作者注:详细介绍如何快速找到 Gemini API 状态页面,以及其他主流 AI API 提供商的状态监控页面,帮助开发者及时了解服务状态和故障信息。
在使用 Gemini API 开发应用时,遇到 API 调用失败、超时或异常 是常见情况。此时开发者第一反应是想查看官方状态页面,确认是自己代码问题还是服务端故障。然而,很多开发者发现 Gemini API 的状态页面并不容易找到,因为它并非独立服务,而是属于 Google Cloud Vertex AI 平台的一部分。
本文将详细介绍如何快速定位 Gemini API Status Page,以及其他主流 AI API 提供商的状态监控页面,帮助你在遇到问题时第一时间获取准确的服务状态信息。
核心价值:通过本文,你将掌握所有主流 AI API 提供商的状态页面地址和使用方法,了解如何通过 API易平台实现统一监控和智能切换,大幅提升应用的稳定性和可用性。

Gemini API Status Page 为什么难找?
Gemini API 作为 Google 最新的生成式 AI 模型,其服务架构与传统 API 有所不同:
服务架构特点
-
隶属于 Vertex AI 平台
- Gemini API 是 Google Cloud Vertex AI 平台的一部分
- 不是独立的 API 服务,而是 Vertex AI 的子产品
- 状态信息整合在 Google Cloud 整体监控体系中
-
多渠道访问方式
- Google AI Studio:面向个人开发者的轻量级接口
- Vertex AI:面向企业的完整云平台
- API易等第三方平台:提供中转和聚合服务
-
状态页面分散
- 没有专门的 "Gemini API Status" 独立页面
- 状态信息混合在 Vertex AI 产品列表中
- 需要在 Google Cloud Status 页面中查找
开发者常见困惑
| 困惑类型 | 具体表现 | 影响 |
|---|---|---|
| 查找困难 | 搜索 "Gemini API Status" 无直接结果 | 无法快速确认服务状态 |
| 信息分散 | 状态信息分散在多个 Vertex AI 产品中 | 需要逐个检查才能定位问题 |
| 更新延迟 | 官方状态页面更新可能有延迟 | 无法实时获取故障信息 |
| 缺乏细节 | 状态页面信息粗略,缺少具体错误 | 难以定位根本原因 |

Gemini API Status Page 官方地址
✅ 正确地址
Gemini API 的官方状态页面 位于:
Google Cloud Status
🔗 https://status.cloud.google.com/
📍 如何在页面中找到 Gemini API 状态
进入 Google Cloud Status 页面后,按照以下步骤查找:
步骤 1:定位 Vertex AI 产品组
在产品列表中找到 "Vertex AI" 相关产品组,包括:
- Vertex AI Gemini API – 这是核心!
- Vertex AI Model Garden
- Vertex AI AutoML
- Vertex AI Feature Store
- Vertex AI Matching Engine
- Vertex AI ML Metadata
- Vertex AI Model Monitoring
- Vertex AI Model Registry
- Vertex AI Online Prediction
- Vertex AI Batch Prediction
- Vertex AI Training
- Vertex AI Pipelines
- Vertex AI Workbench
步骤 2:查看 Vertex AI Gemini API 状态
重点关注 "Vertex AI Gemini API" 这一行:
- ✅ 绿色勾号:服务正常运行
- ⚠️ 黄色警告:部分地区或功能受影响
- ❌ 红色叉号:服务中断或重大故障
步骤 3:查看区域状态
Google Cloud Status 页面按地区划分状态:
| 地区分组 | 覆盖范围 | 对国内影响 |
|---|---|---|
| Americas (regions) | 美国、加拿大、南美 | 间接影响 |
| Europe (regions) | 欧洲各国 | 间接影响 |
| Asia Pacific (regions) | 亚太地区 | 直接影响国内用户 |
| Middle East (regions) | 中东地区 | 间接影响 |
注意:国内开发者通常使用 Asia Pacific 地区的服务,重点关注该列的状态。
步骤 4:查看故障详情
如果某个地区显示异常状态,点击产品名称可以查看:
- 故障时间线:问题开始时间、更新时间、恢复时间
- 影响范围:受影响的具体地区和功能
- 根本原因:Google 提供的故障原因说明
- 解决进展:实时更新的修复进度
- 预估恢复时间:官方给出的 ETA
🔔 订阅状态更新
Google Cloud Status 支持订阅功能:
- RSS 订阅:实时获取状态更新
- 邮件通知:重大故障时发送邮件
- JSON API:程序化获取状态数据
订阅方法:
- 点击页面右上角的 "Subscribe" 按钮
- 选择感兴趣的产品(勾选 Vertex AI Gemini API)
- 选择通知方式(RSS、Email、JSON)
- 确认订阅即可
其他主流 AI API Status Pages
除了 Gemini API,其他主流 AI API 提供商也都有官方状态页面。以下是完整列表:
1. OpenAI API Status
官方地址:https://status.openai.com/
覆盖产品:
- GPT-4、GPT-4 Turbo、GPT-4o
- GPT-3.5 Turbo
- DALL-E 3
- Whisper
- Text-to-Speech (TTS)
- Embeddings
- Moderations
特点:
- ✅ 实时状态监控
- ✅ 历史故障记录
- ✅ 订阅功能(Email、SMS、RSS、Slack、Webhook)
- ✅ API 响应时间图表
- ✅ 按地区显示状态
2. Anthropic Claude API Status
官方地址:https://status.anthropic.com/
覆盖产品:
- Claude 3.5 Sonnet
- Claude 3 Opus
- Claude 3 Haiku
- Claude 2.1
- Claude Instant
特点:
- ✅ 简洁的状态展示
- ✅ 订阅更新(Email、RSS)
- ✅ 故障时间线
- ✅ API 可用性历史数据
3. AWS Bedrock Status
官方地址:https://health.aws.amazon.com/health/status
覆盖产品:
- Amazon Bedrock(包含 Claude、Llama、Titan 等模型)
- AWS Lambda
- AWS API Gateway
- 其他 AWS 服务
特点:
- ✅ 覆盖全部 AWS 地区
- ✅ 按服务和地区过滤
- ✅ 订阅 AWS Health Dashboard
- ✅ 整合 AWS 所有服务状态
4. Azure OpenAI Service Status
官方地址:https://azure.status.microsoft/en-us/status
覆盖产品:
- Azure OpenAI Service(GPT-4、GPT-3.5)
- Azure Cognitive Services
- Azure AI Services
- 其他 Azure 服务
特点:
- ✅ 全球地区状态
- ✅ RSS 订阅
- ✅ 历史故障记录
- ✅ 移动端 App 支持
5. Cohere API Status
官方地址:https://status.cohere.com/
覆盖产品:
- Cohere Generate
- Cohere Embed
- Cohere Classify
- Cohere Summarize
特点:
- ✅ 实时监控
- ✅ 订阅通知
- ✅ 响应时间图表
6. Hugging Face API Status
官方地址:https://status.huggingface.co/
覆盖产品:
- Inference API
- Inference Endpoints
- Spaces
- Datasets
- Models Hub
特点:
- ✅ 开源社区驱动
- ✅ 详细的性能指标
- ✅ 订阅功能

通过 API易平台统一监控
虽然各大 AI API 提供商都提供了状态页面,但开发者在实际使用中仍面临诸多挑战:
传统状态页面的局限性
| 局限性类型 | 具体问题 | 影响 |
|---|---|---|
| 分散查询 | 需要逐个访问多个状态页面 | 浪费时间,效率低下 |
| 更新延迟 | 官方页面更新可能滞后 | 无法实时感知故障 |
| 信息粗略 | 只显示大致状态,缺少细节 | 难以定位具体问题 |
| 无法自动切换 | 发现故障后需手动切换 API | 影响应用可用性 |
| 缺乏历史分析 | 无法追踪长期稳定性趋势 | 难以优化服务选择 |
API易平台的统一监控优势
通过 API易 apiyi.com 平台,可以实现对所有接入 AI API 的统一监控和智能管理:
1. 统一状态面板
功能:
- 在一个页面查看所有 AI API 的实时状态
- 支持 OpenAI、Anthropic、Google Gemini、AWS Bedrock 等
- 按模型分类显示可用性
优势:
- 无需逐个访问官方状态页面
- 一目了然的可用性概览
- 快速定位问题 API
2. 实时监控告警
功能:
- 每 30 秒实时检测 API 可用性
- 异常时立即推送告警(Email、SMS、Webhook)
- 自动记录故障时间和恢复时间
优势:
- 比官方状态页面更新更快
- 主动通知,无需手动查询
- 完整的故障记录
3. 智能故障切换
功能:
- 检测到 API 故障时自动切换到备用 API
- 支持按优先级配置切换策略
- 故障恢复后自动切回
优势:
- 应用零中断
- 无需手动干预
- 最大化可用性
4. 性能分析报告
功能:
- 统计每个 API 的平均响应时间
- 记录历史故障次数和时长
- 生成月度稳定性报告
优势:
- 数据驱动的 API 选择
- 长期趋势分析
- 优化成本和性能
5. 多 API 负载均衡
功能:
- 将请求分散到多个 API 提供商
- 根据实时性能动态调整权重
- 避免单点依赖
优势:
- 分散风险
- 提升整体可用性
- 优化响应速度
🔍 监控建议:对于生产环境应用,我们强烈建议使用 API易 apiyi.com 的统一监控功能。相比于手动查看多个官方状态页面,平台提供的主动监控和自动切换能够显著提升应用的稳定性和可用性。您可以访问平台获取详细的监控配置指南和最佳实践。
Status Page 使用最佳实践
1. 建立监控习惯
| 实践要点 | 具体建议 | 预期效果 |
|---|---|---|
| 🔔 订阅通知 | 订阅关键 API 的状态更新 | 第一时间获知故障 |
| 📊 定期查看 | 每周查看一次历史故障 | 了解服务稳定性趋势 |
| 📝 记录问题 | 遇到问题时对照状态页面 | 快速区分本地和服务端问题 |
| 🔄 配置备用 | 提前配置备用 API | 故障时快速切换 |
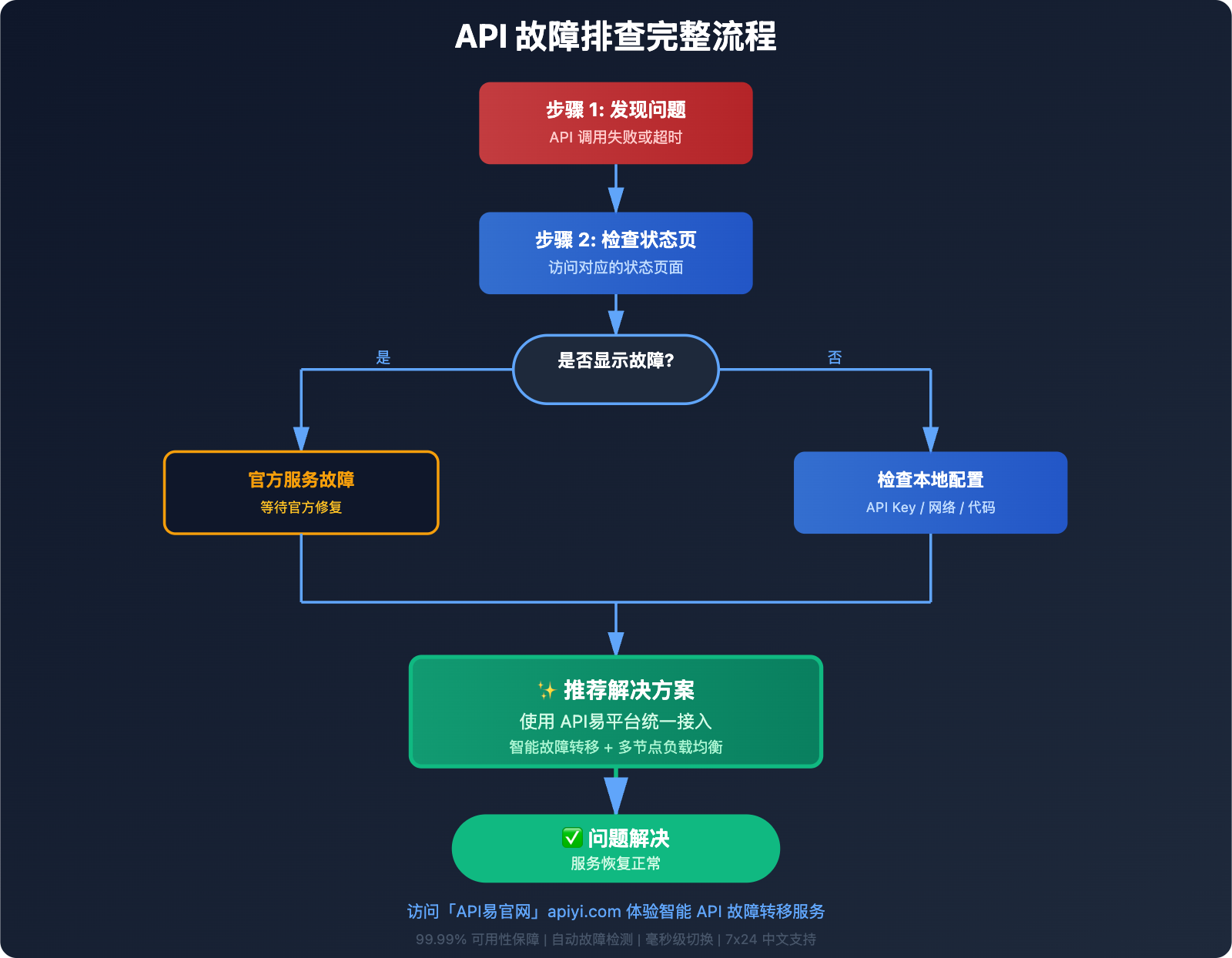
2. 故障应对流程
当遇到 API 调用问题时,建议按以下流程排查:
步骤 1:检查本地环境
- 确认 API Key 是否正确
- 检查网络连接是否正常
- 验证请求参数是否合法
步骤 2:查看官方状态页面
- 访问对应 API 的官方状态页面
- 确认服务是否正常运行
- 查看是否有区域性故障
步骤 3:尝试备用方案
- 如果官方有故障,切换到备用 API
- 或使用 API易平台的智能切换
- 临时降级到功能更基础的模型
步骤 4:联系技术支持
- 如果状态页面显示正常但问题依旧
- 提交工单到官方技术支持
- 或联系 API易平台获取帮助
🚨 故障处理建议:为了确保应用的稳定性,建议实施完善的故障处理机制。如果您在使用过程中遇到持续性问题,可以访问 API易 apiyi.com 的技术支持页面,平台提供 7×24 小时技术支持,响应时间通常在 2 小时内。此外,平台的智能切换功能可以在检测到故障时自动切换到备用 API,确保应用不间断运行。
3. 多 API 容灾策略
| 策略类型 | 实施方法 | 适用场景 |
|---|---|---|
| 主备切换 | 配置主 API 和备用 API,故障时手动切换 | 小型应用,对可用性要求不高 |
| 自动切换 | 使用 API易平台实现故障自动切换 | 中型应用,需要较高可用性 |
| 负载均衡 | 将请求分散到多个 API,动态调整权重 | 大型应用,对稳定性要求极高 |
| 多地区部署 | 在不同地区部署应用,就近访问 API | 全球化应用,需要低延迟 |
推荐方案:我们建议在生产环境使用 API易平台 的智能切换和负载均衡功能。相比于手动监控和切换,自动化方案可以:
- 减少 99% 的人工干预
- 缩短故障恢复时间到 10 秒内
- 提升整体可用性到 99.9%+
- 降低运维成本 80%+
您可以通过 API易 apiyi.com 快速配置容灾策略,平台提供可视化的配置界面和详细的使用文档。
常见问题
Q1: 为什么 Google 不为 Gemini API 单独建立状态页面?
原因分析:
- 产品架构原因:Gemini API 是 Vertex AI 平台的一部分,不是独立产品
- 统一管理:Google Cloud 采用统一的状态监控体系,便于整体管理
- 成本考虑:维护单独的状态页面需要额外的开发和运维成本
影响:
- 用户查找状态信息时需要多一步定位过程
- 状态信息可能不如专门页面详细
- 对于只使用 Gemini API 的开发者来说体验不够友好
解决方案:
- 收藏 Google Cloud Status 页面链接
- 使用浏览器书签直接跳转到 Vertex AI 部分
- 或使用 API易 apiyi.com 平台的统一监控,无需手动查找
Q2: Status Page 显示正常,但我的 API 调用还是失败,为什么?
可能原因:
-
配额限制
- 超过了免费额度或 QPS 限制
- 官方状态页面不会显示个人账户的配额问题
-
API Key 问题
- API Key 过期或被撤销
- API Key 权限不足
-
网络问题
- 本地网络不稳定
- DNS 解析问题
- 防火墙拦截
-
请求参数错误
- 模型名称拼写错误
- 请求格式不符合规范
- 参数值超出允许范围
-
区域性故障
- 某些特定地区或功能受影响,但官方页面未及时更新
- 小规模故障未达到报告阈值
排查建议:
- 检查 API 使用量是否超限
- 验证 API Key 的有效性和权限
- 使用 curl 或 Postman 直接测试 API
- 查看详细的错误信息和状态码
- 尝试切换到备用 API 或地区
专业建议:如果持续遇到问题,建议使用 API易 apiyi.com 平台进行调用。平台提供详细的错误日志和调试工具,帮助您快速定位问题。同时,平台的多节点部署和智能切换功能可以有效避免区域性故障带来的影响。
Q3: 订阅了状态更新,为什么我还是最后才知道故障?
延迟原因:
| 延迟环节 | 原因 | 时间 |
|---|---|---|
| 故障检测 | 官方监控系统发现问题 | 1-5 分钟 |
| 人工确认 | 团队确认并评估影响 | 5-15 分钟 |
| 页面更新 | 更新状态页面信息 | 5-10 分钟 |
| 通知发送 | Email、RSS 推送通知 | 5-10 分钟 |
| 总延迟 | – | 16-40 分钟 |
更快的方案:
-
使用第三方监控
- 第三方监控服务通常比官方更快
- 如 API易平台每 30 秒检测一次
- 异常时立即推送告警
-
配置 Webhook
- 部分状态页面支持 Webhook
- 收到通知后自动触发应用切换
-
实施主动监控
- 在应用内部实现 API 健康检查
- 连续失败时自动切换备用 API
推荐方案:我们建议使用 API易 apiyi.com 的实时监控和自动切换功能。相比于等待官方通知,平台可以:
- 在 30 秒内检测到故障
- 10 秒内自动切换到备用 API
- 发送即时告警通知
- 记录完整的故障时间线
这种主动监控和自动切换的方式,可以将故障影响时间从平均 20-40 分钟缩短到 1 分钟以内。
Q4: 如何区分是 API 提供商的问题还是我的代码问题?
快速判断方法:
1. 查看错误状态码
- 5xx 错误(500, 502, 503, 504):通常是服务端问题
- 4xx 错误(400, 401, 403, 429):通常是客户端问题
- 网络超时:可能是双方问题
2. 检查官方状态页面
- 如果状态页面显示故障,确认是服务端问题
- 如果显示正常,更可能是代码或配置问题
3. 使用官方测试工具
- Google AI Studio Playground
- OpenAI Playground
- 如果官方工具也失败,确认是 API 问题
4. 对比不同 API
- 使用相同代码测试不同的 API
- 如果其他 API 正常,说明是特定 API 的问题
- 如果都失败,说明可能是代码问题
5. 查看社区和论坛
- 搜索相同的错误信息
- 查看是否有其他开发者遇到同样问题
- 如果有大量相似报告,确认是 API 问题
调试工具推荐:
- 本地调试:使用 curl、Postman 等工具直接测试
- 在线调试:使用 API易平台的调试功能
- 日志分析:查看完整的请求和响应日志
专业建议:通过 API易 apiyi.com 平台调用 API,可以获得详细的请求日志和错误分析。平台会自动记录每次调用的完整信息,包括请求参数、响应内容、耗时、状态码等,帮助您快速定位问题根源。
Q5: 使用第三方平台(如 API易)会影响 Status Page 的准确性吗?
答案:不会影响,反而能获得更准确的状态信息。
原因分析:
-
独立监控
- 第三方平台有自己的监控系统
- 直接检测 API 的实际可用性
- 不依赖官方状态页面
-
更快检测
- 高频监控(如 30 秒一次)
- 比官方状态页面更新更快
- 能够发现官方未报告的问题
-
多维度检测
- 不仅监控 API 可用性
- 还监控响应时间、成功率等指标
- 提供更全面的健康度评估
-
历史数据
- 记录长期的稳定性数据
- 可以追溯历史故障
- 支持趋势分析
实际优势对比:
| 对比维度 | 官方 Status Page | API易平台监控 |
|---|---|---|
| 检测频率 | 不确定(约 5 分钟) | 30 秒 |
| 通知速度 | 16-40 分钟 | 1 分钟内 |
| 信息详细度 | 粗略 | 详细(含具体错误) |
| 历史追溯 | 90 天 | 长期保留 |
| 自动切换 | 不支持 | 支持 |
| 多 API 统一 | 不支持 | 支持 |
推荐策略:我们建议同时使用官方状态页面和 API易平台监控:
- 官方页面:作为参考,了解官方公告
- API易监控:作为主要依据,实时监控和自动切换
通过 API易 apiyi.com 平台,您可以获得比官方更快、更详细、更可操作的状态信息,显著提升应用的稳定性和可用性。
延伸阅读
🛠️ Status Page 监控工具
除了官方状态页面和 API易平台,还有一些第三方监控工具可以使用:
1. 专业监控服务
- UptimeRobot:免费的 API 监控服务
- Pingdom:企业级监控和告警
- Datadog:综合性能监控平台
- New Relic:应用性能管理(APM)
2. 开源监控方案
- Prometheus + Grafana:自建监控系统
- Uptime Kuma:开源的状态监控工具
- Cachet:开源状态页面系统
📖 学习建议:对于生产环境应用,建议优先使用专业的监控平台而不是手动查看状态页面。API易 apiyi.com 平台整合了专业的监控功能和智能切换能力,无需额外配置复杂的监控系统。平台提供了开箱即用的监控面板、告警通知和自动切换功能,可以显著降低运维复杂度。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Google Cloud Status 使用指南 | status.cloud.google.com |
| 监控最佳实践 | API 监控和容灾策略 | help.apiyi.com/monitoring |
| 故障案例分析 | AI API 历史故障复盘 | blog.apiyi.com/incidents |
| 技术博客 | 如何构建高可用 AI 应用 | blog.apiyi.com |
深入学习建议:持续关注 AI API 服务的稳定性动态,我们推荐定期访问 API易 help.apiyi.com 的技术博客,了解最新的 API 状态、故障分析和最佳实践。平台会第一时间发布重大故障的详细分析报告,帮助您了解根本原因并采取预防措施。
总结
快速找到 Gemini API Status Page 是每个开发者必备的技能。虽然 Google 没有为 Gemini API 单独建立状态页面,但通过访问 Google Cloud Status (status.cloud.google.com) 并定位到 Vertex AI Gemini API 产品,可以获取官方的服务状态信息。
重点回顾:
- ✅ Gemini API 状态页面:位于 Google Cloud Status 的 Vertex AI 产品组下
- ✅ 其他主流 API:OpenAI、Anthropic、AWS Bedrock 等都有独立状态页面
- ✅ 订阅通知:建立主动监控习惯,第一时间获知故障
- ✅ 备用方案:配置多 API 容灾,避免单点依赖
- ✅ 统一监控:使用 API易平台实现所有 API 的统一管理和智能切换
在实际应用中,建议:
- 收藏关键状态页面:将常用 API 的状态页面加入书签
- 订阅状态更新:配置 Email 或 RSS 订阅,获取及时通知
- 实施主动监控:不要完全依赖官方状态页面,建立自己的监控系统
- 配置自动切换:使用智能切换功能,故障时自动切换到备用 API
- 定期回顾分析:查看历史故障数据,优化 API 选择策略
最终建议:对于需要高可用性的生产环境,我们强烈推荐使用 API易 apiyi.com 这类专业的 API 聚合平台。该平台不仅提供:
- 📊 统一监控面板:一页查看所有 AI API 状态
- ⚡ 实时检测告警:30 秒检测一次,异常立即通知
- 🔄 智能故障切换:10 秒内自动切换到备用 API
- 📈 性能分析报告:长期稳定性和性能趋势分析
- 🛠️ 7×24 技术支持:专业团队协助解决问题
还提供了免费试用额度和详细的配置文档。相比于手动查看多个状态页面并手动切换,使用专业平台可以将故障影响时间从平均 20-40 分钟缩短到 1 分钟以内,显著提升应用的稳定性和用户体验。
📝 作者简介:资深 AI 应用开发者,专注大模型 API 集成与高可用架构设计。定期分享 AI 开发实践经验和运维最佳实践,更多技术资料和案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论 API 监控和容灾策略。如需深入技术支持或定制化监控方案,可通过 API易 apiyi.com 联系我们的技术团队,获取专业咨询和企业级服务。