庫
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # 可達百萬級 token
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a senior code reviewer."},
{"role": "user", "content": f"以下是整個倉庫代碼,請找出最嚴重的 5 個問題:\n\n{repo_text}"},
],
max_tokens=8192,
)
API易平臺接入優勢
Grok 4.20 的 API 已在 API易 apiyi.com 正式上線,價格與官網一致,同時提供以下差異化:
- 充值活動最低 85 折,長期使用成本低於直連;
- 不限併發,適合 Heavy 模式批量跑任務;
- OpenAI 兼容接口,無需改造現有代碼,僅替換
base_url與model字段即可; - 與 Claude / GPT 等其他模型同賬號計費,便於多模型並行 A/B。
🎯 接入建議:Heavy 模式單次 token 消耗是普通模式的數倍,不限併發的優勢在這種場景最明顯。新接入團隊建議先在 API易 apiyi.com 用非推理模式跑通基本邏輯,再把關鍵鏈路切到多智能體或 Heavy 模式。
Grok 4.20 的典型應用場景
最適合 Grok 4.20 的 5 類工作負載
| 場景 | 推薦模式 | 關鍵收益 |
|---|---|---|
| 新聞/研報事實覈驗 | 多智能體(默認) | Harper 實時檢索 + 跨智能體交叉驗證 |
| 投研與合規審查 | Heavy | 16 智能體降低關鍵事實出錯率 |
| 整本書 / 整庫級長文檔分析 | 多智能體 + 2M | 一次性喫入,無須切分 |
| 多步 Agent 工作流 | 多智能體 | 自帶協調者,減少外層工程 |
| 實時輿情 / 社媒監控 | 多智能體 | Harper 原生對接 X Firehose |
不推薦的場景
- 毫秒級 IDE 補全:多智能體並行帶來的延遲不適合 Tab 級交互;
- 極端低成本批處理:Heavy 模式價格高,改用非推理模式或 Haiku 級模型更划算;
- 需要嚴格本地化部署:Grok 4.20 當前以 API 形式提供,無自託管權重。
🎯 遷移路徑建議:將"高幻覺敏感度"的鏈路(合規、醫療、金融研究等)優先切到 Grok 4.20 多智能體模式,通過 API易 apiyi.com 的計費面板按鏈路拆分統計,可量化幻覺下降帶來的業務增益。
常見問題 FAQ
Q1:非幻覺率 78% 與 83% 哪個更可信?
78% 來自獨立第三方 Artificial Analysis Omniscience 測試集,是目前最具公信力的數據;83% 是 xAI 在更廣測試集上的自測結果。選型建議以獨立基準爲主、官方數據爲輔。兩者的一致結論是:Grok 4.20 在非幻覺維度已超越 Claude Opus 4.6 與 GPT-5.4。
Q2:4 個智能體是不是就是調 4 次 API?
不是。多智能體調度在 xAI 服務端內部完成,對用戶只暴露一次 API 調用。token 計費會高於單智能體模式,但遠低於"自己在客戶端串 4 次請求"的方案,且延遲更低。
Q3:Heavy 模式和普通多智能體差多少?
Heavy 把並行智能體從 4 擴到 16,在複雜推理、長證據鏈任務上正確率進一步提升,代價是單請求成本與延遲大幅上升。建議僅在"每錯一條損失很大"的場景啓用,例如合規、醫學、投研。通過 API易 apiyi.com 按請求路由到不同模式可做到"按價值用算力"。
Q4:2M 上下文真的可以喫滿嗎?
可以。Grok 4.20 宣稱的是實際可用上下文,不是理論上限。但同樣要注意:上下文越長、每 token 成本與延遲線性上升;超大上下文建議結合上下文壓縮 + 多智能體的 Harper 檢索一起使用。
Q5:API易上線和官網有什麼差別?
價格與官網一致,充值活動可做到 85 折,關鍵優勢是不限併發,適合 Heavy 模式批量調用。接口保持 OpenAI schema 兼容,代碼層只需把 base_url 指向 apiyi.com 即可。
Q6:Grok 4.20 會取代 Grok 5 嗎?
不會。Grok 5 仍是 xAI 的下一代主力目標,由 Colossus 2 1.5GW 集羣支撐。Grok 4.20 的定位更像是"把多智能體範式先在 4 代架構上跑通",爲 Grok 5 的規模化多智能體提供工程驗證。
總結:多智能體範式開始真正改變旗艦模型格局
Grok 4.20 帶來的不只是一次版本更新,而是旗艦模型競爭維度的變化:從"單模型更大、更深推理鏈"轉向"多角色羣體推理 + 實時證據校驗"。78% 的獨立非幻覺率與 2M 上下文疊加,意味着高風險業務(合規、投研、醫學、法律)第一次有了可以在通用 API 上獲得的"低幻覺首選"方案。
對開發者來說,落地的第一步不是替換全部模型,而是把最怕出錯的鏈路優先遷到 Grok 4.20 多智能體模式,把常規鏈路保留在成本更低的模型上,做成混合編排。行業趨勢上,Grok 5 與 Colossus 2 的 1.5GW 集羣會繼續放大這一優勢,早接入意味着更早積累多智能體調用經驗。
🎯 行動建議:Grok 4.20 API 已在 API易 apiyi.com 正式上線,價格與官網一致,充值活動 85 折,關鍵是不限併發,非常適合多智能體、Heavy 模式和 2M 上下文的大吞吐需求。用一段 OpenAI 兼容代碼即可接入,今天就把"最怕幻覺"的鏈路切過去。
— APIYI Team(API易 apiyi.com 技術團隊)