При вызове моделей Gemini 3.0 Pro Preview или gemini-3-flash-preview столкнулись с ошибкой thinking_budget and thinking_level are not supported together? Это проблема совместимости, возникшая из-за обновления параметров в разных версиях Google Gemini API. В этой статье мы разберем первопричину с точки зрения эволюции дизайна API и научимся правильно задавать конфигурацию.
Главная ценность: Прочитав этот текст, вы поймете, как правильно настраивать параметры режима мышления (thinking mode) для моделей Gemini 2.5 и 3.0, избежите типичных ошибок при вызове API и научитесь оптимизировать производительность и затраты на инференс.

Ключевые моменты эволюции параметров Gemini API
| Версия модели | Рекомендуемый параметр | Тип параметра | Пример конфигурации | Сценарии использования |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
Целое число или -1 | thinking_budget: 0 (откл.)thinking_budget: -1 (динамич.) |
Точный контроль бюджета токенов на размышление |
| Gemini 3.0 Pro/Flash | thinking_level |
Перечисление (Enum) | thinking_level: "minimal"/"low"/"medium"/"high" |
Упрощенная настройка по уровням под конкретную задачу |
| Совместимость | ⚠️ Не использовать вместе | — | Одновременная передача обоих параметров вызовет ошибку 400 | Выбирайте один параметр в зависимости от версии модели |
Основные различия в параметрах режима мышления Gemini
Главная причина, по которой Google ввела параметр thinking_level в Gemini 3.0 — это упрощение жизни разработчикам. В Gemini 2.5 параметр thinking_budget требовал от нас довольно точного расчета количества токенов на «размышления». В Gemini 3.0 эта сложность скрыта за четырьмя понятными уровнями, что значительно снижает порог входа.
Такое изменение отражает подход Google к развитию API: небольшая потеря гибкости ради удобства и единообразия между разными моделями. Для большинства задач абстракции thinking_level вполне достаточно. К thinking_budget стоит возвращаться только если вам нужна экстремальная оптимизация затрат или специфический контроль лимитов токенов.
💡 Технический совет: На практике мы рекомендуем тестировать вызовы через платформу APIYI (apiyi.com). Она предоставляет единый интерфейс для работы с моделями Gemini 2.5 Flash, Gemini 3.0 Pro и Gemini 3.0 Flash, что позволяет быстро проверить, как разные настройки режима мышления влияют на результат и стоимость в реальных условиях.
Основная причина ошибки: стратегия прямой совместимости параметров
Разбор сообщения об ошибке API
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
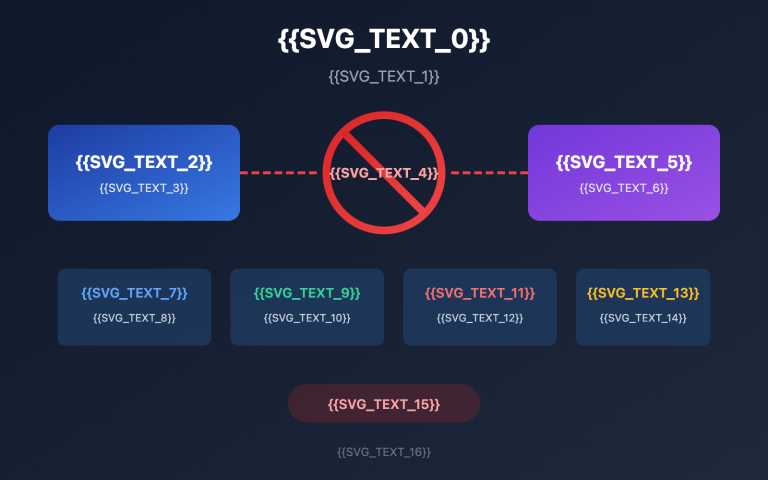
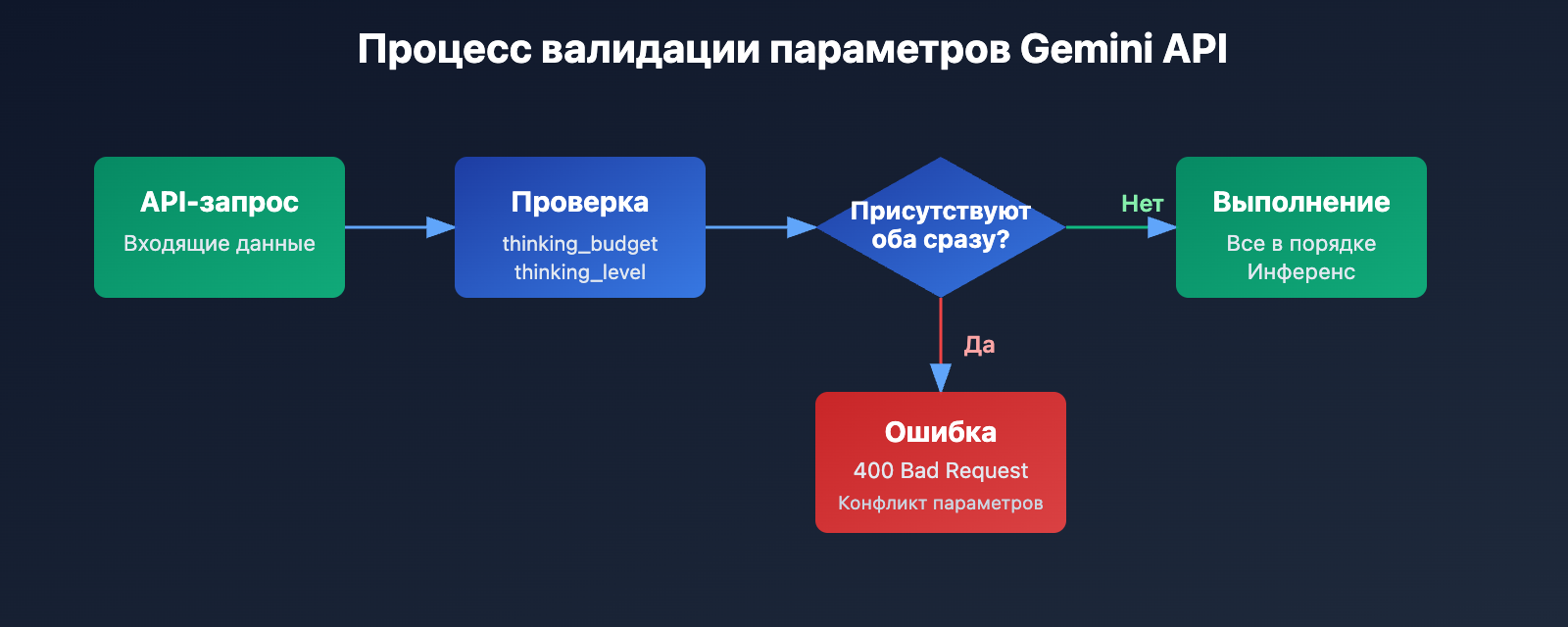
Суть ошибки проста: thinking_budget и thinking_level не могут использоваться одновременно. Google ввел новые параметры в Gemini 3.0, но не стал сразу удалять старые, а применил стратегию взаимоисключения:
- Модели Gemini 2.5: принимают только
thinking_budget, игнорируяthinking_level. - Модели Gemini 3.0: отдают приоритет
thinking_level, но принимаютthinking_budgetдля обратной совместимости. Однако передавать оба параметра сразу запрещено. - Условие возникновения ошибки: в API-запросе одновременно присутствуют параметры
thinking_budgetиthinking_level.
Почему возникает эта ошибка?
Разработчики обычно сталкиваются с этой проблемой в трех случаях:
| Сценарий | Причина | Типичные признаки в коде |
|---|---|---|
| 1. Автозаполнение в SDK | Некоторые AI-фреймворки (например, LiteLLM, AG2) автоматически подставляют параметры в зависимости от имени модели, что приводит к дублированию. | Использование готовых SDK без проверки тела фактического запроса. |
| 2. Хардкод в конфигурации | В коде жестко прописан thinking_budget, а при переходе на Gemini 3.0 имя параметра не обновили. |
Присвоение значений обоим параметрам в конфигах или коде. |
| 3. Ошибка в алиасах моделей | Использование алиасов типа gemini-flash-preview, которые указывают на Gemini 3.0, в то время как настройки остались от версии 2.5. |
Имя модели содержит preview или latest, а конфиг параметров не синхронизирован. |
🎯 Совет: При смене версии модели Gemini рекомендуем сначала протестировать совместимость параметров на платформе APIYI (apiyi.com). Платформа поддерживает быстрое переключение между моделями серий Gemini 2.5 и 3.0, что позволяет легко сравнить качество ответов и задержку при разных настройках режима мышления, избегая конфликтов в продакшене.
3 решения: выбор правильных параметров в зависимости от версии модели
Вариант 1: Конфигурация для Gemini 2.5 (используем thinking_budget)
Подходящие модели: gemini-2.5-flash, gemini-2.5-pro и др.
Описание параметров:
thinking_budget: 0— полностью отключить режим мышления (минимальная задержка и стоимость).thinking_budget: -1— динамический режим: модель сама решает, сколько думать, исходя из сложности промпта.thinking_budget: <положительное число>— точное ограничение количества токенов на размышление.
Краткий пример
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Объясни принцип квантовой запутанности"}],
extra_body={
"thinking_budget": -1 # Динамический режим мышления
}
)
print(response.choices[0].message.content)
Посмотреть полный код (с извлечением процесса размышления)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Объясни принцип квантовой запутанности"}],
extra_body={
"thinking_budget": -1, # Динамический режим
"include_thoughts": True # Включить возврат цепочки рассуждений
}
)
# Извлекаем процесс размышления (если включено)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"Процесс размышления: {part.text}")
# Извлекаем итоговый ответ
final_answer = response.choices[0].message.content
print(f"Итоговый ответ: {final_answer}")
Важно: Поддержка моделей Gemini 2.5 прекратится 3 марта 2026 года. Рекомендуем заранее запланировать переход на серию Gemini 3.0. На платформе APIYI (apiyi.com) вы можете быстро сравнить качество ответов до и после миграции.
Вариант 2: Конфигурация для Gemini 3.0 (используем thinking_level)
Подходящие модели: gemini-3.0-flash-preview, gemini-3.0-pro-preview.
Описание параметров:
thinking_level: "minimal"— минимальное мышление, почти нулевой бюджет. Требует передачи подписей размышлений (Thought Signatures).thinking_level: "low"— низкая интенсивность, подходит для простых инструкций и чатов.thinking_level: "medium"— средняя интенсивность, оптимально для общих логических задач (поддерживается только в Gemini 3.0 Flash).thinking_level: "high"— высокая интенсивность, максимальная глубина рассуждений для сложных вопросов (значение по умолчанию).
Краткий пример
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Проанализируй временную сложность этого кода"}],
extra_body={
"thinking_level": "medium" # Средняя интенсивность мышления
}
)
print(response.choices[0].message.content)
Посмотреть полный код (с передачей подписей размышлений)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Первый этап диалога
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Спроектируй алгоритм LRU-кэша"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Извлекаем подписи размышлений (Gemini 3.0 возвращает их автоматически)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# Второй этап диалога: передаем подписи для сохранения логической цепочки
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "Спроектируй алгоритм LRU-кэша"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "Оптимизируй пространственную сложность этого алгоритма"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 Оптимизация затрат: Для проектов с ограниченным бюджетом отлично подходит Gemini 3.0 Flash API через платформу APIYI (apiyi.com). Платформа предлагает гибкую тарификацию и выгодные цены, что удобно как для команд, так и для индивидуальных разработчиков. Использование
thinking_level: "low"поможет дополнительно снизить расходы.
Вариант 3: Стратегия адаптации при динамическом переключении моделей
Когда использовать: Если ваш код должен поддерживать и Gemini 2.5, и Gemini 3.0 одновременно.
Функция умной адаптации параметров
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
Автоматически выбирает правильный параметр режима мышления в зависимости от модели.
Args:
model_name: Имя модели Gemini
complexity: Сложность мышления ("minimal", "low", "medium", "high", "dynamic")
Returns:
Словарь параметров для extra_body
"""
# Список моделей Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Список моделей Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# Проверяем версию модели
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 использует thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # По умолчанию высокая интенсивность
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 использует thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# Для неизвестных моделей используем параметры Gemini 3.0 по умолчанию
return {"thinking_level": "medium"}
# Пример использования
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # Можно менять динамически
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Ваш вопрос"}],
extra_body=thinking_config
)

| Сложность мышления | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | Когда использовать |
|---|---|---|---|
| Минимальная | 0 |
"minimal" |
Простые инструкции, высокая пропускная способность |
| Низкая | 512 |
"low" |
Чат-боты, легкие вопросы-ответы |
| Средняя | 2048 |
"medium" |
Обычные логические задачи, генерация кода |
| Высокая | 8192 |
"high" |
Сложные вычисления, глубокий анализ |
| Динамическая | -1 |
"high" (дефолт) |
Автоподстройка под сложность |
🚀 Быстрый старт: Рекомендуем использовать платформу APIYI (apiyi.com) для быстрого прототипирования. Платформа предоставляет готовые интерфейсы Gemini API, не требует сложной настройки и позволяет интегрировать модель за 5 минут, переключая параметры мышления одним кликом для сравнения результатов.
Подробный разбор механизма сигнатур мышления (Thought Signatures) в Gemini 3.0
Что такое сигнатуры мышления?
Введенные в Gemini 3.0 сигнатуры мышления (Thought Signatures) — это зашифрованное представление внутреннего процесса рассуждения модели. Если вы включаете параметр include_thoughts: true, модель возвращает в ответе зашифрованную сигнатуру процесса мышления. Вы можете передавать эти сигнатуры в последующих сообщениях, чтобы модель сохраняла последовательность своей цепочки рассуждений.
Основные особенности:
- Зашифрованное представление: Содержимое сигнатуры нечитаемо, его может расшифровать только сама модель.
- Сохранение цепочки рассуждений: Передавая сигнатуру в многоэтапных диалогах, вы позволяете модели продолжать рассуждение на основе своих предыдущих мыслей.
- Принудительный возврат: Gemini 3.0 по умолчанию возвращает сигнатуру мышления, даже если вы её не запрашивали.
Практические сценарии использования сигнатур мышления
| Сценарий | Нужно ли передавать сигнатуру | Пояснение |
|---|---|---|
| Одиночный вопрос-ответ | ❌ Нет | Изолированный вопрос, не требующий сохранения цепочки рассуждений |
| Простой многоэтапный диалог | ❌ Нет | Контекста достаточно, нет зависимости от сложных рассуждений |
| Диалог со сложными рассуждениями | ✅ Да | Например: рефакторинг кода, математические доказательства, многошаговый анализ |
| Минимальный режим мышления (minimal) | ✅ Обязательно | Режим thinking_level: "minimal" требует передачи сигнатуры, иначе вернется ошибка 400 |
Пример кода для передачи сигнатуры мышления
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Раунд 1: просим модель спроектировать алгоритм
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "设计一个分布式限流算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Извлекаем сигнатуру мышления
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# Раунд 2: продолжаем оптимизацию на основе предыдущих рассуждений
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "设计一个分布式限流算法"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # Передаем сигнатуру мышления
},
{"role": "user", "content": "如何处理分布式时钟不一致问题?"}
],
extra_body={"thinking_level": "high"}
)
💡 Лучшая практика: В сценариях, требующих многоэтапных сложных рассуждений (проектирование систем, оптимизация алгоритмов, код-ревью), рекомендуем протестировать разницу в результатах с передачей сигнатур на платформе APIYI apiyi.com. Платформа полностью поддерживает механизм сигнатур Gemini 3.0, что позволяет легко проверить качество рассуждений при разных конфигурациях.
Часто задаваемые вопросы
Q1: Почему Gemini 2.5 Flash продолжает возвращать мысли, даже если thinking_budget=0?
Это известный баг в версии Gemini 2.5 Flash Preview 04-17: параметр thinking_budget=0 не выполняется корректно. Google подтвердили эту проблему на официальном форуме.
Временные решения:
- Используйте
thinking_budget=1(минимальное значение) вместо 0. - Перейдите на Gemini 3.0 Flash и используйте
thinking_level="minimal". - Фильтруйте содержимое мыслей на этапе пост-обработки (если API вернул поле thought).
Рекомендуем быстро переключиться на модель Gemini 3.0 Flash через APIYI apiyi.com — платформа поддерживает последние версии, что позволяет избежать подобных багов.
Q2: Как понять, какая модель используется — Gemini 2.5 или 3.0?
Способ 1: Проверить название модели
- Gemini 2.x: названия содержат
2.5-flash,2-flash-lite. - Gemini 3.x: названия содержат
3.0-flash,3-pro,gemini-3-flash.
Способ 2: Отправить тестовый запрос
# Передаем только thinking_level и смотрим на ответ
response = client.chat.completions.create(
model="your-model-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# Если возвращается ошибка 400 с пометкой, что thinking_level не поддерживается — это Gemini 2.5
Способ 3: Проверить заголовки ответа API
Некоторые реализации API возвращают поле X-Model-Version в заголовках, по которому можно напрямую идентифицировать версию модели.
Q3: Сколько токенов потребляют разные уровни thinking_level в Gemini 3.0?
Google официально не раскрывает точный бюджет токенов для каждого thinking_level, давая лишь общие ориентиры:
| thinking_level | Относительная стоимость | Относительная задержка | Глубина рассуждений |
|---|---|---|---|
| minimal | Самая низкая | Самая низкая | Практически без рассуждений |
| low | Низкая | Низкая | Поверхностные рассуждения |
| medium | Средняя | Средняя | Средний уровень рассуждений |
| high | Высокая | Высокая | Глубокие рассуждения |
Советы по практике:
- Сравните фактическое потребление токенов для разных уровней на платформе APIYI apiyi.com.
- Используйте один и тот же промпт и вызывайте модель с параметрами low/medium/high, чтобы увидеть разницу в расходах.
- Выбирайте подходящий уровень исходя из конкретной бизнес-задачи (качество ответа против стоимости).
Q4: Можно ли принудительно использовать thinking_budget в Gemini 3.0?
Можно, но не рекомендуется.
Для обеспечения обратной совместимости Gemini 3.0 всё еще принимает параметр thinking_budget, однако в официальной документации четко указано:
"Хотя
thinking_budgetпринимается для обратной совместимости, его использование с Gemini 3 Pro может привести к неоптимальной производительности."
Причины:
- Внутренние механизмы рассуждения Gemini 3.0 уже оптимизированы под
thinking_level. - Принудительное использование
thinking_budgetможет обойти новые стратегии рассуждения. - Это может привести к снижению качества ответов или увеличению задержек.
Как делать правильно:
- Переходите на использование параметра
thinking_level. - Используйте функции адаптации параметров (как в примере из "Варианта 3" выше) для динамического выбора корректных аргументов.
Итоги
Основные причины ошибок с параметрами thinking_budget и thinking_level в Gemini API:
- Взаимоисключающие параметры: Gemini 2.5 использует
thinking_budget, а Gemini 3.0 —thinking_level. Передавать их одновременно нельзя. - Идентификация модели: Версия определяется по названию. Для серии 2.5 используйте
thinking_budget, для серии 3.0 —thinking_level. - Динамическая адаптация: Используйте функции-адаптеры, которые автоматически выбирают нужный параметр в зависимости от имени модели, чтобы избежать жесткого кодирования (hardcoding).
- Подписи размышлений (Thinking Signatures): В Gemini 3.0 появился механизм сигнатур. В сложных сценариях с несколькими итерациями диалога (multi-turn) нужно передавать эти подписи, чтобы сохранять цепочку рассуждений.
- Рекомендации по миграции: Поддержка Gemini 2.5 прекратится 3 марта 2026 года. Советуем как можно скорее переходить на серию 3.0.
Рекомендуем использовать APIYI (apiyi.com) для быстрой проверки различных конфигураций режима размышлений. Платформа поддерживает всю линейку моделей Gemini, предоставляет унифицированный интерфейс и гибкую систему тарификации, что отлично подходит как для быстрого тестирования, так и для развертывания в продакшене.
Автор: Техническая команда APIYI | Если у вас возникли вопросы, заходите на APIYI (apiyi.com) за новыми решениями по интеграции моделей ИИ.