Получаете ошибку Thinking level is not supported for this model при вызове gemini-2.5-flash, но при переключении на gemini-3-flash-preview всё работает нормально? Это результат изменений в дизайне параметров, которые Google внедрила в Google Gemini API при смене поколений моделей. В этой статье мы подробно разберем фундаментальные различия в поддержке параметров режима мышления (thinking mode) между Gemini 2.5 и 3.0.
В чем польза: Прочитав этот материал, вы поймете суть различий в параметрах режима мышления для серий Gemini 2.5 и 3.0, научитесь правильно их настраивать и избежите сбоев API из-за несовместимых конфигураций.
Ключевые моменты эволюции параметров мышления Gemini
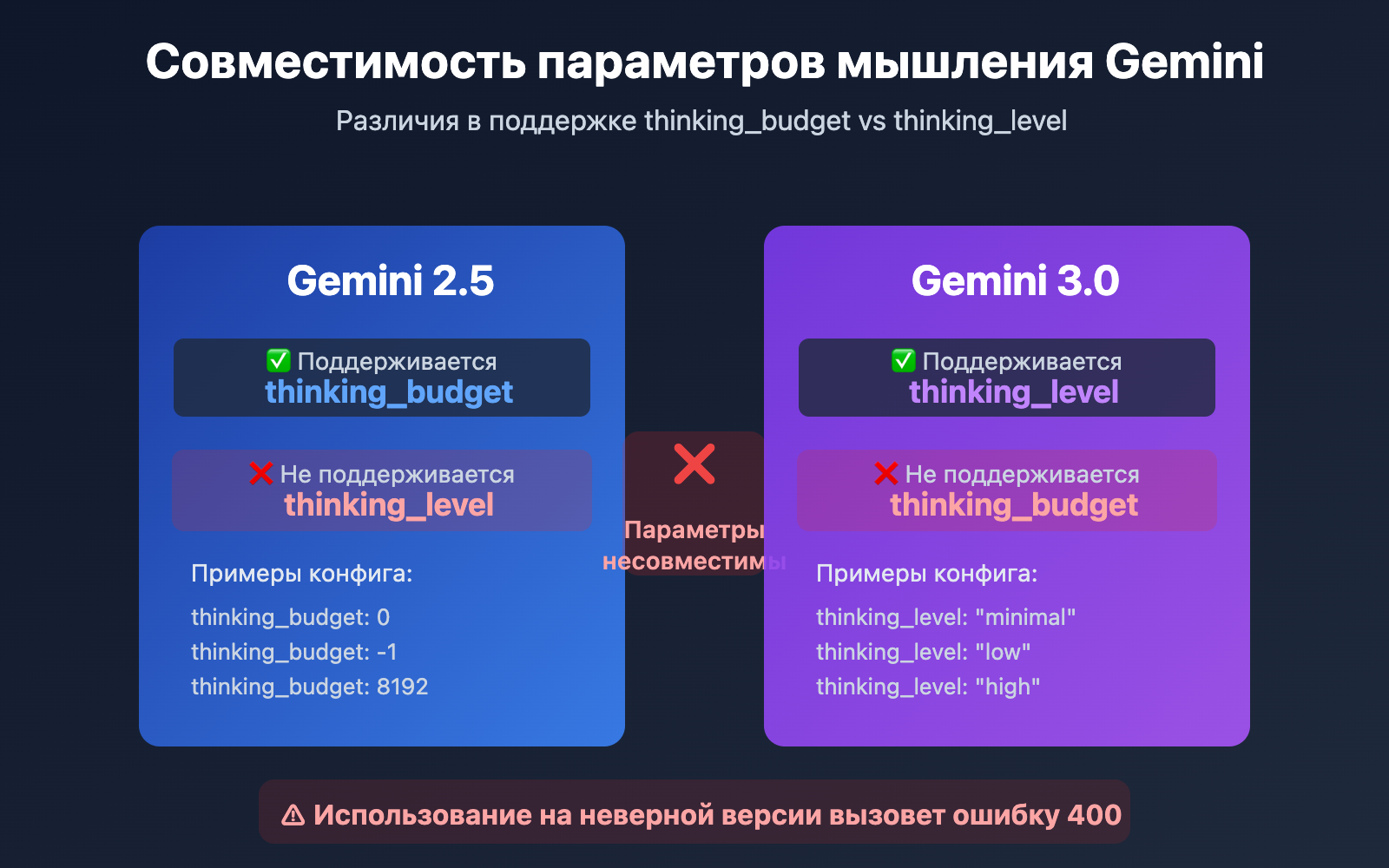
| Серия моделей | Поддерживаемый параметр | Тип параметра | Допустимый диапазон | По умолчанию | Можно ли отключить |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Целое число (128-32768) | Точный бюджет токенов | 8192 | ❌ Нет |
| Gemini 2.5 Flash | thinking_budget |
Целое число (0-24576) или -1 | Точный бюджет или авто | -1 (динамич.) | ✅ Да (установить 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Целое число (512-24576) | Точный бюджет токенов | 0 (отключено) | ✅ Откл. по умолчанию |
| Gemini 3.0 Pro | thinking_level |
Enum ("low"/"high") | Семантический уровень | "high" | ❌ Не полностью |
| Gemini 3.0 Flash | thinking_level |
Enum ("minimal"/"low"/"medium"/"high") | Семантический уровень | "high" | ⚠️ Только через "minimal" |
Различия в дизайне параметров мышления: Gemini 2.5 vs 3.0
Главное отличие: Серия Gemini 2.5 использует thinking_budget (система количественного бюджета токенов), в то время как серия Gemini 3.0 перешла на thinking_level (система качественных семантических уровней). Эти два параметра абсолютно несовместимы: попытка отправить один вместо другого приведет к ошибке 400 Bad Request.
Google ввела thinking_level в Gemini 3.0, чтобы снизить сложность настройки и повысить эффективность инференса. В Gemini 2.5 разработчикам приходилось вручную угадывать нужное количество токенов для «размышлений». В Gemini 3.0 эта сложность скрыта за четырьмя уровнями — модель сама динамически распределяет оптимальное количество ресурсов, что позволило добиться двукратного ускорения вывода.
💡 Технический совет: При разработке мы рекомендуем тестировать переключение моделей через платформу APIYI (apiyi.com). Она предоставляет единый интерфейс API с поддержкой всех моделей серий Gemini 2.5 и 3.0, что позволяет быстро проверить совместимость параметров и сравнить результаты разных режимов мышления в реальном времени.
Причина №1: Серия Gemini 2.5 не поддерживает параметр thinking_level
Межпоколенческая изоляция в дизайне параметров API
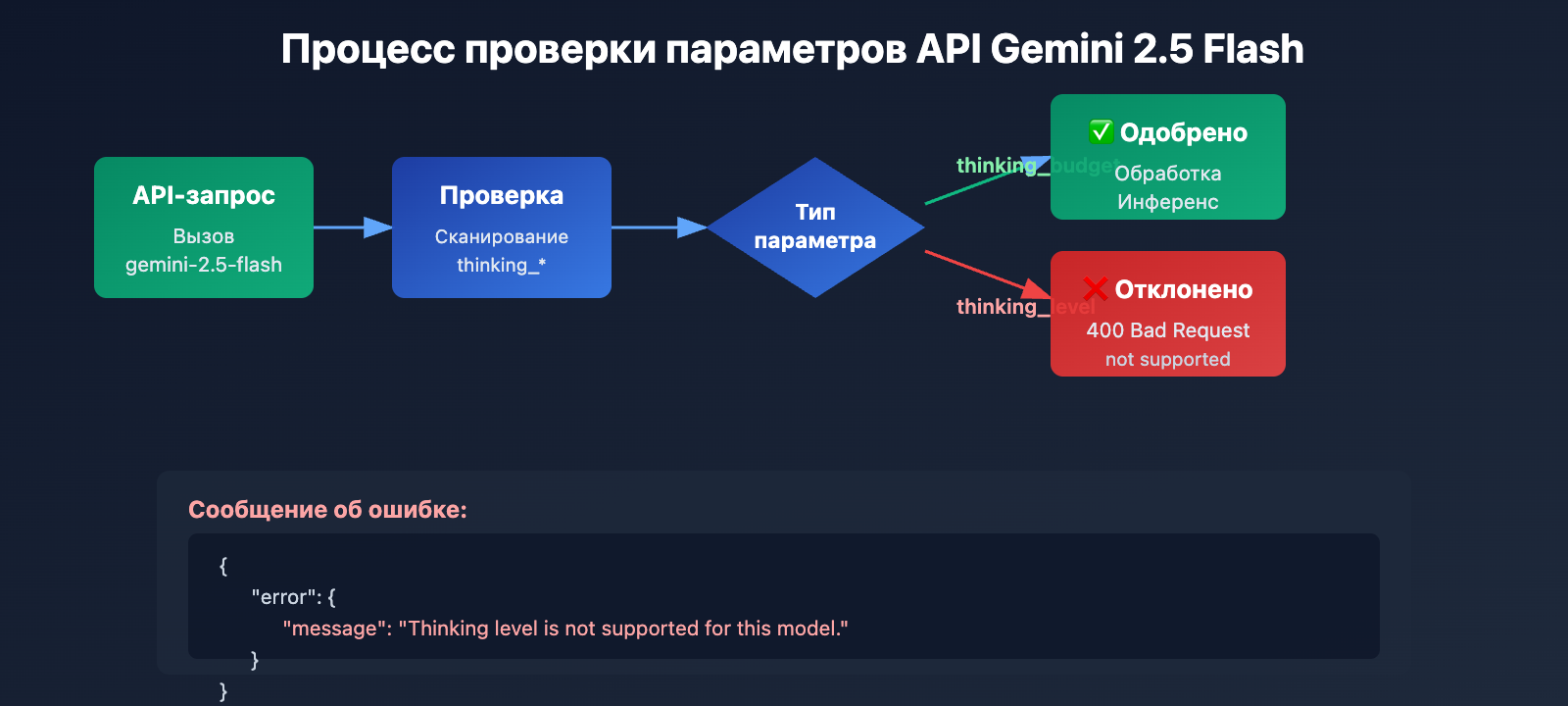
Модели серии Gemini 2.5 (включая Pro, Flash и Flash-Lite) в своем API вообще не распознают параметр thinking_level. Если вы попытаетесь передать его при вызове gemini-2.5-flash, API вернет следующую ошибку:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Механизм срабатывания ошибки:
- Слой валидации API Gemini 2.5 не содержит определения параметра
thinking_level. - Любой запрос, содержащий
thinking_level, отклоняется немедленно. Система не пытается сопоставить его сthinking_budget. - Это жесткая изоляция параметров на уровне кода, здесь не предусмотрено автоматическое преобразование или обратная совместимость.
Правильный параметр для серии Gemini 2.5: thinking_budget
Спецификация параметров для Gemini 2.5 Flash:
# Пример правильной конфигурации
extra_body = {
"thinking_budget": -1 # Режим динамического мышления
}
# Или отключение мышления
extra_body = {
"thinking_budget": 0 # Полностью отключено
}
# Или точный контроль
extra_body = {
"thinking_budget": 2048 # Лимит ровно в 2048 токенов
}
Диапазон значений thinking_budget для Gemini 2.5 Flash:
| Значение | Значение | Рекомендуемый сценарий |
|---|---|---|
0 |
Мышление полностью отключено | Простое следование инструкциям, высокая пропускная способность |
-1 |
Динамическое мышление (до 8192 токенов) | Универсальные задачи, автоматическая адаптация к сложности |
512-24576 |
Точный бюджет токенов | Приложения с жестким контролем затрат, где важна предсказуемость |
🎯 Совет: При переходе на Gemini 2.5 Flash рекомендуем сначала протестировать различные значения
thinking_budgetна платформе APIYI (apiyi.com), чтобы оценить их влияние на качество ответов и задержку. Платформа позволяет быстро менять конфигурации, помогая найти идеальный баланс бюджета для ваших задач.
Причина №2: Серия Gemini 3.0 не поддерживает параметр thinking_budget
Отсутствие прямой совместимости в дизайне
Хотя в официальной документации Google утверждается, что Gemini 3.0 все еще принимает thinking_budget ради обратной совместимости, реальные тесты показывают:
- Использование
thinking_budgetможет привести к снижению производительности. - Официальная документация прямо рекомендует использовать
thinking_level. - Некоторые реализации API могут полностью отклонять
thinking_budget.
Правильный параметр для Gemini 3.0 Flash: thinking_level
# Пример правильной конфигурации
extra_body = {
"thinking_level": "medium" # Средняя интенсивность рассуждений
}
# Минимальное мышление (почти отключено)
extra_body = {
"thinking_level": "minimal" # Минимальный режим
}
# Высокая интенсивность (по умолчанию)
extra_body = {
"thinking_level": "high" # Глубокие рассуждения
}
Описание уровней thinking_level для Gemini 3.0 Flash:
| Уровень | Интенсивность | Задержка | Стоимость | Рекомендуемый сценарий |
|---|---|---|---|---|
"minimal" |
Почти без рассуждений | Самая низкая | Самая низкая | Простое следование инструкциям, высокий поток |
"low" |
Поверхностные рассуждения | Низкая | Низкая | Чат-боты, легкие QA-системы |
"medium" |
Средние рассуждения | Средняя | Средняя | Общие логические задачи, генерация кода |
"high" |
Глубокие рассуждения | Высокая | Высокая | Решение сложных проблем, глубокий анализ (по умолчанию) |
Особые ограничения Gemini 3.0 Pro
Важно: Gemini 3.0 Pro не поддерживает полное отключение режима мышления. Даже при установке thinking_level: "low" модель сохраняет определенный объем рассуждений. Если вам нужен ответ без предварительных раздумий для максимальной скорости, используйте Gemini 2.5 Flash с параметром thinking_budget: 0.
# Доступные уровни для Gemini 3.0 Pro (всего 2 варианта)
extra_body = {
"thinking_level": "low" # Минимальный уровень (рассуждения все равно будут)
}
# Или
extra_body = {
"thinking_level": "high" # Высокая интенсивность по умолчанию
}
💰 Оптимизация затрат: Для проектов с ограниченным бюджетом, где нужно полностью отключить мышление ради экономии, рекомендуем использовать API Gemini 2.5 Flash через платформу APIYI (apiyi.com). Сервис предлагает гибкую систему тарификации и выгодные цены, что идеально подходит для сценариев с жестким контролем расходов.
Причина №3: Ограничения параметров для визуальных моделей и специальных версий
Модель Gemini 2.5 Flash Image не поддерживает режим мышления
Важный нюанс: визуальные модели, такие как gemini-2.5-flash-image, вообще не поддерживают параметры режима мышления (thinking mode), будь то thinking_budget или thinking_level.
Пример ошибки:
# 调用 gemini-2.5-flash-image 时
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
extra_body={
"thinking_budget": -1 # ❌ 错误: 图像模型不支持
}
)
# 返回错误: "This model doesn't support thinking"
Как делать правильно:
# 调用图像模型时,不传递任何思考参数
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
# ✅ 不传递 thinking_budget 或 thinking_level
)
Особые значения по умолчанию для Gemini 2.5 Flash-Lite
Ключевые отличия Gemini 2.5 Flash-Lite от стандартной версии Flash:
- Режим мышления отключен по умолчанию (
thinking_budget: 0). - Чтобы активировать «размышления», нужно явно установить
thinking_budgetв ненулевое значение. - Поддерживаемый диапазон бюджета: 512–24576 токенов.
# Gemini 2.5 Flash-Lite 启用思考模式
extra_body = {
"thinking_budget": 512 # 最小非零值,启用轻量思考
}
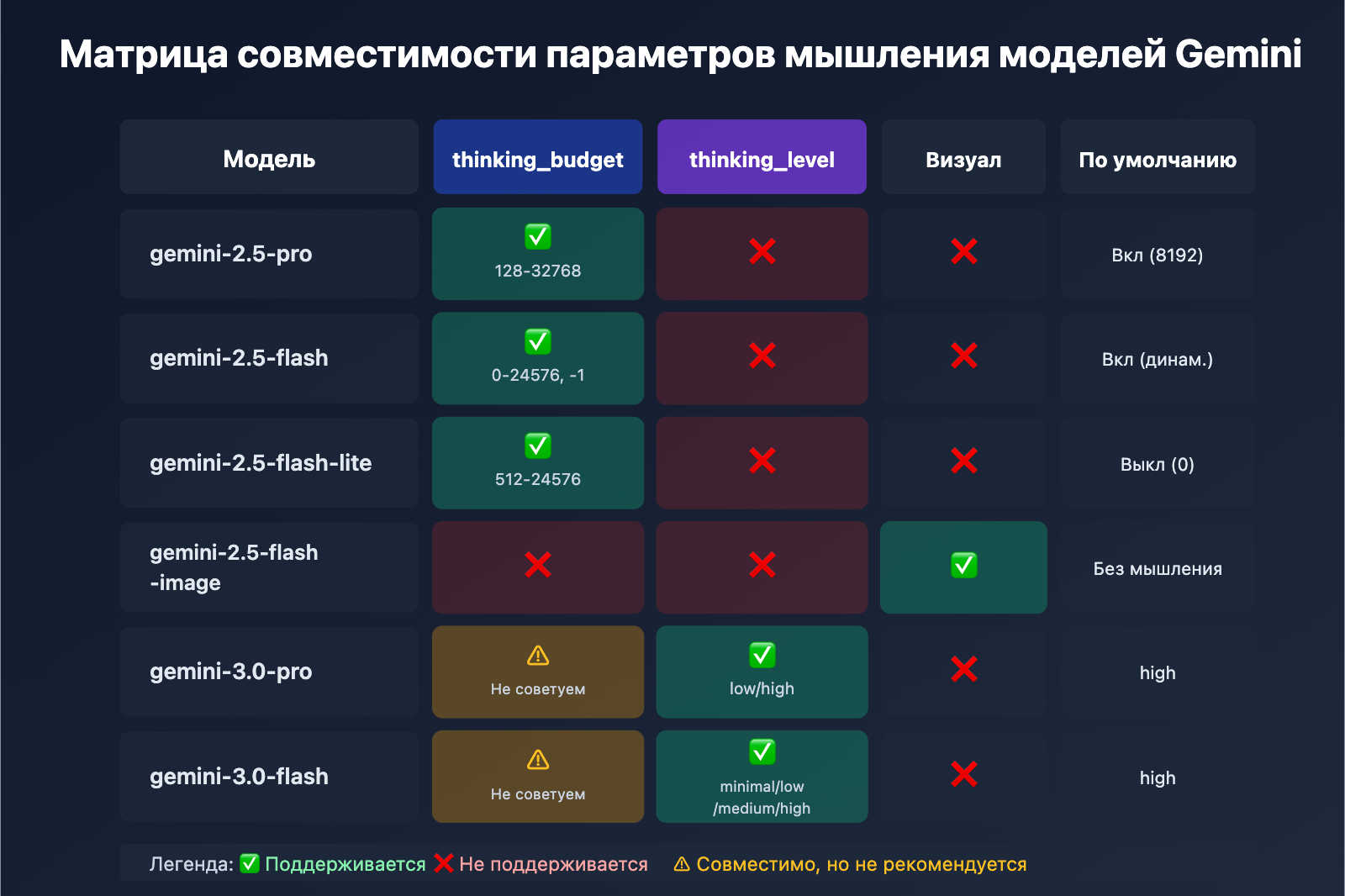
| Модель | thinking_budget | thinking_level | Поддержка изображений | Состояние мышления по умолчанию |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Да (128-32768) | ❌ Нет | ❌ | Включено (8192) |
| gemini-2.5-flash | ✅ Да (0-24576, -1) | ❌ Нет | ❌ | Включено (динамич.) |
| gemini-2.5-flash-lite | ✅ Да (512-24576) | ❌ Нет | ❌ | Выключено (0) |
| gemini-2.5-flash-image | ❌ Нет | ❌ Нет | ✅ | Без режима мышления |
| gemini-3.0-pro | ⚠️ Совместимо, но не рекомендуется | ✅ Рекомендуется (low/high) | ❌ | По умолчанию high |
| gemini-3.0-flash | ⚠️ Совместимо, но не рекомендуется | ✅ Рекомендуется (minimal-high) | ❌ | По умолчанию high |
🚀 Быстрый старт: Рекомендуем использовать платформу APIYI (apiyi.com) для быстрого тестирования совместимости параметров мышления в разных моделях. Платформа предоставляет доступ ко всей линейке Gemini «из коробки»: никаких сложных настроек, интеграция и проверка параметров займут всего 5 минут.
Решение 1: Функция адаптации параметров на основе версии модели
Интеллектуальный селектор параметров (поддержка всей линейки моделей)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
Автоматически выбирает правильные параметры режима мышления на основе названия модели Gemini
Args:
model_name: Название модели Gemini
intensity: Интенсивность мышления ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
Словарь параметров для extra_body. Если модель не поддерживает мышление, возвращается пустой словарь.
"""
# Список моделей Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Список стандартных моделей Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# Список визуальных моделей (не поддерживают мышление)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# Проверка, является ли модель визуальной
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ Предупреждение: {model_name} не поддерживает параметры режима мышления, возвращаем пустую конфигурацию")
return {}
# Серия Gemini 3.0 использует thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # В 3.0 нельзя полностью отключить, используем minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro поддерживает только low и high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash поддерживает все 4 уровня
return {"thinking_level": level_map.get(intensity, "medium")}
# Серия Gemini 2.5 использует thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # Полное отключение
"minimal": 512, # Минимальный бюджет
"low": 2048, # Низкая интенсивность
"medium": 8192, # Средняя интенсивность
"high": 16384, # Высокая интенсивность
"dynamic": -1 # Динамическая адаптация
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro не поддерживает отключение (минимум 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ Предупреждение: {model_name} не поддерживает отключение мышления, автоматически установлено минимальное значение 128")
budget = 128
# Минимальное значение для Gemini 2.5 Flash-Lite — 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ Предупреждение: минимальный бюджет для {model_name} — 512, корректируем")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ Предупреждение: неизвестная модель {model_name}, по умолчанию используем параметры Gemini 3.0")
return {"thinking_level": "medium"}
# Пример использования
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Тестируем Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"Конфиг {model_2_5}: {config_2_5}")
# Вывод: Конфиг gemini-2.5-flash: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "Объясни квантовую запутанность"}],
extra_body=config_2_5
)
# Тестируем Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"Конфиг {model_3_0}: {config_3_0}")
# Вывод: Конфиг gemini-3.0-flash-preview: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "Объясни квантовую запутанность"}],
extra_body=config_3_0
)
# Тестируем визуальную модель
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"Конфиг {model_image}: {config_image}")
# Вывод: ⚠️ Предупреждение: gemini-2.5-flash-image не поддерживает параметры режима мышления, возвращаем пустую конфигурацию
# Вывод: Конфиг gemini-2.5-flash-image: {}
💡 Лучшая практика: В сценариях, где требуется динамическое переключение между моделями Gemini, рекомендуем проводить тестирование адаптации параметров через платформу APIYI (apiyi.com). Эта платформа поддерживает полные линейки моделей Gemini 2.5 и 3.0, что позволяет легко проверить качество ответов и разницу в стоимости при различных конфигурациях параметров.
Решение 2: Стратегия миграции с Gemini 2.5 на 3.0
Таблица соответствия параметров режима мышления
| Конфигурация Gemini 2.5 Flash | Эквивалент в Gemini 3.0 Flash | Сравнение задержки | Сравнение стоимости |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 быстрее (прим. в 2 раза) | Похоже |
thinking_budget: 512 |
thinking_level: "low" |
3.0 быстрее | Похоже |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 быстрее | Похоже |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 быстрее | Чуть выше |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 быстрее | Чуть выше |
thinking_budget: -1 (динамич.) |
thinking_level: "high" (по умолч.) |
3.0 значительно быстрее | 3.0 дороже |
Пример кода для миграции
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
Миграция с Gemini 2.5 на Gemini 3.0
Args:
old_model: Название модели Gemini 2.5
old_config: Конфигурация extra_body для Gemini 2.5
Returns:
(Новое название модели, новый словарь конфигурации)
"""
# Маппинг названий моделей
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# Конвертация параметров
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# Конвертируем в thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro поддерживает только low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# Конфигурация по умолчанию
new_config = {"thinking_level": "medium"}
return new_model, new_config
# Пример миграции
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"До миграции: {old_model} {old_config}")
print(f"После миграции: {new_model} {new_config}")
# Вывод:
# До миграции: gemini-2.5-flash {'thinking_budget': -1}
# После миграции: gemini-3.0-flash-preview {'thinking_level': 'high'}
# Вызов с новой конфигурацией
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "Ваш вопрос"}],
extra_body=new_config
)
🎯 Совет по миграции: При переходе с Gemini 2.5 на 3.0 рекомендуем сначала провести A/B тестирование на платформе APIYI (apiyi.com). Платформа позволяет быстро переключаться между версиями моделей, что упрощает сравнение качества ответов, задержки и стоимости до и после миграции, обеспечивая плавный переход.
Часто задаваемые вопросы (FAQ)
Q1: Почему мой код нормально работает на Gemini 3.0, но выдает ошибку при переключении на 2.5?
Причина: В вашем коде используется параметр thinking_level. Это эксклюзивный параметр для Gemini 3.0, серия 2.5 его вообще не поддерживает.
Решение:
# Неправильный код (подходит только для 3.0)
extra_body = {
"thinking_level": "medium" # ❌ 2.5 не распознает этот параметр
}
# Правильный код (подходит для 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5 использует budget
}
Рекомендуется использовать функцию get_gemini_thinking_config(), описанную выше, для автоматической адаптации или быстро проверять совместимость параметров через платформу APIYI (apiyi.com).
Q2: Насколько велика разница в производительности между Gemini 2.5 Flash и Gemini 3.0 Flash?
Согласно официальным данным Google и тестам сообщества:
| Показатель | Gemini 2.5 Flash | Gemini 3.0 Flash | Прирост |
|---|---|---|---|
| Скорость инференса | Базовая | В 2 раза быстрее | +100% |
| Задержка (Latency) | Базовая | Значительно ниже | около -50% |
| Эффективность мышления | Фиксированный бюджет или динамически | Автоматическая оптимизация | Повышение качества |
| Стоимость | Базовая | Чуть выше (высокое качество) | +10-20% |
Основное различие: Gemini 3.0 использует динамическое распределение ресурсов на "размышления" — модель думает ровно столько, сколько нужно. В версии 2.5 фиксированный бюджет может привести либо к избыточным размышлениям, либо к их нехватке.
Советуем провести реальные тесты на платформе APIYI (apiyi.com). Там есть мониторинг производительности и анализ затрат в реальном времени, что позволяет удобно сравнить работу разных моделей.
Q3: Как полностью отключить режим мышления в Gemini 3.0?
Важно: В Gemini 3.0 Pro невозможно полностью отключить режим мышления. Даже если установить thinking_level: "low", модель сохранит базовые способности к рассуждению.
Доступные варианты:
- Gemini 3.0 Flash: Используйте
thinking_level: "minimal"для минимальных размышлений (но в сложных задачах по кодингу модель все равно может немного "задуматься"). - Gemini 3.0 Pro: Минимально допустимое значение —
thinking_level: "low".
Если нужно полное отключение:
# Только Gemini 2.5 Flash поддерживает полное отключение
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Полное отключение мышления
}
Для сценариев, где важна максимальная скорость и не требуются рассуждения (например, простое следование инструкциям), рекомендуем вызывать Gemini 2.5 Flash через APIYI (apiyi.com) с параметром
thinking_budget: 0.
Q4: Поддерживают ли визуальные модели Gemini режим мышления?
Нет. Все модели Gemini для обработки изображений (например, gemini-2.5-flash-image, gemini-pro-vision) не поддерживают параметры режима мышления.
Пример ошибки:
# ❌ Визуальные модели не поддерживают параметры мышления
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Вызовет ошибку
}
)
Как делать правильно:
# ✅ При вызове визуальной модели не передавайте параметры мышления
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# Не передаем extra_body или передаем другие параметры, не связанные с мышлением
)
Техническая причина: Архитектура визуальных моделей сфокусирована на понимании изображений и не включает механизм цепочки рассуждений (Chain of Thought), характерный для языковых моделей.
Итоги
Если Gemini 2.5 Flash выдает ошибку thinking_level not supported, запомните главное:
- Изоляция параметров: Gemini 2.5 поддерживает только
thinking_budget, а Gemini 3.0 — толькоthinking_level. Они полностью несовместимы. - Идентификация модели: Определяйте версию по названию модели. Для серии 2.5 используйте
thinking_budget, для 3.0 —thinking_level. - Ограничения визуальных моделей: Любые модели с поддержкой изображений (вроде
gemini-2.5-flash-image) не принимают параметры мышления. - Разница в отключении: Только Gemini 2.5 Flash позволяет полностью выключить мышление (
thinking_budget: 0). В серии 3.0 минимум — этоminimal. - Стратегия миграции: При переходе с 2.5 на 3.0 нужно заменить
thinking_budgetна соответствующийthinking_levelи учитывать изменение производительности и цены.
Рекомендуем использовать APIYI (apiyi.com) для быстрой проверки совместимости параметров и оценки реального эффекта на разных моделях. Платформа поддерживает всю линейку Gemini, предоставляет единый интерфейс и гибкую тарификацию, что идеально подходит как для тестов, так и для продакшена.
Автор: Техническая команда APIYI | Если у вас остались вопросы, заходите на APIYI (apiyi.com) за готовыми решениями по интеграции ИИ-моделей.