作者注:xAI 旗艦模型 Grok 4.20 Beta 持續迭代,幻覺率 78% 行業最低,原生 4 Agent 多智能體協作,200 萬 Token 上下文,支持語音對話和圖像視頻生成,本文深度分析核心能力和實際價值
Elon Musk 旗下的 xAI 在 2026 年初發布了 Grok 4.20 Beta,此後持續迭代優化。這款模型最獨特的標籤是"行業最低幻覺率"——在 Artificial Analysis Omniscience 測試中取得 78% 的非幻覺率,同時引入原生 4 Agent 多智能體架構和 200 萬 Token 上下文窗口。最新的 4 月更新進一步改進了指令跟隨、LaTeX 排版和圖像搜索觸發準確性。
核心價值: 5 分鐘瞭解 Grok 4.20 Beta 的核心能力、3 種模型變體的區別、多模態能力,以及它與 Claude/GPT 的定位差異。

Grok 4.20 Beta 核心信息速覽
| 信息項 | 詳情 |
|---|---|
| 發佈日期 | 2026 年 2 月 17 日(公測)/ 3 月 10 日(API) |
| 開發方 | xAI (Elon Musk) |
| 核心定位 | 高誠信度 + 多智能體 + 多模態旗艦 |
| 幻覺率 | 78% 非幻覺率(行業最高) |
| 上下文窗口 | 200 萬 Token(從 Grok 4 的 256K 提升) |
| 模型變體 | Reasoning / Non-Reasoning / Multi-Agent |
| 輸出速度 | 247.8 tok/s(推理模型中位數 68.5) |
| 定價 | 輸入 $2/MTok,輸出 $6/MTok |
| 多模態 | 文本/圖像/視頻/語音 輸入輸出 |
Grok 4.20 Beta 的市場定位
在 AI 大模型競爭格局中,Grok 4.20 Beta 選擇了一條差異化路線:不追求在所有評測上做到最高分,而是在誠信度(低幻覺)、速度和多智能體協作三個維度建立獨特優勢。
Artificial Analysis 智能指數評分 48 分,高於同價位模型中位數 31 分,但與 Claude Opus 4.5 和 GPT-5.4 的頂級評分仍有差距。xAI 的策略是——與其給你一個偶爾驚豔但經常出錯的模型,不如給你一個始終可靠的模型。
Grok 4.20 Beta 核心能力詳解
能力 1: 行業最低幻覺率
Grok 4.20 Beta 最突出的能力是幻覺控制:
| 評測 | Grok 4.20 | 行業平均 | 說明 |
|---|---|---|---|
| AA-Omniscience 非幻覺率 | 78% | ~60-70% | 行業最高 |
| 指令跟隨 | 頂級 | – | 嚴格提示詞遵循 |
| LaTeX 排版 | 持續優化 | – | 4 月更新改進 |
78% 的非幻覺率意味着 Grok 4.20 在回答事實性問題時,每 5 個回答中約有 4 個是準確的——這在所有已測試模型中是最高的。對於需要高度可靠性的場景(如醫療諮詢、法律分析、學術研究),低幻覺率可能比更高的"智能指數"更有實際價值。
4 月持續優化: 最新迭代進一步改進了指令跟隨能力和 LaTeX 數學公式排版,圖像搜索觸發的準確性也有提升。
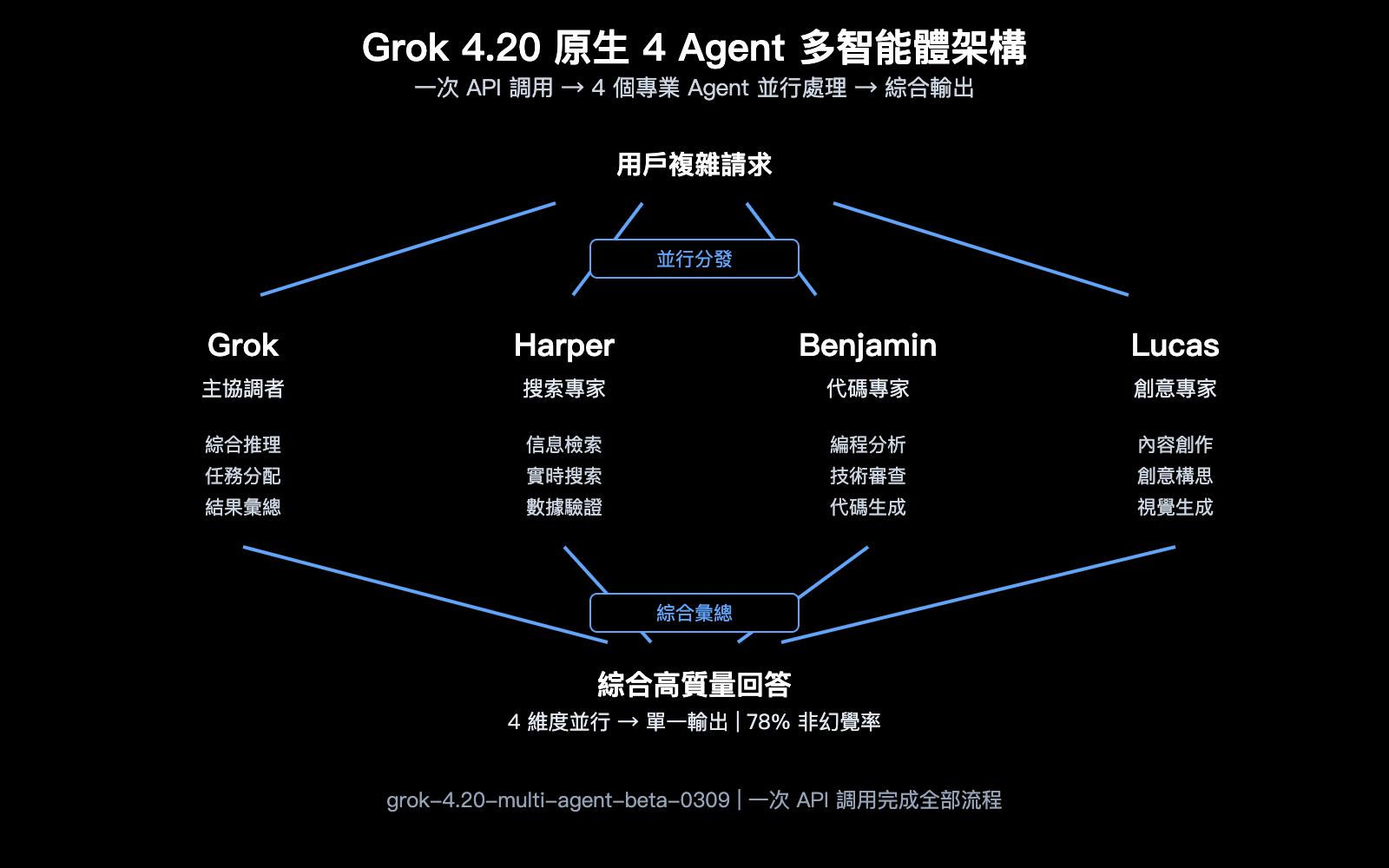
能力 2: 原生 4 Agent 多智能體架構
Grok 4.20 Beta 引入了業界首個原生多智能體 API——一次 API 調用,後臺有 4 個專業 Agent 並行處理:
| Agent 名稱 | 專長 | 角色 |
|---|---|---|
| Grok | 綜合推理和對話 | 主協調者 |
| Harper | 研究和信息檢索 | 搜索專家 |
| Benjamin | 編程和技術分析 | 代碼專家 |
| Lucas | 創意和內容生成 | 創意專家 |
當你通過 Multi-Agent API 發送一個複雜查詢時,4 個 Agent 會同時並行工作,各自發揮專長,最後由 Grok 綜合彙總。這種架構在處理需要多維度能力的複雜任務時效率更高。
能力 3: 200 萬 Token 上下文
Grok 4.20 的上下文窗口從前代 Grok 4 的 256K 直接跳升至 200 萬 Token——這是目前所有主流 API 模型中最長的:
| 模型 | 上下文窗口 | 對比 |
|---|---|---|
| Grok 4.20 Beta | 200 萬 Token | 行業最長 |
| GPT-5.4 (擴展) | 100 萬 Token | Grok 2 倍 |
| Claude Opus 4.5 | 200K Token | Grok 10 倍 |
| Gemini 2.5 Pro | 100 萬 Token | Grok 2 倍 |
200 萬 Token 約等於 150 萬中文字或 300 萬英文單詞,足以容納一整本長篇小說或一個大型代碼倉庫。
🎯 開發者建議: Grok 4.20 Beta 在幻覺控制和上下文長度上有獨特優勢。通過 API易 apiyi.com 可以同時接入 Grok 4.20 和 Claude、GPT,在你的實際任務中對比不同模型的可靠性和準確性。
Grok 4.20 Beta 3 種模型變體
Grok 4.20 模型家族
xAI 發佈了 3 種不同的 Grok 4.20 變體,定價完全相同但能力各異:
| 變體 | 模型 ID | 核心能力 | 適用場景 |
|---|---|---|---|
| Non-Reasoning | grok-4.20-beta-0309-non-reasoning | 快速直接回答 | 日常對話、簡單任務 |
| Reasoning | grok-4.20-beta-0309-reasoning | 深度推理鏈 | 複雜分析、數學 |
| Multi-Agent | grok-4.20-multi-agent-beta-0309 | 4 Agent 並行 | 複雜多維度任務 |
Grok 4.20 定價分析
| 定價項 | Grok 4.20 | Grok 4 (前代) | 變化 |
|---|---|---|---|
| 輸入 | $2/MTok | $3/MTok | 降 33% |
| 輸出 | $6/MTok | $15/MTok | 降 60% |
| 三個變體 | 價格相同 | – | 按需選擇 |
Grok 4.20 的定價非常有競爭力:輸入 $2、輸出 $6,比前代 Grok 4 降了 33-60%。與競品對比:GPT-5.4 標準版 $2.5/$15,Claude Opus 4.5 更貴。在同等價位的模型中,Grok 4.20 的幻覺率最低、速度最快(247.8 tok/s)。
Grok 4.20 Rapid Learning 快速學習架構
Grok 4.20 的一項獨特技術是 Rapid Learning(快速學習)架構:模型會基於真實用戶使用數據每週自動更新能力,無需手動發佈新版本。這意味着你使用的 Grok 4.20 會隨着時間持續變得更好——4 月的 Grok 4.20 已經比 2 月的版本更強。
💡 差異化優勢: Rapid Learning 是 Grok 獨有的——其他模型更新需要發佈新版本號,而 Grok 4.20 在同一版本內持續進化。這就是爲什麼"4 月持續迭代"對 Grok 用戶格外重要。
Grok 4.20 Beta 多模態能力
Grok 4.20 完整多模態矩陣
| 模態 | 輸入 | 輸出 | 說明 |
|---|---|---|---|
| 文本 | ✓ | ✓ | 核心能力 |
| 圖像 | ✓ | ✓ | Grok Imagine API |
| 視頻 | ✓ | ✓ | 端到端視頻生成 |
| 語音 | ✓ | ✓ | Grok Voice 低延遲 |
| 代碼 | ✓ | ✓ | Benjamin Agent 專長 |
| 搜索 | – | ✓ | 實時網絡搜索 |
Grok Voice 語音能力
Grok Voice 是 Grok 4.20 中最具差異化的多模態能力之一:
- 低延遲語音: 支持數十種語言的實時語音對話
- 工具調用: 語音模式下可觸發工具調用和搜索
- 實時數據: 語音對話中可訪問實時網絡數據
- Agent API: 可通過 API 集成到第三方應用
這使得 Grok 4.20 不僅是一個文字模型,更是一個可以"聽、說、看、搜"的全模態 AI 助手。
Grok Imagine 圖像與視頻生成
xAI 在 Grok 4.20 中推出了 Grok Imagine API——統一的端到端視頻和音頻生成套件。支持從文字描述生成圖片和視頻,圖像搜索觸發準確性在 4 月更新中得到進一步提升。

Grok 4.20 Beta 與競品對比
Grok 4.20 vs GPT-5.4 vs Claude Opus 4.5
| 對比維度 | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| 幻覺率 | 78% (最低) | ~65% | ~70% |
| 智能指數 | 48 | ~55+ | ~55+ |
| 上下文 | 200 萬 Token | 272K-1M | 200K |
| 輸出速度 | 247.8 tok/s | ~100 tok/s | ~80 tok/s |
| 輸入價格 | $2/MTok | $2.5/MTok | 更高 |
| 輸出價格 | $6/MTok | $15/MTok | 更高 |
| 多智能體 | 原生 4 Agent | 無 | 無 |
| 語音對話 | 原生支持 | 有限 | 無 |
| 電腦操控 | 無 | 原生支持 | 有限 |
| 編程評測 | 中上 | 頂級 | 頂級 |
Grok 4.20 的優勢領域: 幻覺控制、速度、定價、上下文長度、多智能體、語音
Grok 4.20 的劣勢領域: 純智能/推理評測、編程專項評測
選型建議: 如果你最看重回答的準確性和可靠性,Grok 4.20 是首選。如果你最看重編程能力和複雜推理,Claude/GPT 更強。
🚀 對比建議: 通過 API易 apiyi.com 可以同時接入 Grok 4.20、GPT-5.4 和 Claude,一個 API Key 在三大模型間自由切換,快速找到最適合你場景的模型。
Grok 4.20 Beta API 接入
通過 API易 快速接入
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Non-Reasoning 模式 (快速回答)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "解釋量子計算的基本原理"}]
)
print(response.choices[0].message.content)
查看 Reasoning 和 Multi-Agent 模式調用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Reasoning 模式 (深度推理)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "分析全球AI芯片供應鏈的風險點"}]
)
# Multi-Agent 模式 (4 Agent 並行)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "寫一篇關於量子計算商業化前景的研究報告"
}]
)
# 4 個 Agent (Grok/Harper/Benjamin/Lucas) 並行處理
print(response.choices[0].message.content)
💰 成本優勢: Grok 4.20 的 $2/$6 定價是當前旗艦模型中最低之一。通過 API易 apiyi.com 調用可以進一步優化成本,同時支持在 Grok、Claude、GPT、Gemini 之間按需切換。
常見問題
Q1: Grok 4.20 的三個變體該選哪個?
日常對話選 Non-Reasoning(最快),複雜分析選 Reasoning(更深入),多維度複雜任務選 Multi-Agent(4 Agent 並行)。三個變體定價相同($2/$6 MTok),可以根據任務自由切換。通過 API易 apiyi.com 一個 Key 即可調用全部變體。
Q2: Grok 4.20 的幻覺率最低意味着什麼?
78% 非幻覺率意味着在事實性回答中,Grok 比其他模型更不容易"編造"信息。對於需要高可靠性的場景(醫療、法律、學術、企業決策),這比更高的"智能指數"更有實際價值。但在創意寫作和頭腦風暴場景,適度的"幻覺"反而可能是優勢。
Q3: Grok 4.20 會繼續更新嗎?
會。Grok 4.20 採用 Rapid Learning 架構,基於用戶使用數據每週自動優化。4 月的更新已改進了指令跟隨、LaTeX 排版和圖像搜索。同一個模型 ID 下的能力會持續提升,無需等待新版本號。通過 API易 apiyi.com 調用時,你會自動享受到最新的優化。
總結
Grok 4.20 Beta 的核心價值判斷:
- 行業最低幻覺率: 78% 非幻覺率,在需要高可靠性的場景中具有獨特優勢
- 原生多智能體: 4 Agent(Grok/Harper/Benjamin/Lucas)並行協作,複雜任務效率更高
- 200 萬 Token 超長上下文: 主流 API 模型中最長,配合 247.8 tok/s 的速度優勢
- 持續進化: Rapid Learning 每週自動更新,4 月版本已強於 2 月首發
Grok 4.20 Beta 走了一條差異化路線——不追求全面最強,而是在誠信度、速度和多智能體三個維度做到業界領先。推薦通過 API易 apiyi.com 同時接入 Grok 4.20 和 Claude、GPT,一個 Key 在多模型間對比,找到最適合你場景的方案。
📚 參考資料
-
xAI 官方 Grok 4.20 動態: 最新更新和功能公告
- 鏈接:
x.ai/news - 說明: 包含 Grok 4.20 的持續迭代日誌和功能更新
- 鏈接:
-
Artificial Analysis – Grok 4.20 評測: 獨立第三方評測和數據
- 鏈接:
artificialanalysis.ai/models/grok-4-20 - 說明: 包含智能指數、幻覺率、速度和定價的詳細分析
- 鏈接:
-
Grok 4.20 多智能體詳解: 4 種模型變體的完整對比
- 鏈接:
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - 說明: 包含 Reasoning/Non-Reasoning/Multi-Agent 的詳細使用場景
- 鏈接:
-
Grok 4.20 Beta 全面解讀: 架構和功能深度分析
- 鏈接:
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - 說明: 包含 Rapid Learning 架構和多模態能力詳解
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區分享你使用 Grok 4.20 的體驗,更多 AI 模型接入資料可訪問 API易 docs.apiyi.com 文檔中心